分布式数据存储系统-CockroachDB
 CockroachDB (蟑螂数据库)是一个可伸缩的、支持地理位置处理、支持事务处理的数据存储系统。CockroachDB 是一个开源的云原生 SQL 数据库,也是一个可实现跨数据中心同步的可伸缩数据库。正如它的名字"CockroachDB"("小强DB")一样,官方在宣传中称该数据库是“具有超强生命力的数据库”。CockroachDB 的目标是提供一种稳定可靠的方式来让数据自动复制和同步到各个数据中心的服务器里,这样就算一个数据中心倒下了,应用还能正常运行。采用Go语言开发并在Apache协议下授权。
CockroachDB (蟑螂数据库)是一个可伸缩的、支持地理位置处理、支持事务处理的数据存储系统。CockroachDB 是一个开源的云原生 SQL 数据库,也是一个可实现跨数据中心同步的可伸缩数据库。正如它的名字"CockroachDB"("小强DB")一样,官方在宣传中称该数据库是“具有超强生命力的数据库”。CockroachDB 的目标是提供一种稳定可靠的方式来让数据自动复制和同步到各个数据中心的服务器里,这样就算一个数据中心倒下了,应用还能正常运行。采用Go语言开发并在Apache协议下授权。CockroachDB is the SQL database for building global, scalable cloud services that survive disasters.
CockroachDB 提供两种不同的的事务特性,包括快照隔离(snapshot isolation,简称SI)和顺序的快照隔离(SSI)语义,后者是默认的隔离级别。
CockroachDB是一个分布式的K/V数据仓库,支持ACID事务,多版本值存储是其首要特性。主要的设计目标是最终一致性和可靠性,从蟑螂的命名上是就能看出这点。蟑螂数据库能处理磁盘、物理机器、机架甚至数据中心失效情况下最小延迟的服务中断;整个失效过程无需人工干预。蟑螂的节点是均衡的,其设计目标是同质部署(只有一个二进制包)且最小配置。
蟑螂数据库实现了单一的、巨大的有序映射,键和值都是字节串形式(不是unicode),支持线性扩展,理论上支持4EB的逻辑数据)。映射有一个或者多个Range组成,每一个Range对应一个把数据存储在RocksDB(LevelDB的一个变种,Facebook贡献)上的K/V数据库,并且复制到三个或者更多蟑螂服务器上,Range定义为有开始和结束键值的区间。Range可以合并及分裂来维持总大小在一个全局配置的最大最小范围之间。Range的大小默认是64M,目的是便于快速分裂和合并,在一个热点键值区间快速分配负载。Range的复制确定为分离的数据中心来达到可靠性(比如如下分组:{ US-East, US-West, Japan }, { Ireland, US-East, US-West}, { Ireland, US-East, US-West, Japan, Australia })
Range有一种变化,通过分布式一致性算法实例来调节确保一致性,蟑螂所选择使用Raft一致性算法。所有的一致性状态存在于RocksDB中。据所提供的文档可以看出,这款产品有深刻的PostgreSQL背景。
CockroachDB在百度内部的应用与实践
内容来源:2017年11月18日,百度数据库架构师严龙在“第七届数据技术嘉年华”进行《百度NewSQL-CockroachDB》演讲分享。本次交流主要包括开源 NewSQL 数据库 Cockroach DB 关键技术分析以及 Cockroach DB 在百度内部的应用和实践。
NewSQL起源
对于MySQL、Oracle、PostgreSQL这样的单机数据库,随着数据量的增长在计算容量和存储容量上都会出现问题。于是后续又推出了基于中间件或者NoSQL的方案,但是都并非完美,比如中间件在分布式事务方面以及NoSQL在SQL接口和对事务的支持方面做了一定退让。
2011年分析师Matthew Aslett首次提出了NewSQL的概念,期望将NoSQL和传统的数据库的优势融合,将现有数据库存在的缺陷在下一代中解决掉。而Google首先将这一概念工程化,也就是Spanner。随后开源社区也陆续跟进。
Cockroach DB简介
Cockroach DB于2014年托管在GitHub,遵循Apache License,基于Golang实现。 母公司是Cockroach Labs,公司的三位创始人全部来自Google,有Big Table,GFS,Colossus,Gmail项目背景,已获得来自Benchmark,Google Venture等共计5325万的融资。总部位于纽约,目前有50+员工。
Cockroach DB架构
Cockroach DB采用类似Spanner的分层架构,在分布式KV上提供了SQL引擎,分布式KV之下引入了自身独有三个概念Node、Store、Range。
Node & Store
Node是Cockroach DB的进程实例,一台物理服务器启动一个Node即可,一个物理存储介质例如一块硬盘一般配置一个Store,一个Node中有多个Store。
Range
Range是Cockroach DB存储管理的最小单位,一个Range是一段键值区间的数据分片。一个Store中有多个Range,每个Range分片默认为64M,默认存在3个副本,分布在不同的Node上。
Cockroach DB特性
标准SQL接口
Cockroach DB使用PostgreSQL协议,支持标准SQL接口,兼容关系型数据库SQL生态。支持事务、二级索引、Join等NoSQL欠缺的特性,同时还供了类MPP的分布式查询框架。它还支持Schema在线变更,以方便应对业务的变化。
SQL & KV
由于Cockroach DB底层是分布式KV,那么必然就要将所有的SQL操作转换为KV操作。于是它就在底层抽象出了Get、Put、ConditionalPut、Scan、Del这五个KV作原语。
SQL / KV模型映射
解决完KV操作的问题后,还有另一个问题有待解决,即Schema到KV模型的映射。Cockroach DB的每个表都需要有一个Primary Key,每一列不是每行构成一个Key / Value存储单元,Key由<db>、<table>、<index>、<pkey>、<columnld>这几部分共同构成。
唯一索引
在KV存储中必须保证key全局唯一,这样就能方便前缀匹配。Cockroach DB为了实现唯一索引,首先会将<db>、<table>、<index>、<key>编码到Key中,当做索引扫描时就要进行前缀匹配,然后就能将相应的Value取出来。这里由于<key>是全局唯一的所以索引的唯一性也得以保证。
非唯一索引
对于非唯一索引Cockroach DB处理就比较巧妙了,它将行的<pkey>也编译到了Key中,这样对索引做前缀匹配时,只要相关的索引项匹配到index前面,就能将相应的<pKey>取出来,然后通过<pkey>反向索引到数据。
Column Family
在行存系统中数据的更新只需要进行一次IO操作,但是由于Cockroach DB是列存的,数据在更新时要进行多次IO。为此Cockroach DB提出了column family的概念,将需要被频繁访问的列封装到一起,甚至可以通过column family的方式退化到行存的方式,这样就能有效减少IO操作。
扩展能力强、高并发
为了实现线性扩展的能力,Cockroach DB采用了去中心化的架构,任意节点故障对于集群无影响。它通过Gossip协议实现节点状态管理,理论上单集群支持10K节点规模。两级路由元数据的方式使得单集群最大支撑4EB用户数据存储。整个架构中子模型都采用分布式设计,无单点瓶颈,支持多节点并发写入。
弹性伸缩
面对单机数据库扩展性的问题,一般采用哈希的数据分布方式。但是除非是使用的是一致性哈希,否则普通的哈希分布都需要有数据迁移和停服的过程。而Cockroach DB选择的是Range分布,在进行扩容时无需停服,直接可以在线扩展,同时因为每个数据都被划分为64M的小分片,所以在新节点加入时能做到业务无感知的自动负载均衡多副本强一致性。
MySQL数据同步采用的主从复制架构是弱一致性的,而Cockroach DB的副本数据同步是基于Raft协议,具有强一致性,不会出现当某个节点挂了同时redolog还没有完全复制到从库上导致数据丢失的问题。
服务高可用
Cockroach DB由于架构上去中心化,没有SPDF,所以架构不存在类似Hbase HMaster和Percolator oracle等集中模块,单节点故障也不影响集群群体的可用性。
另外因为基于Raft协议,所以只要半数以上副本存活,则服务可用;当节点异常,数据副本数量少于指定阈值时,自动补齐副本,保证可靠性。
分布式事务
2PC
Cockroach DB使用的是改造过的两阶段提交事务,它引入全局事务表记录事务状态,事务提交/回滚只修改记录的标记位。事务中写入的数据被封装成特殊结构INTENT,这个INTENT中隐含着索引信息可以反向索引事务状态。这种事务处理模型的好处在于事务提交、回滚开销比较小。
1PC
当所有的事务都是写在一个Range上时,可以利用Raft保证原子性,一次完成数据写入。同时能够优化非跨Range写事务性能,减少RPC通信。
MVCC
Cockroach DB使用MVCC的并发控制模式,它以HLC时间作版本号,逆序存储保证最新版本数据优先被访问。支持Time-Travel Query,多版本数据由异步GC清理。
HLC算法
HLC算综合借鉴了Physical Clock和Logical Clock思想。HLC Timestamp ID由时间和逻辑时间两部分组成,物理时间通过NTP同步。在发送消息、产生本地事件和接收到消息时,I、J都会被重置为几个参考值中的最大值。这样消除了单点时钟逆变或不同节点间时钟误差的影响。
HLC是基于NTP的,但它只会读取当前系统时间,而不会去修改,同时HLC又能保证在NTP出现同步问题的时候仍能够很好的进行容错处理。对于一个HLC的时间t来时,它总是大于等于当前的系统时间,并且与其在一个很小的误差范围里面,也就是 |l - pt| < ε。
HLC由两部分组成,physical clock + logic clock,l.j维护的是节点j当前已知的最大的物理时间,c.j则是当前的逻辑时间。那么判断两个事件的先后顺序就很容易了,先判断物理时间pt,在判断逻辑时间ct。
HLC的正确性很大程度上依赖于NTP服务的授时精度。当NTP服务变得不可靠时,HLC也做一定程度上的容忍,消除NTP服务不可用带来的影响。HLC算法不修改本地物理时间,本地物理时间通过主板上的晶振仍然能在一定时间内保证授时精度不会出现太大的偏差,能保证有足够时间恢复NTP服务。其次任一节点收到一个消息(事务)携带的HLC时间和当前节点的偏差超过Maxoffset,该节点可拒绝此消息(事务)防止该异常的HLC时间扩散。CockroachDB节点同时会定期搜集各个节点的HLC时间,如果当前节点和一半以上节点时间偏差超过Maxoffset,当前节点拒绝外部请求并下线。简而言之,MaxOffset只是在限制节点时间偏差,在超过这个偏差时对相应节点做出相应的处理。CockroachDB要求Maxoffset ≥ 物理时钟偏差(即NTP时间同步精度偏差)。
与True Time时钟算法比较
HCL算法实现简单、成本低,有一定时延。它基于NTP时钟服务,不需要额外的硬件,算法简单,实现成本低。不过存在时钟偏差,广域网情况下偏差范围会比较大。
True Time时钟算法有一定成本、时延低。它基于GPS+原子钟等特殊硬件,实现成本较高。本质上类似Physical clock时钟算法,以一个误差区间来替代时刻点。True Time时钟系统精度远远高于NTP,可将时延控制在14ms内。NTP是有误差的,而且NTP还可能出现时间回退的情况,所以我们不能直接依赖NTP来确定一个事件发生的时间。在Google Spanner里面,通过引入True Time来解决了分布式时间问题。
Spanner通过使用GPS + Atomic Clock来对集群的机器进行校时,精度误差范围能控制在ms级别,通过提供一套TrueTime API给外面使用。但spanner有一个最大的问题,TrueTime是基于硬件的,而现在对于很多企业来说,是没有办法搞定这套部署的。
CockroachDB使用HLC追踪事务之间的hb关系,使其能用一个确定的HLC时间获取一个一致的Snapshot来实现事务模型。CockroachDB也可以使用和Spanner同样的Commit-Wait机制来实现事务的Linearizability,但是由于NTP服务的精度问题,这个特性不建议开启。
典型应用场景
Cockroach DB比较适合OLTP场景,同时支持轻量级别OLAP场景。这些场景有如下特点:
-高并发读写,支持多点写入,自动负载均衡
-大数据量存储
-随时按需扩展、在线扩容
-跨数据中心容灾,多副本数据强一致
-时延要求不苛刻
应用案例
在之前百度内部是通过中间件的方式做数据的分片,但是当要扛峰值流量时就要预先扩容。而且在业务层做数据访问时,必须按照固定的规则才能访问数据,不能跨片做分布式事务。在引入Cockroach DB之后我们就能对业务提供统一的数据库视图,使用起来也更简单,更易于运维。在引入Cockroach DB之前我们还做了MySQL语法协议兼容、数据同步、自动化运维的工作。
最新版本:2.0
2018 年 4 月,CockroachDB 2.0 版本正式发布,带来全新升级。作为 CockroachDB 2.x 系列的第一个版本,CockroachDB 2.0 极大提升了性能,并带来了一系列新特性。
企业版特性
表分区功能:允许用户对数据做行级别的分区和存储地域的控制,减少访问延时
集群拓扑图:在 Admin UI 上新增的 Node Map 功能,能实时呈现集群拓扑信息
基于角色的访问控制:简化访问控制方式,允许对用户组统一授权
实时备份恢复:使用备份数据恢复到指定时间点状态
核心特性
支持 JSON 格式的数据存储
Sequences 功能:按照自定义规则定义一组序列化的整数,主要用作数字类型主键
SQL 审查日志功能:打印 SQL 的详细执行信息
支持 Common Table Expressions(CTEs),允许为一条复杂子查询语句命名,提升 SQL 代码的可读性
支持计算列,用于存储由其他列计算生成的列数据
支持外键相关的删除和更新操作
Virtual Schemas:从 2.0 开始支持三个层次的结构命名 database name > virtual schema name > object name
IMPORT 功能增强:完全分布式导入 tabular data,并且 IMPORT 任务可以被暂停、取消和重启
支持 INET 类型,用于存储 IPv4 或者 IPv6 类型地址
支持 TIME 类型,用于存储不带时区的时间
……
使用 TPC-C 标准分别对 CockroachDB 2.0 和 Amazon Aurora 测试吞吐量与 warehouses 数量的关系,数据表明 CockroachDB 2.0 性能更好,测试结果见下图:
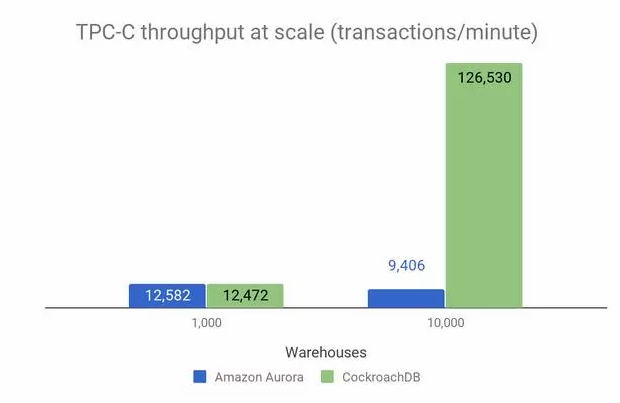
从 2.0 开始,CockroachDB 支持 Geo-partitioning 功能。用户可根据业务需要跨区域部署 CockroachDB 集群,同时可自定义数据部署策略,将数据部署在离业务最近的数据中心,改善访问延时。
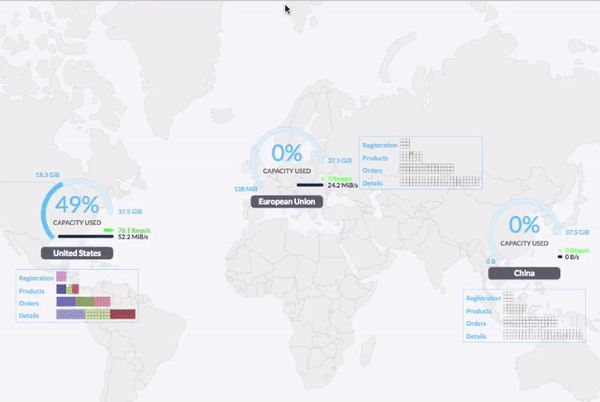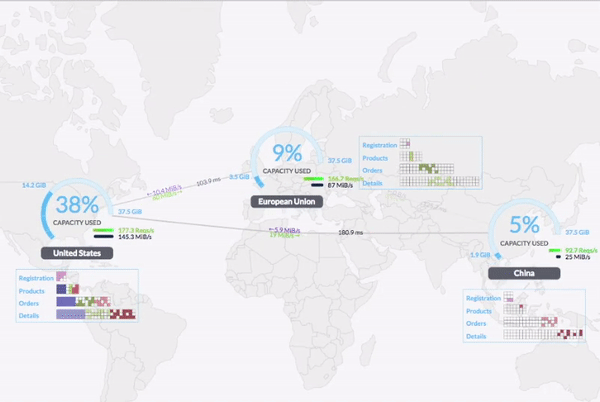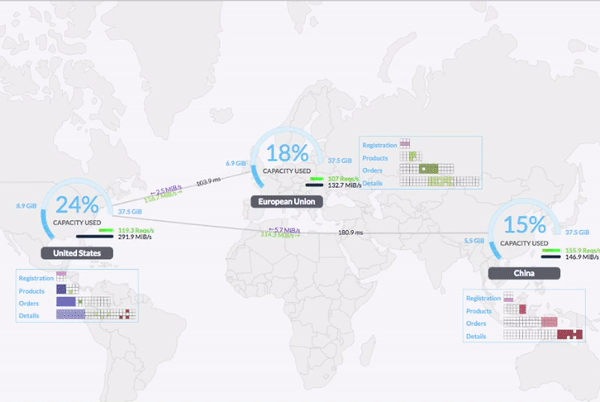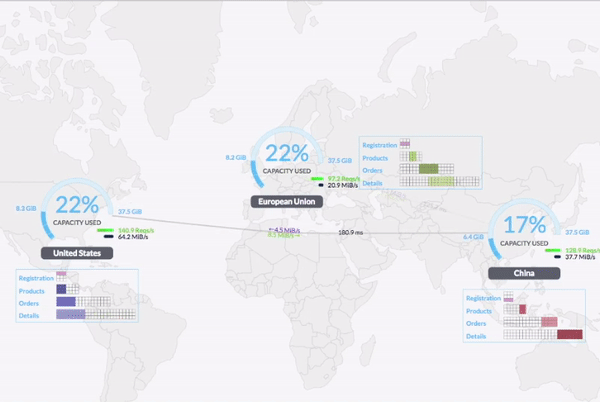
更多详情请参见官方 Release Notes
官方 Blog
CockroachDB 2.0 的部署与升级
[pdf]cockroachdb使用的算法
官方主页:https://www.cockroachlabs.com/