Etcd
 Etcd是CoreOS团队于2013年6月发起的开源项目,用于可靠地存储集群的配置数据的一种持久性,轻量型的,高可用的分布式的键-值(key-value)数据存储组件。兼具一致性和高可用性特点,etcd 的使用其实非常简单,它对外提供了 gRPC 接口,可以通过 Protobuf 和 gRPC 直接对 etcd 中存储的数据进行管理,也可以使用官方提供的 etcdctl 操作存储的数据。内部采用raft协议作为一致性算法,采用Go语言开发并在ApacheV2协议下授权使用。
Etcd是CoreOS团队于2013年6月发起的开源项目,用于可靠地存储集群的配置数据的一种持久性,轻量型的,高可用的分布式的键-值(key-value)数据存储组件。兼具一致性和高可用性特点,etcd 的使用其实非常简单,它对外提供了 gRPC 接口,可以通过 Protobuf 和 gRPC 直接对 etcd 中存储的数据进行管理,也可以使用官方提供的 etcdctl 操作存储的数据。内部采用raft协议作为一致性算法,采用Go语言开发并在ApacheV2协议下授权使用。A distributed, reliable key-value store for the most critical data of a distributed system.
etcd is a strongly consistent, distributed key-value store that provides a reliable way to store data that needs to be accessed by a distributed system or cluster of machines. It gracefully handles leader elections during network partitions and can tolerate machine failure, even in the leader node.
etcd is written in Go, which has excellent cross-platform support, small binaries and a great community behind it. Communication between etcd machines is handled via the Raft consensus algorithm.
Simple: well-defined, user-facing API (gRPC)
Secure: automatic TLS with optional client cert authentication
Fast: benchmarked 10,000 writes/sec
Reliable: properly distributed using Raft
Etcd 是一个分布式可靠的键值存储系统,提供了与 ZooKeeper 相似的功能,通过 GoLang 开发而非 Java,采用 RAFT 算法而非 PAXOS 算法。相对来说,etcd 的安装使用更加简单有效。主要用于保存一些元数据信息,使用它来存储处理大量的数据就显得不合适了。
简单:安装配置简单,而且提供了HTTP API进行交互,使用也很简单
安全:支持TLS证书验证
快速:根据官方提供的benchmark数据,单实例支持每秒2k+读操作
可靠:采用raft算法,实现分布式系统数据的可用性和一致性
条件
运行的 etcd 集群个数成员为奇数,etcd 是一个 leader-based 分布式系统。确保主节点定期向所有从节点发送心跳,以保持集群稳定。
集群的性能和稳定性对网络和磁盘 IO 非常敏感。任何资源匮乏都会导致心跳超时,从而导致集群的不稳定。不稳定的情况表明没有选出任何主节点。在这种情况下,集群不能对其当前状态进行任何更改,保持稳定的 etcd 集群对 Kubernetes 集群的稳定性至关重要。因此请在专用机器或隔离环境上运行 etcd 集群,以满足所需资源需求,确保不发生资源不足的问题。
etcd 集群可分为单节点和多节点 etcd 集群。为了耐用性和高可用性,在生产中将以多节点集群的方式来运行,并且定期备份。建议在生产中使用五个成员的集群。
etcd 支持内置快照,因此备份 etcd 集群很容易。快照可以从使用 etcdctl snapshot save 命令的活动成员中获取,也可以通过从 etcd 数据目录复制 member/snap/db 文件,该 etcd 数据目录目前没有被 etcd 进程使用。获取快照通常不会影响成员的性能。
安装只需要下载对应的二进制文件,并放到合适的路径就行。etcd目前默认使用2379端口提供HTTP API服务,2380端口和peer通信(这两个端口已经被IANA官方预留给etcd);在之前的版本中可能会分别使用4001和7001,在使用的过程中需要注意这个区别。
从日志的输出中有几个比较重要的信息:
name表示节点名称,默认为default。
data-dir 保存日志和快照的目录,默认为当前工作目录default.etcd/目录下。
在http://localhost:2380和集群中其他节点通信。
在http://localhost:2379提供HTTP API服务,供客户端交互。
heartbeat为100ms,该参数的作用是leader多久发送一次心跳到followers,默认值是100ms。
election为1000ms,该参数的作用是重新投票的超时时间,如果follow在该时间间隔没有收到心跳包,会触发重新投票,默认为1000ms。
snapshot count为10000,该参数的作用是指定有多少事务被提交时,触发截取快照保存到磁盘。
集群和每个节点都会生成一个uuid。
启动的时候会运行raft,选举出leader。
etcd 目前支持 V2 和 V3 两个大版本,这两个版本在实现上有比较大的不同,一方面是对外提供接口的方式,另一方面就是底层的存储引擎,V2 版本的实例是一个纯内存的实现,所有的数据都没有存储在磁盘上,而 V3 版本的实例就支持了数据的持久化。V3 版本中与客户端的通讯,使用 gRPC 替换掉了 HTTP,而服务器各个节点之间的通讯还是使用类似 HTTP 的请求。在 V3 版本的设计中,通过 backend 后端这一设计,很好地封装了存储引擎的实现细节,为上层提供一个更一致的接口。底层默认使用的是开源的嵌入式键值存储数据库 BoltDB,但是这个项目目前的状态已经是归档不再维护了,如果想要使用这个项目可以使用 CoreOS 的 BBolt 版本。etcd V3后端存储采用的是 BBolt 存储引擎,其前身是 Bolt,这是一款 golang 实现的嵌入式 KV 存储引擎,参考的是 LMDB,支持事务、ACID、MVCC、ZeroCopy、BTree等特性。
etcd 和 Zookeeper 在定义上有什么不同:
etcd is a distributed reliable key-value store for the most critical data of a distributed system…
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
其中前者是一个用于存储关键数据的键值存储,后者是一个用于管理配置等信息的中心化服务。解决多个节点数据一致性的方案其实就是共识算法,Zookeeper 使用的 Zab 协议以及常见的共识算法 Paxos 和 Raft,etcd 使用的共识算法就是 Raft。
Raft
PAXOS 算法从 1990 年提出到现在已经有二十几年了,不过其流程过于复杂,目前较多的有 Chubby、libpaxos ,以及 Zookeeper 修改后的 Zookeeper Atomic Broadcase, ZAB 。
Raft 是斯坦福的 Diego Ongaro、John Ousterhout 两人设计的一致性算法,在 2013 年发布了论文 《In Search of an Understandable Consensus Algorithm》,目前已经有近十多种语言的实现,其中使用较多的是 Etcd 。
以下内容摘抄自《高可用分布式存储 etcd 的实现原理》,感谢原作者。
Raft 从一开始就被设计成一个易于理解和实现的共识算法,它在容错和性能上与 Paxos 协议比较类似,区别在于它将分布式一致性的问题分解成了几个子问题,然后一一进行解决。每一个 Raft 集群中都包含多个服务器,在任意时刻,每一台服务器只可能处于 Leader、Follower 以及 Candidate 三种状态;在处于正常的状态时,集群中只会存在一个 Leader,其余的服务器都是 Follower。
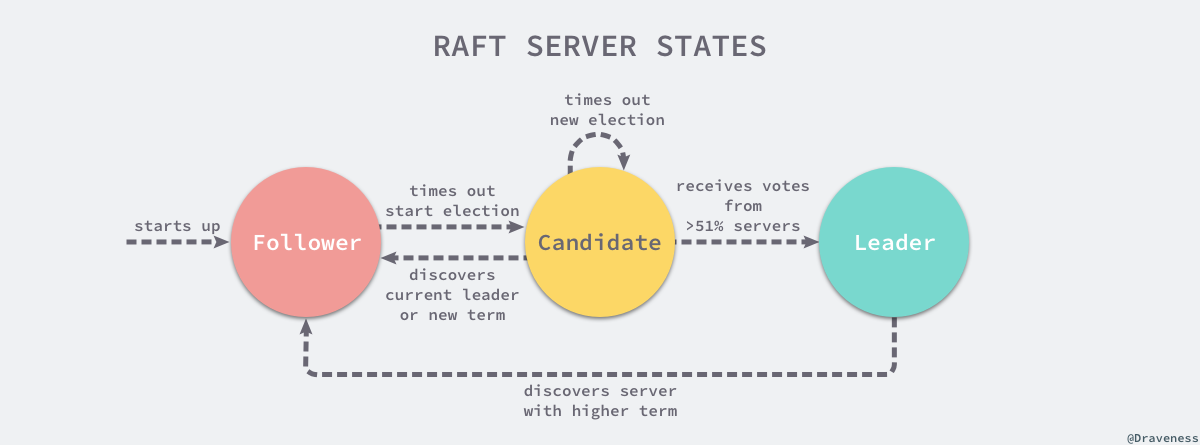
上述图片修改自《In Search of an Understandable Consensus Algorithm》一文 5.1 小结中图四。
所有的 Follower 节点都是被动的,它们不会主动发出任何的请求,只会响应 Leader 和 Candidate 发出的请求,对于每一个用户的可变操作,都会被路由给 Leader 节点进行处理,除了 Leader 和 Follower 节点之外,Candidate 节点其实只是集群运行过程中的一个临时状态。
Raft 集群中的时间也被切分成了不同的几个任期Term,每一个任期都会由 Leader 的选举开始,选举结束后就会进入正常操作的阶段,直到 Leader 节点出现问题才会开始新一轮的选择。
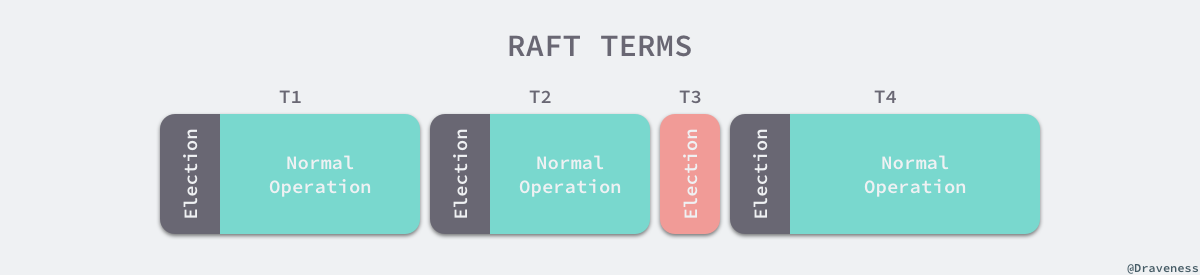
每一个服务器都会存储当前集群的最新任期,它就像是一个单调递增的逻辑时钟,能够同步各个节点之间的状态,当前节点持有的任期会随着每一个请求被传递到其他的节点上。
Raft 协议在每一个任期的开始时都会从一个集群中选出一个节点作为集群的 Leader 节点,这个节点会负责集群中的日志的复制以及管理工作。
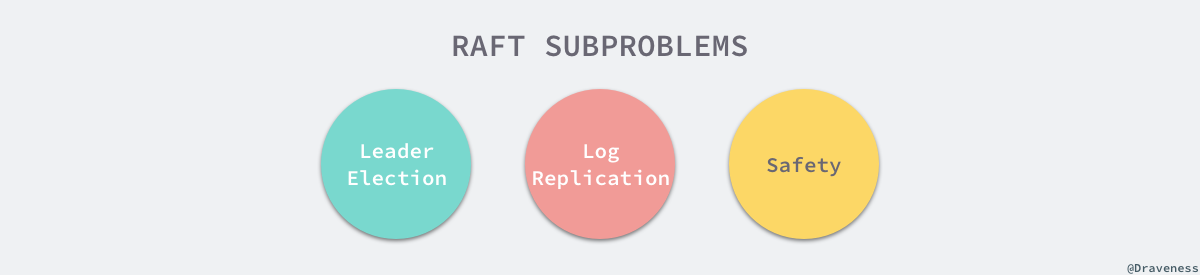
我们将 Raft 协议分成三个子问题:节点选举、日志复制以及安全性,文章会以 etcd 为例介绍 Raft 协议是如何解决这三个子问题的。
节点选举
使用 Raft 协议的 etcd 集群在启动节点时,会遵循 Raft 协议的规则,所有节点一开始都被初始化为 Follower 状态,新加入的节点会在 NewNode 中做一些配置的初始化,包括用于接收各种信息的 Channel。
在做完这些初始化的节点和 Raft 配置的事情之后,就会进入一个由 for 和 select 组成的超大型循环,这个循环会从 Channel 中获取待处理的事件。
作者对整个循环内的代码进行了简化,因为当前只需要关心三个 Channel 中的消息,也就是用于接受其他节点消息的 recvc、用于触发定时任务的 tickc 以及用于暂停当前节点的 stop。
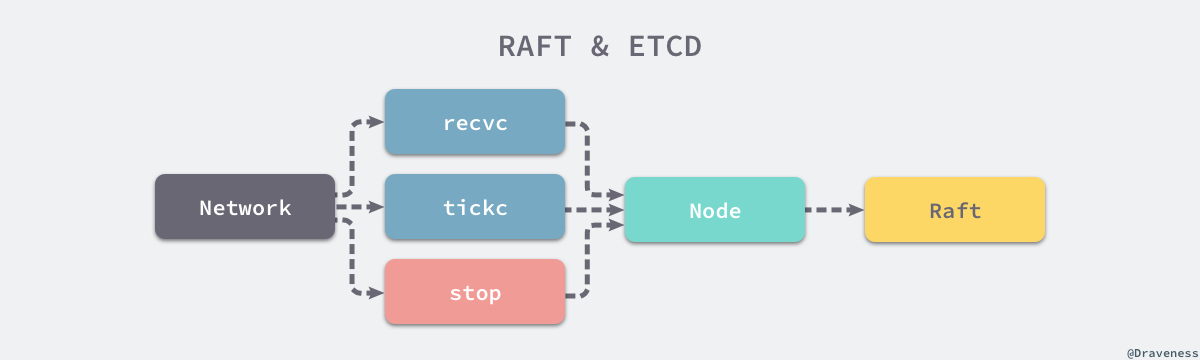
除了 stop Channel 中介绍到的消息之外,recvc 和 tickc 两个 Channel 中介绍到事件时都会交给当前节点持有 Raft 结构体处理。
定时器与心跳
当节点从任意状态包括启动调用 becomeFollower 时,都会将节点的定时器设置为 tickElection。
如果当前节点可以成为 Leader 并且上一次收到 Leader 节点的消息或者心跳已经超过了等待的时间,当前节点就会发送 MsgHup 消息尝试开始新的选举。
但是如果 Leader 节点正常运行,就能够同样通过它的定时器 tickHeartbeat 向所有的 Follower 节点广播心跳请求,也就是 MsgBeat 类型的 RPC 消息。
当 Follower 接受到了来自 Leader 的 RPC 消息 MsgHeartbeat 时,会将当前节点的选举超时时间重置并通过 handleHeartbeat 向 Leader 节点发出响应 —— 通知 Leader 当前节点能够正常运行。
而 Candidate 节点对于 MsgHeartBeat 消息的处理会稍有不同,它会先执行 becomeFollower 设置当前节点和 Raft 协议的配置。
Follower 与 Candidate 会根据节点类型的不同做出不同的响应,两者收到心跳请求时都会重置节点的选举超时时间,不过后者会将节点的状态直接转变成 Follower。
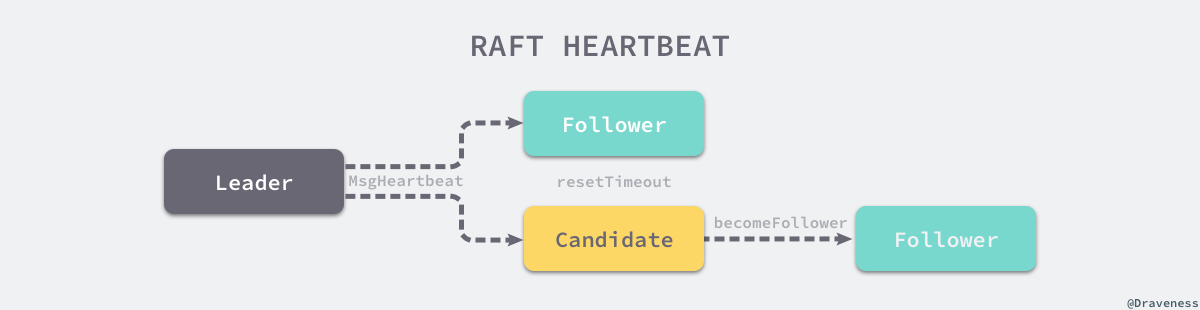
当 Leader 节点收到心跳的响应时就会将对应节点的状态设置为 Active,如果 Follower 节点在一段时间内没有收到来自 Leader 节点的消息就会尝试发起竞选。
到了这里,心跳机制就起到了作用开始发送 MsgHup 尝试重置整个集群中的 Leader 节点,接下来我们就会开始分析 Raft 协议中的竞选流程了。
竞选流程
如果集群中的某一个 Follower 节点长时间内没有收到来自 Leader 的心跳请求,当前节点就会通过 MsgHup 消息进入预选举或者选举的流程。
如果收到 MsgHup 消息的节点不是 Leader 状态,就会根据当前集群的配置选择进入 PreElection 或者 Election 阶段,PreElection 阶段并不会真正增加当前节点的 Term,它的主要作用是得到当前集群能否成功选举出一个 Leader 的答案,如果当前集群中只有两个节点而且没有预选举阶段,那么这两个节点的 Term 会无休止的增加,预选举阶段就是为了解决这一问题而出现的。
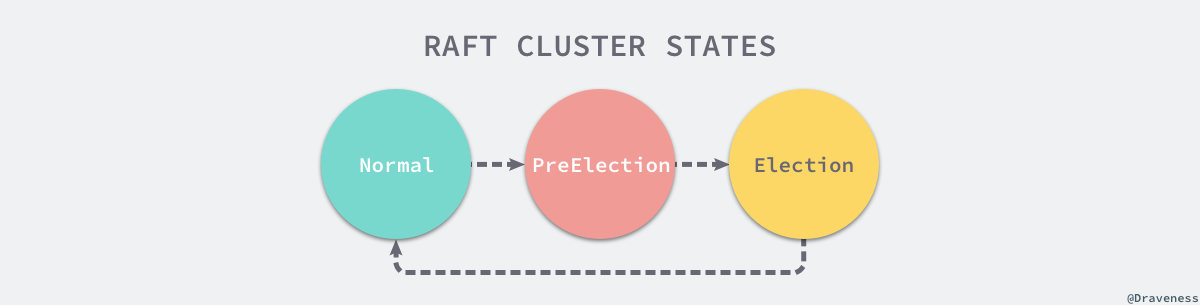
在这里不会讨论预选举的过程,而是将目光主要放在选举阶段,具体了解一下使用 Raft 协议的 etcd 集群是如何从众多节点中选出 Leader 节点的。
当前节点会立刻调用 becomeCandidate 将当前节点的 Raft 状态变成候选人;在这之后,它会将票投给自己,如果当前集群只有一个节点,该节点就会直接成为集群中的 Leader 节点。
如果集群中存在了多个节点,就会向集群中的其他节点发出 MsgVote 消息,请求其他节点投票,在 Step 函数中包含不同状态的节点接收到消息时的响应。
如果当前节点投的票就是消息的来源或者当前节点没有投票也没有 Leader,那么就会向来源的节点投票,否则就会通知该节点当前节点拒绝投票。
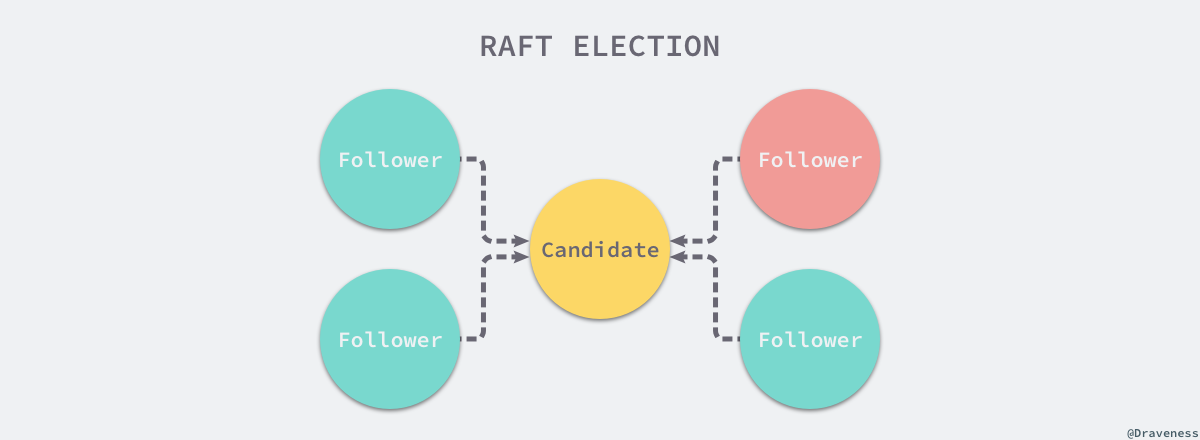
在 stepCandidate 方法中,候选人节点会处理来自其他节点的投票响应消息,也就是 MsgVoteResp。
每当收到一个 MsgVoteResp 类型的消息时,就会设置当前节点持有的 votes 数组,更新其中存储的节点投票状态并返回投『同意』票的人数,如果获得的票数大于法定人数 quorum,当前节点就会成为集群的 Leader 并向其他的节点发送当前节点当选的消息,通知其余节点更新 Raft 结构体中的 Term 等信息。
节点状态
对于每一个节点来说,它们根据不同的节点状态会对网络层发来的消息做出不同的响应,我们会分别介绍下面的四种状态在 Raft 中对于配置和消息究竟是如何处理的。
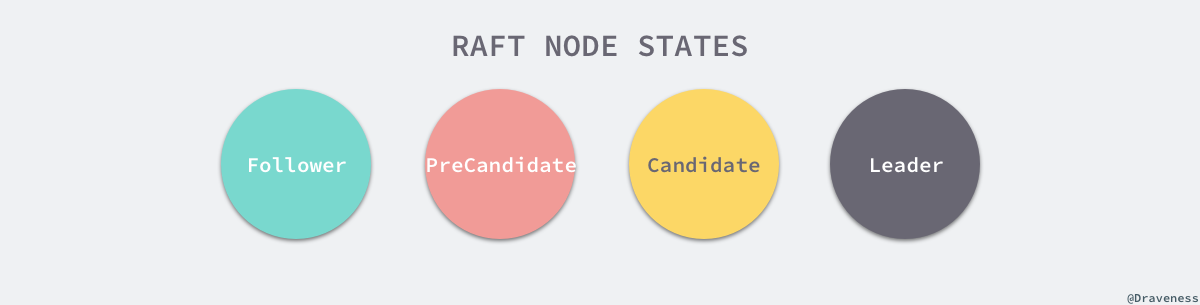
对于每一个 Raft 的节点状态来说,它们分别有三个比较重要的区别,其中一个是在改变状态时调用 becomeLeader、becomeCandidate、becomeFollower 和 becomePreCandidate 方法改变 Raft 状态有比较大的不同,第二是处理消息时调用 stepLeader、stepCandidate 和 stepFollower 时有比较大的不同,最后是几种不同状态的节点具有功能不同的定时任务。
除此之外,它还会设置一个用于在 Leader 节点宕机时触发选举的定时器 tickElection。Candidate 状态的节点与 Follower 的配置差不了太多,只是在消息处理函数 step、任期以及状态上的设置有一些比较小的区别。
应用
在上面已经介绍了核心的 Raft 共识算法以及使用的底层存储,与分布式协调服务 Zookeeper 一样,etcd 在大多数的集群中还是处于比较关键的位置,工程师往往都会使用 etcd 存储集群中的重要数据和元数据,多个节点之间的强一致性以及集群部署的方式赋予了 etcd 集群高可用性。
依然可以使用 etcd 实现微服务架构中的服务发现、发布订阅、分布式锁以及分布式协调等功能,因为虽然它被定义成了一个可靠的分布式键值存储,但是它起到的依然是一个分布式协调服务的作用,这也使我们在需要不同的协调服务中进行权衡和选择。
为什么要在分布式协调服务中选择 etcd 其实是一个比较关键的问题,很多工程师选择 etcd 主要是因为它使用 Go 语言开发、部署简单、社区也比较活跃,但是缺点就在于它相比 Zookeeper 还是一个比较年轻的项目,需要一些时间来成长和稳定。
最新版本:3.4
官方主页:
https://etcd.io/
https://github.com/etcd-io/etcd