通用数据处理平台-Apache Flink
 Apache Flink 是高效和分布式的通用数据处理平台,数据流上的有状态计算。采用Java 和 Scala语言开发并在Apache License 2.0协议下授权。
Apache Flink 是高效和分布式的通用数据处理平台,数据流上的有状态计算。采用Java 和 Scala语言开发并在Apache License 2.0协议下授权。Apache Flink 声明式的数据分析开源系统,结合了分布式 MapReduce 类平台的高效,灵活的编程和扩展性,同时在并行数据库发现查询优化方案。
Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。世界各地有很多要求严苛的流处理应用都运行在 Flink 之上。
特点
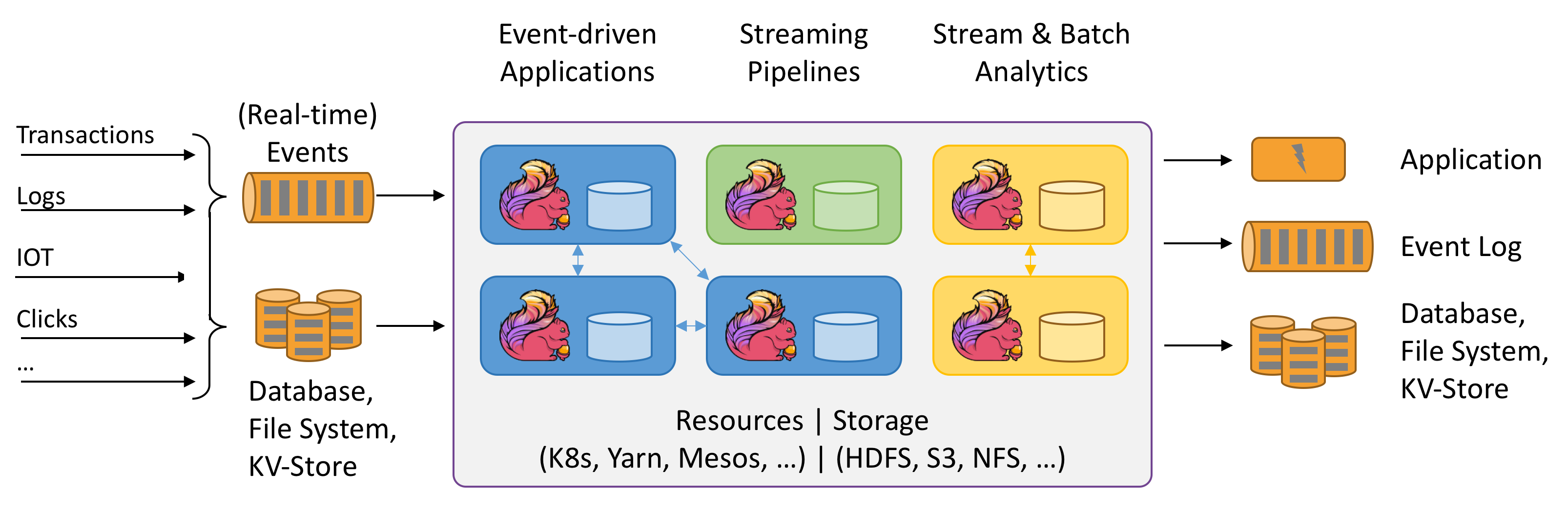
所有流式场景(事件驱动应用,流批分析,数据管道 & ETL)
正确性保证(Exactly-once 状态一致性,事件时间处理,成熟的迟到数据处理)
分层 API(SQL on Stream & Batch Data,DataStream API & DataSet API,ProcessFunction (Time & State))
聚焦运维(灵活部署,高可用,保存点)
大规模计算(水平扩展架构,支持超大状态,增量检查点机制)
性能卓越(低延迟,高吞吐,内存计算)
Flink 是一个非常通用的系统,它以数据流为核心,用于数据处理和数据驱动的应用程序。这些数据流可以是实时数据流或存储的历史数据流。例如,Flink 认为文件是存储的字节流,因此Flink同时支持实时数据处理和批处理应用程序。
流可以是无界的 (不会结束,源源不断地发生事件)或 有界的 (流有开始和结束)。例如,来自消息队列的 Twitter 信息流或事件流通常是无界的流,而来自文件的字节流是有界的流。
如果一切都是流,为什么 Flink 中同时有 DataStream 和 DataSet API?
处理有界流的数据通常比无界流更有效。在(近)实时要求的系统中,处理无限的事件流要求系统能够立即响应事件并产生中间结果(通常具有低延迟)。处理有界流通常不需要产生低延迟结果,因为无论如何数据都有点旧(相对而言)。这样 Flink 就能以更加简单有效的方式去处理数据。
DataStream API 基于一个支持低延迟和对事件和时间(包括事件时间)灵活反应的模型,用来连续处理无界流和有界流。
DataSet API 具有通常可加速有界数据流处理的技术。在未来,社区计划将这些优化与 DataStream API 中的技术相结合。
Flink 与 Hadoop 软件栈之间的关系
Flink 独立于Apache Hadoop,且能在没有任何 Hadoop 依赖的情况下运行。但 Flink 可以很好的集成很多 Hadoop 组件,例如 HDFS、YARN 或 HBase。当与这些组件一起运行时,Flink 可以从 HDFS 读取数据,或写入结果和检查点(checkpoint)/快照(snapshot)数据到 HDFS 。Flink 还可以通过 YARN 轻松部署,并与 YARN 和 HDFS Kerberos 安全模块集成。
使用Flink的先决条件是什么
你需要 Java 8 来运行 Flink 作业/应用程序。
Scala API(可选)依赖 Scala 2.11。
避免单点故障的高可用性配置需要有 Apache ZooKeeper。
对于可以从故障中恢复的高可用流处理配置,Flink 需要某种形式的分布式存储用于保存检查点(HDFS/S3/NFS/SAN/GFS/Kosmos/Ceph/ …)。
Flink支持多大的规模
用户可以同时在小集群(少于5个节点)和拥有 TB 级别状态的1000个节点上运行 Flink 任务。
Flink是否仅限于内存数据集
对于 DataStream API,Flink 通过配置 RocksDB 状态后端来支持大于内存的状态。对于 DataSet API,所有操作(除增量迭代外)都可以扩展到主内存之外。
更多的使用案例可参考官方的应用场景。
最新版本:1.8
Flink 1.8.0 已发布,该版本与之前的 1.x.y 版本 API 兼容。新特性和改进:
Schema Evolution Story 最终版、基于 TTL 持续清除旧状态
使用用户定义的函数和聚合进行 SQL 模式检测、符合 RFC 的 CSV 格式
新的 KafkaDeserializationSchema,可以直接访问 ConsumerRecord
FlinkKinesisConsumer 中的分片水印选项
DynamoDB Streams 的新用户捕获表更改
支持用于子任务协调的全局聚合
重要变化:
使用 Flink 捆绑 Hadoop 库的更改:不再发布包含 hadoop 的便捷二进制文件、FlinkKafkaConsumer 现在将根据主题规范过滤已恢复的分区
表 API 的 Maven 依赖更改:之前具有flink-table依赖关系的用户需要将依赖关系从flink-table-planner更新为正确的依赖关系 flink-table-api-*,具体取决于是使用 Java 还是 Scala:flink-table-api-java-bridge或者flink-table-api-scala-bridge
已知问题:丢弃的检查点可能导致任务失败,更多详情请查阅发行公告。
最新版本:1.12
Flink 1.12.2 已经于2021年3月发布,这是一个 bug 修复版本,包括 83 个修复和优化。部分更新内容:
记录 2.12.8 以后与 Scala 的二进制兼容情况
修复用户代码 CheckpointExceptions 的错误修正
修复在 JDBC 连接器中从 postgres 访问 null 数组时出现 NullPointerException 的问题
修复 EXPLAIN 语句文档中的拼写错误
SerializedValue 的 getByteArray() 缺少空值处理
修复不对齐的检查点恢复可能会导致数据流损坏的问题
修复当操作人员频繁使用托管内存时,托管内存可能无法及时释放的问题
异步检查点失败将不会再使工作失败
修复调用无参数的 var-arg 函数失败的问题
为网站和文档提供引导资源
更多详细内容请查看更新公告。
最新版本:1.18
Flink PMC 已正式于2023年10月下旬发布 Apache Flink 1.18.0 版本。这是一个充实的版本,包含了广泛的改进和新功能。总共有 174 人为此版本做出了贡献,完成了 18 个 FLIPs 和 700 多个问题。迈向 Streaming Lakehouse、Flink SQL 提升、Flink SQL Gateway 的 JDBC Driver。1.18 版本提供了 Flink SQL Gateway 的 JDBC Driver。因此现在可以使用支持 JDBC 的任何 SQL 客户端通过 Flink SQL 与您的表进行交互。
Flink 连接器的存储过程(Stored Procedure)支持
存储过程(Stored Procedure)在传统数据库中一直是不可或缺的工具,它提供了一种方便的方式来封装用于数据操作和任务管理的复杂逻辑。存储过程还提供了增强性能的潜力,因为它们可以直接在外部数据库中触发数据操作的处理。其他流行的数据系统如 Trino 和 Iceberg 将常见的维护任务自动化并简化为一小组存储过程,从而大大减轻了用户的管理负担。
本次更新主要针对 Flink 连接器的开发人员,他们现在可以通过 Catalog 接口预定义自定义存储过程到连接器中。对用户的主要好处是,以前需要编写自定义 Flink 代码来实现的连接器特定任务现在可以用封装化、标准化和潜在优化底层操作的简单调用来替代。用户可以使用熟悉的 CALL 语法执行存储过程,并使用 SHOW PROCEDURES 查看连接器的可用存储过程。连接器内的存储过程提高了 Flink 的 SQL 和 Table API 的可扩展性,为用户提供更顺畅的数据访问和管理能力。用户可以使用 Call 语句来直接调用 catalog 内置的存储过程(注:catalog 内置的存储过程请参考对应 catalog 的文档)。
DDL 支持扩展
从 1.18 版本开始,Flink 支持以下功能:
REPLACE TABLE AS SELECT
CREATE OR REPLACE TABLE AS SELECT
这两个命令以及之前支持的 CREATE TABLE AS 现在都支持原子性,前提是底层连接器也支持。此外 Apache Flink 现在支持在批处理模式下执行 TRUNCATE TABLE。与以前一样,底层连接器需要实现并提供此功能。最后还实现了通过以下方式支持添加、删除和列出分区:
ALTER TABLE ADD PARTITION
ALTER TABLE DROP PARTITION
SHOW PARTITIONS
时间旅行(Time Traveling)
Flink 支持时间旅行(time travel) SQL 语法,用于查询历史版本的数据。用户可以指定一个时间点,来检索表在该时间点的数据和架构。借助时间旅行功能,用户可以轻松分析和比较数据的历史版本。
流处理提升
Table API & SQL 支持算子级别状态保留时间(TTL)
从 Flink 1.18 版本开始,Table API 和 SQL 用户可以为有状态的算子单独设置状态保留时间 (TTL)。在像流 regular join 这样的场景中,用户现在可以为左侧和右侧流设置不同的 TTL。在以前的版本中,状态保留时间只能在 pipeline 级别使用配置项 table.exec.state.ttl 进行控制。引入算子级别的状态保留后,用户现在可以根据其具体需求优化资源使用。
SQL 的水印对齐(Watermark Alignment)和空闲检测(Idleness Detection)
现在可以使用 SQL Hint 配置水印对齐和数据源空闲超时。之前这些功能仅在 DataStream API 中可用。
批处理提升
Hybrid Shuffle 支持远程存储
Hybrid Shuffle 支持将 Shuffle 数据存储在远程存储中。可以使用配置项 taskmanager.network.hybrid-shuffle.remote.path 配置远程存储路径。Hybrid Shuffle 通过将内存用量与并行度解耦,减少了网络内存的使用,提高了稳定性和易用性。
性能提升与 TPC-DS 基准测试
在之前的版本中,社区投入了大量精力来改进 Flink 的批处理性能,产生了显著的改进。在这个发布周期中,社区的贡献者继续付出了重大努力,进一步改进了 Flink 的批处理性能。
Flink SQL 的运行时过滤(Runtime Filter)
运行时过滤(Runtime Filter)是用于优化 join 性能的常见方法。它旨在动态生成某些 join 查询的运行时过滤条件,以减少扫描或 Shuffle 的数据量,避免不必要的 I/O 和网络传输,从而加速查询。我们在 Flink 1.18 版本引入了运行时过滤,并通过 TPC-DS 基准测试验证了其有效性,观察到启用此功能后,某些查询的速度提高了 3 倍。
Flink SQL 算子的融合代码生成(Operator Fusion Codegen)
算子融合代码生成(Operator Fusion Codegen)通过将算子 DAG 融合成一个经过优化的单算子,消除了虚函数调用,利用 CPU 寄存器进行中间数据操作,并减少指令缓存不命中的情况,从而提高了查询的执行性能。作为一项技术优化,我们通过 TPC-DS 验证了其有效性,部分批处理算子(Calc、HashAgg 和 HashJoin)在 1.18 版本中完成了融合代码生成支持,很多查询性能显著提高。
请注意,上述两个功能默认情况下处于关闭状态。可以通过使用 table.optimizer.runtime-filter.enabled 和 table.exec.operator-fusion-codegen.enabled 两个配置项来启用它们。
自 Flink 1.16 以来,Apache Flink 社区一直在通过 TPC-DS 基准测试框架持续跟踪其批处理引擎的性能。在 Flink 1.17 版本中经过重大改进(动态 join 重排序、动态 local aggregation)后,前面描述的两项改进(算子融合、运行时过滤)在分区表 10T 数据集上,与 Flink 1.17 相比性能提高了 14%,与 Flink 1.16 相比性能提高了 54%。
项目主页:https://flink.apache.org/