分布式搜索平台-Elastic
 Elastic believes getting immediate, actionable insight from data matters. As the company behind the open source projects — Elasticsearch, Logstash, Kibana, and Beats — designed to take data from any source and search, analyze, and visualize it in real time, Elastic is helping people make sense of data. From stock quotes to Twitter streams, Apache logs to WordPress blogs, our products are extending what's possible with data, delivering on the promise that good things come from connecting the dots.
Elastic believes getting immediate, actionable insight from data matters. As the company behind the open source projects — Elasticsearch, Logstash, Kibana, and Beats — designed to take data from any source and search, analyze, and visualize it in real time, Elastic is helping people make sense of data. From stock quotes to Twitter streams, Apache logs to WordPress blogs, our products are extending what's possible with data, delivering on the promise that good things come from connecting the dots. Elastic Search 是一个基于Lucene构建的开放源代码、分布式、RESTful搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。支持通过HTTP使用JSON进行数据索引,采用Java开发并在Apache协议授权。提供多种主流语言的客户端 API:Java、.NET、Perl、PHP、Python、Ruby等。提供 Marvel 可视化监控台,包含了一系列的应用组件集合。
查询构建器-ElasticQuery
ElasticQuery 是用于 ElasticSearch 的简单查询构建器。可使用 metod 方法调用和相应的参数来生成查询、过滤和聚合对象。输出的 dict/json 可直接传递给 ES。ElasticQueryV3 改进内容包括:
完全支持 ES 2 DSL
移除对 Filter & ES 1 的支持
尽可能使用 ValueError 替代 Exceptions
100% 测试覆盖率
集群架构
1. 集群节点
一个ES集群可以有多个节点构成,一个节点就是一个ES服务实例,通过配置集群名称cluster.name加入集群。那么节点是如何通过配置相同的集群名称加入集群的呢?必须先搞清楚ES集群中节点的角色。
ES中节点有角色的区分的,通过配置文件conf/elasticsearch.yml中配置以下配置进行角色的设定。
node.master: true/false
node.data: true/false
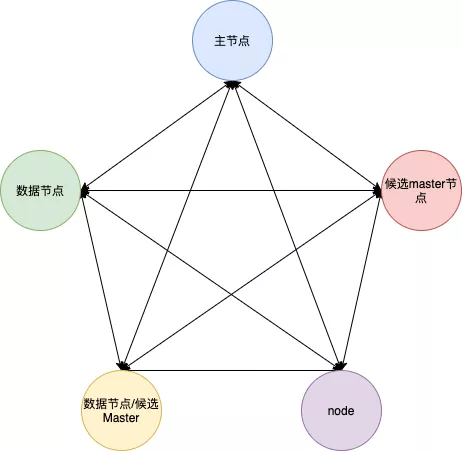
集群中单个节点既可以是候选主节点也可以是数据节点,通过上面的配置可以进行两两组合形成四大分类:
(1)仅为候选主节点
(2)既是候选主节点也是数据节点
(3)仅为数据节点
(4)既不是候选主节点也不是数据节点
候选主节点:只有是候选主节点才可以参与选举投票,也只有候选主节点可以被选举为主节点。
主节点:负责索引的添加、删除,跟踪哪些节点是群集的一部分,对分片进行分配、收集集群中各节点的状态等,稳定的主节点对集群的健康是非常重要。
数据节点:负责对数据的增、删、改、查、聚合等操作,数据的查询和存储都是由数据节点负责,对机器的CPU,IO以及内存的要求比较高,一般选择高配置的机器作为数据节点。
此外还有一种节点角色叫做协调节点,其本身不是通过设置来分配的,用户的请求可以随机发往任何一个节点,并由该节点负责分发请求、收集结果等操作,而不需要主节点转发。这种节点可称之为协调节点,集群中的任何节点都可以充当协调节点的角色。每个节点之间都会保持联系。
2. 发现机制
上面说到通过设置一个集群名称,节点就可以加入集群,那么ES是如何做到这一点的呢?
这里就要讲一讲ES特殊的发现机制ZenDiscovery。
ZenDiscovery是ES的内置发现机制,提供单播和多播两种发现方式,主要职责是集群中节点的发现以及选举Master节点。
多播也叫组播,指一个节点可以向多台机器发送请求。生产环境中ES不建议使用这种方式,对于一个大规模的集群,组播会产生大量不必要的通信。
单播,当一个节点加入一个现有集群,或者组建一个新的集群时,请求发送到一台机器。当一个节点联系到单播列表中的成员时,它就会得到整个集群所有节点的状态,然后它会联系Master节点,并加入集群。
只有在同一台机器上运行的节点才会自动组成集群。ES 默认被配置为使用单播发现,单播列表不需要包含集群中的所有节点,它只是需要足够的节点,当一个新节点联系上其中一个并且通信就可以了。如果你使用 Master 候选节点作为单播列表,你只要列出三个就可以了。
这个配置在 elasticsearch.yml 文件中:
discovery.zen.ping.unicast.hosts: ["host1", "host2:port"]
集群信息收集阶段采用了 Gossip 协议,上面配置的就相当于一个seed nodes,Gossip协议这里就不多做赘述了。
ES官方建议unicast.hosts配置为所有的候选主节点,ZenDiscovery 会每隔ping_interval(配置项)ping一次,每次超时时间是discovery.zen.ping_timeout(配置项),3次(ping_retries配置项)ping失败则认为节点宕机,宕机的情况下会触发failover,会进行分片重分配、复制等操作。
如果宕机的节点不是Master,则Master会更新集群的元信息,Master节点将最新的集群元信息发布出去,给其他节点,其他节点回复Ack,Master节点收到discovery.zen.minimum_master_nodes的值-1个 候选主节点的回复,则发送Apply消息给其他节点,集群状态更新完毕。如果宕机的节点是Master,则其他的候选主节点开始Master节点的选举流程。
2.1 选主
Master的选主过程中要确保只有一个,ES通过一个参数quorum的代表多数派阈值,保证选举出的master被至少quorum个的候选主节点认可,以此来保证只有一个master。选主的发起由候选主节点发起,当前候选主节点发现自己不是master节点,并且通过ping其他节点发现无法联系到主节点,并且包括自己在内已经有超过minimum_master_nodes个节点无法联系到主节点,那么这个时候则发起选主。
选主流程图
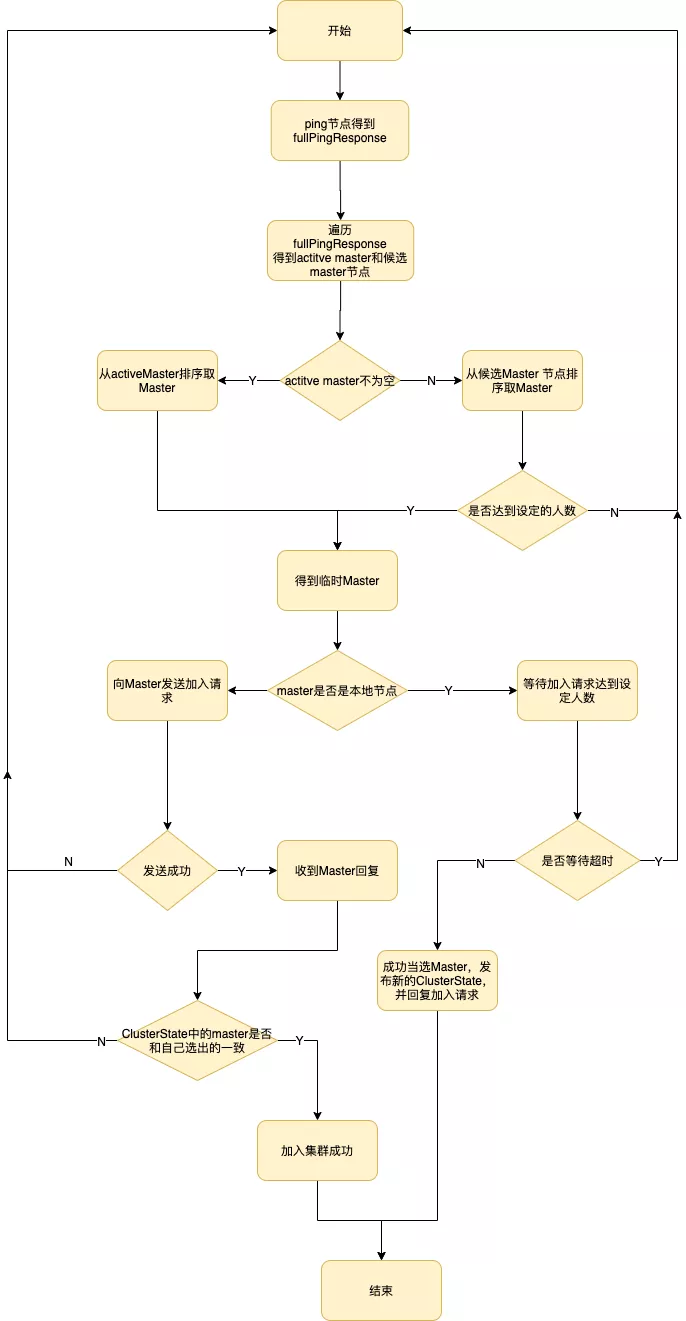
选主的时候按照集群节点的参数<stateVersion, id> 排序。stateVersion从大到小排序,以便选出集群元信息较新的节点作为Master,id从小到大排序,避免在stateVersion相同时发生分票无法选出 Master。排序后第一个节点即为Master节点。当一个候选主节点发起一次选举时,它会按照上述排序策略选出一个它认为的Master。
2.2 脑裂
提到分布式系统选主,不可避免的会提到脑裂这样一个现象,什么是脑裂呢?如果集群中选举出多个Master节点,使得数据更新时出现不一致,这种现象称之为脑裂。简而言之集群中不同的节点对于 Master的选择出现了分歧,出现了多个Master竞争。一般而言脑裂问题可能有以下几个原因造成:
网络问题:集群间的网络延迟导致一些节点访问不到Master,认为Master 挂掉了,而master其实并没有宕机,而选举出了新的Master,并对Master上的分片和副本标红,分配新的主分片。
节点负载:主节点的角色既为Master又为Data,访问量较大时可能会导致 ES 停止响应(假死状态)造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。
内存回收:主节点的角色既为Master又为Data,当Data节点上的ES进程占用的内存较大,引发JVM的大规模内存回收,造成ES进程失去响应。
如何避免脑裂:我们可以基于上述原因,做出优化措施:
适当调大响应超时时间,减少误判。通过参数 discovery.zen.ping_timeout 设置节点ping超时时间,默认为 3s,可以适当调大。
选举触发,我们需要在候选节点的配置文件中设置参数 discovery.zen.munimum_master_nodes 的值。这个参数表示在选举主节点时需要参与选举的候选主节点的节点数,默认值是 1,官方建议取值(master_eligibel_nodes/2)+1,其中 master_eligibel_nodes 为候选主节点的个数。这样做既能防止脑裂现象的发生,也能最大限度地提升集群的高可用性,因为只要不少于 discovery.zen.munimum_master_nodes 个候选节点存活,选举工作就能正常进行。当小于这个值的时候,无法触发选举行为,集群无法使用,不会造成分片混乱的情况。
角色分离,即是上面我们提到的候选主节点和数据节点进行角色分离,这样可以减轻主节点的负担,防止主节点的假死状态发生,减少对主节点宕机的误判。
3.索引如何写入的
3.1. 写索引原理
3.1.1 分片
ES支持PB级全文搜索,通常我们数据量很大的时候,查询性能都会越来越慢,我们能想到的一个方式的将数据分散到不同的地方存储,ES也是如此,它通过水平拆分的方式将一个索引上的数据拆分出来分配到不同的数据块上,拆分出来的数据库块称之为一个分片Shard,很像MySQL的分库分表。不同的主分片分布在不同的节点上,那么在多分片的索引中数据应该被写入哪里?肯定不能随机写,否则查询的时候就无法快速检索到对应的数据了,这需要有一个路由策略来确定具体写入哪一个分片中,怎么路由我们下文会介绍。在创建索引的时候需要指定分片的数量,并且分片的数量一旦确定就不能修改。
3.1.2 副本
副本就是对分片的复制,每个主分片都有一个或多个副本分片,当主分片异常时,副本可以提供数据的查询等操作。主分片和对应的副本分片是不会在同一个节点上的,避免数据的丢失,当一个节点宕机的时候,还可以通过副本查询到数据,副本分片数的最大值是 N-1(其中 N 为节点数)。
对doc的新建、索引和删除请求都是写操作,这些写操作是必须在主分片上完成,然后才能被复制到对应的副本上。ES为了提高写入的能力这个过程是并发写的,同时为了解决并发写的过程中数据冲突的问题,ES通过乐观锁的方式控制,每个文档都有一个 _version号,当文档被修改时版本号递增。一旦所有的副本分片都报告写成功才会向协调节点报告成功,协调节点向客户端报告成功。
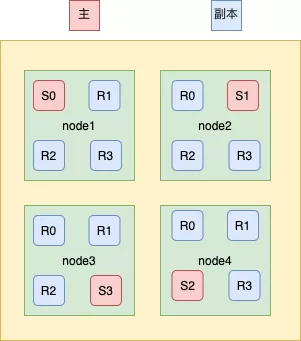
3.1.3 Elasticsearch 的写索引流程
上面提到了写索引是只能写在主分片上,然后同步到副本分片,那么如图4所示,这里有四个主分片分别是S0、S1、S2、S3,一条数据是根据什么策略写到指定的分片上呢?这条索引数据为什么被写到S0上而不写到 S1 或 S2 上?这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
以上公式的值是在0到number_of_primary_shards-1之间的余数,也就是数据档所在分片的位置。routing通过Hash函数生成一个数字,然后这个数字再除以number_of_primary_shards(主分片的数量)后得到余数。routing是一个可变值,默认是文档的_id,也可以设置成一个自定义的值。在一个写请求被发送到某个节点后,该节点按照前文所述,会充当协调节点,会根据路由公式计算出写哪个分片,当前节点有所有其他节点的分片信息,如果发现对应的分片是在其他节点上,再将请求转发到该分片的主分片节点上。
在ES集群中每个节点都通过上面的公式知道数据的在集群中的存放位置,所以每个节点都有接收读写请求的能力。那么为什么在创建索引的时候就确定好主分片的数量,并且不可修改?因为如果数量变化了,那么所有之前路由计算的值都会无效,数据也就再也找不到了。
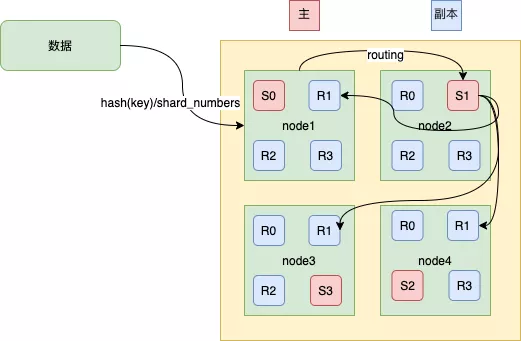
如上图所示,当前一个数据通过路由计算公式得到的值是 shard=hash(routing)%4=0,则具体流程如下:
(1)数据写请求发送到 node1 节点,通过路由计算得到值为1,那么对应的数据会应该在主分片S1上。
(2)node1节点将请求转发到 S1 主分片所在的节点node2,node2 接受请求并写入到磁盘。
(3)并发将数据复制到三个副本分片R1上,其中通过乐观并发控制数据的冲突。一旦所有的副本分片都报告成功,则节点 node2将向node1节点报告成功,然后node1节点向客户端报告成功。
这种模式下,只要有副本在,写入延时最小也是两次单分片的写入耗时总和,效率会较低,但是这样的好处也很明显,避免写入后单个机器硬件故障导致数据丢失,在数据完整性和性能方面,一般都是优先选择数据,除非一些允许丢数据的特殊场景。在ES里为了减少磁盘IO保证读写性能,一般是每隔一段时间(比如30分钟)才会把数据写入磁盘持久化,对于写入内存,但还未flush到磁盘的数据,如果发生机器宕机或者掉电,那么内存中的数据也会丢失,这时候如何保证?对于这种问题,ES借鉴数据库中的处理方式,增加CommitLog模块,在ES中叫transLog,在Lucene的设计参考文档中可以看到。
4.监控指标
Elasticsearch以结构化JSON文档的形式呈现数据,并通过RESTful API提供全文搜索。其服务是具有弹性的,因为它易于水平扩展--只需添加更多节点即可分配负载。现在有很多企业动用它来动态存储,搜索和分析大量数据。在监视其全局运行指标以及节点级系统指标时,可以结合具体的使用场景挑选出最重要的指标。
4.1.工作方式
在探讨性能指标之前,先来看看Elasticsearch的工作方式,集群由一个或多个节点组成,如下:
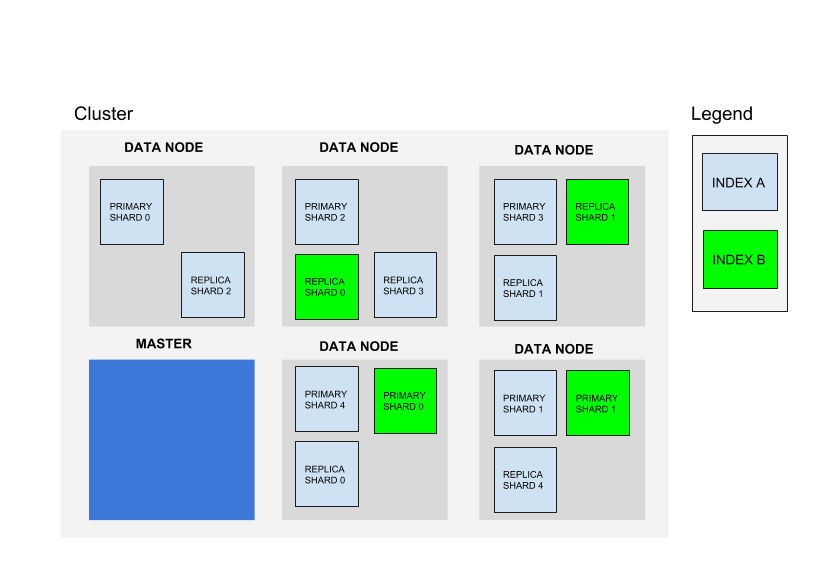
每个节点都是单个Elasticsearch实例,其elasticsearch.yml配置文件制定它属于哪个集群(cluster.name)以及它是哪种类型的节点。配置文件中设置的任何属性(包括集群名称)也可以通过命令行参数指定。上图中的集群由一个专用主节点和五个数据节点组成。
Elasticsearch中最常见的三种类型的节点是:
符合条件的主节点:默认情况下,每个节点均可作为主节点。每个集群都会自动从所有主节点中选择一个主节点。如果当前主节点发生故障(例如停电,硬件故障或者内存不足),会从符合条件的节点中选出一个主节点。主节点负责协调集群任务,例如跨节点分发分片,创建以及删除索引。符合条件的主节点也可以充当数据节点。不过在较大的集群中,通常启动不存储任何数据的专用主节点(配置文件中设置node.data为false),来提高可靠性。在高使用率的环境中,将主节点和数据节点分开有助于确保总是有足够的资源分配给只有主节点可以处理的任务。
数据节点:默认情况下,每个节点都是以分片形式存储数据的数据节点,这些节点执行索引,搜索以及聚合数据相关的操作。在较大的集群中,可通过在配置文件中设置node.master: false来创建专用数据节点,来确保这些节点有足够的资源来处理与数据相关的请求,而无需处理集群相关管理任务的额外工作量。
客户节点:如果将node.master和node.data设置为false,那么该节点会成为一个客户节点,用作一个负载均衡器,以帮助路有索引和搜索请求。客户端节点可以承担一部分的搜索工作量,以便让数据节点和主节点可以专注于核心任务。根据使用情况,客户节点可能不是必须的,因为数据节点能够自行处理请求路由。但是,如果搜索|索引的工作负载足够大,可以利用客户节点来帮助路有请求。
4.2.数据的存储
在Elasticsearch中,相关数据通常存储在同一个索引中,可以将其视为配置逻辑包装的等价物。每个索引都包含一组JSON格式的相关文档。Elasticsearch的全文索引使用的是Lucence的倒排索引。为文档创建索引时,Elasticsearch会自动为每个字段创建倒排索引;倒排索引将字段映射到包含这些字段的文档。索引存储在在主分片(一个或多个)和副本分片(零个或多个)中,每个分片都是一个Lucence的完整实例,可以当成一个迷你搜索引擎。
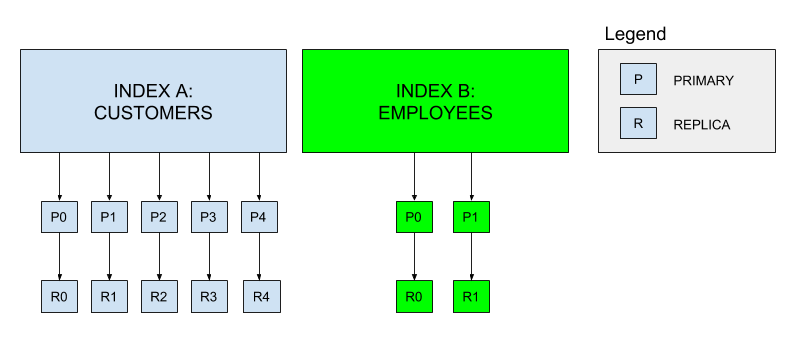
当创建索引时,可以制定主分片的数量以及每个主分片的副本数量。默认值为每个索引五个主分片,每个主分片一个副本。在索引被创建后,主分片的数量无法更改,因此在选择数量时要谨慎,否则后面可能需要重新建立索引。副本的数量可以在后面根据需求更新。为了防止数据丢失,主节点确保每个副本分片不会和主分片分配到同个节点上。
4.3.关键指标
Elasticsearch提供了大量指标,可以帮助用户检测出故障迹象,并在遇到诸如不可靠节点,内存不足和GC时间过长等问题时采取措施。一些需要监控的关键指标是:
搜索和索引的性能
内存和垃圾回收
主机和网络
集群健康度和节点可用性
资源饱和和错误
上面列出的指标都可以通过Elasticsearch的API以及像Elastic的Marvel这样的工具收集到。
4.4.搜索性能指标
搜索请求和索引请求是Elasticsearch中的两个主要请求类型。在某种程度上,这些请求和传统数据库系统中的读取和写入请求很类似。Elasticsearch提供了与搜索过程的两个主要阶段(查询和提取)相对应的指标。一次搜索请求从开始到结束的路径如下
客户端向节点2发送请求
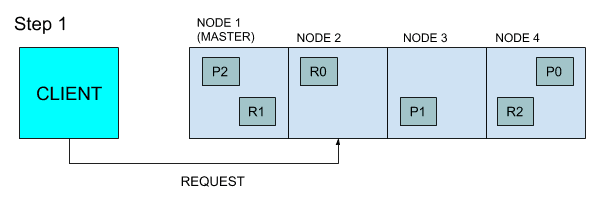
节点2(协调节点)将查询发送到索引中每个分片的副本(主副本或分片副本)
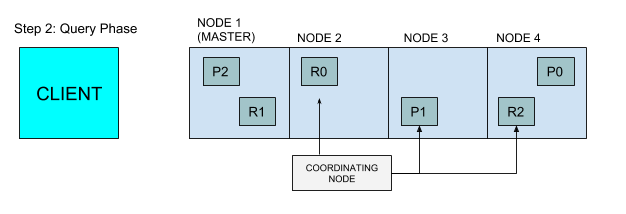
每个分片在本地执行查询并将结果传给节点2。节点2将这些结果排序并编译为全局优先级队列。
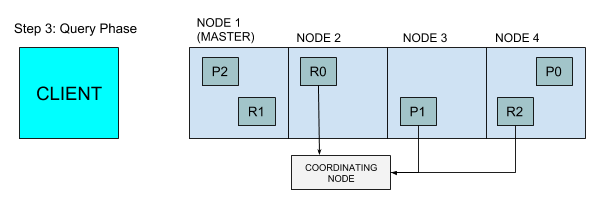
节点2找出需要提取的文档,并向相关分片发出多个GET请求
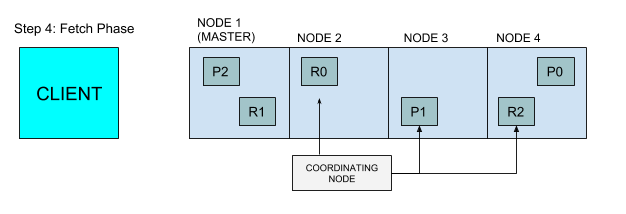
每个分片加载文档,并返回给节点2
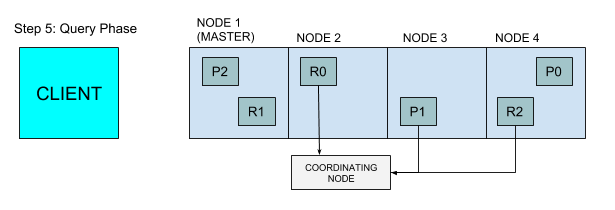
节点2将结果返回给客户端
当Elasticsearch主要用于搜索时,有必要监控查询延迟并在超过阙值时采取措施。监控有关查询和提取的相关指标非常重要,这些指标可以帮助确定在一段时间内的搜索性能。比如可以跟踪查询请求中的峰值和长期的的增长趋势,以准备优化配置来获得更好的性能和可靠性。
| 指标描述 | 指标名 | 指标类型 |
|---|---|---|
| query总数 | indices.search.query_total | 吞吐量 |
| query总耗时 | indices.search.query_time_in_millis | 性能 |
| 当前在处理的query数量 | indices.search.query_current | 吞吐量 |
| fetch总数 | indices.search.fetch_total | 吞吐量 |
| fetch总耗时 | indices.search.fetch_time_in_millis | 性能 |
| 当前在处理的fetch数量 | indices.search_fetch_current | 吞吐量 |
重点指标
Query 负载:监控当前正在进行的query数量可以大致了解集群在任何特定时刻处理的请求数量。可以考虑在出现异常尖峰和骤降时发出警告。
Query延迟:尽管Elastisearch没有明确提供这个指标,但是可以用现有指标来推算这个值,算法是定期用查询总数除以总耗时。
Fetch延迟:搜索的第二阶段(fetch阶段)通常比query阶段耗时要少。如果这个值持续增加,可能意味着磁盘速度慢,或者请求的结果数量过多。
4.5.索引性能指标
索引请求类似于传统数据库系统中的写请求。如果Elasticsearch集群主要用于索引,那么对索引性能的监控是非常有必要的。在讨论监控指标前,我们先看看Elasticsearch处理索引的方式。当在索引中添加新信息或者删除现有信息时,索引中的每个分片都会通过两个步骤更新:refresh和flush。
refresh
新加入到索引的文档不能立即用于搜索,这些文档会先被写入内存缓冲区,等待下一次索引刷新,默认情况下每秒刷新一次。refresh先从之前内存缓冲区中创建新的内存段,让这些内容能够被搜索到,然后清空缓存区,过程如下
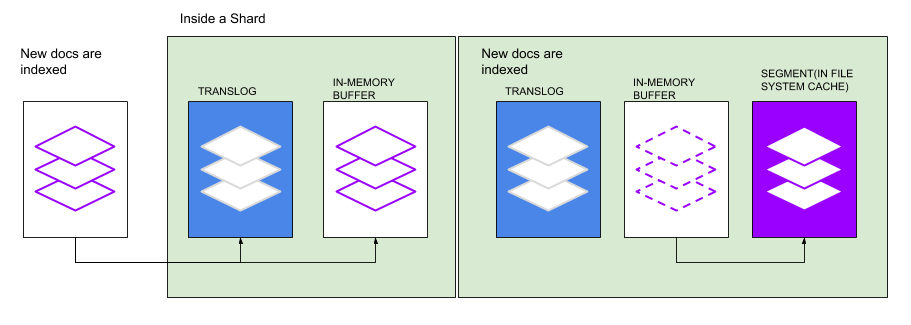
段
索引的分片由多个段组成。这个Lucene的核心数据结构,一个段实际上索引的变更集。每个段使用文件,内存和CPU,为了有效利用这些资源,这些段在每次刷新时创建,随后合并。段是微型的倒排索引,可以将词映射到包含这些词的文档。每次搜索索引时,依次搜索主分片或者副本分片,在分片中搜索每个分段。段是不可变的,所以更新文档会:
在refresh过程中将信息写入新段
将旧信息标记为删除
当过期段与另一个段合并时,最终会删除旧信息。
flush
在将新索引文档添加到内存缓冲区的同时,这些内容也会添加到分片的translog,translog用于持久记录操作的日志。每隔30分钟,或者当translog大小到达最大时(默认是512MB),会触发一次flush操作。在flush期间,内存缓冲区的任何文档都会刷新(存储在新段中),所有内存中的段都会提交到磁盘,同时translog被清空。
translog有助于防止节点故障时丢失数据。可以用translog帮助恢复可能在刷新之间丢失的操作。日志每5秒提交到磁盘;或在索引,删除,更新或批量请求成功后,日志提交到磁盘。流程如下
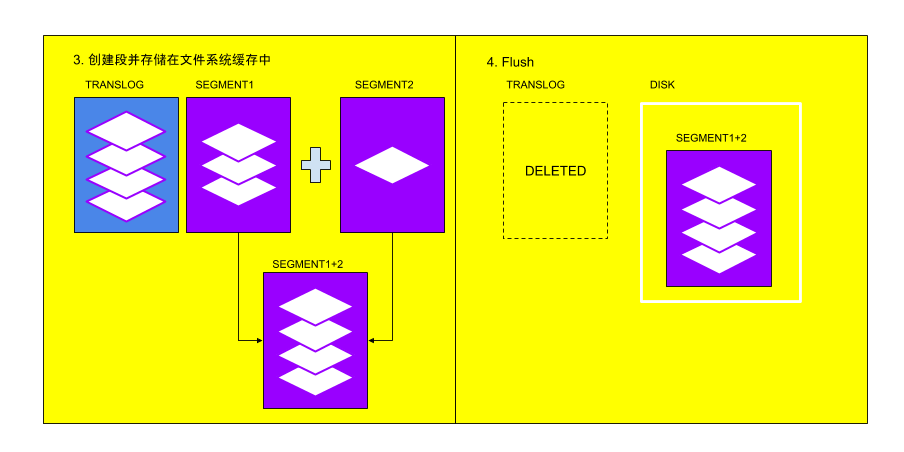
Elasticsearch提供了很多有关索引的指标
| 指标描述 | 指标名 | 指标类型 |
|---|---|---|
| 索引的文档总数 | indices.indexing.index_total | 吞吐量 |
| 索引文档总耗时 | indices.indexing.index_time_in_millis | 性能 |
| 当前索引的文档数 | indices.indexing.index_current | 吞吐量 |
| 索引refresh总数 | indices.refresh.total | 吞吐量 |
| refresh总耗时 | indices.refresh.total_time_in_millis | 吞吐量 |
| 索引flush到磁盘总数 | indices.flush.total | 吞吐量 |
| flush总耗时 | indices.flush.total_time_in_millis | 吞吐量 |
重点指标
索引延迟:Elasticsearch并不直接提供这个指标,不过可以根据index_total和index_time_in_millis算出来。如果注延迟增加,可能是因为一次索引的太多文档(Elastisearch建议批量索引大小为5MB-15MB)。如果计划索引大量文档,并且不需要新的信息可立即用于搜索,可以通过降低刷新频率来优化索引性能而不是搜索性能,直到完成索引。
Flush延迟:由于数据在成功完成刷新之前不会持久保存到磁盘,因此跟踪刷新延迟并在性能开始下潜时采取措施会很有用。如果看到此指标稳步增加,则可能表示磁盘速度较慢;此问题可能会升级并最终阻止向索引添加新文档。在这种情况下,可以尝试降低index.translog.flush_threshold_size,此设置确定在触发刷新之前translog大小可以达到的大小。如果Elasticsearch写比较重,可以考虑使用iostat关注磁盘I/O。
4.6.内存和垃圾回收
内存是需要监控的关键指标之一。Elasticsearch和Lucene以两种方式利用节点上的所有可用内存:JVM堆和文件系统缓存。Elasticsearch在Java虚拟机(JVM)中运行,这意味着JVM垃圾收集的持续时间和频率也是需要监控起来的。
JVM堆
使用Elasticsearch需要设置适当的JVM堆大小。一般来说,Elasticsearch的经验法则是将不到50%的可用RAM分配给JVM堆,永远不会高于32GB。分配给Elasticsearch的堆内存越小,Lucene可用的内存就越多,而Lucene很大程度上依赖于文件系统缓存来快速响应请求;但是也不能设置的太小,因为可能会遇到内存不足,或者因为频繁GC导致吞吐量降低。这篇博客有详细描述。
Elasticsearch默认设置JVM堆大小为1G,在大多数场景下这个都太小,可以所需要的堆大小导出为环境变量,然后重新启动Elasticsearch。
export ES_HEAP_SIZE=10g
垃圾回收
Elasticsearch依赖于垃圾收集(GC)进程来释放堆内存。需要留意GC的频率和持续时间。将堆设置得太大会导致垃圾收集时间过长;这些过度暂停是危险的,会导致集群中其他节点认为该节点失去响应。
| 指标描述 | 指标名 | 指标类型 |
|---|---|---|
| 年轻代垃圾回收总数 | jvm.gc.collectors.young.collection_count | |
| 年轻代垃圾回收耗时 | jvm.gc.collectors.young.collection_time_in_millis | |
| 年老代垃圾回收总数 | jvm.gc.collectors.old.collection_count | |
| 年老代垃圾回收耗时 | jvm.gc.collectors.old.collection_time_in_millis | |
| 当前JVM堆占比 | jvm.mem.heap_used_percent | |
| 已提交的JVM堆量 | jvm.mem.heap_committed_in_bytes |
重点指标
在使用的JVM堆:Elasticsearch设置为在JVM堆使用率达到75%时启动垃圾回收。监视哪些节点表现出高堆使用率并设置警报以查明是否有任何节点始终使用超过85%的堆内存可能很有用:这表明垃圾收集的速度跟不上垃圾创建的速度。要解决这个问题,可以增加堆大小,或者通过添加更多节点来扩展群集。
已使用的堆和已提交的堆:使用的堆内存量通常采用锯齿模式,当垃圾堆积时会上升,当收集垃圾时会下降。已使用堆和已提交堆比例增加时,意味着垃圾收集的速率跟不上对象创建的速度,这可能导致垃圾收集时间变慢,并最终导致OutOfMemoryErrors。
GC持续时间和频率:回收年轻代和年老代垃圾回收都会经历“世界停止”阶段,因为JVM停止执行程序来进行回收。在这段时间内,节点无法完成任何任务。主节点会每隔30秒检查其他节点状体啊,如何任何节点的垃圾回收时间超过30秒,主节点将认为这个节点已经挂掉。
内存使用率:如上所述,Elasticsearch充分利用了尚未分配给JVM堆的任何RAM,其依靠操作系统的文件系统缓存来快速可靠地处理请求。有许多变量决定Elasticsearch是否成功从文件系统缓存中读取。如果段文件最近由Elasticsearch写入磁盘,则它已在缓存中;但是,如果节点已关闭并重新启动,则第一次查询段时,很可能必须从磁盘读取信息。这是需要为什么确保集群保持稳定并且节点不会崩溃的重要原因之一。
4.7.主机指标
I/O:在创建,查询和合并段时,Elasticsearch会对磁盘进行大量写入和读取操作。对于具有持续经历大量I/O活动的节点的大量集群,Elasticsearch建议使用SSD来提高性能。
CPU使用率:可视化CPU使用率会很有用。CPU使用率增加通常是由大量搜索和索引请求导致。
网络流出/流入字节数:节点之间的通信是平衡群集的关键。除了Elasticsearch提供有关群集通信的传输指标,还可以查看网卡发送和接收的字节速率。
打开文件数:文件描述符用于节点到节点通信,客户端连接和文件操作。如果此数字达到系统的最大容量,则在旧的连接关闭之前,将无法进行新的连接和文件操作。
集群状态和节点可用性
| 指标描述 | 指标名 | 指标类型 |
|---|---|---|
| 集群状态 | cluster.health.status | |
| 节点数量 | cluster.health.number_of_nodes | 可用性 |
| 初始化中的分片数 | cluster.health.initializing_shards | 可用性 |
| 未分配分片数 | cluster.health.unassigned_shards | 可用性 |
集群状态:如果群集状态为黄色,则至少有一个副本分片未分配或丢失。搜索结果仍然完整,但如果更多分片消失,可能会丢失数据。
红色群集状态表示至少缺少一个主分片,并且数据正在丢失,这意味着搜索将返回部分结果。
初始化中和未分配的分片:首次创建索引或重新启动节点时,其主机节点尝试将分片分配给节点时,其分片将在转换为“已启动”或“未分配”状态之前暂时处于“初始化”状态。如果发现分片在初始化或未分配状态下保留的时间过长,则可能表示集群不稳定。
Elasticsearch 和 Kibana 变更开源许可协议
2021年1月16日,Elastic 公司宣布即将变更 Elasticsearch 和 Kibana 的其中一项开源许可协议——Apache License 2.0,将 Apache License 2.0 变更为双授权许可,即 Server Side Public License (SSPL) + Elastic License,使用者可选择适合自己使用场景的许可协议。目前 Elasticsearch 和 Kibana 使用了以下三种开源许可协议:
(i) Apache License 2.0
(ii) Apache License 2.0 compatible license
(iii) Elastic License
此次变更只影响使用到了 Apache License 2.0 的源代码,与 Apache License 2.0 无关的部分像过去一样保持不变。例如 Elasticsearch和 Kibana 的默认发行版会继续在 Elastic License 许可下发布,用户可以继续免费下载和使用。Elastic 公司表示,此次许可协议变更对大部分免费使用默认发行版的社区用户没有影响,也不会影响他们的 Elastic Cloud 云客户或自管理的订阅客户,主要是限制云服务提供商在没有回馈的情况下将 Elasticsearch 和 Kibana 作为一项服务提供给他人使用,以此保护 Elastic 公司在开发免费和开放产品方面的持续投资。此次开源许可协议的变更将会对 Elasticsearch 和 Kibana 的所有维护分支生效,从即将发布的 7.11 版本开始,使用了 Apache License 2.0 的 Elasticsearch 和 Kibana 源代码将开源许可变更为 SSPL + Elastic License 双授权许可。

SSPL 是 MongoDB 创建的 Source-Available 许可协议,它基于 GPLv3,并被认为是 Copyleft License,旨在体现开源的同时为产品应对云厂商提供保护,防止云厂商将开源产品作为服务提供而不为之回馈。SSPL 允许自由和不受限制地使用和修改产品源代码,简单的要求是,如果你将产品作为服务提供给他人,那么必须在 SSPL 下公开发布任何修改以及管理层的源代码。更多和开源许可协议变更的问题查看:FAQ on the license change。
Elasticsearch 母公司 Elastic 于2022年12月宣布裁员 13%
Elastic 是开源搜索和数据分析引擎 Elasticsearch 背后的母公司。其CEO 在发给全体员工的邮件中称,目前全球宏观经济环境正在迫使他们的客户收紧预算,并更谨慎地审查投资。在市场的某些部分尤其如此,例如中小企业在不确定时期的消费意愿有限。为了渡过这个阶段,公司要将重心放在那些对未来最关键的业务领域,并找到更有效的方法来服务公司业务的某些部分。公司向被裁员工提供了如下方案:
遣散费:向所有被裁员工支付至少 14 周的补偿金,另外工作满一年就增加一周的补偿金。
PTO:对于所有未使用的 PTO 时间(Pay Time Off,带薪休假)支付相应的薪水。
医疗保健:对于参与 Elastic 公司医疗保健计划的员工,支付 6 个月的现有医疗保健保费,或将根据工作地点支付等值现金。
RSU 股票:被裁员工将会获得截至 12 月 8 日的 RSU 股票。
职业支持:为受影响的员工提供简历和求职支持。
移民支持:为有需要的人提供移民支持。
业界人士点评:像这种以某一个软件为主要产品的公司,会较快萎缩的,因为公司提供的不是服务而是软件,而在技术/产品发展过快的领域,这种公司及其软件,就只能维持一段不长甚至很短的上升期,然后是长期的下降期;而不像大型通用软件/服务公司,比如微软,甲骨文,或者搜索引擎公司,几乎不会非常依赖于某一个具体应用软件,实际上软件公司提供的就应该是服务,而不是软件,软件不好用了,自然就会被替代,而服务几乎是永久的,用户对背后的技术/产品并不关心,其真正需要的是服务。软件开发人员和软件公司一定要做好服务,其次是提供服务的软件。
最新版本:2.2
增加了如下一些新特性。首先是基于Lucene 5.4.1,修复了v2.1.2和v1.7.5版本中存在的很多bug,同时v2.2.0增加了两个很棒的新功能:查询分析器和增强地理位置字段。这个版本增加了更加严格的安全性和修复了2.1的一个重大bug,就是在分片恢复的时候会非常缓慢。以及许多其他的错误修复和改进,官方鼓励所有用户升级到此版本。
分析器(Profile API):利用分析器可以得到查询的详细分析信息,它可以让你了解和调试查询性能。查询的每一部分都独立的记录了统计时间,如多长时间重写查询,找到匹配的文档以及他们的得分情况。这个当查询慢的时候就不需要进行猜测为什么这么慢:只要设置profile这个参数为true,你就可以得到最直接的深入的查询分析。
增强地理位置字段:地理位置字段在2.20版本中几乎进行了从写,它利用一个新的紧凑型数据结构存储在Lucene的索引中,可以增加50%的入库效率, 20-50%的查询效率,一半的存储空间和内存的占用以及更简单的映射参数。
对插件和脚本进行更严格的安全性检查:作为安全增强的一部分,Groovy和Lucene的表达式脚本语言已经移出了核心层,现在把他们作为默认的分布式模块的插件。这样的调整可以控制这些模块的权限,已减少黑客的攻击,Elasticsearch的核心模块在未来将会更多的进行模块化处理。脚本语言,现在预定义提供一个白名单列表,这些脚本不能读写文件,不能打开远程的连接。默认情况下,都不准许插件有特殊权限,否则必须事先声明这些权限。同时在插件安装时将会被警告有特殊权限的要求,这个时候你可以根据需要确认是否移除这些插件。
最新版本:6.0
v6.0.0 部分亮点如下:
无宕机升级:使之能够从 5 的最后一个版本滚动升级到 6 的最后一个版本,不需要集群的完整重启。无宕机在线升级,无缝滚动升级。
跨多个 Elasticsearch 群集搜索:和以前一样,Elasticsearch 6.0 能够读取在 5.x 中创建的 Indices,但不能读取在 2.x 中创建的 Indices。不同的是现在不必重新索引所有的旧 Indices,你可以选择将其保留在 5.x 群集中,并使用跨群集搜索同时在 6.x 和 5.x 群集上进行搜索。
迁移助手:Kibana X-Pack 插件提供了一个简单的用户界面,可帮助重新索引旧 Indices,以及将 Kibana、Security 和 Watcher 索引升级到 6.0。群集检查助手在现有群集上运行一系列检查,以帮助在升级之前更正任何问题。还应该查阅弃用日志,以确保您没有使用 6.0 版中已删除的功能。
使用序列号更快地重启和还原:6.0 版本中最大的一个新特性就是序列 ID,它允许基于操作的分片恢复。 以前,如果由于网络问题或节点重启而从集群断开连接的节点,则节点上的每个分区都必须通过将分段文件与主分片进行比较并复制任何不同的分段来重新同步。 这可能是一个漫长而昂贵的过程,甚至使节点的滚动重新启动非常缓慢。 使用序列 ID,每个分片将只能重放该分片中缺少的操作,使恢复过程更加高效。
使用排序索引更快查询:通过索引排序,只要收集到足够的命中,搜索就可以终止。它对通常用作过滤器的低基数字段(例如 age, gender, is_published)进行排序时可以更高效的搜索,因为所有潜在的匹配文档都被分组在一起。
稀疏区域改进:以前每个列中的每个字段都预留了一个存储空间。如果只有少数文档出现很多字段,则可能会导致磁盘空间的巨大浪费。现在,你付出你使用的东西。密集字段将使用与以前相同的空间量,但稀疏字段将显着减小。这不仅可以减少磁盘空间使用量,还可以减少合并时间并提高查询吞吐量,因为可以更好地利用文件系统缓存。
更多信息请参考发行说明。
最新版本:9
时隔 3 年后的2025年4月下旬,Elasticsearch 迎来重大版本更新!基于 Lucene 10.1.0 构建,v9.0.0 版本在 AI 搜索、安全分析、向量计算、集群管理 等多个领域实现突破性升级。版本亮点如下:
新增rank_vectors字段类型:支持late-interaction排名,提升复杂搜索排序能力。
ES|QL LOOKUP JOIN技术预览:更强大、灵活的SQL级联查询功能。
semantic_text字段类型全面GA(稳定版):为语义搜索注入新活力。
权限认证升级:支持更安全的SSHA-256 API密钥散列方式,精细化Kibana系统用户权限管理。
重要功能与优化
1. 集群与分配机制
新增“非主节点”状态,实现更精准负载均衡。
嵌入更多指标,提升集群健康监测效率。
2. 安全与权限增强
完善了内置和预留角色的查询和管理权限。
为安全解决方案相关数据流配置更完善的索引权限。
3. 数据流与重索引
新增基于源索引创建的索引操作接口,简化数据迁移。
支持重索引过程的取消和状态查询API,提升管理灵活性。
优化OTel日志索引排序,加速分布式数据查询。
4. ESQL与SQL查询引擎
引入多项ES|QL功能扩展,如偏移缩减、支持null值、异步查询元数据查询。
探索多日期纳秒级别支持,丰富时间序列分析能力。
查询计划优化,提升大规模数据处理效能。
5. 机器学习与推理
集成DeBERTa-v2/v3分词器,提升NLP模型表现。
增强Inference API的统一调用体验,支持聊天和重排任务。
引入mTLS支持,加强推理服务安全。
6. 核心引擎与存储
升级为Java 24环境,抛弃Java SecurityManager,采用Elastic自研Entitlements权限系统。
升级Lucene至10.1版本,进一步提升索引检索能力。
7. 网络与接口
默认启用HTTP非安全缓冲,优化网络通信效率。
新增错误响应控制参数,提升API错误处理的灵活性。
修复与改进精选
修复ECDSA签名错误、OIDC认证空指针异常和CAT API文档错误等关键问题。
重写查询计划中的大小写比较逻辑,增强规则推送到Lucene正确性。
优化日志和追踪,防止节点在错误情况下泄漏堆栈信息。
确保系统数据流快照可恢复、合并映射模板准确。
安全预警与升级建议
v9.0.0正式淘汰Java SecurityManager,改为全新Entitlements保护机制,运行环境升级需注意兼容性。
强化elastic-keystore加密强度到AES 256。
关注安全公告页面,及时获取最新补丁和漏洞修复信息。
Elasticsearch v9.0.0不仅拥抱了最新的技术栈和安全机制,还在查询引擎、数据流、机器学习等多领域进行了深度优化,助您构建更高效、更安全的搜索和分析平台。
官方主页:https://www.elastic.co/