基于PostgreSQL的大规模并行处理数据库-Greenplum DB
 Greenplum(GPDB)之前是一家总部位于美国加利福尼亚州,为全球大型企业用户提供新型企业级数据仓库(EDW)、企业级数据云(EDC)和商务智能(BI)提供解决方案和咨询服务的公司。Greenplum 已经归属于 Pivotal,采用 Apache协议授权。它是一个无共享的大规模并行处理数据库,主要用来处理大规模的数据分析任务,包括数据仓库、商务智能OLAP和数据挖掘等。GPDB专为海量数据分析而生,使用最先进的基于成本的查询优化器,是目前最为先进的开源数据库之一,能对PB级数据进行快速高效的查询、分析。Greenplum最为一个严格的数据库系统,同样支持线性扩展,高可用性架构,数据与主机的容错机制,还有数据的分区与压缩功能。
Greenplum(GPDB)之前是一家总部位于美国加利福尼亚州,为全球大型企业用户提供新型企业级数据仓库(EDW)、企业级数据云(EDC)和商务智能(BI)提供解决方案和咨询服务的公司。Greenplum 已经归属于 Pivotal,采用 Apache协议授权。它是一个无共享的大规模并行处理数据库,主要用来处理大规模的数据分析任务,包括数据仓库、商务智能OLAP和数据挖掘等。GPDB专为海量数据分析而生,使用最先进的基于成本的查询优化器,是目前最为先进的开源数据库之一,能对PB级数据进行快速高效的查询、分析。Greenplum最为一个严格的数据库系统,同样支持线性扩展,高可用性架构,数据与主机的容错机制,还有数据的分区与压缩功能。Pivotal Greenplum Database
Massively-Parallel, Shared-Nothing Database based on PostgreSQL
The Greenplum Database (GPDB) is an advanced, fully featured, open source data warehouse. It provides powerful and rapid analytics on petabyte scale data volumes. Uniquely geared toward big data analytics, Greenplum Database is powered by the world’s most advanced cost-based query optimizer delivering high analytical query performance on large data volumes.
Greenplum DB 号称是世界上第一个开源的大规模并行数据仓库,最初是基于 PostgreSQL,现在已经添加了大量数据库方面的创新。Greenplum 提供 PD 级别数据量的强大和快速分析能力,特别是面向大数据方面的分析能力,支持大数据的超高性能分析查询。Greenplum官方中文文档提供相当多的中文参考。
Greenplum数据库也简称GPDB,它拥有丰富的特性:
1,完善的标准支持:GPDB完全支持ANSI SQL 2008标准和SQL OLAP 2003 扩展;从应用编程接口上讲,它支持ODBC和JDBC。完善的标准支持使得系统开发、维护和管理都大为方便。而现在的 NoSQL,NewSQL和Hadoop 对 SQL 的支持都不完善,不同的系统需要单独开发和管理,且移植性不好。
2,支持分布式事务,支持ACID。保证数据的强一致性。
3,做为分布式数据库,拥有良好的线性扩展能力。在国内外用户生产环境中,具有上百个物理节点的GPDB集群都有很多案例。
4,GPDB是企业级数据库产品,全球有上千个集群在不同客户的生产环境运行。这些集群为全球很多大的金融、政府、物流、零售等公司的关键业务提供服务。
5,GPDB是Greenplum(现在的Pivotal)公司十多年研发投入的结果。GPDB基于PostgreSQL 8.2,PostgreSQL 8.2有大约80万行源代码,而GPDB现在有130万行源码。相比PostgreSQL 8.2,增加了约50万行的源代码。
6,Greenplum有很多合作伙伴,GPDB有完善的生态系统,可以与很多企业级产品集成,譬如SAS,Cognos,Informatic,Tableau等;也可以很多种开源软件集成,譬如Pentaho,Talend 等。
Greenplum设计初衷是面向大规模数据分析的,能轻松扩展到 Petabyte 级别,通过 Greenplum 的并行数据流引擎能够让程序员玩 MapReduce,DBA 跑 SQL,可谓两全其美。Greenplum采用PostgreSQL Wire Protocol,所有可以同PostgreSQL交互的工具都可以顺畅地同Greenplum交互。
GreenPlum主要特性
大规模并行处理架构
高性能加载,使用 MPP 技术,提供 Petabyte 级别数据量的加载性能
大数据工作流查询优化
多态数据存储和执行
基于 Apache MADLib 的高级机器学习功能
借助于HAWQ,PostgreSQL 以及 PostGIS,完全可以构建一体化的 PostgreSQL 企业数据架构。
Greenplum的架构采用了MPP(大规模并行处理)。在 MPP 系统中,每个 SMP 节点也可以运行自己的操作系统、数据库等。换言之,每个节点内的 CPU 不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution) 。
与传统的SMP架构明显不同,通常情况下,MPP系统因为要在不同处理单元之间传送信息,所以它的效率要比SMP要差一点,但是这也不是绝对的,因为MPP系统不共享资源,因此对它而言,资源比SMP要多,当需要处理的事务达到一定规模时,MPP的效率要比SMP好。这就是看通信时间占用计算时间的比例而定,如果通信时间比较多,那MPP系统就不占优势了,相反如果通信时间比较少,那MPP系统可以充分发挥资源的优势,达到高效率。
当前使用的OTLP程序中,用户访问一个中心数据库,如果采用SMP系统结构,它的效率要比采用MPP结构要快得多。而MPP系统在决策支持和数据挖掘方面显示了优势,可以这样说,如果操作相互之间没有什么关系,处理单元之间需要进行的通信比较少,那采用MPP系统就要好,相反就不合适了。
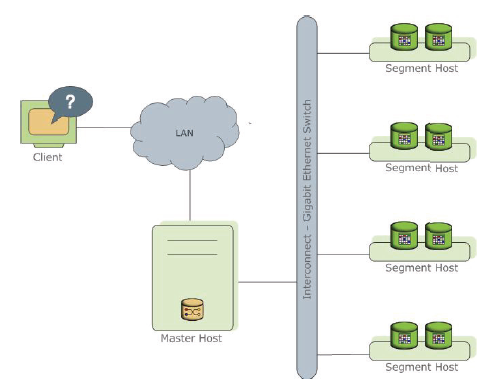
Greenplum架构图
了解完Greenplum的架构后,对其工作流程也就相对简单了。因greenplum采用了MPP架构,其主要的优点是大规模的并行处理能力,应该把精力主要放并行处理与在大规模存储两个方面。
并行处理
Greenplum的并行处理主要体现在外部表并行装载,并行备份恢复与并行查询处理三个方面。数据仓库的主要精力一般集中在数据的装载和查询,数据的并行装载主要是在采用外部表或者web表方式,通常情况下通过gpfdist来实现。
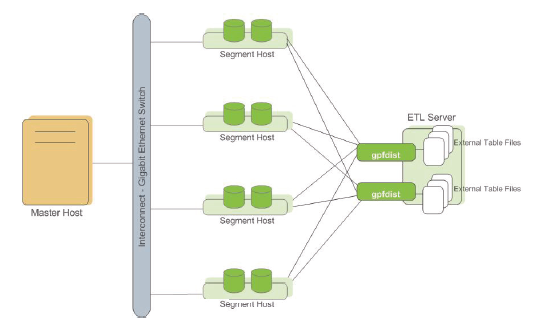
Gpfidist架构
Gpfdist程序能够以370MB/s装载text格式的文件和200MB/s装载CSV格式文件,ETL带宽为1GB的情况下,我们可以运行3个gpfdist程序装载text文件,或者运行5个gpfdist程序装载CSV格式文件。可以根据实际的环境通过配置postgresql.conf参数文件来优化装载性能。
查询性能的强弱往往由查询优化器的水平来决定,greenplum主节点负责解析SQL与生成执行计划。Greenplum的执行计划生成同样采用基于成本的方式,基于数据库是由诸多segment实例组成,在选择执行计划时主节点还要综合考虑节点间传送数据的代价。
I/O瓶颈的解决为并行计算能力的提升创造了良好的环境,下面一起来看看Greenplum是如何进行高性能的并行计算的。
在硬件方面,Greenplum可以使用标准的服务器并通过服务器间的高级通信连接,将多台服务器组成一个强大的计算平台,实现快速的海量并行运算。
在系统内部,Greenplum通过自己的并行数据流引擎来实现更多计算需求的硬件资源调度。一般,多表JOIN操作是考验系统并行计算能力的经典 案例。在Greenplum中,这一过程是将一个表里的数据平均分布到每个节点,并为每个表指定一个分发列,之后便根据Hash算法来分布数据。
这样,每个节点的数据通过分发列即得知。如果对Distribute Column做JOIN操作,只需要通过分发列得到数据的节点位置,并对相应的节点进行计算,最后合并结果就可完成。当然这种几个表规模的查询还不能证明Greenplum在并行计算方面的能力。但重要的是,通过Greenplum的并行数据流引擎,我们可以在一个主机上同时启动多个PostgreSQL数据库进行更多表的关联及更复杂的查询操作。这就充分发挥了硬件资源的性能。
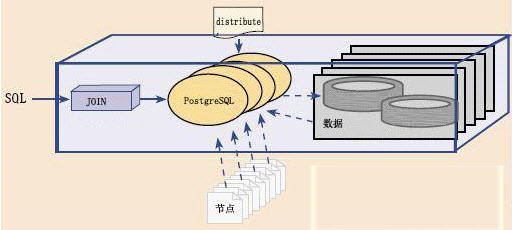
在进行数据装载时,不是常规的一个中心数据源将数据分发至各节点,而是所有节点同时读取数据,然后根据Hash算法,将属于自己的数据留下,将其他的节点的数据通过网络直接传送给需求方。这种多数据流的并行传输保证了高性能的数据装载速度。
在进行并发数据分析时,Greenplum的另一个强大之处是支持对一个Segment节点的虚拟化,在载入数据后,我们可以对数据节点虚拟多个数 据库进行并行分析操作,依旧源于Share nothing架构,Greenplum的一个Segment可支持2-10个虚拟数据库(官方推荐为6个),可以最大限度发挥硬件设备,提高并行规模和查询分析效率。
大规模存储
Greenplum数据库通过将数据分布到多个节点上来实现规模数据的存储。数据库的瓶颈经常发生在I/O方面,数据库的诸多性能问题最终总能归罪到I/O身上,久而久之,IO瓶颈成为了数据库性能的永恒的话题。
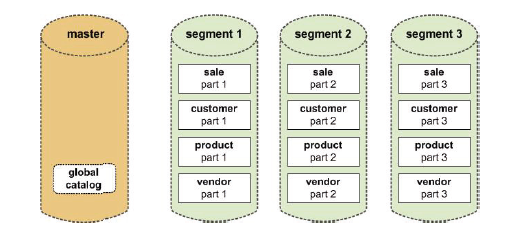
Greenplum采用分而治之的办法,将数据规律的分布到节点上,充分利用segment主机的IO能力,以此让系统达到最大的IO能力主要是带宽。
在Greenplum中每个表都是分布在所有节点上的。Master host首先通过对表的某个或多个列进行hash运算,然后根据hash结果将表的数据分布到segment host中。整个过程中master host不存放任何用户数据,只是对客户端进行访问控制和存储表分布逻辑的元数据。
Greenplum起源
Greenplum最早是在10多年前(大约在2002年)出现的,基本上和Hadoop是同一时期(Hadoop 约是2004年前后,早期的Nutch可追溯到2002年)。当时的背景是:
互联网行业经过之前近10年的由慢到快的发展,累积了大量信息和数据,数据在爆发式增长,这些海量数据急需新的计算方式,需要一场计算方式的革命;
传统的主机计算模式在海量数据面前,除了造价昂贵外,在技术上也难于满足数据计算性能指标,传统主机的Scale-up模式遇到了瓶颈,SMP(对称多处理)架构难于扩展,并且在CPU计算和IO吞吐上不能满足海量数据的计算需求;
分布式存储和分布式计算理论刚刚被提出来,Google的两篇著名论文发表后引起业界的关注,一篇是关于GFS分布式文件系统,另外一篇是关于MapReduce 并行计算框架的理论,分布式计算模式在互联网行业特别是收索引擎和分词检索等方面获得了巨大成功。
Greenplum数据库基于PostgreSQL开源技术。本质上讲,它是多个PostgreSQL实例一起充当一个数据库管理系统。Greenplum以PostgreSQL 8.2.15为基础构建,在SQL支持、特性、配置选项和终端用户功能方面非常像PostgreSQL,用户操作Greenplum就跟平常操作PostgreSQL一样。不过,为了支持Greenplum数据库的并发结构,PostgreSQL的内部构件经过了修补。例如,为了在所有并行的PostgreSQL数据实例上并发执行查询,系统目录、优化器、查询执行器以及事务管理器组件都经过了修改和增强。此外,Greenplum还引入了针对商业智能工作负载优化PostgreSQL的特性。如增加了并行数据加载、资源管理、查询优化、存储增强。这些功能是标准PostgreSQL所不具备的。
Greenplum master是Greenplum数据库系统的入口,接受客户端连接及提交的SQL语句,将工作负载分发给其它数据库实例(segment实例),由它们存储和处理数据。Greenplum interconnect负责不同PostgreSQL实例之间的通信。Greenplum segment是独立的PostgreSQL数据库,每个segment存储一部分数据。大部分查询处理都由segment完成。
根据Pivotal的开源公告,他们希望Greenplum会成为一个重大的里程碑,永久改变数据仓库这个行业。Greenplum数据库与其它开源数据处理系统(如Apache Hadoop、MySQL甚或PostgreSQL)的差别在架构和功能上都有体现。借助MPP,Greenplum在大型数据集上执行复杂SQL分析的速度比他们测试过的任何一个方案都要快。而借助下一代查询优化技术,Greenplum带来了其它开源方案中没有的数据管理质量特性、升级和扩展能力。他们相信,这样一款经过证明的、广泛采用的数据仓库开源将会在整个业界引发巨大的连锁反应。最重要的是,这降低了大规模实时数据分析的门槛,更多的公司可以参与到大数据所带来的挑战中来。
另据InfoWorld报道,数据库行业分析师Curt Monash将Greenplum视为分析型RDBMS的真正竞争者。而且,相比现有的产品(如Teradata、HP Vertica、IBM Netezza和Oracle Exadata),其引入成本更低。Greenplum作为一项服务似乎是个再简单不过的选择,它有一个为人熟知的名字和广泛的用户基础。MySQL或PostgreSQL也通过类似的技术提供云端服务。但Greenplum真要展现出其优势,需要做好两个方面的工作:一是从现有的Greenplum部署移植要简单;二是有一个可行的发展路线,要么可以通过其它云托管产品富集数据,要么集成新兴的分析技术,如Spark。
在Hacker News上,Pivotal Labs成员jacques_chester回答了多名网友的问题。网友tlrobinson提出:
为什么Greenplum以PostgreSQL 8.2为基础,而不是更新的版本?
对此,jacques_chester解释说,“那是因为Greenplum最初从该版本派生。”网友djokkataja的问题也是围绕这一点:
现在有计划吗?Greenplum最终是否会与现行的PostgreSQL开发有同等的特性,或者Greenplum主要还是遵循自己的发展路线?
jacques_chester并没有明确回答这个问题,只是说,这取决于许多因素。同时他还指出:
Greenplum采用PostgreSQL Wire Protocol。所有可以同PostgreSQL交互的工具都可以顺畅地同Greenplum交互。
还有网友担心Greenplum的单master会成为写入瓶颈,jacques_chester答复说,这是gpfdist要解决的问题,只要正确使用,就可以实现批量并行加载,而且master不会成为瓶颈。
总的来说,Greenplum具有下面一些优点:
数据存储
当今是个数据不断膨胀的时代,采取MPP架构的数据库系统可以对海量数据进行管理。Greenplum支持50PB(1PB=1024TB)级海量数据的存储和处理,Greenplum将来自不同源系统的、不同部门、不同平台的数据集成到数据库中集中存放,并且存放详尽历史的数据轨迹,业务用户不用再面对一个又一个信息孤岛,也不再困惑于不同版本数据导致的偏差,同时对于IT人员也降低管理维护工作的复杂度。
高并发
随着商业智能在企业内的快速发展,BI 用户对信息分析平台的访问频率和查询复杂度也快速提升,因此要求相应的数据库系统对高并发查询进行支持。Greenplum利用强大并行处理能力提供并发支持。Greenplum提供资源管理功能(workload managemnt)来管理数据库资源,利用资源队列管理可实现按用户组的进行资源分配,如Session同时激活数、最大资源值等。通过资源管理功能,可以按用户级别进行资源分配和管理用户SQL查询优先级别,同时也能防止低质量SQL(如没有条件的多表join等)对系统资源的消耗。
线性扩展
Greenplum与其他分布式大数据产品如Yonghong Z-DataMart一样采用了通用的MPP并行处理架构,在MPP架构中增加节点就可以线性提高系统的存储容量和处理能力。Greenplum在扩展节点时操作简单,在很短时间内就能完成数据的重新分布。Greenplum线性扩展支持为数据分析系统将来的拓展给予了技术上的保障,用户可根据实施需要进行容量和性能的扩展。
高性价比
Greenplum数据库软件系统节点基于业界各种开放式硬件平台,如SUN/HP/DELL等厂商的PC Server等,在普通的x86 Server上就能达到很高的性能,因此性价比很高,相比于其他封闭式数据仓库专用系统,Greenplum每TB的投资是前者的1/5甚至更低。同样,Greenplum产品的维护成本相比同类厂商也低许多。
反应速度
我们面对的是一个瞬息变化的市场,谁能首先感知到市场的需求和变化,就能在竞争中先行一步,获得主动权,在竞争中立于不败之地。Greenplum通过准实时、实时的数据加载方式,实现数据仓库的实时更新,进而实现动态数据仓库(ADW)。基于动态数据仓库,业务用户能对当前业务数据进行BI实时分析-“Just In Time BI”,能够让企业敏锐感知市场的变化,加快决策支持反应速度。
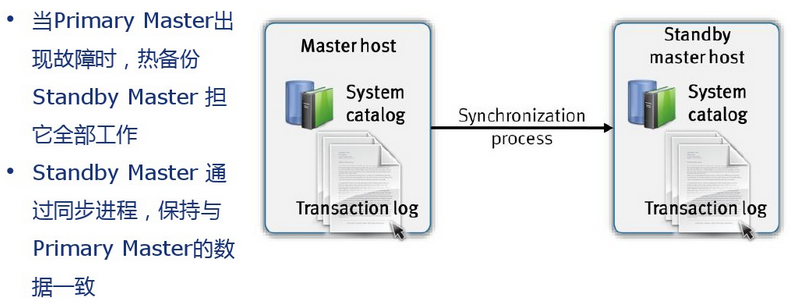
高可用性
Greenplum是高可用的系统,在已有案例中最多使用了96台机器的集群MPP环境。除了硬件级的Raid技术外,Greenplum还提供数据库层Mirror机制保护,即每个节点数据在另外的节点中同步镜像,单个节点的错误不影响整个系统的使用。对于主节点,Greenplum提供Master/Stand by机制进行主节点容错,当主节点发生错误时,可以切换到Stand by节点继续服务。
整体易用
Greenplum产品是基于流行的PostgreSQL之上开发,几乎所有的PostgreSQL客户端工具及PostgreSQL应用都能运行在Greenplum平台上,在Internet上有着丰富的PostgreSQL资源供用户参考。
总体架构(这里参考了:海量数据处理利器greenplum--初识)
Greenplum的总体架构如下:
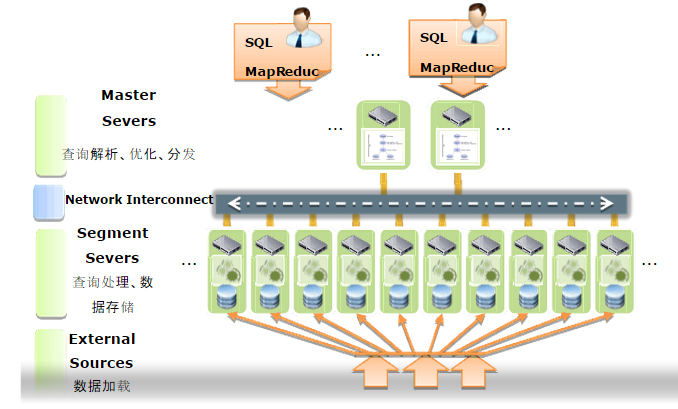
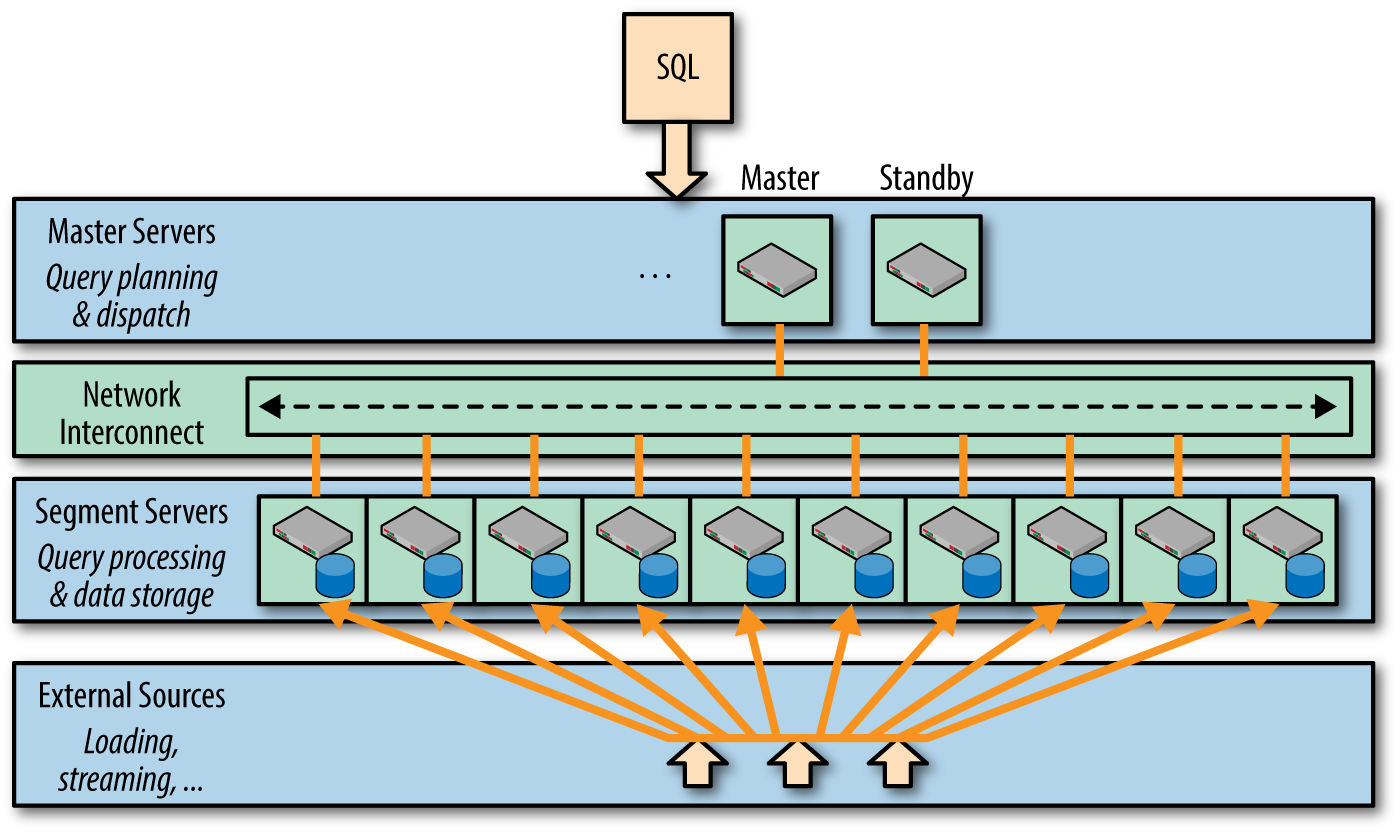
数据库由Master Severs和Segment Severs通过Interconnect互联组成。
Master主机负责:建立与客户端的连接和管理;SQL的解析并形成执行计划;执行计划向Segment的分发收集Segment的执行结果;Master不存储业务数据,只存储数据字典。
Segment主机负责:业务数据的存储和存取;用户查询SQL的执行。
greenplum使用mpp架构
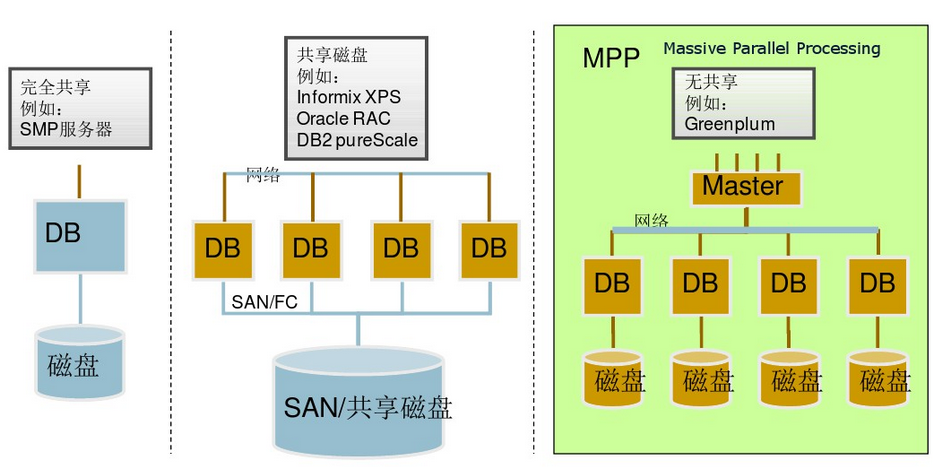
基本体系架构
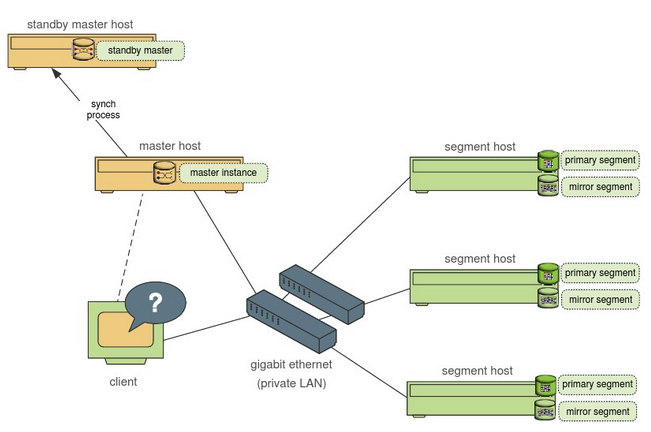
master节点,可以做成高可用的架构

master node高可用,类似于hadoop的namenode和second namenode,实现主备的高可用。
segments节点

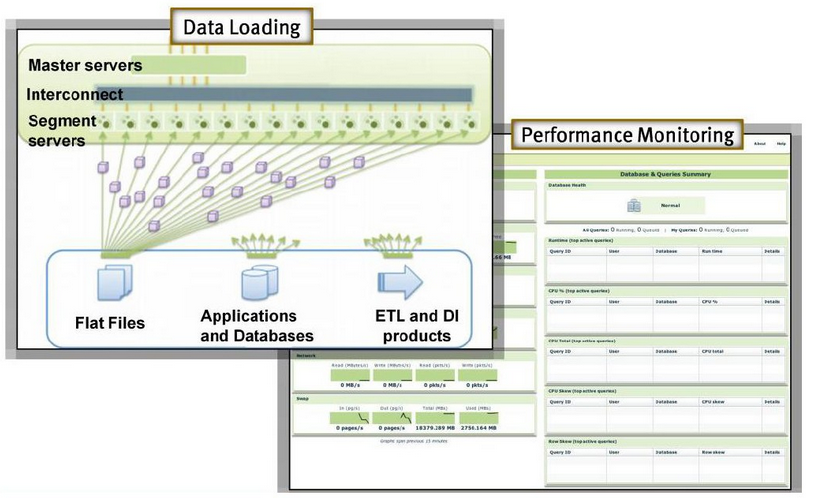
并行管理
对于数据的装载和性能监控。
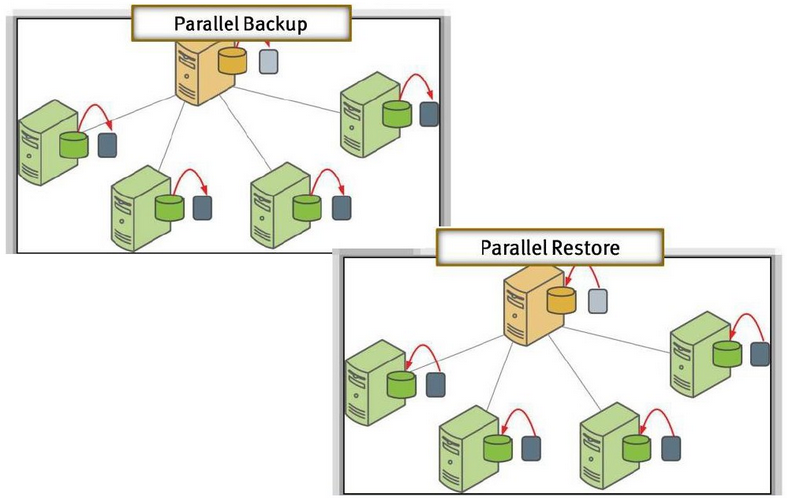
并行备份和恢复。
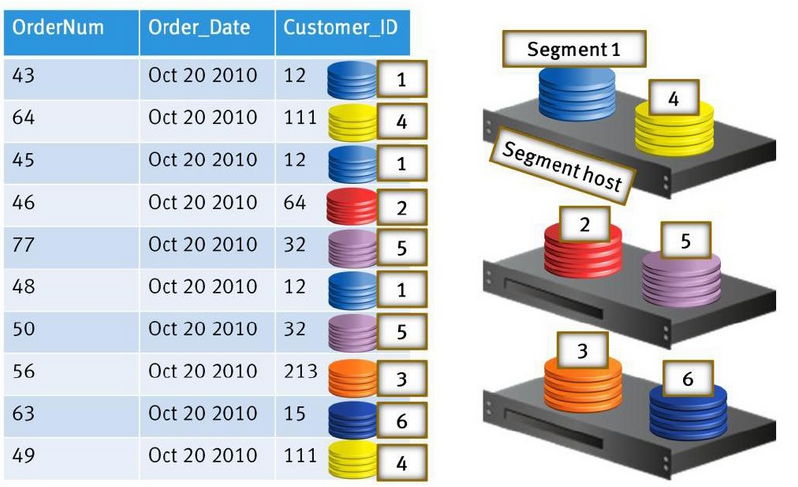
数据访问流程,数据分布到不同颜色的节点上
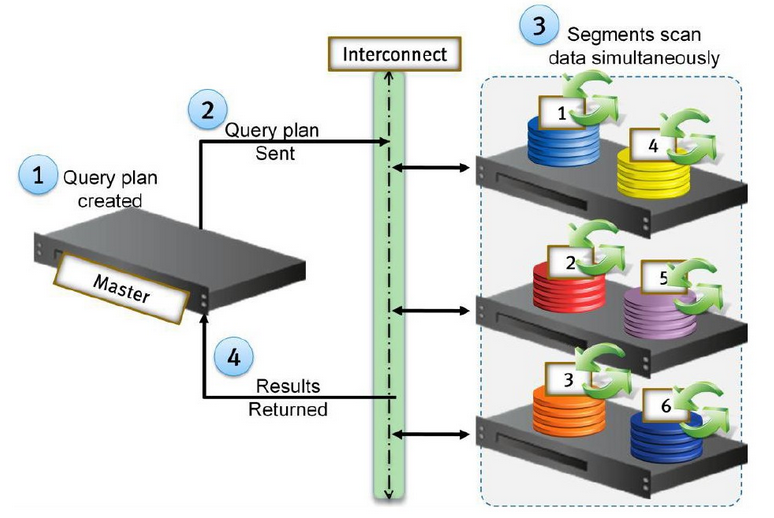
查询流程分为查询创建和查询分发,计算后将结果返回。
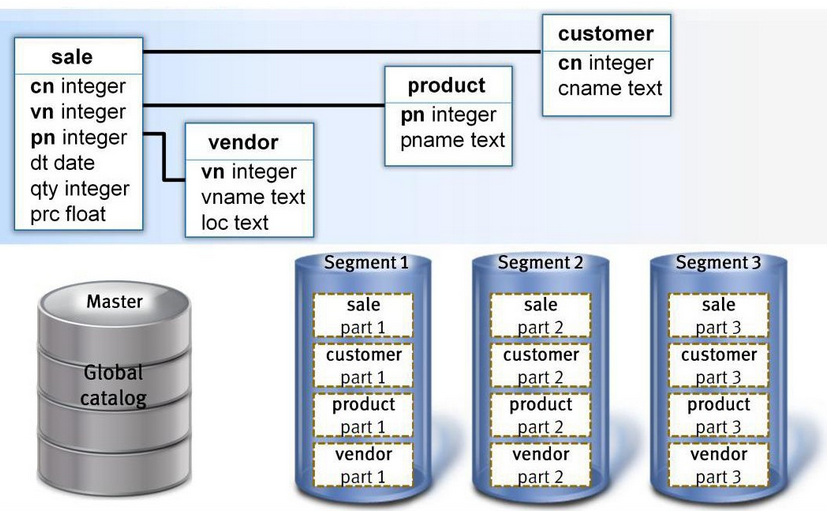
对于存储,将存储的内容分布到各个结点上。
对于数据的分布,分为hash分布和随机分布两种。
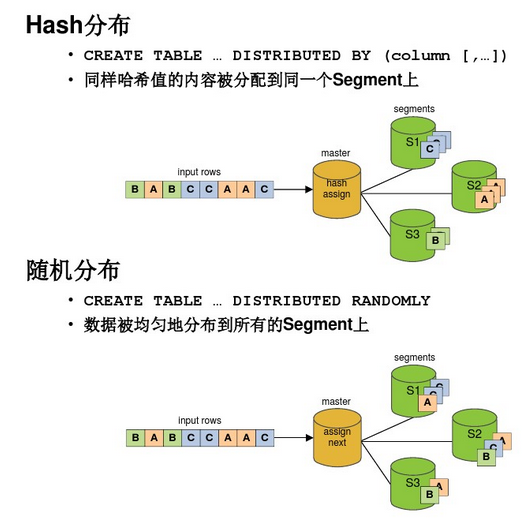
均匀分布的情况:

GPDB从开始设计的时候就被定义成数据仓库,如果是OLAP的应用,可以尝试使用GPDB。
Greenplum商业版具有众多扩展组件来帮助用户更便捷的使用Greenplum,其中Greenplum监控管理平台GPCC和数据加载解决方案GPSS均是其中关键组件之一,在过去的一个月中,GPSS和GPCC均进行了版本更新,新版本的GPSS和GPCC带来了一些新功能。
GPSS(Greenplum stream server)
GPSS 1.6.0已于2021年5日28日正式发布。Greenplum Stream Server简称GPSS是Greenplum下一代数据加载解决方案,能将不同源端的增量数据同步到Greenplum中。
新功能
gpss增加-c选项, 用于指定配置文件路径
gpsscli的--version参数也会打印gpss server的版本信息
gpss和gpsscli日志支持--color和--csv格式, 默认为空格分隔的文本格式
gpss的Kafka job配置新增IDLE_DURATION 参数, 当超过IDLE_DURATION 时间后对应的kafka topic中没有新消息, GPSS将会释放目标表的锁
gpss新增SCHEMA_PATH_ON_GPDB 参数, 支持从Greenplum集群的segment节点上获取avro的schema
gpss新增FALLBACK_OFFSET 参数, 可以设置当消息的offset不连续时(未及时加载就被清空)时,从何处继续加载消息
gpss支持基于HTTPS的scheme service服务
gpss支持了kafka的group.id 配置, 可通过第三方工具监控加载进度
除了exactly once, gpss支持最多一次和最少一次一致性保证
gpss支持通过custom formatter方式实现自定义消息格式
实验功能
gpss新增了RECOVER_FAILING_BATCH 配置, 可以将Greenplum无法处理的事务中的错误数据暂存
gpss组件增加了新的dataflow extension, 包含gp_jsonb数据类型和text_in formatter
GPCC(Greenplum Command Center)
GPCC 6.5已于2021年5月31日正式发布。Greenplum Command Center 6.5 为 Tanzu Greenplum Database 6 提供管理和监控功能,与以下平台兼容:
Tanzu Greenplum 数据库 6.x
Redhat 企业版 Linux 6.x1 和 7.x
CentOS 6.x1 和 7.x
SUSE 企业版 Linux 12
Ubuntu 18.04
有关最新的兼容性信息,请参阅Tanzu Greenplum Command Center支持平台相关文档。
增强功能
查询监视器Query Monitor页面现允许用户根据查询的状态正在运行、已排队或已阻止过滤显示的查询。更多信息,请参阅查询监视器文档
查询监视器页面现包含高级搜索工具。该工具允许用户根据查询指标例如查询 ID、数据库名称、资源组等过滤显示的查询。有关更多信息,请参阅查询监视器文档页面
用户现在可以暂停查询监视器以查看查询的快照。有关更多信息,请参阅查询监视器文档页面
查询监视器现在显示有关会话的各种信息,例如会话状态、关联的用户和数据库、空闲时间和关联的查询等。具有管理员或操作员权限的用户可以查看和取消所有用户的会话,以及将会话详细信息导出到 CSV 文件。有关更多信息,请参阅查询监视器文档页面
实时查询详细信息页面现在可以显示查询的查询标签
查询历史详情页面现在可以显示查询的查询标签
在历史记录页面上,高级搜索工具现在允许用户过滤查询的查询标签。有关更多信息,请参阅历史文档页面
用户可以创建工作负载规则来终止空闲会话,并可以检查终止会话的规则日志。有关更多信息,请参阅工作负载管理文档页面
用户可以通过溢出文件大小创建规则。有关更多信息,请参阅工作负载管理文档页面
gpmetrics 模式包含一个新的 gpmetrics.gpcc_queries_now 表,用于存储实时查询指标数据
gpcc_wlm_rule 表增加了两行:一个用于存储空闲会话终止规则的参数,另一个用于存储溢出文件大小。更多信息请参阅gpmetrics架构参考文档
Greenplum Command Center将不再支持Microsoft IE 浏览器。
2019年VMware 拟收购 Pivotal后,继2023年博通拟收购VMware,Greenplum的命运与前途变的岌岌可危。
Greenplum版本更新录(202x)
官方主页:http://greenplum.org/
项目主页:https://github.com/greenplum-db
该文章最后由 阿炯 于 2024-05-31 12:27:06 更新,目前是第 2 版。