cpu参数知多少
 1.主频
1.主频主频也叫时钟频率,单位是MHz,用来表示CPU的运算速度。CPU的主频=外频×倍频系数。很多人认为主频就决定着CPU的运行速度,这不仅是个片面的,而且对于服务器来讲,这个认识也出现了偏差。至今,没有一条确定的公式能够实现主频和实际的运算速度两者之间的数值关系,即使是两大处理器厂家Intel和 AMD,在这点上也存在着很大的争议,我们从Intel的产品的发展趋势,可以看出Intel很注重加强自身主频的发展。像其他的处理器厂家,有人曾经拿过一快1G的全美达来做比较,它的运行效率相当于2G的Intel处理器。
所以,CPU的主频与CPU实际的运算能力是没有直接关系的,主频表示在CPU内数字脉冲信号震荡的速度。在Intel的处理器产品中,我们也可以看到这样的例子:1 GHz Itanium芯片能够表现得差不多跟2.66 GHz Xeon/Opteron一样快,或是1.5 GHz Itanium 2大约跟4 GHz Xeon/Opteron一样快。CPU的运算速度还要看CPU的流水线的各方面的性能指标。
当然,主频和实际的运算速度是有关的,只能说主频仅仅是CPU性能表现的一个方面,而不代表CPU的整体性能。
2.外频
外频是CPU的基准频率,单位也是MHz。CPU的外频决定着整块主板的运行速度。说白了,在台式机中,我们所说的超频,都是超CPU的外频(当然一般情况下,CPU的倍频都是被锁住的)相信这点是很好理解的。但对于服务器CPU来讲,超频是绝对不允许的。前面说到CPU决定着主板的运行速度,两者是同步运行的,如果把服务器CPU超频了,改变了外频,会产生异步运行,(台式机很多主板都支持异步运行)这样会造成整个服务器系统的不稳定。
目前的绝大部分电脑系统中外频也是内存与主板之间的同步运行的速度,在这种方式下,可以理解为CPU的外频直接与内存相连通,实现两者间的同步运行状态。外频与前端总线(FSB)频率很容易被混为一谈,下面的前端总线介绍我们谈谈两者的区别。
3.前端总线(FSB)频率
前端总线(FSB)频率(即总线频率)是直接影响CPU与内存直接数据交换速度。有一条公式可以计算,即数据带宽=(总线频率×数据带宽)/8,数据传输最大带宽取决于所有同时传输的数据的宽度和传输频率。比方,现在的支持64位的至强Nocona,前端总线是800MHz,按照公式,它的数据传输最大带宽是6.4GB/秒。
外频与前端总线(FSB)频率的区别:前端总线的速度指的是数据传输的速度,外频是CPU与主板之间同步运行的速度。也就是说,100MHz外频特指数字脉冲信号在每秒钟震荡一千万次;而100MHz前端总线指的是每秒钟CPU可接受的数据传输量是100MHz×64bit÷8Byte/bit=800MB/s。
其实现在 “HyperTransport”构架的出现,让这种实际意义上的前端总线(FSB)频率发生了变化。之前我们知道IA-32架构必须有三大重要的构件:内存控制器Hub (MCH) ,I/O控制器Hub和PCI Hub,像Intel很典型的芯片组 Intel 7501、Intel7505芯片组,为双至强处理器量身定做的,它们所包含的MCH为CPU提供了频率为533MHz的前端总线,配合DDR内存,前端总线带宽可达到4.3GB/秒。但随着处理器性能不断提高同时给系统架构带来了很多问题。而“HyperTransport”构架不但解决了问题,而且更有效地提高了总线带宽,比方AMD Opteron处理器,灵活的HyperTransport I/O总线体系结构让它整合了内存控制器,使处理器不通过系统总线传给芯片组而直接和内存交换数据。这样的话,前端总线(FSB)频率在AMD Opteron处理器就不知道从何谈起了。
4.CPU的位和字长
位:在数字电路和电脑技术中采用二进制,代码只有“0”和“1”,其中无论是 “0”或是“1”在CPU中都是 一“位”。
字长:电脑技术中对CPU在单位时间内(同一时间)能一次处理的二进制数的位数叫字长。所以能处理字长为8位数据的CPU通常就叫8位的CPU。同理 32位的CPU就能在单位时间内处理字长为32位的二进制数据。字节和字长的区别:由于常用的英文字符用8位二进制就可以表示,所以通常就将8位称为一个字节。字长的长度是不固定的,对于不同的CPU、字长的长度也不一样。8位的CPU一次只能处理一个字节,而32位的CPU一次就能处理4个字节,同理字长为64位的CPU一次可以处理8个字节。
5.倍频系数
倍频系数是指CPU主频与外频之间的相对比例关系。在相同的外频下,倍频越高CPU的频率也越高。但实际上,在相同外频的前提下,高倍频的CPU本身意义并不大。这是因为CPU与系统之间数据传输速度是有限的,一味追求高倍频而得到高主频的CPU就会出现明显的“瓶颈”效应—CPU从系统中得到数据的极限速度不能够满足CPU运算的速度。一般除了工程样版的Intel的CPU都是锁了倍频的,而AMD之前都没有锁。
6.缓存
缓存大小也是CPU的重要指标之一,而且缓存的结构和大小对CPU速度的影响非常大,CPU内缓存的运行频率极高,一般是和处理器同频运作,工作效率远远大于系统内存和硬盘。实际工作时,CPU往往需要重复读取同样的数据块,而缓存容量的增大,可以大幅度提升CPU内部读取数据的命中率,而不用再到内存或者硬盘上寻找,以此提高系统性能。但是由于CPU芯片面积和成本的因素来考虑,缓存都很小。
L1 Cache(一级缓存)是CPU 第一层高速缓存,分为数据缓存和指令缓存。内置的L1高速缓存的容量和结构对CPU的性能影响较大,不过高速缓冲存储器均由静态RAM组成,结构较复杂,在CPU管芯面积不能太大的情况下,L1级高速缓存的容量不可能做得太大。一般服务器CPU的L1缓存的容量通常在32—256KB。
L2 Cache(二级缓存)是CPU的第二层高速缓存,分内部和外部两种芯片。内部的芯片二级缓存运行速度与主频相同,而外部的二级缓存则只有主频的一半。L2高速缓存容量也会影响CPU的性能,原则是越大越好,现在家庭用CPU容量最大的是512KB,而服务器和工作站上用CPU的L2高速缓存更高达256-1MB,有的高达2MB或者3MB。
L3 Cache(三级缓存),分为两种,早期的是外置,现在的都是内置的。而它的实际作用即是,L3缓存的应用可以进一步降低内存延迟,同时提升大数据量计算时处理器的性能。降低内存延迟和提升大数据量计算能力对游戏都很有帮助。而在服务器领域增加L3缓存在性能方面仍然有显著的提升。比方具有较大L3缓存的配置利用物理内存会更有效,故它比较慢的磁盘I/O 子系统可以处理更多的数据请求。具有较大L3缓存的处理器提供更有效的文件系统缓存行为及较短消息和处理器队列长度。
其实最早的L3缓存被应用在AMD发布的K6-III处理器上,当时的L3缓存受限于制造工艺,并没有被集成进芯片内部,而是集成在主板上。在只能够和系统总线频率同步的L3缓存同主内存其实差不了多少。后来使用L3缓存的是英特尔为服务器市场所推出的Itanium处理器。接着就是P4EE和至强 MP。Intel还打算推出一款9MB L3缓存的Itanium2处理器,和以后24MB L3缓存的双核心Itanium2处理器。
但基本上L3缓存对处理器的性能提高显得不是很重要,比方配备1MB L3缓存的Xeon MP处理器却仍然不是Opteron的对手,由此可见前端总线的增加,要比缓存增加带来更有效的性能提升。
7.CPU扩展指令集
CPU依靠指令来计算和控制系统,每款CPU在设计时就规定了一系列与其硬件电路相配合的指令系统。指令的强弱也是CPU的重要指标,指令集是提高微处理器效率的最有效工具之一。从现阶段的主流体系结构讲,指令集可分为复杂指令集和精简指令集两部分,而从具体运用看,如Intel的MMX(Multi Media Extended)、SSE、 SSE2(Streaming-Single instruction multiple data-Extensions 2)、SEE3和AMD的3DNow!等都是CPU的扩展指令集,分别增强了CPU的多媒体、图形图象和Internet等的处理能力。我们通常会把 CPU的扩展指令集称为"CPU的指令集"。SSE3指令集也是目前规模最小的指令集,此前MMX包含有57条命令,SSE包含有50条命令,SSE2包含有144条命令,SSE3包含有13条命令。目前SSE3也是最先进的指令集,英特尔Prescott处理器已经支持SSE3指令集,AMD会在未来双核心处理器当中加入对SSE3指令集的支持,全美达的处理器也将支持这一指令集。
8.CPU内核和I/O工作电压
从586CPU开始,CPU的工作电压分为内核电压和I/O电压两种,通常CPU的核心电压小于等于I/O电压。其中内核电压的大小是根据CPU的生产工艺而定,一般制作工艺越小,内核工作电压越低;I/O电压一般都在1.6~5V。低电压能解决耗电过大和发热过高的问题。
9.制造工艺
制造工艺的微米是指IC内电路与电路之间的距离。制造工艺的趋势是向密集度愈高的方向发展。密度愈高的IC电路设计,意味着在同样大小面积的IC中,可以拥有密度更高、功能更复杂的电路设计。现在主要的180nm、130nm、90nm。最近官方已经表示有65nm的制造工艺了。
10.指令集
(1)CISC指令集
CISC指令集,也称为复杂指令集,英文名是CISC,(Complex Instruction Set Computer的缩写)。在CISC微处理器中,程序的各条指令是按顺序串行执行的,每条指令中的各个操作也是按顺序串行执行的。顺序执行的优点是控制简单,但计算机各部分的利用率不高,执行速度慢。其实它是英特尔生产的x86系列(也就是IA-32架构)CPU及其兼容CPU,如AMD、VIA的。即使是现在新起的X86-64(也被成AMD64)都是属于CISC的范畴。
要知道什么是指令集还要从当今的X86架构的CPU说起。X86指令集是Intel为其第一块16位CPU(i8086)专门开发的,IBM1981年推出的世界第一台PC机中的 CPU—i8088(i8086简化版)使用的也是X86指令,同时电脑中为提高浮点数据处理能力而增加了X87芯片,以后就将X86指令集和X87指令集统称为X86指令集。
虽然随着CPU技术的不断发展,Intel陆续研制出更新型的i80386、i80486直到过去的 PII至强、PIII至强、Pentium 3,最后到今天的Pentium 4系列、至强(不包括至强Nocona),但为了保证电脑能继续运行以往开发的各类应用程序以保护和继承丰富的软件资源,所以Intel公司所生产的所有 CPU仍然继续使用X86指令集,所以它的CPU仍属于X86系列。由于Intel X86系列及其兼容CPU(如AMD Athlon MP、)都使用X86指令集,所以就形成了今天庞大的X86系列及兼容CPU阵容。x86CPU目前主要有intel的服务器CPU和AMD的服务器 CPU两类。
(2)RISC指令集
RISC是英文“Reduced Instruction Set Computing ” 的缩写,中文意思是“精简指令集”。它是在CISC指令系统基础上发展起来的,有人对CISC机进行测试表明,各种指令的使用频度相当悬殊,最常使用的是一些比较简单的指令,它们仅占指令总数的20%,但在程序中出现的频度却占80%。复杂的指令系统必然增加微处理器的复杂性,使处理器的研制时间长,成本高。并且复杂指令需要复杂的操作,必然会降低计算机的速度。基于上述原因,20世纪80年代RISC型CPU诞生了,相对于CISC型CPU ,RISC型CPU不仅精简了指令系统,还采用了一种叫做“超标量和超流水线结构”,大大增加了并行处理能力。RISC指令集是高性能CPU的发展方向。它与传统的CISC(复杂指令集)相对。相比而言,RISC的指令格式统一,种类比较少,寻址方式也比复杂指令集少。当然处理速度就提高很多了。目前在中高档服务器中普遍采用这一指令系统的CPU,特别是高档服务器全都采用RISC指令系统的CPU。RISC指令系统更加适合高档服务器的操作系统 UNIX,现在Linux也属于类似UNIX的操作系统。RISC型CPU与Intel和AMD的CPU在软件和硬件上都不兼容。
目前,在中高档服务器中采用RISC指令的CPU主要有以下几类:PowerPC处理器、SPARC处理器、PA-RISC处理器、MIPS处理器、Alpha处理器。
(3)IA-64
EPIC(Explicitly Parallel Instruction Computers,精确并行指令计算机)是否是RISC和CISC体系的继承者的争论已经有很多,单以EPIC体系来说,它更像Intel的处理器迈向 RISC体系的重要步骤。从理论上说,EPIC体系设计的CPU,在相同的主机配置下,处理Windows的应用软件比基于Unix下的应用软件要好得多。
Intel采用EPIC技术的服务器CPU是安腾Itanium(开发代号即Merced)。它是 64位处理器,也是IA-64系列中的第一款。微软也已开发了代号为Win64的操作系统,在软件上加以支持。在Intel采用了X86指令集之后,它又转而寻求更先进的64-bit微处理器,Intel这样做的原因是,它们想摆脱容量巨大的x86架构,从而引入精力充沛而又功能强大的指令集,于是采用 EPIC指令集的IA-64架构便诞生了。IA-64 在很多方面来说,都比x86有了长足的进步。突破了传统IA32架构的许多限制,在数据的处理能力,系统的稳定性、安全性、可用性、可观理性等方面获得了突破性的提高。
IA-64微处理器最大的缺陷是它们缺乏与x86的兼容,而Intel为了IA-64处理器能够更好地运行两个朝代的软件,它在IA-64处理器上(Itanium、Itanium2 ……)引入了x86-to-IA-64的解码器,这样就能够把x86指令翻译为IA-64指令。这个解码器并不是最有效率的解码器,也不是运行x86代码的最好途径(最好的途径是直接在x86处理器上运行x86代码),因此Itanium 和Itanium2在运行x86应用程序时候的性能非常糟糕。这也成为X86-64产生的根本原因。
(4)X86-64 (AMD64/EM64T)
AMD公司设计,可以在同一时间内处理64位的整数运算,并兼容于X86-32架构。其中支持64位逻辑定址,同时提供转换为32位定址选项;但数据操作指令默认为32位和8位,提供转换成64位和16位的选项;支持常规用途寄存器,如果是32位运算操作,就要将结果扩展成完整的64位。这样,指令中有 “直接执行”和“转换执行”的区别,其指令字段是8位或32位,可以避免字段过长。
x86-64(也叫 AMD64)的产生也并非空穴来风,x86处理器的32bit寻址空间限制在4GB内存,而IA-64的处理器又不能兼容x86。AMD充分考虑顾客的需求,加强x86指令集的功能,使这套指令集可同时支持64位的运算模式,因此AMD把它们的结构称之为x86-64。在技术上AMD在x86-64架构中为了进行64位运算,AMD为其引入了新增了R8-R15通用寄存器作为原有X86处理器寄存器的扩充,但在而在32位环境下并不完全使用到这些寄存器。原来的寄存器诸如EAX、EBX也由32位扩张至64位。在SSE单元中新加入了8个新寄存器以提供对SSE2的支持。寄存器数量的增加将带来性能的提升。与此同时,为了同时支持32和64位代码及寄存器,x86-64架构允许处理器工作在以下两种模式:Long Mode(长模式)和Legacy Mode(遗传模式),Long模式又分为两种子模式(64bit模式和Compatibility mode兼容模式)。该标准已经被引进在AMD服务器处理器中的Opteron处理器。
而今年也推出了支持64位的EM64T技术,再还没被正式命为EM64T之前是IA32E,这是英特尔64位扩展技术的名字,用来区别X86指令集。Intel的 EM64T支持64位sub-mode,和AMD的X86-64技术类似,采用64位的线性平面寻址,加入8个新的通用寄存器(GPRs),还增加8个寄存器支持SSE指令。与AMD相类似,Intel的64位技术将兼容IA32和IA32E,只有在运行64位操作系统下的时候,才将会采用IA32E。 IA32E将由2个sub-mode组成:64位sub-mode和32位sub-mode,同AMD64一样是向下兼容的。Intel的EM64T将完全兼容AMD的X86-64技术。现在Nocona处理器已经加入了一些64位技术,Intel的Pentium 4E处理器也支持64位技术。
应该说,这两者都是兼容x86指令集的64位微处理器架构,但EM64T与AMD64还是有一些不一样的地方,AMD64处理器中的NX位在Intel的处理器中将没有提供。
11.超流水线与超标量
在解释超流水线与超标量前,先了解流水线(pipeline)。流水线是Intel首次在486芯片中开始使用的。流水线的工作方式就象工业生产上的装配流水线。在CPU中由5—6个不同功能的电路单元组成一条指令处理流水线,然后将一条X86指令分成5—6步后再由这些电路单元分别执行,这样就能实现在一个CPU时钟周期完成一条指令,因此提高CPU的运算速度。经典奔腾每条整数流水线都分为四级流水,即指令预取、译码、执行、写回结果,浮点流水又分为八级流水。
超标量是通过内置多条流水线来同时执行多个处理器,其实质是以空间换取时间。而超流水线是通过细化流水、提高主频,使得在一个机器周期内完成一个甚至多个操作,其实质是以时间换取空间。例如Pentium 4的流水线就长达20级。将流水线设计的步(级)越长,其完成一条指令的速度越快,因此才能适应工作主频更高的CPU。但是流水线过长也带来了一定副作用,很可能会出现主频较高的CPU实际运算速度较低的现象,Intel的奔腾4就出现了这种情况,虽然它的主频可以高达1.4G以上,但其运算性能却远远比不上AMD 1.2G的速龙甚至奔腾III。
12.封装形式
CPU封装是采用特定的材料将CPU芯片或CPU模块固化在其中以防损坏的保护措施,一般必须在封装后CPU才能交付用户使用。CPU的封装方式取决于CPU安装形式和器件集成设计,从大的分类来看通常采用Socket插座进行安装的CPU使用PGA(栅格阵列)方式封装,而采用Slot x槽安装的CPU则全部采用SEC(单边接插盒)的形式封装。现在还有PLGA(Plastic Land Grid Array)、OLGA(Organic Land Grid Array)等封装技术。由于市场竞争日益激烈,目前CPU封装技术的发展方向以节约成本为主。
13、多线程
同时多线程Simultaneous multithreading,简称SMT。SMT可通过复制处理器上的结构状态,让同一个处理器上的多个线程同步执行并共享处理器的执行资源,可最大限度地实现宽发射、乱序的超标量处理,提高处理器运算部件的利用率,缓和由于数据相关或Cache未命中带来的访问内存延时。当没有多个线程可用时,SMT 处理器几乎和传统的宽发射超标量处理器一样。SMT最具吸引力的是只需小规模改变处理器核心的设计,几乎不用增加额外的成本就可以显著地提升效能。多线程技术则可以为高速的运算核心准备更多的待处理数据,减少运算核心的闲置时间。这对于桌面低端系统来说无疑十分具有吸引力。Intel从3.06GHz Pentium 4开始,所有处理器都将支持SMT技术。
14、多核心
多核心,也指单芯片多处理器(Chip multiprocessors,简称CMP)。CMP是由美国斯坦福大学提出的,其思想是将大规模并行处理器中的SMP(对称多处理器)集成到同一芯片内,各个处理器并行执行不同的进程。与CMP比较, SMT处理器结构的灵活性比较突出。但是,当半导体工艺进入0.18微米以后,线延时已经超过了门延迟,要求微处理器的设计通过划分许多规模更小、局部性更好的基本单元结构来进行。相比之下,由于CMP结构已经被划分成多个处理器核来设计,每个核都比较简单,有利于优化设计,因此更有发展前途。目前, IBM 的Power 4芯片和Sun的 MAJC5200芯片都采用了CMP结构。多核处理器可以在处理器内部共享缓存,提高缓存利用率,同时简化多处理器系统设计的复杂度。
2005年下半年,Intel和AMD的新型处理器也将融入CMP结构。新安腾处理器开发代码为Montecito,采用双核心设计,拥有最少18MB片内缓存,采取90nm工艺制造,它的设计绝对称得上是对当今芯片业的挑战。它的每个单独的核心都拥有独立的L1,L2和L3 cache,包含大约10亿支晶体管。
15、SMP
SMP (Symmetric Multi-Processing),对称多处理结构的简称,是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系统以及总线结构。在这种技术的支持下,一个服务器系统可以同时运行多个处理器,并共享内存和其他的主机资源。像双至强,也就是我们所说的二路,这是在对称处理器系统中最常见的一种(至强MP可以支持到四路,AMD Opteron可以支持1-8路)。也有少数是16路的。但是一般来讲,SMP结构的机器可扩展性较差,很难做到100个以上多处理器,常规的一般是8个到16个,不过这对于多数的用户来说已经够用了。在高性能服务器和工作站级主板架构中最为常见,像UNIX服务器可支持最多256个CPU的系统。
构建一套SMP系统的必要条件是:支持SMP的硬件包括主板和CPU;支持SMP的系统平台,再就是支持SMP的应用软件。
为了能够使得SMP系统发挥高效的性能,操作系统必须支持SMP系统,如WINNT、LINUX、以及UNIX等等32位操作系统,即能够进行多任务和多线程处理。多任务是指操作系统能够在同一时间让不同的CPU完成不同的任务;多线程是指操作系统能够使得不同的CPU并行的完成同一个任务。
要组建SMP系统,对所选的CPU有很高的要求,首先、CPU内部必须内置APIC(Advanced Programmable Interrupt Controllers)单元。Intel 多处理规范的核心就是高级可编程中断控制器(Advanced Programmable Interrupt Controllers--APICs)的使用;再次,相同的产品型号,同样类型的CPU核心,完全相同的运行频率;最后,尽可能保持相同的产品序列编号,因为两个生产批次的CPU作为双处理器运行的时候,有可能会发生一颗CPU负担过高,而另一颗负担很少的情况,无法发挥最大性能,更糟糕的是可能导致死机。
16、NUMA技术
NUMA即非一致访问分布共享存储技术,它是由若干通过高速专用网络连接起来的独立节点构成的系统,各个节点可以是单个的CPU或是SMP系统。在NUMA中,Cache 的一致性有多种解决方案,需要操作系统和特殊软件的支持。图2中是Sequent公司NUMA系统的例子。这里有3个SMP模块用高速专用网络联起来,组成一个节点,每个节点可以有12个CPU。像Sequent的系统最多可以达到64个CPU甚至256个CPU。显然,这是在SMP的基础上,再用 NUMA的技术加以扩展,是这两种技术的结合。
17、乱序执行技术
乱序执行(out-of-orderexecution),是指CPU允许将多条指令不按程序规定的顺序分开发送给各相应电路单元处理的技术。这样将根据个电路单元的状态和各指令能否提前执行的具体情况分析后,将能提前执行的指令立即发送给相应电路单元执行,在这期间不按规定顺序执行指令,然后由重新排列单元将各执行单元结果按指令顺序重新排列。采用乱序执行技术的目的是为了使CPU内部电路满负荷运转并相应提高了CPU的运行程序的速度。分枝技术:(branch)指令进行运算时需要等待结果,一般无条件分枝只需要按指令顺序执行,而条件分枝必须根据处理后的结果,再决定是否按原先顺序进行。
18、CPU内部的内存控制器
许多应用程序拥有更为复杂的读取模式(几乎是随机地,特别是当cache hit不可预测的时候),并且没有有效地利用带宽。典型的这类应用程序就是业务处理软件,即使拥有如乱序执行(out of order execution)这样的CPU特性,也会受内存延迟的限制。这样CPU必须得等到运算所需数据被除数装载完成才能执行指令(无论这些数据来自CPU cache还是主内存系统)。当前低段系统的内存延迟大约是120-150ns,而CPU速度则达到了3GHz以上,一次单独的内存请求可能会浪费200 -300次CPU循环。即使在缓存命中率(cache hit rate)达到99%的情况下,CPU也可能会花50%的时间来等待内存请求的结束-比如因为内存延迟的缘故。
你可以看到Opteron整合的内存控制器,它的延迟,与芯片组支持双通道DDR内存控制器的延迟相比来说,是要低很多的。英特尔也按照计划的那样在处理器内部整合内存控制器,这样导致北桥芯片将变得不那么重要。但改变了处理器访问主存的方式,有助于提高带宽、降低内存延时和提升处理器性能。
19、Linux下对物理CPU CPU核数 逻辑CPU 超线程的理解
基本概念
物理CPU:物理CPU就是插在主机上的真实的CPU硬件,在Linux下可以数不同的physical id 来确认主机的物理CPU个数。
核心数:物理CPU下一层概念就是核心数,我们常常会听说多核处理器,其中的核指的就是核心数。在Linux下可以通过cores来确认主机的物理CPU的核心数。
逻辑CPU:核心数下一层的概念是逻辑CPU,逻辑CPU跟超线程技术有联系,假如物理CPU不支持超线程的,那么逻辑CPU的数量等于核心数的数量;如果物理CPU支持超线程,那么逻辑CPU的数目是核心数数目的两倍。在Linux下可以通过 processors 的数目来确认逻辑CPU的数量。
超线程:超线程是英特尔开发出来的一项私有技术,使得单个处理器可以象两个逻辑处理器那样运行,这样单个处理器以并行执行线程。这里的单个处理器也可以理解为CPU的一个核心;这样便可以理解为什么开启了超线程技术后,逻辑CPU的数目是核心数的两倍了。
关于CPU的一些信息可在 /proc/cpuinfo 这个文件中查看:
processor : 9
vendor_id : GenuineIntel
cpu family : 6
model : 62
model name : Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz
stepping : 4
microcode : 0x416
cpu MHz : 1679.526
cache size : 25600 KB
physical id : 0
siblings : 10
core id : 12
cpu cores : 10
apicid : 24
initial apicid : 24
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm cpuid_fault epb pti tpr_shadow vnmi flexpriority ept vpid fsgsbase smep erms xsaveopt dtherm ida arat pln pts
bugs : cpu_meltdown spectre_v1 spectre_v2
bogomips : 5588.33
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
以上输出项的含义如下:
processor :系统中逻辑处理核的编号。对于单核处理器,则课认为是其CPU编号,对于多核处理器则可以是物理核、或者使用超线程技术虚拟的逻辑核
vendor_id :CPU制造商
cpu family :CPU产品系列代号
model :CPU属于其系列中的哪一代的代号
model name:CPU属于的名字及其编号、标称主频
stepping :CPU属于制作更新版本
cpu MHz :CPU的实际使用主频
cache size :CPU二级缓存大小
physical id :单个CPU的标号
siblings :单个CPU逻辑物理核数
core id :当前物理核在其所处CPU中的编号,这个编号不一定连续
cpu cores :该逻辑核所处CPU的物理核数
apicid :用来区分不同逻辑核的编号,系统中每个逻辑核的此编号必然不同,此编号不一定连续
fpu :是否具有浮点运算单元(Floating Point Unit)
fpu_exception :是否支持浮点计算异常
cpuid level :执行cpuid指令前,eax寄存器中的值,根据不同的值cpuid指令会返回不同的内容
wp :表明当前CPU是否在内核态支持对用户空间的写保护(Write Protection)
flags :当前CPU支持的功能
bogomips :在系统内核启动时粗略测算的CPU速度(Million Instructions Per Second)
clflush size :每次刷新缓存的大小单位
cache_alignment :缓存地址对齐单位
address sizes :可访问地址空间位数
power management :对能源管理的支持,有以下几个可选支持功能:
ts:temperature sensor
fid:frequency id control
vid:voltage id control
ttp:thermal trip
tm:
stc:
100mhzsteps:
hwpstate:
CPU信息中flags各项含义:
fpu: Onboard (x87) Floating Point Unit
vme: Virtual Mode Extension
de: Debugging Extensions
pse: Page Size Extensions
tsc: Time Stamp Counter: support for RDTSC and WRTSC instructions
msr: Model-Specific Registers
pae: Physical Address Extensions: ability to access 64GB of memory; only 4GB can be accessed at a time though
mce: Machine Check Architecture
cx8: CMPXCHG8 instruction
apic: Onboard Advanced Programmable Interrupt Controller
sep: Sysenter/Sysexit Instructions; SYSENTER is used for jumps to kernel memory during system calls, and SYSEXIT is used for jumps: back to the user code
mtrr: Memory Type Range Registers
pge: Page Global Enable
mca: Machine Check Architecture
cmov: CMOV instruction
pat: Page Attribute Table
pse36: 36-bit Page Size Extensions: allows to map 4 MB pages into the first 64GB RAM, used with PSE.
pn: Processor Serial-Number; only available on Pentium 3
clflush: CLFLUSH instruction
dtes: Debug Trace Store
acpi: ACPI via MSR
mmx: MultiMedia Extension
fxsr: FXSAVE and FXSTOR instructions
sse: Streaming SIMD Extensions. Single instruction multiple data. Lets you do a bunch of the same operation on different pieces of input: in a single clock tick.
sse2: Streaming SIMD Extensions-2. More of the same.
selfsnoop: CPU self snoop
acc: Automatic Clock Control
IA64: IA-64 processor Itanium.
ht: HyperThreading. Introduces an imaginary second processor that doesn’t do much but lets you run threads in the same process a bit quicker.
nx: No Execute bit. Prevents arbitrary code running via buffer overflows.
pni: Prescott New Instructions aka. SSE3
vmx: Intel Vanderpool hardware virtualization technology
svm: AMD "Pacifica" hardware virtualization technology
lm: "Long Mode," which means the chip supports the AMD64 instruction set
tm: "Thermal Monitor" Thermal throttling with IDLE instructions. Usually hardware controlled in response to CPU temperature.
tm2: "Thermal Monitor 2″ Decrease speed by reducing multipler and vcore.
est: "Enhanced SpeedStep"
根据以上内容,我们则可以很方便的知道当前系统关于CPU、CPU的核数、CPU是否启用超线程等信息。
查询系统具有多少个逻辑核:cat /proc/cpuinfo | grep "processor" | wc -l
查询系统CPU的物理核数:cat /proc/cpuinfo | grep "cpu cores" | uniq
查询系统CPU是否启用超线程:cat /proc/cpuinfo | grep -e "cpu cores" -e "siblings" | sort | uniq
如果cpu cores数量和siblings数量一致,则没有启用超线程,否则超线程被启用。
查询系统CPU的个数:cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l
查询系统CPU是否支持某项功能,则根以上类似,输出结果进行sort, uniq和grep就可以得到结果。
判断依据:
1.具有相同core id的 cpu是同一个core的超线程。
2.具有相同physical id的cpu是同一颗cpu封装的线程或者cores。
一些操作系统的最新版本已经更新了 /proc/cpuinfo 文件,以支持多路平台。如果您的系统中的 /proc/cpuinfo 文件能够正确地反映出处理器信息,那么就不需要执行上述步骤。反之,可采用本文中的信息进行解释。
/proc/cpuinfo 文件包含系统上每个处理器的数据段落。/proc/cpuinfo 描述中有 6个条目适用于多 内核和超线程(HT)技术检查:processor, vendor id, physical id, siblings, core id 和 cpu cores。
processor 条目包括这一逻辑处理器的唯一标识符。
physical id 条目包括每个物理封装的唯一标识符。
core id 条目保存每个内核的唯一标识符。
siblings 条目列出了位于相同物理封装中的逻辑处理器的数量。
cpu cores 条目包含位于相同物理封装中的内核数量。
如果处理器为英特尔处理器,则 vendor id 条目中的字符串是 GenuineIntel。
1.拥有相同 physical id 的所有逻辑处理器共享同一个物理插座。每个 physical id 代表一个唯一的物理封装。
2.Siblings 表示位于这一物理封装上的逻辑处理器的数量。它们可能支持也可能不支持超线程(HT)技术。
3.每个 core id 均代表一个唯一的处理器内核。所有带有相同 core id 的逻辑处理器均位于同一个处理器内核上。
4.如果有一个以上逻辑处理器拥有相同的 core id 和 physical id,则说明系统支持超线程(HT)技术。
5.如果有两个或两个以上的逻辑处理器拥有相同的 physical id,但是 core id 不同,则说明这是一个多内核处理器。cpu cores 条目也可以表示是否支持多内核。
例如,如果系统包含两个物理封装,每个封装中又包含两个支持超线程(HT)技术的处理器内核,则 /proc/cpuinfo 文件将包含此数据。
processor 下的 core id表示这个逻辑CPU属于哪个核心,而physical id则表示这个核心或者说逻辑CPU属于哪个物理CPU。了解这些信息,便可以方便地查看上面说到的那些参数。
从接口看看CPU发展
AM5接口的AMD Ryzen 7000系列处理器推出后,意味着全部处理器都转向了LGA接口,AM4这个末代PGA接口就此挥别,PGA再无发展可能。可能有些疑问,这些个名词又是LGA又是PGA的,究竟是什么意思?

来一起通过这些接口插槽来看看CPU吧!本节转自智趣东西的个人空间,感谢原作者。
什么是PGA
在CPU插槽尚未发明之前,CPU是直接焊接在主板上的。因早期电脑不普及、CPU种类较少,基本无问题。后来CPU开始变得多种多样,且DIY日益兴起,为了方便CPU的拆装更换,CPU插槽应运而生。
所谓PGA,其实它是一个缩写,全称为Pin Grid Array,即插针网格阵列。PGA封装一般是将集成电路(IC)焊接在一块电路板上,电路板的另一面是排列成方阵的插针,这些插针可以插入或焊接到其他电路板上对应的插座中,适合于需要频繁插拔的场合。其实,无论PGA还是LGA,都是以Socket插座形式安装的,只不过习惯上我们用Socket指代PGA罢了。
一般PGA插针的间隔为1/10英寸或2.54毫米。早期的Intel Pentium处理器采用的是PGA封装(Pentium 2之前),后来的Pentium 4处理器则采用了基于PGA技术发展来的FC-PGA(反转芯片PGA)封装,但依旧属于PGA范畴。

什么是LGA
那么,什么是LGA呢?LGA全称为Land grid array,即平面网格数组封装,是一种集成电路的表面安装技术。其特点在于其针脚是位于插座上而非集成电路上。LGA封装的芯片能被连接到印刷电路板(PCB)上或直接焊接至电路板上。与传统针脚在集成电路上的封装方式相比,可减少针脚损坏的问题并可增加脚位。

其实早在1996年,MIPS R10000和HP PA-8000处理器就已经使用LGA封装,但Intel从2004年的Pentium 4 (Prescott) 处理器才开始使用。所有Pentium D和Core 2 Duo乃至今天的所有Intel台式机处理器都使用LGA封装。从2006年第一季度开始,Intel开始在服务器领域使用LGA封装。而AMD之前只在服务器及高性能领域才使用LGA封装(如 Socket G34,LGA 1944),直到现在全新一代的Ryzen 7000系列才转换到LGA(AM5)。
插槽之演变
如果我们将处理器与普通芯片“一视同仁”,就会发现,无论是PGA还是LGA不过是为了方便更换而生的一种插槽接口方式。对比其他很多芯片,接插、安装方式多为焊接不可更换(或者说需要专业工具)的形式,例如双列直插封装、单列直插封装(SIP)、锯齿形直插封装(ZIP)、球栅阵列封装(BGA)等等。

CPU之所以需要更换,就是为了便于用户或者厂商对处理器的升级、更替。如果从电气特性、安全性来看,BGA方式其实是非常好的选择——但是它不具备便利的可更换特性。

PGA接口的出现,极大方便了更换处理器的工作,LGA的出现则更大程度上是为了降低维修成本——针脚从处理器一侧改在主板上,别看这个小改变,PGA的针脚容易断裂、且间隔较大。另一方面,LGA具备极佳的“扩展性”,PGA则不便于容纳更多接触点。这些点位或是供电、或是信号,随着处理器的复杂程度日益加剧,PGA显然不如LGA来得好。

当然,无论是PGA还是LGA接口,在安装处理器的时候,如何将其固定就十分有讲究了。为此,针对不同的接口也有不同的固定方式。在PGA接口上,其插座为零插拔力插座,即ZIF(Zero insertion force)。它通过一个杠杆让用户拉起或推开插座,这个时候,插座内的弹簧式触点就会分开,然后将PGA接口的处理器对准放下,再将拉杆拉回到原位卡主。当插座“归位”后,接触点会闭合并且“抓紧”处理器的针脚,以此固定。
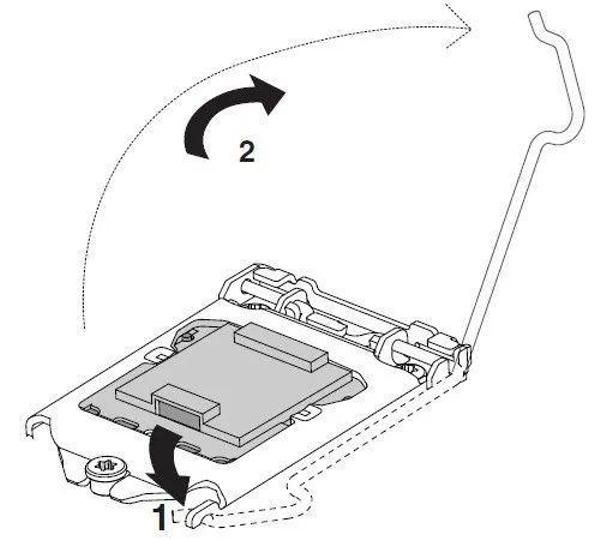
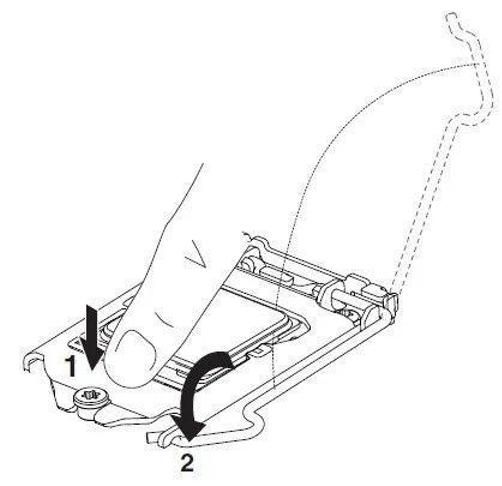
而在LGA接口上,其实也是大同小异,只不过它是通过紧固顶盖的方式固定,少了弹簧式触点而已。
你方唱罢我登场
Socket 1—Socket 3
1989年,Intel最著名的80486处理器登场了,与之配套的便是Socket 1插座,这个时候,处理器的针脚不过169个,对比Intel最多触点的Socket R4插座(2066个触点),几乎是12倍的差距!Socket 1也是Intel第一个标准化的处理器插座,以此为基础,Socket 1一直发展至Socket 3。这期间,CPU一直是80486一个型号,当然区分为80486 SX/DX/DX2/DX4,乃至80486 OverDrive不同的规格,针脚也一路从169个升级到237个。

Socket 4—Socket 5
Socket 4至Socket 5时期,Intel推出了著名的Pentium品牌处理器,也就是通俗意义上的80586(实际上没有这个名称)。同一时期,AMD也在Socket 5上推出了AMD K5处理器——尽管性能还是要比Pentium来得差一些。在Socket 4接口上,处理器的针脚数量为273个,而到了Socket 5上,已经增加到了320个针脚,当然,不同接口下的Pentium 处理器型号、性能也在变化。

Socket 7
1994年正式启用的Socket 7极为经典,Intel Pentium MMX就是基于Socket 7接口的处理器产品,也正是这个时期,个人电脑在中国开始流行起来。在这个时期,最为经典的Intel 430TX芯片组主板+Pentium MMX或者AMD K6-2几乎是“标配”的组合。
而且Socket 7接口因为没有专利壁垒的制约,所以第三方处理器如雨后春笋般爆发,包括Cyrix、AMD、IDT、Rise等处理器都在使用Socket 7。这也让Intel“痛定思痛”,推出了一个非常有悖常理的Slot 1接口,以专利壁垒的形式让诸多处理器厂商就此退出赛道。但是Socket 7接口的寿命并没有随着Intel改换门庭而终结,相反,在AMD的“大力支持”下,Socket 7一直存活到了2000年——AMD在这个接口上一直持续推出处理器,包括著名的K6-2+和K6-3。

Super Socket 7
1998年是属于AMD的一个闪耀时代,AMD K6-2大放异彩,这也是AMD第一次有了正面抗衡Intel处理器底气的一款经典产品。AMD的处理器此前一直采用Intel的插槽,而Socket 7是AMD拥有合法授权的最后一个。Intel曾希望通过中止Socket 7发展和走向Slot 1,让其他厂商无路可走,这个时期,诸多处理器厂商都倒下了。而AMD却坚持下来,根据需要,将Socket 7升级为Super Socket 7——它以配备100 MHz FSB(前端总线),在Socket 7接口上,最高只能支持83MHz的FSB。而且,Super Socket 7还提供了对AGP总线的支持,这也是Socket 7接口上没有的。
另外,Super Socket 7还向下相容Socket 7,这意味着Socket 7的处理器可以用在Super Socket 7接口的主板上,但使用Super Socket 7规格的处理器在Socket 7主板上无法全速运作(前端总线的制约)。

特殊时期的产物
Slot 1
Slot 1是Intel于1997年推出的一种处理器插槽,使用P6 GTL+总线协议,它拥有242个引脚,与当时的Intel Pentium 2一同推出。Slot 1并不是一个明智的技术产物,或者说它更是为了以专利壁垒限制竞争对手的商业手段——Intel在当时声称,在Socket 7接口的处理器中无法放置二级缓存,必须从物理形式上进行改变以满足这个设计要求。然而在此之后的不久,Intel就推出了Socket 370接口,在Socket 370的Celeron 300A处理器上,128KB的二级缓存赫然在列。而且,这种金手指的设计实际上也不可能有太多的发展空间,处理器越发复杂,需要的针脚也越来越多,金手指的插槽物理尺寸限制不可能无限扩大。最终Socket 370接口全面取代了Slot 1接口,这是因为Slot 1的设计传输速率达到了极限。

Slot A
Intel推出的Slot 1无疑堵住了大多数人的前进之路,不过AMD是个例外。你有Slot 1,我就弄一个Slot A!而且Slot A接口下的Athlon处理器,是历史上第一个达到1GHz的处理器产品!相比于Super Socket 7,Slot A拥有更高的总线速度,而且与之配套的处理器采用的是DEC原本为Alpha处理器开发的的EV6总线协议(服务器用),它的技术规格在当时非常先进。
有趣的是,Slot A接口从外观上看和Slot 1几乎就是调转了180度,这样可以让主板生产厂商从现有市场采购所需要的接插件加以利用——当然,虽然物理形式极为接近,但是它对每个针脚(金手指)的物理定义完全不同。

Socket 370
正如前文所述,Intel在转换到Slot 1接口之后不久,针对性的又推出了Socket 370接口的处理器,本意是针对OEM市场及中低端市场使用。很快,这个接口就取代了Slot 1,成为了相当时间内的主流处理器接口。所谓Socket 370,是指它的针脚达到了370个,进一步提升了密度,有趣的是,这个处理器接口和Slot 1可以实现转换——即Slot 1接口主板可以通过转接卡安装Socket 370接口的部分处理器,毕竟一段时间内它们都是使用Intel B440BX芯片组的。在Socket 370接口的处理器中,最出名的莫过于Intel Tualatin Pentium 3/Pentium 3S了,它们的性能甚至超过了部分早期的Intel Pentium 4处理器。

Socket A
Intel和AMD的双雄局面就是从Slot 1/Slot A至Socket 370/Socket A阶段正式形成的。为了对抗由Slot 1到Socket 370的转变,AMD在Slot A接口之后推出了Socket A接口,或者称之为Socket 462接口。Socket A接口拥有 462个针脚,密度更进一步,它主要支持Athlon K7至Athlon XP 3200+处理器,包括历史上极为著名的Barton Athlon XP、Morgan Duron处理器,都是基于Socket A接口的产物。最重要的是,这一时期AMD的处理器性能普遍要好于同级别的Intel处理器10%以上——Intel Pentium 4这个历史上最失败的处理器拖了后腿。

Socket 423—Socket 478
Intel犯错一直持续到Socket 423接口上。Socket 423的出现是为了配合Pentium 4处理器推出的,针脚数量达到了423个,目的是为了RDRAM内存数据交互和处理器的频率提升而设计。不过很快Intel就发现了一个致命错误,Willamette核心的Pentium 4处理器本意是为了高频而生,但是因为设计问题,频率始终无法突破2GHz,很快,它就被Socket 478接口的产品取代了——那些购买了Socket 423接口产品的人非常痛苦,因为它们升级的代价就是全面替换,而不是渐进升级。

Socket 478为替代Socket 423而生,初期也不是很顺利,最早的Socket 478接口主板因为设计问题不能支持533MHz前端总线,直至中期才开始完善并且最终支持到800MHz前端总线。而且,Socket 478接口时期也是Intel历史上非常黑暗的一段日子,这个接口下的Pentium 4处理器极为差劲,超高流水线、超高频率的Pentium 4处理器性能实际上非常孱弱,尤其是Prescott核心的Pentium 4处理器,性能低功耗高,发热也十分恐怖。到了2004年,LGA 775取代了Socket 478,Intel才迎来了曙光。

Socket 754—Socket 939
2003年9月,AMD发布了Socket 754接口平台,用以支持Athlon 64和Sempron处理器使用,这也是首个支持64位处理器的接口平台。与后期发布的Socket 939接口平台对比,它实际是一个“不完全体”,具体表现在它支持单通道内存,HyperTransport总线带宽只有9.6GB/s,这也限制了这个平台的性能发挥,因此Socket 754接口的寿命并不长。

2004年6月,也就是Socket 754推出后不到一年的时间,AMD发布了Socket 939接口平台,它可以支持Socket 754所不能提供的双通道内存规格,并且HyperTransport总线的带宽也更大。不过你以为Socket 939很长寿吗?答案是否定的,仅仅过了不到两年时间,也就是2005年的5月,Socket 939就迅速被AM2接口取代了。

新世代LGA VS PGA 性能之争
截至目前,除了Slot 1和Slot A接口外,无一例外处理器都是使用PGA方式设计的,而在2004年,Intel推出了更为先进的LGA即LGA 775平台,就此一场PGA VS LGA的争夺战正式打响——如果以AMD的AM5作为截止符,这场“争夺”持续了18年之久。
LGA 775
LGA 775于2004年7月发布,最初取名为Socket T,这是首个使用LGA方式的接口平台。不过这个时期,Intel的处理器性能依旧“拉胯”,Pentium 4、Pentium D、部分Prescott核心的Celeron(Celeron D)性能难以让消费者满意,直到划时代的Core 2 Duo处理器诞生,才让Intel重回性能之巅。

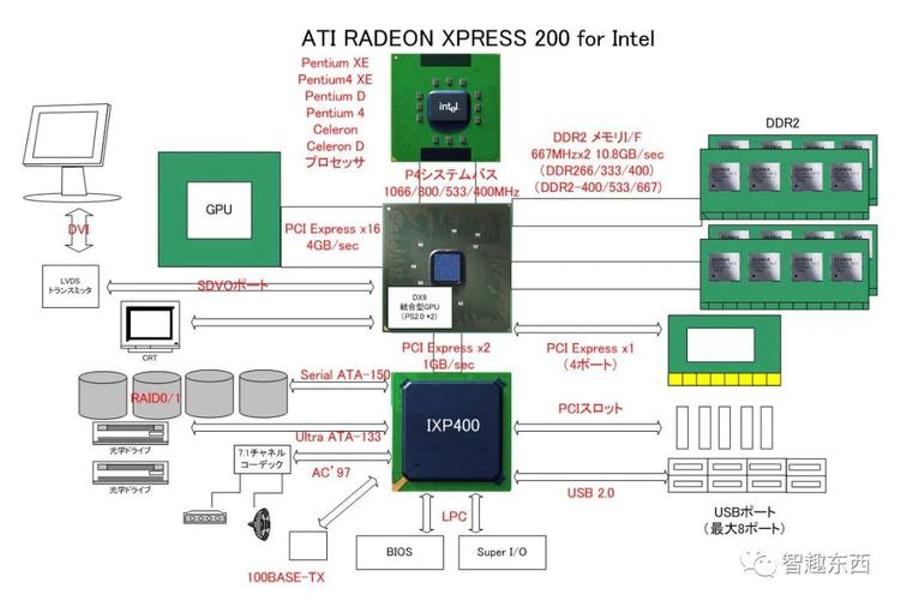
有趣的是,LGA 775接口平台也是最后一个拥有第三方芯片组的产物,这个时期除了Intel自己的芯片组产品外,NVIDIA还推出了支持LGA 775接口平台的nForce系列芯片组产品,SIS也拥有 SIS649/656/656FX/661FX/662/670/671FX多款产品,VIA也有VIA PM800/PT800Pro/PT894/PT894 Pro多款。最有趣的是,刚刚被AMD收购的ATI也推出了支持Intel处理器的Radeon Xpress 200 IE、RD600芯片组产品。在此之后Intel也好、AMD也罢,再也没有第三方芯片组产品了,这两家厂商形成了事实上的平台垄断。
LGA 1156—LGA 1151
LGA 775接口平台的Core 2 Duo一经发布便让Intel重回巅峰,自然Intel希望凭借这个优势稳固自己的优势地位,LGA 1366和LGA 1156就此诞生。LGA 1366接口平台产品性能极为强悍,但是多用在服务器、工作站上,对普通用户而言LGA 1156更为合适,在LGA 1156接口平台上,第一次取消了南北桥设计,也就是将北桥功能集成于处理器之中,南桥则演变为PCH芯片,也就是单芯片构架,这种模式沿用至今。之后的LGA 1155更是达到了一个新高度,著名的Sandy Bridge构架处理器至今还有一些老用户在使用,可见其性能之强悍。

到了2013年,短命的LGA 1150诞生了,尤其对比后来者LGA 1151接口平台,它的寿命不过只有两年,很快就被取代了。LGA 1151接口品台于2015年推出,从Skylake到Coffee Lake,LGA 1151接口平台历经了Intel四代处理器,甚至最早的100系列芯片组可以通过“破解、修改”从第六代处理器一直支持到第九代处理器,历经5年之久。

Socket AM2—Socket AM3+
在Intel LGA接口平台高歌猛进之时,AMD却陷入了麻烦,2006年AMD推出了Socket AM2接口平台,针脚数量为940个(单就数量而言只比Socket 939多了一针),与之匹配的Phenom构架系列处理器性能对比Intel同时代产品总是差强人意,也是这个时期,Intel的处理器因为领先优势代际间性能差距并不大——因为这已经足够压制AMD平台产品了。
为了保持竞争力,AMD的Socket AM2至Socket AM3保持了良好的兼容性,因此设计也颇为奇特。比如到了AM3接口平台的时候,其主板的接口拥有941个针脚,但是处理器则是938个针脚,这样独特而怪异的设计应该是历史上唯二的存在。在AM2和AM3接口平台之间,还有一个过渡性的AM2+,用以平滑过渡,但是它的存在时间极为短暂,只不过是以AM2接口平台为基础,增加了对HyperTransport 3.0总线的支持,但是又不能使用DDR3,很快就被淘汰了。
到了AM3+时,主板底座针脚数为942个,处理器针脚数为938个,以此来保持对AM3接口处理器的兼容。它提供了AM3接口平台没有的HyperTransport 3.1总线,并且DDR3内存规格和供电效率上改进明显。不过,这个时候的AMD处理器依旧难与Intel同时代产品竞争,可以说,这一段时期也是AMD历史上最为艰难的时刻。

Socket AM 4
什么是扬眉吐气?Socket AM 4接口平台完美的诠释了这一点。早期的Socket AM 4平台几乎就是APU的天下,代号为Bristol Ridge的APU产品集成了诸多功能,用以吸引用户使用。2016年发布的Socket AM 4拥有1331个针脚,这让它的拓展性大为增加。到了2017年,隐忍了许久的AMD终于爆发了——Ryzen在此时横空出世,它让AMD再也次拥有了和Intel一较高下的本钱。时至今日,Socket AM 4横跨了四代产品,从Zen直至Zen3微构架的Ryzen处理器将Intel的同时代产品比了下去,同时,其保持了极佳的兼容性,即便是老款的Socket AM 4接口平台芯片组主板,也能对新处理器提供良好的兼容性支持。可以说,Socket AM 4接口平台功不可没。

LGA 1200—LGA 1700
LGA 1200接口平台的推出,无疑现在看是一个过渡性产品,而且其配套处理器的性能并不令人满意。2020年5月发布,2021年就被LGA 1700取代了。上不能替LGA 1151,下无法与LGA 1700平滑过渡,LGA 1200接口平台虽然支持10代和11代酷睿处理器,但只是昙花一现的存在而已。
LGA 1700接口平台无疑是Intel的一个翻身仗——大小核心设计、支持DDR5内存规格的12代酷睿处理器终于迎头赶上,性能提升巨大,但也正因如此,其对电压、信号等设计更加复杂,更多的针脚来定义相关规格势在必行。这也是为什么LGA 1700的触点数量一下提升了500个的根本原因。

LGA AM5
Intel和AMD总是呈现螺旋式的技术竞争,不过在接口方面,AMD最终也从PGA转换到LGA了。

可以说,Socket AM4已经是PGA方式的天花板了,处理器拥有高达1331个针脚,实难再扩大面积增加针脚数量。要知道新一代Ryzen 7000系列的处理器拥有高达1718个触点,继续使用PGA模式无疑是非常困难的(除非继续增大处理器面积),无论对安装还是后期维修来说,都已经很难实现,因此必须专用AM5接口平台。之所以需要这么多的触点,是因为在Ryzen 7000系列处理器不仅要提供对DDR5的支持,同时还需要对PCI-E 5.0提供支撑,那么多的信号定义、供电定义,无论如何也是AM4接口平台那1331个针脚无法支撑的,这也是为什么AMD最终也转向了LGA的根本原因。
从技术角度,LGA确实要比PGA更好,因为在有限的面积内它可以容纳更多的触点,PGA的针脚间距不可能一直缩小。而且在维修上,更换处理器底座的技术难度远远低于修复处理器针脚的难度。
如果不考虑更换升级的可能性,BGA才是最终的“王道”,例如APPLE的处理器产品,目前无一例外都采用BGA方式,这样可以充分保证足够的电气特性,同时也兼具稳定性,故障几率相比也是最低的。但是对于大多数人而言(包括我在内),可更换、升级处理器是一个必须的选项。显然,在可见的未来相当长一段时间内,LGA将是唯一的选择。
CPU散热器发展编年简史
在早期,CPU虽然制造工艺在现在看着非常落后,而且主频都非常低,但功率也比较低,所以发热量自然也就不高,甚至486之前的CPU很多都不安装散热器“裸奔”,例如Intel的80386处理器,TDP为1.85W,最大功耗也仅为2.3W,也就没有必要安装散热器了,但并不代表厂商对于发热问题不重视,例如CPU采用了陶瓷封装而不是塑料封装。

到了486时期,由于CPU频率的提升(虽然依然只有几十MHz),发热量也有所增加,例如英特尔486DX4处理器的最大功耗已经达到了5W。而当时的CPU和主板均没有安全温度运行保护机制,导致CPU烧毁现象时有发生,因此CPU在出厂的时候就自带了小尺寸的被动散热片,只是导热介质是导热强力胶,而不是硅脂,这也意味着散热片贴上去容易,再取下来可就难喽。但也有一个好处就是……什么叫扣具?

等到了奔腾时期(也可以说是586时期),由于CPU的主频突破了100MHz,功耗也大幅提升到了11.2w,被动式散热片已经无法满足需求了,因此Intel第一代奔腾开始就配备了带有散热风扇的散热器,虽然体型小巧但颜值非常高,而且已经具备了风冷散热器的雏形,只是当时主板没有CPU风扇专用的3PIN/4PIN插针,需要从硬盘的D型4Pin取电。

不过,注意观察此时的Socket7 CPU插槽,可以发现它的两侧已经有了可以固定散热风扇的挂耳,尤其是Intel奔腾MMX和AMD的K6-2这种自带金属盖的CPU,就已经可以使用第三方的散热器了,当然后期的主板也出现了CPU散热器专用的3Pin插座。
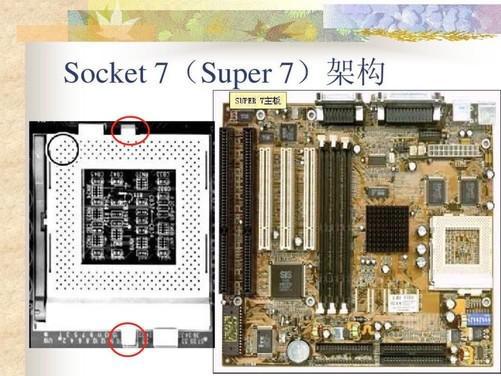
当年的Socket7第三方散热器就长这样的,已经和现在的普通风冷散热器无二致了,只是体型要小很多,并终于能用导热硅脂了。

而随着CPU性能的不断提升,功耗也不断增长,于是散热片的体型也开始变大。不过有意思的是,在Slot1的奔腾2时代,Intel还是有部分CPU不配散热风扇,但是散热片的体积嘛,看下图吧。

到了奔腾三和奔腾四时期,CPU的性能、功耗和发热量急剧增长,于是散热器的体积越来越大,散热风扇的尺寸也随之增长。不过1.xGHz的Socket370的散热器的底面积依然与插座相同,等到了2.0GHz以后的Socket478的奔腾四时期,这个尺寸就变得非常大了,如下图。

不过,尽管散热器尺寸不断变大,但奔腾4后期引入了3GHz的Prescott核心后,CPU的功耗和发热量持续上涨,单纯的铝鳍散热器已经不能满足需求,因此也出现了导热性能更好的纯铜的散热器。

但是纯铜散热器价格比较贵,重量又大,对于立式机箱来说增加了不少主板的负担,而且它的导热性能比纯铝好,但是散热性能却比纯铝差,因此又出现了铜底、塞铜以及铜铝结合的鳍片散热器,下图就是Intel原装的塞铜散热器,注意内部红色的铜芯。

下图是当年超频三的一款铜铝结合的鳍片散热器,CA即是铜铝结合的意思。

不过这些散热器,对于低主频CPU倒是完全够用,但是高主频,尤其是3GHz以上的CPU就有些力不从心了,因此热管+鳍片散热器也应运而生,而且也是采用铜底与CPU接触,并通过回流焊与热管结合在一起。当然当时的价格不算便宜,而且一开始也是卧式(或者叫下压式)的。

后来人们发现,将散热器立起来,可以实现合理的风道,从而进一步提升散热性能,因此塔式的热管鳍片风冷散热器也就应运而生了,也就是现在的样子,只是根据散热功率的不同,热管和散热风扇的数量也不一样,同时散热风扇的尺寸也增加到了8cm、9cm以上。这样,塔式散热器就可以应对更高功率的CPU了,而高端双塔式风冷散热器甚至面对入门级240mm水冷也毫无惧色。

不过,风冷散热器应对酷睿i9这类顶级处理器也难免力不从心,加上人们追求更好的散热效果和更低的噪音,因此水冷散热器也出现在市场上。水冷散热器的一整套系统其实可以看作是北方供暖系统的微缩版,毕竟液体的比热容较大,吸热效果更佳,而且冷排面积较大,散热效果自然也就更好。同时,根据CPU发热量的不同,水冷又有120mm、240mm和360mm几种规格。如今,水冷散热器的价格也不再高高在上,甚至不到400元就可以买到240mm的入门级水冷。

当然,这些对于消费者来说都算是普通的散热器,而对于超频玩家来说,干冰、液氮可能才是心头好。
参考来源:
Intel CPU
AMD CPU
64bit cpu
苹果M2处理器发行
Intel.英特尔.AMD.超微.所有CPU型号大全.pdf
该文章最后由 阿炯 于 2023-08-12 22:29:17 更新,目前是第 2 版。