通用数据处理平台-Apache Spark
 Apache Spark 是使用 Scala 实现的基于内存计算的大数据开源集群计算环境,提供了 java,scala, python,R 等语言的调用接口,是专为大规模数据处理而设计的快速通用的计算引擎,现在形成一个高速发展应用广泛的生态系统。采用了Apache V2.0的授权协议。
Apache Spark 是使用 Scala 实现的基于内存计算的大数据开源集群计算环境,提供了 java,scala, python,R 等语言的调用接口,是专为大规模数据处理而设计的快速通用的计算引擎,现在形成一个高速发展应用广泛的生态系统。采用了Apache V2.0的授权协议。Apache Spark™ is a unified analytics engine for large-scale data processing.
Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)(Algorithms, Machines, and People Lab)所开源的类Hadoop MapReduce的通用并行框架,用来构建大型的、低延迟的数据分析应用程序。它拥有Hadoop MapReduce所具有的优点,但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS;因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
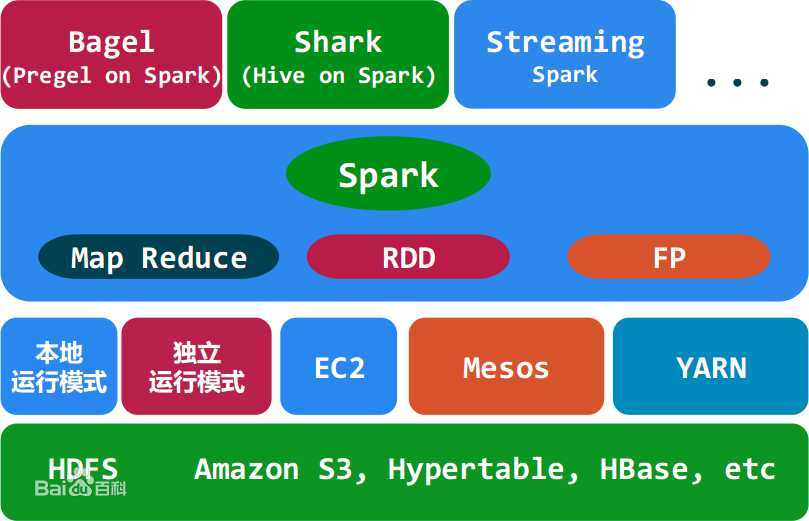
与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。
特点
首先,高级 API 剥离了对集群本身的关注,Spark 应用开发者可以专注于应用所要做的计算本身。
其次,Spark 很快,支持交互式计算和复杂算法。
最后,Spark 是一个通用引擎,可用它来完成各种各样的运算,包括 SQL 查询、文本处理、机器学习等,而在 Spark 出现之前,我们一般需要学习各种各样的引擎来分别处理这些需求。
基本原理
Spark Streaming:构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片段(几秒),以类似batch批量处理的方式来处理这小部分数据。Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+),虽然比不上专门的流式数据处理软件,也可以用于实时计算,另一方面相比基于Record的其它处理框架(如Storm),一部分窄依赖的RDD数据集可以从源数据重新计算达到容错处理目的。此外小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法。方便了一些需要历史数据和实时数据联合分析的特定应用场合。
性能特点
更快的速度:内存计算下,Spark 比 Hadoop 快100倍。
易用性:Spark 提供了80多个高级运算符。
通用性:Spark 提供了大量的库,包括Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX。 开发者可以在同一个应用程序中无缝组合使用这些库。
支持多种资源管理器:Spark 支持 Hadoop YARN,Apache Mesos,及其自带的独立集群管理器
系统架构
首先明确相关术语:
- 应用程序(Application): 基于Spark的用户程序,包含了一个Driver Program 和集群中多个的Executor;
- 驱动(Driver): 运行Application的main()函数并且创建SparkContext;
- 执行单元(Executor): 是为某Application运行在Worker Node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的Executors;
- 集群管理程序(Cluster Manager): 在集群上获取资源的外部服务(例如:Local、Standalone、Mesos或Yarn等集群管理系统);
- 操作(Operation): 作用于RDD的各种操作分为Transformation和Action。
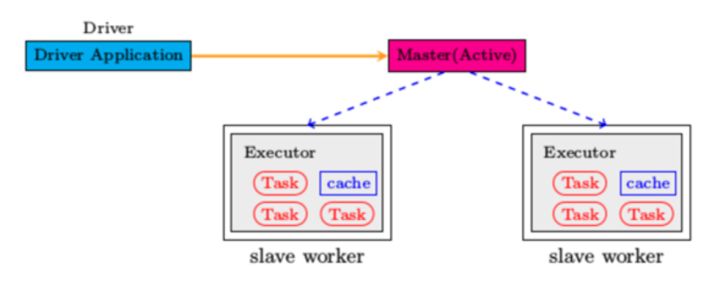
整个 Spark 集群中分为 Master 节点与 worker 节点,其中 Master 节点上常驻 Master 守护进程和 Driver 进程, Master 负责将串行任务变成可并行执行的任务集Tasks,同时还负责出错问题处理等,而 Worker 节点上常驻 Worker 守护进程, Master 节点与 Worker 节点分工不同, Master 负载管理全部的 Worker 节点,而 Worker 节点负责执行任务.
Driver 的功能是创建 SparkContext, 负责执行用户写的 Application 的 main 函数进程,Application 就是用户写的程序.
Spark 支持不同的运行模式,包括Local, Standalone,Mesoses,Yarn 模式.不同的模式可能会将 Driver 调度到不同的节点上执行.集群管理模式里, local 一般用于本地调试.
每个 Worker 上存在一个或多个 Executor 进程,该对象拥有一个线程池,每个线程负责一个 Task 任务的执行.根据 Executor 上 CPU-core 的数量,其每个时间可以并行多个 跟 core 一样数量的 Task.Task 任务即为具体执行的 Spark 程序的任务.
关于RDD
RDD(Resilent Distributed Datasets)俗称弹性分布式数据集,是 Spark 底层的分布式存储的数据结构,可以说是 Spark 的核心, Spark API 的所有操作都是基于 RDD 的.数据不只存储在一台机器上,而是分布在多台机器上,实现数据计算的并行化.弹性表明数据丢失时,可以进行重建.在Spark 1.5版以后,新增了数据结构 Spark-DataFrame,仿造的 R 和 python 的类 SQL 结构-DataFrame, 底层为 RDD, 能够让数据从业人员更好的操作 RDD.
在Spark 的设计思想中,为了减少网络及磁盘 IO 开销,需要设计出一种新的容错方式,于是才诞生了新的数据结构 RDD. RDD 是一种只读的数据块,可以从外部数据转换而来,你可以对RDD 进行函数操作(Operation),包括 Transformation 和 Action. 在这里只读表示当你对一个 RDD 进行了操作,那么结果将会是一个新的 RDD, 这种情况放在代码里,假设变换前后都是使用同一个变量表示这一 RDD,RDD 里面的数据并不是真实的数据,而是一些元数据信息,记录了该 RDD 是通过哪些 Transformation 得到的,在计算机中使用 lineage 来表示这种血缘结构,lineage 形成一个有向无环图 DAG, 整个计算过程中,将不需要将中间结果落地到 HDFS 进行容错,加入某个节点出错,则只需要通过 lineage 关系重新计算即可.
1).RDD 主要具有如下特点:
- 1.它是在集群节点上的不可变的、已分区的集合对象;
- 2.通过并行转换的方式来创建(如 Map、 filter、join 等);
- 3.失败自动重建;
- 4.可以控制存储级别(内存、磁盘等)来进行重用;
- 5.必须是可序列化的;
- 6.是静态类型的(只读)。
2).RDD 的创建方式主要有2种:
- 并行化(Parallelizing)一个已经存在与驱动程序(Driver Program)中的集合如set、list;
- 读取外部存储系统上的一个数据集,比如HDFS、Hive、HBase,或者任何提供了Hadoop InputFormat的数据源.也可以从本地读取 txt、csv 等数据集
3).RDD 的操作函数(operation)主要分为2种类型 Transformation 和 Action.

Transformation 操作不是马上提交 Spark 集群执行的,Spark 在遇到 Transformation 操作时只会记录需要这样的操作,并不会去执行,需要等到有 Action 操作的时候才会真正启动计算过程进行计算.针对每个 Action,Spark 会生成一个 Job, 从数据的创建开始,经过 Transformation, 结尾是 Action 操作.这些操作对应形成一个有向无环图(DAG),形成 DAG 的先决条件是最后的函数操作是一个Action.
生态圈
1)、Shark:Shark基本上就是在Spark的框架基础上提供和Hive一样的HiveQL命令接口,为了最大程度的保持和Hive的兼容性,Spark使用了Hive的API来实现query Parsing和 Logic Plan generation,最后的PhysicalPlan execution阶段用Spark代替HadoopMapReduce。通过配置Shark参数,Shark可以自动在内存中缓存特定的RDD,实现数据重用,进而加快特定数据集的检索。同时Shark通过UDF用户自定义函数实现特定的数据分析学习算法,使得SQL数据查询和运算分析能结合在一起,最大化RDD的重复使用。
2)、SparkR:SparkR是一个为R提供了轻量级的Spark前端的R包。SparkR提供了一个分布式的data frame数据结构,解决了 R中的data frame只能在单机中使用的瓶颈,它和R中的data frame 一样支持许多操作,比如select,filter,aggregate等等。(类似dplyr包中的功能)这很好的解决了R的大数据级瓶颈问题。SparkR也支持分布式的机器学习算法,比如使用MLib机器学习库。SparkR为Spark引入了R语言社区的活力,吸引了大量的数据科学家开始在Spark平台上直接开始数据分析之旅。
在核心框架 Spark 的基础上,主要提供四个范畴的计算框架:
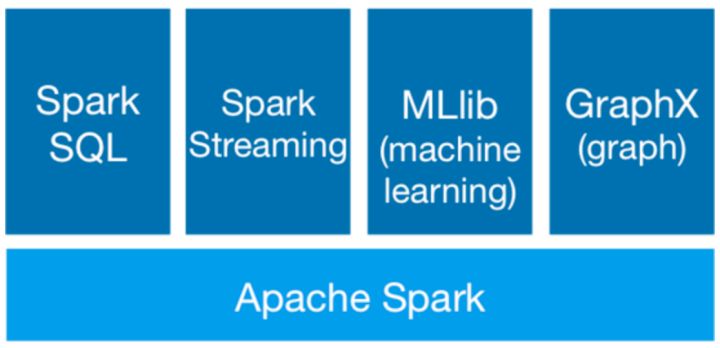
- Spark SQL: 提供了类 SQL 的查询,返回 Spark-DataFrame 的数据结构(类似 Hive)
- Spark Streaming: 流式计算,主要用于处理线上实时时序数据(类似 storm)
- MLlib: 提供机器学习的各种模型和调优
- GraphX: 提供基于图的算法,如 PageRank
Spark vs Flink
Flink出来的时间比较晚,但是发展速度很快,到2016年的时候才崭露头角,Stratosphere 项目最早在 2010 年 12 月由德国柏林理工大学教授 Volker Markl 发起,主要开发人员包括 Stephan Ewen、Fabian Hueske。Stratosphere 是以 MapReduce 为超越目标的系统,同时期有加州大学伯克利 AMP 实验室的 Spark。相对于 Spark,Stratosphere 是个彻底失败的项目。其实刚开始的时候Flink也是做批处理的,但是当时spark已经在批处理领域有所建树,所以Flink决定放弃批处理,直接在流处理方面发力。所以 Volker Markl 教授参考了谷歌的流计算最新论文 MillWheel,决定以流计算为基础,开发一个流批结合的分布式流计算引擎 Flink。Flink 于 2014 年 3 月进入 Apache 孵化器并于 2014 年 11 月毕业成为 Apache 顶级项目。

Spark与Flink的对比与分析
1.性能对比
相同点:Spark与Flink都运行在Hadoop YARN上,两者都拥有非常好的计算性能,因为两者都可以基于内存计算框架以进行实时计算。
不同点:结合上图三者的迭代次数(纵坐标是秒,横坐标是次数)图表观察,可得出在性能上,呈现Flink > Spark > Hadoop(MR)的结果,且迭代次数越多越明显。Flink之所以优于Spark和Hadoop,最主要的原因是Flink支持增量迭代,具有对迭代自动优化的功能。
结果:Flink胜。
2.流式计算比较
相同点:Spark与Flink都支持流式计算。
相异点:Spark是基于数据片集合(RDD)进行小批量处理的,它只能支持秒级计算,所以Spark在流式处理方面,不可避免会增加一些延时。Flink是一行一行的,它的流式计算跟Storm的性能差不多,是支持毫秒级计算的。
结果:Flink胜。
3.与Hadoop兼容性对比
相同点:Spark与Flink的数据存取都支持HDFS、HBase等数据源,而且,它们的计算资源调度都支持YARN的方式。
相异点:Spark不支持TableMapper和TableReducer这些方法。Flink对Hadoop有着更好的兼容,如可以支持原生HBase的TableMapper和TableReducer,唯一不足是新版本的MapReduce方法无法得到支持,现在只支持老版本的MapReduce方法。
结果:Flink胜。
4.SQL支持对比
相同点:两者都支持SQL。
相异点:从范围上说,Spark对SQL的支持比Flink的要大一些,而且Spark支持对SQL的优化(包括代码生成和快速Join操作),还要提供对SQL语句的扩展和更好地集成。Flink主要支持对API级的优化。
结果:Spark胜。
5.计算迭代对比
相同点:如下图所示,Hadoop(MR)、Spark和Flink均能迭代。
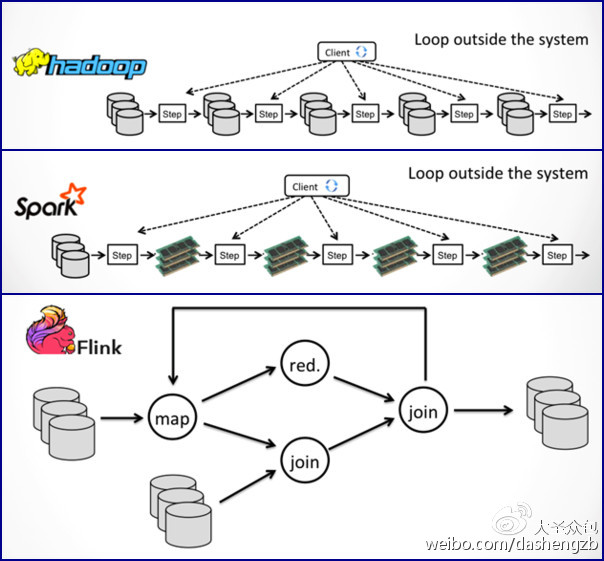
相异点:Flink特有delta-iterations,这让它能够在迭代中显著减少计算。并且Flink具有自动优化迭代程序功能,具体流程如下图所示。
结果:Flink胜。
6.社区支持对比
相同点:Spark与Flink均有社区支持。
相异点:Spark社区活跃度比Flink高很多。
结果:Spark胜。
非技术之外的咨询
Spark得到了微软的大力加持,Flink现在背后的公司被阿里收购了,阿里收购了它然后以其之力来跟spark竞争。Spark是用scala来实现的,它提供了Java,Python和R的编程接口;Flink是java实现的,当然同样提供了Scala API。所以从语言的角度来看,Spark要更丰富一些。Spark和Flink都在模仿scala的collection API,所以从表面看起来,两者都很类似。
建议公司不使用Flink,几个原因:
1、Spark对于绝大部分公司已经够用,目前投入也很多;
2、对于阿里保持谨慎怀疑态度,持续投入,质量,内部政策的不确定性;
3、技术方向,阿里主导技术可能导致厂商锁定,开源大数据和容器技术,阿里把开源的东西改的比较糟,迁移存在一定风险。
Flink是一个类似spark的“开源技术栈”,因为它也提供了批处理,流式计算,图计算,交互式查询,机器学习等。flink也是内存计算,比较类似spark,但是不一样的是,spark的计算模型基于RDD,将流式计算看成是特殊的批处理,它的DStream其实还是RDD。而flink把批处理当成是特殊的流式计算,但是批处理和流式计算的层的引擎是两个,抽象了DataSet和DataStream。
1、Spark在SQL上的优化,尤其是DataFrame到DataSet其实是借鉴的Flink的。Flink最初一开始对SQL支持得就更好。
2、Spark的cache in memory在Flink中是由框架自己判断的,而不是用户来指定的,因为Flink对数据的处理不像Spark以RDD为单位,就是一种细粒度的处理,对内存的规划更好。
3、Flink原来用Java写确实很难看,现在也在向Spark靠拢,Scala的支持也越来越好。
参考来源:
Spark学习之spark原理简述
大数据处理引擎Spark与Flink对比分析
Spark和Flink的对比(谁是下一代大数据流计算引擎)
最新版本:3.1
Apache Spark 3.1 作为 Databricks Runtime 8.0 的一部分已于2021年3月初正式发布,这也是 Apache Spark 3.x 系列的第二个 release。开发团队表示,为了让 Spark 更快、更方便使用以及更智能,Spark 3.1 对以下特性进行了扩展:
Python 可用性
ANSI SQL 合规性
查询优化增强
改进 Shuffle hash join
History Server 对结构化流数据的支持
下面简单介绍部分高级的新功能和改进。
Project Zen
Project Zen 启动于此版本,主要从以下三个方面改进了 PySpark 的可用性。
更加 Python 化
在 PySpark 中提供更好和更易用的可用性
提供与其他 Python 库更好的互操作性
ANSI SQL 合规性
该版本增加了针对 ANSI SQL 合规性的额外改进,有助于简化从传统数据仓库系统到 Spark 的工作负载迁移。
性能
Catalyst 是用于优化大多数 Spark 应用的查询编译器。在 Databricks 中,每天有数十亿次查询被优化和执行。此版本增强了查询优化 (query optimization),以及提升查询处理 (query processing) 的速度。
流处理
Spark 是构建分布式流处理应用程序的最佳平台。每天有超过 10 万亿条记录在 Databricks 上使用 structured streaming 进行处理。此版本增强了 structured streaming 的监控能力、可用性和功能。
其他更新
除了上述这些新功能,此版本还关注可用性、稳定性和完善性,处理了约 1500 个工单。
更多内容查看发行公告。
项目主页:http://spark.apache.org