Java全文搜索框架Lucene
 Lucene是Apache软件基金会一个开放源代码的完全用 Java 编写的高性能全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。采用Java开发并在Apache协议下授权。
Lucene是Apache软件基金会一个开放源代码的完全用 Java 编写的高性能全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。采用Java开发并在Apache协议下授权。这是一套用于全文检索和搜寻的开放源码程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具;就其本身而论,Lucene是现在并且是这几年,最受欢迎的免费Java资讯检索程式库。
Lucene最初是由Doug Cutting所撰写的,是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎的主要开发者,后来在Excite担任高级系统架构设计师,目前从事 于一些INTERNET底层架构的研究。他贡献出Lucene的目标是为各种中小型应用程式加入全文检索功能。
倒排索引
要讲明白什么是倒排索引,首先我们先梳理下什么索引,比如一本书,书的目录页,有章节,章节名称,我们想看哪个章节,通过目录页,查到对应章节和页码,就能定位到具体的章节内容,通过目录页的章节名称查到章节的页码,进而看到章节内容,这个过程就是一个索引的过程,那么什么是倒排索引呢?
比如查询《java编程思想》这本书的文章,翻开书本可以看到目录页,记录这个章节名字和章节地址页码,通过查询章节名字“继承”可以定位到“继承”这篇章节的具体地址,查看到文章的内容,我们可以看到文章内容中包含很多“对象”这个词。
那么如果我们要在这本书中查询所有包含有“对象”这个词的文章,那该怎么办呢?
按照现在的索引方式无疑大海捞针,假设有一个“对象”--→文章的映射关系,不就可以了吗?类似这样的反向建立映射关系的就叫倒排索引。
如图所示,将文章进行分词后得到关键词,在根据关键词建立倒排索引,关键词构建成一个词典,词典中存放着一个个词条(关键词),每个关键词都有一个列表与其对应,这个列表就是倒排表,存放的是章节文档编号和词频等信息,倒排列表中的每个元素就是一个倒排项,最后可以看到,整个倒排索引就像一本新华字典,所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件。
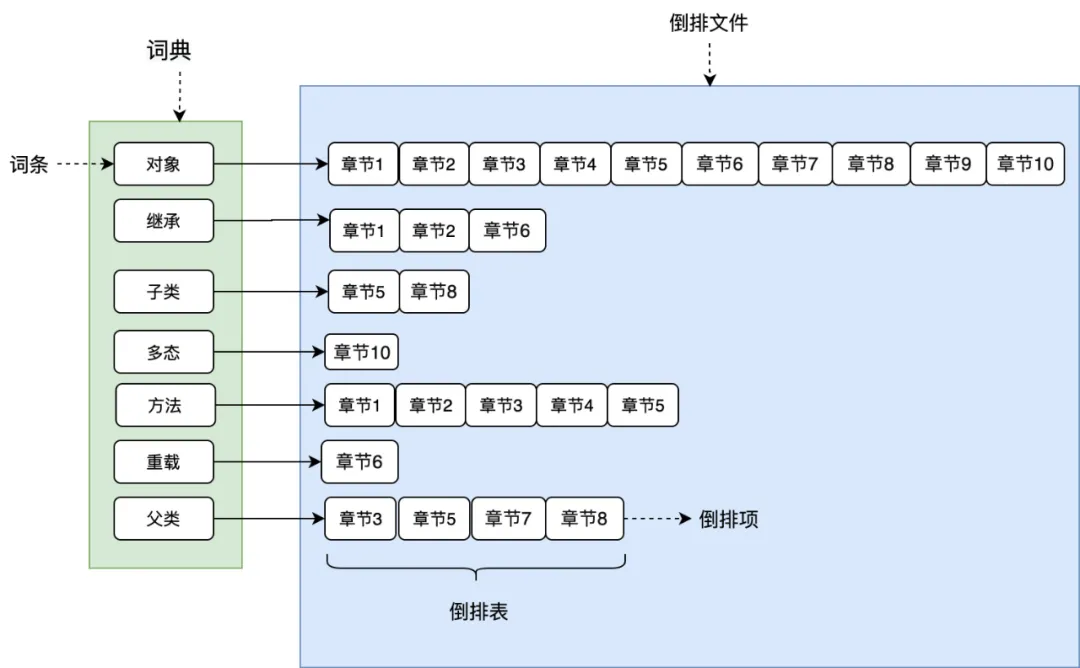
词典和倒排文件是Lucene的两种基本数据结构,但是存储方式不同,词典在内存中存储,倒排文件在磁盘上。相关还涉及分词,tf-idf,BM25,向量空间相似度等构建倒排索引和查询倒排索引所用到的技术,读者只需要对倒排索引有个基本的认识即可。
Lucene原理简介
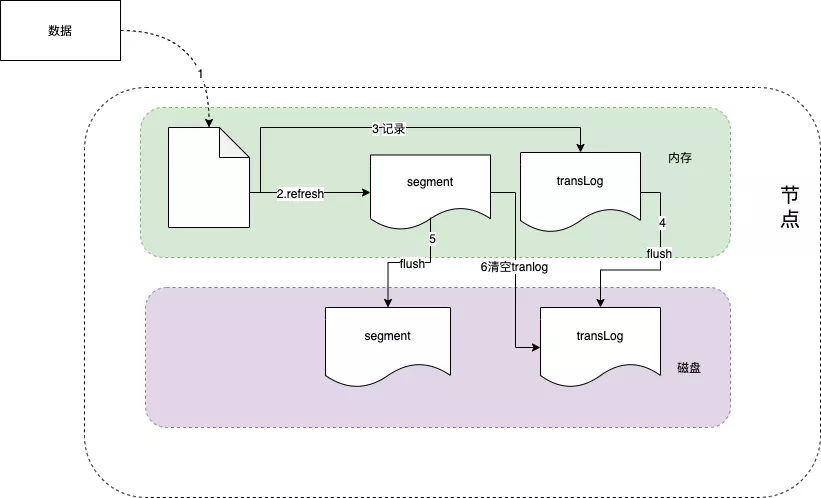
Lucene 工作原理如下图所示,当新添加一片文档时,Lucene进行分词等预处理,然后将文档索引写入内存中,并将本次操作写入事务日志(transLog),transLog类似于mysql的binlog,用于宕机后内存数据的恢复,保存未持久化数据的操作日志。
默认情况下,Lucene每隔1s(refresh_interval配置项)将内存中的数据刷新到文件系统缓存中,称为一个segment(段)。一旦刷入文件系统缓存,segment才可以被用于检索,在这之前是无法被检索的。
因此refresh_interval决定了ES数据的实时性,因此说ES是一个准实时的系统。segment 在磁盘中是不可修改的,因此避免了磁盘的随机写,所有的随机写都在内存中进行。随着时间的推移,segment越来越多,默认情况下,Lucene每隔30min或segment 空间大于512M,将缓存中的segment持久化落盘,称为一个commit point,此时删掉对应的transLog。
当我们在进行写操作的测试的时候,可以通过手动刷新来保障数据能够被及时检索到,但是不要在生产环境下每次索引一个文档都去手动刷新,刷新操作会有一定的性能开销。一般业务场景中并不都需要每秒刷新。可以通过在 Settings 中调大 refresh_interval = "30s" 的值,来降低每个索引的刷新频率,设值时需要注意后面带上时间单位,否则默认是毫秒。当 refresh_interval=-1 时表示关闭索引的自动刷新。
索引文件分段存储并且不可修改,那么新增、更新和删除如何处理呢?
新增,新增很好处理,由于数据是新的,所以只需要对当前文档新增一个段就可以了。
删除,由于不可修改,所以对于删除操作,不会把文档从旧的段中移除而是通过新增一个 .del 文件,文件中会列出这些被删除文档的段信息,这个被标记删除的文档仍然可以被查询匹配到, 但它会在最终结果被返回前从结果集中移除。
更新,不能修改旧的段来进行文档的更新,其实更新相当于是删除和新增这两个动作组成。会将旧的文档在 .del 文件中标记删除,然后文档的新版本中被索引到一个新的段。可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就会被移除。
segment被设定为不可修改具有一定的优势也有一定的缺点。
优点:
不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
其它缓存(像 Filter 缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。
写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和需要被缓存到内存的索引的使用量。
缺点:
当对旧数据进行删除时,旧数据不会马上被删除,而是在 .del 文件中被标记为删除。而旧数据只能等到段更新时才能被移除,这样会造成大量的空间浪费。
若有一条数据频繁的更新,每次更新都是新增新的,标记旧的,则会有大量的空间浪费。
每次新增数据时都需要新增一个段来存储数据。当段的数量太多时,对服务器的资源例如文件句柄的消耗会非常大。
在查询的结果中包含所有的结果集,需要排除被标记删除的旧数据,这增加了查询的负担。
段合并
由于每当刷新一次就会新建一个segment(段),这样会导致短时间内的段数量暴增,而segment数目太多会带来较大的麻烦。大量的segment会影响数据的读性能。每一个segment都会消耗文件句柄、内存和CPU 运行周期。
更重要的是,每个搜索请求都必须轮流检查每个segment然后合并查询结果,所以segment越多,搜索也就越慢。
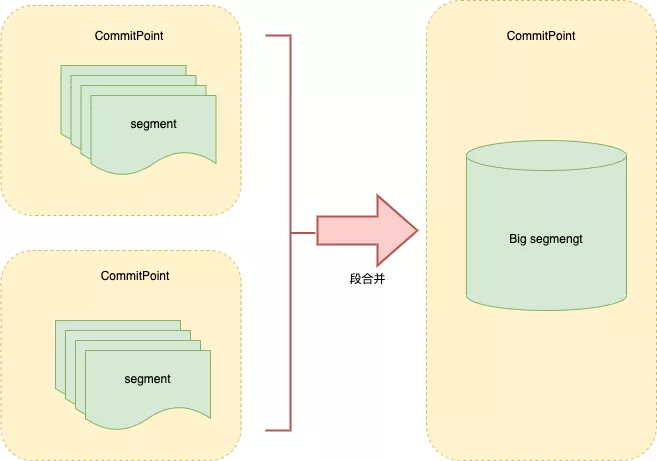
因此Lucene会按照一定的策略将segment合并,合并的时候会将那些旧的已删除文档从文件系统中清除。被删除的文档不会被拷贝到新的大segment中。
合并的过程中不会中断索引和搜索,倒排索引的数据结构使得文件的合并是比较容易的。
段合并在进行索引和搜索时会自动进行,合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中,这些段既可以是未提交的也可以是已提交的。
合并结束后老的段会被删除,新的段被刷新到磁盘,同时写入一个包含新段且排除旧的和较小的段的新提交点,新的段被打开,可以用来搜索。段合并的计算量庞大,而且还要吃掉大量磁盘 I/O,并且段合并会拖累写入速率,如果任其发展会影响搜索性能。
ES在默认情况下会对合并流程进行资源限制,所以搜索性能可以得到保证。
最新版本:8.0
查询执行:新版本对术语查询、短语查询和布尔查询进行了优化,在不需要总点击数的时候,可以有效地跳过不具竞争性的文档。根据实际查询和数据分布的不同,查询的速度会在慢几个百分点和快几倍之间变化,对术语查询和纯粹析取(pure disjunctions)来说更是如此。为配合这个改进,一些 API 做了改动:
TopDocs.totalHits 现在是一个能给出实际点击数下限的对象。
IndexSearcher 的 search 和 searchAfter 方法可以精确地计算总点击数,现在最大值只能可达 1,000,以便查询优化的默认启用。
现在需要查询才能产生非负分数。
编解码器
发布当下的索引得分,会影响到附带的的跳过数据(skip data)。这也是在点击计数不需要的情况下,术语查询对热门点击集合进行优化的方式。
Doc 值引入了跳转表,以便可以不中断地运行,这对稀疏字段来说有很大作用。
现在术语索引 FST 会在堆外加载使用 MMapDirectory 的非主键字段,从而减少这些字段的堆使用。
自定义评分:新的 FeatureField 允许将诸如 pagerank 的静态特征有效地集成到分数中,并且新的 LongPoint#newDistanceFeatureQuery 和 LatLonPoint#newDistanceFeatureQuery 方法可以分别从新近度(recency)和地理距离来提升分数。这些新帮手针对不需要总点击数的情况进行了优化。举个例子,如果 pagerank 在您的分数中有着高的权重,那么 Lucene 往往能跳过低 pagerank 值的文档。
具体更新信息可查阅更改日志。
最新版本:8.8
8.8.0 已于2021年2月2日发布, 此版本包含许多错误修复、优化和改进。部分更新内容:
接受 LatLonGeometries 数组的新 LatLonPoint 查询
LatLonPoint 查询支持空间关系
接受 XYGeometries 数组的新 XYPoint 查询
FeatureField 支持 newLinearQuery,该评分使用要素的原始索引值而不进行任何转换
Doc 值现在允许配置如何权衡压缩以提高检索速度
添加 CJKWidthCharFilter 及其 factory
ExitableTermsEnum 将在调用 next() 之前采样超时和中断检查
当提供的最小值为 1 时,GlobalOrdinalsWithScore 不应计算出现次数
二进制文档值字段现在在字段信息的属性中公开其配置的压缩模式
详细内容请查看更新公告。
最新版本:9.0
9.0 现已于2021年12上旬发布,主要更新内容如下:
支持索引高维度的数字向量,以执行最近的邻居搜索,使用分层可导航的小世界图算法
针对塞尔维亚语、尼泊尔语和泰米尔语的新分析器
对日语的 IME 友好的自动建议
Snowball 2,增加了印地语、印度尼西亚语、尼泊尔语、塞尔维亚语、泰米尔语和意第绪语的词干
为瑞典语和挪威语提供了新的规范化/词干功能
分类法分面的速度提高了400%
多维点的索引速度提高 10-15%
对以点为索引的字段的排序速度提高了数倍。这个优化在 8.x 版本后期是一个选择项,现在从 9.0 版本开始也是选择项了
ConcurrentMergeScheduler 现在假定快速 I/O,在启发式方法会错误地检测系统是否有现代 I/O 的情况下,可能会提高索引的速度
发布列表的编码从 FOR-delta 改为 PFOR-delta,以进一步节省磁盘空间
文件格式都从 big-endian 顺序改为 little-endian 顺序
Lucene 9 不再有分支的包。这需要在 lucene-core JAR 之外重新命名一些包,所以你需要相应地调整一些导入
在模块系统中使用 Lucene 9 应该被认为是实验性的
更多详情请查看项目主页。
项目主页:http://lucene.apache.org/