PostgreSQL最常见问题
 常见问题
常见问题1.1)PostgreSQL 是什么?该怎么发音?
PostgreSQL 读作 Post-Gres-Q-L,有时候也简称为Postgres 。
它是面向目标的关系数据库系统,它具有传统商业数据库系统的所有功能,同时又含有将在下一代 DBMS 系统的使用的增强特性。同时也是自由免费的,并且所有源代码都可以获得。开发队伍主要为志愿者,他们遍布世界各地并通过互联网进行联系,这是一个社区开发项目,它不被任何公司控制。 如想加入开发队伍,请参见开发人员常见问题(FAQ)。
1.2)PostgreSQL 的版权是什么?
其发布遵从经典的BSD版权。关于源代码的如何使用没有任何限制,我们很喜欢这种方式并且还没有打算改变它。
下面就是我们使用的BSD版权内容:
部分版权(c)1996-2005,PostgreSQL 全球开发小组,部分版权(c)1994-1996 加州大学董事
(Portions copyright (c) 1996-2005, PostgreSQL Global Development Group Portions Copyright (c) 1994-6 Regents of the University of California)
允许为任何目的使用,拷贝,修改和分发这个软件和它的文档而不收取任何费用, 并且无须签署因此而产生的证明,前提是上面的版权声明和本段以及下面两段文字出现在所有拷贝中。
(Permission to use, copy, modify, and distribute this software and its documentation for any purpose, without fee, and without a written agreement is hereby granted, provided that the above copyright notice and this paragraph and the following two paragraphs appear in all copies.)
在任何情况下,加州大学都不承担因使用此软件及其文档而导致的对任何当事人的直接的, 间接的,特殊的,附加的或者相伴而生的损坏,包括利益损失的责任,即使加州大学已经建议了这些损失的可能性时也是如此。
(IN NO EVENT SHALL THE UNIVERSITY OF CALIFORNIA BE LIABLE TO ANY PARTY FOR DIRECT, INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, INCLUDING LOST PROFITS, ARISING OUT OF THE USE OF THIS SOFTWARE AND ITS DOCUMENTATION, EVEN IF THE UNIVERSITY OF CALIFORNIA HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.)
加州大学明确放弃任何保证,包括但不局限于某一特定用途的商业和利益的隐含保证。 这里提供的这份软件是基于“当作是”的基础的,因而加州大学没有责任提供维护,支持,更新,增强或者修改的服务。
(THE UNIVERSITY OF CALIFORNIA SPECIFICALLY DISCLAIMS ANY WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE SOFTWARE PROVIDED HEREUNDER IS ON AN "AS IS" BASIS, AND THE UNIVERSITY OF CALIFORNIA HAS NO OBLIGATIONS TO PROVIDE MAINTENANCE, SUPPORT, UPDATES, ENHANCEMENTS, OR MODIFICATIONS.)
1.3)PostgreSQL 可以运行在哪些操作系统平台上?
一般说来,一个现代的 UNIX 兼容的平台都能运行 PostgreSQL ,在安装指南里列出了发布时经过明确测试的平台。PostgreSQl也可以直接运行在基于微软Windows-NT的操作系统,如Win2000,WinXP 和 Win2003,已制作完成的安装包可从 http://pgfoundry.org/projects/pginstaller下载,基于MSDOS的Windows操作系统 (Win95,Win98,WinMe)需要通过Cygwin模拟环境运行PostgreSQL。
1.4)我从哪里能得到 PostgreSQL?
通过浏览器可从http://www.postgresql.org/ftp/下载,也可通过FTP,从 ftp://ftp.PostgreSQL.org/pub/ 站点下载。
1.5)我从哪里能得到对 PostgreSQL 的支持?
PostgreSQL社区通过邮件列表为其大多数用户提供帮助,加入邮件列表的主站点是 http://www.postgresql.org/community/lists/,一般情况下,先加入General 或 Bug邮件列表是一个较好的开始。
主要的IRC频道是在FreeNode(irc.freenode.net)的#postgresql,为了连上此频道,可以使用UNIX程序irc,其指令格式: irc -c '#postgresql' "$USER" irc.freenode.net ,或者使用其他IRC客户端程序。在此网络中还存在一个PostgreSQL的西班牙频道(#postgersql-es)和法语频道 (#postgresql-fr)。同样地,在EFNET上也有一个PostgreSQL的交流频道。
商业支持公司的列表在此处。
1.6)我如何提交一个BUG报告?
可访问此处填写Bug上报表格即可。同样也可访问ftp站点ftp://ftp.PostgreSQL.org/pub/ 检查有无更新的PostgreSQL版本或补丁。
1.7)最新版的PostgreSQL 是什么?
其最新的版本是版本 8.0.2。我们计划每年发布一个主要版本,每几个月发布一个小版本。
1.8)能够获取的最新文档有哪些?
PostgreSQL包含大量的文档,主要有一些手册,手册页和一些的测试例子。参见 /doc 目录(译注:应为 $PGHOME/doc)。 你还可以在线浏览 PostgreSQL 的手册,其地址是:http://www.PostgreSQL.org/docs。
有两本关于 PostgreSQL 的书在线提供,在 http://www.PostgreSQL.org/docs/awbook.html 和 http://www.commandprompt.com/ppbook/。也有大量的PostgreSQL书籍可供购买,其中最为流行的一本是由Korry Douglas编写的。在 http://techdocs.PostgreSQL.org/techdocs/bookreviews.php 上有大量有关PostgreSQL书籍的简介。在 http://techdocs.PostgreSQL.org/ 上收集了有关 PostgreSQL 的大量技术文章。
客户端的命令行程序psql有一些以 \d 开头的命令,可显示关于类型,操作符,函数,汇总等的信息,使用 \? 可以显示所有可用的命令。我们的 web 站点包含更多的文档。
1.9)我如何了解已知的 BUG 或暂缺的功能?
PostgreSQL 支持一个扩展了的 SQL-92 的子集。参阅我们的TODO 列表,获取一个已知Bug,暂缺的功能和将来的计划。
1.10)我应该怎样学习 SQL ?
首先考虑上述提到的与PostgreSQL相关的书籍,另外一本是Teach Yourself SQL in 21 Days, Second Edition, 我们的许多用户喜欢The Practical SQL Handbook Bowman, Judith S., et al., Addison-Wesley,其他的则喜欢 The Complete Reference SQL, Groff et al., McGraw-Hill。
1.11)我应该怎样加入开发队伍?
详见 Developer's FAQ 。
1.12)PostgreSQL 和其他数据库系统比起来如何?
评价软件有好几种方法:特性,性能,可靠性,支持和价格。
特性
PostgreSQL 拥有大型商用 DBMS 里大多数特性, 例如:事务,子查询,触发器,视图,外键参考完整性和复杂的锁等。 我们还有一些它们没有的特性,如用户定义类型,继承,规则和多版本并行控制以减少锁的争用等。
性能
PostgreSQL 和其他商用和开源的数据库具有类似的性能。 对某些处理它比较快,对其他一些处理它比较慢。与其他数据库相比,我们的性能通常在 +/- 10%之间。
可靠性
我们知道 DBMS 必须是可靠的,否则它就一点用都没有。 我们努力做到发布经过认真测试的,稳定的臭虫最少的代码。每个版本至少有一个月的 beta 测试时间,并且我们的发布历史显示我们可以提供稳定的,牢固的,可用于生产使用的版本。我们相信 在这方面我们与其他的数据库软件是相当的。
支持
我们的邮件列表提供一个非常大的开发人员和用户的组以帮助解决所碰到的任何问题。 我们不能保证肯定能解决问题,相比之下,商用 DBMS 也并不是总能够提供解决方法。 直接与开发人员,用户群,手册和源程序接触令 PostgreSQL 的支持比其他 DBMS 还要好。还有一些商业性的预包装的支持,可以给提供给那些需要的人。(参阅 FAQ 条款 1.5 小节)
价格
我们对任何用途都免费,包括商用和非商用目的。 你可以不加限制地向你的产品里加入我们的代码,除了那些我们在上面的版权声明里声明的 BSD 风格的版权外。
1.13)谁控制PostgreSQL ?
如果你在寻找PostgreSQL的掌门人,或是什么中央委员会,或是什么所属公司,你只能放弃了---因为一个也不存在,但我们的确有一个 委员会和CVS管理组,但这些工作组的设立主要是为了进行管理工作而不是对PostgreSQL进行控制,PostgreSQL项目是由任何人均 可参加的开发人员社区和所有用户控制的,你所需要做的就是加入邮件列表,参与讨论即可(要参与PostgreSQL的开发详见 Developer's FAQ 获取信息)。
用户客户端问题
2.1)我们可以用什么语言和 PostgreSQL 打交道?
PostgreSQL(缺省情况)只安装有C和内嵌式C的接口,其他的接口都是独立的项目,能够分别下载,这些接口项目独立的好处 是他们可以有各自的发布计划和各自独立的开发组。一些编程语言如Perl都有访问 PostgreSQL 的接口,PHP,TCL,Python以及很多其他语言的接口在 http://gborg.postgresql.org 上的Drivers/Interfaces小节可找到,并且通过Internet很容易搜索到。
2.2)有什么工具可以把 PostgreSQL 用于 Web 页面?
一个介绍以数据库为后台的挺不错的站点是:http://www.webreview.com。对于 Web 集成,PHP 是一个极好的接口。它在:http://www.php.net/。对于复杂的任务,很多人采用 Perl 接口和 CGI.pm 或 mod_perl 。
2.3)PostgreSQL 拥有图形用户界面吗?
是的,在 http://techdocs.postgresql.org/guides/GUITools有一个详细的列表。
系统管理问题
3.1)我怎样能把 PostgreSQL 装在 /usr/local/pgsql 以外的地方?
在运行 configure 时加上 --prefix 选项。
3.2)我如何控制来自其他主机的连接?
缺省时,PostgreSQL 只允许通过 unix 域套接字或TCP/IP方式且来自本机的连接。 你只有在修改了配置文件postgresql.conf中的listen_addresses,且也在配置文件pg_hba.conf中打开了 主机为基础( host-based )的身份认证,并重新启动PostgreSQL,否则其他机器是不能与你的PostgreSQL服务器连接的。
3.3)我怎样调整数据库引擎以获得更好的性能?
有三个主要方面可以提升PostgreSQL的潜能。
查询方式的变化
这主要涉及修改查询方式以获取更好的性能:
创建索引,包括表达式和部分索引;
使用COPY语句代替多个Insert语句;
将多个SQL语句组成一个事务以减少提交事务的开销;
从一个索引中提取多条记录时使用CLUSTER;
从一个查询结果中取出部分记录时使用LIMIT;
使用预编译式查询(Prepared Query);
使用ANALYZE以保持精确的优化统计;
定期使用 VACUUM 或 pg_autovacuum
进行大量数据更改时先删除索引(然后重建索引)
服务器的配置
配置文件postgres.conf中的很多设置都会影响性能,所有参数的列表可见: Administration Guide/Server Run-time Environment/Run-time Configuration, 有关参数的解释可见:
http://www.varlena.com/varlena/GeneralBits/Tidbits/annotated_conf_e.html
http://www.varlena.com/varlena/GeneralBits/Tidbits/perf.html
硬件的选择
计算机硬件对性能的影响可浏览 http://candle.pha.pa.us/main/writings/pgsql/hw_performance/index.html 和 http://www.powerpostgresql.com/PerfList/。
3.4)PostgreSQL 里可以获得什么样的调试特性?
其有很多类似 log_* 的服务器配置变量可用于查询的打印和进程统计,而这些工作对调试和性能测试很有帮助。
3.5)为什么在试图连接时收到“Sorry, too many clients”消息?
这表示你已达到缺省100个并发后台进程数的限制,你需要通过修改postgresql.conf文件中的max_connections值来 增加postmaster的后台并发处理数,修改后需重新启动postmaster。
3.6)为什么要在升级 PostgreSQL 主要发布版本时做 dump 和 restore?
开发组对每次小的升级仅做了较少的修改,因此从 7.4.0 升级到 7.4.1 不需要 dump 和 restore。 但是主要的升级(例如从 7.3 到 7.4)通常会修改系统表和数据表的内部格式。 这些变化一般比较复杂,因此我们不维数据文件的向后兼容。 dump 将数据按照通用的格式输出,随后可以被重新加载并使用新的内部格式。
3.7)(使用PostgreSQL)我需要使用什么计算机硬件?
由于计算机硬件大多数是兼容的,人们总是倾向于相信所有计算机硬件质量也是相同的。事实上不是, ECC RAM(带奇偶校验的内存),SCSI (硬盘)和优质的主板比一些便宜货要更加可靠且具有更好的性能。PostgreSQL几乎可以运行在任何硬件上, 但如果可靠性和性能对你的系统很重要,你就需要全面的研究一下你的硬件配置了。在我们的邮件列表上也有关于 硬件配置和性价比的讨论。
操作问题
4.1)如何只选择一个查询结果的头几行?或是随机的一行?
如果你只是要提取几行数据,并且你在执行查询中知道确切的行数,你可以使用LIMIT功能。 如果有一个索引与 ORDER BY中的条件匹配,PostgreSQL 可能就只处理要求的头几条记录, (否则将对整个查询进行处理直到生成需要的行)。如果在执行查询功能时不知道确切的记录数,可使用游标(cursor)和FETCH功能。
可使用以下方法提取一行随机记录的:
SELECT cols FROM tab ORDER BY random() LIMIT 1 ;
4.2)如何查看表、索引、数据库以及用户的定义?如何查看psql里用到的查询指令并显示它们?
在psql中使用 \dt 命令来显示数据表的定义,要了解psql中的完整命令列表可使用\? ,另外你也可以阅读 psql 的源代码 文件pgsql/src/bin/psql/describe.c,它包括为生成psql反斜杠命令的输出的所有 SQL 命令。你还可以带 -E 选项启动 psql, 这样它将打印出执行你在psql中所给出的命令的内部实际使用的SQL查询。PostgreSQL也提供了一个兼容SQL的INFORMATION SCHEMA接口, 你可以从这里获取关于数据库的信息。
在系统中有一些以pg_ 打头的系统表也描述了表的定义。使用 psql -l 指令可以列出所有的数据库。也可以浏览一下 pgsql/src/tutorial/syscat.source文件,它列举了很多可从数据库系统表中获取信息的SELECT语法。
4.3)如何更改一个字段的数据类型?
在8.0版本里更改一个字段的数据类型很容易,可使用 ALTER TABLE ALTER COLUMN TYPE 。在以前的版本中,可以这样做:
BEGIN;
ALTER TABLE tab ADD COLUMN new_col new_data_type;
UPDATE tab SET new_col = CAST(old_col AS new_data_type);
ALTER TABLE tab DROP COLUMN old_col;
COMMIT;
你然后可以使用VACUUM FULL tab 指令来使系统收回无效数据所占用的空间。
4.4)一行记录,一个表,一个库的最大尺寸是多少?
下面是一些限制:
一个数据库最大尺寸? 无限制(已存在有 32TB 的数据库)
一个表的最大尺寸? 32 TB
一行记录的最大尺寸? 1.6 TB
一个字段的最大尺寸? 1 GB
一个表里最大行数? 无限制
一个表里最大列数? 250-1600 (与列类型有关)
一个表里的最大索引数量? 无限制
当然,实际上没有真正的无限制,还是要受可用磁盘空间、可用内存/交换区的制约。 事实上,当这些数值变得异常地大时,系统性能也会受很大影响。表的最大尺寸 32 TB 不需要操作系统对大文件的支持。大表用多个 1 GB 的文件存储,因此文件系统尺寸的限制是不重要的。如果缺省的块大小增长到 32K ,最大的表尺寸和最大列数还可以增加到四倍。
4.5)存储一个典型的文本文件里的数据需要多少磁盘空间?
一个 Postgres 数据库(存储一个文本文件)所占用的空间最多可能需要相当于这个文本文件自身大小5倍的磁盘空间。例如,假设有一个 100,000 行的文件,每行有一个整数和一个文本描述。 假设文本串的平均长度为20字节。文本文件占用 2.8 MB。存放这些数据的 PostgreSQL 数据库文件大约是 6.4 MB:
32 字节: 每行的头(估计值)
24 字节: 一个整数型字段和一个文本型字段
+ 4 字节: 页面内指向元组的指针
----------------------------------------
60 字节每行
PostgreSQL 数据页的大小是 8192 字节 (8 KB),则:
8192 字节每页
------------------- = 136 行/数据页(向下取整)
60 字节每行
100000 数据行
-------------------- = 735 数据页(向上取整)
128 行每页
735 数据页 * 8192 字节/页 = 6,021,120 字节(6 MB)
索引不需要这么多的额外消耗,但也确实包括被索引的数据,因此它们也可能很大。空值NULL存放在位图中,因此占用很少的空间。
4.6)为什么我的查询很慢?为什么这些查询没有利用索引?
并非每个查询都会自动使用索引。只有在表的大小超过一个最小值,并且查询只会选中表中较小比例的记录时才会采用索引。 这是因为索引扫描引起的随即磁盘存取可能比直接地读取表(顺序扫描)更慢。
为了判断是否使用索引,PostgreSQL必须获得有关表的统计值。这些统计值可以使用 VACUUM ANALYZE,或 ANALYZE 获得。 使用统计值,优化器知道表中有多少行,就能够更好地判断是否利用索引。 统计值对确定优化的连接顺序和连接方法也很有用。在表的内容发生变化时,应定期进行统计值的更新收集。
索引通常不用于 ORDER BY 或执行连接。对一个大表的一次顺序扫描,再做一个显式的排序通常比索引扫描要快。但是,在 LIMIT 和 ORDER BY 结合使用时经常会使用索引,因为这只会返回表的一小部分。 实际上,虽然 MAX() 和 MIN() 并不使用索引,通过对 ORDER BY 和 LLIMIT 使用索引取得最大值和最小值也是可以的:
SELECT col FROM tab ORDER BY col [ DESC ] LIMIT 1;
如果你确信PostgreSQL的优化器使用顺序扫描是不正确的,你可以使用SET enable_seqscan TO 'off'指令, 然后再次运行查询,你就可以看出使用一个索引扫描是否确实要快一些。
当使用通配符操作,例如 LIKE 或 ~ 时,索引只能在特定的情况下使用:
字符串的开始部分必须是普通字符串,也就是说:
LIKE 模式不能以 % 打头。
~ (正则表达式)模式必须以 ^ 打头。
字符串不能以匹配多个字符的模式类打头,例如 [a-e]。
大小写无关的查找,如 ILIKE 和 ~* 等不使用索引,但可以用 4.8 节描述的函数索引。
在做 initdb 时必须采用缺省的本地设置 C locale,因为系统不可能知道在非C locale情况时下一个最大字符是什么。 在这种情况下,你可以创建一个特殊的text_pattern_ops索引来用于LIKE的索引。
在8.0之前的版本中,除非要查询的数据类型和索引的数据类型相匹配,否则索引经常是未被用到,特别是对int2,int8和数值型的索引。
4.7)我如何才能看到查询优化器是怎样评估处理我的查询?
参考 EXPLAIN 手册页。
4.8)我怎样做正则表达式搜索和大小写无关的正则表达式查找?怎样利用索引进行大小写无关查找?
操作符 ~ 处理正则表达式匹配,而 ~* 处理大小写无关的正则表达式匹配。大写些无关的 LIKE 变种成为 ILIKE。
大小写无关的等式比较通常写做:
SELECT * FROM tab WHERE lower(col) = 'abc';
这样将不会使用标准的索引。但是可以创建一个可被利用的函数索引:
CREATE INDEX tabindex ON tab (lower(col));
4.9)在一个查询里,我怎样检测一个字段是否为 NULL ?我如何才能准确排序而不论某字段是否含 NULL 值?
用 IS NULL 和 IS NOT NULL 测试这个字段,具体方法如下:
SELECT * FROM tab WHERE col IS NULL;
为了能对含 NULL字段排序,可在 ORDER BY 条件中使用 IS NULL和 IS NOT NULL 修饰符,条件为真 true 将比条件为假false 排在前面,下面的例子就会将含 NULL 的记录排在结果的上面部分:
SELECT * FROM tab ORDER BY (col IS NOT NULL)
4.10)各种字符类型之间有什么不同?
类型 内部名称 说明
VARCHAR(n) varchar 指定了最大长度,变长字符串,不足定义长度的部分不补齐
CHAR(n) bpchar 定长字符串,实际数据不足定义长度时,以空格补齐
TEXT text 没有特别的上限限制(仅受行的最大长度限制)
BYTEA bytea 变长字节序列(使用NULL也是允许的)
"char" char 一个字符
在系统表和在一些错误信息里你将看到内部名称。
上面所列的前四种类型是"varlena"(变长)类型(也就是说,开头的四个字节是长度,后面才是数据)。 于是实际占用的空间比声明的大小要多一些。 然而这些类型都可以被压缩存储,也可以用 TOAST 脱机存储,因此磁盘空间也可能比预想的要少。
VARCHAR(n) 在存储限制了最大长度的变长字符串是最好的。 TEXT 适用于存储最大可达 1G左右但未定义限制长度的字符串。
CHAR(n) 最适合于存储长度相同的字符串。 CHAR(n)会根据所给定的字段长度以空格补足(不足的字段内容), 而 VARCHAR(n) 只存储所给定的数据内容。 BYTEA 用于存储二进制数据,尤其是包含 NULL 字节的值。这些类型具有相似的性能特性。
4.11.1)我怎样创建一个序列号/自动递增的字段?
PostgreSQL 支持 SERIAL 数据类型。它在字段上自动创建一个序列和索引。例如:
CREATE TABLE person (
id SERIAL,
name TEXT
);
会自动转换为:
CREATE SEQUENCE person_id_seq;
CREATE TABLE person (
id INT4 NOT NULL DEFAULT nextval('person_id_seq'),
name TEXT
);
参考 create_sequence 手册页获取关于序列的更多信息。
4.11.2)我如何获得一个插入的序列号的值?
一种方法是在插入之前先用函数 nextval() 从序列对象里检索出下一个 SERIAL 值,然后再显式插入。使用 4.11.1 里的例表,可用伪码这样描述:
new_id = execute("SELECT nextval('person_id_seq')");
execute("INSERT INTO person (id, name) VALUES (new_id, 'Blaise Pascal')");
这样还能在其他查询中使用存放在 new_id 里的新值(例如,作为 person 表的外键)。 注意自动创建的 SEQUENCE 对象的名称将会是 <table>_<serialcolumn>_seq, 这里 table 和 serialcolumn 分别是你的表的名称和你的 SERIAL 字段的名称。
类似的,在 SERIAL 对象缺省插入后你可以用函数 currval() 检索刚赋值的 SERIAL 值,例如:
execute("INSERT INTO person (name) VALUES ('Blaise Pascal')");
new_id = execute("SELECT currval('person_id_seq')");
4.11.3)使用 currval() 会导致和其他用户的冲突情况(race condition)吗?
不会。currval() 返回的是你本次会话进程所赋的值而不是所有用户的当前值。
4.11.4)为什么不在事务异常中止后重用序列号呢?为什么在序列号字段的取值中存在间断呢?
为了提高并发性,序列号在需要的时候赋予正在运行的事务,并且在事务结束之前不进行锁定, 这就会导致异常中止的事务后,序列号会出现间隔。
4.12)什么是 OID ?什么是 CTID ?
PostgreSQL 里创建的每一行记录都会获得一个唯一的OID,除非在创建表时使用WITHOUT OIDS选项。 OID创建时会自动生成一个4字节的整数,所有 OID 在整个 PostgreSQL 中均是唯一的。 然而,它在超过40亿时将溢出, OID此后会出现重复。PostgreSQL 在它的内部系统表里使用 OID 在表之间建立联系。
在用户的数据表中,最好是使用SERIAl来代替OID 因为SERIAL只是保证在单个表中数据是唯一的,这样它溢出的可能性就非常小了, SERIAL8可用来保存8字节的序列号字段。
CTID 用于标识带着数据块(地址)和(块内)偏移的特定的物理行。 CTID 在记录被更改或重载后发生改变。索引入口使用它们指向物理行。
4.13)为什么我收到错误信息“ERROR: Memory exhausted in AllocSetAlloc()”?
这很可能是系统的虚拟内存用光了,或者内核对某些资源有较低的限制值。在启动 postmaster 之前试试下面的命令:
ulimit -d 262144
limit datasize 256m
取决于你用的 shell,上面命令只有一条能成功,但是它将把你的进程数据段限制设得比较高, 因而也许能让查询完成。这条命令应用于当前进程,以及所有在这条命令运行后创建的子进程。 如果你是在运行SQL客户端时因为后台返回了太多的数据而出现问题,请在运行客户端之前执行上述命令。
4.14)我如何才能知道所运行的 PostgreSQL 的版本?
从 psql 里,输入 SELECT version();指令。
4.15)我如何创建一个缺省值是当前时间的字段?
使用 CURRENT_TIMESTAMP:
CREATE TABLE test (x int, modtime TIMESTAMP DEFAULT CURRENT_TIMESTAMP );
4.16)我怎样进行 outer join (外连接)?
PostgreSQL 采用标准的 SQL 语法支持外连接。这里是两个例子:
SELECT * FROM t1 LEFT OUTER JOIN t2 ON (t1.col = t2.col);
或是
SELECT * FROM t1 LEFT OUTER JOIN t2 USING (col);
这两个等价的查询在 t1.col 和 t2.col 上做连接,并且返回 t1 中所有未连接的行(那些在 t2 中没有匹配的行)。 右[外]连接(RIGHT OUTER JOIN)将返回 t2 中未连接的行。 完全外连接(FULL OUTER JOIN)将返回 t1 和 t2 中未连接的行。 关键字 OUTER 在左[外]连接、右[外]连接和完全[外]连接中是可选的,普通连接被称为内连接(INNER JOIN)。
4.17)如何使用涉及多个数据库的查询?
没有办法查询当前数据库之外的数据库。 因为 PostgreSQL 要加载与数据库相关的系统目录(系统表),因此跨数据库的查询如何执行是不定的。附加增值模块contrib/dblink允许采用函数调用实现跨库查询。当然用户也可以同时连接到不同的数据库执行查询然后在客户端合并结果。
4.18)如何让函数返回多行或多列?
在函数中返回数据记录集的功能是很容易使用的,详情参见:http://techdocs.postgresql.org/guides/SetReturningFunctions
4.19)为什么我在使用PL/PgSQL函数存取临时表时会收到错误信息“relation with OID ##### does not exist”?
PL/PgSQL会缓存函数的内容,由此带来的一个不好的副作用是若一个 PL/PgSQL 函数访问了一个临时表,然后该表被删除并重建了,则再次调用该函数将失败, 因为缓存的函数内容仍然指向旧的临时表。解决的方法是在 PL/PgSQL 中用EXECUTE 对临时表进行访问,这样会保证查询在执行前总会被重新解析。
4.27)目前有哪些数据复制方案可用?
“复制”只是一个术语,有好几种复制技术可使用,每种都有优点和缺点:
主/从复制方式是允许一个主服务器接受读/写的申请,而多个从服务器只能接受读/SELECT查询的申请, 目前最流行且是免费的主/从 PostgreSQL复制方案是 Slony-I 。
多个主服务器的复制方式允许将读/写的申请发送给多台的计算机,这种方式由于需要在多台服务器之间同步数据变动 可能会带来较严重的性能损失,Pgcluster是目前这种方案 中最好的,而且还可以免费下载。也有一些商业需付费和基于硬件的数据复制方案,支持上述各种复制模型。
我们再来看看从应用与运维上的比较
全栈数据库
成熟的应用可能会用到许许多多的数据组件(功能):缓存,OLTP,OLAP/批处理/数据仓库,流处理/消息队列,搜索索引,NoSQL/文档数据库,地理数据库,空间数据库,时序数据库,图数据库。MySQL就只能扮演OLTP关系型数据库的角色,但如果是PostgreSQL,就可以身兼多职,比如:
OLTP:事务处理是PostgreSQL的本行
OLAP:citus分布式插件,ANSI SQL兼容,窗口函数,CTE,CUBE等高级分析功能,任意语言写UDF
流处理:PipelineDB扩展,Notify-Listen,物化视图,规则系统,灵活的存储过程与函数编写
时序数据:timescaledb时序数据库插件,分区表,BRIN索引
空间数据:PostGIS扩展(杀手锏),内建的几何类型支持,GiST索引。
搜索索引:全文搜索索引足以应对简单场景;丰富的索引类型,支持函数索引,条件索引
NoSQL:JSON,JSONB,XML,HStore原生支持,至NoSQL数据库的外部数据包装器
数据仓库:能平滑迁移至同属Pg生态的GreenPlum,DeepGreen,HAWK等,使用FDW进行ETL
图数据:递归查询
缓存:物化视图
运维友好
当然除了功能强大之外,Pg的另外一个重要的优势就是运维友好,有很多非常实用的特性:
DDL能放入事务中,删表,TRUNCATE,创建函数,索引,都可以放在事务里原子生效,或者回滚。
这就能进行很多操作,比如在一个事务里通过RENAME,完成两张表的易位。
能够并发地创建、删除索引,添加非空字段,重整索引与表(不锁表)。
这意味着可以随时在线上不停机进行重大的模式变更,按需对索引进行优化。
复制方式多样:段复制,流复制,触发器复制,逻辑复制,插件复制等等。
这使得不停服务迁移数据变得相当容易:复制,改读,改写三步走,线上迁移稳定。
提交方式多样:异步提交,同步提交,法定人数同步提交。
这意味着Pg允许在C和A之间做出权衡与选择,例如交易库使用同步提交,普通库使用异步提交。
系统视图非常完备,做监控系统相当简单。
FDW的存在让ETL变得无比简单,一行SQL就能解决。
FDW可以方便地让一个实例访问其他实例的数据或元数据。在跨分区操作,数据库监控指标收集,数据迁移等场景中妙用无穷。同时还可以对接很多异构数据系统。
生态健康
PostgreSQL的生态也很健康,社区相当活跃。
相比MySQL,PostgreSQL的一个巨大的优势就是协议友好。PG采用类似BSD/MIT的PostgreSQL协议,差不多理解为只要别打着Pg的旗号出去招摇撞骗,随便你怎么搞,换皮出去卖都行。君不见多少国产数据库,或者不少“自研数据库”实际都是Pg的换皮或二次开发产品。
当然,也有很多衍生产品会回馈主干,比如timescaledb,pipelinedb, citus 这些基于PG的“数据库”,最后都变成了原生PG的插件。很多时候你想实现个什么功能,一搜就能找到对应的插件或实现。
Pg的代码质量相当之高,注释写的非常清晰。C的代码读起来有种Go的感觉,代码都可以当文档看了。能从中学到很多东西。而MySQL社区版采用的是GPL协议,要不是GPL传染,怎么会有这么多基于MySQL改的数据库开源出来呢?而且MySQL还在Oracle这个业界毒瘤手中呢?Facebook修改React协议的风波就算是一个前车之鉴了。
存在的问题
当然,要说有什么缺点或者遗憾,那还是有几个的:
因为使用了MVCC,数据库需要定期VACUUM,需要定期维护表和索引避免膨胀导致性能下降。
没有很好的开源集群监控方案,需要自己做。
慢查询日志和普通日志是混在一起的,需要自己解析处理。
官方Pg没有很好用的列存储,对数据分析而言算一个小遗憾。
当然都是些无关痛痒的小毛小病,不过真正的问题可能和技术无关……
说到底,MySQL确实是最流行的开源关系型数据库,没办法,写Java的,写PHP的,很多人最开始用的都是MySQL…,所以Pg招人相对困难是一个事实,很多时候只能自己培养。不过看DB Engines上的流行度趋势,未来还是很光明的。
存储结构浅析
PostgreSQL 数据库是功能强大的开源数据库,越来越多的公司开始使用 PostgreSQL。存储系统是 PostgreSQL 的最底层模块,它向下通过操作系统接口访问物理数据,向上为上层模块提供存储操作的接口和函数。这里通过对 PostgreSQL 的存储结构进行浅析,帮助大家了解这一强大的关系型数据库是如何存储数据的。本小节转自浪潮云溪数据库。
- 数据目录 -
PostgreSQL 安装完成后必须先使用 initdb 程序初始化磁盘上的数据存储区,生成模板数据库和相应的目录、文件信息。
initdb -D /usr/local/pgsql/data
初始化目录中包含数据文件、参数文件、控制文件、数据库运行日志及 WAL 日志文件等,下图各目录和子文件的用途在此不做赘述。
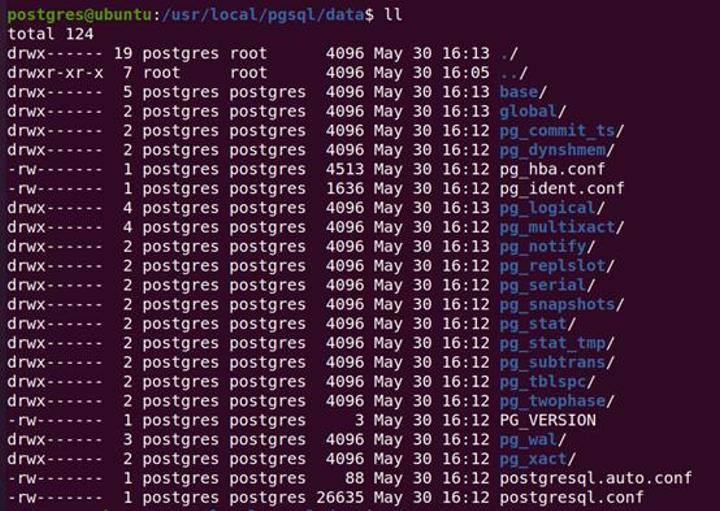
默认情况下,PostgreSQL 中的所有数据都存储在其数据目录里,这个数据目录通常会用环境变量 PGDATA 来引用,对于某个具体的数据库,在 PGDATA/base 里都对应有一个子目录,子目录的名字是该数据库在系统表 pg_database 里的 OID,每个表的数据都存在其所属数据库目录下的独立文件里,文件以该表的 filenode 号命名,为了避免有些文件系统不支持大文件,PostgreSQL 限制表文件大小不能超过 1GB(默认 1GB,编译时可通过 ./configure --with-segsize= x 修改)因此,当表文件超过 1GB 时,会另建一个有尾缀的文件 relfilenode.1,relfilenode.2…… 以此类推。
表文件的物理位置为:$PGDATA/BASE/DATABASE_OID/PG_CLASS.RELFILENODE
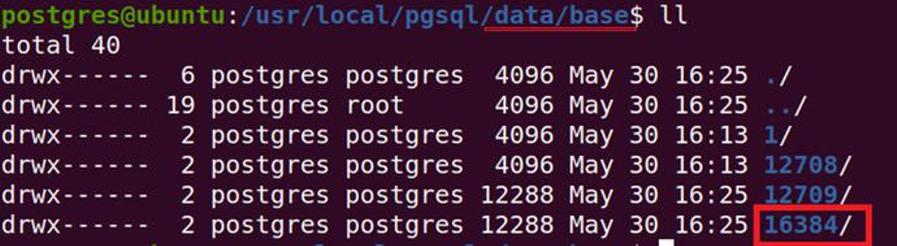
-- 查看数据库 test 的 OID
#select oid,datname from pg_database where datname='test';

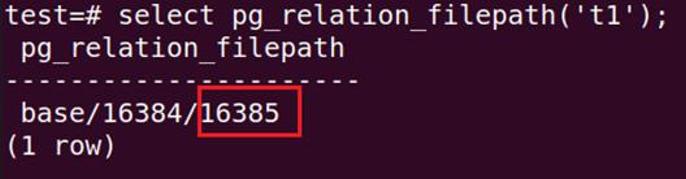
-- 查看表 t1 的 filenode
#select pg_relation_filepath('t1');
- 数据文件结构 -
在 PG 中,磁盘存储和内存中的最小管理单位都是块,保存在磁盘中的数据块称为 Page,内存中的数据块称为 Buffer,表和索引称为 Relation,行称为 Tuple。数据的读写是以 Page 为最小单位,每个 Page 默认大小为 8kB,在源码编译时可通过 ./configure --with-blocksize=BLOCKSIZE 设置其他大小,此后都不可更改。每个表文件由多个 BLCKSZ 字节大小的 Page 组成,每个 Page 包含若干 Tuple。
内存中的共享缓冲池缓存了 block 块(默认 1000 个),若缓冲池中的 block 块为脏,需要刷回磁盘,缓冲池细节在此不做赘述,需要时可另起一文解析。
Page 结构
Page 结构包括五部分:
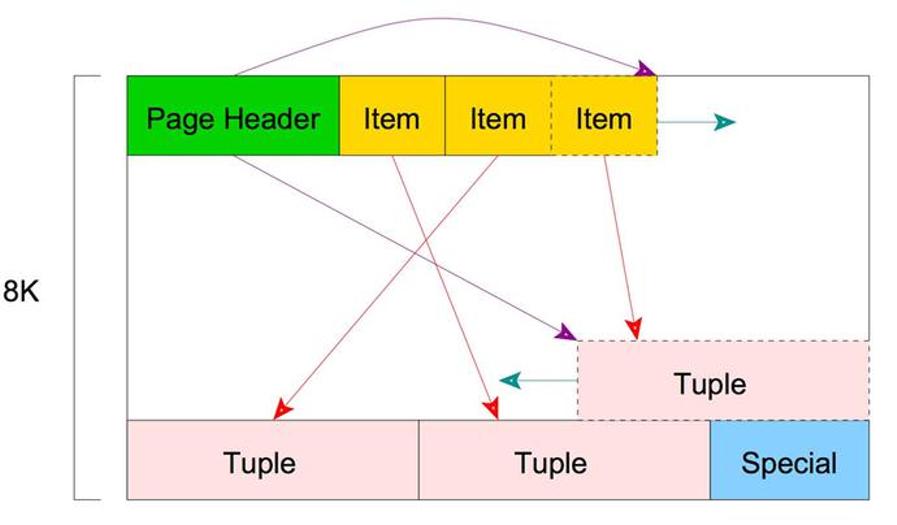
PageHeaderData -- 在 page 头部,24 个字节长度,记录 page 的元数据信息。
pg_lsn,存储 page 最新更改时,WAL 日志的 lsn 信息。
pg_checksum,存储 page 的校验值。
pd_flags,标志位。
pg_lower,到空闲空间开头的偏移量。
pg_upper,到空闲空间结尾的偏移量。
pd_pagesize_version,页面大小和布局版本号信息。
pd_prune_xid,页面上最早未删除 XMAX,如果没有则为 0。
ItemIdData -- 在 page header 之后,一个记录(偏移量,长度)对的数组,指向实际 tuple 项,每个 4 字节。
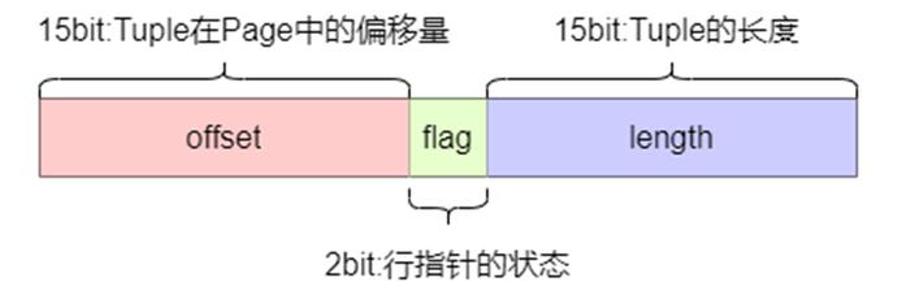
Free space -- 未分配的空间(空闲空间)。新项指针从这个区域的开头开始分配,新项从其结尾开始分配。
Items -- 用来存放行数据 Tuple。
Special space -- 索引访问模式相关的数据。不同的索引访问方式存放不同的数据。在普通表中为空。
Tuple
页中的元组可细分为 “普通数据元组和 TOAST 元组”。
TOAST (The Oversized-Attribute Storage Technique,超大属性存储技术) 主要用于存储变长数据,当待插入元组的数据大小大于约为 2KB (即页的 1/4) 时候,会自动启动 TOAST 技术来存储该元组。TOAST 较普通元组稍加复杂些,这里主要针对普通元组文件进行说明。

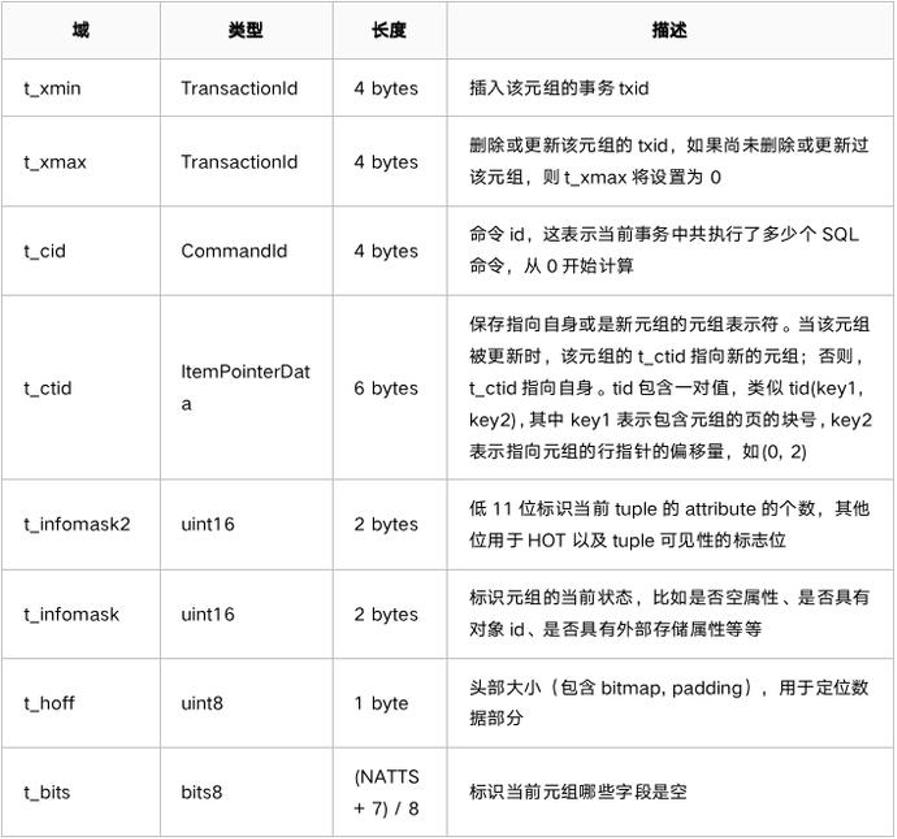
元组内部可以分为三部分,分别是: 堆元组头部( 23 字节) 、 NULL 值位图 和 用户存储的数据 。
Pageinspect 扩展
PostgreSQL 在源码目录 contrib 下提供了许多扩展的功能,pageinspect 扩展模块提供的函数让你从低层次观察数据库页面的内容,这对于调试目的很有用。
安装
#cd $PGSRC/contrib/pageinspect
#make
#sudo make install
简单使用
#psql -d test
test=#create extension pageinspect; -- 首次使用需创建 Extension
-- 创建测试表
drop table if exists t1;
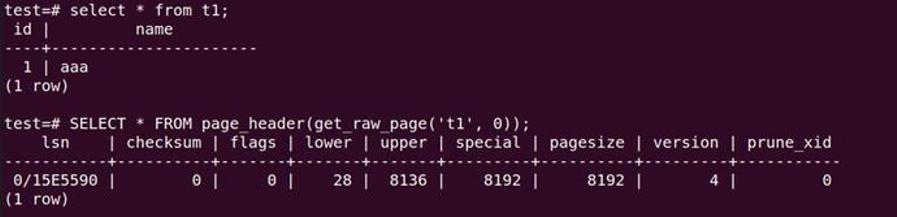
create table t1 (id int, name varchar(20));
insert into t1 values(1,'aaa');
-- 查看 page header&item
SELECT * FROM page_header(get_raw_page('t1', 0));
select * from heap_page_items(get_raw_page('t1',0));
-- 更新一行数据
update t1 set name='bbb' where id=1;
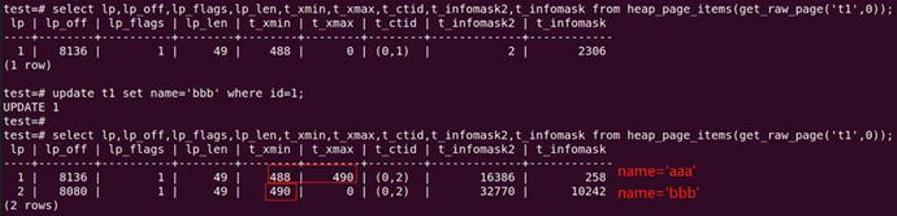
查看 heap_page_items(),发现多了一条 item,原因是 PG 更新数据时并不修改原 tuple,而是插入一条新的 tuple,并标记原 tuple.t_xmax= 新 tuple 的事务 id。
初学者必知的Postgres基础知识点
1、元组(tuples)是行的物理版本
元组是什么?简单来说,Postgres中的元组是一行数据的物理版本。这意味着当一行中的数据发生更改时,Postgres不会更改现有数据,而是为该行增加一个新的版本(元组)。这个版本控制系统称为MVCC(多版本并发控制),了解它对于设计性能良好的系统非常重要。
以下是各种写入操作期间发生的情况:
当执行一个DELETE命令,它不会立即回收磁盘空间。相反,旧元组被标记为死亡,但会一直保留到VACUUM删除它。如果这些死元组可以累积并通过大量清理而被删除,则会导致表和索引膨胀。
同样当UPDATE一行,Postgres不会修改现有的元组。相反它创建该行的新版本(一个新元组)并将旧的标记为已死。取消INSERT创建一个死元组,就是在插入一条记录然后回滚该操作,则要插入的元组将被标记为死亡。
为了帮助掌握这些概念,Postgres中的每个表都有可以选择的隐藏列:ctid,xmin,xmax。ctid表示元组的位置(页码+其中的偏移量),而xmin和xmax可以被视为元组的“出生日期”和“死亡日期”。
通过尽早了解这种行为,将能够更好地应对与磁盘空间、膨胀和自动清理进程等机制。
>create table t1 as select 1 as id;
>select ctid,xmin,xmax,* from t1;
ctid | xmin | xmax | id
-------+--------+------+----
(0,1) | 184225 | 0 | 1
>update t1 set id=id where id=1;
>select ctid,xmin,xmax,* from t1;
ctid | xmin | xmax | id
-------+--------+------+----
(0,2) | 184234 | 0 | 1
上面,创建了一个只有一行的表,然后检查该行的活动元组的位置(ctid),进行一个UPDATE操作,从逻辑上讲,它不会做任何事情,它不会实际改变值。但地点变了,从(0,1)(第0页,偏移量1),至(0,2)。因为在物理上,Postgres 创建了一个新的元组——一个新的行版本。了解 Postgres 的这种行为将帮助设计更高效地工作的系统。
2、EXPLAIN
了解查询的运行方式对于优化其性能至关重要。在PostgreSQL中可以使用EXPLAIN命令可以用来了解查询运行的过程。为了获得更精细的视角,需要使用特殊参数化的:EXPLAIN(ANALYZE, BUFFERS)
EXPLAIN本身提供查询计划,让用户深入了解Postgres打算用来获取或修改数据的操作。这包括顺序扫描、索引扫描、连接、排序等等。该命令应单独用于检查查询计划而不执行。添加ANALYZE混合不仅显示计划的操作,还执行查询并提供实际的运行时统计信息。例如可以将估计行数与实际行数进行比较,从而帮助了解Postgres可能出现问题的地方。它还提供每个执行干的操作计时信息。
BUFFERS选项,则提供有关缓冲区使用情况的信息。具体来说,缓冲池中命中了多少块或从底层缓存或磁盘读取了多少块。这提供了有关查询的IO密集程度的底层操作信息。
3、最佳UI工具选择
要深入了解Postgres的世界时,初学者面临的第一个选择是使用哪个客户端或界面。虽然许多初学者因为pgAdmin的受欢迎程度和可访问性而开始使用它,但随着对Postgres了解一点点加深,就会发现一些更强大和通用的工具可用。
当然PostgreSQL最强大的客户端之一是其内置的命令行工具psql。虽然命令行界面对某些人来说可能看起来令人生畏或不方便,但psql包含了高效数据库交互的功能。且它无需额外部署,始终和数据库共存。其在配合上tmux可以让DBA和运维能够轻松管理多个会话和脚本。对于更加喜欢图形界面的用户,有一些界面可以在用户友好性和高级功能之间提供平衡,而且使用图形界面可以帮助初学者突破学习的屏障,让学习曲线更加平滑。
Heidisql、DBeaver、JetBrains DataGrip、Postico提供了复杂的界面,支持查询执行、数据可视化等。无论选择哪种图形工具,都需要投入一些时间来了解其细节psql可能会非常有益。
4、日志记录设置
与许多系统一样,在Postgres中日志是信息宝库,可详细了解系统的操作和潜在问题。通过启用全面的日志记录,可以领先于问题、优化性能并确保数据库的整体健康状况。选择要记录的内容:有效记录的关键是知道要记录的内容而不会使系统不堪重负。通过设置参数:
log_checkpoints = 0,
log_autovacuum_min_duration = 0,
log_temp_files = 0,
log_lock_waits = on,
可以了解检查点、自动清理操作、临时文件创建和锁定等待。这些是一些最容易出现问题的领域,因此对于监控至关重要。
洞察力和开销之间的平衡:需要注意的是,虽然大量日志记录可以提供有价值的洞察力,但它也会带来开销。如果设置log_min_duration_statement到一个非常低的值。例如将其设置为 200ms会记录每一条花费比这更长的时间的语句,这既可以提供信息,也可能会降低性能。始终保持谨慎并意识到 “观察者效应” ——监控过程对被观察系统的影响。但如果没有日志中的详细见解,诊断问题就会更具挑战性。从本质上讲,虽然日志记录是Postgres工具库中一个非常强大的工具,但它需要仔细配置和定期审查,以确保它仍然是一种帮助,而不是一种障碍。
5、性能扩展
为了维护Postgres数据库的性能和健康状况时,一些扩展模块可能是是最佳工具套件。比如pg_stat_statements。该模块提供了一种跟踪服务器成功执行的所有SQL语句的执行统计信息的方法。通俗地说,它可以帮助监控哪些查询正在频繁运行、哪些查询消耗更多时间以及哪些可能需要优化。通过此扩展,可以了解数据库的操作,从而可以发现并纠正效率低下的情况。
尽管pg_stat_statements是自上而下查询分析的核心,还有其他值得注意的扩展可以提供更深入的见解:
pg_stat_kcache:有助于了解实际的磁盘 IO 和 CPU 使用情况,这正是您识别导致高 CPU 利用率或磁盘 IO 的查询的方法
pg_wait_sampling或者pgsentinel:这两个可以更清晰地显示您的查询在哪里花费时间等待 – 提供所谓的等待事件分析,又称活动会话历史记录分析(类似于 RDS Performance Insights)
auto_explain:此扩展自动记录慢语句的执行计划,使理解和优化它们变得更简单
请记住,这些扩展需要一些初始设置和调整才能获得最佳结果和较低的开销。另外,大多数托管Postgres提供商并不提供pg_stat_kcache等这些插件。
6、数据库分支
数据库的开发和测试过程通常需要复制数据,这可能会占用大量资源、速度缓慢且繁琐。然而通过精简克隆和分支,有一种更聪明的方法。
精简克隆
精简克隆工具提供轻量级、可写的数据库克隆。这些克隆与源共享相同的底层数据块,但对用户来说显示为独立的数据库。当对克隆进行更改时,只有这些更改会消耗额外的存储。这是使用写时复制(CoW)实现的,类似于容器或Git的功能,但在块级别而不是文件级别。这使得创建用于开发、测试或分析的多个副本变得异常快速和高效。
数据库分支的好处
数据库分支是精简克隆的扩展,能够保存进度并允许基于新状态进一步创建克隆。 就像代码版本控制一样,数据库上下文中的分支允许开发人员在主数据集之外创建分支。 这意味着您可以在隔离环境中测试新功能或更改,而不会影响主要数据。
数据校验
数据完整性是任何数据库的基石。 如果不相信数据的准确性和一致性,即使是最先进的数据库结构或算法也会变得毫无用处。 这就是 Postgres 中的数据校验和发挥关键作用的地方。
数据校验和
在数据库上下文中,校验和是从数据块中所有字节之和得出的值。如果启用了数据校验和,Postgres将使用它来验证磁盘上存储的数据的完整性。当数据写入磁盘时,Postgres 会计算并存储校验和值。随后,当该数据被读回内存时,Postgres会重新计算校验和并将其与存储的值进行比较,以确保数据没有被损坏。
数据存储
磁盘级损坏可能是由多种因素引起的,从硬件故障到软件错误。启用数据校验和后,Postgres可以在损坏的数据影响您的应用程序或导致更大问题之前识别出损坏的数据。
激活
需要注意的是,数据校验和需要在数据库集群创建时激活(initdb)。如果不转储和恢复数据,或者不使用特殊工具,则无法为现有数据库集群打开它们, pg_checksums(这需要经验)。与数据校验和相关的开销相对较小,特别是与确保数据完整性的好处相比。
7、自动清理
自动清理过程就像数据库的清洁人员。自动清理进程在后台工作,清理旧数据并为新数据腾出空间,以确保数据库保持高效。
Postgres中的INSERT,UPDATE,DELETE的操作都会创建行(元组)的一个版本。随着时间的推移,这些旧版本会累积并需要清理。自动清理通过回收存储空间、删除死行来进行清理。它还负责保持表统计信息最新并防止事务 ID 环绕事件。
如果不定期进行自动清理,数据库可能会出现膨胀——数据库保留未使用的空间,这会减慢查询速度并浪费磁盘空间。另一个问题是过时的统计数据,可能导致计划选择次优和性能下降。配置自动清理使其运行更频繁并更快地完成任务。在高层次上,调整必须在两个方向上进行:
给予autovacuum 更多权限
更多的工作人员,更大的配额,因为默认情况下,它只允许3个工作进程,并且受到相当保守的限制。
让它更频繁地触发
因为默认情况下,只有当元组的10-20%发生重大更改时,它才会触发;在OLTP中,可能需要将其减少到1%甚至更低。
8、查询优化
当谈到Postgres的性能时,在大多数情况下,最好“足够好”地优化Postgres配置,不经常重新审视决策(仅当发生Postgres主要升级等重大变化时),然后完全专注于查询调优。通过初期调整其配置可以提高性能。但随着应用程序的增长和发展,性能的主要争夺通常从配置转移到查询优化。正确结构化的查询可能是平滑扩展的应用程序和在负载下逐渐停止的应用程序之间的区别。最终将不得不转向不断优化查询。
9、调优
前面提到老的pg_stat_statements是识别有问题查询的宝贵工具。它提供了 SQL语句的排名列表,按各种指标排序。当与 EXPLAIN (ANALYZE, BUFFERS)在上面也讨论过,可以了解查询的执行计划并查明效率低下的地方。
索引维护
在任何关系数据库系统,影响性能的最关键因素是索引,Postgres中更是如此。随着时间的推移,随着数据的变化,索引变得碎片化并且效率降低。即使使用最新Postgres版本(特别是使用btree优化的Postgres13和14)和经过调优的autovacuum,索引健康状况仍然会随着时间的推移而下降,同时发生大量写入。
健康指数
当插入、更新或删除数据时,反映该数据的索引会发生变化。这些更改可能会导致索引结构变得不平衡或出现死条目,从而降低搜索性能。
索引重建
索引不会无限期地保持其最佳结构。它们需要定期重建。此过程涉及创建新版本的索引,这通常会产生更紧凑、更高效的结构。为这些重建做好准备(最好以自动化方式进行)可确保数据库性能保持一致。
清理
除了重建之外,删除未使用或冗余的索引也同样重要。它们不仅浪费存储空间,还会减慢写入操作。定期检查和清理不必要的索引应该成为日常维护的一部分。
重申一个关键点:索引至关重要,但像所有工具一样,它们需要维护;保持它们的健康对于维持 Postgres 数据库的快速性能至关重要。
10、now() 的陷阱:事务内时间静止问题
PostgreSQL 中 now() 是常用的时间函数,但当它在事务内部被调用时,行为可能出乎意料;开发者 Marcin 于2026年5月在开发 Emmett 库时踩到了这个坑,并在博客中详细记录了问题根因和解决方案。
核心问题在于:now() 返回的是事务开始时的时间戳,而非每次调用时的当前时间。这意味着在同一事务内,无论代码运行了多久、经过了多少次重试,now() 的值始终是事务开启时的那个时间点。
这个特性为什么会引发 Bug?Marcin 遇到的具体场景是分布式锁的获取重试逻辑。当持有锁的事务超时释放后,需要用 WHERE lock_expires_at <now () 来找到已过期的锁并尝试重新获取。但如果整个重试流程都发生在同一个事务内,now() 永远等于事务开始的时间 —— 即那个锁还没有过期的时刻。WHERE 条件因此无法正确筛选出过期的锁,重试逻辑失效。
解决方案是用 clock_timestamp() 替代 now ()。与 now() 不同的是 clock_timestamp() 每次调用都返回真实的当前时间,因此即使在事务内部也能反映时间的流逝。
两者的语义区别值得记住:now() 适合在同一事务内需要所有记录共享同一时间戳的场景 —— 例如审计日志中需要记录事务开始时间;而 clock_timestamp() 适合需要判断时间是否已经推进的场景 —— 例如检查超时、处理定时任务。
这是一个典型的 "看起来正确但实际埋坑" 的案例。直觉上 now() 代表 "当前时间",但 PostgreSQL 的事务语义让它在事务内部变成了一个常量。在做时间相关条件判断时,特别是涉及重试逻辑的代码,养成先问自己 "这个判断是否需要真实时间" 的习惯,可以避免很多难以调试的生产问题。
PostgreSQL中文社区上有较新的FAQ(v8.4):
一般常见问题汇总(FAQ)
开发人员常见问题汇总(DEV_FAQ)
本文源自:互联网