流处理开发框架-Apache StreamPark
 StreamX 是一个 Apache Flink 极速开发框架,其初衷是让 Flink 开发更简单。主要由Java、Scala开发并在Apache协议下授权使用。
StreamX 是一个 Apache Flink 极速开发框架,其初衷是让 Flink 开发更简单。主要由Java、Scala开发并在Apache协议下授权使用。StreamPark is a streaming application development framework. Aimed at ease building and managing streaming applications, StreamPark provides development framework for writing stream processing application with Apache Flink and Apache Spark, More other engines will be supported in the future. Also, StreamPark is a professional management platform for streaming application , including application development, debugging, interactive query, deployment, operation, maintenance, etc. It was initially known as StreamX and renamed to StreamPark in August 2022.
StreamX 定位是 Flink|Spark 开发脚手架 + 流批一体大数据平台,项目本身采用 java、scala 开发。前端使用 vuejs、antd design vue,使用 StreamX 开发,可以极大降低学习成本和开发门槛,让开发者只用关心最核心的业务。
StreamX 规范了项目的配置,鼓励函数式编程,定义了最佳的编程方式,提供了一系列开箱即用的 Connectors,标准化了配置、开发、测试、部署、监控、运维的整个过程,提供 scala 和 java 两套 api,其最终目的是打造一个一站式大数据平台,流批一体的解决方案。
特性
开发脚手架
多版本 Flink 支持 (1.11,x, 1.12.x, 1.13)
一系列开箱即用的 connectors
支持项目编译功能 (maven 编译)
在线参数配置
支持 Applicaion 模式, Yarn-Per-Job 模式启动
快捷的日常操作 (任务启动、停止、savepoint, 从 savepoint 恢复)
支持火焰图
支持 notebook(在线任务开发)
项目配置和依赖版本化管理
支持任务备份、回滚 (配置回滚)
在线管理依赖 (maven pom) 和自定义 jar
自定义 udf、连接器等支持
Flink SQL WebIDE
支持 catalog、hive
任务运行失败发送告警邮件
支持任务失败重启重试
从任务开发阶段到部署管理全链路支持
...
项目架构如下:
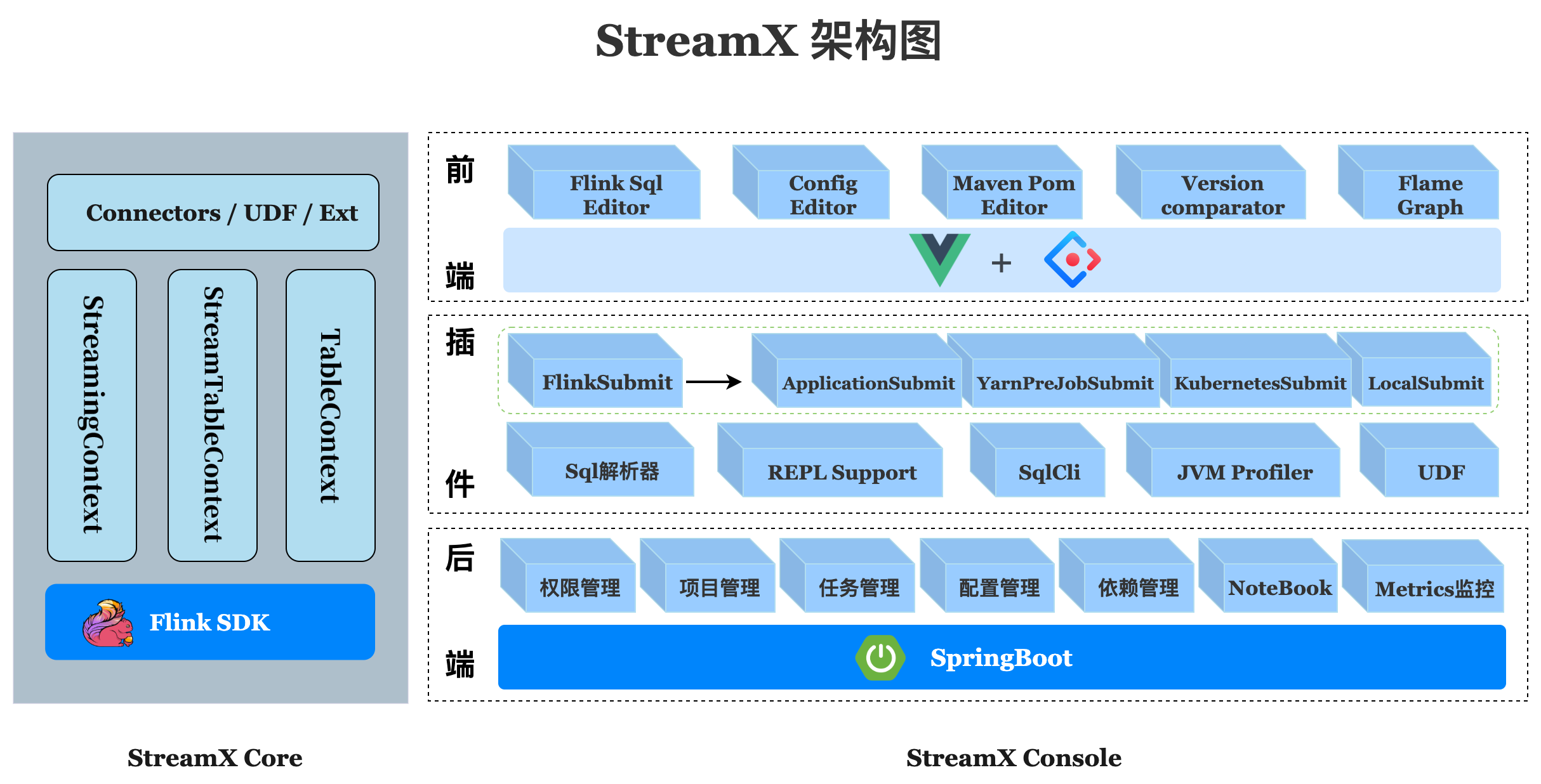
组成部分
Streamx 有三部分组成,分别是 streamx-core、streamx-pump 和 streamx-console。
streamx-core
streamx-core 定位是一个开发时框架,关注编码开发,规范了配置文件,按照约定优于配置的方式进行开发,提供了一个开发时 RunTime Content 和一系列开箱即用的 Connector, 扩展了 DataStream 相关的方法,融合了 DataStream 和 Flink sql api, 简化繁琐的操作,聚焦业务本身,提高开发效率和开发体验
streamx-pump
pump 是抽水机,水泵的意思,streamx-pump 的定位是一个数据抽取的组件,类似于 flinkx, 基于 streamx-core 中提供的各种 connector 开发,目的是打造一个方便快捷,开箱即用的大数据实时数据抽取和迁移组件,并且集成到 streamx-console 中,解决实时数据源获取问题,目前在规划中
streamx-console
streamx-console 是一个综合实时数据平台,低代码 (Low Code) 平台,可以较好的管理 Flink 任务,集成了项目编译、发布、参数配置、启动、savepoint, 火焰图 (flame graph),Flink SQL, 监控等诸多功能于一体,大大简化了 Flink 任务的日常操作和维护,融合了诸多最佳实践。旧时王谢堂前燕,飞入寻常百姓家,让大公司有能力研发使用的项目,现在人人可以使用,其最终目标是打造成一个实时数仓,流批一体的一站式大数据解决方案
最新版本 :2.0
这是 StreamPark 加入 Apache 孵化器以来发布的第一个版本,于2023年2月下旬发行,也是一个重大功能更新的版本,距离上次发版长达半年之久。在这半年的时间里,我们开发了很多非常实用的新功能,也经历了社区小伙伴的数次催更和发版的合规整改,终于和大家见面了,这是一个诚意满满的,值得期待的版本。有超过 100 位 Contributor 贡献了超过 700 个 Pull Request, 带来了诸多的新特性和改进修复 , 感谢每一位贡献者的努力。
在 2.0.0 版本中完成了 Apache 项目的合规要求。此次发版投票跨越 3 个月,经过社区和 AFS 孵化器导师们长达 7 轮的投票,每次投票被打回我们都认真整改,由衷感受到 ASF 对项目的严苛要求,对 License (是一种具有法律性质的合同或指导,目的在于规范受著作权保护的软件的使用或散布行为) 合规的高度重视,终于在第 7 轮投票中通过了本次发布。这意味着 2.0.0 版本 License 合规最大程度的得到保证,可以被更多企业更大范围的放心使用
本次重写了整个前端模块,更加专业和美观,构建和启动速度和历史版本比提升了 5~10 倍。对 Flink 做了更好的支持,支持最新的 Flink 1.16。部署 Flink 作业 on Kubernetes 到达生产可用级别,另外在实用性和易用性上做了大量改进,修复了诸多历史 Bug 和安全漏洞,建议所有人升级使用。
Apache StreamPark(Incubating) 提供了两个安装包, 在 scala 版本上有所不同, 如下:
apache-streampark_2.11-2.0.0-incubating-bin.tar.gz
apache-streampark_2.12-2.0.0-incubating-bin.tar.gz
2.11 和 2.12 即为 scala 的版本 , 这里 scala 版本与支持 Flink 的 scala 版本一致 , 如果 Flink 版本是 1.15 及以上,那么只能使用 scala 2.12 版本的 StreamPark, 因为 Flink 1.15+ 只支持 scala 2.12, 1.15 以下的版本则 scala 2.11 和 2.12 都支持 , 总之需要下载与目标 Flink 的 scala 版本对应的 StreamPark 安装包。
新特性解读
全新的前端
StreamPark 历史版本的前端模块是基于 Vue2 框架开发的 , 不少页面代码量过多 , 页面和组件复用率低 , 在可读性和维护性上都带来了不小的挑战 , 本次基于 Vue3 重写了整个前端部分 , 组件划分清晰 , 可复用性更高 , 很好的解决了以上问题。升级 Vue3 之后模块按需编译按需导入的,前端体积比之前更小 , 编译、启动和渲染等速度更快。
本次支持了 i18n, 支持中 / 英切换 , 此外反馈较多的关于异常信息的提示也做了改进: 之前作业失败等异常信息只记录到了后台日志 , 并未在前端显示给用户 , 这会给排查问题带来不便 , 本次改进了这部分 , 相关信息直观的呈现给用户 , 方便用户快速分析和定位问题。
在美观度上 , 进一步改进了暗黑模式 , 优化了非常多的细节,普遍反馈本次页面更加美观和专业。
K8S 能力更稳定
本次在部署 Flink on Kubernetes 上 , 修复了诸多历史 Bug, 支持了查看 Kubernetes 部署模式下的实时日志 , 重构了作业状态获取这部分的实现 , 在状态获取这部分引入了基于读取 historyserver 归档文件来获取作业状态的保底策略 , 需要特别指出的是 StreamPark 中关于 Flink on Kubernetes 的实现并非基于 Flink-kubernetes-operator。在作业部署提交、状态获取等各个方面都做了大量的测试 , 整体稳定性和可用性经过企业大量作业的验证 , 达到生产可用级别。
更好的 Flink 支持
在 StreamPark 2.0.0 版本中 , 支持了最新的 Flink 1.16, 到此 Flink 1.12.x 至 1.16 都已经做了完整的支持 , 并且本次对适配 Flink 做了改进 , 使得适配一个新版本的 Flink 更加简单。此外对 Flink 开发框架这部分也进行了改进 , 统一了 StreamPark 中的开发 Flink 作业的参数配置 , 重新规范了参数名 , 使 StreamPark 的 Flink 开发框架部分的参数与 Apache Flink 参数名保持一致,大大提升了用户配置 Flink 参数的易用性 , 从而减轻开发者的心智负担和使用学习成本。
易用性改进
历史版本中 StreamPark 平台部分的元信息存储强依赖 MySQL, 本次扩展支持了三种数据库供用户选择:分别是 H2, MySQL, PostgreSQL。默认使用 H2, 对于想要快速体验的用户来说 , 下载安装包 , 执行启动脚本启动服务即可 , 无需其他额外配置和操作就可以体验 StreamPark 了 , 进一步降低了用户的体验门槛和使用成本。
本次新增了变量管理功能 , 在没有变量之前在 StreamPark 里编写 Flink SQL 作业时会将连接器的相关信息 , 如: 数据库的连接字符串、用户名、 密码等明文的写在 SQL 中 , 不但容易出错 , 作业多了混乱不方便管理 , 而且还不安全。有了变量管理和填充功能之后:在创建作业时可以使用定义好的变量进行填充,同时可以方便查看某个组件被哪些作业使用 , 避免手动输入带来的错误。
除此之外 , 本次还优化了很多其他方面关于易用性上的细节,如: 提供了 Docker 方式一键部署启动 StreamPark, 支持了通过 copy 已有的作业来快速创建一个新的作业 , 等等,这些功能都不同程度的提升了 StreamPark 的易用性,给用户带来更好的使用体验。
企业级支持
本次新增了团队管理,在没有团队管理之前,所有的作业都展示在一个页面,非常不便于作业的分类和管理,同时作业的权限也得不到保证。新增团队管理后,不同的团队之间资源隔离,团队成员只能看到本团队的作业,这样作业的管理和权限问题都得到了解决。
为了更好的和企业现有账号体系打通,本次新增了 LDAP 登录功能,只需要在系统的配置中进行 LDAP 相关的配置,然后在登录时选择通过 LDAP 登录即可。这样就可以快捷的一键登录 StreamPark 平台。对于企业用户生产环境使用来讲,作业的稳定性至关重要,与之相关的预警机制是也是一个必须要考量的一个重要指标,本次告警通知方式新增支持了: 钉钉、企业微信、飞书、邮件 等方式。用户只需要配置一个告警组,在作业里指定告警组即可,做到了灵活配置和复用。
其他更新和改进
改进项目构建体验,记录上一次构建日志
支持了 Flink SQL 所有语法
开发框架部分支持 HOCON 配置文件
run-mode 支持 streaming 和 batch
修复 env.java.opts 参数不生效的 bug
修复支持 yarn 队列不生效的 bug
修复 on yarn 下 kerberos 认证相关的 bug
更多信息可参考发行说明。
项目主页: https://streampark.apache.org/