Postgres使用案例之通用化
 用Postgres取代一切,将一切都Postgres化
用Postgres取代一切,将一切都Postgres化PostgreSQL 不只是数据库,它已经成为一个全能平台了
UserJot站长说Postgres几乎能处理它们的一切
为什么要毅然转向PostgreSQL
PostgreSQL是一款功能强大、开源、面向对象的关系型数据库系统,具有强大的可扩展性和可靠性,适合多种开发场景。无论你是准备构建企业级应用,还是开发个人项目,PostgreSQL 都能为你提供稳定而灵活的数据库解决方案。做为一个开源的对象-关系型数据库管理系统(ORDBMS),源自于 POSTGRES 项目,最初由加州大学伯克利分校(University of California, Berkeley)开发。PostgreSQL 支持大部分 SQL 标准,并在此基础上增加了许多现代特性,比如复杂查询、外键、触发器、视图、事务完整性和多版本并发控制(MVCC)。
它广泛应用于金融、制造业、政府、地理信息系统(GIS)等领域。
发展历程
PostgreSQL 数据库的历史最早可以追溯到 1986 年,比很多现代数据库还要悠久。其最初只是加州大学伯克利分校(UC Berkeley)计算机科学系发起的一个名为 POSTGRES 的研究项目,项目负责人是著名数据库专家 Michael Stonebraker 教授。该项目旨在改进当时的 Ingres 数据库系统,并引入更多面向对象的特性和更强的事务处理能力。下面是 PostgreSQL 项目的重要发展节点:
• 1986 年:POSTGRES 项目启动,旨在探索新的数据库概念,如规则系统、对象继承等。
• 1989 年:发布第一个 POSTGRES 原型系统。
• 1994 年:项目重构为支持 SQL 查询语言,并更名为 Postgres95,增加了 SQL 支持、性能优化等改进。
• 1996 年:Postgres95 更名为 PostgreSQL,从此成为一个正式的开源数据库项目。
• 1996 年以后:PostgreSQL 社区逐步建立,吸引全球开发者参与,不断添加新特性和扩展插件。
• 2005 年以后:PostgreSQL 在企业级场景中得到广泛应用,成为 MySQL 之外最受欢迎的开源数据库系统之一。
• 近年来:PostgreSQL 已发展为支持并发控制(MVCC)、逻辑复制、JSON/JSONB 数据类型、并行查询等现代数据库特性的领先系统。
其发展离不开全球开源社区的支持。如今每个新版本的发布都由 PostgreSQL 全球开发组(PostgreSQL Global Development Group)负责协调,同时也得到了企业(如 Red Hat、Microsoft、EDB 等)的大力支持。其名字中,“PostgreSQL” 保留了对 POSTGRES 项目的致敬,而 SQL 则强调了对标准查询语言的支持。你在日常交流中也可以简称为 Postgres。
特性
PostgreSQL 提供了以下一些关键特性,使其在众多数据库系统中脱颖而出:
• 开源免费:你可以自由下载、使用和修改 PostgreSQL,无需支付许可费用。
• 跨平台支持:支持各种操作系统,包括 Linux、Windows 和 macOS。
• 标准 SQL 支持:兼容大多数 SQL 标准,支持复杂查询和联合(JOIN)操作。
• 多版本并发控制(MVCC):确保数据库的高并发性和一致性。
• 事务支持:支持 ACID(原子性、一致性、隔离性、持久性)事务。
• 完整的数据类型支持:内置如 INTEGER、VARCHAR、BOOLEAN 等数据类型,也支持用户自定义类型。
• 可扩展性强:你可以添加自定义函数(使用 C/C++、PL/pgSQL、Python、Perl 等语言),并通过插件扩展其功能。
• 丰富的索引机制:包括 B-tree、Hash、GIN、GiST 和 SP-GiST 等索引类型。
• 支持外键、视图、触发器、存储过程:帮助你构建健壮的数据逻辑层。
• 高可靠性:支持日志记录、故障恢复、并发控制等机制。
架构
PostgreSQL 的架构遵循典型的客户端-服务器模型,如下图所示:
+----------------------+
| Client |
|----------------------|
| psql / pgAdmin / ORM |
+----------+-----------+
|
v
+----------------------+
| PostgreSQL Server |
+----------+-----------+
|
+-----------------------------+-----------------------------+
| | |
v v v
+-------------+ +---------------+ +-----------------+
| Connection | <--------> | Query Engine | <--------> | Storage Engine |
| Manager | | (Parser, | | (Tables, Index, |
| (Postmaster)| | Planner, | | WAL files) |
+-------------+ | Optimizer, | +-----------------+
| Executor) |
+-------+-------+
|
v
+---------------+
| Transaction |
| Manager |
| (MVCC, Locks)|
+---------------+
图示说明:
• 客户端(Client):你可以通过各种工具连接 PostgreSQL,例如 psql 命令行、pgAdmin 图形界面,或者使用程序代码(如 Python、Java、Node.js)与服务器通信。
• 服务器(Server):负责处理来自客户端的请求,并执行相应的数据库操作。
• 连接管理器(Connection Manager / Postmaster):负责接受来自客户端的连接请求,创建独立的后端进程或线程来处理每个连接。
• 查询引擎(Query Engine):包括 SQL 的解析器(Parser)、查询规划器(Planner)、优化器(Optimizer)以及执行器(Executor),负责将 SQL 转换为数据库内部操作。
• 事务管理器(Transaction Manager):处理事务的原子性、隔离性等特性,内部采用 MVCC(多版本并发控制)机制,并负责锁管理。
• 存储引擎(Storage Engine):实际负责数据的存储与读取,管理表、索引、写前日志(WAL)等物理文件。
优缺点
选择 PostgreSQL 的理由有很多,以下是它的一些显著优点:
• 免费开源,社区活跃
• 高度稳定,适合生产环境
• 支持 NoSQL 特性(如 JSON、HSTORE)
• 高度可定制和可扩展
• 丰富的文档和开发工具支持
尽管其功能强大,但它也存在一些不足:
• 相比某些专有数据库,学习曲线可能稍陡峭
• 默认配置下性能可能不如某些为特定场景优化过的数据库
• 对于大数据量下的写入密集型场景,调优工作较复杂
应用场景
PostgreSQL 在多个领域都有广泛应用,包括但不限于:
• Web 应用开发:与 Python(Django)、Node.js、Ruby on Rails 等框架良好集成
• 地理信息系统(GIS):通过 PostGIS 插件增强空间数据支持
• 数据仓库:支持复杂查询和大数据量分析
• 金融、电商系统:需要事务一致性和高并发处理能力的系统
用Postgres取代一切,将一切都Postgres化
曾经流传已久的小而美的架构思想已经被到处卷的现代IT给抛弃了。系统变得越来越大,分系统越来越多,架构越来与复杂,出现问题排查越来越难。那么回归简单不好么?关键是怎么实现成了一个问题,在此介绍一个以PostgreSQL为基础的,简化堆栈、减少移动部件、加快开发速度、降低风险并的方法,那就是“用Postgres取代一切”!这种方法特别适合一些刚刚开始的初创公司和还在探索优化架构的那些组织。
简单来说就是用Postgres取代几乎所有的后端数据库和数据缓存层,其中包括Kafka、RabbitMQ、Mongo和Redis。这可以让每个应用程序都更易于开发、扩展和操作。移动部件较少可以让开发人员把精力和时间不要放在这些不提供价值或仅复制现有功能(前端)的部件上,而为把精力和时间都卷在全力为客户提供价值的部件上来。
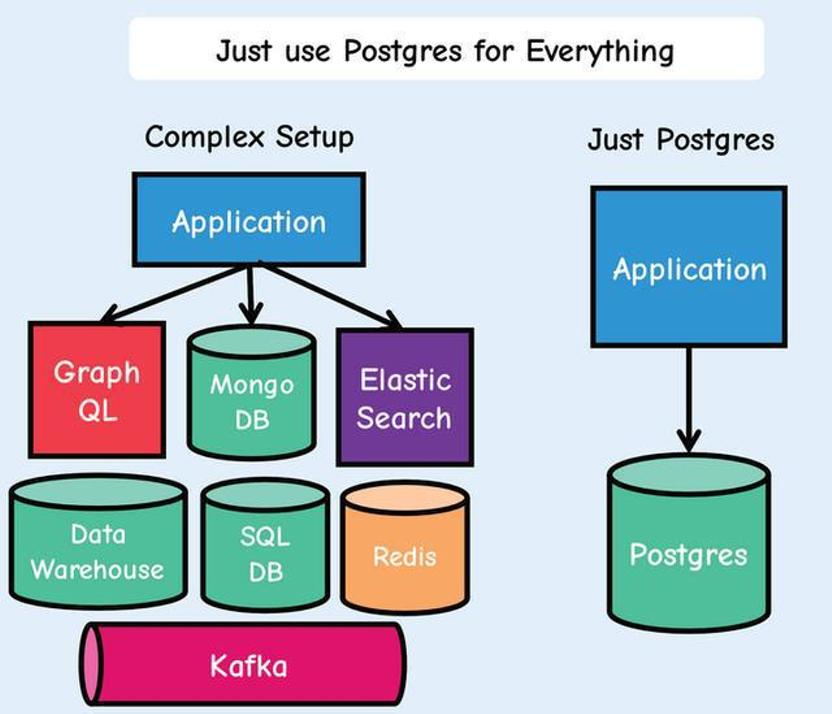
概述
一切都使用Postgres!
使用Postgres代替Redis进行缓存,并使用UNLOGGED表和TEXT作为Json数据类型。使用存储过程或使用ChatGPT为编写它们,为数据添加和强制执行到期日期,就像在Redis中一样。
使用Postgres 作为cron在特定时间执行操作,例如发送邮件,并使用pg_cron将事件添加到消息队列。消息队列使用Postgres的SKIP LOCKED来是先,而不用Kafka。或者可以用Golang的River作业队列。
Postgres Timescale作为数据仓库。
Postgres pg_analytics结合Apache Datafusion使用作为内存OLAP,可以实现高性能查询。
Postgres使用带有JSONB将JSON文档存储在数据库中,对它们进行搜索和索引,而不用Mongo。
使用Postgres进行地理空间查询。
使用Postgres代替Elastic进行全文搜索。
使用Postgres在数据库中生成JSON,无需编写服务器端代码,直接交给API。
使用Postgres进行pgaudit审计
如果需要,将Postgres与 GraphQL适配器结合使用来提供GraphQL。
一切都使用Postgres!
数据缓存
在Postgres中可以使用缓存表,来做为数据缓存:
CREATE UNLOGGED TABLE cache (id serial PRIMARY KEY,key text UNIQUE NOT NULL,value jsonb,inserted_at timestamp);CREATE INDEX idx_cache_key ON cache (key);
与普通表的唯一区别是UNLOGGED关键词。至于列,使用的是JSONB值,但可以使用任何适合需要的值,例如text, varchar或者hstore。还包括inserted_at列,该列将用于缓存失效。还创建一个索引以获得更好的读取性能。
当然缓存服务应该具有的功能应该包括:缓存条目的过期。在PostgreSQL中可以通过创建一个定期删除旧行的存储过程:
CREATE OR REPLACE PROCEDURE expire_rows (retention_period INTERVAL) ASBEGINDELETE FROM cacheWHERE inserted_at < NOW() - retention_period;COMMIT;$$ LANGUAGE plpgsql;CALL expire_rows('60 minutes');-- This will remove rows older than 1 hour
为了定期调用这个expire_rows程序。可以使用PostgreSQL的另一个大法宝pg_cron。
可以通过以下方式安排过程调用:
-- 创建一条每小时执行的定期任务SELECT cron.schedule('0 * * * *', $$CALL expire_rows('1 hour');$$);
如果不想为此安装扩展,那么也可以编写一个每次插入行时运行的触发器:
CREATE OR REPLACE FUNCTION expire_rows_func (retention_hours integer) RETURNS void ASBEGINDELETE FROM cacheWHERE inserted_at < NOW() - (retention_hours || ' hours')::interval;$$ LANGUAGE plpgsql;CREATE OR REPLACE FUNCTION expire_rows_func_trigger() RETURNS trigger ASBEGINPERFORM expire_rows_func (1);RETURN NEW;$$ LANGUAGE plpgsql;CREATE TRIGGER cache_cleanup_triggerAFTER INSERT ON cacheFOR EACH ROWEXECUTE FUNCTION expire_rows_func_trigger();
显然,实际的到期/清除时间表取决于数据和用例。
作业调度
用Redis做为数据缓存层或者用于协调后台作业队列(以及一些有限的原子操作)是现代架构中常见的方式,但是实际上这些都可以使用PostgreSQL来实现,且效率比Redis更好。
作业调度
Redis最常见的用途是协调从Web服务到后台程序池的作业调度。比如希望记录执行某些后台作业的愿望(可能需要一些输入数据),并确保只有众多后台工作人员之一会接手它。Redis对此有所帮助,因为它为其数据结构提供了一组丰富的原子操作。
PostgreSQL 9.5中新发布了一个功能SKIP LOCKED选项为SELECT ... FOR ...。当指定此选项时,PostgreSQL将忽略任何需要等待锁释放的行。
从后台工作者的角度考虑这个例子:

通过指定FOR UPDATE SKIP LOCKED,对于从返回的任何行隐式获取行级锁 SELECT。此外,因为指定SKIP LOCKED,该语句不可能阻塞另一个事务。如果还有其他作业可供处理,则会返回该作业。由于行级锁,不必担心运行此命令的多个工作程序会接收同一行。
应用程序锁
假设有一个与第三方服务的同步例程,并且只希望在所有服务器进程中为任何给定用户运行该例程的一个实例。这是Redis另一个常见应用:分布式锁定。
PostgreSQL也可以使用其咨询锁来实现这一点。建议锁允许利用PostgreSQL 内部使用的相同锁定引擎来实现自己的应用程序定义的目的。
发布/订阅
例如,假设需要通知用户有一条新消息可供阅读。或者可能希望在数据可用时将数据流式传输到客户端。通常Web套接字是这些事件的传输层,而Redis则充当发布/订阅引擎。
从PostgreSQL 9开始开始支持LISTEN和NOTIFY声明。任何PostgreSQL客户端都可以订阅(LISTEN)到特定的消息通道,它只是一个任意字符串。当任何其他客户端发送消息时(NOTIFY)在该频道上,所有其他订阅的客户端都将收到通知。或者,可以附加一条小消息。对于使用Rails和ActionCable的通许,可以直接调用PostgreSQL替换。
TimescaleDB
TimescaleDB构建在PostgreSQL之上的时间序列数据库。它旨在处理大量带有时间戳的数据,并为时间序列数据提供高效且可扩展的查询性能。它针对存储和查询时间序列数据进行了优化,扩展了PostgreSQL,提供专门针对时间序列数据管理的附加特性和功能,例如自动时间分区、优化索引和压缩。
TimescaleDB采用分布式超表架构,根据时间间隔对数据进行分区,从而能够随着时间的推移高效查询大量数据。它还为时间序列数据提供高级分析和可视化功能,包括连续聚合和窗口函数。
pg_analytics
pg_analytics是个用于加速Postgres分析性能的扩展,安装pg_analytics Postgres可实现比Elasticsearch快8倍的性能。pg_analytics直接在Postgres 内加速分析查询,pg_analytics是Postgres中分析的嵌入式解决方案,无需提取、转换和将(ETL)数据加载到另一个系统中。
常规Postgres表(称为堆表)按行组织数据。虽然这对于操作来说是有意义的数据,对于分析查询来说效率低下,分析查询通常从数据的子集中扫描大量数据表中的列。ParadeDB引入了一种新的表,称为parquet表。parquet表的行为与常规Postgres表类似但通过Apache Arrow使用面向列的布局并利用 Apache DataFusion 对面向列的数据进行了优化。这意味着用户可以在面向行和列的存储之间进行选择表创建时间。
Arrow和Datafusion通过Postgres API的两个功能与Postgres集成:表访问方法和执行器hook。表访问方法寄存器parquet带有Postgres目录的表并处理数据操作语言 (DML) 语句,例如插入。执行器hooks拦截查询并将其重新路由到 DataFusion,它解析查询,构建最佳查询计划,执行它,并将结果返回到 Postgres。
数据使用Parquet格式持久保存到磁盘,这是一种用于面向列的数据的高度压缩文件格式。Parquet、ParadeDB 压缩数据的能力是常规Postgres和Elasticsearch的5倍。
CREATE EXTENSION pg_analytics;-- 创建一个parquet表CREATE TABLE t (a int) USING parquet;INSERT INTO t VALUES (1), (2), (3);SELECT COUNT(*) FROM t;
JSONB

PostgreSQL中支持JSON 列类型——JSONB。它允许JSON对象直接存储在表的行中。
CREATE TABLE cc_jsonb (id serial NOT NULL PRIMARY KEY,data jsonbINSERT INTO cc_jsonb (data) VALUES ('{"name": "CC", "count": 12, "Date": "2024-07-09T12:14:01", "extra": "some text"}');INSERT INTO cc_jsonb (data) VALUES ('{"name": "DD", "count": 23, "Date": "2024-07-09T15:17:01"}');SELECT data->>'name', data->>'Date' FROM cc_jsonb WHERE (data->'count')::int > 12
将JSON文档添加到PostgreSQL表仅比将文档添加到MongoDB集合稍微复杂一些,PostgreSQL需要使用CREATE TABLE语句来先创建文档的目标。
在查询JSON文档中的数据时,MongoDB提供了两种方法:用于简单查询的find和aggregate用于更复杂情况的。
在PostgreSQL中,可以使用SQL语法来执行MongoDB中需要聚合框架的连接和分组操作,SQL语法更直观、更高效。
在PostgreSQL中,可以创建一个“GIN”(通用倒排索引)索引来索引JSONB对象中的所有属性,或者可以使用“表达式”索引来在特定JSONB元素上创建索引:
CREATE INDEX ccjsonb_path_ops_idx ON cc_jsonb USING GIN (data jsonb_path_ops);SELECT * FROM cc_jsonb WHERE data @> '{"name":"First"}'::jsonbSELECT * FROM cc_jsonb WHERE data @@ '$.count > 15'
修改JSON文档时,MongoDB 提供了许多运算符,允许更新文档中的特定元素。在PostgreSQL中,可以将值设置或附加到JSONB中的现有元素,但对于任何重要的事情,可能需要选择整个JSONB,在应用程序代码中对其进行操作,然后使用新对象更新JSONB列。
PostgreSQL拥有许多MongoDB中所没有的高级功能。SQL方言实际上比MongoDB支持的SQL领先数十年,事务支持明显更加成熟,并且对语句级并行性和高级索引选项的支持也很有吸引力。
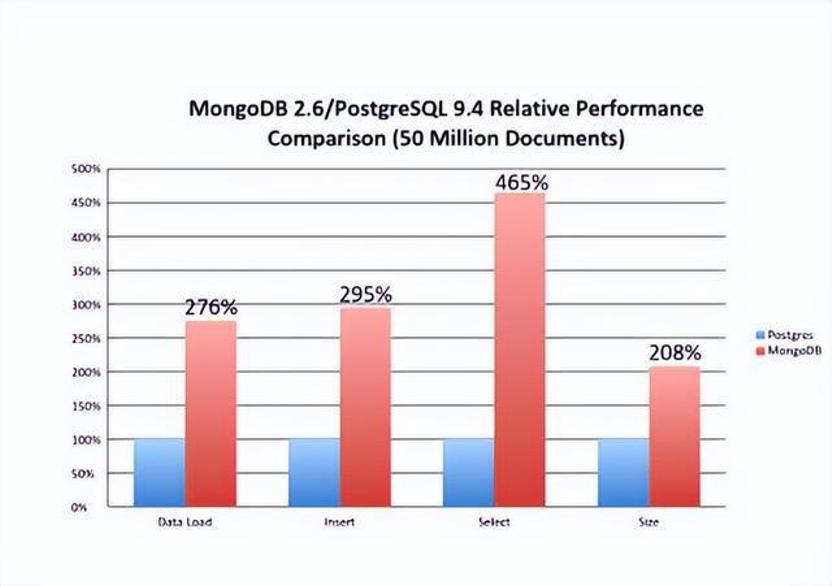
在性能方面持续有来和MongoDB的基准测试,基于一些案例PostgreSQL性能要高4倍以上。
全文搜索
在很多架构中,需要借助第三方的像Solr和ElasticSearch,不光架构复杂,还需要处理分词、索引和查询方面的事情。而使用Postgres中全文搜索可是自带的标配。许多项目都可以很好地使用 Postgres 全文搜索和其他内置扩展,例如三元组搜索(pg_trgm)。
假设有个电影表movies,其结构如下:
create table movies (id bigint primary key generated by default as identity,title text not null,original_title text not null,overview text not null,created_at timestamptz not null default now());
给其增加一个字段用户存储全文关键字:
add column fts_doc_engenerated always as to_tsvector ('english', title || ' ' || original_title || ' ' || overview) stored;
然后再创建一个GIN索引加速搜索:
create index movies_fts_doc_en_idxon moviesusing gin (fts_doc_en);
Postgres全文搜索支持更多的功能,例如对搜索结果进行排名的功能,限于篇幅此处只是简单地使用演示:
select * from movies where doc_en @@ websearch_to_tsquery('english', 'Avengers');
小结
限于篇幅,本节只能列举一些常见的且已经被广泛证明了Postgres可以做得很多好的功能,当然还有更多部分也值得探索,可以参考Postgres文档,以后有机会也可以分功能详细进行介绍。
PostgreSQL 不只是数据库,它已经成为一个全能平台了
Postgres正演变成一个功能全面的平台:能力覆盖搜索引擎、实时应用、消息队列、数据仓库,甚至在某些场景下,能替代微服务架构。一起来看看。
插件系统很厉害
过去总是根据具体需求挑选不同数据库:
全文搜索用 ElasticSearch
缓存靠 Redis
消息传递上 RabbitMQ
灵活存 JSON 选 MongoDB
分析任务交给 ClickHouse 或 BigQuery
但现在的情况变了。
Postgres 一库通吃 —— 原生支持、稳定可靠且只需维护一个统一运维面。这得益于它强大的扩展能力,比如:
pgvector:支持向量相似度搜索(没错,就是类似 OpenAI 用来做嵌入的那种)
PostGIS:用于地理空间查询(Uber 用的就是它)
pgmq:内置持久队列(RabbitMQ 是时候退役了吗?)
timescaledb:专为时序数据优化的存储
citext、hstore、ltree:支持灵活“类结构”数据模型
用 Postgres 写 SQL,不再只是写查询语句——是在用一个统一核心,构建多模态应用系统。
它还能玩 JSON呢。其对 JSONB 的支持非常成熟,这意味着:
想存半结构化数据,不用 Mongo 也行
JSON 字段可以像普通列一样建立索引
深层嵌套字段查询起来也非常高效
举个例子你就明白了:
SELECT data->'user'->>'email'
FROM orders
WHERE data->'user'->>'country' = 'China';
Postgres 对 JSON 的处理不只是备选方案,在许多场景下比传统 NoSQL 更快、更安全,也更易用。
Postgres 还能做事件存储?
现通过像 pgmq 这样的扩展,或采用一些经典模式,可以把 Postgres 打造成消息队列或事件日志系统:
用 Outbox 表 + 轮询机制
用逻辑复制槽(Logical Replication Slots)实现变更监听
利用 NOTIFY / LISTEN 构建发布-订阅模型
换言之,原本可能需要 Kafka + Redis + Postgres 三套系统配合,现只用 Postgres 一个系统就能:写数据、发布事件、保证事务一致性。
少了组件,少了依赖,也就少了出故障的可能。
下面的 Postgres 平台化架构图可以助力理解,假设有一张文本版的 UML 组件图,清晰可读、结构简洁:
+------------------+
| Clients |
+------------------+
|
v
+---------------------------+
| API Server |
+---------------------------+
|
v
+---------------------------+
| PostgreSQL DB |
|---------------------------|
| Tables (relational) |
| JSONB Docs |
| Vector Store (pgvector) |
| Queue (pgmq) |
| Geospatial (PostGIS) |
| Time-series (Timescale) |
+---------------------------+
重点不是概念,而是实践。市面上已经有不少产品基于这种架构上线 —— 经过实战验证,稳定、可靠、易维护。
Postgres用于做数据分析也是可以的。得益于列式扩展(比如 cstore_fdw 和 TimescaleDB),可以:
存储 OLAP 风格的数据
快速处理上百万行聚合查询
用你熟悉的 SQL 做分析
甚至无需把数据管道接入 Snowflake 或 Redshift,直接用 Postgres 驱动仪表盘、可视化图表、BI 工具也没问题。而且还没说到它的高级特性,比如物化视图、后台处理线程,甚至可以用 Rust、Python、JavaScript 写自定义函数。
这对开发者有什么重大意义
因为 Postgres 正在变成后端世界的“操作系统”。它的价值不只是“数据库”,而是让你的系统更简单、更一致、更可控。
你只需要监控一个系统
事务处理天然一致
网络通信更少,系统连线更少
SQL 工具链统一、成熟
本地开发部署简单
由于省去了中间 glue code,Bug 也更少
这不是对Postgres的盲目崇拜,而是工程层面的理性选择:简洁、更安全、还能扩展。
小结:
Postgres早就不是那个“只管存表”的数据库了。它已经能胜任搜索引擎、聊天应用、地理位置系统、推荐系统,甚至事件驱动架构的核心平台。
原本要靠五六个工具拼出的系统,现在一个 Postgres 全搞定 —— 用更少的基础设施、更强的一致性保障、还有几十年积累下来的稳定性。所以在准备拉起六个微服务、再加几个队列来打通它们之前,先考虑一下Postgres。
UserJot站长说Postgres几乎能处理它们的一切
一些独立开发者和创业公司创始人疯狂地拼凑技术栈,用Redis做缓存,RabbitMQ做队列,Elasticsearch做搜索,还有MongoDB,为什么呢?
事实证明对这个显而易见的问题避而不谈:
Postgres几乎可以做到这一切;它的效果比你想象的还要好。
1、“Postgres 无法扩展”的谬论正在让人损失金钱
你肯定听说过 Postgres“只是个关系型数据库”,需要专门的工具来完成特定的任务。我以前也是这么想的,直到发现Instagram仅用一个Postgres实例就能支持1400万用户;Discord可以处理数十亿条消息;Notion整个产品都是基于 Postgres开发的。
但关键在于:其使用Postgres的方式已经和2005年不一样了。
2、排队系统
别再为Redis和RabbitMQ付费了。Postgres原生支持 LISTEN/NOTIFY 且比大多数专用解决方案更能处理消息队列:
-- Simple job queue in pure Postgres
CREATE TABLE job_queue (
id SERIAL PRIMARY KEY,
job_type VARCHAR(50),
payload JSONB,
status VARCHAR(20) DEFAULT 'pending',
created_at TIMESTAMP DEFAULT NOW(),
processed_at TIMESTAMP
);
-- ACID-compliant job processing
BEGIN;
UPDATE job_queue
SET status = 'processing', processed_at = NOW()
WHERE id = (
SELECT id FROM job_queue
WHERE status = 'pending'
ORDER BY created_at
FOR UPDATE SKIP LOCKED
LIMIT 1
)
RETURNING *;
COMMIT;
这样就能实现精确一次处理,而且无需任何额外的基础设施。如果试着用Redis实现这一点会让人抓狂的。
在 UserJot 中使用这种模式来处理反馈提交、发送通知和更新路线图项目。只需一次事务,就能保证数据一致性,而且无需消息代理,也能降低复杂性。
3、键值存储
Redis在大多数平台上最低每月收费 20 美元。Postgres的JSONB功能已包含在现有的数据库中,可以满足大部分需求:
-- Your Redis alternative
CREATE TABLE kv_store (
key VARCHAR(255) PRIMARY KEY,
value JSONB,
expires_at TIMESTAMP
);
-- GIN index for blazing fast JSON queries
CREATE INDEX idx_kv_value ON kv_store USING GIN (value);
-- Query nested JSON faster than most NoSQL databases
SELECT * FROM kv_store
WHERE value @> '{"user_id": 12345}';
该@>操作符是 Postgres 的秘密武器。它比大多数 NoSQL 查询速度更快,而且能保持数据一致性。
4、全文检索
Elasticsearch 集群成本高昂且复杂,而Postgres内置的全文搜索功能非常出色:
-- Add search to any table
ALTER TABLE posts ADD COLUMN search_vector tsvector;
-- Auto-update search index
CREATE OR REPLACE FUNCTION update_search_vector() RETURNS trigger AS $$
BEGIN
NEW.search_vector := to_tsvector('english', COALESCE(NEW.title, '') || ' ' || COALESCE(NEW.content, ''));
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
-- Ranked search results
SELECT title, ts_rank(search_vector, query) as rank
FROM posts, to_tsquery('startup & postgres') query
WHERE search_vector @@ query
ORDER BY rank DESC;
它开箱即用,支持模糊匹配、词干提取和相关性排序。在UserJot的反馈搜索功能中,用户可立即通过标题、描述和评论中找到所需的功能请求,无需Elasticsearch集群,纯粹依靠Postgres发挥其核心优势即可实现。
5、实时功能
抛开复杂的 WebSocket 架构,Postgres 的 LISTEN/NOTIFY机制可为你提供实时更新,无需任何额外服务:
-- Notify clients of changes
CREATE OR REPLACE FUNCTION notify_changes() RETURNS trigger AS $$
BEGIN
PERFORM pg_notify('table_changes', json_build_object(
'table', TG_TABLE_NAME,
'action', TG_OP,
'data', row_to_json(NEW)
)::text);
RETURN NEW;
END;
LANGUAGE plpgsql;
应用程序会监听这些通知,并将更新推送给用户,不需要使用Redis发布或者订阅模式。
6、“专业化”工具的隐性成本
来算笔账,一个典型的“现代”堆栈的成本是:
Redis:每月20美元
消息队列:每月25美元
搜索服务:每月50美元
3项服务的监控费用:每月30美元,总计:每月125美元。但这只是主机托管费用,真正的痛点在于:
1)、运营费用
三项不同的服务需监控、更新和调试
不同的扩展模式和故障模式
维护多种配置
独立的备份和灾难恢复程序
每项服务的安全考虑因素各不相同
2)、开发复杂性
不同的客户端库和连接模式
协调跨多个服务的部署
系统间数据不一致
复杂的测试场景
不同的性能调优方法
如果你选择自建服务器,那么还需进行服务器管理、安全补丁,以及在Redis占用全部内存时不得不在凌晨3点进行调试。但Postgres通过单一服务即可处理所有这些事务,该服务本就在你的管理范围内。
7、可扩展的单一数据库
大多数人可能没有意识到:单个Postgres实例就能处理海量数据。我们说的是每天数百万笔交易、数 TB 的数据以及数千个并发连接。实际案例:
Airbnb:单个Postgres集群处理数百万笔预订
Robinhood:数十亿笔金融交易
GitLab:基于Postgres的完整DevOps平台
Postgres的魅力在于其架构,它具备极强的垂直扩展能力,而当你最终需要水平扩展时,也有很多成熟的方案可选择,例如:
读取副本以进行查询扩展
分区处理大型表
连接池实现并发
分布式架构的逻辑复制
大多数企业永远不会遇到这些限制。除非你需要处理数百万用户或复杂的分析工作负载,否则单个实例可能就足够了。相比之下,管理那些扩展能力不一的独立服务则截然不同:你的Redis可能内存已达上限,消息队列可能吞吐量不足,而搜索服务则需要完全不同的硬件配置。
8、从一开始就停止过度设计
现代开发的最大陷阱,莫过于架构空想。我们总在为尚未出现的问题设计系统,针对从未遇到的流量做方案,为可能永远达不到的规模做准备。
1)、过度设计循环
1)“或许有一天需要扩大规模”;
2)添加 Redis、队列、微服务和多个数据库;
3)花费数月时间调试集成问题;
4)面向47位用户发布;
5)每月支付200美元购买的基础设施,其实只需一台5美元的VPS就能运行;
与此同时,你的竞争对手交付速度更快。因为他们不会在真正需要分布式系统之前就盲目投入精力去搭建和维护它。
2)、更好的方法
1)从Postgres开始,简单起步;
2)监控实际存在的瓶颈,而不是臆想出来的瓶颈;
3)当达到实际限制时,调整特定组件的规模;
4)仅在方案能解决实际问题时,才引入复杂设计。
你的用户并不关心你的架构,他们只关心你的产品是否好用,能否解决他们的问题。
9、当你真正需要专用工具时
专用工具自有其用处,但可能只有出现以下情况才用到它们:
每分钟处理超过10万个作业;
需要亚毫秒级的缓存响应;
正在对TB级的数据进行复杂的分析;
拥有数百万并发用户;
需要满足特定一致性要求的全球数据分发。
10、为什么这真的很重要
最让人震惊的是:Postgres 可以同时作为主数据库、缓存、队列、搜索引擎和实时系统,而且还能在所有组件间保持ACID事务。
-- One transaction, multiple operations
BEGIN;
INSERT INTO users (email) VALUES ('user@example.com');
INSERT INTO job_queue (job_type, payload) VALUES ('send_welcome_email', '{"user_id": 123}');
UPDATE kv_store SET value = '{"last_signup": "2024-01-15"}' WHERE key = 'stats';
COMMIT;
试试在 Redis、RabbitMQ 和 Elasticsearch 之间执行这样的操作,看你能不能不崩溃。
11、无聊的技术却能获胜
Postgres并不引人注目,它既没有花里胡哨的官网,也没有像TikTok那样爆红的平台。但数十年来,当其他数据库不断迭代更替时,它始终在背后默默支撑着互联网的运转。
选择这类朴实可靠、能稳定落地的技术,本身就很有讲究。
12、下一个项目的行动步骤
1. 先只使用 Postgres开始:不要急于添加其他数据库;
2. 使用 JSONB 实现灵活性:既能享受无模式的优势,又能拥有SQL的强大功能;
3. 在 Postgres 中实现队列:节省成本并降低复杂性;
4. 真正遇到瓶颈时才添加专用工具:注意,不是想象中的瓶颈。
13、真实经历
UserJot 的开发正是对这一理念的完美检验。作为一款反馈与路线图工具,它需要:
提交反馈后实时更新;
对数千个功能请求进行全文搜索;
用于发送通知的后台任务;
为频繁访问的路线图提供缓存;
存储用户偏好和设置的键值存储。
整个后端仅由单个Postgres数据库构成。没有Redis,没有Elasticsearch,也没有消息队列。从用户身份验证到实时WebSocket通知,一切都由Postgres处理。结果如何?可以更快地发布功能,需要调试的组件更少,基础设施成本也降到了最低。所有底层工作都由Postgres完成:用户提交反馈、搜索功能或获取路线图变更的实时更新。
这早已不是纸上谈兵,而是承载着真实用户与业务数据,稳定运行于生产和环境。
14、令人意外的结论
Postgres或许过于优秀反而成了负担。它功能如此强大,以至于让其他数据库在90%的应用场景中显得多余。行业惯例让人相信每件事都需要专用工具,但或许只是把事情搞得比实际更复杂。
初创公司不需要成为分布式系统的展示平台,它需要解决真实用户面临的实际问题。Postgres让你能够专注于此,而不是一直在维护基础设施。所以下次如果有人提议添加Redis"提升性能"或添加MongoDB"增强灵活性"时,不妨反问:"你是否尝试过先用Postgres实现?"
答案或许会让人惊讶。应用完全构建在Postgres之上时也感到非常意外,而它至今运行得无比顺畅。
为什么要毅然转向PostgreSQL
MySQL老兵"真香"的数据库之PostgreSQL。
痛点一:JSON支持?MySQL真的"太糙了"
可能说:MySQL 5.7不是也支持JSON吗?
是的,但那更像是个"贴牌货"。
-- MySQL: 想查询JSON里的某个字段?只能这样
SELECT * FROM users WHERE JSON_EXTRACT(profile, '$.age') > 25;
-- PostgreSQL: 直接当普通字段用!
SELECT * FROM users WHERE profile->>'age' > '25';
PostgreSQL的JSONB是二进制存储,查询速度快10倍以上,还支持索引!这意味着你不需要为每个JSON字段单独建表了。
痛点二:复杂查询?MySQL表示"臣妾做不到"
有没有遇到过这种情况:
想做递归查询(比如查组织架构树),MySQL要写一堆存储过程
想做全文检索,MySQL的中文支持"一言难尽"
想做窗口函数统计,MySQL 8.0之前直接报错
PostgreSQL原生支持递归查询(WITH RECURSIVE)、全文检索、窗口函数、物化视图... 这些功能不是"后来加的",而是"原生就有"!
痛点三:扩展性?PostgreSQL简直是"数据库界的乐高"
敢信数据库还能装"插件"吗?
PostGIS:让数据库秒变"地图引擎",支持空间查询
pg_trgm:模糊搜索神器,"张三"能搜出"张山"
TimescaleDB:时序数据场景,性能吊打InfluxDB
Citus:一键把PostgreSQL变成分布式数据库
这不是"功能多",这是"生态强"!
底层逻辑:为什么PostgreSQL更强
用一个比喻来解释:
MySQL像是一辆卡罗拉——可靠、省油、好上手,但你想改个涡轮增压?抱歉,发动机舱塞不下。
PostgreSQL像是一辆改装版的保时捷911——性能强悍、可玩性高,而且官方就给你留好了改装接口!
技术层面的核心差异:
| 特性 | MySQL | PostgreSQL |
| 存储过程 | 简单的SQL | 支持Python、Perl等多语言 |
| 事务隔离 | 基于MVCC | 真正的MVCC,无回滚段 |
| 并发控制 | 表锁/行锁 | MVCC + 多种锁粒度 |
| 数据类型 | 基础类型 | JSONB、数组、几何、自定义... |
| 索引种类 | B-Tree、Hash | B-Tree、Hash、GIN、GiST、SP-GiST... |
GIN索引(通用倒排索引)是PostgreSQL的秘密武器,让JSON、数组、全文检索的查询速度直接起飞!
实操SOP:MySQL到PostgreSQL的"无痛迁移"三步走
第一步:安装与基本配置(10分钟搞定)
macOS(最简单):
brew install postgresql@16
brew services start postgresql@16
Ubuntu/Debian:
sudo apt update
sudo apt install postgresql postgresql-contrib
sudo systemctl start postgresql
初始化连接:
# 切换到postgres用户
sudo -u postgres psql
# 创建自己的用户和数据库
CREATE USER myuser WITH PASSWORD 'mypassword';
CREATE DATABASE mydb OWNER myuser;
GRANT ALL PRIVILEGES ON DATABASE mydb TO myuser;
第二步:核心语法对照表(收藏这个就够了)
作为MySQL老手只需要掌握这些"思维转换":
1. 字符串引号——最容易踩的坑
-- MySQL:双引号单引号都行
SELECT * FROM users WHERE name = "张三";
-- PostgreSQL:严格区分!字符串必须单引号,双引号是标识符
SELECT * FROM users WHERE name = '张三'; -- 正确
SELECT * FROM users WHERE name = "张三"; -- 报错!
2. 自增主键——从AUTO_INCREMENT到SERIAL
-- MySQL
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100)
);
-- PostgreSQL
CREATE TABLE users (
id SERIAL PRIMARY KEY, -- 或 BIGSERIAL
name VARCHAR(100)
);
-- 更推荐的新写法(PostgreSQL 10+)
CREATE TABLE users (
id INT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
name VARCHAR(100)
);
3. LIMIT OFFSET——这个不需要改
好消息!这个语法完全一样:
SELECT * FROM users LIMIT 10 OFFSET 20; -- 两个数据库通用
4. 反引号变双引号——IDE自动补全要注意
-- MySQL:用反引号包裹表名/字段名
SELECT `name`, `age` FROM `users`;
-- PostgreSQL:用双引号(通常不需要写)
SELECT "name", "age" FROM "users";
-- 推荐:直接不写,PostgreSQL会自动转小写
SELECT name, age FROM users;
5. 时间函数——完全不同的体系
-- MySQL
SELECT NOW(), DATE_FORMAT(NOW(), '%Y-%m-%d');
SELECT DATE_ADD(NOW(), INTERVAL 7 DAY);
-- PostgreSQL
SELECT NOW(), TO_CHAR(NOW(), 'YYYY-MM-DD');
SELECT NOW() + INTERVAL '7 days';
-- 获取当前日期(不含时间)
-- MySQL: CURDATE()
-- PostgreSQL: CURRENT_DATE
6. GROUP BY——PostgreSQL更严格
-- MySQL(宽松模式,可能返回不确定结果)
SELECT name, age, COUNT(*) FROM users GROUP BY name;
-- PostgreSQL(严格模式,必须包含所有非聚合字段)
SELECT name, age, COUNT(*) FROM users GROUP BY name, age;
第三步:数据迁移实战(含避坑指南)
方案一:使用pgLoader(自动化迁移神器)
# 安装
sudo apt install pgloader # Ubuntu
brew install pgloader # macOS
# 执行迁移
pgloader mysql://user:pass@localhost/mydb \
postgresql://user:pass@localhost/mydb
方案二:手动迁移(更可控)
# 1. 从MySQL导出数据
mysqldump -u root -p --no-create-info --complete-insert \
--skip-extended-insert mydb > data.sql
# 2. 转换语法(可以用在线工具或脚本)
# 主要替换:ENGINE=InnoDB → 删掉
# AUTO_INCREMENT=x → 删掉
# ` → "
# 3. 导入PostgreSQL
psql -U myuser -d mydb -f data.sql
避坑指南(踩过的3个坑):
编码问题:确保MySQL是UTF-8,PostgreSQL默认是UTF8
布尔类型:MySQL的tinyint(1)会变成PostgreSQL的boolean
时间精度:MySQL的DATETIME精度不同,注意时区设置
真实案例:我的迁移数据对比
曾把一个日活10万的SaaS产品从MySQL迁移到PostgreSQL,数据量约500GB:
| 指标 | 迁移前(MySQL 8.0) | 迁移后(PostgreSQL 16) | 提升 |
| JSON查询响应 | 2.3秒 | 0.15秒 | 93%↓ |
| 复杂关联查询 | 8.5秒 | 1.2秒 | 86%↓ |
| 全文检索 | 需引入ES | 原生支持 | 成本-50% |
| 存储空间 | 520GB | 410GB | 21%↓ |
| 运维复杂度 | 中 | 低 | 心力-30% |
最让人意外的是:迁移后存储空间反而少了20%+,这是因为PostgreSQL的压缩算法更优。
30天PostgreSQL学习路线
如果决定"叛变",这是我总结的学习路径:
第1-7天:基础语法适应
每天写5个SELECT,强制不用MySQL语法
重点练习:时间函数、字符串处理、类型转换
第8-14天:进阶功能探索
学习JSONB操作符:-> ->> @> ?
尝试窗口函数:ROW_NUMBER() RANK() LAG()
玩转CTE(WITH语句):让复杂查询变清晰
第15-21天:性能优化实战
理解EXPLAIN ANALYZE输出
学习不同索引的使用场景
配置调优:shared_buffers work_mem effective_cache_size
第22-30天:生态插件探索
安装PostGIS,玩一下空间查询
用pg_stat_statements分析慢查询
尝试pgAdmin 4或DBeaver作为GUI工具
写在最后
技术选型没有绝对的"最好",只有"更适合"。如果项目是简单的CRUD,团队都是MySQL老手,那没必要强行迁移。
但如果场景涉及:
复杂的JSON数据存储和查询
地理位置相关功能
需要全文检索但不想引入ES
有复杂的分析型查询需求
PostgreSQL绝对值得你花时间学习。迁移的过程会有阵痛,但相信——当你第一次用GIN索引让一个10秒的JSON查询变成0.1秒时,会觉得一切都值了。