时序流式关系数据库-TimescaleDB
 TimescaleDB 是基于 PostgreSQL 数据库开发的一款时序数据库,以插件化的形式提供(打包为扩展程序),随着 PostgreSQL 的版本升级而升级,不会因为另立分支带来麻烦。数据自动按时间和空间分片(chunk),是唯一一个原生支持全 SQL 的开源时间序列数据库;结合了关系型数据库的功能、可靠性和易用性以及 NoSQL 系统的典型扩展性。它建立在PostgreSQL的基础上,并为快速摄入和复杂查询进行了优化。TimescaleDB 被部署用于支持关键任务的应用,包括工业数据分析、复杂的监控系统、运营数据仓库、金融风险管理和地理空间资产跟踪,这些行业包括制造业、太空、公共事业、石油和天然气、物流、采矿、广告技术、金融、电信等等。其特点包括:
TimescaleDB 是基于 PostgreSQL 数据库开发的一款时序数据库,以插件化的形式提供(打包为扩展程序),随着 PostgreSQL 的版本升级而升级,不会因为另立分支带来麻烦。数据自动按时间和空间分片(chunk),是唯一一个原生支持全 SQL 的开源时间序列数据库;结合了关系型数据库的功能、可靠性和易用性以及 NoSQL 系统的典型扩展性。它建立在PostgreSQL的基础上,并为快速摄入和复杂查询进行了优化。TimescaleDB 被部署用于支持关键任务的应用,包括工业数据分析、复杂的监控系统、运营数据仓库、金融风险管理和地理空间资产跟踪,这些行业包括制造业、太空、公共事业、石油和天然气、物流、采矿、广告技术、金融、电信等等。其特点包括:透明的时间/空间分割 —— 向上(单个节点)扩展和水平扩展。
高效数据写入(包括批量提交,内存索引、事务支持,支持数据回填)。
单个节点上尺寸合适的区块(二维数据分区)确保大量数据快速摄取。
跨区操作和服务器操作同时进行。
虽然此前 TimescaleDB 分为开源版本和企业版本,但从2020年他们决定不再销售企业版,并将所有企业版本的功能都包含在免费版的产品中,将收入完全押赌在云端。这种方式也为 TimescaleDB 吸引来了更多用户,目前每月有超过 200 万个活跃的数据库正在使用 TimescaleDB。其提供跨时间和空间的自动分区,以及完整的 SQL 支持。
TimescaleDB 架构
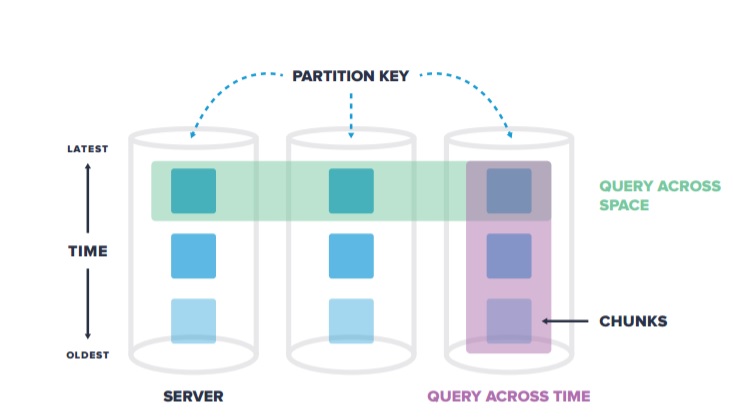
数据自动按时间和空间分片(chunk)
随着物联网的发展,时序数据库的需求越来越多,比如水文监测、设备监控、安全相关的数据监控、通讯监控、金融行业指标数据、传感器数据等。而在互联网行业中,也有着非常多的时序数据,例如用户访问网站的行为轨迹,应用程序产生的日志数据等等。
时序数据有几个特点
1. 基本上都是插入,没有更新的需求。
2. 数据基本上都有时间属性,随着时间的推移不断产生新的数据,旧的数据不需要保存太久。
业务方对时序数据通常有几个查询需求
1. 获取最新状态,查询最近的数据(例如传感器最新的状态)
2. 展示区间统计,指定时间范围,查询统计信息,例如平均值,最大值,最小值,计数等。。。
3. 获取异常数据,根据指定条件,筛选异常数据
时序数据库应该具备的特点
1. 压缩能力
通常用得上时序数据库的业务,传感器产生的数据量都是非常庞大的,数据压缩可以降低存储成本。
2. 自动rotate
时序数据通常对历史数据的保留时间间隔是有规定的,例如一个线上时序数据业务,可能只需要保留最近1周的数据。为了方便使用,时序数据库必须有数据自动rotate的能力。
3. 支持分片,水平扩展
因为涉及的传感器可能很多,单个节点可能比较容易成为瓶颈,所以时序数据库应该具备水平扩展的能力,例如分表应该支持水平分区。
4. 自动扩展分区
业务对时序数据的查询,往往都会带上对时间区间进行过滤,因此时序数据通常在分区时,一定会有一个时间分区的概念。时序数据库务必能够支持自动扩展分区,减少用户的管理量,不需要人为的干预自动扩展分区。例如1月份月末,自动创建2月份的分区。
5. 插入性能
时序数据,插入是一个强需求,对于插入性能要求较高。
6. 分区可删
分区可以被删除,例如保留1个月的数据,1个月以前的分区都可以删除掉。
7. 易用性(SQL接口)
SQL是目前最通用的数据库访问语言,如果时序数据库能支持SQL是最好的。
8. 类型丰富
物联网的终端各异,会有越来越多的非标准类型的支持需求。例如采集图像的传感器,数据库中至少要能够存取图像的特征值。而对于其他垂直行业也是如此,为了最大程度的诠释业务,必须要有精准的数据类型来支撑。
9. 索引接口
支持索引,毫无疑问是为了加速查询而引入的。
10. 高效分析能力
时序数据,除了单条的查询,更多的是报表分析或者其他的分析类需求。这对时序数据库的统计能力也是一个挑战。
11. 其他特色
11.1 支持丰富的数据类型,数组、范围类型、JSON类型、K-V类型、GIS类型、图类型等。满足更多的工业化需求,例如传感器的位置信息、传感器上传的数据值的范围,批量以数组或JSON的形式上传,传感器甚至可能上传图片特征值,便于图片的分析。(例如国家安全相关),轨迹数据的上层则带有GIS属性。
11.2 支持丰富的索引接口,因为类型丰富了,普通的B-TREE索引可能无法满足快速的检索需求,需要更多的索引来支持 数组、JSON、GIS、图特征值、K-V、范围类型等 (例如PostgreSQL的gin, gist, sp-gist, brin, rum, bloom, hash索引接口)。
这两点可以继承PostgreSQL数据库的已有功能,已完全满足。
TimescaleDB 具有以下特点
1. 基于时序优化
2. 自动分片(自动按时间、空间分片(chunk))
3. 全 SQL 接口
4. 支持垂直于横向扩展
5. 支持时间维度、空间维度自动分区。空间维度指属性字段(例如传感器 ID,用户 ID 等)
6. 支持多个 SERVER,多个 CHUNK 的并行查询。分区在 TimescaleDB 中被称为 chunk。
7. 自动调整 CHUNK 的大小
8. 内部写优化(批量提交、内存索引、事务支持、数据倒灌)。
内存索引,因为 chunk size 比较适中,所以索引基本上都不会被交换出去,写性能比较好;
数据倒灌,因为有些传感器的数据可能写入延迟,导致需要写以前的 chunk,timescaleDB 允许这样的事情发生(可配置)。
9. 复杂查询优化(根据查询条件自动选择 chunk,最近值获取优化(最小化的扫描,类似递归收敛),limit 子句 pushdown 到不同的 server,chunks,并行的聚合操作)
10. 利用已有的 PostgreSQL 特性(支持 GIS,JOIN 等),方便的管理(流复制、PITR)
11. 支持自动的按时间保留策略(自动删除过旧数据)
使用示例
Creating a hypertable
-- We start by creating a regular SQL table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);
-- Then we convert it into a hypertable that is partitioned by time
SELECT create_hypertable('conditions', 'time');
项目更多信息可参考《Timescale发展记》。
最新版本:0.12
修复了在涉及到并行 worker 时对 DISCARD ALL 命令的处理,这有时会导致扩展程序抗议它未预加载。用户在数据库中查找 TRIGGER 权限的用户权限 bug 已修复,这个 bug 会导致无法将数据插入到可改写的数据中。修复了与新调度程序和后台 worker 框架相关的一些问题,修复了自适应分块中的 bug,其中不正确的索引可用于推断当前间隔。改进了测试、代码清理和其他内务管理。源码下载和发布说明请查看这里。
最新版本:1.0
1.0 正式发布了,开发团队表示,自2018年9月分宣布第一个候选版本以来,Timescale 的工程师团队合并了 50 多个 PR,以加强数据库,提高稳定性和易用性。随着TimescaleDB 1.0 宣布正式推出,官方表示该版本已可用于生产环境,是首个支持完整 SQL 和扩展的企业级时序数据库。更新亮点如下:
更广泛的可用性改进
后台作业自动化和调度的基础
增强了数据库强化和测试
构建开源监控堆栈:对 Grafana 和 Prometheus 的原生支持
1.0 是 TimescaleDB 新的开始。
最新版本:1.4
v1.4.0 包含连续聚合的主要新功能,并使分析查询的性能得到改进。1.3.0 版本中添加了对连续聚合的支持,最初仅限于一个连续聚合。新版本删除了这个限制,并允许多个连续聚合。1.4.0 还添加了一个可以执行的新自定义节点 ChunkAppend 来执行时间约束排除,也用于有序附加。有序追加不再需要 LIMIT 条款,并且现在支持 time_bucket 的空间分区和排序。更新内容如下:
使用 ChunkAppend 替换 Append 节点,支持多个连续聚合
从有序追加中删除 LIMIT 子句限制,在 Ordered Append 中支持时间桶功能
为 REFRESH MATERIALIZED VIEW 添加警告消息,添加架构和位大小以进行遥测
将作业统计信息列添加到 timescaledb information.continuous aggregate stats 视图
Bug 修复
不要使用一次性过滤器删除 Result 节点
修复遥测报告返回值
修复连续的 agg 目录表插入失败问题
更新连续的 agg bgw 作业开始时间
最新版本:1.6
v1.6.0 的主要新特性使用户可以将聚合数据保持为连续聚合,同时使用drop_chunks删除原始数据,这使用户可以通过仅保留聚合来节省存储空间。连续聚合的 refresh_lag 参数的语义已更改为相对于当前时间戳,而不是相对于表中的最大值。此更改要求在具有基于整型的时间列的超表上设置 integer_now 函数,以在此表上使用连续聚合。为连续聚合添加了一个参数 timescaledb.ignore_invalidation_older_than,该参数接受时间间隔(例如 1 个月),如果设置,它将限制处理无效的时间。因此,如果为timescaledb.ignore_invalidation_older_than = '1 month',则对自修改时间到当前时间戳的 1 个月以上的数据的任何修改都不会导致连续聚合被更新。此外还修复了一些 bug,详情查看更新说明。
最新版本:2.0
2020年12月23日,2.0.0 正式发布,此版本增加了对分布式超表(多节点 TimescaleDB)的支持,并添加了一些新特性和功能增强,让用户对数据的控制更加清晰和灵活。
多节点架构:特别是在 TimescaleDB 2.0 中,用户现在可以在 TimescaleDB 的多个实例上创建分布式超表,配置成一个实例作为访问节点,其他多个实例作为数据节点。分布式超表的所有查询都是向访问节点发出的,但插入的数据和查询会在数据节点上向下推送,以提高规模和性能。多节点 TimescaleDB 可以自我管理,或者为了便于操作,可以在 Timescale 的完全托管的云服务中启动。此版本还添加了:
支持用户定义的操作,允许用户定义、自定义和计划自动任务,这些任务可以由现在向用户公开的内置作业调度框架来运行。
对连续聚合的重大更改,现在将视图创建与策略分开。用户现在可以刷新连续聚合实例化视图的各个区域,或通过策略安排自动刷新。
重新设计了信息视图,包括新的(更通用的)视图,这些视图提供有关 hypertable 的维度和块、策略和用户定义的操作以及对多节点 TimescaleDB 的支持的信息。
将所有以前的企业功能移至社区版,并更新 Timescale 许可证,该许可证现在为用户和开发人员提供了更多(更宽松)的权限。
值得注意的是,上述的某些更改(例如,连续聚合、更新的信息视图)的确向 API 引入了重大更改,并且不向后兼容。虽然 TimescaleDB 2.0 中的更新脚本将自动升级运行 TimescaleDB 1.x 的数据库,但是其中一些 API 和功能更改可能需要更改依赖于先前 API 的客户端和/或上游脚本。升级之前,建议用户查看 docs.timescale.com 上的升级文档以了解更多详细信息。更多详情可查看更新说明。
2021年1月28日,发布了2.0.1版本,此版本增加了对分布式超表(多节点 TimescaleDB)的支持,并添加了一些新特性和功能增强,让用户对数据的控制更加清晰和灵活。该版本中包含的修补程序解决了连续聚合、压缩、具有超表的 JOINs 和从早期版本升级时产生的问题。同年2月底在2.0.2版本中修复了连接、后台作业状态和禁用压缩的问题。它还包括对连续聚合的增强,改进策略的验证和优化,以便在出现大量无效情况时更快地刷新。修复了如下的一些Bug:
始终验证现有数据库和扩展,远程数据获取程序的配置枚举条目,在更新时添加删除块的检查,改善 cagg 水印缓存
更新脚本中的目录修复,设置 next_start 字段时,请勿将工作标记为已开始,升级期间的连续聚合权限,涉及压缩块的嵌套循环联接
从更新脚本中删除压缩状态更新,避免 partialize_agg 的分区规划,gapfill 计划中的损坏,由于未初始化的内存导致的 partitionwise agg 崩溃
更多更新详情可查看发行说明。
最新版本:2.2
v2.2已于2021年4中旬发布,此版本包含了自 2.1.1 版本以来增加的一些新功能,官方将其标为中等程度的优先升级。该版本添加了 Skip Scan 优化,显著提高了 DISTINCT ON 的查询性能。目前,这个优化还不能应用于分布式超表的查询。同时还增加了一个功能,以创建一个分布式的还原点,允许从备份中执行多节点集群的一致还原。此外,其还进行了一些 bug 修复。包括解决了 size 和 stats functions 的问题、分布式插入中内存占用率高、分布式 ORDER BY queries 速度慢、涉及 INCLUDE 的索引和 single chunk 查询规划等问题。官方表示其计划只继续支持 PostgreSQL 11 直到2021年6月中旬,届时将公布具体的不支持 PG 11 版本的 TimescaleDB 版本。
添加分布式还原点功能
SkipScan 加快 SELECT DISTINCT 的速度
重构和强化 size 和 stats functions
减少分布式插入的内存使用
修复 multi-node order by queries 极慢的问题
修复块索引列名称映射
在 ChunkAppend 中保留 Append pathkeys
更多详情请查看此处。
最新版本:2.4
v2.4.0 已于2021年7月未发布,此版本添加了自 2.3.1 版本以来的新实验性功能。此版本中的实验性功能是:
用于在分布式 hypertable 设置中跨数据节点进行块操作的 API。这包括添加数据节点并将块移动到新数据节点以进行集群重新平衡的能力。
time_bucket_ng函数是time_bucket的较新版本。支持年、月、日、小时、分钟和秒。
此版本还包括几个错误修复;以及 TimescaleDB 2.4 不再支持 Postgres 11,需要 Postgres 12 及以上版本。具体更新内容如下:
添加 timescaledb_experimental 模式
将 block_new_chunks 和 allow_new_chunks API 添加到实验模式。添加基于块的 refresh_continuous_aggregate。
引入实验性的 time_bucket_ng 函数
允许在连续聚合中使用实验性 time_bucket_ng 函数
在 time_bucket_ng 中支持秒、分钟和小时
实现对 chunk copy/move 的清理
修复没有 fdw_private 的 RelOptInfo 的段错误
验证压缩路径的压缩块有效性
修复连续聚合视图的目标列表名称
从 relcache 无效回调中删除扩展检查
修复 remote_tx_heal_data_node 以仅使用当前数据库
详情查看此处。
最新版本:2.5
v2.5.2 现已于2022年2月中旬发布,这个版本值得注意的特性包括:
改进自定义扫描节点的注册
修复 GRANT 命令的 role 类型解析
使用一次性过滤器修复 DataNodeScan 计划
修复插入内部压缩表时的 segfault 错误
修复 32 位平台上的 subtract_integer_from_now 并改进错误处理
在 time_bucket_gapfill 中修复映射(projection)处理
在数据提取器中避免双重 PGclear()
修复索引谓词的解析
在 interpolate 中消除浮点取整的不稳定性
修复 ALTER TABLE EventTrigger 初始化
修复过早的缓存释放调用
修复具有目录条目的已删除块的状态
修复 ANY 结构中的 riinfo NULL 处理问题
修复扩展安装权限提升问题
更多详情可查看此处。
最新版本:2.6
v2.6.0 现已于2022年2月下旬发布,自 2.5.2 版本以来增加的主要新功能包括:
带压缩的 Continuous aggregates,time_bucket_ng 对连续聚合的 N 个月和时区的支持。实验性功能包括:
time_bucket_ng 函数,time_bucket 的更新版本。此函数支持年、月、日、小时、分钟、秒和时区。
time_bucket_ng 对连续聚合的 N 个月和时区的支持。
用于在分布式 hypertable setup 中跨数据节点进行分块操作的 API。这包括添加数据节点并将块移动到新数据节点以进行集群重新平衡的能力。
新特性:
允许 ALTER TABLE ADD COLUMN with DEFAULT 在 compressed hypertable 上
允许 compressed hypertable 上的 ALTER TABLE DROP COLUMN
对连续聚合启用压缩
优化 first/last
在多节点上添加对 ALTER SCHEMA 的支持
在多节点上添加对 DROP SCHEMA 的支持
CAGG 中的时区支持
Bug 修复:
正确处理 max_retries 选项
修复远程事务修复逻辑
修复分布式 hypertable 上的 ALTER SET/DROP NULL 约束
修复 add_compression_policy 中的 segfault
修复分布式 hypertable 上 EXPLAIN VERBOSE 中的崩溃
消除 interpolate 中的浮点取整不稳定性
更新处于过渡状态的 ts_extension_oid
修复分区方案中的缓冲区溢出问题
具有大量块的 hypertable 的查询规划性能得到改进。更多更新说明请查看此处。
最新版本:2.1x
v2.10.2 于2023年4月下旬正式发布,此版本修复了 2.10 版本的若干 bug :
修复 COPY 提取器中的文件尾部处理
在 libpq 调用中添加对 malloc 失败的检查
修复 on_proc_exit 插槽耗尽问题
扫描元数据时使用一致的快照
不对大直方图 () 参数进行段错误
在复制 / 移动块期间,确保超级用户权限
修复连续聚合定义中没有 FROM 子句的问题
修复 CAggs 中的连接 rte
修复 timescaledb_experimental.policies 视图中的重复条目
在压缩表上删除列后修复段错误
在排序之前复制 scheduled_jobs 列表
在 Cagg 定义中允许命名 time_bucket 参数
修复从具有可变时间桶的连续聚合开始的刷新
在部分压缩块的未压缩部分启用索引扫描
更多内容可参考更新公告。
v2.11版本于2023年5月下旬正式发布,该版本包含自 v2.10.3 版本以来的新功能和错误修复,值得注意的特性包括:
支持对压缩块的 DML 操作:
支持 UPDATE/DELETE、对压缩块的唯一约束
支持 ON CONFLICT DO UPDATE、ON CONFLICT DO NOTHING
支持分层的 Continuous Aggregates 的连接。
更多详情可查看更新公告。
v2.13.1 现已于2024年1月中旬发布,此版本包含自 v2.13.0 版本以来的错误修复。具体更新内容如下(Bug 修复):
在近似行数中使用 numrows_pre_compression
在 PG16 中使用已处理的组子句
更改 bgw_log_level 以使用 PGC_SUSET
禁用表达式的向量化总和。
从物化数据中读取 CAgg 水印
修复 PG16 中的 gapfill 的 groupby pathkeys
修复 DML 解压期间的索引匹配
修复 PG16 上的压缩块权限处理
修复丢失的并发 CAgg 更新
修复压缩块上的唯一表达式索引
修复解压排序逻辑中释放路径的使用
详情可查看更新说明。
最新版本:2.2x
v2.23.0 现已于2025年10月下旬发布,此版本较 2.22.1 版本进行了性能改进和错误修复。官方建议尽快升级。一些更新亮点内容如下:
此版本全面支持 PostgreSQL v18 的所有现有功能。TimescaleDB v2.23 适用于 PostgreSQL 15、16、17 和 18。
列存储现已默认启用 UUIDv7 压缩。此功能已在 v2.22.0 版本中推出。它至少可节省 30% 的存储空间,并且在筛选条件中使用 UUIDv7 列时,查询性能可提升约 2 倍。
新增了将超表设置为 unlogged 的功能,解决了社区提出的公开请求#836。该功能可在持久性与性能间实现权衡,后者更适用于大规模导入场景。
通过允许在连续聚合中使用返回集合的函数,此版本解决了社区长期存在的阻碍问题。
PostgreSQL v15 弃用公告
TimescaleDB 将继续支持 PostgreSQL v15 至 2026 年 6 月。届时官方将公布不再支持 v15 的具体 TimescaleDB 版本。
v2.24.0 现已于2025年12月上旬发布,此版本较 2.23.1 版本进行了性能改进和错误修复。官方建议尽快升级。主要更新如下:
1.Direct Compress 功能变得更加智能和快速:它现在可以与生成连续聚合的超表无缝协作。失效范围直接基于已摄取的批次在内存中计算,并在事务提交时高效写入。此更改通过消除失效日志的写入放大,大幅降低了 I/O 占用。
2.连续聚合现在支持 UUIDv7:通过增强 time_bucket 功能,完全支持按 UUIDv7 分区的超表,该功能接受 UUIDv7 值并返回精确的、时区感知的时间戳 —— 从而在现代 UUID 驱动的表架构上解锁强大的时间序列分析。
3.Lightning-fast recompression:convert_to_columnstoreAPI 上的新选项 recompress := true 支持纯内存重新压缩,与之前的基于磁盘的处理方式相比,速度提高了 4-5 倍。
ARM 对布隆过滤器的支持:
升级到 2.24 版本后,稀疏布隆过滤器索引将停止工作。如果你遇到此问题,升级期间 Postgres 日志中将出现警告 “bloom filter sparse indexes require action to re-enable”。在 2.24 之前的版本中,布隆过滤器稀疏索引的哈希方案依赖于 TimescaleDB 可执行文件的构建选项。这些选项由软件包发布者设置,并且可能因软件包来源甚至版本而异。升级到具有不同选项的版本后,使用布隆过滤器查找的查询可能会错误地停止返回实际上应该符合查询条件的行。2.24 版本通过为每个哈希方案使用不同的列名修复了此问题。
升级到 2.24 之前创建的压缩块的布隆过滤器稀疏索引将被禁用。要重新启用它们,必须先解压缩,然后再压缩受影响的块。如果在 AMD64 架构上运行的是官方 APT 软件包,则哈希方案没有改变,可以安全地使用现有的布隆过滤器稀疏索引。要启用此功能,需要在服务器配置中设置 GUCtimescaledb.read_legacy_bloom1_v1 = on。升级到 2.24 后压缩的数据块将使用新的索引格式,布隆过滤器稀疏索引将继续照常为这些数据块工作,无需任何干预。
v2.25现已于2026年1月下旬发布,其较 2.24.0 版本进行了性能改进和错误修复,官方建议尽快升级。此版本针对列存储上的连续聚合进行了多项改进:
更快的刷新速度:现在可以在物化视图刷新期间使用直接压缩,从而提高吞吐量并减少 I/O 使用量。
Efficiency:启用删除优化功能可显著降低系统资源需求。
Smaller transactions:将 buckets_per_batch 默认值调整为 10 可减少交易规模,从而减少 WAL 持有时间。
Faster queries:更智能的 segmentby 和 orderby 默认设置,提升了查询性能并提高了列存储的压缩率。
Sunsetting announcements
此版本移除了基于 WAL 的连续聚合失效机制。该机制在 2.22.0 版本中作为技术预览版引入,旨在利用逻辑解码构建失效日志。该机制专为高负载数据摄取而设计,可减少写入放大。随着后续对连续聚合的一系列改进,该机制的优先级降低并被移除。
旧版连续聚合格式(已在 2.10.0 版本中弃用)已在此版本中从 TimescaleDB 中完全移除。仍在使用旧格式的用户应阅读迁移文档以迁移到新格式。Tiger Cloud 用户已自动迁移。
v2.27.0 现已于2026年5月中旬发布,较 2.26.4 版本进行了性能改进和错误修复。官方建议尽快升级。
1.Hypercore 引擎现在支持过滤器的向量化实现,通过标准的 Postgres 函数路径对其进行内联评估。这扩展了可通过列存储的更快路径执行的查询集(包括连续聚合刷新),在基准测试中实现了 30% 到 2 倍的速度提升。
2.现在,带有等值谓词的 UPDATE 和 DELETE 语句可以使用布隆过滤器来跳过解压缩那些压缩行不匹配的批次。当应用多个布隆过滤器时,它们将按列数从多到少的顺序进行评估(选择性最高的优先),并且 EXPLAIN 现在会通过新增的 “Compressed batches filtered” 和 “atches filtered after decompression counters” 计数器来报告过滤活动。在某些情况下,查询性能最多可提升 160 倍。
3.现在,UPSERT 查询可以利用布隆过滤器(包括复合过滤器)来跳过解压缩批次,前提是仲裁值肯定不存在;当存在多个过滤器时,系统会自动选择选择性最高的过滤器。EXPLAIN 输出新增了统计信息,例如布隆过滤器检查的批次、布隆过滤器修剪的批次、未经过布隆过滤器的批次以及布隆过滤器误报,以便更清晰地了解修剪效果。
PostgreSQL v15 即将停止支持公告
即将于 2026 年 6 月发布的 TimescaleDB 版本将是最后一个正式支持 PostgreSQL 15 的版本。此弃用公告最初于 2025 年 10 月 29 日在 v2.23.0 版本更新日志中发布,以便用户有充足的时间进行准备。为了确保能够不间断地使用新功能、修复错误并提升性能,所有实例都必须升级到 PostgreSQL 16 或更高版本。
向后不兼容的变更
1.#9579 压缩 int2 列上的布隆过滤器稀疏索引可能导致 SELECT 查询无法返回实际符合 WHERE 条件的行。受影响数据库的升级已被阻止,必须在升级前手动删除错误的索引。
2.此版本引入了复合布隆过滤器元数据的新命名规则。虽然此更改不会影响查询处理,但 v2.27 无法自动使用 v2.26 中生成的复合布隆过滤器。要转换现有的 v2.26 复合布隆过滤器,必须重命名旧版元数据列。这是一个轻量级的目录操作,无需重新压缩任何数据,可以使用此迁移脚本完成此操作。
官方主页:http://www.timescale.com/
该文章最后由 阿炯 于 2026-05-17 22:06:40 更新,目前是第 2 版。