 PostgreSQL是一个自由的对象-关系功能强大的开源数据库系统,采用C语言开发并在灵活的BSD风格许可证下发行。它提供了相对其他开放源代码数据库系统(比如 MySQL和Firebird),和对专有系统比如Oracle、Sybase、IBM 的 DB2 和 Microsoft SQL Server的一种选择。
PostgreSQL是一个自由的对象-关系功能强大的开源数据库系统,采用C语言开发并在灵活的BSD风格许可证下发行。它提供了相对其他开放源代码数据库系统(比如 MySQL和Firebird),和对专有系统比如Oracle、Sybase、IBM 的 DB2 和 Microsoft SQL Server的一种选择。PostgreSQL不寻常的名字导致一些读者停下来尝试拼读它,特别是那些把SQL拼读为"sequel"的人,PostgreSQL 开发者把它拼读为 "post-gress-Q-L",它也经常被简略念为 "postgres"。经过长达15年以上的积极开发和不断改进,PostgreSQL已在可靠性、稳定性、数据一致性等获得了业内极高的声誉。目前PostgreSQL可以运行在所有主流操作系统上,包括Linux、Unix(AIX、BSD、HP-UX、SGI IRIX、Mac OS X、Solaris和Tru64)和Windows。PostgreSQL是完全的事务安全性数据库,完整地支持外键、联合、视图、触发器和存储过程(并支持多种语言开发存储过程)。它支持了大多数的SQL:2008标准的数据类型,包括整型、数值值、布尔型、字节型、字符型、日期型、时间间隔型和时间型,它也支持存储二进制的大对像,包括图片、声音和视频。PostgreSQL对很多高级开发语言有原生的编程接口,如C/C++、Java、.Net、Perl、Python、Ruby、Tcl 和ODBC以及其他语言等,也包含各种文档。
PostgreSQL is a powerful, open source object-relational database system. It has more than 15 years of active development and a proven architecture that has earned it a strong reputation for reliability, data integrity, and correctness. It runs on all major operating systems, including Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64), and Windows. It is fully ACID compliant, has full support for foreign keys, joins, views, triggers, and stored procedures (in multiple languages). It includes most SQL:2008 data types, including INTEGER, NUMERIC, BOOLEAN, CHAR, VARCHAR, DATE, INTERVAL, and TIMESTAMP. It also supports storage of binary large objects, including pictures, sounds, or video. It has native programming interfaces for C/C++, Java, .Net, Perl, Python, Ruby, Tcl, ODBC, among others, and exceptional documentation.
An enterprise class database, PostgreSQL boasts sophisticated features such as Multi-Version Concurrency Control (MVCC), point in time recovery, tablespaces, asynchronous replication, nested transactions (savepoints), online/hot backups, a sophisticated query planner/optimizer, and write ahead logging for fault tolerance. It supports international character sets, multibyte character encodings, Unicode, and it is locale-aware for sorting, case-sensitivity, and formatting. It is highly scalable both in the sheer quantity of data it can manage and in the number of concurrent users it can accommodate. There are active PostgreSQL systems in production environments that manage in excess of 4 terabytes of data. Some general PostgreSQL limits are included in the table below.
最大单个数据库大小:不限
最大数据单表大小:32 TB
单条记录最大:1.6 TB
单字段最大允许:1 GB
单表允许最大记录数:不限
单表最大字段数:250 - 1600(取决于字段类型)
单表最大索引数:不限
由于PostgreSQL的优异性能,它已赢得最终用户和业内的多次大奖,包括Linux新媒体(Linux New Media)的最佳数据库奖和5次Linux期刊编辑选出的最佳数据库奖。做为世界上最为先进的开源关系型数据库专为可扩展性和自定义而设计的,支持ANSI/ISO兼容的SQL(强烈符合ANSI-SQL:2008标准规范)。并且它还具有良好的可靠性、可移植性、可伸缩性以及安全性。它具有如下的一些特性:
众多功能和标准兼容性
PostgreSQL对SQL标准高度兼容,它实现的功能完全遵守于ANSI-SQL:2008标准。目前完全支持子查询(包括在FROM中的子查询)、授权读取和可序列化的事务隔离级别。同时PostgreSQL也具有完整的关系数据库系统的目录功能,它支持单数据库的多模式功能,每一个目录可通过SQL标准中定义的字典信息模式进行访问。
Data集成性功能包括(复合)主键、含有严格约束或级联更新和删除功能的外键、录入检查约束、唯一性约束和非空约束。具有很多扩展模块和更高级的功能。其中有为方便使用的通过序列实现的自增字段、 允许返回部分记录集的LIMIT/OFFSET选项,也支持复合、唯一、部分和函数式索引,索引并支持B-Tree、R-Tree、Hash或GiST存储方式。
GiST(通用搜索树)
索引是一种高级系统算法,它将不同的排序算法与包含B-Tree、B+-Tree、R-Tree、部分汇总树、可加权的B+-Tree以及其他多种搜索逻辑结合在一起,它也提供了接口允许创建用户数据类型和扩展的查询方法。这样,GiST提供了用户指定存储和定义新方法进行查询的灵活性---它大大超越了标准B-Tree、R-Tree和其他通用搜索逻辑所能提供的功能。
GiST现在也成为很多其他使用PostgreSQL公共项目的基础,如OpenFTS和PostGIS项目。 OpenFTS(开源全文搜索引擎)项目提供在线索引和数据库搜索的相当权重评分。 PostGIS项目给PostgreSQL增加了地理信息管理功能,允许用户将PostgreSQL作为GIS空间地理信息数据库使用,这和专业的ESRI公司的SDE系统以及Oracle的空间地理扩展模块功能相同。
其他高级功能包括表继承、规则和数据库事件响应功能等。表继承功能可以按原来的一个表创建一个有关系的新表,这样允许数据库设计人员可以将一个表作为基表,从基表派生出新表。并且PostgreSQL甚至可以使用此方式实现单级或多级的继承。
规则功能是用来调用查询的重算功能,允许数据库设计人员根据不同的表或视图来创建规则,以实现动态改变数据库原操作为新的操作的功能。
事件响应功能是一个内部通讯功能,它将系统信息或事件在用户使用的LISTEN和NOTIFY两条指令后进行传递,允许简要的点对点通讯或是对指定数据库事件的定点通讯。由于信息可以从触发器或是存储过程中发出,PostgreSQL的用户可以监控类似更新、新增或是删除的数据库事件。
高度可定制性
PostgreSQL的存储过程开发可以使用众多的程序语言,包括Java、Perl、Python、Ruby、Tcl、C/C++和自带的PL/pgSQL,其中的PL/pgSQL与Oracle的PL/SQL很相似,内置了数百个函数,功能从基本的算术计算和字符串处理到加密逻辑计算并与Oracle有高度兼容性。触发器和存储过程可以使用C语言开发并可以作为内部库文件加载至数据库内部,开发上的巨大灵活性扩展了数据库能力。相应地,PostgreSQL也包括一套框架允许开发人员定义和创建他们自己的可在函数中使用数据类型,也可以定义操作符新的处理方式,具有了这样的能力后,PostgreSQL现已具有了各种高级数据类型,包括几何图形、空间地理、网络地址甚至于ISBN/ISSN(国际标准书号/国际标准序列号),这些都可以加入至系统中。
由于有很多的存储过程语言可以使用,这样也产生了很多的库接口,这样允许各种编译型或是解释型的语言在PostgreSQL进行使用,包括Java(JDBC)、ODBC、Perl、Python、Ruby、C、C++、PHP、Lisp、Scheme和Qt等。
最重要的一点,PostgreSQL的源代码可以自由获取,它的授权是在非常自由的开源授权下,这种授权允许用户在各种开源或是闭源项目中使用、修改和发布PostgreSQL的源代码。用户对源代码的可以按用户意愿进行任何修改、改进。因此,PostgreSQL不仅是一个强大的企业级数据库系统,也是一个用户可以开发私用、网络和商业软件产品的数据库开发平台。
优点
开源且遵从SQL标准:PostgreSQL是一款开源的、免费的、功能非常强大的关系型数据库。
强大的社区:由一个忠实的、经验丰富的社区支持,用户可以通过知识库和Q&A网站获得全天候的免费服务。
强有力的第三方支持:除了非常先进的特性之外,PostgreSQL还有很多优秀的、开源的第三方工具可以辅助系统的设计、管理和使用。
可扩展:可以通过存储过程扩展其功能。
面向对象:PostgreSQL不仅是一个关系型数据库,它还是一个面向对象的数据库——支持嵌套等功能。
缺点
性能:对于简单繁重的读取操作,使用PostgreSQL可能有点小题大做,同时性能也比MySQL这样的同类产品要差。
流行程度:尽管有大量的部署,但是鉴于该数据库的性质,它的受欢迎程序并不高。
托管:由于上面提到的几点,提供托管PostgreSQL实例的主机或者服务提供商较少。
何时应该使用PostgreSQL
数据完整性:当绝对需要可靠性和数据完整性的时候,它是更好的选择。
复杂的定制程序:如果需要数据库执行定制程序,那么可扩展的PostgreSQL是更好的选择。
集成:如果将来可能需要将整个数据库迁移到其他合适的解决方案上,那么其可能兼容性最好也更容易切换,且提供了非常开放的使用授权。
复杂的设计:与其他开源且免费的数据库相比,对于复杂的数据库设计PostgreSQL在功能方面最全面,潜力最大,不需要你放弃其他有价值的资产。
何时不应该使用PostgreSQL
速度:如果只需要快速读取操作,它可能并不合适。
简单:除非需要绝对的数据完整性,ACID遵从性或者设计复杂,否则PostgreSQL对于简单的场景而言有点多余。
复制:对于缺少数据库和系统管理经验的人而言使用MySQL实现复制要更简单,除非你愿意花费时间、精力和资源。
PostgreSQL 具有许多功能,旨在帮助开发人员构建应用程序,帮助管理员保护数据完整性和构建容错环境,并帮助您管理数据,无论数据集大小如何。除了免费和开源 之外,PostgreSQL 还具有很高的可扩展性。例如,可以定义自己的数据类型,构建自定义函数,甚至可以从 不同的编程语言编写代码,而无需重新编译数据库!其尝试符合 SQL 标准,只要这种符合性不与传统功能相矛盾或导致糟糕的架构决策。SQL 标准要求的许多功能都得到支持,尽管有时语法或功能略有不同。随着时间的推移,可以预期会进一步朝着符合性迈进。截至 2023 年 9 月的 16 版,PostgreSQL 符合 SQL:2023 核心符合性的 179 个强制功能中的至少 170 个。以下是 PostgreSQL 中发现的各种功能的不详尽列表,在每次主要版本中都会添加更多功能:
数据类型
基本类型:整数、数字、字符串、布尔
结构化:日期/时间、数组、范围/多范围、UUID
文档:JSON/JSONB、XML、键值(Hstore)
几何:点、线、圆、多边形
自定义:复合类型、自定义类型
数据完整性
唯一、非空
主键
外键
排除约束
显式锁、咨询锁
并发性、性能
索引:B 树、多列、表达式、部分
高级索引:GiST、SP-Gist、KNN Gist、GIN、BRIN、覆盖索引、布隆过滤器
复杂的查询规划器/优化器、仅索引扫描、多列统计
事务、嵌套事务(通过保存点)
多版本并发控制 (MVCC)
读取查询和构建 B 树索引的并行化
表分区
SQL 标准中定义的所有事务隔离级别,包括可序列化
表达式的即时 (JIT) 编译
可靠性、灾难恢复
预写式日志 (WAL)
复制:异步、同步、逻辑
时间点恢复 (PITR)、活动备用
表空间
安全性
身份验证:GSSAPI、SSPI、LDAP、SCRAM-SHA-256、证书等
强大的访问控制系统
列级和行级安全性
使用证书和附加方法进行多因素身份验证
可扩展性
存储函数和过程
过程语言:PL/pgSQL、Perl、Python 和 Tcl。通过扩展提供了其他语言,例如 Java、JavaScript (V8)、R、Lua 和 Rust
SQL/JSON 构造函数和路径表达式
外部数据包装器:使用标准 SQL 接口连接到其他数据库或流
表的可自定义存储接口
提供附加功能的许多扩展,包括 PostGIS
国际化、文本搜索
支持国际字符集,例如通过 ICU 校对
不区分大小写和不区分重音的校对
全文搜索
可以在 PostgreSQL 文档 中发现更多功能。此外 PostgreSQL 具有高度可扩展性:许多功能(如索引)都定义了 API,以便您可以使用它来解决您的难题。PostgreSQL 已被证明具有高度可扩展性,无论是在它可以管理的数据量方面,还是在它可以容纳的并发用户数量方面。生产环境中存在管理数 TB 数据的活跃 PostgreSQL 集群,以及管理 PB 级数据的专门系统。
体系结构
服务
在大多数操作系统上,PostgreSQL是作为一种服务(或者叫守护进程)安装的。多个PostgreSQL服务可以运行于同一台物理服务器上,但它们的侦听端口不能重复,也不能共享同一个数据存储目录。server(服务器)和 service(服务)这两个术语大多数情况下可互换使用,因为大多数人在一台物理服务器上只会安装一个服务。
database
每个PostgreSQL服务可以包含多个独立的 database。
schema
ANSI-SQL标准中对schema有着明确的定义,database的下一层逻辑结构就是schema。如果把database比作一个国家,那么schema就是一些独立的州(或者是省、府、辖区等,具体取决于各国的实际情况)。大多数对象是隶属于某个schema的,然后schema又隶属于某个 database。在创建一个新的database时,PostgreSQL会自动为其创建一个名为 public的schema。如果未设置search_path变量(后续会介绍该变量的含义),那么PostgreSQL会将你创建的所有对象默认放入 public schema中。如果表的数量较少,这是没问题的,但如果你有几千张表,那么我们还是建议你将它们分门别类放入不同的schema中。
catalog
catalog是系统级的schema,用于存储系统函数和系统元数据。每个databas创建好以后默认都会含有两个catalog:一个名为pg_catalog,用于存储PostgreSQL系统自带的函数、表、系统视图、数据类型转换器以及数据类型定义等元数据;另-一-个是infornation_schena,用于存储ANSI标准中所要求提供的元数据查询视图,这些视图遵从ANSI SQL标准的要求,以指定的格式向外界提供 PostgreSQL元数据信息。
一直以来,PostgreSOL数据库的发展都严格地遵循着其“自由与开放”的核心理念。如果你足够了解这款数据库,会发现它几乎是一种可以“自我生长”的数据库。比如,它所有的核心设置都保存在系统表中,用户可以不受限地查看和修改这些数据,这为PostgreSQL提供了远超任何一种商业数据库的巨大灵活性(不过从另一个角度看,将这种灵活性称为“可破坏性”也未尝不可)。只要仔细地研究一下pg_catalog就可以了解到PostgreSQL这样一个庞大的系统是如何基于各种部件构建起来的。如果有超级用户权限,那么可以直接修改pg_catalog的内容。
Infornation_schema catalog 在 MySQL 和 SQL Server 中也有。PostgreSQL Infornation_schena中最常用的视图一般有以下几个:columns视图列出了数据库中的所有表列;tables视图列出了数据库中的所有表(包括视图);views视图列出了所有视图以及用于构建或重新构建该视图的关联SQL。同样在 MySQL和SQL Server中也有这些视图,不过它们所含的列没有PostgreSOL那么多。PostgreSQL 另外添加了几个用于描述自定义数据类型列的列,比如colunns.udt_name。
尽管colurns、tables、views这三个元数据视图本身也是标准的PostgreSQL视图,但由于其身份的特殊性,pgAdmin界面中还是把它们放在了information_schema -→ CatalogObjects分支下。
变量
变量是PostgreSQL统一配置机制(GUC)的一部分,是可以在多个级别进行设置的各种选项,这些级别包括服务级、database级以及其他级别。很多人容易在search_path这个选项上犯错,该选项的工作机制是:如果在search_path中指定了schema的名称,那么该schema资产在使用时就无需显式指定其schema名,系统会按照search_path中登记的schema名按顺序逐个搜索。
扩展包
PostgreSQL 9.1版中引入了对于扩展包机制的支持。开发人员可以通过该机制将一组相关的函数、数据类型、数据类型转换器、用户自定义索引、表以及GUC等对象打包成一个功能扩展包,该扩展包可以整体安装或者整体删除。扩展包在概念上与Oracle的package类似,一般推荐使用该机制来为数据库提供功能扩展。关于扩展包的具体安装步骤,请参考开发手册。一般来说需要先将扩展包的二进制安装包和脚本复制到服务器,然后再为需要该扩展包功能的 database单独安装。
假设需要用到某个扩展包的功能,那么仅需将其安装到对应的database中即可,而不必为当前数据库系统中的每个database都安装一遍。比如需要对某个database中的数据进行高级文本搜索,那么单独为该database安装fuzzystrratch扩展包即可。安装扩展包时可以指定装到哪个schema,若不指定则默认会装到 public schema中。我们不建议这么做,因为这会导致public schema变得庞大复杂且难以管理,尤其是如果你将自己的数据库对象也都存入 public schema中,那么情况会变得更糟糕。建议你创建一个独立的schema用于存放所有扩展包的对象,甚至为规模较大的扩展包单独创建一个schema。为避免出现找不到新增扩展包对象的问题,请将这些新增的schema名称加入search_path变量中,这样就可以直接使用扩展包的功能而无需关注它到底装到了哪个schema中。也有一些扩展包明确要求必须安装到某个schema下,这种情况下你就不能自行指定了。例如有很多语言扩展包,比如plv8,就要求必须安装到pg_catalog中。
表
任何一个数据库中,表都是最核心和最“忙碌”的对象类型。在PostgreSQL中表首先属于某个schema,而schema又属于某个database,这样就构成了一种三级存储结构。PostgreSQL的表支持两种很强大的功能。第一种是表继承,即一张表可以有父表和子表。这种层次化的结构可以极大地简化数据库设计,还可以为你省掉大量的重复查询代码。
第二种是创建一张表的同时,系统会自动为此表创建一种对应的自定义数据类型。换句话说,可以将某个完整的数据结构定义为一个表,然后将该表用作另一个表中的一个列。
外部表和外部数据封装器
外部表的首次亮相是在9.1版中。它们是一些虚拟表,通过它们可以直接在本地数据库中访问来自外部数据源的数据。只要数据映射关系配置正确,那么外部表的用法就与普通表没有任何区别。外部表支持映射到以下类型的数据源:CSV文件、另一个服务器上的 PostgreSQL表、SQL Server 或Oracle这些异构数据库中的表、Redis这样的 NoSOL数据库或者甚至像Twitter或Salesforce这样的Web服务。外部表映射关系的建立是通过配置外部数据封装器(Foreign Data Wrapper,FDW)实现的。FDW是PostgreSQL和外部数据源之间的一架“魔法桥”,可实现两边数据的互联互通。其内部实现机制遵循SQL标准中的MED(Management of External Data)规范,更多细节请参考维基百科上关于MED的描述(http://en.wikipedia.org/wiki/SQL/MED)。
许多编程人员已经为当下绝大部分流行的数据源开发了FDW并已免费共享出来。你也可以通过创建自己的FDW来练习。(建议你一旦成功了也公布出来,这样整个社区都可以分享你的劳动成果。)FDW是通过扩展包机制实现的,装好以后在pgAdmin界面上名为Foreign Data Wrapper的目录节点下能看到它。
表空间
表空间是用于存储数据的物理空间。PostgreSQL将用于物理存储的表空间和用于逻辑存储的schema分开管理,二者之间并无耦合关系。这样就很容易在不影响业务应用逻辑的情况下,将database甚至是单张表和索引在不同的物理驱动器之间进行移动。
视图
大多数关系型数据库都支持视图,通过视图可以大大简化复杂的查询逻辑,另外也可以通过对视图执行更新操作来修改其基表数据。PostgreSQL也不例外,从9.3版开始支持对基于单表的视图直接使用SOL进行更新操作,这样就不需要再写额外的规则或者触发器来实现对此类简单视图的更新。但对于包含更复杂逻辑的视图,或者是基于多张表的视图,对其进行数据更新操作时仍需编写规则或者触发器。9.3版还引入了对物化视图的支持,该机制通过对视图数据进行缓存来实现对常用查询的加速。
函数
PostgreSQL中函数执行后的返回结果可以是一个标量值或几个记录集。可以在函数中对表数据进行修改,其他数据库对于这种会修改表记录的函数一般称为存储过程。
内置编程语言
函数是以过程化语言(Procedural Language,PL)编写的。PostgreSQL默认支持三种内置编程语言:SQL、PL/pgSQL 以及C语言。可以通过CREATE EXTENSION或者CREATE PRODCEDURAL LANGUAGE 命令来安装其他语言包。目前较常用的语言有 Python、JavaScript、Perl以及R。
运算符
运算符本质上是符号化的已命名函数(例如=、&等),它需要一个或者两个实参(argument),底层有一个相应的函数来实现其运算逻辑。PostgreSQL支持自定义运算符。如果定义了自己的数据类型,那么可定义一些运算符来与之配合工作。比如可以为自定义数据类型定义=运算符;甚至可以为两个完全不同的数据类型定义一个运算符,来对其进行比较运算。
数据类型(或者仅仅类型)
每种数据库产品都会支持一系列的数据类型,比如整型、字符型、数组,等等。除前述常见类型外,PostgreSQL还支持复合数据类型,这种类型可以是多种数据类型的一个组合,比如虚数、极坐标、张量都是复合数据类型。如果你定义了自己的复合数据类型,那么可以创建一组函数和运算符来配合它工作,可以做得很专业,很复杂、很“高端”,比如自定义实现div(散度运算)、grad(梯度运算)和curls(旋度运算)等。
数据类型转换器
cast是数据类型转换器,就是将一种数据类型转换为另一种类型的工具。转换器在其底层其实是通过调用转换函数来实现真正的转换逻辑的。PostgreSQL的独到之处在于支持用户自定义转换器,这样就可以改变系统默认的转换行为。例如需要把邮政编码(美国的邮政编码是一个5位的整数)从integer转换为character,那么可以自定义一个支持“数字不足5位则前面自动补0”规则的转换器。转换器可以被隐式调用也可以被显式调用。隐式转换是系统自动执行的,一般来说,将一种特定数据类型转为更通用的数据类型(比如数字转换为字符串)时就会发生隐式类型转换。如果进行隐式转换时系统找不到合适的转换器,就必须显式执行转换动作。
序列
序列控制serial数据类型的自动递增。在PostgreSQL中定义serial列时会自动创建序列,但很容易更改初始值、增量和下一个值。因为序列是独立对象,所以多个表可以使用同一个序列对象。这样可以创建跨越多个表的独特键值。SQL Server和Oracle也都有序列对象,但必须手动创建。
行或记录
“行”和“记录”这两个术语可在多数情况下互换使用。在PostgreSQL中,“记录”这个概念可以脱离表而独立存在。当在函数或者在SQL语句中使用记录构造函数语法(语法类似于:SELECT ROW(1,2.5, 'this is a test'))时会对这一点有深刻体会。
触发器
绝大多数企业级数据库都支持触发器机制,该机制可以实现对数据修改事件的捕获,并在之后触发用户自定义的操作行为。触发器的触发时机是可设置的,可以是语句级触发或者记录级触发,可以是修改前触发也可以是修改后触发。
PostgreSQL的触发器技术正在快速的演进之中。9.0版引入了对 WITH子句的支持,通过它可以实现带条件的记录级触发,即只有当某条记录符合指定的WHEN条件时,触发器才会被调用。9.0版还引人了UPDATE OF子句,通过它可以指定要监控哪些列的更改。当列更改时,就会触发触发器;在9.1版中,视图中的数据更改可以触发触发器。在9.3版中,数据定义语言(DDL)事件可以触发触发器。目前支持触发器的DDL命令列表请参见官方手册中“触发器触发时机一览表”。在9.4版中,针对外部表的触发器也获得了支持。请参考官方文档中“创建触发器”这一节的内容以获取更多信息。
规则
规则是一种能够将一种动作替换为另一种动作的机制。PostgreSQL 内部就是使用此机制来实现视图的,比如定义了这样一个视图:
CREATE VIEW vw_pupils AS SELECT * FROM pupils wHERE active;
实际上PG在后台自动创建了一个 INSTEAD OF SELECT类型的规则,其内容是:当查询名为vw_pupils的表时,自动重定向为查询pupils表中 active字段值为true的记录。
规则还可以用于替代一些特定的简单触发器。通常情况下在对记录行进行更新/插入/删除操作时会调用触发器。规则却不一样,它的运作机理是修改用户原本的行为逻辑(也就是你执行的SQL语句本身),或者是在用户原有逻辑的基础上额外附加一些SOL逻辑。相比触发器而言,这种整体取而代之的方式避免了针对每条记录都调用-次触发器所造成的负担。一般来说,如果希望在数据修改时加载自定义逻辑,还是推荐使用触发器而不是规则。很多PostgreSQL用户认为规则是过时的技术,因为出问题时很难诊断,而且规则只支持用SQL语法来编写,PostgreSQL所支持的其他编程语言则无用武之地。
核心组件与数据流转逻辑
工作流是:应用连数据库→后台进程处理请求→共享内存缓存加速→辅助进程保障稳定→数据最终落盘为物理文件。
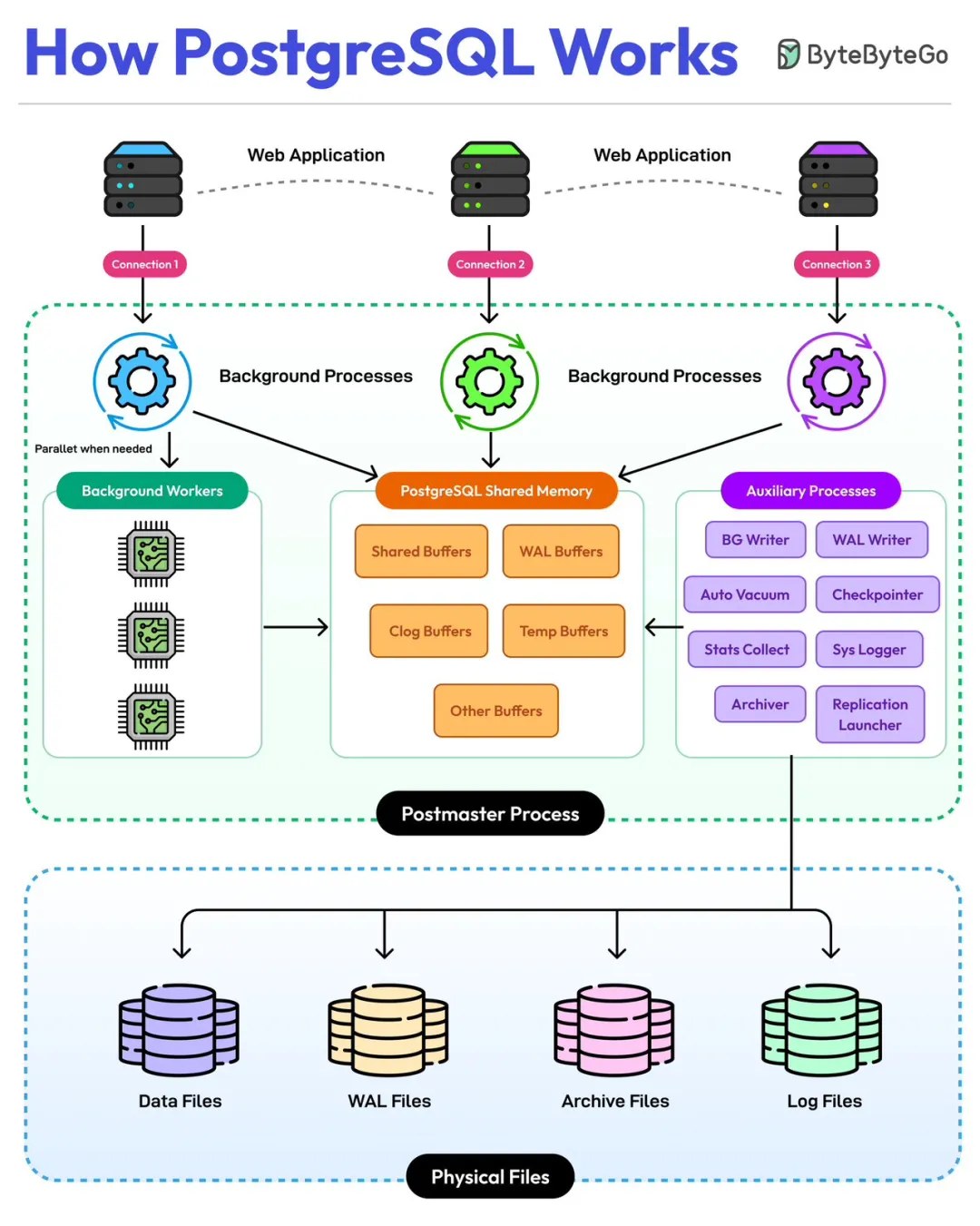
图源ByteByteGo。
1、客户端连接:Web 应用的入口
多个应用(图中 Web Application)通过 Connection 1/2/3 与 PostgreSQL 建立连接,发送查询、写入等请求。每个连接对应数据库的一个“会话”,处理应用的交互。
2、后台进程:数据库的“工作者”
PostgreSQL 靠后台进程驱动核心逻辑,分为三类关键角色:
• Background Workers:按需并行工作的“工人”,处理计算密集型任务(如并行查询、备份),提升多核 CPU 利用率。
• PostgreSQL Shared Memory:共享内存区,是性能核心。里面包含多种“缓冲区”:
• Shared Buffers:缓存数据页,减少磁盘 IO(常用数据存在这里,读数据时先查缓存,不直接读磁盘)。
• WAL Buffers:预写日志(Write-Ahead Log)的缓存,保障数据持久化(写数据时,先写日志再落盘,防止断电丢数据)。
• 还有 Clog Buffers(事务状态缓存)、Temp Buffers(临时数据缓存)等,各司其职。
• Auxiliary Processes:辅助进程,负责数据库的“运维类”工作:
• BG Writer:后台写进程,把 Shared Buffers 里的脏数据(修改后的数据)异步刷到磁盘,不阻塞前台查询。
• WAL Writer:把 WAL Buffers 里的日志刷到磁盘,保障日志持久化。
• Auto Vacuum:自动清理过期数据(PostgreSQL 中,删除/更新数据是“标记删除”,Auto Vacuum 会真正回收空间,防止表膨胀)。
• 还有 Checkpointer(检查点,定期刷脏数据与日志)、Stats Collector(统计信息收集,为查询优化提供依据)等,保障数据库稳定运行。
3、主进程:数据库的“大管家”
Postmaster Process 是 PostgreSQL 的主进程,负责:
• 管理后台进程的启动、停止。
• 监听客户端连接请求,分配连接资源。
• 协调各进程工作,是数据库的“总指挥”。
4、物理文件:数据的“最终归宿”
所有数据最终落盘为物理文件,分为四类:
• Data Files:存储表、索引的实际数据(Shared Buffers 缓存的就是这些文件的数据页)。
• WAL Files:预写日志文件,记录数据修改历史,用于故障恢复。
• Archive Files:WAL 日志的归档文件,用于备份、时间点恢复(比如要恢复到昨天 10 点的状态,靠归档日志)。
• Log Files:数据库运行日志,记录错误、警告、操作记录,用于问题排查。
数据库驱动程序
任何情况下都不可能脱离具体的业务系统而仅仅使用PostgreSQL数据库本身,那显然是无意义的。为了实现PostgreSQL与业务系统之间的交互,就需要借助数据库驱动程序。PG拥有大量免费驱动,支持各种编程语言和开发工具。此外很多商业公司也以很低廉的价格提供了各有特色的驱动。目前比较流行的几种开源驱动如下:
PHP驱动:PHP语言广泛应用于Web开发领域,大多数PHP发行包都自带了较老的pgsql驱动或者是较新的pdo_pgsql驱动。一般来说这两种驱动默认都会安装,不过可能需要修改php.ini来决定启用哪一种。
JDBC 驱动:JAVA 开发所使用的JDBC驱动一直是与最新版PostgreSQL同步更新的,可以从 PG方站点下载。
.NET驱动:.NET框架(含微软的官方版和Mono社区的开源版)可使用Npgsql驱动。目前该驱动支持微软.NET框架V3.5及之后的版本,包括微软Entity Framework开发框架以及 Mono开源.NET框架。
ODBC驱动:如果需要从微软Access、Office系列工具或者其他支持ODBC的产品连接到PostgreSQL,可从PG官网下载ODBC驱动,支持32位和64位两个版本。
LibreOffice/OpenOffice驱动:LibreOffice 3.5及之后的版本中自带了PostgreSQL 驱动,但3.5之前的版本以及OpenOffice是不带的,可以使用JDBC或者SDBC驱动。
Python驱动:Python可通过多种驱动访问 PostgreSQL,目前 psycopg 是最流行的一种。Python的Django开发框架对其也有着良好的支持。
Ruby驱动:对Ruby开发人员来说,请使用rubygems pg驱动。
Perl驱动:Perl可以使用DBI架构和DBD::Pg驱动,也可以使用由CPAN网站提供的DBD::PgPP驱动。
.Node.js驱动:Node.js是一个基于Google V8 JavaScript 引擎的运行平台,可用于构建高可扩展性的网络应用。该平台目前支持三种PostgreSQL驱动:Node Postgres、Node Postgres Pure(与前者的区别在于不需要编译),以及 Node-DBI。
更多的相关周边可见此图:
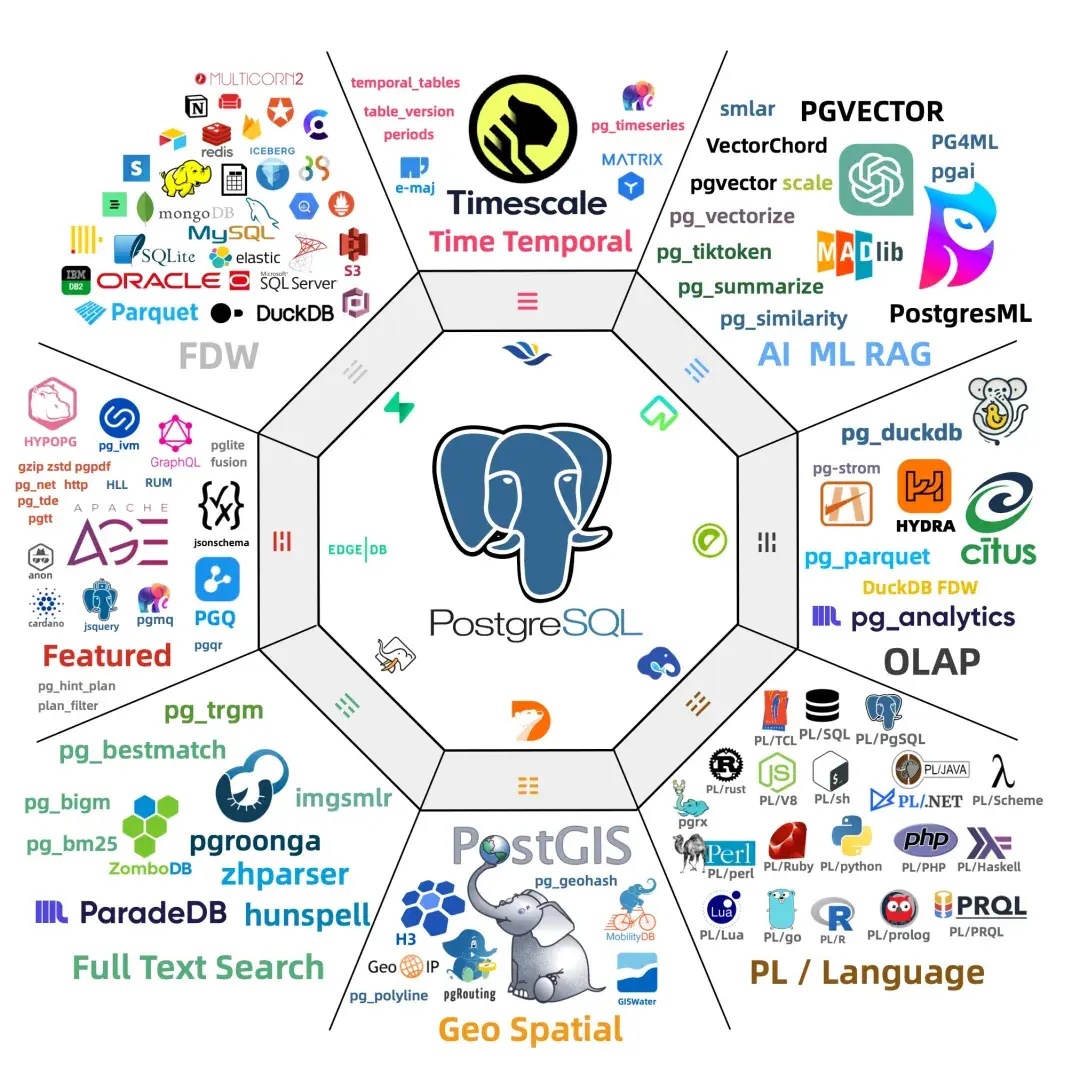
PostgreSQL的主要衍生版本
PostgreSQL 使用了MIT/BSD 风格的许可证,任何人都可以合法地对其修改并二次传播,因此对于那些想创建自己数据库分支的人来说,PostgreSQL 是绝佳的选择。在过去的很多年间,有很多团队创建了自己的PostgreSQL 衍生版本,其中的部分修改也已经回馈到PostgreSQL 的 主干代码中。
目前数据仓库领域使用很广泛的Netezza就是源自PostgreSQL。亚马逊公司的Redshift数据仓库事实上是PostgreSQL 的一个分支的分支。支持PB 级数据分析的著名数据仓库GreenPlum 最初的源头是Bizgres,而Bizgres 是一款基于PostgreSQL 的面向大数据的数据仓库和智能分析软件。EnterpriseDB公司推出的PostgreSQL Advanced Plus 也是以PostgreSQL 为基础,另外增加了对于Oracle 语法和特性的兼容支持,以吸引原Oracle 用户。EnterpriseDB公司向PostgreSQL 社区提供了资金和开发力量的支持,对此我们表示感谢。他们的Postgres Plus Advanced Server 产品在版本更新节奏上也一直是密切跟进最新的PostgreSQL稳定版的。
盖老师在《数据库简史》一书出版时曾绘制了一幅Ingres路线图:
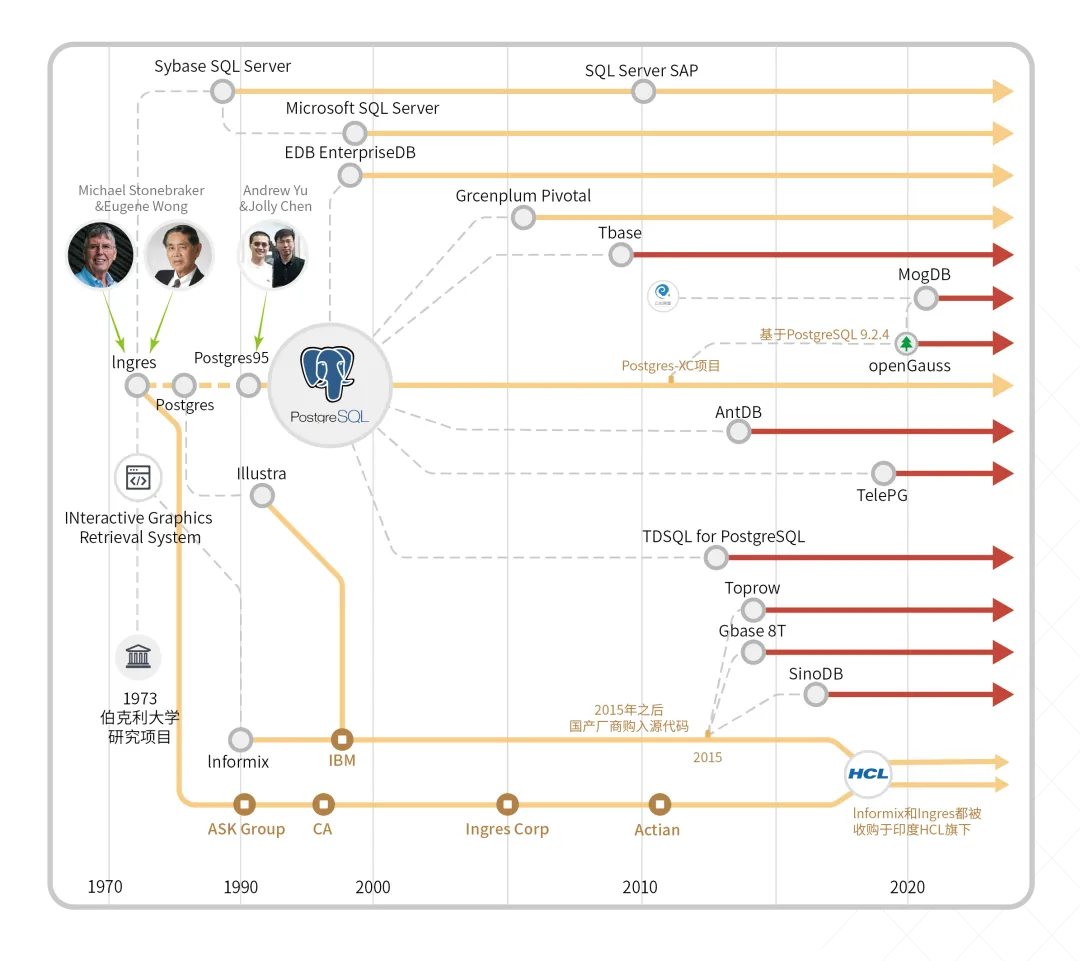
前述衍生产品都是商业化的闭源软件。tPostgres、Postgres-XC和BigSQL是三款还处于发展初期但已经崭露头角的开源衍生产品,它们都得到了OpenSCG公司的资金支持。tPostgreSQL 的最新版本基于PostgreSQL 9.3,其目标是取代MicrosoftSQL Server。tPostgreSQL 中内嵌了pgtsql 语言扩展包,可以用T-SQL 语法来编写函数。pgtsql 语言包是标准的PostgreSQL 扩展包,因此它其实可以安装到任何一台PostgreSQL9.3 数据库上。Postgres-XC 是一套集群服务器系统,它能够提供可扩展的写能力并支持同步多主复制,其分布式处理和多主复制能力使它在所有类似系统中脱颖而出。目前Postgres-XC 还只是1.0 版本。最后介绍一下BigSQL, 它实现了PostgreSQL 和Hadoopwith Hive 这两款重量级产品的融合。BigSQL 自带了hadoop_fdw这款扩展包,可以查询和更新外部Hadoop数据源的数据。
此外,最近还发布了一款PostgreSQL 开源分支产品Postgres-XL(XL 代表eXtensibleLattice, 即可扩展的晶格),该产品面向大规模并行处理(MPP)领域,支持节点间数据的分片存储能力;与此类似的还有基于PostgreSQL的大规模并行处理数据库-Greenplum DB。更多信息可参考《基于PostgreSQL集群数据库系统概览》。
2021年8月,Postgres.app发布,这是用于在 Mac 上安装 PostgreSQL 的工具,其自我介绍是“在 Mac 上开始使用 PostgreSQL 的最简单方法”。其提供了使用 PostgreSQL 所需的一切条件,并附带了美观的 GUI 用于启动/停止服务器,支持同时运行多个版本 PostgreSQL。Postgres.app 将 PostgreSQL 封装成标准的 Mac App,包括常见的插件,如:PostgreSQL、PostGIS、plv8、wal2json、pldebugger等;另外提供了小版本的自动升级功能(PostgreSQL 跨主版本号不兼容,不能自动升级)。
更多信息参考:
PostgreSQL使用记录
PostgreSQL最常见问题
PostgreSQL周边大事记
PostgreSQL功能发布计划
PostgreSQL 1x Beta 版本特性
PostgreSQL版本更新记录(202x)
最新版本:8
最新版本:9
最新版本:10
最新版本:11
最新版本:12
最新版本:13
最新版本:14
最新版本:15
最新版本:16
官方主页:http://www.postgresql.org/