开箱即用的PostgreSQL发行套件-Pigsty
 Pigsty 是开箱即用的开源 PostgreSQL 发行版。带有全面专业的监控系统,稳定可靠的部署方案;提供简单省心的用户界面,与灵活开放的扩展机制。可以用于大规模生产数据库的监控部署与管理;也可以在本地 1 核 1GB 的虚拟机中运行,用于学习、开发、测试与数据分析等场景。注意该软件方案主要在AGPLv3.0协议下授权,v4.0 重新从 AGPLv3 许可证改回了 Apache 2.0 宽松许可证。
Pigsty 是开箱即用的开源 PostgreSQL 发行版。带有全面专业的监控系统,稳定可靠的部署方案;提供简单省心的用户界面,与灵活开放的扩展机制。可以用于大规模生产数据库的监控部署与管理;也可以在本地 1 核 1GB 的虚拟机中运行,用于学习、开发、测试与数据分析等场景。注意该软件方案主要在AGPLv3.0协议下授权,v4.0 重新从 AGPLv3 许可证改回了 Apache 2.0 宽松许可证。PostgreSQL In Great STYle.
—— A battery-included, local-first, open-source RDS PG alternative.
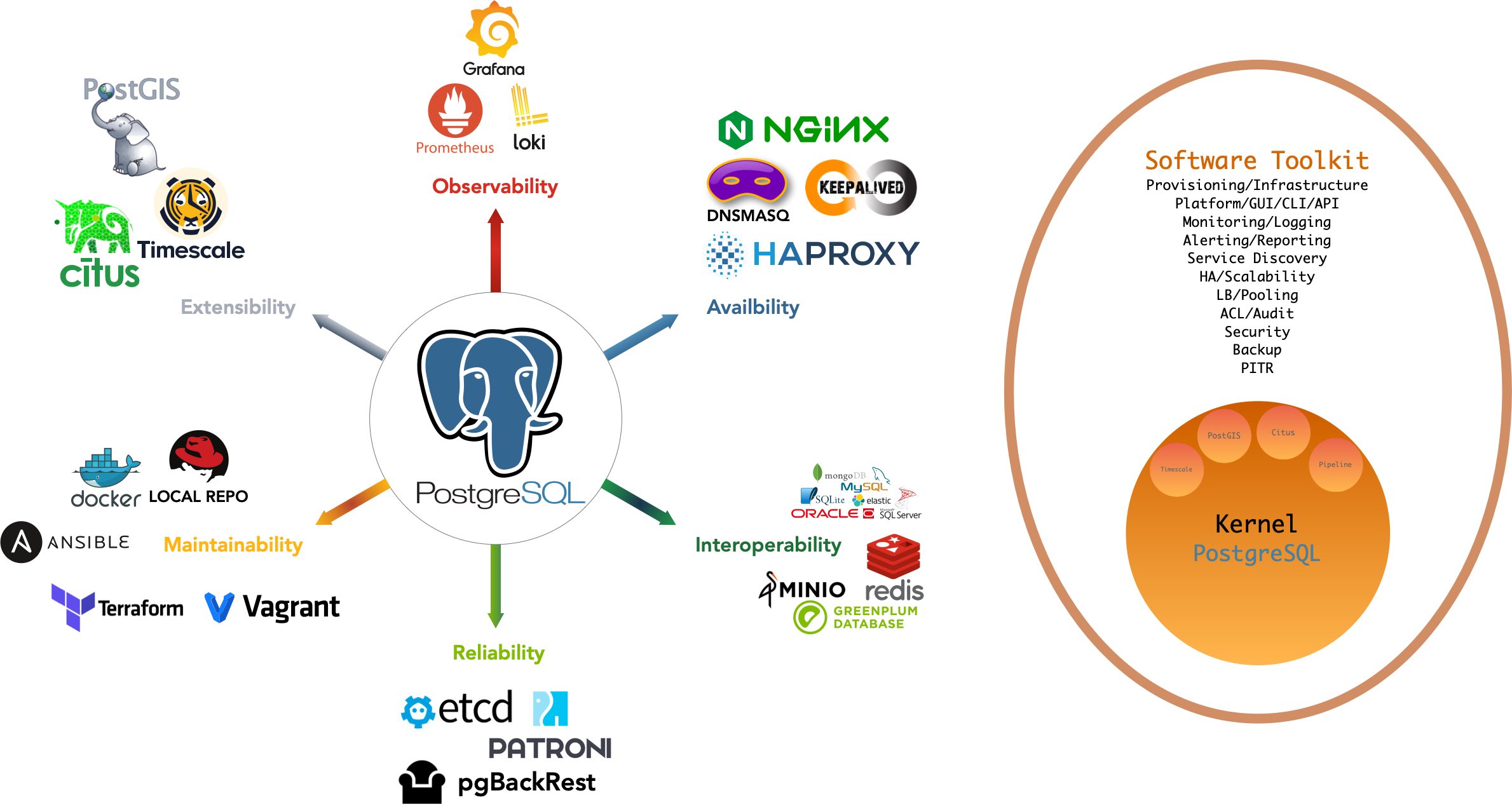
特性
全面专业的监控系统,基于 Grafana & Prometheus & pg_exporter
稳定可靠的部署方案,基于 Ansible 的物理机/虚拟机部署。
简单省心的安装方式与用户界面,开箱即用的沙箱环境,降低使用门槛。
高可用数据库集群架构,基于 Patroni 实现,具有秒级故障自愈能力。
基于 DCS 的服务发现与配置管理,维护管理自动化,智能化。
无需互联网访问与代理的离线安装模式,快速且可靠。
代码定义的基础设施,可配置,可定制。
基于 PostgreSQL 13 与 Patroni 2.0,享受最新特性。
长时间的大规模生产环境验证(200+ node x 64C|400GB|3TB)
功能介绍
监控系统
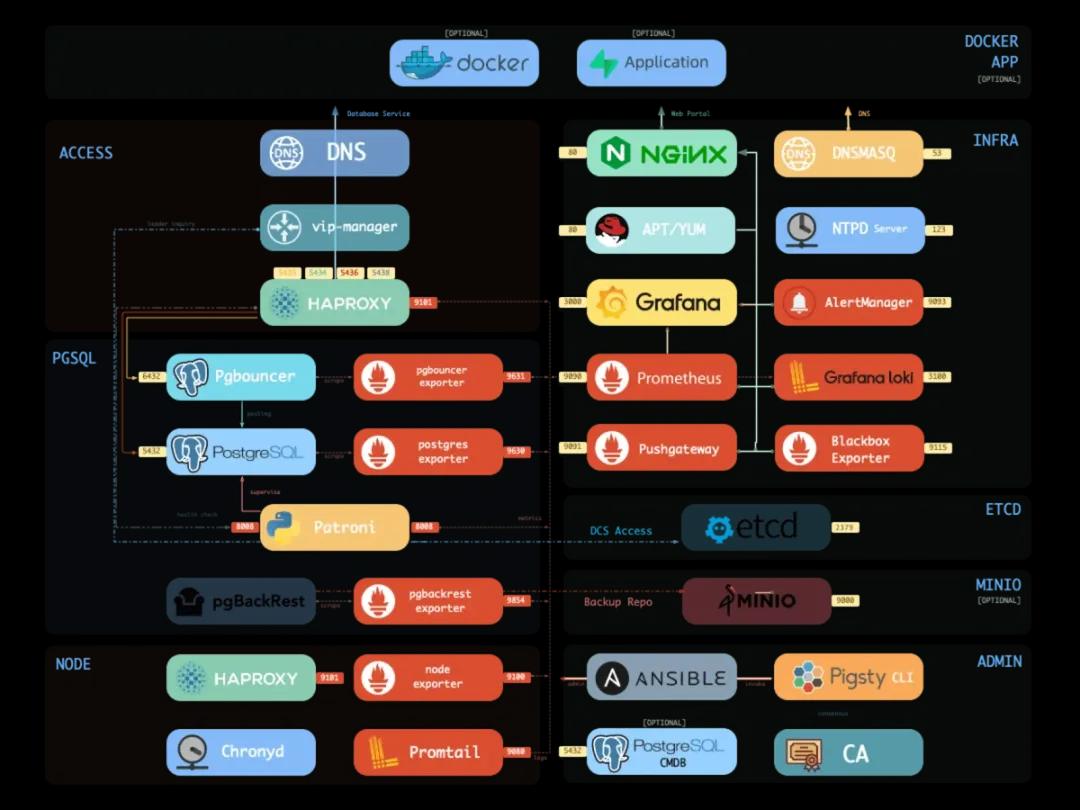
Pigsty 带有一个针对大规模数据库集群管理而设计的专业级 PostgreSQL 监控系统。包括约 1200 类指标,20 + 监控面板,上千个监控仪表盘,覆盖了从全局大盘到单个查询的详细信息。面向专业用户,提供不可替代的价值点。监控系统基于业内最佳实践,采用 Prometheus、Grafana 作为监控基础设施。开源开放,定制便利,可复用,可移植,没有厂商锁定。可与各类已有数据库实例集成。
部署方案
数据库是管理数据的软件,管控系统是管理数据库的软件。
Pigsty 内置了一套以 Ansible 为核心的数据库管控方案。并基于此封装了命令行工具与图形界面。它集成了数据库管理中的核心功能:包括数据库集群的创建,销毁,扩缩容;用户、数据库、服务的创建等。Pigsty 采纳 “Infra as Code” 的设计哲学使用了声明式配置,通过大量可选的配置选项对数据库与运行环境进行描述与定制,并通过幂等的预置剧本自动创建所需的数据库集群,提供近似私有云般的使用体验。其吸纳了 Kubernetes 架构设计中的精髓,采用声明式的配置方式与幂等的操作剧本。用户只需要描述 “自己想要什么样的数据库”,而无需关心 Pigsty 如何去创建它,修改它。Pigsty 会根据用户的配置文件清单,在几分钟内从裸机节点上创造出所需的数据库集群。
高可用
Pigsty 创建的数据库集群是分布式、高可用的数据库集群。Pigsty 创建的数据库基于 DCS、Patroni、Haproxy 实现了高可用。数据库集群中的每个数据库实例在使用上都是幂等的,任意实例都可以通过内建负载均衡组件提供完整的读写服务,提供分布式数据库的使用体验。数据库集群可以自动进行故障检测与主从切换,普通故障能在几秒到几十秒内自愈,且期间只读流量不受影响。故障时。集群中只要有任意实例存活,就可以对外提供完整的服务。其架构方案经过审慎的设计与评估,着眼于以最小复杂度实现所需功能。该方案经过长时间,大规模的生产环境验证,已经被多个行业内的组织所使用。
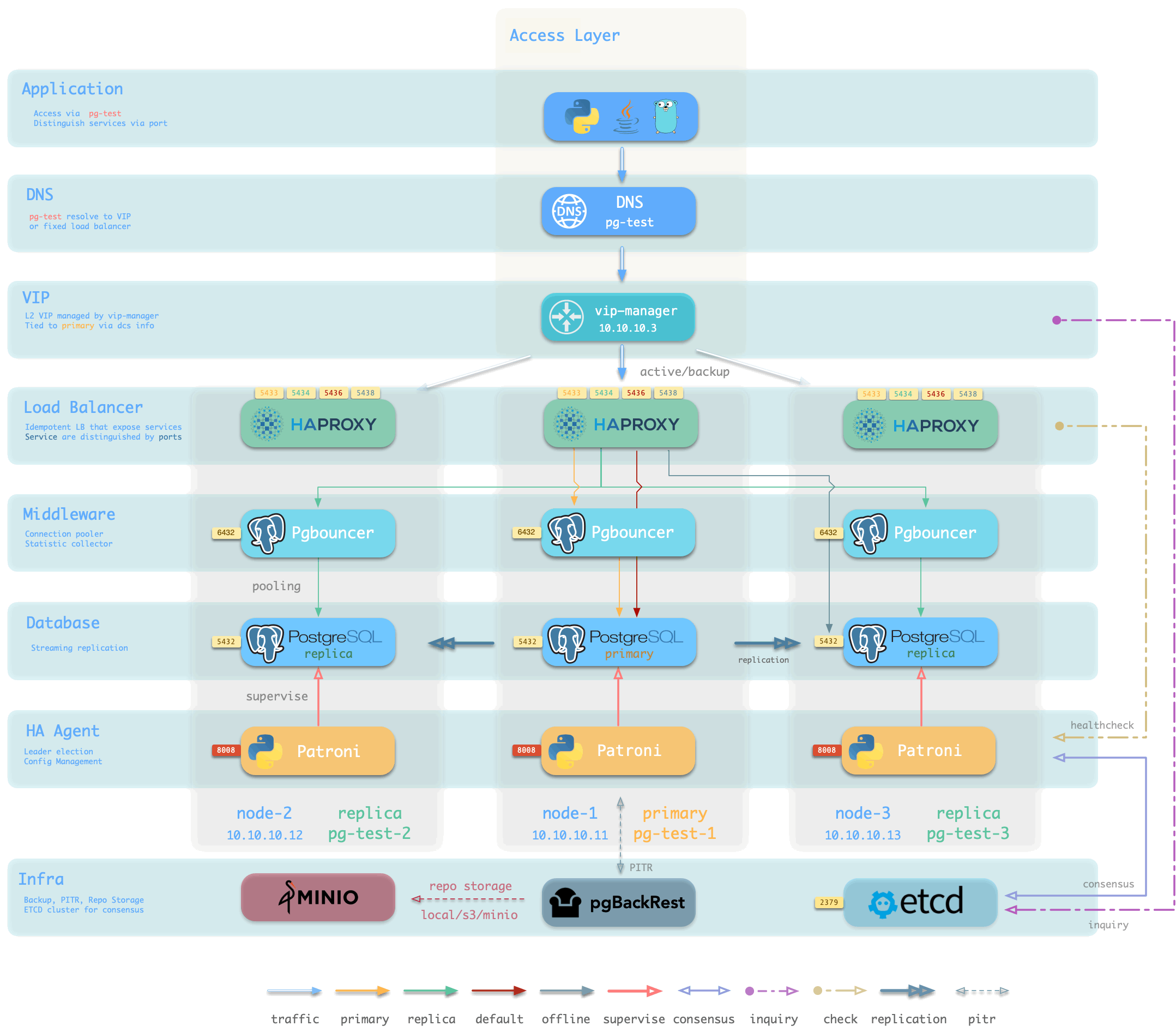
用户界面
Pigsty 旨在降低 PostgreSQL 的使用门槛,因此在易用性上做了大量工作。部署分为三步:下载源码,配置环境,执行安装,均可通过一行命令完成。遵循经典的软件安装模式,并提供了配置向导。您需要准备的只是一台 CentOS7.8 机器及其 root 权限。管理新节点时,Pigsty 基于 Ansible 通过 ssh 发起管理,无需安装 Agent,即使是新手也可以轻松完成部署。
在管理与使用上,Pigsty 提供了不同层次的用户界面,以满足不同用户的需求。新手用户可以使用一键拉起的本地沙箱与图形用户界面,而开发者则可以选择使用 pigsty-cli 命令行工具与配置文件的方式进行管理。经验丰富的 DBA、运维与架构师则可以直接通过 Ansible 原语对执行的任务进行精细控制。
服务发现
Pigsty 提供了可选的服务发现机制,基于 DCS(Consul/Etcd)实现。监控系统将自动从服务注册中心发现所有的监控对象,而 Patroni 则使用 DCS 作为集中的配置存储。Consul 提供 DNS 可用作客户端服务发现机制,而 UI 可以让您对环境中的服务一览无余。
沙箱环境
Pigsty 既可以在生产环境中管理成百上千个高规格的生产节点,也可以独立运行于本地 1 核 1GB 虚拟机中,作为开箱即用的数据库实例使用。在本地计算机上使用时,Pigsty 提供基于 Vagrant 与 Virtualbox 的沙箱。可以一键拉起与生产环境一致的数据库环境,用于学习,开发,测试数据分析,数据可视化等场景。
离线安装
Pigsty 支持离线安装,对于没有互联网访问的环境尤为方便。Pigsty 的离线安装包中带有监控系统,数据库以及所有相关的依赖。您可以通过向导自动下载,或从 Github Release 页面或 CDN 手工下载离线安装包。
数据分析
Pigsty 提供了一种名为 “Datalet” 的扩展机制,允许用户和开发者对 Pigsty 进行进一步的定制,将其用到意想不到的地方,例如数据分析与可视化。Pigsty 集成了 Echarts,以及常用地图底图等,可以方便地实现高级可视化需求。比起 Julia,Matlab,R 这样的传统科学计算语言 / 绘图库而言,PG + Grafana + Echarts 的组合允许您以极低的成本制作出可分享,可交付,标准化的数据应用或可视化作品。
所有 Pigsty 高级专题监控面板都会以 Datalet 的方式发布。Pigsty 也自带了一些的 Datalet 案例:Redis 监控系统,疫情数据分析,七普人口数据分析,PG 日志挖掘等。
最新版本:2.1
v2.1.0 于2023年6月上旬发布,为跟随 PG 社区主干的例行升级,添加 PG 11 - 16 支持,现在您可以使用 Pigsty 部署 PG 15.3 , 14.8, 13.11, 12.15, 与 16 beta1。v2.1 针对 PostgreSQL 16 进行了适配,改进了监控系统效果,添加了一系列便利命令工具,建议按需升级。具体更新内容包括:
PostgreSQL 16 beta 支持,以及 12 ~ 15 支持。
添加 PGVector for AI Embedding for 12 - 15
为 grafana 添加 6 个额外的面板和数据源插件
添加 bin/profile 来配置文件远程进程并生成火焰图
添加 bin/validate 验证 pigsty.yml 配置文件
添加 bin/repo-add 来添加上游 repo 文件到 /etc/yum.repos.d
PostgreSQL 16 可观察性:pg_stat_io 和相应的仪表板
PostgreSQL 15.3、14.8、13.11、12.15、11.20 和 16 beta1
pgBackRest 2.46
pgbouncer 1.19
Redis 7.0.11
Grafana v9.5.3
Loki/Promtail/Logcli 2.8.2
Prometheus 2.44
TimescaleDB 2.11.0
minio-20230518000536/mcli-20230518165900
Bytebase v2.2.0
现在在安装本地用户的公钥时使用所有的 id*.pub
更新说明详见此处。
最新版本:2.3
Pigsty v2.3 现已于2023年8月下旬发布,此版本进一步完善了监控系统、应用生态、并跟进 PostgreSQL 例行的小版本更新(CVE 修复)。跟随 PostgreSQL 主干小版本进行更新,包括 15.4, 14.9, 13.12, 12.16 以及 16.beta3,此更新修复了一个 CVE 安全漏洞。此外高可用管控 Patroni 也升级到 3.1 版本,解决了一些 BUG 。
v2.3 提供了对 FerretDB 的支持,它是一个构建在 PostgreSQL 之上,真正开源的 MongoDB 替代。用户可以使用 MongoDB 客户端访问它,但是真正的数据都存储在底层的 PostgreSQL 里。还默认添加了一款名为 NocoDB 的开源应用:这是 AirTable 的开源替代:这是一个数据库 - 电子表格的混合体,可以用低代码的方式快速打造一个多人在线协作应用。新增了为主机节点集群绑定一个 L2 VIP 的功能,使用 VRRP 协议确保全链路上没有单点,并提供了完整的监控:keepalived_exporter 被用于收集监控数据。而且每一个 Node VIP (keepalived)与 PGSQL VIP (vip-manager)都会添加到 blackbox_exporter 的 ICMP / PING 监控列表中。
在监控系统上,v2.3 在 v2.2 的基础上进行了打磨优化:新增了 VIP 监控,VIP 与节点 PING 指标被加入到 NODE / PGSQL 监控的醒目位置;PGSQL 监控新增了锁等待树视图;REDIS 监控进行了风格优化;MinIO 监控适配的新的监控指标名称;MySQL / MongoDB 监控新增了实现存根,为后续实现奠定基础。
MongoDB 支持
MongoDB 是一个很受欢迎的 NoSQL 文档数据库。但由于开源协议问题(SSPL),与软件定位问题(Postgres 发型版),Pigsty 决定使用 FerretDB 来提供对 MongoDB 的支持。FerretDB 是一个有趣的开源项目:它让 PostgreSQL 可以提供 MongoDB 的能力。
MongoDB 与 PostgreSQL 是两个非常不同的数据库系统:MongoDB 使用文档模型,使用专用的查询语言进行交互 。但是鉴于 PostgreSQL 也提供了完整的 JSON/JSONB/GIN 功能支持,所以这么做在理论上也是完全可行的:FerretDB 负责将你的 SON 查询转换为 SQL 查询:use test
在 Pigsty 定义一个 FerretDB 集群与其他类型的数据库并无二致,你仅需要提供核心的身份参数:集群名称与实例号。需要关注的是 mongo_pgurl 参数,它指定了 FerretDB 底层使用的 PostgreSQL 地址。
可以直接填入一个已由 Pigsty 创建的任意 PostgreSQL 服务地址。数据库不需要预先配置什么,只需要确保所使用的用户具有 DDL 权限即可。配置完成后使用 ./mongo.yml -l ferret 即可完成安装。当然,如果更喜欢使用容器,也可以直接 cd pigsty/app/ferretdb; make 使用 docker-compose 拉起 FerretDB 使用。安装完成后可以使用任何 MongoDB Client 访问 FerretDB,例如 MongoSH:
mongosh 'mongodb://test:test@10.10.10.45:27017/test?authMechanism=PLAIN'
对于那些希望从 MongoDB 迁移到 PostgreSQL 的用户来说,这是一种改造成本极小的折衷手段。Pigsty 同样提供了另一种支持方式 MongoFDW:在 PostgreSQL 中使用 SQL 查询现有的 MongoDB 集群。
新应用:NocoDB
在 v2.3 中添加了对 NocoDB 的内置支持,可以使用默认的 Docker Compose 模板,一键拉起 NocoDB 并使用内置的 PostgreSQL 作为存储。NocoDB 是 Airtable 的开源替代品,那 AirTable 又是什么呢?其实有点类似于 Google Docs/腾讯云文档。但是提供了非常丰富的接口,钩子,可以用来实现一些非常强大的功能。
NocoDB 可以让各种关系型数据库变身成为 Excel,运行你自己的本地云文档软件。它也可以让用户用低代码的方式实现一些需求:比如你可以把自动生成的表单发送给别人填写,将结果自动整理成为实时共享、可协作、可编程的多维表格。在 Pigsty 中拉起 NocoDB 非常容易,只需要一行命令即可。可以修改 .env 中的 DATABASE_URL 参数来使用不同的数据库。
cd ~/pigsty/app/nocodb; make up
Node VIP 支持
Pigsty v2.3 新增了为主机节点集群绑定一个 L2 VIP 的功能,使用 VRRP 协议确保全链路上没有单点,并提供了完整的监控。
在古早的 Pigsty 版本中(0.5 前),曾经提供过基于 Keepalived 的 L2 VIP 功能实现。但随后被 HAProxy + VIP-Manager 所取代:HAProxy 不挑网络,可以进行灵活的健康检查、流量分发,更是提供了一个简单易用的管控界面。而 VIP Manager 则可以将一个 L2 VIP 绑定在数据库集群主库上。但通用的 L2 VIP 需求仍然是存在的,例如,如果用户选择使用 HAProxy 集群接入,那么 HAProxy 本身的可靠性如何保证?尽管你可以使用 DNS LB 的方式进行切换,但 VRRP 在可靠性与易用性上显然更胜一筹。此外,MinIO/ETCD ,Prometheus 这些组件,有时也会有这样的需求。
想要为集群绑定一个 L2 VIP 其实很简单,只需要启用 vip_enabled,分配一个 VLAN 中唯一的 VirtualRouterID 号与 VIP 地址就可以了。默认情况下,所有集群成员使用 BACKUP 初始状态以非抢占模式工作。你可以通过设置 vip_role 与 vip_preempt 来改变这一行为。L2 VIP 会自动被纳入监控中。当 MASTER 宕机后, BACKUP 会立即进行接管。
监控系统改进
Pigsty v2.2 基于 Grafana 10 对监控系统进行了彻底的翻新重制。v2.3 在 v2.2 的基础上进行了更多优化。例如新增的 NODE VIP 监控面板用于展示一个 VIP 的状态:所属集群/成员,网络 RT,KA 的状态等等。
更丝滑的构建流程
Pigsty v2.2 提供了官方 Yum 源,在 v2.3 中则默认启用了全站 HTTPS。当选择直接从互联网下载 Pigsty 所需的软件时,可能会遭遇到功夫网的烦恼。例如默认的 Grafana / Prometheus Yum 源下载速度极慢。除此之外,还有一些零散的 RPM 包需要通过 Web URL 的方式,而不是 repotrack RPM 的方式进行下载。
在 v2.2 中解决了这个问题。Pigsty 提供了一个官方的 yum 源:http://get.pigsty.cc ,并配置为默认的上游源之一。所有零散的 RPM,需要翻墙的 RPM 都放置其中,可以有效加快在线安装 / 构建速度。此外 Pigsty 还在 v2.2 中提供了对信创操作系统,统信 UOS 1050e uel20 的支持,满足一些特殊客户的特殊需求。Pigsty 针对这些系统重新编译了 PG 相关的 RPM 包,为有需求的客户提供支持。
安装
Pigsty v2.3 的安装命令为:bash -c "$(curl -fsSL https://get.pigsty.cc/latest)"
一行命令,即可在全新机器上完整安装 Pigsty. 如果你想要尝鲜 beta 版本,将 latest 换为 beta 即可。对于没有互联网访问的特殊环境,也可以使用以下链接下载 Pigsty,以及打包了所有软件的离线安装包:https://get.pigsty.cc/v2.3.0/pigsty-v2.3.0.tgz
以上就是 Pigsty v2.3 带来的变化。更多细节可参考 Pigsty 官方文档与 Github Release Note。
最新版本:4
v4.2于2026年3月上旬正式发布,紧随 PostgreSQL 紧急号外小版本更新。本次更新同时交付了三款全新 PG 内核 —— 图数据库 AgensGraph、多写分布式 pgEdge、MPP 数仓 Cloudberry —— 并重建了 Babelfish、OrioleDB、OpenHalo 三款既有内核。至此 Pigsty 支持的内核总数达到了 12 个。可以用一份配置文件,把所有这些不同风味的 PostgreSQL 部署为自带监控、高可用、时间点恢复与 IaC 的企业级数据库服务。这就是 "Meta PG 发行版" 的含义。v4.0 的主题是:更开放、更高效、更安全、更智能。v4.0 重新从 AGPLv3 许可证改回了 Apache 2.0 宽松许可证。对于用户来说,当在公司使用时,就不需要再和法务去讨论了,ISV 也可以用它放心地集成,作为各类软件与项目的底座。如果想做一个自己的定制 PG 发行版,也完全可以在 Pigsty 的基础上进行,避免重复造轮子。
PostgreSQL 以极致的可扩展性闻名。生态中有超过 1000 个扩展,Pigsty 则提供了其中 461 个开箱即用。但有些能力是扩展做不到的 —— 比如定制语法。如果想在 PostgreSQL 里原生使用 Oracle 的 PL/SQL、SQL Server 的 T-SQL、MongoDB 的 BSON 协议、或者 Cypher 图查询语法,而不是通过函数调用来模拟,那就需要修改内核。这也是为什么 Pigsty 不仅提供生态中数量最多的扩展,还要支持不同的内核分支。在 Pigsty 里使用这些内核,和使用原版 PostgreSQL 几乎没有区别 —— 同样的部署流程、同样的监控面板、同样的高可用机制、同样的备份恢复。区别只是配置文件里改一个 pg_mode 的值。一行配置的差异,工程上的大一统。
这次 PostgreSQL 的小版本更新值得单独提一下。v18.2 系列引入了 substring 与 WAL 回放相关的回归问题 —— 修漏洞的时候带进了新 bug。社区在两周后紧急发布了 18.3 / 17.9 / 16.13 / 15.17 / 14.22 补丁版本。Pigsty 的做法还是老规矩 —— 新版本发布次日,离线安装包就绪、所有扩展重新编译验证、文档同步更新。你要做的就是一行命令的事。
扩展总数也顺势推到了 461 个。如果追求极致的可扩展性和最佳的稳定性,原生 PostgreSQL 始终是最佳默认选择。Pigsty 支持处于生命周期内的 PG 14 到 PG 18。值得一提的是,本版本是最后一个支持 PG 13 的版本,后续最低版本将升至 PG 14。
pgEdge:原生多主复制
pgEdge 是本次新增的重量级选手。传统 PostgreSQL 高可用是一主多从 —— 写操作只能发往主节点。pgEdge 的核心扩展 Spock 打破了这个限制:集群中的每个节点都可以读写,数据通过逻辑复制在节点间异步同步,冲突通过可配置策略自动解决。
严格来说,pgEdge 不是一个全新的内核,而是基于标准 PostgreSQL + Spock 扩展的多主方案。但由于多主复制的一些底层能力需要内核补丁(这些 Patch 尚未合并到 PostgreSQL 主干),它目前不得不以"Patch 内核 + 扩展"的方式发布。这一点和 OrioleDB、Percona TDE 类似 —— 如果 PostgreSQL 主干未来合并了这些 Patch,它们都可以转变为纯扩展形态工作,这是非常值得期待的趋势。
pgEdge 团队有几位 PostgreSQL 社区的内核老将,技术功底很扎实。关于它的开源历程也值得一说:之前它使用的是类似 Confluent 风格的 Source Available 协议(pgEdge Community License),严格来说不算开源。但 2025 年 9 月,它全面转向了 PostgreSQL License。
不过有个细节需要注意:源代码遵循 PostgreSQL 协议,但官方提供的二进制包依然受商业许可约束。具体来说,开发环境可以免费使用,但生产环境必须付费订阅。老冯直接基于 PostgreSQL 协议的源码自行打包 —— 制作了带 Patch 的 PostgreSQL 内核包,并在 Pigsty 支持的全部主流操作系统上完成适配。没有外部依赖,从 Pigsty 仓库直接装就行,不存在生产环境的许可问题。当然,如果你想用他们的云服务和商业支持,也欢迎去打钱支持一下。
pgEdge 由三个核心扩展组成:
•Spock 5.0.5:多主逻辑复制引擎,每个节点同时处理读写
•Lolor 1.2.2:大对象逻辑复制
•Snowflake 2.4:分布式序列号生成
冲突解决方面,pgEdge 提供了多种策略:最简单的"最后写入获胜"(LWW)、专门的 CRDT 方案、冲突日志表、以及用户自定义策略。如果有全球地理分布的需求 —— 比如北京、法兰克福、弗吉尼亚各放一个节点,用户就近读写 —— 这种多主模式非常合适。它相当于在 PostgreSQL 生态里原生提供了类似 CockroachDB / TiDB 的多写能力,只不过底座还是那个你熟悉的 PostgreSQL。
在 Pigsty 中使用只需要:configure -c pgedge。
AgensGraph:图数据库
AgensGraph 的定位是基于 PostgreSQL 的多模型图数据库 —— 在一个引擎内同时原生支持关系模型和属性图模型,而不是像 Neo4j 那样另起炉灶。这是由韩国 Bitnine 团队发起主导的项目。有人会问:PostgreSQL 生态里不是有 Apache AGE 这个图扩展吗,为什么还要做 fork 内核?
这里有个有意思的渊源:AGE 和 AgensGraph 其实是同一个团队做的。最初他们做的是 AgensGraph 这个内核 fork,大概 1000 多个 Star。后来他们尝试以扩展形式实现类似功能,做了 AGE 并捐献给 Apache。结果扩展形式反而更受欢迎,拿到了 4000 多个 Star。
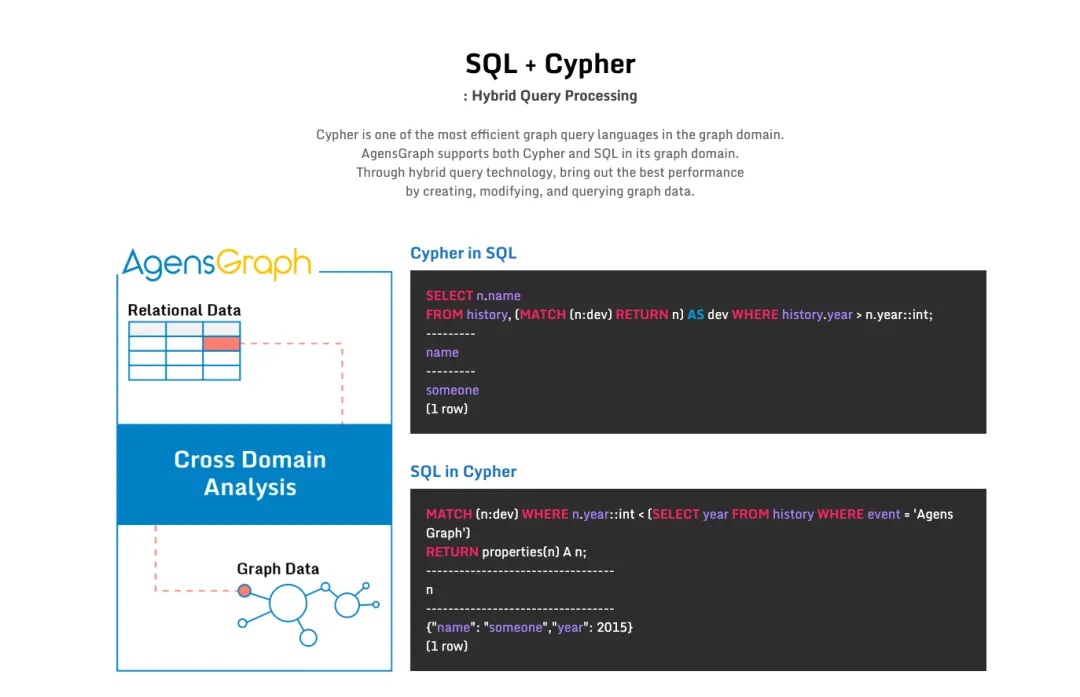
AGE 虽然在2025年经历了一阵维护风波,但最近已恢复更新,发布了针对 PG 17/18 的 1.7.0 版本。那 fork 版本还有什么存在价值?至少四个方面:
一是原生语法。在 AGE 里需要用函数调用来执行 Cypher 查询(把查询字符串传进去);而在 AgensGraph 里,你可以直接写 CREATE GRAPH,Cypher 是一等公民语法。
二是存储优化。它的存储引擎针对图属性做了专门优化,理论上性能更好(虽然我还没实际 bench 过)。
三是查询优化统一。Cypher、JSON、SQL 三种查询语言在优化器层面是统一处理的,这种原生实现方式很有意思。
四是向量兼容。AgensGraph 最近宣称支持了 pgvector 兼容,意味着可以在同一个库里做 Graph RAG —— 图 + 向量的组合检索。这是当下非常火的前沿方向。这个专门的 vector 插件我还没打包进来,后面可能会补上。
当然,fork 路径的代价也很明显:版本跟进 PG 主线的难度很高。目前 PG 已经到 18 了,AgensGraph 还是基于 PG 16。这始终是 fork 方案的宿命,要落后一两个大版本。
在 Pigsty 中使用:configure -c agens。
Cloudberry:MPP 数仓
Cloudberry 是本次新增的第三款内核。它是一个 Apache 项目,由 HashData 团队主导,本质上是 Greenplum 7 的 fork —— 但做了不少改进,比如内核从 Greenplum 的 PG 12 升级到了 PG 14,补上了不少好用的新特性。v2.0 发布后就不再提供官方二进制包了 —— 之前 1.18 和 1.19 还有 RPM,现在也没了。等了几个月没见到官方有计划解决这个问题,就决定在 Claude 的帮助下自己动手。打包过程整体顺利,只是在个别较新的操作系统上需要改些代码、打几个补丁。之前只有 RPM,现在 DEB 也有了,Pigsty 支持的 14 个 Linux 发行版上全部可用。
关于 Cloudberry/Greenplum 的部署脚本和监控方案,其实早在 Pigsty v1.4 就做过,后来因为用户太少就去掉了。毕竟上 MPP 数仓的体量不是一般公司能达到的。所以思忖再三,先将其作为 Beta 模块按需提供 —— 包已经打好放在仓库里了,可以直接下载使用;完整的部署剧本会在后续版本中择机提供。
Babelfish:SQL Server 兼容
说完三个新增内核,再来聊三个重建的内核。
Babelfish 是 AWS 开源的 SQL Server 兼容层 —— 让 PostgreSQL 理解 T-SQL 语法和 TDS 协议,你的 SQL Server 应用不改驱动、不改大部分查询,就能连上 PostgreSQL 跑起来。好项目,但打包构建实在是复杂,复杂到专门有一个开源项目 WiltonDB 就是干这件事的。
之前直接用了 WiltonDB 打的包。说实话那个包的质量一直让人不太舒服:不支持 Debian 全系列和 EL10,依赖体系跟标准 PG 不一样,而且版本还停留在 PG15 —— 但 Babelfish 上游都已经支持 PG17 了。这次有了前面几个内核的打包经验,这个反而简单了 —— 把 Babelfish 的四个核心扩展打成一个包,配合一个 Patch 内核包,开箱即用。现在不再依赖外部 WiltonDB 仓库,直接从 Pigsty 仓库安装即可。版本升级到了 Babelfish 5.5 + PG17。
在 Pigsty 中使用:configure -c mssql。
OrioleDB:新存储引擎
OrioleDB 是被 Supabase 收购的新一代 PostgreSQL 存储引擎项目,目标是从根本上解决 MVCC 膨胀问题 —— 用 Undo Log 替代传统的 Dead Tuple + VACUUM 机制。本次重建升级到了 OrioleDB Beta14,基于 OriolePG 17.16 构建。新版本的一个重要进展是支持了 PITR 增量备份恢复能力。仍处于 Beta 阶段,不建议关键生产环境使用。但作为 PostgreSQL 存储引擎的未来演进方向之一,值得持续关注和实验。
在 Pigsty 中使用:configure -c oriole。
OpenHalo:MySQL 协议兼容
OpenHalo 是重建的第三个内核。它提供了 MySQL 线缆协议兼容 —— 你可以同时用 MySQL 客户端和 PG 客户端读写同一个数据库,这个能力非常有意思。由易景羲和团队开发,是少数几家踏踏实实做事、并且愿意把成果开源出来的国产数据库公司,很难得。这次更新的变化:
•版本从 PG 14.10 升级到 14.18
•版本号正式更新为 1.0,按照 Pigsty 打包规范重新调整了命名
虽然基线版本是 PG14,稍显陈旧,但在 MySQL 迁移场景下确实是一个值得考虑的选择。
在 Pigsty 中使用:configure -c mysql。
其余六位常驻选手
除了本次新增和重建的六款内核,Pigsty 还有6位一直在的"常驻选手":
IvorySQL(pg_mode: ivory)—— 瀚高出品的 Oracle PL/SQL 兼容内核,目前基于 PG 18.1。
Percona TDE(pg_mode: tde)—— 透明数据加密,满足合规场景中"落盘加密"的刚需。更新节奏稍慢于 PG 主线,后续会跟进到最新版本。
PolarDB(pg_mode: polar)—— 阿里开源的共享存储架构 PG 内核,更新了小版本。
Citus(pg_mode: citus)—— 微软出品的分布式扩展,正式发布 14.0.0 版本,支持 PG 18。
Ferret / DocumentDB(pg_mode: mongo)—— MongoDB 协议兼容方案,让你用 MongoDB 驱动直连 PostgreSQL。
Supabase 自建模板也例行升级到了最新版本。
其他改进
除了内核,v4.2 还有一些值得注意的工程改进:
Redis 目录规范化:默认目录从 /data 调整为 /data/redis。存量配置如果还用 /data,需要先改过来再升级,部署阶段会阻止旧路径继续使用。
Configure 脚本优化:支持 -o 绝对路径输出并自动建目录;区域探测改为三态(境内/境外/离线回退),修复了 behind_gfw() 卡住的问题。
pgBackRest 初始化容错:stanza-create 增加重试(2 次、间隔 5 秒),缓解与 archive-push 的锁竞争。踩过这个坑的人知道它有多烦。
Supabase 应用栈升级:PostgREST 14.5、Vector 0.53.0,S3 访问密钥变量补齐。
Vibe 模板更新:内置 @anthropic-ai/claude-code、@openai/codex、happy-coder 等工具,AI 编码沙箱开箱即用。
基础设施例行升级:Grafana 12.4、Prometheus 3.10、VictoriaMetrics 1.136、etcd 3.6.8、Kafka 4.2 等。注意 Grafana 12.4 有 data link 合并行为变化,自定义面板需检查。
后续的工作重心会逐渐转向子项目:
Pig CLI 最近更新了很多强大功能 —— 把 PostgreSQL、Patroni、PgBouncer、pgBackRest 的管理全部封装成了命令行工具,方便 Claude Code 这样的 DBA Agent 调用。这种同时为人类 DBA 和 AI Agent 设计的命令行工具称之为 Agent-Native CLI。
DBA Agent 方面,最近写了一些 Claude Skills 和提示词模板,让 Pigsty 环境可以被 AI 工具感知。这样就可以把 Claude Code 放进 Pigsty 环境里,让它助你干活。
v4 也在安全方面做了大量工作,对照等保,SOC2 等合规标准,基本实现了所有能做的安全合规点。几个值得一提的改进:
随机默认强密码:经常有用户部署直接用默认密码,这次新增了 configure -g 选项,自动把所有默认密码替换成随机强密码。
ETCD 启用 RBAC:以前全局用证书认证,现在每个 PG 集群一个自己的 etcd 用户密码。管理节点可以管理所有集群,普通数据库节点仅能管理自身所在的集群,避免串台干扰。
SELinux 规则优化:以前默认关闭,现在 EL 系统中基本的安全上下文都已配置妥当,默认为 permissive 模式,可以直接按需 enforce。
防火墙默认支持:现在支持定义公网开放端口,内网网段。即使云服务器没有提供安全组,也可以自己用简单的方式将暴露面缩小到最小状态(默认开 ssh 22,http 80,https 443,按需 pgsql 5432)
项目主页:https://github.com/Vonng/pigsty