开源分布式关系型数据库-TiDB
 TiDB 是一款定位于在线事务处理/在线分析处理( HTAP: Hybrid Transactional/Analytical Processing)的融合型数据库产品,实现了一键水平伸缩,强一致性的多副本数据安全,基于 Raft 算法的多副本复制等重要的分布式事务,实时 OLAP 等重要特性。同时兼容 MySQL 协议和生态,迁移便捷,运维成本极低,其设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景。采用Go及Rust语言开发并在Apache 2.0协议下授权。
TiDB 是一款定位于在线事务处理/在线分析处理( HTAP: Hybrid Transactional/Analytical Processing)的融合型数据库产品,实现了一键水平伸缩,强一致性的多副本数据安全,基于 Raft 算法的多副本复制等重要的分布式事务,实时 OLAP 等重要特性。同时兼容 MySQL 协议和生态,迁移便捷,运维成本极低,其设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景。采用Go及Rust语言开发并在Apache 2.0协议下授权。TiDB 是 PingCAP 公司设计的开源分布式 HTAP (Hybrid Transactional and Analytical Processing) 数据库,结合了传统的 RDBMS 和 NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的目标是为 OLTP (Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案,比较典型的既要..又要的双满足模式。
特性:
高度兼容 MySQL:多数情况下无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
水平弹性扩展:通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
分布式事务:TiDB 100% 支持标准的 ACID 事务。
真正金融级高可用:相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
一站式 HTAP 解决方案:TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解决方案,一份存储同时处理 OLTP & OLAP,无需传统繁琐的 ETL 过程。
云原生 SQL 数据库:TiDB 是为云而设计的数据库,支持公有云、私有云和混合云,使部署、配置和维护变得十分简单。
其主页上的三篇文章介绍 TiDB 技术内幕,也即原理与实现:
说存储
说计算
谈调度
TiDB Server 在整个系统中位于 Load Balancer(或者是 Application) 与底层的存储引擎之间,主要部分分为三层:
MySQL Protocol 层接收 MySQL Client 的请求,解析 MySQL Protocol 的包并转换为 TiDB Session 中的各种命令;处理完成后,将结果结果为 MySQL Protocol 格式,返回给 Client。
SQL 层解析并执行 SQL 语句,制定查询计划并优化,生成执行器并通过 KV 层读取或写入数据,最后返回结果给 MySQL Protocol层。
KV 层提供带事务的(分布式/单机)存储,在 KV 层和 SQL 层之间,有一层抽象,使得 SQL 层能够忽略下面不同的 KV 存储的差异,看到统一的接口。
目前业界最流行的分布式数据库有两类,一个是以Google Spanner为代表,一个是以AWS Auraro为代表。
Spanner 是 shared nothing 的架构,内部维护了自动分片、分布式事务、弹性扩展能力,数据存储还是需要 sharding,plan 计算也需要涉及多台机器,也就涉及了分布式计算和分布式事务。主要产品代表为TiDB、CockroachDB、OceanBase等;这三个产品可以说目前话题量不相上下,TiDB属于国产PingCAP公司的、CockroachDB比TiDB早出来一年、OceanBase阿里团队的,2017年双11交出4200万/秒的处理能力。
Auraro 主要思想是计算和存储分离架构,使用共享存储技术,这样就提高了容灾和总容量的扩展。但是在协议层,只要是不涉及到存储的部分,本质还是单机实例的 MySQL,不涉及分布式存储和分布式计算,这样就和 MySQL 兼容性非常高。主要产品代表为 PolarDB。
TiDB 架构是 SQL 层和 KV 存储层分离,相当于 InnoDB 插件存储引擎与 MySQL 的关系。从下图可以看出整个系统是高度分层的,最底层选用了当前比较流行的存储引擎 RocksDB,RockDB 性能很好但是是单机的,为了保证高可用所以写多份(一般为 3 份),上层使用 Raft 协议来保证单机失效后数据不丢失不出错。保证有了比较安全的 KV 存储的基础上再去构建多版本,再去构建分布式事务,这样就构成了存储层 TiKV。有了 TiKV,TiDB 层只需要实现 SQL 层,再加上 MySQL 协议的支持,应用程序就能像访问 MySQL 那样去访问 TiDB 了。
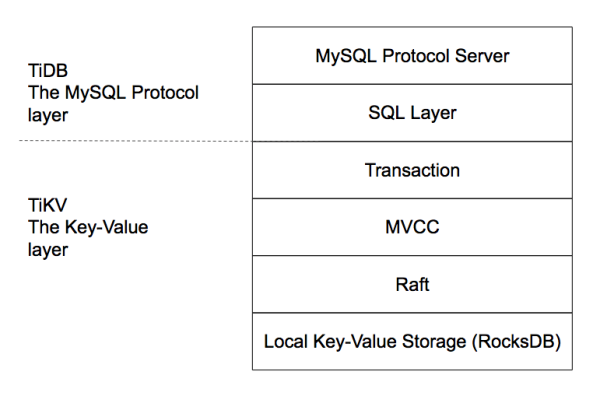
这里还有个非常重要的概念叫做 Region。MySQL 分库分表是将大的数据分成一张一张小表然后分散在多个集群的多台机器上,以实现水平扩展。同理,分布式数据库为了实现水平扩展,就需要对大的数据集进行分片,一个分片也就成为了一个 Region。数据分片有两个典型的方案:一是按照 Key 来做 Hash,同样 Hash 值的 Key 在同一个 Region 上,二是 Range,某一段连续的 Key 在同一个 Region 上,两种分片各有优劣,TiKV 选择了 Range partition。TiKV 以 Region 作为最小调度单位,分散在各个节点上,实现负载均衡。另外 TiKV 以 Region 为单位做数据复制,也就是一个 Region 保留多个副本,副本之间通过 Raft 来保持数据的一致。每个 Region 的所有副本组成一个 Raft Group, 整个系统可以看到很多这样的 Raft groups。
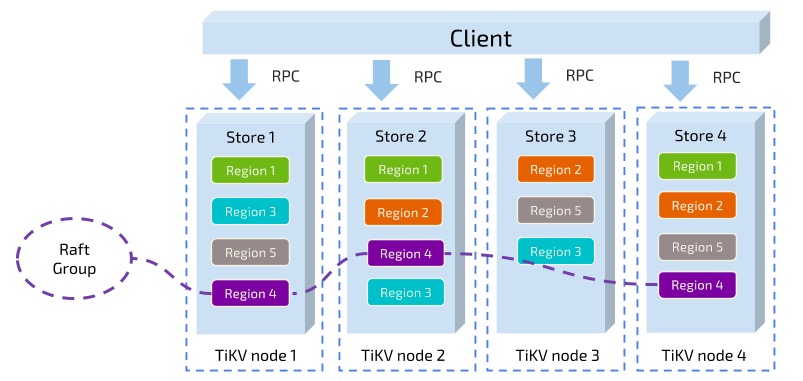
最后简单说一下调度。TiKV 节点会定期向 PD 汇报节点的整体信息,每个 Region Raft Group 的 Leader 也会定期向 PD 汇报信息,PD 不断的通过这些心跳包收集信息,获得整个集群的详细数据,从而进行调度,实现负载均衡。
TiDB整体架构
要深入了解 TiDB 的水平扩展和高可用特点,首先需要了解 TiDB 的整体架构。
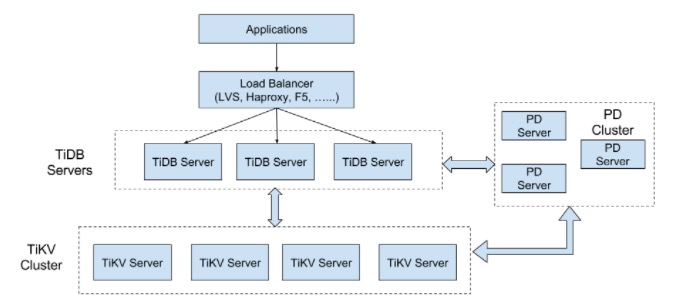
整体概述
TiDB 集群主要分为三个组件:
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。 TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft Group Leader 的迁移等);三是分配全局唯一且递增的事务 ID。PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署 3 个节点。
TiKV Server
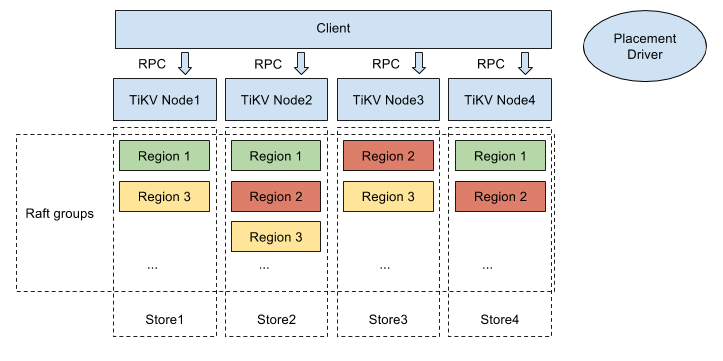
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region(区域),每个 Region 负责存储一个 Key Range (从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。TiKV 最初是为了补充 TiDB 而创建的。TiKV 采用 Rust 构建,由 Raft 提供支持,受到 Google Spanner 和 HBase 设计的启发,提供简化的调度和自动平衡,但不依赖于任何分布式文件系统。这是一个开源、统一分布式存储层,支持功能强大的数据一致性、分布式事务、水平可扩展性和云原生架构。
功能特性:
异地复制 :TiKV 使用 Raft 和 Placement Driver 进行异地复制来保证数据的安全性。
水平扩展 :凭借 PD 和精心设计的 Raft 组,TiKV 在水平可扩展性方面表现出色,可轻松扩展至100多TB数据。
一致性分布式事务:与 Google 的 Spanner 类似,TiKV 支持外部一致的分布式事务。
协处理器支持:与 Hbase 类似,TiKV 实现了一个支持分布式计算的协处理器框架。
和 TiDB 融合:得益于内部优化,TiKV 和 TiDB 可以协同工作,成为具有高水平可扩展性、外部一致性事务,RDBMS 支持和 NoSQL 设计模式的数据库解决方案。
核心特性
水平扩展
无限水平扩展是 TiDB 的一大特点,这里说的水平扩展包括两方面:计算能力和存储能力。TiDB Server 负责处理 SQL 请求,随着业务的增长,可以简单的添加 TiDB Server 节点,提高整体的处理能力,提供更高的吞吐。TiKV 负责存储数据,随着数据量的增长,可以部署更多的 TiKV Server 节点解决数据 Scale 的问题。PD 会在 TiKV 节点之间以 Region 为单位做调度,将部分数据迁移到新加的节点上。所以在业务的早期,可以只部署少量的服务实例(推荐至少部署 3 个 TiKV, 3 个 PD,2 个 TiDB),随着业务量的增长,按照需求添加 TiKV 或者 TiDB 实例。
高可用
高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。下面分别说明这三个组件的可用性、单个实例失效后的后果以及如何恢复。
TiDB 是无状态的,推荐至少部署两个实例,前端通过负载均衡组件对外提供服务。当单个实例失效时,会影响正在这个实例上进行的 Session,从应用的角度看,会出现单次请求失败的情况,重新连接后即可继续获得服务。单个实例失效后,可以重启这个实例或者部署一个新的实例。
PD 是一个集群,通过 Raft 协议保持数据的一致性,单个实例失效时,如果这个实例不是 Raft 的 leader,那么服务完全不受影响;如果这个实例是 Raft 的 leader,会重新选出新的 Raft leader,自动恢复服务。PD 在选举的过程中无法对外提供服务,这个时间大约是3秒钟。推荐至少部署三个 PD 实例,单个实例失效后,重启这个实例或者添加新的实例。
TiKV 是一个集群,通过 Raft 协议保持数据的一致性(副本数量可配置,默认保存三副本),并通过 PD 做负载均衡调度。单个节点失效时,会影响这个节点上存储的所有 Region。对于 Region 中的 Leader 结点,会中断服务,等待重新选举;对于 Region 中的 Follower 节点,不会影响服务。当某个 TiKV 节点失效,并且在一段时间内(默认 10 分钟)无法恢复,PD 会将其上的数据迁移到其他的 TiKV 节点上。
与CockroachDB的比较
在开源分布式New SQL数据库领域中最著名的两个产品是PingCap公司的TiDB和Cockroach LABs的CockroachDB(简称 CRDB)。这两个产品都是受到Google Spanner 论文启发,是它的开源克隆版本实现。
TiDB兼容MySQL,而CRDB是兼容PostgreSQL。对于应用开发人员来说,如果比较熟悉MySQL,那么选择TiDB可能是比较好的选择;如果比较熟悉PostgreSQL,那么Crdb可能是优先的选择。除了这一点之外,下面的表格给出这两个产品对于SQL支持的比较,这些也可能是开发人员所关注的。
| TiDB | CockroachDB |
存储过程、用户自定义函数 | No(没有后续支持计划) | No(计划支持) |
触发器 | No(没有后续支持计划) | No(计划支持) |
用户自定义函数 | No(没有后续支持计划) | No(计划支持) |
视图 | No | Yes |
Sequence | No | Yes |
主键 | Yes | Yes |
外键 | No | Yes |
Check约束 | No | Yes |
分区表 | No(很快支持) | Yes |
游标 | No | No |
全局临时表 | No | No |
事务隔离级别 | SI | SI SSI(Serializable Snapshot Isolation) |
表级锁、行级锁 | 乐观锁 | 乐观锁 |
黄东旭谈TiDB :从决定创业到获得融资只用 3 天
2020年 11 月,PingCAP 宣布完成 D 轮 2.7 亿美元融资,打破全球数据库公司融资纪录。与此同时,PingCAP 旗下的分布式 NewSQL 数据库产品 TiDB 也连续登顶国内最受欢迎数据库排行榜,成为当之无愧的国产数据库之星。TiDB 成功的背后,离不开一位技术狂热者对基础软件技术的执着以及对数据库市场的敏锐嗅觉,这个人就是 TiDB 的联合创始人兼 CTO 黄东旭。

黄东旭少年时期的经历在旁人看来就是一名为技术而生的天才少年。小的时候,黄东旭十分爱打电子游戏,为了不让他玩游戏成瘾,父亲就把家里游戏机所有的游戏卡带都收了起来,只留下了 Basic 的卡带。于是,黄东旭突发奇想打算自己摸索着尝试编写游戏。
彼时,Windows 系统尚未普及,还在上小学的黄东旭就从“小霸王”学习机的 QBasic 写起,开始了自己的“代码生涯”。后来他又利用课余时间研究 DOS 汇编,到了小学四、五年级时,他已经学会了 C 语言。高中时期,黄东旭开始使用 Linux 系统进行开发,此后就一直钟情于开源和自由软件运动,在这个过程中逐渐受到开源精神和开源世界所推崇的理念影响。
尽管在初中之前就学完了很多大学计算机的课程,但黄东旭并不觉得自己是什么「天才」,用他自己的话说“就是从小接触,太热爱这些东西了。”“在国内我算比较早接触开源和写代码的这批人,我年龄虽然不大,但雷军在混 BBS 写 WPS 时我也在(笑)。我觉得编码给我一种感受,就是从零开始构建你想象中的东西,当你有能力搞定时,这感觉很好,我很享受造物的成就感。”黄东旭在 2016 年接受 OSC 采访时说。
上了大学的黄东旭自然而然地选择了软件工程专业,大三时去了微软亚洲研究院工作了一年,毕业后去了网易有道做有道词典,主要负责 Windows 端、Mac 端以及部分服务器端,经历了产品从无到有的整个过程。后来到了豌豆荚,由于对豌豆荚的文化很欣赏,认为这是一个非常硅谷范儿的公司,所以黄东旭就加入了当时还很小的豌豆荚。
“我本身很喜欢 OpenSource 的文化和 Hacker 精神, 在豌豆荚又认识了有共同爱好的刘奇,所以我们的团队基本上做的所有东西都是开源的。”黄东旭回忆。后来黄东旭与刘奇一起做了 Codis 项目,国内很多公司都受益于 Codis,他们感到非常自豪。
当时 Codis 解决了很多公司的分布式缓存问题,这个项目在互联网公司使用很广泛,缓存的问题基本解决了,但是在底层关系型数据库扩展问题上还没有什么优雅的解决方案,黄东旭和刘奇就开始研究很多论文做了很多功课。直到看到了 Google 在 2012、13 年发表的两篇论文 Spanner 和 F1,他们认为未来数据库就应该是这个样子,从而萌生了做一套 NewSQL 系统的想法。不过当时二人所在公司的业务重点并不在这个领域,所以他们索性就出来单干了。
“我最早是在豌豆荚基础软件团队维护 MySQL 集群时有了这个想法。当时豌豆荚的整体技术架构比较朴素,上层用 Codis 支撑分布式缓存,底层数据库是 MySQL 和一部分 HBase 。当时 MySQL 大概有 16 个分片,就是最传统的分库分表。当时豌豆荚还没有全职 MySQL DBA ,维护 MySQL 就由我们基础架构团队负责。”黄东旭说,“当时我们非常痛苦,每一次数据库扩容和调整都感觉要掉一层皮。主生产库不能容忍停机,同时每一个分片有自己的储备,扩容一次不仅要把主节点拆分,还同时要在业务层上做拆分;而且在业务层有很多的工作,比如说语句的所有请求必须带着 Sharding Key ,不能做 Cross-shard 的事务或者稍微复杂的查询。当时大家很希望有办法解决这些问题。”
离开豌豆荚之后,两人就开始基于 Spanner+F1 的设计理念开发新一代分布式数据库 TiDB,并创立了 PingCAP。当然,从开发转向创业的过程并不容易,但从硅谷获得的宝贵经验也让 PingCAP 创始团队少走了不少弯路。“当时我们是三个人的原始团队,三个技术人员的创业被问到商业方面问题还比较头疼,但是我觉得让一个程序员学商业的东西,比教 Sales 写程序还是要简单不少(笑)。而且 OpenSource Business Model(开源的商业模式)在硅谷也是很成熟的商业模式 ,在美国像 Clouder, Docker, CoreOS 甚至 OpenStack 基金会等这些依托于开源项目的成功的公司也有很多,其商业模式是得到过验证的。”黄东旭说。
据黄东旭回忆,当时他们在周五决定创业,第二个周的周二就拿到了经纬天使轮投资,下午 5 点见的投资人,一拍即合,当天晚上 8 点就签了。

解决了后顾之忧,以技术驱动的 PingCAP 迅速进入发展正轨。随着 TiDB 项目的不断优化迭代,PingCAP 不断吸引着资本市场的青睐。2016 年 9 月,PingCAP 获得 A 轮 700 万美元融资;2017 年 6 月获得 B 轮 1500 万美元融资;2018 年 9 月获得 C 轮 5000 万美元融资;2020 年 11 月获得 D 轮 2.7 亿美元融资,创下全球数据库公司融资纪录。
现在的黄东旭依然奔走在分布式数据库技术的推广,以及自己一直以来所崇尚的开源精神的布道途中。2021 年 7 月,黄东旭将作为全球开源技术峰会 GOTC 分论坛出品人,为大家带来主题为“分布式数据库与存储”的系列演讲。
最新版本:5.0
TiDB 5.0 现已于2021年4月发布,该版本专注于帮助企业基于 TiDB 数据库快速构建应用程序,使企业在构建过程中无需担心数据库的性能、性能抖动、安全、高可用、容灾、SQL 语句的性能问题排查等问题。在 5.0 版本中,可以获得以下关键特性:
TiDB 通过 TiFlash 节点引入了 MPP 架构。这使得大型表连接类查询可以由不同 TiFlash 节点分担共同完成。当 MPP 模式开启后,TiDB 将会根据代价决定是否应该交由 MPP 框架进行计算。MPP 模式下,表连接将通过对 JOIN Key 进行数据计算时重分布(Exchange 操作)的方式把计算压力分摊到各个 TiFlash 执行节点,从而达到加速计算的目的。经测试,TiDB 5.0 在同等资源下,MPP 引擎的总体性能是 Greenplum 6.15.0 与 Apache Spark 3.1.1 两到三倍之间,部分查询可达 8 倍性能差异。
引入聚簇索引功能,提升数据库的性能。例如,TPC-C tpmC 的性能提升了 39%。
开启异步提交事务功能,降低写入数据的延迟。例如:Sysbench 设置 64 线程测试 Update index 时, 平均延迟由 12.04 ms 降低到 7.01ms ,降低了 41.7%。
通过提升优化器的稳定性及限制系统任务对 I/O、网络、CPU、内存等资源的占用,降低系统的抖动。例如:测试 8 小时,TPC-C 测试中 tpmC 抖动标准差的值小于等于 2%。
通过完善调度功能及保证执行计划在最大程度上保持不变,提升系统的稳定性。
引入 Raft Joint Consensus 算法,确保 Region 成员变更时系统的可用性。
优化 EXPLAIN 功能、引入不可见索引等功能帮助提升 DBA 调试及 SQL 语句执行的效率。
通过从 TiDB 备份文件到 Amazon S3、Google Cloud GCS,或者从 Amazon S3、Google Cloud GCS 恢复文件到 TiDB,确保企业数据的可靠性。
提升从 Amazon S3 或者 TiDB/MySQL 导入导出数据的性能,帮忙企业在云上快速构建应用。例如:导入 1TiB TPC-C 数据性能提升了 40%,由 254 GiB/h 提升到 366 GiB/h。
系统变量
新增系统变量 tidb_executor_concurrency,用于统一控制算子并发度。原有的 tidb_*_concurrency(例如 tidb_projection_concurrency)设置仍然生效,使用过程中会提示已废弃警告。
新增系统变量 tidb_skip_ascii_check,用于决定在写入 ASCII 字符集的列时,是否对字符的合法性进行检查,默认为 OFF。
新增系统变量 tidb_enable_strict_double_type_check,用于决定类似“double(N)”语法是否允许被定义在表结构中,默认为 OFF。
系统变量 tidb_dml_batch_size 的默认值由 20000 修改为 0,即在 LOAD/INSERT INTO SELECT ... 等语法中,不再默认使用 Batch DML,而是通过大事务以满足严格的 ACID 语义。
注意:
该变量作用域从 session 改变为 global,且默认值从 20000 修改为 0,如果应用依赖于原始默认值,需要在升级之后使用 set global 语句修改该变量值为原始值。
临时表的语法兼容性受到 tidb_enable_noop_functions 系统变量的控制:当 tidb_enable_noop_functions 为 OFF 时,CREATE TEMPORARY TABLE 语法将会报错。
新增 tidb_gc_concurrency、tidb_gc_enable、tidb_gc_life_time、tidb_gc_run_interval、tidb_gc_scan_lock_mode 系统变量,用于直接通过系统变量调整垃圾回收相关参数。
系统变量 enable-joint-consensus 默认值由 false 改成 ture,默认开启 Joint consensus 功能。
系统变量 tidb_enable_amend_pessimistic_txn 的值由数字 0 或者 1 变更成 ON 或者 OFF。
系统变量 tidb_enable_clustered_index 默认值由 OFF 改成 INT_ONLY 且含义有如下变化:
ON:开启聚簇索引,支持添加或者删除非聚簇索引。
OFF:关闭聚簇索引,支持添加或者删除非聚簇索引。
INT_ONLY:默认值,行为与 v5.0 以下版本保持一致,与 alter-primary-key = false 一起使用可控制 INT 类型是否开启聚簇索引。
5.0 GA 中 tidb_enable_clustered_index 的 INT_ONLY 值和 5.0 RC 中的 OFF 值含义一致,从已设置 OFF 的 5.0 RC 集群升级至 5.0 GA 后,将展示为 INT_ONLY。
配置文件参数
新增 index-limit 配置项,默认值为 64,取值范围是 [64, 512]。MySQL 一张表最多支持 64 个索引,如果该配置超过默认值并为某张表创建超过 64 个索引,该表结构再次导入 MySQL 将会报错。
新增 enable-enum-length-limit 配置项,用于兼容 MySQL ENUM/SET 元素长度并保持一致(ENUM 长度 < 255),默认值为 true。
删除 pessimistic-txn.enable 配置项,通过环境变量 tidb_txn_mode 替代。
删除 performance.max-memory 配置项,通过 performance.server-memory-quota 替代。
删除 tikv-client.copr-cache.enable 配置项,通过 tikv-client.copr-cache.capacity-mb 替代,如果配置项的值为 0.0 代表关闭此功能,大于 0.0 代表开启此功能,默认:1000.0。
删除 rocksdb.auto-tuned 配置项,通过 rocksdb.rate-limiter-auto-tuned 替代。
删除 raftstore.sync-log 配置项,默认会写入数据强制落盘,之前显式关闭 raftstore.sync-log,成功升级 v5.0 版本后,会强制改为 true。
gc.enable-compaction-filter 配置项的默认值由 false 改成 true。
enable-cross-table-merge 配置项的默认值由 false 改成 true。
rate-limiter-auto-tuned 配置项的默认值由 false 改成 true。
其他:为了避免造成数据正确性问题,列类型变更不再允许 VARCHAR 类型和 CHAR 类型的互相转换。
新功能
SQL、List 分区表 (List Partition)(实验特性)
用户文档
采用 List 分区表后,你可以高效地查询、维护有大量数据的表。
List 分区表会按照 PARTITION BY LIST(expr) PARTITION part_name VALUES IN (...) 表达式来定义分区,定义如何将数据划分到不同的分区中。分区表的数据集合最多支持 1024 个值,值的类型只支持整数型,不能有重复的值。可通过 PARTITION ... VALUES IN (...) 子句对值进行定义。可以设置 session 变量 tidb_enable_list_partition 的值为 ON,开启 List 分区表功能。
List COLUMNS 分区表 (List COLUMNS Partition)(实验特性)。
List COLUMNS 分区表是 List 分区表的变体,主要的区别是分区键可以由多个列组成,列的类型不再局限于整数类型,也可以是字符串、DATE 和 DATETIME 等类型。
可以设置 session 变量 tidb_enable_list_partition 的值为 ON,开启 List COLUMNS 分区表功能。
不可见索引(Invisible Indexes)
DBA 调试和选择相对最优的索引时,可以通过 SQL 语句将某个索引设置成 Visible 或者 Invisible,避免执行消耗资源较多的操作,如 DROP INDEX 或 ADD INDEX。DBA 通过 ALTER INDEX 语句可以修改某个索引的可见性。修改后,查询优化器会根据索引的可见性决定是否将此索引加入到索引列表中。
EXCEPT 和 INTERSECT 操作符
INTERSECT 操作符是一个集合操作符,返回两个或者多个查询结果集的交集。一定程度上可以替代 Inner Join 操作符。EXCEPT 操作符是一个集合操作符,返回两个查询结果集的差集,即在第一个查询结果中存在但在第二个查询结果中不存在的结果集。
事务
悲观事务模式下,如果事务所涉及到的表存在并发的 DDL 操作或者 SCHEMA VERSION 变更,系统自动将该事务的 SCHEMA VERSION 更新到最新版本,以此确保事务会提交成功,避免事务因并发的 DDL 操作或者 SCHEMA VERSION 变更而中断时客户端收到 Information schema is changed 的错误信息。
系统默认关闭此功能,你可以通过修改 tidb_enable_amend_pessimistic_txn 系统变量开启此功能,此功能从 4.0.7 版本开始提供,5.0 版本主要修复了以下问题:
TiDB Binlog 在执行 Add column 操作的兼容性问题
与唯一索引一起使用时存在的数据不一致性的问题
与添加索引一起使用时存在的数据不一致性的问题
当前此功能存在以下不兼容性问题:
并发事务场景下事务的语义可能发生变化的问题
与 TiDB Binlog 一起使用时,存在已知的兼容性问题
与 change column 功能不兼容
字符集和排序规则:支持 utf8mb4_unicode_ci 和 utf8_unicode_ci 排序规则。 用户文档,支持字符集比较排序时不区分大小写。
为满足各种安全合规(如《通用数据保护条例》(GDPR))的要求,系统在输出错误信息和日志信息时,支持对敏感信息(例如,身份证信息、信用卡号)进行脱敏处理,避免敏感信息泄露。TiDB 支持对输出的日志信息进行脱敏处理,你可以通过以下开关开启此功能:
全局系统变量 tidb_redact_log:默认值为 0,即关闭脱敏。设置变量值为 1 开启 tidb-server 的日志脱敏功能。
配置项 security.redact-info-log:默认值为 false,即关闭脱敏。设置配置项值为 true 开启 tikv-server 的日志脱敏功能。
配置项 security.redact-info-log:默认值为 false,即关闭脱敏。设置配置项值为 true 开启 pd-server 的日志脱敏功能。
配置项 security.redact_info_log(对于 tiflash-server)和配置项 security.redact-info-log(对于 tiflash-learner):两个配置项的默认值均为 false,即关闭脱敏。设置配置项值为 true 开启 tiflash-server 及 tiflash-learner 的日志脱敏功能。
此功能从 5.0 版本中开始提供,使用过程中必须开启以上所有系统变量及配置项。
性能优化
MPP 架构
TiDB 通过 TiFlash 节点引入了 MPP 架构。这使得大型表连接类查询可以由不同 TiFlash 节点分担共同完成。当 MPP 模式开启后,TiDB 会通过代价决策是否应该交由 MPP 框架进行计算。MPP 模式下,表连接将通过对 JOIN Key 进行数据计算时重分布(Exchange 操作)的方式把计算压力分摊到各个 TiFlash 执行节点,从而达到加速计算的目的。更进一步,加上之前 TiFlash 已经支持的聚合计算,MPP 模式下 TiDB 可以将一个查询的计算都下推到 TiFlash MPP 集群,从而借助分布式环境加速整个执行过程,大幅度提升分析查询速度。
经过 Benchmark 测试,在 TPC-H 100 的规模下,TiFlash MPP 提供了显著超越 Greenplum,Apache Spark 等传统分析数据库或数据湖上分析引擎的速度。借助这套架构,用户可以直接针对最新的交易数据进行大规模分析查询,且性能超越传统离线分析方案。经测试,TiDB 5.0 在同等资源下,MPP 引擎的总体性能是 Greenplum 6.15.0 与 Apache Spark 3.1.1 两到三倍之间,部分查询可达 8 倍性能差异。当前 MPP 模式不支持的主要功能如下(详细信息请参阅用户文档):
分区表、Window Function、Collation、部分内置函数、读取 TiKV 数据、OOM Spill、Union、Full Outer Join
聚簇索引
DBA、数据库应用开发者在设计表结构时或者分析业务数据的行为时,如果发现有部分列经常分组排序、返回某范围的数据、返回少量不同的值的数据、有主键列及业务数据不会有读写热点时,建议选择聚簇索引。
聚簇索引 (Clustered Index),部分数据库管理系统也叫索引组织表,是一种和表的数据相关联的存储结构。创建聚簇索引时可指定包含表中的一列或多列作为索引的键值。这些键存储在一个结构中,使 TiDB 能够快速有效地找到与键值相关联的行,提升查询和写入数据的性能。开启聚簇索引功能后,TiDB 性能在一些场景下会有较大幅度的提升。例如,TPC-C tpmC 的性能提升了 39%。聚簇索引主要在以下场景会有性能提升:
插入数据时会减少一次从网络写入索引数据。
等值条件查询仅涉及主键时会减少一次从网络读取数据。
范围条件查询仅涉及主键时会减少多次从网络读取数据。
等值或范围条件查询涉及主键的前缀时会减少多次从网络读取数据。
每张表既可以采用聚簇索引排序存储数据,也可以采用非聚簇索引,两者区别如下:
创建聚簇索引时,可指定包含表中的一列或多列作为索引的键值,聚簇索引根据键值对表的数据进行排序和存储,每张表只能有一个聚簇索引,当某张表有聚簇索引时,该表称为聚簇索引表。相反如果该表没有聚簇索引,称为非聚簇索引表。
创建非聚簇索引时,表中的数据存储在无序结构中,用户无需显式指定非聚簇索引的键值,系统会自动为每一行数据分配唯一的 ROWID,标识一行数据的位置信息,查询数据时会用 ROWID 定位一行数据。查询或者写入数据时至少会有两次网络 I/O,因此查询或者写入数据的性能相比聚簇索引会有所下降。
当修改表的数据时,数据库系统会自动维护聚簇索引和非聚簇索引,用户无需参与。
系统默认采用非聚簇索引,用户可以通过以下两种方式选择使用聚簇索引或非聚簇索引:
创建表时在语句上指定 CLUSTERED | NONCLUSTERED,指定后系统将按照指定的方式创建表。具体语法如下:
CREATE TABLE `t` (`a` VARCHAR(255), `b` INT, PRIMARY KEY (`a`, `b`) CLUSTERED);
或者:CREATE TABLE `t` (`a` VARCHAR(255) PRIMARY KEY CLUSTERED, `b` INT);
通过 SHOW INDEX FROM tbl-name 语句可查询表是否有聚簇索引。
设置 tidb_enable_clustered_index 控制聚簇索引功能,取值:ON|OFF|INT_ONLY
ON:开启聚簇索引,支持添加或者删除非聚簇索引。
OFF:关闭聚簇索引,支持添加或者删除非聚簇索引。
INT_ONLY:默认值,行为与 5.0 以下版本保持一致,与 alter-primary-key = false 一起使用可控制 INT 类型是否开启聚簇索引。
优先级方面,建表时有指定 CLUSTERED | NONCLUSTERED 时,优先级高于系统变量和配置项。
推荐创建表时在语句上指定 CLUSTERED | NONCLUSTERED 的方式使用聚簇索引和非聚簇索引,此方式对业务更加灵活,业务可以根据需求在同一个系统同时使用所有数据类型的聚簇索引和非聚簇索引。
不推荐使用 tidb_enable_clustered_index = INT_ONLY,原因是 INT_ONLY 是满足兼容性而临时设置的值,不推荐使用,未来会废弃。
聚簇索引功能有如下限制:
不支持聚簇索引和非聚簇索引相互转换。
不支持删除聚簇索引。
不支持通过 ALTER TABLE SQL 语句增加、删除、修改聚簇索引。
不支持重组织和重建聚簇索引。
不支持启用、禁用索引,也就是不可见索引功能对聚簇索引不生效。
不支持 UNIQUE KEY 作为聚簇索引。
不支持与 TiDB Binlog 一起使用。开启 TiDB Binlog 后 TiDB 只允许创建单个整数列作为主键的聚簇索引;已创建的聚簇索引表的数据插入、删除和更新动作不会通过 TiDB Binlog 同步到下游。
不支持与 SHARD_ROW_ID_BITS 和 PRE_SPLIT_REGIONS 属性一起使用。
集群升级回滚时,存量的表不受影响,新增表可以通过导入、导出数据的方式降级。
异步提交事务(Async Commit)
数据库的客户端会同步等待数据库系统通过两阶段 (2PC) 完成事务的提交,事务在第一阶段提交成功后就会返回结果给客户端,系统会在后台异步执行第二阶段提交操作,降低事务提交的延迟。如果事务的写入只涉及一个 Region,则第二阶段可以直接被省略,变成一阶段提交。开启异步提交事务特性后,在硬件、配置完全相同的情况下,Sysbench 设置 64 线程测试 Update index 时, 平均延迟由 12.04 ms 降低到 7.01ms ,降低了 41.7%。开启异步提交事务特性时,数据库应用开发人员可以考虑将事务的一致性从线性一致性降低到 因果一致性,减少 1 次网络交互降低延迟,提升数据写入的性能。开启因果一致性的 SQL 语句为 START TRANSACTION WITH CAUSAL CONSISTENCY。开启因果一致性后,在硬件和配置完全相同的情况下,Sysbench 设置 64 线程测试 oltp_write_only 时,平均延迟由 11.86ms 降低到 11.19ms,降低了 5.6%。
事务的一致性从线性一致性降低到因果一致性后,如果应用程序中多个事务之间没有相互依赖关系时,事务没有全局一致的顺序。
新创建的 5.0 集群默认开启异步提交事务功能。
从旧版本升级到 5.0 的集群,默认不开启该功能,你可以执行 set global tidb_enable_async_commit = ON; 和 set global tidb_enable_1pc = ON; 语句开启该功能。
异步提交事务功能有如下限制:
不支持直接降级
默认开启 Coprocessor cache 功能
5.0 GA 默认开启 Coprocessor cache 功能。开启此功能后,TiDB 会在 tidb-server 中缓存算子下推到 tikv-server 计算后的结果,降低读取数据的延时。
要关闭 Coprocessor cache 功能,你可以修改 tikv-client.copr-cache 的 capacity-mb 配置项为 0.0。
提升 delete * from table where id < ? limit ? 语句执行的性能
delete * from table where id < ? limit ? 语句执行的 p99 性能提升了 4 倍。
优化 load base 切分策略,解决部分小表热点读场景数据无法切分的性能问题。
稳定性提升
优化因调度功能不完善引起的性能抖动问题
TiDB 调度过程中会占用 I/O、网络、CPU、内存等资源,若不对调度的任务进行控制,QPS 和延时会因为资源被抢占而出现性能抖动问题
通过以下几项的优化,测试 8 小时,TPC-C 测试中 tpm-C 抖动标准差的值小于等于 2%
引入新的调度算分公式,减少不必要的调度,减少因调度引起的性能抖动问题
当节点的总容量总是在系统设置的水位线附近波动或者 store-limit 配置项设置过大时,为满足容量负载的设计,系统会频繁地将 Region 调度到其他节点,甚至还会调度到原来的节点,调度过程中会占用 I/O、网络、CPU、内存等资源,引起性能抖动问题,但这类调度其实意义不大。为缓解此问题,PD 引入了一套新的调度算分公式并默认开启,可通过 region-score-formula-version = v1 配置项切换回之前的调度算分公式。
默认开启跨表合并 Region 功能
在 5.0 之前,TiDB 默认关闭跨表合并 Region 的功能。从 5.0 起,TiDB 默认开启跨表合并 Region 功能,减少空 Region 的数量,降低系统的网络、内存、CPU 的开销。你可以通过修改 schedule.enable-cross-table-merge 配置项关闭此功能。
默认开启自动调整 Compaction 压缩的速度,平衡后台任务与前端的数据读写对 I/O 资源的争抢。在 5.0 之前,为了平衡后台任务与前端的数据读写对 I/O 资源的争抢,自动调整 Compaction 的速度这个功能默认是关闭的;从 5.0 起,TiDB 默认开启此功能并优化调整算法,开启之后延迟抖动比未开启此功能时的抖动大幅减少。
可以通过修改 rate-limiter-auto-tuned 配置项关闭此功能。
默认开启 GC in Compaction filter 功能,减少 GC 对 CPU、I/O 资源的占用
TiDB 在进行垃圾回收和数据 Compaction 时,分区会占用 CPU、I/O 资源,系统执行这两个任务过程中存在数据重叠。
GC Compaction Filter 特性将这两个任务合并在同一个任务中完成,减少对 CPU、I/O 资源的占用。系统默认开启此功能,你可以通过设置 gc.enable-compaction-filter = false 关闭此功能。
TiFlash 限制压缩或整理数据占用 I/O 资源(实验特性)
该特性能缓解后台任务与前端的数据读写对 I/O 资源的争抢。
系统默认关闭该特性,你可以通过 bg_task_io_rate_limit 配置项开启限制压缩或整理数据 I/O 资源。
增强检查调度约束的性能,提升大集群中修复不健康 Region 的性能。
保证执行计划在最大程度保持不变,避免性能抖动。
SQL BINDING 支持 INSERT、REPLACE、UPDATE、DELETE 语句
在数据库性能调优或者运维过程中,如果发现因为执行计划不稳定导致系统性能不稳定时,你可以根据自身的经验或者通过 EXPLAIN ANALYZE 测试选择一条人为优化过的 SQL 语句,通过 SQL BINDING 将优化过的 SQL 语句与业务代码执行的 SQL 语句绑定,确保性能的稳定性。
通过 SQL BINDING 语句手动的绑定 SQL 语句时,你需要确保优化过的 SQL 语句的语法与原来 SQL 语句的语法保持一致。你可以通过 SHOW {GLOBAL | SESSION} BINDINGS 命令查看手工、系统自动绑定的执行计划信息。输出信息基本跟 5.0 之前的版本保持一致。
自动捕获、绑定执行计划
在升级 TiDB 时,为避免性能抖动问题,你可以开启自动捕获并绑定执行计划的功能,由系统自动捕获并绑定最近一次执行计划然后存储在系统表中。升级完成后,你可以通过 SHOW GLOBAL BINDINGS 导出绑定的执行计划,自行分析并决策是否要删除绑定的执行计划。系统默认关闭自动捕获并绑定执行计划的功能,你可以通过修改 Server 或者设置全局系统变量 tidb_capture_plan_baselines = ON 开启此功能。开启此功能后,系统每隔 bind-info-lease (默认 3 秒)从 Statement Summary 抓取出现过至少 2 次的 SQL 语句并自动捕获、绑定。
TiFlash 查询稳定性提升
新增系统变量 tidb_allow_fallback_to_tikv,用于决定在 TiFlash 查询失败时,自动将查询回退到 TiKV 尝试执行,默认为 OFF。
TiCDC 稳定性提升,缓解同步过多增量变更数据的 OOM 问题
自 v4.0.9 版本起,TiCDC 引入变更数据本地排序功能 Unified Sorter。在 5.0 版本,默认开启此功能以缓解类似场景下的 OOM 问题:
场景一:TiCDC 数据订阅任务暂停中断时间长,其间积累了大量的增量更新数据需要同步。
场景二:从较早的时间点启动数据订阅任务,业务写入量大,积累了大量的更新数据需要同步。
Unified Sorter 整合了老版本提供的 memory、file sort-engine 配置选择,不需要用户手动配置变更的运维操作。
限制与约束:用户需要根据业务数据更新量提供充足的磁盘空间,推荐使用大于 128G 的 SSD 磁盘。
高可用和容灾:提升 Region 成员变更时的可用性。
Region 在完成成员变更时,由于“添加”和“删除”成员操作分成两步,如果两步操作之间有故障发生会引起 Region 不可用并且会返回前端业务的错误信息。TiDB 引入的 Raft Joint Consensus 算法将成员变更操作中的“添加”和“删除”合并为一个操作,并发送给所有成员,提升了 Region 成员变更时的可用性。在变更过程中,Region 处于中间的状态,如果任何被修改的成员失败,系统仍然可以使用。系统默认开启此功能,你可以通过 pd-ctl config set enable-joint-consensus 命令设置选项值为 false 关闭此功能。
优化内存管理模块,降低系统 OOM 的风险
跟踪统计聚合函数的内存使用情况,系统默认开启该功能,开启后带有聚合函数的 SQL 语句在执行时,如果当前查询内存总的使用量超过 mem-quota-query 阈值时,系统自动采用 oom-action 定义的相应操作。
提升系统在发生网络分区时的可用性
数据迁移
从 S3/Aurora 数据迁移到 TiDB
数据迁移类工具支持 Amazon S3(也包含支持 S3 协议的其他存储服务)作为数据迁移的中间转存介质,同时支持将 Aurora 快照数据直接初始化 TiDB 中,丰富了数据从 Amazon S3/Aurora 迁移到 TiDB 的选择。
TiDB Cloud 数据导入性能优化
数据导入工具 TiDB Lightning 针对 TiDB Cloud AWS T1.standard 配置(及其等同配置)的 TiDB 集群进行了数据导入性能优化,测试结果显式使用 TiDB Lightning 导入 1TB TPC-C 数据到 TiDB,性能提升了 40%,由 254 GiB/h 提升到了 366 GiB/h。
TiDB 数据共享订阅
TiCDC 集成第三方生态 Kafka Connect (Confluent Platform)(实验特性)
为满足将 TiDB 的数据流转到其他系统以支持相关的业务需求,该功能可以把 TiDB 数据流转到 Kafka、Hadoop、 Oracle 等系统。Confluent 平台提供的 kafka connectors 协议支持向不同协议关系型或非关系型数据库传输数据,在社区被广泛使用。TiDB 通过 TiCDC 集成到 Confluent 平台的 Kafka Connect,扩展了 TiDB 数据流转到其他异构数据库或者系统的能力。
TiCDC 支持 TiDB 集群之间环形同步(实验特性)
由于地理位置差异导致的通讯延迟等问题,存在以下场景:用户部署多套 TiDB 集群到不同的地理区域来支撑其当地的业务,然后通过各个 TiDB 之间相互复制,或者汇总复制数据到一个中心 TiDB hub,来完成诸如分析、结算等业务。
TiCDC 支持在多个独立的 TiDB 集群间同步数据。比如有三个 TiDB 集群 A、B 和 C,它们都有一个数据表 test.user_data,并且各自对它有数据写入。环形同步功能可以将 A、B 和 C 对 test.user_data 的写入同步到其它集群上,使三个集群上的 test.user_data 达到最终一致。
该功能适用于以下场景:
多套 TiDB 集群之间相互进行数据备份,灾难发生时业务切换到正常的 TiDB 集群
跨地域部署多套 TiDB 集群支撑当地业务,TiDB 集群之间的同一业务表之间数据需要相互复制
限制与约束:
无法支持业务在不同集群写入使用自增 ID 的业务表,数据复制会导致业务数据相互覆盖而造成数据丢失
无法支持业务在不同集群写入相同业务表的相同数据,数据复制会导致业务数据相互覆盖而造成数据丢失
问题诊断
在排查 SQL 语句性能问题时,需要详细的信息来判断引起性能问题的原因。5.0 版本之前,EXPLAIN 收集的信息不够完善,DBA 只能通过日志信息、监控信息或者盲猜的方式来判断问题的原因,效率比较低。
5.0 版本中,通过以下几项优化提升排查问题的效率:
支持对所有 DML 语句使用 EXPLAIN ANALYZE 语句以查看实际的执行计划及各个算子的执行详情。#18056
支持对正在执行的 SQL 语句使用 EXPLAIN FOR CONNECTION 语句以查看实时执行状态,例如各个算子的执行时间、已处理的数据行数等。#18233
EXPLAIN ANALYZE 语句显示的算子执行详情中新增算子发送的 RPC 请求数、处理锁冲突耗时、网络延迟、RocksDB 已删除数据的扫描量、RocksDB 缓存命中情况等。#18663
慢查询日志中自动记录 SQL 语句执行时的详细执行状态,输出的信息与 EXPLAIN ANALYZE 语句输出信息保持一致,例如各个算子消耗的时间、处理数据行数、发送的 RPC 请求数等。#15009
部署及运维:优化集群部署操作逻辑,帮助 DBA 更快地部署一套标准的 TiDB 生产集群
DBA 在使用 TiUP 部署 TiDB 集群过程发现环境初始化比较复杂、校验配置过多,集群拓扑文件比较难编辑等问题,导致 DBA 的部署效率比较低。5.0 版本通过以下几个事项提升 DBA 部署 TiDB 的效率:
TiUP Cluster 支持使用 check topo.yaml 命令,进行更全面一键式环境检查并给出修复建议。
TiUP Cluster 支持使用 check topo.yaml --apply 命令,自动修复检查过程中发现的环境问题。
TiUP Cluster 支持 template 命令,获取集群拓扑模板文件,供 DBA 编辑且支持修改全局的节点参数。
TiUP 支持使用 edit-config 命令编辑 remote_config 参数配置远程 Prometheus。
TiUP 支持使用 edit-config 命令编辑 external_alertmanagers 参数配置不同的 AlertManager。
在 tiup-cluster 中使用 edit-config 子命令编辑拓扑文件时允许改变配置项值的数据类型。
提升升级稳定性
TiUP v1.4.0 版本以前,DBA 使用 tiup-cluster 升级 TiDB 集群时会导致 SQL 响应持续长时间抖动,PD 在线滚动升级期间集群 QPS 抖动时间维持在 10~30s。TiUP v1.4.0 版本调整了逻辑,优化如下:
升级 PD 时,会主动判断被重启的 PD 节点状态,确认就绪后再滚动升级下一个 PD 节点。
主动识别 PD 角色,先升级 follower 角色 PD 节点,最后再升级 PD Leader 节点。
优化升级时长
TiUP v1.4.0 版本以前,DBA 使用 tiup-cluster 升级 TiDB 集群时,对于节点数比较多的集群,整个升级的时间会持续很长,不能满足部分有升级时间窗口要求的用户。从 v1.4.0 版本起,TiUP 进行了以下几处优化:
新版本 TiUP 支持使用 tiup cluster upgrade --offline 子命令实现快速的离线升级。
对于使用滚动升级的用户,新版本 TiUP 默认会加速升级期间 Region Leader 的搬迁速度以减少滚动升级 TiKV 消耗的时间。
运行滚动升级前使用 check 子命令,对 Region 监控状态的检查,确保集群升级前状态正常以减少升级失败的概率。
支持断点功能
TiUP v1.4.0 版本以前,DBA 使用 tiup-cluster 升级 TiDB 集群时,如果命令执行中断,那么整个升级操作都需重新开始。新版本 TiUP 支持使用 tiup-cluster replay 子命令从断点处重试失败的操作,以避免升级中断后所有操作重新执行。
增强运维功能
新版本 TiUP 进一步强化了 TiDB 集群运维的功能:
支持对已停机的 TiDB 和 DM 集群进行升级或 patch 操作,以适应更多用户的使用场景。
为 tiup-cluster 的 display 子命令添加 --version 参数用于获取集群版本。
在被缩容的节点中仅包含 Prometheus 时不执行更新监控配置的操作,以避免因 Prometheus 节点不存在而缩容失败
在使用 TiUP 命令输入结果不正确时将用户输入的内容添加到错误信息中,以便用户更快定位问题原因。
TiDB 在遥测中新增收集集群的使用指标,包括数据表数量、查询次数、新特性是否启用等。若要了解所收集的信息详情及如何禁用该行为,可参见遥测文档。
更多更新说明请参考此处。
最新版本:5.2
TiDB 5.2 现已于2021年8月未旬发布。在该版本中可以获得以下关键特性:
支持基于部分函数创建表达式索引 (Expression index),极大提升查询的性能。
提升优化器的估算准确度 (Cardinality Estimation),有助于选中最优的执行计划。
锁视图 (Lock View) 成为 GA 特性,提供更直观方便的方式观察事务加锁情况以及排查死锁问题。
新增 TiFlash I/O 限流功能,提升 TiFlash 读写稳定性。
为 TiKV 引入新的流控机制代替之前的 RocksDB write stall 流控机制,提升 TiKV 流控稳定性。
简化 Data Migration (DM) 工具运维,降低运维管理的成本。
TiCDC 支持 HTTP 协议 OpenAPI 对 TiCDC 任务进行管理,在 Kubernetes 以及 On-Premises 环境下提供更友好的运维方式(实验特性)。
最新版本:7.4
于2023年10月发行,正式兼容 MySQL 8.0。Oracle 官宣将在 2023 年 10 月终止 MySQL 5.7 版本的官方技术支持。据第三方统计显示,目前仍有超过一半的 MySQL 服务器运行在 5.7 版本。在未来几个月,大量的 MySQL 实例必须升级至 8.0 及更高版本,否则将无法享受 Oracle 提供的技术支持和重要补丁更新,企业级用户将面临重大考验。TiDB 作为新一代分布式关系型数据库,从诞生第一天起拥抱 MySQL 生态,不断地兼容 MySQL 5.7 和 MySQL 8.0,为用户带来更加顺畅的迁移和使用体验。本文将介绍 TiDB 7.4 DMR 在 MySQL 8.0 兼容方面的新进展,探讨其如何从根本上解决 MySQL 用户面临的各种挑战,MySQL用户的五大挑战有如下:
1.升级影响业务连续性。单实例或 "主从模式" 运行的 MySQL 升级时会造成数据库服务的停机,可能会对业务运营造成冲击。运行着大量 MySQL 实例的企业级用户,为了应对升级存在的潜在风险,需要投入大量的人力、物力进行测试和演练。
2.业务规模扩展困难。随着业务规模的扩大和数据使用场景的增多,用户通常需要在单机容量限制和分片管理复杂度之间进行权衡,数据库扩展的难度制约了业务规模和发展速度。
3.缺乏极致高可用方案。对于支撑核心业务场景的 MySQL 数据库来说,如果遇到不可预测的宕机事件,恢复业务变得复杂,达成极低的恢复时间目标(RTO)成为数据库管理员的挑战。
4.实时分析能力不足。MySQL 在处理大规模数据实时分析时性能不如在 OLTP(联机事务处理)场景下出色。这对于需要进行复杂查询和数据分析的业务是一个挑战。
5.原厂托管服务受限。虽然云服务商都会提供 MySQL 托管服务,但大多缺乏 Oracle 原厂的官方支持。这意味着在处理深层次的产品问题和发现通用功能需求时,用户无法获得来自数据库原厂的快速反馈和支持。
因此迁移到一个成熟的产品并一举解决上述难题,无疑是明智之举。TiDB 就是 MySQL 全面升级的理想之选。选择它不仅可以摆脱 MySQL 升级和扩展性的困境,还能够享受 HTAP、数据库整合等多方面的额外收益。
TiDB 是由 PingCAP 自主研发的企业级分布式关系型数据库,具备水平扩缩容、金融级高可用、实时 HTAP、云原生、兼容 MySQL 5.7 协议和生态等重要特性。TiDB 采用原生分布式架构设计,具备灵活的弹性伸缩能力,整个过程对业务透明,无需人工干预。TiDB 的多副本存储和 Multi-Raft 协议确保数据的强一致性和高可用性,在部分副本发生故障时不影响数据的可用性。TiDB 通过滚动升级的方式使得版本更新的影响降至最低,此外可采用增加临时节点的方式,确保 TiDB 在升级过程中的性能波动和连接闪断控制在 5% 以内,大幅降低升级对业务的影响。另外,作为 TiDB 的缔造者,PingCAP 基于全球领先云服务商推出数据库托管服务 TiDB Cloud,服务支持涵盖复杂问题诊断、升级支持、紧急救援等,充分体现了原厂服务的优势。从项目初期开始,TiDB 坚持拥抱 MySQL 生态的产品战略一直延续至今。其兼容 MySQL 的 wire protocol 和语法命令,这意味着 MySQL 客户端、驱动程序以及部分工具可以直接在 TiDB 上运行。对于绝大多数在 MySQL 上运行的应用程序来说,几乎不需要修改任何代码。随着 MySQL 8.0 的发布,TiDB 在兼容 MySQL 5.7 的基础之上,积极扩展了对 MySQL 8.0 的兼容。TiDB v7.4.0 版本发布了对 MySQL 8.0 常用功能的支持,这使得平滑迁移 MySQL 8.0 的应用变得轻而易举。本文列举了部分功能:
1、公共表表达式(CTE)
作为 MySQL 8.0 引入的重要能力,TiDB 从 5.1 版本开始支持 ANSI SQL 99 标准的 CTE 及其递归的写法。在编写复杂查询的时候,利用公共表表达式 (CTE) 可以构建一个临时的中间结果集,在 SQL 语句中引用多次,提高 SQL 语句编写效率,可读性,执行效率。目前版本中,TiFlash 也同样支持 CTE。比如表 authers 保存了作家的信息,book_authors 记录了作家 id 与其所编写书籍 id 的对应关系。
mysql> desc authors;
+------------+--------------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+--------------+------+------+---------+-------+
| id | bigint(20) | NO | PRI | NULL | |
| name | varchar(100) | NO | | NULL | |
| gender | tinyint(1) | YES | | NULL | |
| birth_year | smallint(6) | YES | | NULL | |
| death_year | smallint(6) | YES | | NULL | |
+------------+--------------+------+------+---------+-------+
mysql> desc book_authors;
+-----------+------------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+------------+------+------+---------+-------+
| book_id | bigint(20) | NO | PRI | NULL | |
| author_id | bigint(20) | NO | PRI | NULL | |
+-----------+------------+------+------+---------+-------+
利用 CTE 能够很容易编写出 SQL,列出最年长的 50 位作家分别编写过多少书籍
mysql> WITH top_50_eldest_authors_cte AS (
-> SELECT a.id, a.name, (IFNULL(a.death_year, YEAR(NOW())) - a.birth_year) AS age
-> FROM authors a
-> ORDER BY age DESC
-> LIMIT 50
-> )
-> SELECT
-> ANY_VALUE(ta.id) AS author_id,
-> ANY_VALUE(ta.age) AS author_age,
-> ANY_VALUE(ta.name) AS author_name,
-> COUNT(*) AS books
-> FROM top_50_eldest_authors_cte ta
-> LEFT JOIN book_authors ba ON ta.id = ba.author_id
-> GROUP BY ta.id;
+-----------+------------+----------------------+-------+
| author_id | author_age | author_name | books |
+-----------+------------+----------------------+-------+
| 524470241 | 80 | Alexie Kirlin | 7 |
| 67511645 | 80 | Bridgette Tromp | 9 |
...
| 48355494 | 80 | Audrey Mayert | 7 |
+-----------+------------+----------------------+-------+
50 rows in set (0.23 sec)
相关文档:https://docs.pingcap.com/zh/tidb/stable/dev-guide-use-common-table-expression
2、窗口函数 (window function)
窗口函数 (Window Function),又被叫做分析函数, 在对数据进行分析、汇总、排序时会被用到。窗口函数能够以 SQL 形式的写法,来完成一些复杂的数据整理工作,协助用户发掘数据价值。例如数据分组排序, 变化趋势分析等。TiDB 目前已经完整支持了 MySQL 8.0 提供的窗口函数,大部分可以下推到 TiFlash 运行。
相关文档:https://docs.pingcap.com/zh/tidb/stable/window-functions
3、资源管控
TiDB 在 7.1 版本引入了资源管控,目的是能够对集群资源做合理分配,提升数据库的稳定性,并降低数据库的使用成本。在多个应用共享一个 TiDB 集群的场景下,资源隔离可以有效降低应用负载变化对其他应用产生的影响,资源管理还能解决批量作业及后台任务对核心业务的影响,以及突发的 SQL 性能问题拖慢整个集群,是提升大集群稳定性的重要能力。尽管和 MySQL 的实现方式有差别,TiDB 兼容了 MySQL 指定资源组的语法以及 hint,降低用户学习成本和迁移成本。另外TiDB 的资源隔离能够更有效地对最重要的 I/O 资源进行管控,达到和 MySQL 同等甚至更好的效果。下面展示了利用资源管控,将 usr1 使用的所有资源控制在每秒 500 RU 以内。
● 预估集群容量
mysql> CALIBRATE RESOURCE
● 创建 app1 资源组,限额是每秒 500 RU
mysql> CREATE RESOURCE GROUP IF NOT EXISTS app1 RU_PER_SEC = 500;
● 将用户与资源组关联, usr1 的会话自动关联到资源组 app1
mysql> ALTER USER usr1 RESOURCE GROUP app1;
也可以修改会话所属的资源组
mysql> SET RESOURCE GROUP `app1`;
或者利用 hint RESOURCE_GROUP () 指定语句所属的资源组
mysql> SELECT /*+ RESOURCE_GROUP(rg1) */ * FROM t limit 10;
相关文档:https://docs.pingcap.com/zh/tidb/stable/tidb-resource-control
4、基于角色的权限管理
TiDB 支持 MySQL 兼容的角色管理。基于角色的授权,可以简化权限管理的工作,并降低了出错的风险。通过将权限与角色相关联,可以更好地控制数据库的访问。客户可以将不同场景的工作进行分类,创建对应角色,并把角色授予有权限的数据库用户, 数据库用户在实际操作时,根据场景不同,切换角色,降低误操作的可能。这里举一个利用角色拆分权限场景的例子。用户 dev_adm_usr 作为应用管理员,要操作数据库 app_db 的数据,多数情况下只是查询,偶尔在需要做数据修正的时候才会做修改。为了防止 dev_adm_usr 的误操作,我们将两部分权限利用角色拆开,只有必要的时候,才给自己赋予读写的角色。
● 创建角色 app_read_role 和 app_write_role
mysql> CREATE ROLE 'app_read_role', 'app_write_role';
● 为角色授予对应的权限,这里为两个角色分别授予 app_db 的读和写的权限
mysql> GRANT SELECT ON app_db.* TO 'app_read_role'@'%';
mysql> GRANT INSERT, UPDATE, DELETE ON app_db.* TO 'app_write_role'@'%';
● 将两个角色授予用户 dev_adm_usr
mysql> GRANT 'app_read_role','app_write_role' TO 'dev_adm_usr'@'localhost';
● 把 app_read_role 设为 dev_adm_usr 的默认角色,这样用户 dev_adm_usr 登录时默认是只读权限
mysql> SET DEFAULT ROLE 'app_read_role' TO 'dev_adm_usr'@'localhost';
● 当 dev_adm_usr 需要修改数据时,启用角色 app_write_role
mysql> SET ROLE app_read_role,app_write_role;
或者启用所有角色
mysql> SET ROLE ALL;
相关文档:https://docs.pingcap.com/zh/tidb/stable/role-based-access-control
5、增强 uft8mb4 字符集
MySQL 8.0 的一个重要变化是默认字符集变成了更通用的 uft8mb4,默认排序方式变为 utf8mb4_0900_ai_ci。TiDB 在新版本里也加入了 utf8mb4_0900_ai_ci 的排序方式,以便更轻松地进行系统迁移。为了同时兼容 MySQL 5.7 和 MySQL 8.0,TiDB 支持了 MySQL 兼容的变量 default_collation_for_utf8mb4。允许用户调整 utf8mb4 字符集的默认排序方式。这个方式确保了 TiDB 在不同 MySQL 版本之间的平滑过渡,并能够适应不同应用程序的需求。
如果从 MySQL 8.0 迁移,设为 8.0 默认排序 utf8mb4_0900_ai_ci
set global default_collation_for_utf8mb4='utf8mb4_0900_ai_ci';
如果从 MySQL 5.7 迁移,设为 5.7 为 utf8mb4 的默认排序 utf8mb4_general_ci
set global default_collation_for_utf8mb4='utf8mb4_general_ci';
6、JSON 多值索引 (Multi-valued Index)
在支持了 MySQL 5.7 的完整函数之后,TiDB 在不断添加对 MySQL 8.0 新发布功能的支持。最近的版本支持了 "多值索引",允许对 JSON 类型中的某个 "数组" 进行索引,从而提高了对 JSON 数据的检索效率。与 MySQL 用法完全相同,这意味着在迁移过程中,无需修改数据建模或应用程序,用户可以继续按照熟悉的方式操作 JSON 数据。
多值索引是对普通索引结构的延伸。不同于普通索引与表 1:1 的对应关系, 多值索引与表的对应是 N:1。与 MySQL 相同,条件中利用 MEMBER OF(),JSON_CONTAINS(),JSON_OVERLAPS() 这几个函数检索时,都可能会选择到多值索引。比如假定有一张客户信息表,所有详细信息以 JSON 格式编入一个 JSON 类型的列中, 其中有一个数组结构保存客户所在的几个城市。
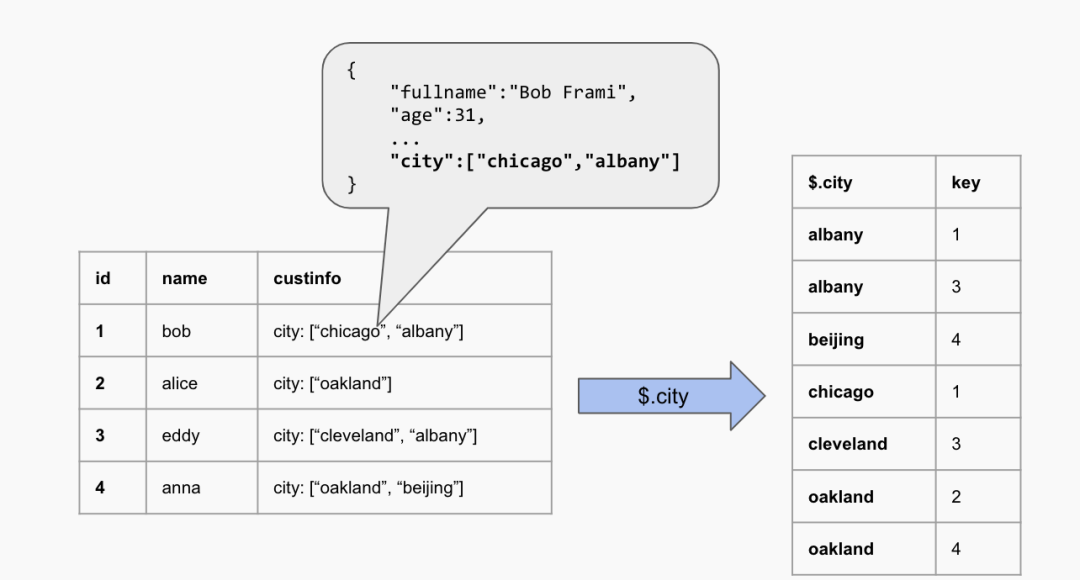
当我们需要检索哪些客户在北京时,如果没有多值索引,这个查询需要扫描整张表。
SELECT name FROM customer
WHERE 'beijing' MEMBER OF $.city;
这时我们可以针对 city 这个数组创建多值索引,上述查询就可以利用索引检索符合的记录,大幅提升查询性能。
ALTER TABLE customers add index idx_city (name, (CAST(custinfo->'$.city' AS char(20) ARRAY)));
和普通索引一样, 当优化器没有选择到多值索引时,可以利用优化器提示 USE_INDEX () 或 USE_INDEX_MERGE () 强制优化器做选择。
相关文档:https://docs.pingcap.com/zh/tidb/stable/choose-index# 使用多值索引
7、修改会话变量的 hint (SET_VAR ())
MySQL 8.0 引入了一个特殊的 hint SET_VAR ()。利用这个 hint,可以在语句运行期间修改某个会话级系统变量。TiDB 在 v7.4.0 也支持了这个 hint,提升了系统变量设置的灵活度, 能够针对 SQL 语句做 “定制”。包括优化器相关的,执行时相关的多个变量都支持用 hint 修改。比如针对大表的分析处理,适当增加 SQL 的执行并行度。
SELECT /*+ set_var(tidb_executor_concurrency=20) */
l_orderkey,
SUM(
l_extendedprice * (1 - l_discount)
) AS revenue,
o_orderdate,
o_shippriority
FROM
customer,
orders,
lineitem
WHERE
c_mktsegment = 'BUILDING'
AND c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate < DATE '1996-01-01'
AND l_shipdate > DATE '1996-02-01'
GROUP BY
l_orderkey,
o_orderdate,
o_shippriority
ORDER BY
revenue DESC,
o_orderdate
limit 10;
也可以利用这个 hint 强制刚才的查询选择 TiFlash,而其他查询保持不变。
SELECT /*+ set_var(tidb_isolation_read_engines='tidb,tiflash') */
l_orderkey,
SUM(
l_extendedprice * (1 - l_discount)
) AS revenue,
o_orderdate,
o_shippriority
FROM
customer,
orders,
lineitem
WHERE
c_mktsegment = 'BUILDING'
AND c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate < DATE '1996-01-01'
AND l_shipdate > DATE '1996-02-01'
GROUP BY
l_orderkey,
o_orderdate,
o_shippriority
ORDER BY
revenue DESC,
o_orderdate
limit 10;
相关文档:https://docs.pingcap.com/zh/tidb/v7.4/optimizer-hints#set_varvar_namevar_value
8、CHECK 约束
它是一致性约束检查的一种,用来维护数据的准确性。CHECK 约束可以用于限制表中某个字段的值必须满足指定条件。当为表添加 CHECK 约束后,在插入或者更新数据时,TiDB 会检查约束条件是否满足,如果不满足,则会报错。MySQL 在 8.0 之前只支持 CHECK 约束的语法,在实际运行中并不会真正去检查, 在 8.0 之后才全面支持。TiDB 在新版本中也添加了这个功能, 为了防止客户的 DDL 中有残存的 CHECK 条件,可能会因为这个特性产生问题,TiDB 默认并不会开启 CHECK 约束的检查,而是通过变量 tidb_enable_check_constraint 手工开启, 这充分体现了 TiDB 同时兼容 MySQL 5.7 和 8.0 的产品策略。
mysql> set global tidb_enable_check_constraint=on;
mysql> CREATE TABLE t
-> ( a INT CHECK(a > 10) NOT ENFORCED, -- 不生效 check
-> b INT,
-> c INT,
-> CONSTRAINT c1 CHECK (b > c)
-> );
mysql> insert into t values (20,20,20);
ERROR 3819 (HY000): Check constraint 'c1' is violated.
相关文档:https://docs.pingcap.com/zh/tidb/dev/constraints#check-%E7%BA%A6%E6%9D%9F
为了降低用户数据迁移的复杂度,TiDB 推出了一款工具 TiDB Data Migration (DM) 。它能够协助用户从与 MySQL 协议兼容的数据库(MySQL、MariaDB、Aurora MySQL)到 TiDB 的全量数据迁移和增量数据同步。DM 支持 DDL 同步,分库分表合并,并内置多种过滤器以灵活适应不同场景,切实地提升了数据迁移的效率。TiDB 7.4 将是 TiDB 7 系列最后一个 DMR 版本,针对 MySQL 8.0 做出了诸多优化。作为 MySQL 的全面升级,其技术领先性帮助用户应对不断变化的业务数据挑战,实现业务的持续增长和创新。TiDB 在高度兼容 MySQL 5.7 和 MySQL 8.0 特性的同时,也将持续提供技术支持,确保用户能够平滑地迁移各类业务应用程序,从而减少迁移过程中的工作量和风险。
官方主页:https://www.pingcap.com/index.html