计算机视觉库-OpenCV
 OpenCV是Intel®开源计算机视觉库。它由一系列 C 函数和少量 C++ 类构成并在BSD协议下授权,实现了图像处理和计算机视觉方面的很多通用算法。拥有包括 300 多个C函数的跨平台的中、高层 API。它不依赖于其它的外部库——尽管也可以使用某些外部库。
OpenCV是Intel®开源计算机视觉库。它由一系列 C 函数和少量 C++ 类构成并在BSD协议下授权,实现了图像处理和计算机视觉方面的很多通用算法。拥有包括 300 多个C函数的跨平台的中、高层 API。它不依赖于其它的外部库——尽管也可以使用某些外部库。OpenCV is released under a BSD license, it is free for both academic and commercial use. It has C++, C, Python and soon Java interfaces running on Windows, Linux, Android and Mac. The library has >2500 optimized algorithms (see figure below). It is used around the world, has >2.5M downloads and >40K people in the user group. Uses range from interactive art, to mine inspection, stitching maps on the web on through advanced robotics.
OpenCV 对非商业应用和商业应用都是免费的,OpenCV 为Intel Integrated Performance Primitives (IPP) 提供了透明接口,这意味着如果有为特定处理器优化的的 IPP 库, OpenCV 将在运行时自动加载这些库。OpenCV可以在Windows, Android,Maemo,FreeBSD,OpenBSD,iOS,Linux和Mac OS等平台上运行。用户可以在SourceForge获得官方版本,或者从SVN获得开发版本,OpenCV也是用CMake。
OpenCV 开源协议将从 BSD 变更为 Apache 2
2020年07月15日,计算机视觉库 OpenCV 即将迎来 20 周年,其重要版本 v5 也发布在即。OpenCV 官方宣布:其开源许可协议将从 3-clause BSD 变更为 Apache 2。

自项目发布之初,OpenCV 就一直使用较为宽松的 BSD 协议。然而该协议已很难满足快速发展的计算机视觉领域,尤其因为该协议不涉及专利,而使用该协议的代码很有可能包含一些专利算法的实现。根据 OpenCV 的介绍,“从传统的视觉算法到深度学习拓扑网络以及两者的混合,越来越多的算法申请了专利”。但在 BSD 条款下,专利用户的权利难以得到保障。
此前的报道有提到过,为了避免这个问题,OpenCV 选择不接收有专利的算法。这样做虽然保障了安全性,但也让一些优秀算法无法进入 OpenCV。
经过考量,OpenCV 团队发现 Apache 2 是最为有效的解决方案。因为 “Apache 2 比 BSD 协议更新,提供了与 BSD 许可相同的免费使用特性,还包含有关专利的使用条款”。关于专利,Apache 2 中有两项条款做了大致说明:
如果个人或实体在 Apache 2 协议下提供代码,由于包含的专利被授予了一个隐含许可,则用户不能因违反该实体在该代码中的专利或从该代码派生的作品中的专利而被起诉。
如果个人或实体(A)决定起诉某人或某个实体(B),被起诉的(B)创建了一个由(A)的专利所涵盖的上述(1)中代码派生的作品,那么(A)将失去他们所有的 Apache 2 专利诉讼保护,从而可能使他们面临其他方面的法律攻击。
OpenCV 表示,虽然这种专利保护不是绝对的,但 Apache 2 在这方面目前是最先进的,因此决定进行协议变更。
迁移将从 OpenCV 4.4 开始,考虑到原有许可和原有版权,该版本会在同一个仓库中复制分支。仍旧需要使用 BSD 许可证的用户,可以继续使用 OpenCV 2.x、OpenCV 3.x 和 OpenCV 4.x,以及最新的 OpenCV 4.4。
从 OpenCV pre-5.0(将在新创建的分支中开发)和 OpenCV pre-4.5(“master”分支)开始,许可证将正式更改为 Apache 2。所有新功能的贡献者都必须同意将他们的代码在 Apache 2 许可证下授权。此次协议变更对于 OpenCV 用户来说并无太大变化,主要是需要增加针对专利诉讼的保护措施。Apache 2 许可下的 OpenCV 仍然可以自由地用于商业和非商业项目。
最新版本:3
该版本主要改进:
OpenCV 提供了通过 cv::getBuildInformation() 获取完整构建信息的方法
支持Mac OS x下用ffmpeg进行视频读写的操作
MOG2 background subtraction by Zoran Zivkovic was optimized using TBB.
文档的完善、修复了多个bug、支持 Asus Xtion
最新版本:4.5
core:增加了对并行后端的支持,特殊的 OpenCV 构建允许选择并行后端和/或通过插件动态加载它;
imgproc:增加了 IntelligentScissors 的实现。该功能已集成到 CVAT 注释工具中,可以在https://cvat.org 上在线试用;
videoio: 改进的硬件加速视频解码/编码任务。
DNN 模块:
改进了 TensorFlow 解析错误的调试;
改进了图层/激活/支持更多模型;
优化了 NMS 处理、DetectionOutput;
修复了 Div with constant、MatMul、Reshape;
增加了支持:Mish ONNX 子图、NormalizeL2 (ONNX)、LeakyReLU (TensorFlow)、TanH (Darknet)、SAM (Darknet)、Exp;
增加了对OpenVINO 2021.3版本的支持。
G-API 模块:
支持 Python:
引入了一个新的 Python 后端 —— 现在 G-API 可以运行用 Python 编写的自定义内核,作为管道的一部分;
扩展了 G-API Python 绑定中的推理支持;
在 G-API 的 Python 绑定中增加了更多的图形数据类型支持;
推理支持:
在 OpenVINO 推理后端中引入了动态输入/CNN 重塑功能;
在 OpenVINO 推理后端引入异步执行支持,现在推理可以在多个请求中并行运行,以增加流密度/吞吐量;
在 ONNX 推理后端中扩展了 INT64/INT32 支持的数据类型,在 OpenVINO 推理后端中扩展了 INT32 支持的数据类型;
在 ONNX 后端引入 cv::GFrame/cv::MediaFrame 和恒定支持;
媒体支持:
在绘图/渲染界面中引入了 cv::GFrame / cv::MediaFrame 支持;
在流媒体模式中引入了多流媒体输入支持和帧同步策略,以支持立体声等情况;
增加了 Y 和 UV 操作,以在图形级别访问 cv::GFrame 的 NV12 数据;
如果媒体格式不同,转换是即时完成的;
操作和内核:
增加了新操作的性能测试(MorphologyEx、BoundingRect、FitLine、FindContours、KMeans、Kalman、BackgroundSubtractor);
修正了 PlaidML 后台的 RMat 输入支持;
为 Fluid AbsDiffC、AddWeighted 和 bitwise 操作添加了 ARM NEON 优化。
更多详情可查看此处。
最新版本:4.7
该版本于2022年12月下旬发布,主要更新内容如下:
DNN:
新的 ONNX 层
对卷积的性能进行了显著的优化,Winograd 算法的实现
支持 OpenVino 2022.1
算法:
ArUco 标记和 April 标签支持,包括 ChAruco 的检测和校准
二维码检测和解码质量的提高,支持对齐标记
基于神经网络的 Nanotrack v2 跟踪器
Stackblur 算法的实现
多媒体:
支持 FFmpeg 5.x。
支持 CUDA 12.0。通过现代 Video Codec SDK 在 NVIDIA 平台上支持硬件加速的视频编解码器。
使用 FFmpeg 支持 CV_16UC1 读 / 写视频
在 Mac 上用本地媒体 API 提供方向元数据支持
新的基于迭代器的 API 用于多页图像格式
对 PNG 格式的 libSPNG 支持
对自建的 libJPEG-Turbo 的 SIMD 加速
在 Android 上支持 H264/H265
G-API:将所有核心 API 暴露给 Python,包括有状态的内核
优化:用于可扩展矢量指令的新通用内在函数后端。RISC-V RVV 1.0 的第一个可扩展实现
DNN 模块补丁 :
改进层/支持更多模型:
添加了 CANN 后端支持
添加了用于多类对象检测的 bathed NMS
加速卷积,特别适用于 ARM CPU
Winograd 的卷积优化
更多详情可查看此处。
最新版本:4.10
根据“OpenCV 中国团队”于2024年6月上旬介绍,从 v4.10 开始 OpenCV 对 JPEG 图像的读取和解码有了 77% 的速度提升,超过了 scikit-image、imageio、pillow。下边是该版本的一些亮点:
dnn 模块的改进:
改善内存消耗
增加了将模型转储为与 Netron 工具兼容的 pbtxt 格式的功能
支持多个新的 TFlite、ONNX 和 OpenVINO 层
改进了现代 Yolo 探测器支持
添加了 CuDNN 9+ 和 OpenVINO 2024 支持
core 模块的改进:
为 cv::Mat 添加了 CV_FP16 数据类型
扩展了 HAL API,用于 minMaxIdx、LUT、meanStdDev 和其他函数
imgproc 模块的改进:
为 cv::remap 添加了相对位移场选项
重构 findContours 和 EMD
扩展了 HAL API,用于 projectPoints、equalizeHist、Otsu 阈值和其他功能
添加了针对现代 ARMv8 和 ARMv9 平台优化的新底层 HAL 库(KleidiCV)
支持 CUDA 12.4+
添加了 zlib-ng 作为经典 zlib 的替代品
对 Wayland、Apple VisionOS 和 Windows ARM64 的实验性支持
OpenCV Model Zoo 新增几个功能
最新版本:5
v5 现已于2026年6月上旬正式发布,这是自 2018 年 OpenCV 4 发布以来八年间最大的一次升级。本次升级包含了无数开发者的贡献,其中下面三个单位系统性组织了开发:
1、Big Vision 公司:负责 OpenCV 开发、OpenCV 大学、OpeCV 推广等
2、OpenCV 中国团队:负责 RISC-V 和嵌入式系统优化、CPU 性能测试基准开发等(感谢中科院软件所、进迭时空公司支持 RISC-V 生态优化)
3、OpenCV.ai 公司
v5 对中国开发者意味着什么
对中国开发者来说v5 有几层特别现实的意义。
1、边缘设备更重要。中国有大量面向机器人、工业检测、智能安防、车载、消费电子和具身智能的视觉应用,部署环境经常不是标准服务器,而是 ARM、Snapdragon、RISC-V、NPU 等多种硬件。OpenCV 5 重新整理 HAL,对这类场景尤其关键。
2、现代模型部署更顺。大量科研和工程项目会把模型导出为 ONNX,再接入 C++ 或 Python 视觉流程。OpenCV 5 提升 ONNX 覆盖率和动态 shape 支持,可以减少 “模型训练好了,但部署时卡住” 的情况。
3、OpenCV 正在从传统 CV 扩展到 “视觉系统底座”。未来一个视觉应用里,可能同时有传统图像处理、检测分割、视觉语言模型、几何重建和硬件加速。OpenCV 5 的价值,不只是某个单点更强,而是让这些模块尽量在同一套工具链里协同工作。
4、参与开源社区的机会更清晰。OpenCV 5.x 周期还会持续推进 GPU DNN、非 CPU HAL、更多模型与更多硬件支持。对高校、研究机构和企业开发者来说,这也是参与国际开源项目、提交 patch、贡献测试和优化的好机会。
关于 v5
对很多开发者来说,OpenCV 是 “装上就能用” 的底层工具:读图、变换、滤波、检测、跟踪、标定、拼接、部署,几乎每个视觉项目都会在某个环节碰到它。也正因为太常用,OpenCV 的每一次大版本更新,都不只是库本身的事情,而会影响大量科研原型、工程系统和产业应用。这次的v5不是常规的小修小补。它针对近几年计算机视觉技术栈的变化做了一次系统性升级:深度学习模型越来越复杂,ONNX 模型越来越常见,Transformer 和大视觉模型进入生产环境,边缘设备和异构硬件越来越多,Python 成为很多视觉开发者的第一入口。v5 正是面向这些变化而来。其把 “传统视觉工具箱” 往 “现代视觉应用底座” 又推进了一大步。
为什么需要 OpenCV v5
从 v4 到 v5,计算机视觉的开发环境已经变了很多。现在的视觉应用往往不再是 “读一张图、跑一个传统算法” 这么简单,而是把经典图像处理、深度学习、Transformer、大视觉模型、边缘部署、异构硬件和 Python 工作流混在一起。
开发者的期待也变了:同一套代码最好能在笔记本、服务器、嵌入式设备、ARM 芯片、Snapdragon 平台以及专用加速器上高效运行;一个从 PyTorch 导出的 ONNX 模型,最好能直接加载,而不是到处报算子不支持、动态 shape 不兼容。
v5 要解决的核心问题很明确:让核心库更快、更小,让 API 更干净,让 DNN 引擎跟上现代模型,让硬件加速路径更清晰,让 3D 视觉工具更好用,也让文档真正变得容易查。
最大的变化:全新的 DNN 引擎
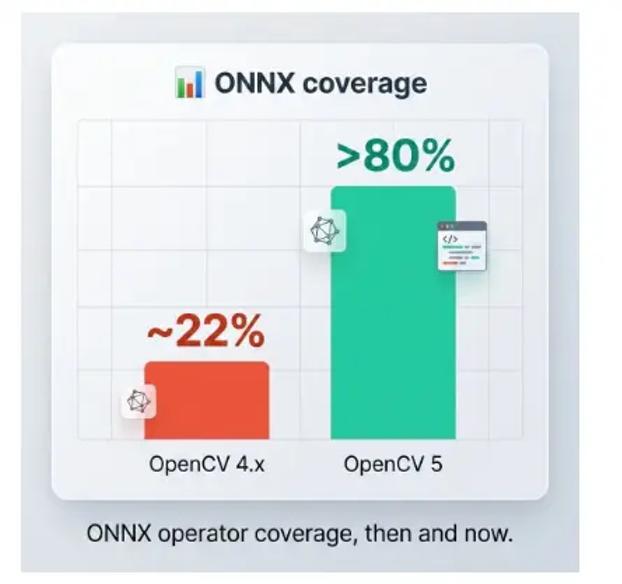
v5 最重要的变化,是 DNN 引擎重写。ONNX 算子覆盖率:v4.x 时期大约只有 22%,到 v5 提升到 80% 以上。
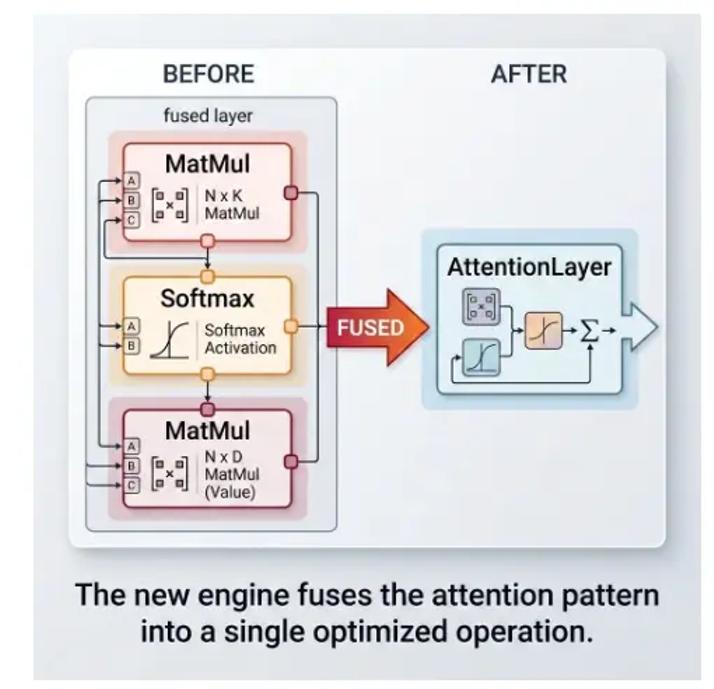
这个数字背后,解决的是很多开发者过去最熟悉的痛点:模型导出成 ONNX 后,OpenCV DNN 不一定能顺利读;即便能读,也可能因为动态 shape、控制流、量化图或某些 Transformer 结构而失败。OpenCV 5 的新 DNN 引擎不再把网络简单看成一层一层顺序执行的列表,而是重建为带类型信息的计算图。这样一来,系统可以做形状推理、常量折叠、算子融合和更激进的内存复用。
新引擎开始支持过去很难处理的几类模型结构:带 If 和 Loop 的子图;符号 shape 和动态 shape;用于量化模型的 Quantize/Dequantize 图;以及 Transformer 里常见的 Attention 和 MatMul 融合。其中 Attention 融合很关键。引擎可以识别 Transformer 中典型的 “MatMul - Softmax - MatMul” 模式,并把它折叠成一个融合后的 Attention 操作,底层采用类似 FlashAttention 的实现思路。对开发者而言,使用方式没有变:加载模型,运行推理,性能提升由引擎自动完成。
三个引擎,一套 API
大版本重写最容易让人担心兼容性。OpenCV 5 的处理方式比较稳妥:在同一套 DNN API 背后保留多个引擎,开发者可以在读取模型时指定使用哪一个。
主要选项包括:ENGINE_CLASSIC,强制使用 4.x 风格的经典引擎,也是当前支持 CUDA、OpenVINO 等非 CPU 后端和 target 的路径;ENGINE_NEW,强制使用新的图引擎,支持融合和动态 shape,但目前只跑 CPU;ENGINE_AUTO,默认选项,先尝试新引擎,失败时回退到经典引擎;ENGINE_ORT,使用内置的 ONNX Runtime 封装,仅适用于 ONNX 模型,并且编译时需要启用 WITH_ONNXRUNTIME。
这意味着,大部分已有代码不必大改。你仍然可以像以前一样调用 readNetFromONNX;默认情况下 OpenCV 会优先尝试新引擎,必要时自动回退;如果要明确指定引擎,也可以在加载模型时传入 engine 参数。
# Python版本
import cv2 as cv
# 默认行为:ENGINE_AUTO,优先尝试新引擎,失败后回退到经典引擎
net = cv.dnn.readNetFromONNX("model.onnx")
# 也可以显式指定新图引擎
net = cv.dnn.readNetFromONNX("model.onnx", engine=cv.dnn.ENGINE_NEW)
net.setInput(blob)
out = net.forward()
// C++版本
#include <opencv2/dnn.hpp>
using namespace cv;
// Default behaviour (ENGINE_AUTO).
dnn::Net net = dnn::readNetFromONNX("model.onnx");
// Or pin a specific engine at load time.
/*
dnn::Net netNew = dnn::readNetFromONNX("model.onnx", dnn::ENGINE_NEW);
*/
net.setInput(blob);
Mat out = net.forward();
速度如何:在 CPU 上对标 ONNX Runtime
盖率只是第一步,真正到工程里还要看速度。官方测试在 Intel Core i9-14900KS 和 Ubuntu 24.04 LTS 上比较了 OpenCV 5 DNN 与 ONNX Runtime 在多个真实模型上的 CPU 推理延迟。结果显示,在若干模型上,OpenCV 5 的新 DNN 引擎不仅能跑,而且有竞争力,很多情况下还更快。
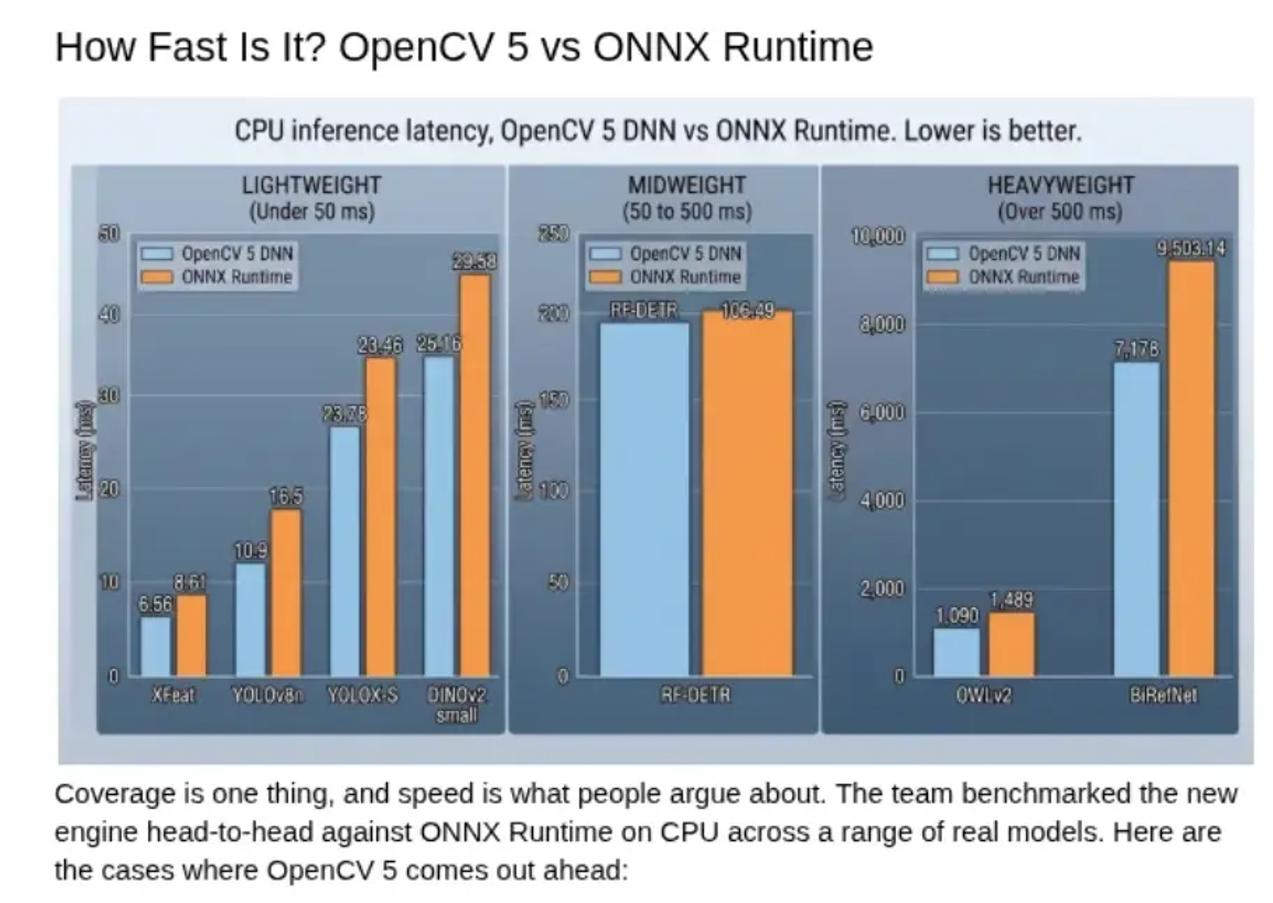
例如,XFeat 上 OpenCV 5 为 6.56 毫秒,ONNX Runtime 为 8.61 毫秒;YOLOv8n 上分别为 10.9 毫秒和 12.15 毫秒;DINOv2 small 上分别为 23.78 毫秒和 29.58 毫秒;OWLv2 上分别为 1090 毫秒和 1489 毫秒。数值越低越好。
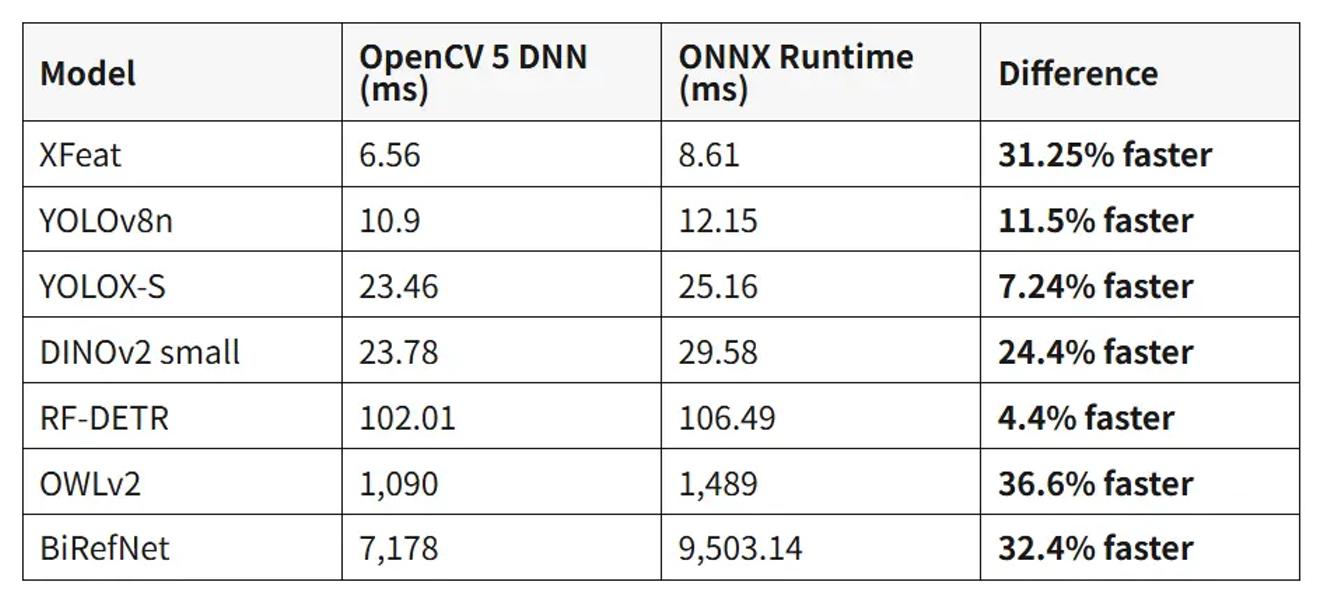
当然,这些结果不能简单理解为 OpenCV 5 在所有场景都一定快于 ONNX Runtime。更准确的理解是:v5 的新 DNN 引擎已经不再只是 “能不能加载模型” 的补充选项,而是在 CPU 推理上有了正面竞争的能力。对于希望减少依赖、把视觉流程尽量留在 OpenCV 内部的项目,这一点很有价值。
更多模型可以开箱即用
ONNX 覆盖率提升以后,最直接的好处就是更多现代模型可以直接跑。OpenCV 5 已经针对一批覆盖检测、分割、特征骨干网络和生成式模型的现代模型进行了验证。

这对工程项目很实际。过去一个视觉系统里可能同时依赖 OpenCV、ONNX Runtime、某个检测框架、某个分割框架,再加上一堆前后处理代码。OpenCV 5 的目标不是替代所有深度学习框架,而是让更多常见视觉模型能在同一个库里完成部署,降低依赖复杂度。
LLM 和 VLM 也进入了 OpenCV
OpenCV 5 里一个很有意思的变化,是 DNN 模块可以直接运行大语言模型和视觉语言模型,不再必须依赖单独的推理运行时。为了做到这一点,OpenCV 5 加入了两个过去传统 CV 库不太需要的组件:内置 tokenizer,以及用于自回归解码的 KV-cache。前者负责把文本转成模型需要的 token,后者让模型逐 token 生成时保持效率。官方文章提到,相关能力覆盖 Qwen 2.5、Gemma 3、PaliGemma 以及 GPT-2/GPT-4 家族,并且仍然通过开发者熟悉的 Net API 调用。
需要强调的是,OpenCV 并不是要变成专门的 LLM 服务框架。它更适合在视觉流程中调用小型语言模型或视觉语言模型,比如图像描述、OCR 后处理、开放词表查询,或者在一个视觉系统内部完成简单的图文理解。对于这类任务,少引入一个运行时,往往就少一层部署负担。
LaMa 图像修复:一个 forward 完成物体移除
v5 还展示了基于 LaMa 的图像修复能力。输入一张图,再给出要移除区域的 mask,DNN 引擎就可以在一次 forward 中完成修复,把被遮挡区域补回来,并让边缘自然融合。
流程很直接:准备原图;准备 mask;调用一次 Net::forward;得到干净输出。官方还在 OpenCV 5.x 分支里提供了可运行的 samples/dnn/inpainting.py。如果希望进一步尝试扩散模型版本,也可以看 samples/dnn/ldm_inpainting.py。

实现上图功能的代码只有如下 5 行:
import cv2 as cv
net = cv.dnn.readNetFromONNX("lama.onnx")
blob = cv.dnn.blobFromImages([img, mask], scalefactor=1/255.)
net.setInput(blob)
out = net.forward() # inpainted imag
这类能力说明 v5 的 DNN 模块已经覆盖到更广的现代视觉任务,不再只是传统意义上的分类、检测和分割。
特征匹配也进入深度学习时代
特征检测和匹配是 OpenCV 最经典的任务之一。图像拼接、图像对齐、三维重建,很多系统都从 SIFT、ORB、FAST 这些传统特征开始。v5 保留了这些经典方法,同时把现代学习式特征匹配作为一等公民引入。
新的 Features 模块替代原来的 Features2D,加入了完整的神经网络式检测、描述和匹配流程。
1、cv::ALIKED 是基于 CNN 的关键点检测与描述方法,可以像 SIFT 或 ORB 一样嵌入已有调用位置;
2、cv::DISK 是通过强化学习训练出来的学习式特征,在宽基线和低纹理场景中更有优势;
3、cv::LightGlueMatcher 则是基于 Attention 的匹配器,可以输出带置信度的匹配结果,并能接入图像拼接模块。
这不是“新方法替代旧方法”,而是让开发者有了更灵活的选择:简单场景继续用稳定、轻量的传统特征;困难场景则可以直接尝试学习式特征和 LightGlue 匹配。
核心库更快,也更现代
v5 并不只是在 DNN 上做文章。底层 core 模块也做了很多会影响日常开发体验的改动。首先是数据类型。OpenCV 5 加入了原生 FP16,也就是 cv::hfloat 和 CV_16F,还加入了 BF16,也就是 cv::bfloat 和 CV_16BF,同时补齐了 bool、64 位整数等类型。现代 AI 工作负载大量使用这些数据类型,原生支持意味着少做很多来回转换。
其次是更完整的 N 维数组和标量支持。过去 cv::Mat 至少需要二维,这在处理标量、1D 数组以及很多模型中间结果时并不自然。OpenCV 5 的 cv::Mat 可以表示 0D 标量和 1D 数组,并加入 broadcasting,以及 transposeND、flipND 等 N 维操作。很多过去需要手工 reshape、扩维、挤维的代码,可以变得更直接。

语言层面也更清爽:历史包袱很重的 C API 正式进入弃用状态;C++17 成为最低推荐标准,后续 5.x 还计划引入 C++20 modules;Python 侧支持 NumPy 2.x,并且让 C++ 算法在 Python 里更好地支持命名参数。也就是说,过去必须记住一串位置参数的调用,现在可以写成 cv.someAlgorithm (threshold=0.5) 这种更直观的形式。
硬件加速:让同一套代码跑在更多芯片上
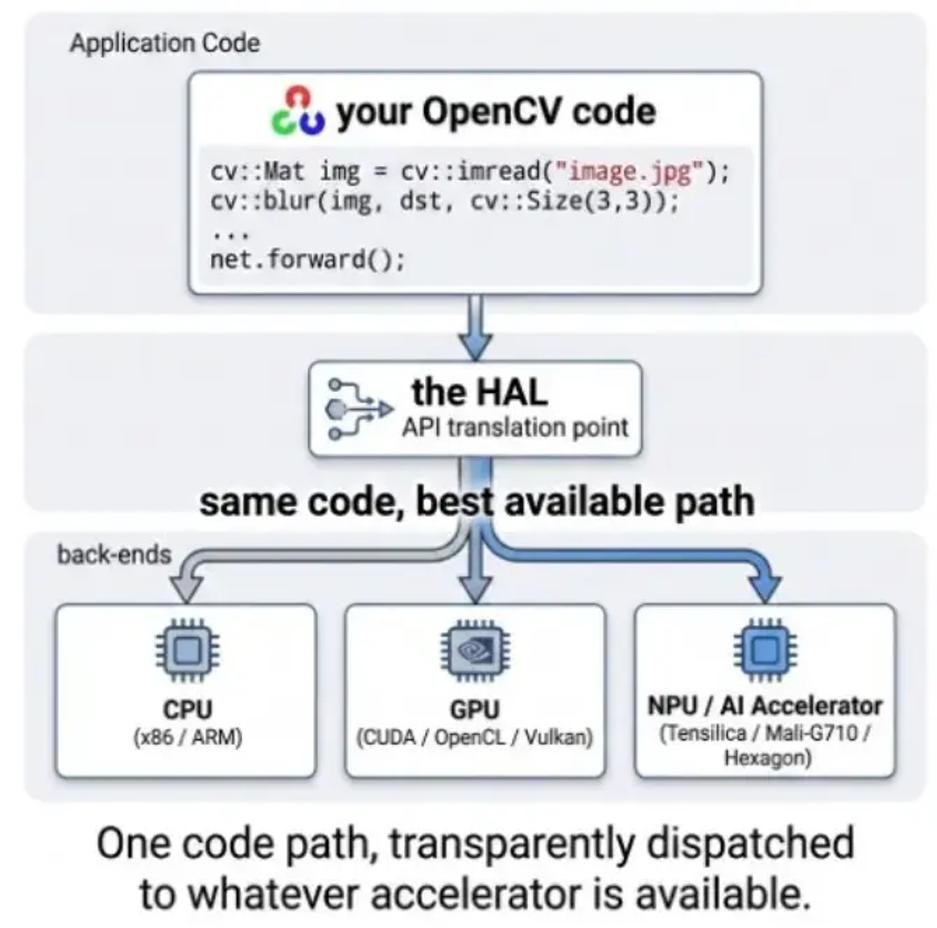
v5 里还有一个不那么显眼、但非常关键的变化:重新设计了 Hardware Acceleration Layer,也就是 HAL。过去支持不同硬件,常常意味着大量条件编译、重复实现和分散在各处的优化代码。v5 希望把这件事收敛到一套干净的 HAL 契约里:硬件厂商可以为自己的芯片接入优化 kernel,OpenCV 在可用时自动调用,开发者的上层代码不用改。
目前已经接入或推进的路径包括:Intel IPP/IPPICV,这是 OpenCV 早期就很重要的 x86/x64 加速路径;Arm KleidiCV,面向 AArch64,使用 NEON、SVE 和 SME 加速核心图像处理与 DNN kernel;Qualcomm FastCV,面向 Snapdragon 等移动平台,可通过 Hexagon DSP 和 NPU 加速;RISC-V Vector,也就是 RVV,相关工作主要由 OpenCV China 推动。
底层还有 Universal Intrinsics 2.0,用一套向量化代码映射到 SSE、AVX2/512、NEON、SVE、RVV 等不同指令集。对开发者来说,理想状态很简单:写一次 OpenCV 代码,落到不同硬件上时尽量自动走最优路径。
3D 视觉模块重新整理
OpenCV 的 3D 能力这些年一直在增长,但旧的 calib3d 模块已经越来越像一个 “大抽屉”。OpenCV 5 把相关能力拆成三个更清晰的模块:3d、calib 和 stereo。
3D 模块负责基础 3D 几何与视觉能力,包括 I/O、几何基本元素、ICP 等算法,以及部分 SLAM 相关能力;calib 模块负责相机标定,包括单相机标定和重构后的多相机标定流程;stereo 模块负责双目深度。
更值得注意的功能包括:通过 calibrateMultiview 进行多相机标定,也就是 N 相机 bundle adjustment;通过 registerCameras 做相机间外参注册,并支持手眼标定、机器人世界标定等机器人场景;通过 loadPointCloud、savePointCloud、loadMesh、saveMesh 读写点云和网格,支持 OBJ、PLY;通过 TSDF、HashTSDF 和 ColorTSDF 完成稠密 RGB-D 融合,并加入视觉里程计;此外还有包含 MAGSAC 的现代 USAC 框架,以及 RANSAC 平面和球体拟合。
如果你的工作涉及 SfM、机器人、三维重建或 RGB-D 融合,这次调整不是简单改名,而是一次实用的能力升级。
文档更好用了
v5 的文档也重做了。新的文档系统从纯 Doxygen 转向 Sphinx + Doxygen,带来了更现代的阅读体验:左侧导航常驻,手写教程和自动生成的 API 参考放在一起,Python 签名可以和 C++ 一起展示,提交前还有链接检查,整体样式也更清爽。这类变化听起来不如 DNN 引擎重写那么 “硬核”,但对日常开发非常重要。很多人学习 OpenCV、查函数签名、找样例代码,首先接触的就是文档。文档少一点阻力,库本身就更容易被用起来。
v5.0 到底带来了什么
要点:ONNX 算子覆盖率从 4.x 时期的大约 22% 提升到 80% 以上;DNN 引擎重写为图引擎,支持融合、动态 shape 和统一 buffer pool;可以通过 ENGINE_ORT 接入 ONNX Runtime;LLM/VLM 支持进入 DNN 模块,内置 tokenizer 和 KV-cache;动态 shape ONNX 由新的形状推理引擎原生支持;cv::Mat 支持 0D 标量和 1D 数组;数据类型补齐 FP16、BF16、bool、64 位整数等。
这些变化合在一起,说明 OpenCV 5 不是简单增加几个函数,而是在补现代视觉应用所需要的底层能力。
下一步:GPU 版 DNN 引擎,以及非 CPU HAL
v5.0 是一次大更新,但更像是一个新架构的起点。接下来最值得关注的,是两条路线。
第一条是新 DNN 引擎的原生 GPU 支持。当前官方展示的 DNN benchmark 主要在 CPU 上运行,新图引擎也是 CPU 优先。如果现在要 GPU 推理,可以使用 ONNX Runtime 后端以及 CUDA、TensorRT 等 execution provider。OpenCV 后续希望把 GPU 加速带入自己的原生图引擎,让开发者仍然通过同一个 Net API 拿到 GPU 速度,而不是必须额外引入独立运行时。
第二条是非 CPU HAL,用于加速前处理和后处理。真实视觉流水线里,模型推理往往只是其中一部分。每一次 forward 前后都有 resize、颜色转换、归一化、letterbox、NMS、mask resize、结果绘制等步骤。今天很多系统是 CPU 做前后处理,加速器做推理,数据在 CPU 和 GPU/NPU 之间来回搬。很多时候,真正的瓶颈不是模型,而是这些搬运。
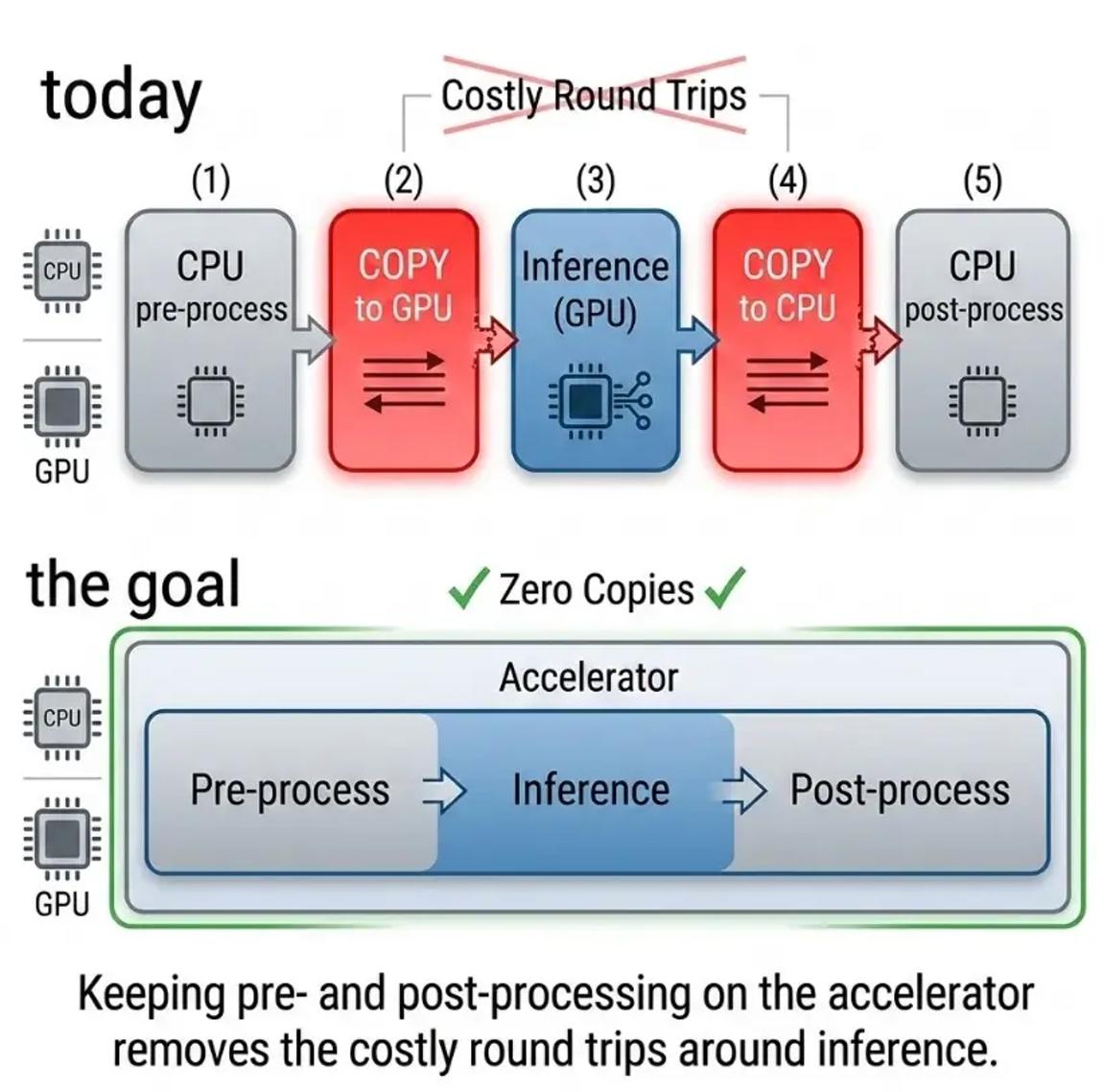
非 CPU HAL 的目标,是让常见 imgproc 函数也能跑在 GPU、NPU 或其他加速器上。理想流程是:帧保留在加速器上,resize 和 normalize 在上面做,推理在上面做,后处理也在上面
结语
OpenCV v5 的意义,不在于多了几个新函数,而在于它把 OpenCV 带回了现代计算机视觉开发的主战场。全新的 DNN 引擎解决了最常见的模型部署痛点,核心库和 Python 接口减少了日常摩擦,HAL 为异构硬件打开了更干净的加速路径,3D 视觉和特征匹配也补上了近年来的发展。更重要的是,v5 没有抛弃庞大的既有用户。经典引擎还在,传统特征还在,已有 API 尽量保持不变。它一边激进现代化,一边保留兼容性。对这样一个被广泛嵌入科研、教学和工程系统的基础库来说,这种克制很重要。如果说 OpenCV 过去二十多年是计算机视觉应用的 “基础水电”,那么 v5 就是一次面向 AI 时代的管线改造。它不会让所有问题一夜之间消失,但它让很多过去绕不开的麻烦,终于有了更干净的解决路径。
官方主页:
http://www.opencv.org.cn/
http://opencv.willowgarage.com/wiki/
该文章最后由 阿炯 于 2026-06-08 21:40:40 更新,目前是第 2 版。