Linux块设备BlockSize探究
 在Linux管理中经常碰到“Block Size”。但经常发现此block size非彼block size,意义不相同,大小值也不相同,下面是一些总结。通常Linux的“block size”指的是1024 bytes,Linux用1024 byte blocks 作为buffer cache的基本单位。但linux的文件系统的block确不相同,例如ext3系统,block size是4096。使用tune2fs或dumpe2fs指令能够查看有文件系统的磁盘分区的相关信息,其中就包括了block size。例如:
在Linux管理中经常碰到“Block Size”。但经常发现此block size非彼block size,意义不相同,大小值也不相同,下面是一些总结。通常Linux的“block size”指的是1024 bytes,Linux用1024 byte blocks 作为buffer cache的基本单位。但linux的文件系统的block确不相同,例如ext3系统,block size是4096。使用tune2fs或dumpe2fs指令能够查看有文件系统的磁盘分区的相关信息,其中就包括了block size。例如:# tune2fs -l /dev/sda1 |grep "Block"
Block count:131072
Block size:1024
Blocks per group:8192
其实本来这几个概念不是很难,主要是他们的名字都相同,都叫"Block Size"。
1).硬盘上的 block size, 应该是"Sector size",即通常的扇区大小是512 bytes
2).有文件系统的分区的block size, 是"block size",有时也显示为bsize,大小不一,能够用工具查看
3).没有文件系统的分区的block size,也叫"block size",大小指的是1024 bytes
4).Kernel buffer cache 的block size, 就是"block size",大部分PC是1024
5).磁盘分区的"cylinder size",用fdisk 能够查看,见1中的说明。
来看看fdisk显示的不同的信息,理解一下这几个概念:
Disk /dev/hda: 250.0 GB, 250059350016 bytes
255 heads, 63 sectors/track, 30401 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 1305 10482381 83 Linux
/dev/hda2 1306 1566 2096482+ 82 Linux swap
/dev/hda3 1567 30401 231617137+ 83 Linux
8225280就是cylinder size,一共有30401个cylinder。Start和End分别标记的是各个分区的起始cylinder。第4列显示的就是以1024为单位的block。为什么“2096482+”有个“+”号呢?因为啊,总size除1024除不尽,是个约数,表示2096482强!
块是文件系统的抽象,而非磁盘的属性,一般是 Sector Size 的倍数;扇区大小则是磁盘的物理属性,它是磁盘设备寻址的最小单元。另外内核中要求 Block_Size = Sector_Size * (2的n次方),且 Block_Size <= 内存的 Page_Size (页大小)。
Block与Inode
Unix/Linux下的目录和文档是有权限、属性和本身数据的,一般权限、属性这些元信息都存放在inode中,一个文件就有且一个inode,inode记录文件数据所在block的号码;而文件内的数据信息放置在block中。超级块superblock会记录整个文件系统的整体信息,包括inode与block的总量、使用及剩余量等。找到文档的inode号,就可以找到文档所使用的block,因此inode也是一个索引式文件。
对于inode,
每个 inode 大小均固定为 128 bytes
每个文件都仅会占用一个 inode 而已
文件系统能够建立的档案数量与 inode数量正相关
系统读档案时需要先找到 inode,从 inode 中分析是否有相关的权限
对于block,
连续的八个扇区组成一个block(块)
它是文件的存取的最小单位:512*8=4096bytes=4KiB
访问文件流程
用户访问文件,系统则查找对应的inode信息,根据信息内容,判断是否有权限进行访问,有权限则直接访问到数据块block,无权限则拒绝访问。
来看看这段外文对linux上block size的解析
block size on linux
Theoretically, it could be possible to use any block size. Most devices are using 512-byte blocks, and some of them, particularly large HDDs are using 4096-byte blocks. Some optical media are using 2304byte blocks.
The important thing is: the block device controller doesn't know anything from the filesystem on it. It can only read and write blocks, in its block size, to his medium. This is what the block device driver uses to provide the block device for the kernel: essentially a single, large byte array. It doesn't matter, how is it partitioned or which fs is using it.
The filesystem block size is the block size in which the filesystem data structures are organized in the filesystem. It is the internal feature of the filesystem, there isn't even a requirement to use block-oriented data structures, and some filesystems doesn't even do it.
page size on Intel x86 are 4 KiloBytes aligned i.e.. each page size in memory is of 4KB while for IA-64 they are 8 KiloBytes aligned. And the alignement on disk is of 512 Bytes (on most case where the size of a sector is 512 bytes) its like this because to optimize the loading time or mapping the file to memory.
Ext4 uses most typically 4096byte blocks, Disk in most case where the size of a sector is 512 bytes.
Furthermore, disk IO data is handled typically not directly by the processes, but with the virtual memory of your OS. It uses extensively paging. The VM page size is typically 4096 bytes (might be different on non-x86 CPUs), it is determined by the CPU architecture. (For example, newer amd64 CPUs can handle 2MB pages, or dec alpha used 8192 byte pages).
To optimize the data IO, the best if all of them are the multiply of eachother, yet better if they are equal. This typically means: use 4096 byte fs blocks.
It is also important: if your block device is partitioned, the partitions should begin/end of exact page sizes. If you don't do it, for example your sda1 starts on the 17. block of your sda, the CPU will have to issue TWO read/write commands for all page read/write operations, because the physical and the filesystem blocks will overlap.
In the most common scenario, it means: all partitions should start or begin on a sector divisible by 8 (4096/512 = 8). The page size will likely be a multiple of the block size.
Note, typically the low level block IO happens not in single block read/write operations, instead multiple blocks are sent/received in a single command. And re-organizing data is typically not a very big overhead, because memory IO is typically much faster that block device IO. Thus, not following these won't be a big overhead.
上面的解析没有看明白,没有关系,2022年9月笔者再度从不同方面对Linux下Blocks和Block size的一些解析。
一个字符在不同的编码下占有几个字节,不一样的字符所占的字节数是不一样的。
ASCII码:一个英文字母(不分大小写)占一个字节的位置,一个中文汉字占两个字节的位置。一个二进制数字序列在计算机中作为一个数字单元,一般为8位二进制数,换算为十进制时最小值0,最大值255。一个ASCII码就是一个字节。
UTF-8编码:一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。
Unicode编码:一个英文字符等于两个字节,一个中文(含繁体)等于两个字节。
符号:英文标点占一个字节,中文标点占两个字节。示例:英文句号“.”占1个字节的大小,中文句号“。”占2个字节的大小。
先盘点Linux系统中能获取硬盘和各分区的大小及使用情况的命令。
当然df无出其右
df --total -TH --exclude-type=tmpfs | awk '{print $3}' | tail -n 1
468G
df -k | grep /dev/sda
将为提供大小(KB)以及使用的空间和可用空间。
在ext2+的文件系统上可使用dumpe2fs
dumpe2fs /dev/sdxN|grep '^Free blocks'
或者使用更快tune2fs
tune2fs -l /dev/sdxN|grep '^Free blocks:'
带有-I开关的hdparm显示直接从驱动器请求的标识信息。这包括驱动器的大小以及可能感兴趣的几乎所有内容。要仅显示驱动器的大小,可以使用以下命令:
hdparm -I /dev/sdX | grep "device size"
device size with M = 1024*1024: 1907729 MBytes
device size with M = 1000*1000: 2000398 MBytes (2000 GB)
警告:hdparm需要root用户权限,它是一种潜在的破坏性工具。虽然-I开关使用起来非常安全,但其他开关则不一定。
实际上有多种指令来取的这些信息,但并不是所有这些程序都会默认安装,它们都可以在任何GNU/Linux发行版上轻松使用:
lsblk -do NAME,SIZE /dev/sd?
NAME SIZE
sda 75G
sdb 200G
lsblk --bytes --list
产生信息丰富、无歧义和可解析的输出
lshw | grep -A 15 disk | grep size
size: 465GiB (500GB)
fdisk -l | grep "^Disk /" | gawk '{print $3,$4}'
500.1 GB,
cfdisk /dev/sda
或内置的stat指令
stat -f /dev/sda
File: "/dev/sda"
ID: 0 Namelen: 255 Type: tmpfs
Block size: 4096 Fundamental block size: 4096
Blocks: Total: 2048 Free: 2048 Available: 2048
Inodes: Total: 16384 Free: 16082
从运行时虚拟目录(/proc或/sys)中获取
/sys/block/sda/size
该文件将返回一些数字,如312581808,然后这个数字需要乘以512标准块(standard block size)大小,然后得到以字节为单位的长整型值,视情况转换为GiB或TiB。还有其它方法:
more /proc/partitions
major minor #blocks name
8 0 120627360 sda
8 1 120624021 sda1
8 16 120627360 sdb
blockdev命令查看指定分区的Block Size
blockdev --getbsz /dev/sda6
4096
Linux 中 1 blocks 为多少 kb
block 是块,这个是系统文件系统的最小分配单位,注意是操作系统的,不是硬件的。这个block是看文件系统建立时的设置情况,类似于 Windows 下面所说的簇。是在格式化系统时进行设置,具体多大看文件系统,默认都是 4k 。至少 Ext3 默认是 4k 。而且 block 大小和磁盘最大限制有关系的,如果你用 4k ,ext3 极限最高 16T,也就是 4k x 2^32 ,如果用的是 1k 大小,那么就缩小到了 4T。
在 Linux 系统中一个 block 的默认大小是 512 bytes。
每个文件系统都需要将分区分割成块来存储文件和文件部分;这就是为什么文件系统有不同的块大小,正如在这里看到的:
stat -f /dev/sda1
File: "/dev/sda1"
ID: 0 Namelen: 255 Type: tmpfs
Block size: 4096 Fundamental block size: 4096
Blocks: Total: 128237 Free: 128237 Available: 128237
Inodes: Total: 128237 Free: 127912
stat -f /boot
File: "/boot"
ID: db28d01327503824 Namelen: 255 Type: ext2/ext3
Block size: 1024 Fundamental block size: 1024
Blocks: Total: 198337 Free: 68998 Available: 58758
Inodes: Total: 51200 Free: 50853
1.空闲计数和可用计数之间的差异来自对root用户的保留块。
2.使用env来确保不使用shell的内置stat命令(可能提供或可能不提供所有使用的选项)。
root@crux:/tmp# stat -f .
File: "."
ID: 80200000000 Namelen: 255 Type: xfs
Block size: 4096 Fundamental block size: 4096
Blocks: Total: 4032000 Free: 2003084 Available: 2003084
Inodes: Total: 8069120 Free: 7914521
因此,如果将文件存储在此文件系统中,它将存储在4096字节的块中,即使文件仅包含5字节,它也将从磁盘容量中减去4096字节。
root@crux:/tmp# df .
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/root 16128000 8115664 8012336 51% /
root@crux:/tmp# echo '123' > a.txt
root@crux:/tmp# df .
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/root 16128000 8115688 8012312 51% /
# du -csh a.txt
4.0K a.txt
4.0K total
1. stat命令输出的Blocks单位通常是512 bytes,也就是一个扇区的大小。
2. 一个文件假设只有几个字节,其实也会占用一个文件块(Block size)大小,通常是4096 bytes。
3. 系统通常一次会读取一个Block size大小,而不是一个扇区大小。
stat -f -c %a /var # Find the number of free blocks on /var
stat -f -c %S /var # Determine the block size
因此可以使用自定义的(-c)stat输出格式来获取/上的可用空间(%a):
env stat -f -c %a /
1711744
还是来看df的输出吧
df
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/sda3 1950359084 1333202556 617156528 69% /
1K块的标题行是可用的总空间,以1kB为单位。根据POSIX标准,df应以512字节块为单位报告空间。旧版本的Unix在文件系统中使用512字节的块。
The 1K block in GNU coreutils df(1) means 1024 bytes. Confirmed by taking a quick look at GNU coreutils, version 8.13, source code:
964 if (human_output_opts == -1)
965 {
966 if (posix_format)
967 {
968 human_output_opts = 0;
969 output_block_size = (getenv ("POSIXLY_CORRECT") ? 512 : 1024);
970 }
971 else
972 human_options (getenv ("DF_BLOCK_SIZE"),
973 &human_output_opts, &output_block_size);
974 }
如上所见,GNU的核心工具命令df从8.13开始的默认输出块大小为1024,除非设置了环境变量POSIXLY_CORRECT它才会以512字节为块的基本单位。当然这也只是在显式上的区别而已。
1K-blocks – the size of the filesystem, measured in 1K blocks.
Used – the amount of space used in 1K blocks.
Available – the amount of available space in 1K blocks.
块大小(block size)是文件系统的基本单位,每次读写都以块大小的整数倍来进行。块大小也是文件在磁盘上分配的最小单位。如果块大小为16字节,则16字节的文件刚好占用磁盘上的整个块。
The book "Practical file system design" states:
Block: The smallest unit writable by a disk or file system. Everything a file system does is composed of operations done on blocks. A file system block is always the same size as or larger (in integer multiples) than the disk block size.
Block size on fs refers to mapping disk surface; minor the size of the single block major the number of blocks (and so the elements in the table that keeps information on allocation of files). With stat command:
%b number of blocks allocated (see %B)
%B the size in bytes of each block reported by %b
%s block size (for faster transfers)
file "a.txt" now contains 6 bytes, an "12345" and a newline character.
# stat -c "%b %B %s" a.txt
8 512 4
There are 8 blocks allocated, each block is 512 bytes in size.
这是文件系统跟踪的最小空间量。
sysfs下记录了操作系统所发现设备或分区的大小,如整个硬盘的大小:/sys/block/sda/size
more /sys/class/block/sda/size
This gives you its size in 512-byte blocks.
A block is a sequence of bit or Bytes with a fixed length ie 512 bytes, 4kB, 8kB, 16kB, 32kB etc.
块是具有固定长度的位或字节序列,即512字节、4kB、8kB、16kB、32kB等。
/proc/partitions give similar information in 1K-sized blocks
man excerpt of blockdev
--getsize64 Print device size in bytes.
--getsize Print device size (32-bit!) in sectors. Deprecated in favor of the --getsz option.
--getsz Get size in 512-byte sectors.
blockdev --getsize64=512*(blockdev --getsz)
使用blockdev来获取块设备分区的大小信息
blockdev --getsize64 <dev> returns device size in bytes;
blockdev --getsz <dev> returns device size in 512-bytes sectors;
blockdev --getsize64 /dev/sda returns size in bytes.
blockdev --getsz /dev/sda returns size in 512-byte sectors.
Deprecated: blockdev --getsize /dev/sda returns size in sectors.
Options --getsz and deprecated --getsize are not the same.
BLKSSZGET (blockdev --getss) is for physical sector size and
BLKBSZGET (blockdev --getbsz) is for logical sector size.
取的sda块设备大小
echo $(($(blockdev --getsize64 /dev/sda)/$(blockdev --getss /dev/sda)))
3907029168
调用bc来做计算
echo "`cat /sys/class/block/sda2/size`*512" | bc
如果使用bash或任何其他类似POSIX的shell,其算术运算符可以处理64位整数,甚至不需要调用bc
echo "$((512*$(cat /sys/class/block/sda2/size)))"
以字节为单位给出大小。可以优化cat对fork的调用(bash除外)以兼容ksh93和zsh:
echo "$((512*$(</sys/class/block/sda2/size)))"
$(($(blockdev --getsize64 /dev/sda)/$(blockdev --getss /dev/sda))) = $(blockdev --getsz /dev/sda)
blockdev --getbsz partition
blockdev --getbsz /dev/sda1
4096
So the block size of this file system is 4kB.The ioctl BLKGETSIZE has the same problem as it is in units of 512 rather than BLKSSZGET. BLKGETSIZE64 solves this ambiguity. The real block count is BLKGETSIZE64/BLKSSZGET.
所以该文件系统的块大小是4kB。ioctl BLKGETSIZE与以512为单位而不是以BLKSSZGET为单位存在相同的问题。BLKGETSIZE64解决了这种不确定性。实际块计数为BLKGETSIZE64/BLKSSZGET。
Block size typically refers to File System block size. In General, Linux uses default block size of 4096 bytes (or 4 KB). Even if you create a file with size of just 10 bytes, it occupies 1 block aka 4096-byte block.
块大小通常指文件系统块大小。通常Linux使用默认块大小4096字节(或4KB)。即使创建一个大小仅为10字节的文件,它也会占用一个块,即4096字节块。
Linux内核对待分区与扇区大小字节
size of linux kernel partition sector size
扇区的信息在block/stat.txt文档中定义。
With the patch:
diff --git a/Documentation/ABI/testing/sysfs-block
+What: /sys/block/<disk>/<partition>/size
+Date: October 2002
+Contact: linux-block@vger.kernel.org
+Kernel Version: 2.5.43
+Description:
+ Size of the partition in standard UNIX 512-byte sectors
+ (not a device-specific block size).
从Linux源代码注释可知:Linux总是认为扇区长度为512字节,与设备的实际块大小无关。
开发者视角查询块设备大小
No need for ioctl in C. Just seek to the end of the file and get the size (in bytes) that way:
/* define this before any #includes when dealing with large files: */
#define _FILE_OFFSET_BITS 64
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
// ...
int fd = open("/dev/sda", O_RDONLY);
off_t size = lseek(fd, 0, SEEK_END);
// Now size is the size of the file, in bytes, or -1 on error.
// lseek(fd, 0, SEEK_SET) to get back to the start of the file.
参考链接:
Gnu-coreutils-Block-size
determine-the-size-of-a-block-device
file-block-size-difference-between-stat-and-ls
计算机网络知识全介绍
顺带说一下块设备的存储系统分层模型(转自数形演绎的究竟,感谢原作者)
计算机存储系统实际上可以认为只有两层,底层是块设备,一块连续的存储空间,如一块硬盘或一个分区;上层是文件系统,管理经典的目录树结构。
1、块设备层:化整为零,化零为整
存储系统的最底层是物理硬盘,但操作系统并不直接与闪存颗粒或磁道扇区打交道,而是通过ATA和SCSI协议来访问硬盘,再给出“块设备”这个抽象接口。
块设备将存储介质抽象为一个可以按固定大小块(如512字节、4K)随机读写的线性空间。我们常见的 /dev/sda、/dev/nvme0n1 就是硬盘本身的块设备文件。然而,直接使用整块硬盘非常不灵活,根据不同的用途,需要将硬盘先切为几块再用。
分区表定义了如何将一块物理硬盘划分为多个独立的分区(又称为卷 Volume,如 /dev/sda1),从而实现了在同一块硬件上隔离不同用途的数据,比如分开操作系统和用户文件。MBR是DOS时代遗留下来的分区表格式,只支持4个主分区、最大2TB,现在一般用GPT分区表格式替代了。
分区依然受限于单块物理硬盘的边界,且不易扩展和调整。如果硬盘空间耗尽,扩展分区往往需要停机、备份数据,耗时耗力地重新划分分区。
逻辑卷管理器(LVM)的引入突破了这一限制。LVM对硬盘做了二次抽象:先将普通分区格式化为“物理卷(PV)”,然后聚合成“卷组(VG)”,最后从卷组中按需切分出灵活的“逻辑卷(LV)”。物理卷(PV)就类似分区表,卷组(VG)类似新组建了一块大硬盘,在其上划分了多个分区,就是逻辑卷(LV),逻辑卷呈现为一个块设备。逻辑卷可以动态扩容、缩小,甚至跨越多块物理硬盘,极大地提升了存储管理的灵活性。
为提高性能、解决容量限制,将多块硬盘拼成一块,就必须考虑单块硬盘寿命的影响。独立磁盘冗余阵列(RAID)通过将数据以特定方式分布到多块硬盘上,实现了数据冗余(如RAID 1/5/6)或性能提升(如RAID 0)。在Linux上,可以在不同层面实现:可以通过专用的物理阵列卡或磁盘阵列服务器接入,直接显示为一整块“物理硬盘”;也可以通过mdadm工具创建RAID块设备,作为一块逻辑硬盘;还可以用LVM,创建RAID类型的逻辑卷LV,作为一个分区。
为了将存储设备和计算设备分离,iSCSI和网络块设备(NBD)可以通过网络,拉一根数据线,将远程的储存空间作为本地硬盘来使用。iSCSI是一个功能完备、兼容广泛的标准协议,很多NAS和磁盘阵列服务器都支持将虚拟卷映射到iSCSI端口。NBD是Linux上原生的块设备共享协议,安装和配置相对简单。
Linux 内核通过 /dev 下统一的设备文件给出这些块设备的接口,并自动处理分区表,将分区表中包含的分区也作为独立的块设备。例如 /dev/sda 是一整块硬盘,/dev/sda1 是这块硬盘的第一个分区。实际操作中,可以用 /dev/disk/by-id 或 /dev/disk/by-uuid 下的链接指代硬盘或分区,能防止插拔后编号变动带来不便。这个统一的块设备层,是上层文件系统无需关心硬件实现的前提。
2、文件系统层:功能、性能、稳定性的权衡
文件系统是非常复杂的组件。在熟悉的目录树结构下,文件系统不仅要高性能地实现读写,还要管理各种文件属性,实现并发控制,用日志保证完整性等。Linux 下的文件系统,每种都在根据它的适应场景迭代升级。
ext4 是 Linux 上最广泛使用的文件系统,稳定、高效、易用。XFS 与 ext4 在功能和性能上比肩,能支持更大的文件和高并发 IO。考虑到 ext4 支持缩小,第三方支持(数据恢复工具)更完善,一般情况下还是建议直接使用默认的 ext4。
Btrfs 的写时复制(COW)和快照功能在数据备份场景下非常友好,包括很多高级特性,如数据压缩、完整性检查、子卷、去重等,原先被认为是 ext4 的继任者。然而这个文件系统长年被“不稳定”的阴影笼罩,且性能明显落后于其他文件系统,所以目前基本上只在数据备份、扩展存储(NAS)领域得到广泛应用。Btrfs 也计划支持多盘阵列,但相关功能还有很多严重问题未修复。
与 Btrfs 并列的 ZFS 支持类似的功能,其稳定性得到了广泛的验证,且支持文件系统级别的多磁盘管理,实现类似 RAID 的数据冗余机制。其问题在于许可证限制不能包含在 Linux 内核内,升级维护成本较高。
除了管理本地块设备,文件系统的概念还可以通过网络延伸。NFS和SMB/CIFS 是两种主流的网络文件系统协议,它们允许客户端像访问本地目录一样访问远程服务器共享的文件。这种抽象简化了文件共享,但引入了更多不确定因素,如难以确保各客户端的一致性;当网络不稳定时,极易引发读写文件时进程挂起。
为了在用户空间灵活实现各种文件系统,Linux 提供了 FUSE 框架,它使得开发者无需修改内核就能创建新的文件系统。例如 sshfs,可以直接用 ssh 协议挂载远程主机上的文件夹。在FUSE框架下,可以用各种语言无限制地实现功能,显然性能、稳定性就得不到保证了。
各种文件系统的共同点是提供给上层统一的目录树接口,区别就在于如何有效利用底层块存储或网络,实现各自的特色功能。
3、具体场景下的选型
面对千变万化的存储需求,Linux强大的存储分层模型提供了灵活的组合方案,其核心在于理解每一层抽象解决的问题,并基于具体场景匹配最合适的层级和技术。
对于配置固定、用途明确且无需后续扩展的单机系统(如嵌入式设备、特定用途服务器),可以直接使用分区表分区。如将硬盘直接分为系统根目录和 Swap 交换分区(即虚拟内存),系统分区格式化为 ext4。
云上虚拟机,或高配置台式机的存储需求可能会经常增长。这时,可以用 LVM 管理分区。当单个 LV 空间不足时,管理员可以在线增减分区,或在线扩展其所属 VG 的容量(添加新云盘或扩展现有云盘),然后无缝扩展 LV 及其上的文件系统。整个过程通常无需停机,也避免了传统分区方案中需要备份数据、移动分区的繁琐和风险。
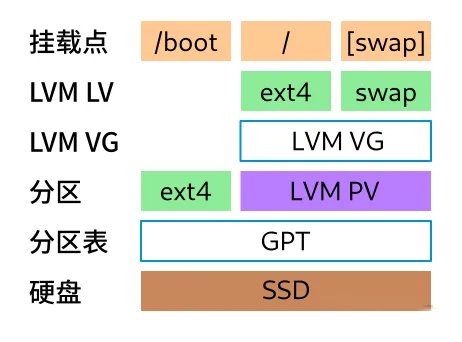
(图:使用LVM的典型Linux分区方案)
用固态硬盘加速大容量机械硬盘是一个常见需求。稳定可靠的做法是通过 LVM 的缓存机制,将固态硬盘和机械硬盘放入同一个 VG 卷组,在机械硬盘上先创建主数据分区,再在固态硬盘上附加缓存分区。
lvcreate --type cache --cachemode writeback -L <大小> -n <名称> <vg/pv> </dev/SSD的PV分区>
同时使用多块硬盘扩展容量时,必须考虑可用性的保证。由于现代硬盘容量非常大,恢复时的大量读写容易导致相似寿命的第二块硬盘提前损坏,大于三块硬盘时应避免使用 RAID5,可以直接在 RAID10(性能)和 RAID6(安全性)中选择。Linux 上有多种实现途径:一种是用 mdadm 直接管理软件阵列,将硬盘组合为一块逻辑硬盘;一种是用 LVM 创建 raid 类型的 LV 逻辑分区;一种是用 ZFS 管理多块硬盘,创建 raidz2 模式的 zpool 存储池。
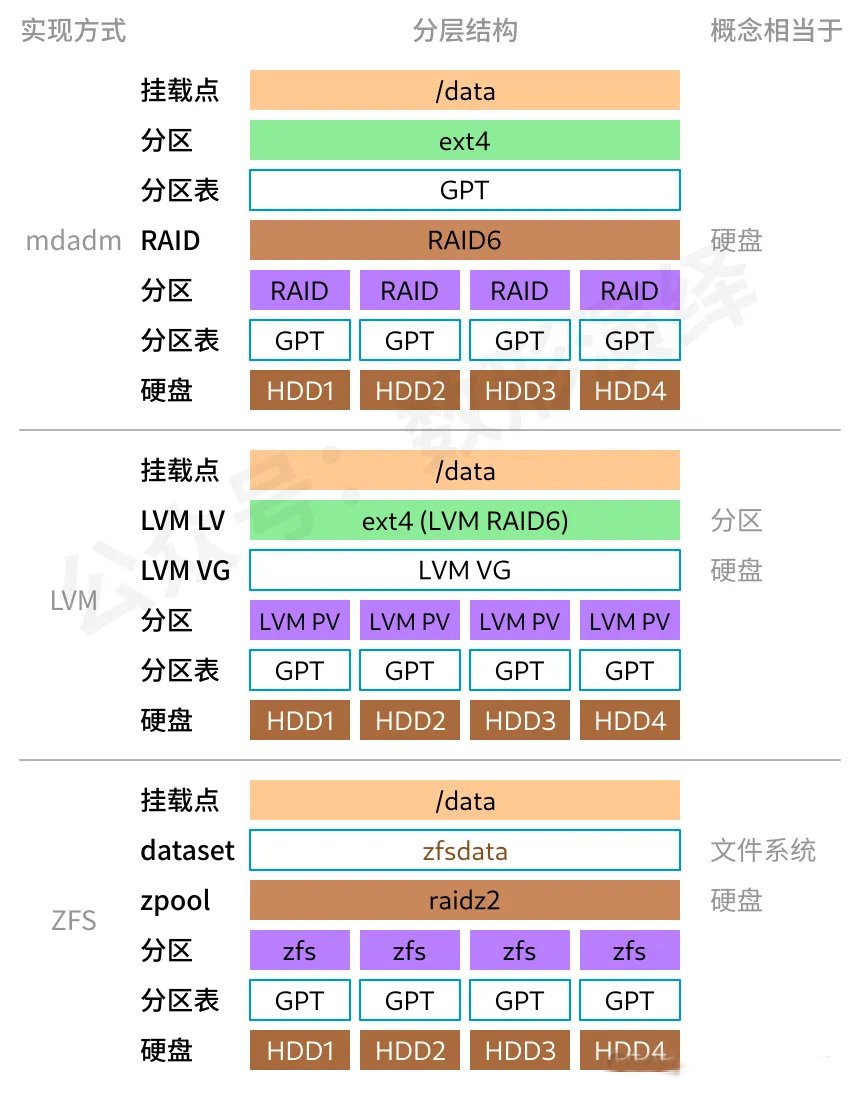
(图:三种RAID6的实现方式)
需要注意的是,在上述硬盘阵列的实现过程中,实际上既可以直接在硬盘块设备上操作,也可以在分区块设备上操作。为了防止第三方软件和系统误认为硬盘上没有数据,应先创建GPT分区表,在分区上创建RAID阵列、PV物理卷或ZFS文件系统。
在网络存储中,应优先选择块设备(iSCSI/NBD)的方式共享存储,性能损耗小。其次,接口简洁的对象存储接口(如S3)也要比NFS/SMB更适用于现代应用,减少了网络波动、锁机制问题的影响范围。
处理海量小文件(如小图片、JSON/XML)的场景已经不适合使用文件系统。这类场景下,文件系统元数据操作是很大的瓶颈。此时可直接将数据存储在数据库中(如 SQLite, PostgreSQL),便于查找和事务管理,也减少了读写开销。
数据库(如PostgreSQL)的存储机制与Linux存储系统的分层模型也可以类比。数据库的表数据最终以物理文件形式存储在磁盘上,这些文件就如同块设备,用分页结构管理线性存储空间;而表的逻辑结构(字段定义)则类似文件系统的目录树,为用户提供了结构化的访问接口。用户通过SQL语句操作表时无需关心底层文件的存储细节,正如操作目录树时,文件系统屏蔽了块设备的物理地址和访问模式。
这种分层设计的核心价值在于显著提升了存储系统的可扩展性与灵活性,每一层都专注解决特定问题。块设备层通过分区、RAID等技术实现存储资源的隔离与聚合,文件系统层则通过不同的格式满足性能、功能或稳定性需求,各层独立迭代又可灵活组合,让存储方案能适配从嵌入式设备到分布式集群的各种场景。
提高存储性能本质上是减少不必要的读写开销:例如ext4的数据结构比Btrfs更简单,所以元数据操作性能更优;iSCSI/NBD作为块设备共享时,相比NFS/SMB等网络文件系统,减少了协议层的复杂交互,上层文件系统合并了区块的读写,从而降低了读写延迟。
可维护性则依赖于对成熟技术的选择,选择成熟、稳定且运维团队熟悉的技术栈,能大幅降低故障排查与日常运维的复杂度,让存储系统在灵活扩展的同时保持可靠与可控。因此在实践中,理解分层模型、明晰每层技术解决的问题及其接口,并基于具体场景做出平衡和务实的选择,是构建可靠、高效存储系统的关键。