64位 CPU
 64位处理器是指可以对虚拟地址空间(virtual address space)进行64位寻址的处理器,其可以以64位格式存贮数据,并可以对64位操作数执行数学运算操作。另外处理器的通用寄存器(GPRs)和运算器(ALUs)也是64位的。
64位处理器是指可以对虚拟地址空间(virtual address space)进行64位寻址的处理器,其可以以64位格式存贮数据,并可以对64位操作数执行数学运算操作。另外处理器的通用寄存器(GPRs)和运算器(ALUs)也是64位的。
计算机中的位数指的是 CPU 一次能处理的最大位数。在 Intel 由 16 位的 286 升级到 386 的时候,为了和 16 位系统兼容,它先推出的是 386SX,这种 CPU 内部预算为 32 位,外部数据传输为 16 位。直到 386DX 以后,所有的 CPU 在内部和外部都是32位的了。
在计算机中出现的“位”和 Byte,KB,MB 等有何关系,8 位等于一字节 Byte,即 8bit=1B。32 位处理器每次最多处理 4Byte(32bit),同理64位处理器每次最多处理 8Byte(64bit) 。32 位架构的 CPU 数据总线宽度是 32 位,每次可以传输 32 位数据,可以计算 4 个字节。64 位架构的 CPU 数据总线宽度是 64 位,每次可以传输 64 位数据,可以计算 8 个字节。
数据总线
数据总线是 CPU 与内存或其它器件之间的数据传输的通道,数据总线的宽度决定了 CPU 和外界的数据传输速度,每根线可以传输 1 位二进制数据,32 根线每次就可以传输 32 位数据,64 根线每次就可以传输 64 位数据。除了数据总线外还有地址总线和控制总线。
地址总线
CPU 通过地址总线来指定存储单元,地址总线的宽度决定了 CPU 所能访问的最大内存空间大小,1 根地址线能访问的内存空间是 1bit,32 根线访问的最大内存空间是 4G,64 根线...太大了。
控制总线
CPU 通过控制总线对外部器件进行控制,主要通过控制总线来传输控制信号和时序信号,控制总线是各种信号线的集合,是计算机各部件之间传送数据、地址和控制信息的公共通道,控制总线的宽度决定了 CPU 对外部器件的控制能力。
总体来说,CPU 作为总线的主控,通过控制总线向各个外部器件发送控制信号,通过地址总线访问内存地址,通过数据总线传输数据。CPU 的位数越大,可以计算的数值就越大,64 位 CPU 可以执行更大数字的运算,但这个优势在普通应用上不太明显,普通应用也没必要进行太大数字的运算,但是对于数值计算较多的应用就非常明显。同时 64 位 CPU 有更大的寻址空间。
运算速度不同:64 位 CPU 的通用寄存器数据宽度是 64 位,处理器依次可以读取 64 位数据,比 32 位多一倍,运算速度理论上会提升一倍。既然位数越高处理器运算速度越快,为什么不用 128 位、256 位的CPU?因为位数越高,处理器芯片的设计也就越复杂,当前的科技水平还无法制造这么复杂的 CPU。
32 位指令的程序一般来说可以在 64 位机器上运行,可以兼容。64 位指令的程序不可以在 32 位机器上运行,因为 32 位的寄存器存不下 64 位的指令。注意,其实还有 16 位的程序,但 16 位的程序不能运行在 64 位的机器上,因为没有提供兼容机制。
操作系统其实也是程序,64 位的操作系统使用的是 64 位的指令,不能安装在 32 位机器上。
设计初衷不同
64 位操作系统的设计初衷是为了满足需要大量内存和复杂浮点数运算的需求,一般用在科学计算、人工智能、平面设计、视频处理、3D 动画和游戏数据库以及各种网络服务器等领域中。
安装环境不同
64 位操作系统只能安装在 64 位 CPU 的机器上,同时需要配合 64 位的程序才能发挥最佳性能,32 位操作系统既可以安装在 32 位 CPU 的机器上,也可以安装在 64 位 CPU 的机器上,但没啥意义,64 位的性能会被打折扣。
寻址能力不同
32 位操作系统最多可以寻址 2 的 32 次方即 4,294,967,296 字节,约 4GB 内存,4GB 的内存就现在而言在很多服务端程序上都是不够用的,而 64 位操作系统理论上可以寻址 2 的 64 次方即 18,446,744,073,709,551,616 字节,超过 1亿GB 内存,但这只是理论上,由于不同架构的 CPU 设计不同,所以寻址能力也有差别。
32 位操作系统和 64 位操作系统下数据类型对应的字节大小也是不同的,正常数据类型对应的字节数应该是 CPU 位数决定的,但实际上貌似是由编译器决定的,看下表:
20 世纪和 21 世纪早期制造的计算机大多都是 32 位的机器,现如今大多都是 64 位的机器了,但为了兼容 32 位机器,一般编程都会开发出两个版本,例如打包一个 Android SDK,SDK 内部一般都会包含 32 位和 64 位的动态链接库,iOS 的 Framework 内部也会有 32 位和 64 位的静态链接库。
目前市场上Intel兼容处理器可以实现64位计算的主要有3种:
1)Intel IA64,基于安腾2处理器,不兼容32位应用。
2)Intel EM64T,基于Xeon DP "Nocona"和MP处理器,兼容32位应用。
3)AMD AMD64,基于Opteron处理器,兼容32位应用。
1)IA-64
是Intel独立开发,不兼容现在的传统的32位计算机,仅用于Itanium(安腾)以及后续产品Itanium 2 。
自从1993年Intel及其伙伴企业推出基于486系统的IA服务器以来,IA服务器经历了486系统、PentiumPro系统、PII系统、PIII系统、XEON系统等几个阶段。处理器系统的处理能力在大幅度提高,而服务器系统的总线结构始终是IA-32总线体系。
IA-32服务器在发展到8路XEON服务器以后,体系结构已经开始成为制约服务器性能提高的瓶颈。先是PCI通道带宽瓶颈,现在是内存总线带宽瓶颈和处理器系统扩展瓶颈。因此,hp和Intel自1994年开始合作开发IA-64架构的处理器,希望通过把hp在RISC领域的十年工作经验和超长指令字结合起来,在微处理器级上改进性能,以增加指令级上的并行性。
IA-64结构既不是Intel的32位x86结构的扩充,也不是完全采用hp公司64位PA-RISC结构,而是一种全新的设计样式。IA-64基于EPIC(显性并行指令计算-Explicitly Parallel Instruction Computing)技术。IA-64主要特性表现在几个方面:
* IA-64的系统内存寻址空间更大,可以支持32GB以上的内存,而IA-32服务器目前可以支持的最大内存容量是16GB。
* IA-64的处理器寻址、处理能力更强、速度更快。安腾(Itanium)处理器主频起步至少1GHz,二级Cache在2MB以上。
* IA-64系统增强的128位浮点计算寄存器大大提高了系统的浮点计算能力。
* IA-64系统将使用基于Infiniband技术的总线结构,它是以交换式系统总线代替目前的共享式总线为核心,将NGIO和 FutureIO两种技术合二为一,使系统总线、内存总线带宽和I/O总线带宽都将大大提高。IA-64系统带宽在2GB/s以上,而目前的SMPIA- 32服务器的系统带宽是1.06GB/s,PCI带宽一般是0.4GB/s。
* IA-64包括一系列的内置特征,以延长计算机的正常运转时间,减少宕机时间。机器检测体系在内存和数据路径中提供了错误恢复和纠错能力,它能让IA-64平台从预先导致系统失败的错误中恢复过来。
目前正式宣布支持IA-64平台的有Monterey、Linux64、hp-UX、Solaris、Win2000等操作系统。
2)EM64T
EM64T技术为需要超过4GB内存支持的应用提供强大的性能支持。
Intel官方是给EM64T这样定义的:EM64T全称Extended Memory 64 Technology,即扩展64bit内存技术。EM64T 是Intel IA-32架构的扩展,即IA-32e(Intel Architectur-32 extension)。IA-32处理器通过附加EM64T技术,便可在兼容IA-32软件的情况下,允许软件利用更多的内存地址空间,并且允许软件进行 32 bit线性地址写入。EM64T特别强调的是对32 bit和64 bit的兼容性。Intel为新核心增加了8个64 bit GPRs(R8-R15),并且把原有GRPs全部扩展为64 bit,如前文所述这样可以提高整数运算能力。增加8个128bit SSE寄存器(XMM8-XMM15),是为了增强多媒体性能,包括对SSE、SSE2和SSE3的支持。
Intel为支持EM64T技术的处理器设计了两大模式:传统IA-32模式(legacy IA-32 mode)和IA-32e扩展模式(IA-32e mode)。在支持EM64T技术的处理器内有一个称之为扩展功能激活寄存器(extended feature enable register,IA32_EFER)的部件,其中的Bit10控制着EM64T是否激活。Bit10被称作IA-32e模式有效(IA-32e mode active)或长模式有效(long mode active,LMA)。当LMA=0时,处理器便作为一颗标准的32 bit(IA32)处理器运行在传统IA-32模式;当LMA=1时,EM64T便被激活,处理器会运行在IA-32e扩展模式下。
3)AMD64
AMD64,又称“x86-64”或“x64”,是一种64位元的电脑处理器架构。它是建基于现有32位元的x86架构,由AMD公司所开发,应用 AMD64指令集的自家产品有Athlon 64、Athlon 64 FX、Athlon 64 X2、Turion 64、Opteron及最新的Sempron处理器。
架构概述 AMD试图以自家的AMD64指令集去清理Intel的x86-32专属的,并把x86更新至近似领先的RISC环境。曾参与设计DEC Alpha64位处理器的Dirk Meyer也有份参与制定AMD64的规格,以及AMD的员工中有不少前Alpha处理器的工程师,因此他们为AMD64立下不少功劳。部份重大改变如 下:
新增暂存器 地址阔度加长 SSE2、SSE3指令“禁止执行”位元 (NX-bit): AMD64其中一个特色是拥有“禁止执行”(No-Execute,NX)的位元,可以防止蠕虫病毒以缓冲区满溢的方式来进行攻击(也称:缓冲区溢位攻击,Buffer Overflow)。
市场分析 AMD64代表AMD放弃了跟随Intel标准的一贯作风,选择了像把16位的Intel 8086扩充成32位的80386般,去把x86架构扩充成64位版本,且兼容原有标准。
AMD64架构在IA-32上新增了64位暂存器,并兼容早期的16位和32位软件,可使现有以x86为对象的编译器容易转为AMD64版本。除此之外,NX bit也是引人注目的特色之一。
不少人认为,像DEC Alpha般的64位RISC芯片,最终会取代现有过时及多变的x86架构。但事实上,为x86系统而设的应用软件实在太庞大,成为Alpha不能取代 x86的主要原因,AMD64能有效地把x86架构移至64位的环境,并且能兼容原有的x86应用程序。
4)AArch64
5)小结
争论在于EM64T和AMD64是不是真正的64位处理器,Intel称其架构为"Extended Memory 64 Technology",使人容易产生这个疑问。我们知道它是IA32指令集的延伸,那么EM64T和AMD64到底是不是“真正”的64位处理器呢?答案很明确,是。当处理器执行 64位操作,具备64位寻址能力,通用寄存器和运算器宽度是64位,运算器可以处理64位数据块,因此,在此处理模式下它们完全可以被称作64位处理器。
请注意:虽然IA64,EM64T和AMD64都是64位处理器,但它们不完全兼容。
EM64T和AMD64除了很少数指令,如3DNOW以外,可以互相兼容,在其中之一上面编写和编译的应用程序通常可以全速运行在另外一个处理器上。
IA64采用了与其他两种完全不同的指令集,为Itanium2写的64位应用程序不能运行在EM64T和AMD64上,反之亦然。
CPU缓存一致性协议MESI
缓存与主存
解读缓存一致性(Cache Coherency),先看一下CPU的架构
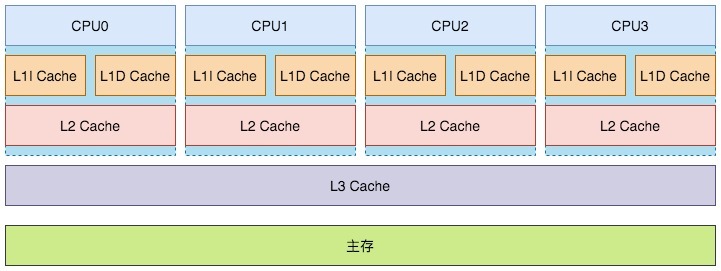
图示一个4核CPU,有三个级别的缓存,分为是L1 Cache(一级缓存)、L2 Cache(二级缓存)、L3 Cache(三级缓存)
其中一级缓存有两部分组成:L1I Cache(一级指令缓存)和L1D Cache(一级数据缓存)。
越靠近CPU的缓存速度越快,单价也更昂贵。其中一级和二级如今都属于片内缓存(在CPU核内,早期L2缓存是片外的)独立归属给各个CPU,而三级缓存是CPU间共享的。
查询缓存的时候也是由近及远,优先从一级缓存去查找,找到就结束查找,找不到则再去二级缓存查找。二级缓存找不到去三级缓存查找。三级缓存还找不到就去主存(Main Memory)查找。这里说的主存,就是我们平常说的内存。
内存是DRAM(Dynamic RAM),缓存是SRAM(Static RAM)。
缓存行
CPU操作缓存的单位是”缓存行“(cacheline),也就是说如果CPU要读一个变量x,那么其实是读变量x所在的整个缓存行。
缓存行大小
既然我们知道了CPU读写缓存的单位是缓存行,那么缓存行的大小是多少呢?
查看机器缓存行大小的方法有很多,在Linux上可以查看如下文件确认缓存行大小:
# L1D Cache
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
# L1I Cache
cat /sys/devices/system/cpu/cpu0/cache/index1/coherency_line_size
# L2 Cache
cat /sys/devices/system/cpu/cpu0/cache/index2/coherency_line_size
# L3 Cache
cat /sys/devices/system/cpu/cpu0/cache/index3/coherency_line_size
或者使用getconf命令:
# L1D Cache
getconf LEVEL1_DCACHE_LINESIZE
# L1I Cache
getconf LEVEL1_ICACHE_LINESIZE
# L2 Cache
getconf LEVEL2_CACHE_LINESIZE
# L3 Cache
getconf LEVEL3_CACHE_LINESIZE
一般会看到:64,表示的是64字节。
注意,单核CPU上,可能没有L3缓存,比如云平台的最低配云主机……
MESI
并发场景下(比如多线程)如果操作相同变量,如何保证每个核中缓存的变量是正确的值,这涉及到一些”缓存一致性“的协议。其中应用最广的就是MESI协议(当然这并不是唯一的缓存一致性协议)。
状态介绍
在缓存行的元信息中有一个Flag字段,它会表示4种状态,分为对应如下所说的M、E、S、I状态。
| 状态 | 描述 |
|---|---|
| M(Modified) | 代表该缓存行中的内容被修改了,并且该缓存行只被缓存在该CPU中。这个状态的缓存行中的数据和内存中的不一样,在未来的某个时刻它会被写入到内存中(当其他CPU要读取该缓存行的内容时。或者其他CPU要修改该缓存对应的内存中的内容时 |
| E(Exclusive) | 代表该缓存行对应内存中的内容只被该CPU缓存,其他CPU没有缓存该缓存对应内存行中的内容。这个状态的缓存行中的内容和内存中的内容一致。该缓存可以在任何其他CPU读取该缓存对应内存中的内容时变成S状态。或者本地处理器写该缓存就会变成M状态 |
| S(Shared) | 该状态意味着数据不止存在本地CPU缓存中,还存在别的CPU的缓存中。这个状态的数据和内存中的数据是一致的。当其他CPU修改该缓存行对应的内存的内容时会使该缓存行变成 I 状态 |
| I(Invalid) | 代表该缓存行中的内容是无效的 |
总线嗅探机制
CPU和内存通过总线(BUS)互通消息。
CPU感知其他CPU的行为(比如读、写某个缓存行)就是是通过嗅探(Snoop)线性中其他CPU发出的请求消息完成的,有时CPU也需要针对总线中的某些请求消息进行响应。这被称为”总线嗅探机制“。
这些消息类型分为请求消息和响应消息两大类,细分为6小类。
| 消息类型 | 请求/响应 | 描述 |
|---|---|---|
| Read | 请求 | 通知其他处理器和内存,当前处理器准备读取某个数据。该消息内包含待读取数据的内存地址 |
| Read Response | 响应 | 该消息内包含了被请求读取的数据。该消息可能是主内存返回的,也可能是其他高速缓存嗅探到Read 消息返回的 |
| Invalidate | 请求 | 通知其他处理器删除指定内存地址的数据副本(缓存行中的数据)。所谓“删除”,其实就是更新下缓存行对应的FLAG(MESI那个) |
| Invalidate Acknowledge | 响应 | 接收到Invalidate消息的处理器必须回复此消息,表示已经删除了其高速缓存内对应的数据副本 |
| Read Invalidate | 请求 | 此消息为Read 和 Invalidate消息组成的复合消息,主要是用于通知其他处理器当前处理器准备更新一个数据了,并请求其他处理器删除其高速缓存内对应的数据副本。接收到该消息的处理器必须回复Read Response 和 Invalidate Acknowledge消息 |
| Writeback | 响应 | 消息包含了需要写入内存的数据和其对应的内存地址 |
举例
假设CPU0、CPU1、CPU2、CPU3中有一个缓存行(包含变量x)都是S状态。
此时CPU1要对变量x进行写操作,这时候通过总线嗅探机制,CPU0、CPU2、CPU3中的缓存行会置为I状态(无效),然后给CPU1发响应(Invalidate Acknowledge),收到全部响应后CPU1会完成对于变量x的写操作,更新了CPU1内的缓存行为M状态,但不会同步到内存中。
接着CPU0想要对变量x执行读操作,却发现本地缓存行是I状态,就会触发CPU1去把缓存行写入(回写)到内存中,然后CPU0再去主存中同步最新的值。
Store Buffer
当然前面的描述隐藏了一些细节,比如实际CPU1在执行写操作,更新缓存行的时候,其实并不会等待其他CPU的状态都置为I状态,才去做些操作,这是一个同步行为,效率很低。当前的CPU都引入了Store Buffer(写缓存器)技术,也就是在CPU和cache之间又加了一层buffer,在CPU执行写操作时直接写StoreBuffer,然后就忙其他事去了,等其他CPU都置为I之后,CPU1才把buffer中的数据写入到缓存行中。
Invalidate Queue
看前面的描述,执行写操作的CPU1很聪明啦,引入了store buffer不等待其他CPU中的对应缓存行失效就忙别的去了。而其他CPU也不傻,实际上他们也不会真的把缓存行置为I后,才给CPU0发响应。他们会写入一个Invalidate Queue(无效化队列),还没把缓存置为I状态就发送响应了。
后续CPU会异步扫描Invalidate Queue,将缓存置为I状态。和Store Buffer不同的是,在CPU1后续读变量x的时候,会先查Store Buffer,再查缓存。而CPU0要读变量x时,则不会扫描Invalidate Queue,所以存在脏读可能。
L3 Cache在MESI中的角色
L3 缓存是所有CPU共享的一个缓存。纵观刚才描述的MESI,好像涉及的都是CPU内的缓存更新,不涉及L3缓存,那么L3缓存在MESI中扮演什么角色呢?
其实在常见的MESI的状态流程描述中,所有提到”内存“的地方都是值得商榷的。比如我上一节举的例子中,CPU0中某缓存行是I,CPU1 中是M。当CPU0想到执行local read操作时,就会触发CPU1中的缓存写入到内存中,然后CPU0从内存中取最新的缓存行。其实准确来讲这里是不准确的,因为由于L3缓存的存在,这里其实是直接从L3缓存读取缓存行,而不直接访问内存。猜测是如果描述MESI状态流转的时候引入L3缓存,会造成描述会极其复杂,所以一般的描述都好似有意地忽略了L3缓存。
英特尔本可在64位过渡中击败AMD 但却错误地选择了放弃
x86-64 指令集最初由 AMD 于 1999 年发布,为领先的 PC 计算架构提供了重大升级。 事实证明,这项技术非常成功,英特尔不得不追赶竞争对手,这在 x86 历史上尚属首次。不过事情本可以大不相同。
英特尔公司已经准备好为"经典"的 32 位 x86 ISA 添加 64 位功能的解决方案,但该公司却选择了推进 Itanium(安腾)架构。
2024年10月,一个新的技术历史片段从一年前的 Quora 讨论中浮出水面。英特尔前"首席 x86 架构师"鲍勃-科威尔提供了一个以前不为人知的精彩花絮。
AMD 工程师 Phil Park 在研究x86-64 过渡背后的历史时,发现了这段对话。科威尔透露,英特尔在奔腾 4 芯片中嵌入了一个未激活的 x86-64 ISA 内部版本。公司管理层强迫工程团队"熔断"这些功能。
功能是有了,但用户无法访问。英特尔决定把重点放在为 Itanium 开发的 64 位本地架构上,而不是 x86-64。公司认为,64 位奔腾 4 会损害 Itanium 赢得 PC 市场的机会。据称管理层"不是一次,而是两次"告诉 Colwell,如果他想保住工作,就不要再谈论 x86 上的 64 位演化。
工程师决定妥协,将与 x86-64 功能相关的逻辑门"隐藏"在硬件设计中。科尔韦尔打赌英特尔需要追赶 AMD 并迅速实现其版本的 x86-64 ISA,他猜对了。Itanium CPU 与 16 位和 32 位 x86 软件没有提供向后兼容性,因此该架构也成了英特尔历史上最糟糕的商业(和技术)失败之一。
x86-64 ISA 与"传统"x86 代码完全兼容,同时引入了新的 64 位模式,具有更强大的指令、更大的矢量寄存器等。与 32 位 CPU 相比,它还能使用更大的虚拟和物理内存池。AMD 首先通过基于 K8 的 Athlon 64 和 Opteron 芯片实现了 x86-64 指令集,这最终迫使英特尔通过改进版的 NetBurst 架构(奔腾 4)"走向 64 位"。
鲍勃-科威尔为英特尔的历史做出了重大贡献,在 2000 年退休前,他负责管理了奔腾 Pro、奔腾 II、奔腾 III 和奔腾 4 等流行 PC CPU 的开发。与此同时,今天英特尔和 AMD 在市场上销售的 x86 芯片仍然与几乎所有为 x86 架构开发的程序保持完全向后的硬件兼容性。