关于inode
 您是否曾经对一些 UNIX 命令(如df)中的 Iused 和 %Iused 的含义感到困惑,或者当人们讨论 inode 的时候不知所云?UNIX 和 Linux 系统都使用了inode 。下文将向您介绍什么是 inode 、为什么对于Unix/Linux来说 inode 非常重要、inode 的结构,以及操作 inode 的命令。
您是否曾经对一些 UNIX 命令(如df)中的 Iused 和 %Iused 的含义感到困惑,或者当人们讨论 inode 的时候不知所云?UNIX 和 Linux 系统都使用了inode 。下文将向您介绍什么是 inode 、为什么对于Unix/Linux来说 inode 非常重要、inode 的结构,以及操作 inode 的命令。 inode 是 UNIX 操作系统中的一种数据结构,它包含了与文件系统中各个文件相关的一些重要信息。在Unix/Linux中创建文件系统时,同时将会创建大量的 inode ,通常文件系统磁盘空间中大约百分之一的空间分配给了 inode 表。人们使用了一些不同的术语,如 inode 和索引编号 (inumber)。这两个术语非常相似,并且相互关联,但它们所指的并不是同样的概念。inode 指的是数据结构,而索引编号实际上是 inode 的标识编号,因此也称其为 inode 编号或者索引编号。索引编号只是文件相关信息中一项重要的内容,下面将介绍 inode 中的其他一些属性。
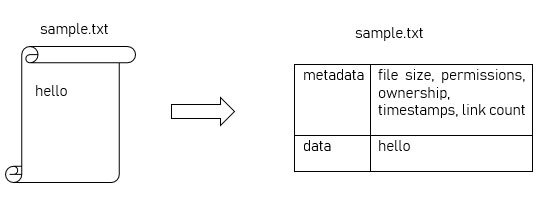
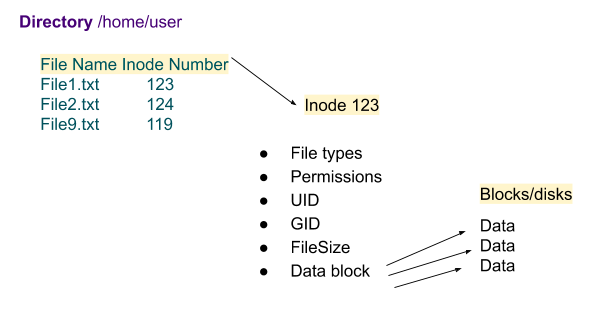
在Unix/Linux系统中,表面上用户通过文件名来操作文件,实际上系统内部将这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。储存文件元信息(文件的创建者、文件的创建日期、文件的大小等)的区域就叫做inode,中文译名为"索引节点"。inode 表包含一份清单,其中列出了对应文件系统的所有 inode 编号。当用户搜索或者访问一个文件时,操作系统通过 inode 表查找正确的 inode 编号。在找到 inode 编号之后,相关的命令才可以访问该 inode,并对其进行适当的更改。例如,使用 vi 来编辑一个文件。当键入 vi
先来复习一下硬盘的结构
硬盘的最基本的组成是有金属材料制成的涂以磁性介质的盘面,不同容量的磁盘的盘面数不同,每个盘面有正反两面,都可以记录信息。盘片被分成许多扇形的区域,每个区域叫做一个扇区(sector),每个扇区可存储128x2的N次方的字节信息。在DOS中每个扇区是128x2的2次方=512个字节(sector size)。
盘片表面以片面的中心为圆心,不同半径的同心圆称作磁道。
不同盘面的相同半径的磁道所组成的圆柱称为柱面(cylinder)。
每个磁盘有两面,每面都有一个磁头(head)。
因此磁盘的存储容量的计算公式:磁头数(heads,多少个盘面) * 柱面(cylinders,每个盘面多少个磁道) * 每道扇区数(sectors) * 每个扇区字节数(sector size)
磁盘上的每个磁道被等分为若干个弧段,这些弧段便是磁盘的扇区,每个扇区可以存放512个字节的信息,磁盘驱动器在向磁盘读取和写入数据时,要以扇区为单位。
硬盘通常由重叠的一组盘片构成,每个盘面都被划分为数目相等的磁道,并从外缘的"0"开始编号,从图2这张放大的硬盘结构图我们可以看出,具有相同编号的磁道形成一个圆柱,称之为磁盘的柱面。磁盘的柱面数与一个盘面上的磁道数是相等的。由于每个盘面都有自己的磁头,因此,盘面数等于总的磁头数。所谓硬盘的CHS,即Cylinder(柱面)、Head(磁头)、Sector(扇区),只要知道了硬盘的CHS的数目,即可确定硬盘的容量,硬盘的容量=柱面数x磁头数x扇区数x512B。
簇(cluster)或块(block)是操作系统中的文件系统层的概念:我们知道磁盘是由一个一个扇区组成的,若干个扇区合为一个簇,文件存取是以簇为单位的,哪怕这个文件只有1个字节。每个簇在文件分配表中都有对应的表项,簇号即为表项号,每个表项占1.5个字节(磁盘空间在10MB以下)或2个字节(磁盘空间在10MB以上)。
每个磁道上的扇区数目是一样的么
早期的磁盘每个磁道上的扇区数目是一样,限制了磁盘的容量;后来为了增大磁盘容量采用了新技术,也就是说越往外每磁道扇区数目越多。早期的硬盘是每个磁道有相同的扇区,但是现在的硬盘采用线性寻址,所以每个磁道上扇区数不一样,外面的多,里面的少。光盘跟硬盘差不多,但是用螺线的,不像硬盘采用同心圆。不过还是可以用CHS(柱面,磁道,扇区)的方式来定位,因为IDE磁盘做了内部转换,让你看起来好像每条磁道上面的簇数量都是一样的。
0磁道是在磁盘的外圈还是内圈
由于历史原因,磁盘的0磁道在最外圈(过去的老式硬盘,每条磁道上的簇的数量都是一样多的。也就是说最里面和最外面的磁道的簇的数目是一样的。显然,磁密度越低,数据的安全越有保障。而MBR放在0柱面的,第0个磁道的,第1个簇上面,为了这个关键数据的安全,所以磁道要从最外开始安排。)但光盘的0磁道和磁盘,软盘刚好向盘,光盘的0磁道是在最内圈的。尽管扇区是能独立寻址的最小单位,但资源分配的最小单位是簇(簇为Windows的叫法,Linux为Block,但本质和表现是一样的:文件系统层面上最小分配单位)。所以文件的大小和文件所占用的磁盘空间是不同的,所占用的磁盘空间往往多于文件的大小,这是必要且不得不的'浪费'。
硬盘簇的大小设为多少才合适
默认的情况下,在格式化的时侯如果没有指定簇的大小,那么系统会根据分区的大小选择默认的簇值;其实在文件系统中格式化的时候,可以在“Format”命令后面添加“/a:UnitSize”参数来指定簇的大小,UnitSize表示簇大小的值,支持512/1024/2048/4096/8192/16K/32K/64KB。簇的大小会影响到磁盘文件的排列,设置适当的簇大小可以减少磁盘空间丢失和分区上碎片的数量。如果簇设置过大,会减少到磁盘存储效率,但会提高IO效率;反之如果设置过小,虽然会提高利用效率,但是会产生大量磁盘碎片。
inode 的结构
对于经验丰富的 UNIX 开发人员或者管理员来说,inode 的结构相对比较简单,但是可能还有一些您尚不了解的、令人惊讶的有关 inode 的内幕。下面的定义仅给出了 inode 中所包含的、UNIX 用户经常使用的一些重要信息:
* inode 编号
* 用来识别文件类型,以及用于 stat C 函数的模式信息
* 文件的链接数目(指向这个inode)
* 属主的 UID
* 属主的组 ID (GID)
* 文件的字节大小
* 文件所使用的磁盘块的实际数目
* 文件的三个时间戳:最近一次(打开)访问的时间(atime)、最近一次(内容)修改的时间(mtime)、最近一次(属性)更改的时间(ctime)
* 文件的读、写、执行权限
* 文件数据block的位置
从根本上讲,inode 中包含有关文件的所有信息(除了文件的实际名称以及实际数据内容之外)。
以上所列举的信息对于文件来说非常重要,并且在 UNIX 中频繁使用;如果没有这些信息,那么文件将被认为遭到破坏和不可用。
与其他的操作系统相比,UNIX 系统中的目录和文件可能看起来有所不同,但事实并非如此。在 UNIX 中,目录本身就是文件,只是在它们的 inode 中使用了一些附加的设置。目录本质上就是一个包含了其他文件的文件。另外其模式信息中设置了一些相应的标志,以告知系统该文件实际上是一个目录。
使用 inode
了解如何在 UNIX 中使用 inode 可以节约大量的时间,并提高工作效率。在尚未了解 inode 之前,可以使用下面的命令,以减少可能碰到的问题。在Linux下一个文件具有一个Inode号,一个Inode号对应着至少一个block块,bolck是访问文件内容的结构,文件block块的个数和文件的大小有关,并且在Linux系统下,block块的大小是固定的。
df 命令
如前所述,当您在 UNIX 中创建一个文件系统时,将为 inode 表分配大约百分之一的总磁盘空间。每次在文件系统中创建一个文件时,都会为该文件分配一个 inode 。通常与一个文件系统相关联的 inode 的数目足够多,但耗尽 inode 的可能性始终存在。要监视是否发生了这种情况,可以观察 df 的输出。
使用 df 命令可以查看所有已挂载的文件系统或者特定的文件系统。在该命令的输出中,可以查看各个文件系统中已使用的 inode 的数目,以及文件系统中总体使用情况百分比,如清单 1 中所示。
清单1. 使用 df 来监视 inode 的使用
# df -k|head -6
Filesystem 1024-blocks Free %Used Iused %Iused Mounted on
/dev/hd4 229376 138436 40% 4730 13% /
/dev/hd2 8028160 962692 89% 110034 33% /usr
/dev/hd9var 1835008 366400 81% 25829 24% /var
/dev/hd3 524288 523564 1% 98 1% /tmp
/dev/hd1 32768 32416 2% 5 1% /home
如果由于某种原因,某个文件系统 inode 的使用率达到百分之百,那么您将无法在该文件系统中创建更多的文件、设备、目录等等。对于这种情况,一种解决方案是通过 smitty chfs 命令为该文件系统添加更多的空间,另一种解决方案是创建较小的 inode 区段。现在,在增强的日志文件系统 (Enhanced Journal File System) 中,IBM AIX 5L 允许 inode 区段小于 16KB 的缺省大小。
istat 和 stat
在 AIX 中检查 inode 的一种快捷的方式是使用 istat 命令。使用这个命令,您可以找到特定文件的索引编号,以及其他的 inode 项目,如权限、文件类型、UID、GID、链接的数目(非符号链接)、文件大小和最近一次更新、最近一次修改以及最近一次访问的时间戳。
清单2 显示了 AIX 中文件 /usr/bin/ksh 的 inode 信息。
清单2. /usr/bin/ksh 的 inode 信息
# istat /usr/bin/ksh
Inode 18150 on device 10/8 File
Protection: r-xr-xr-x
Owner: 2(bin) Group: 2(bin)
Link count: 5 Length 237804 bytes
Last updated: Wed Oct 24 17:37:10 EDT 2007
Last modified: Wed Apr 18 23:58:06 EDT 2007
Last accessed: Mon Apr 28 11:25:35 EDT 2008
除了显示来自 istat 的标准信息之外,现在您还知道了 /usr/bin/ksh 对应的索引编号。如果您同时还找到了该文件所处的逻辑卷,那么甚至可以显示更多的信息。要查找该信息,一种方式是通过使用 df 命令来查看该文件位于哪个已挂载的文件系统中:
# df /usr/bin
Filesystem 512-blocks Free %Used Iused %Iused Mounted on
/dev/hd2 16056320 1925384 89% 110034 33% /usr
文件 /usr/bin/ksh 位于目录 /usr/bin 中。查看 df 命令的输出,您可以发现,目录 /usr/bin 包含于 /usr 文件系统中,并且 /usr 文件系统位于逻辑卷 /dev/hd2 之中。现在已经知道了索引编号和逻辑卷的名称,那么就可以将这两个信息项作为参数来使用 istat,这样一来便可以确定组成该文件的磁盘块的十六进制地址,如清单 3 中所示。
清单3. 确定文件磁盘块的十六进制地址
# istat 18150 /dev/hd2
Inode 18150 on device 10/8 File
Protection: r-xr-xr-x
Owner: 2(bin) Group: 2(bin)
Link count: 5 Length 237804 bytes
Last updated: Wed Oct 24 17:37:10 EDT 2007
Last modified: Wed Apr 18 23:58:06 EDT 2007
Last accessed: Mon Apr 28 11:44:20 EDT 2008
Block pointers (hexadecimal):
11620 ef8c0
Linux 提供了其特有的 istat 版本:stat。Linux stat 命令可以显示类似的信息,并且还包括一些在 AIX istat 命令中没有提供的命令开关:
# stat /bin/bash
File: `/bin/bash'
Size: 722684 Blocks: 1432 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 12799859 Links: 1
Access: (0755/-rwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2008-04-06 19:13:50.000000000 -0400
Modify: 2006-07-12 03:11:53.000000000 -0400
Change: 2007-11-22 04:05:30.000000000 -0500
stat 命令可以查看文件的详细信息,包括
size:文件大小(单位为字节)
blocks:占用块数,此处的8不是指文件系统块,此处的块应该是指sector(扇区,512Byte),8Blocks相当于文件系统中的1Block(4096Byte)
IO Block: 文件系统中块的大小
regular file:文件类型
Access:文件权限
Uid:文件所有者
Gid:文件组
atime:最后访问时间
mtime:最后修改时间(ls -l中显示的时间)
ctime:最后状态改变时间
另外,stat -f 查看文件系统的信息。
ls 命令
在您的日常工作中总会碰到这样的情况,难以删除或者管理某些文件,因为这些文件的文件名中使用了短横线或者其他特殊字符、或者其文件名完全不正确。这很可能是有人对该文件进行了错误命名。
因为 UNIX 中的大多数命令,包括开关或者选项在内,都是以连字符 (-) 或者双连字符 (--) 开头的,很难使用诸如 rm、mv 和 cp 之类常用的命令来操作这些文件。幸运的是,某些命令提供了一些选项,以用来显示相关文件所关联的 inode 的索引编号。ls 命令就提供了一个这样的选项:
# ls
- -- -p fileA fileB fileC fileD
fileE fileF fileG fileH fileI fileJ fileK fileL
使用 ls -i 命令,您可以看到文件名称旁边的索引编号,如清单 4 中所示。现在,您已经知道了文件的索引编号,那么就可以很容易地操作该文件了。
清单4. 查看文件的索引编号
# ls –i
38988 38991 -p 38984 fileC 38982 fileF 38977 fileI 38978 fileL
38989 - 38980 fileA 38986 fileD 38983 fileG 38987 fileJ
38990 -- 38979 fileB 38976 fileE 38985 fileH 38981 fileK
find 命令
使用 UNIX find 命令,您可以完成使用 ls 命令所开始的工作。对于要进行操作的文件,您已经知道了它们的索引编号,那么就可以开始进行相应的操作了。要删除看似无名的文件,只需要使用 find 和 -inum 开关对索引编号和文件进行定位。然后在找到该文件之后,使用 find 和 -exec 开关删除该文件:
# find . -inum 38988 -exec rm {} \;
要对该文件进行重命名,可以再次进行相同的操作,但这一次使用 mv 而不是 rm:
# find . -inum 38989 -exec mv {} fileM \;
为了验证取得了预期的结果,只需要再次使用 ls -i 命令:
# ls -i
38990 -- 38979 fileB 38976 fileE 38985 fileH 38981 fileK
38991 -p 38984 fileC 38982 fileF 38977 fileI 38978 fileL
38980 fileA 38986 fileD 38983 fileG 38987 fileJ 38989 fileM
对于那些不能通过rm filename直接删除的文件,如文件名为“--file”,可以借助inode号将其删除,当然也可以用rm --file或者rm ./--file的方式。
fsck 命令
不幸的是,硬件设备不可能一直使用下去,系统可能会在使用多年后出现故障。当发生这种情况,以及由于电源故障或者某些其他问题而导致操作系统异常关闭的时候,您可能会在还原系统备份时碰到一些在崩溃期间处于打开状态的文件,并且现在需要对其加以处理。此时,您可能会碰到一些需要修复 inode 或者存在错误的消息。如果发生这种状况,那么 fsck 命令可以用来救急!您可以使用 fsck 来修复文件系统或者修正受损的 inode,而不是还原系统、或者甚至重新构建操作系统。下面的命令可以尝试修复逻辑卷 /dev/hd1:
# fsck –p /dev/hd1 –y
通过使用 fsck 命令,您还可以缩小受损 inode 的搜索范围。如果正在搜索一个特定的 inode,那么可以使用带 -ii-NodeNumber 开关的 fsck 命令。
可以用命令:dumpe2fs -h /dev/hda | grep "Inode size" 来查看文件分区的i节点信息。
inode与block
inode
Inode也会消耗硬盘空间,所以硬盘格式化时,操作系统自动将文件分成两个区域。一个是数据区,用于存放文件数据;另一个是inode区,用于存放inode所包含的信息。
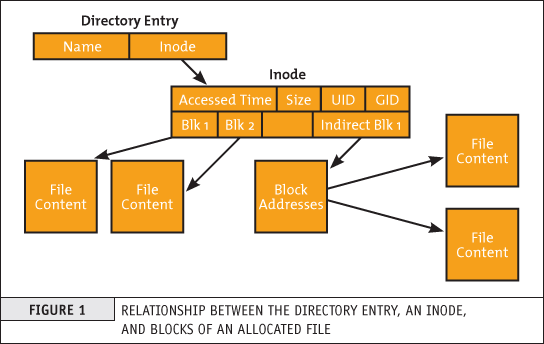
每个inode节点的大小一般是128字节或256字节。Inode节点的总数在格式化时就给定,一般是1KB或2KB或4KB就设置一个inode。如果一块1GB的硬盘,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode区的大小就会达到128MB,占整个硬盘的12.8%(所以block可以设置的大一点)。每个inode都有一个号码,操作系统用inode号来识别不同的文件。
Unix/Linux系统内部不是用文件名,而使用inode号来识别文件。对于系统来说,文件名只是iode号便于识别的别名。表面上用户是通过文件名打开文件,实际上系统内部分成三个步骤:首先,系统找到这个文件名对应的inode号;其次通过inode号获取inode信息;最后根据inode信息找到文件数据所在的block,读出数据。可以使用指令'ls -i [filename]'快速查看文件的inode号。
在Unix/Liunx系统中,目录也是一种文件。目录文件的结构非常简单,即使一系列目录项的列表。每个目录项由所包含文件的文件名以及该文件名对应的inode号组成。可以使用'ls -id [directory]'快速查看目录的inode号:
# ls -id /etc
16777281 /etc
另外可以使用'df -i'查看每个磁盘分区的inode总数和已经使用的数量。
注意:由于每个文件都必须有一个inode号,因此有可能发生inode已用光,但硬盘未存满的情况。这时就无法在硬盘上创建新的文件,可以在创建文件系统时指定inode的数量占比:mkfs.xfs -i size=num,maxpct=n /dev/sdb1
inode的特殊作用
有时文件名有特殊字符或乱码,无法正常修改或删除,可以通过inode号来进行操作。
find . -inum 17062 -exec rm -i {} \;
移动或重命名文件,只改变文件名,inode并没有受影响。
block
block是真正存储数据的地方。block是文件系统中的最小存储单位,扇区是磁盘中的最小存储单位。
注意:Linux下叫block,Windows下叫簇。
Windows如何修改簇的大小
可以右键一个分区,点击格式化会出现如下窗口:"分配单元大小(A)"这里即是簇的大小,默认为4k(4096)。
Block或簇的大小对系统的影响
簇或block调大时,节约了寻址时间,速度变快,但浪费空间;簇和block调小时,节约空间,但寻址时间变长,速度变慢。
说明:为什么簇或block调大会浪费空间?这是因为一个文件会占用多个簇或block来存放。当前一个簇或block放不下时,就会占用下一个簇或block,到最后如果产生不足以占用一个完整的簇或block时,仍然会占用一个完整的簇或block,就会浪费这个簇或block剩下的空间。例如有一个2T的硬盘,可以前1.5T使用4K的簇或block,后0.5G使用64K的簇或block,这样可以改善机械硬盘越到最后速度越慢的问题。
访问-修改-状态改动这三类时间
可以通过stat命令查看文件的状态,其中的三类时间在此命令中会全部展现出来。在Linux下一个文件有三种时间,分别是:访问时间、修改时间、状态改动时间,即Access Time(访问时间)、Modify Time(修改时间)、Change Time(改变时间);Windows平台下亦如此。在Linux下没有创建时间的概念,也就是不能知道文件的建立时间,但如果文件建立后就没有修改过,修改时间=建立时间;如果文件建立后,状态就没有改动过,那么修改时间=建立时间;如果文件建立后,没有被读取过,那么访问时间=建立时间,因为不好判断文件是否被改过、读过、其状态是否变过,所以判断文件的建立时间基本上不可能。
$ stat freeoa.txt
文件:freeoa.txt
大小:69603 块:136 IO 块:4096 普通文件
设备:fe00h/65024d Inode:809517787 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 1000/ ehto) Gid:( 1000/ eghf)
最近访问(Access):2021-03-08 13:08:53.492004356 +0800
最近更改(Modify):2021-03-08 13:08:38.691929602 +0800
最近改动(Change):2021-03-08 13:08:50.475989118 +0800
创建时间:-
Access访问时间。Modify修改时间。Change状态改动时间。可以stat *查看这个目录所有文件的状态。
ctime=change time
atime=access time
mtime=modifiy time
下面来解读一下这3个时间点:
1、atime是Access Time的简写,在Linux的文件系统中被称为访问时间,当文件的内容被访问时,就会更新这个时间,例如使用cat、more、less等命令查看文件的内容时,文件的访问时间就会被更新。访问时间,读一次这个文件的内容,这个时间就会更新。ls、stat命令都不会修改文件的访问时间。
2、mtime是Modification Time的简写,它指的是当“内容数据”被修改时,Linux系统会去更新这个时间。修改时间是文件内容最后一次被修改时间。比如:vi后保存文件,ls -l列出的时间就是这个时间。也就是说修改文件内容往往也会更新文件的状态改变时间和访问时间,但这不是绝对的。
3、ctime是Linux系统中的status time,即状态时间,当文件的状态即文件的属性被改变是就会更改这个时间,例如文件系统中的links(链接数),size(文件的大小)、文件的权限、blocks(文件的block数);当这些参数被改变时,Linux就会更改该文件所对应的这个时间参数。状态改动时间是该文件的i节点最后一次被修改的时间,通过chmod、chown命令修改一次文件属性,这个时间就会更新。更改文件的属性便会更新该时间,比如使用chmod命令更改文件属性,或者执行其他命令时隐式的附带更改了文件的属性如文件大小等。因此文件的mtime被修改,该文件的ctime也会被改变。
另外除了可以通过stat来查看文件的mtime、ctime、atime等属性,也可以通过ls命令来查看,具体如下:
ls -l +–time=xx时间+文件名
该种查询方法默认情况下显示的是文件的mtime。
ls -lx +文件名
这种查询方式中
c<—->ctime
u<—->atime
ls -lc filename 列出文件的 ctime(最后更改时间)
ls -lu filename 列出文件的 atime(最后存取或访问时间)
ls -l filename 列出文件的 mtime(最后修改时间)
在linux中stat函数中,用st_atime表示文件数据最近的存取时间(last accessed time);用st_mtime表示文件数据最近的修改时间(last modified time);使用st_ctime表示文件i节点数据最近的修改时间(last i-node's status changed time)。
字段 说明 例子 ls(-l)
st_atime 文件数据的最后存取时间 read -u
st_mtime 文件数据的最后修改时间 write 缺省
st_ctime 文件数据的最后更改时间 chown,chmod -c
在linux系统中,系统把文件内容数据与i节点数据是分别存放的,i节点数据存放了文件权限与文件属主之类的数据。另外可以格式化输出文件的三种时间,如:
find . -name file -printf "%AY-%Am-%Ad %AH:%AM:%AS"
find . -name file -printf "%TY-%Tm-%Td %TH:%TM:%TS"
find . -name file -printf "%CY-%Cm-%Cd %CH:%CM:%CS"
linux的ctime代表的是文件修改时间,如果文件被修改过就很难知道文件的创建时间,在某些特殊情况下,需要查看文件的创建时间,正常情况下查看文件的ctime是无法实现的。可以使用一个变通的方法来实现保留文件创建时间,但是同时也会牺牲一些其它特性和提高一些IO性能:
可以在mount文件的时候使用参数-o noatime,来把系统更新atime的特性关闭。使用了noatime参数挂载后,在文件被修改后文件的atime是不会被改变的,使用stat查看到的atime就是文件的创建时间。
从linux kernel2.6.29开始,还默认集成了一个relatime的属性。出现此属性可能是在文件读操作很频繁的系统中,atime更新所带来的开销很大,所以在挂装文件系统的时候使用noatime属性来停止更新atime。但是有些程序需要根据atime进行一些判断和操作,所以Linux就推出了一个relatime特性。使用这个特性来挂装文件系统后,只有当mtime比atime更新的时候,才会更新atime。事实上,这个时候atime和mtime已经是同一个东西了。所以这个选项就是为了实现对atime的兼容才推出的。并不是一个新的时间属性。使用方法就是通过mount -o relatime /dir来挂装到目录。
后面再来看看Linux中用touch命令改变文档或目录时间,包括存取时间或更改时间,也可以用于创建新文件的示例。
命令格式:touch [选项] [参数]
选项:
-a:只更改文件的读取时间(access time)。
-m:只更改文件的修改时间(mtime),而不建立文件。
-c:如指定的文件不存在,不会建立新的文件。
-d:更改指定日期时间,而不是当前系统时间,可设定多种格式,后面可以接日期,也可以使用 --date="日期或时间"。
-r:把指定的文档或目录的时间设置成与参考文档或目录的日期时间一致。
-t:使用指定的时间,而不是当前系统时间,可设置多种格式,格式为 [YYMMDDhhmm]。
--help:显示帮助
--version:显示版本信息
touch 命令以 [[CC]YY]MMDDhhmm[.ss] 的格式指定新时间戳的日期和时间,相关信息如下:
CC:指定年份的前两位数字。
YY:指定年份的后两位数字。
MM:指定一年的哪一月,1-12。
DD:指定一年的哪一天,1-31。
hh:指定一天中的哪一个小时,0-23。
mm:指定一小时的哪一分钟,0-59。
参数:指定要设置时间属性的文件列表或要创建的目录。
注意:如果touch后面接一个已经存在的文件,则该文件的3个时间(atime/ctime/mtime)都会更新为当前时间。若该文件不存在,则会主动建立一个新的空文件。
示例:
touch freeoa.txt 如果abc.txt不存在则创建文件freeoa.txt,如果freeoa.txt存在,则使用当前时间更改文件时间(三个都改)。
touch -r test2 将文件日期更改为参考文件日期。
touch -d "2 days ago" test2 将文件修改日期调整为两天前。
touch -t "01231215" test2 将文件修改日期调整为指定日期,1月23日12点15分。
小结
如果没有 inode ,那么 UNIX 中的文件和目录将根本无法使用。希望在阅读完本文之后,可以更好地了解 inode 、它们对于 AIX 系统的重要性,以及如何管理它们。可能会对 df 命令的看法大为改观。
Linux 文件系统基础之块、i节点
文件系统是Linux系统的心脏部分,提供了层次结构的目录和文件。文件系统将磁盘空间划分为每1024个字节一组,称为块(也有用512字节为一块的,如:SCOXENIX)。编号从0到整个磁盘的最大块数。
全部块可划分为四个部分,块0称为引导块,文件系统不用该块;块1称为专用块,专用块含有许多信息,其中有磁盘大小和全部块的其他两部分的大小。从块2开始是i节点表,i节点表中含有i节点,表的块数是可变的,后面将做讨论。i节点表之后是空闲存储块(数据存储块),可用于存放文件内容。
文件的逻辑结构和物理结构是十分不同的,逻辑结构是用户敲入cat命令后所看到的文件,用户可得到表示文件内容的字符流。物理结构是文件实际上如何存放在磁盘上的存储格式。用户认为自己的文件是边疆的字符流,但实际上文件可能并不是以边疆的方式存放在磁盘上的,长于一块的文件通常将分散地存放在盘上。然而当用户存取文件时,linux文件系统将以正确的顺序取出各块,给用户提供文件的逻辑结构。当然,在linux系统的某处一定会有一个表,告诉文件系统如何将物理结构转换为逻辑结构。这就涉及到i节点了。i节点是一个64字节长的表,含有有关一个文件的信息,其中有文件大小、文件所有者、文件存取许可方式,以及文件为普通文件、目录文件还是特别文件等。在i节点中最重要的一项是磁盘地址表。
该表中有 13个块号。前10个块号是文件前10块的存放地址。这10个块号能给出一个至多10块长的文件的逻辑结构,文件将以块号在磁盘地址表中出现的顺序依次取得相应的块。当文件长于10块时又怎样呢?磁盘地址表中的第11项给出一个块号,这个块号指出的块中含有256个块号,至此,这种方法满足了至多长于 266块的文件(272384字节)。如果文件大于266块,磁盘地址表的第12项给出一个块号,这个块号指出的块中含有256个块号,这256个块号的每一个块号又指出一块,块中含256个块号,这些块号才用于取文件的内容。磁盘地址中和第13项索引寻址方式与第12项类似,只是多一级间接索引。
这样在linux系统中,文件的最大长度是16842762块,即17246988288字节,有幸是Linux系统对文件的最大长度(一般为1到2M字节)加了更实际的限制,使用户不会无意中建立一个用完整个磁盘区所有块的文件。文件系统将文件名转换为i节点的方法实际上相当简单。一个目录实际上是一个含有目录表的文件:对于目录中的每个文件,在目录表中有一个入口项,入口项中含有文件名和与文件相应的i节点号。当用户在终端敲入'cat xxx'时,文件系统就在当前目录表中查找名为xxx的入口项,得到与文件xxx相应的i节点号,然后开始取含有文件xxx的内容的块。
查看某目录下文件的个数 :
ls -l |grep "^-"|wc -l
或
find ./ccyou -type f | wc -l
查看某目录下文件的个数,包括子目录里的。
ls -lR|grep "^-"|wc -l
查看某文件夹下目录的个数,包括子目录里的。
ls -lR|grep "^d"|wc -l
说明:
ls -l
长列表输出该目录下文件信息(注意这里的文件,不同于一般的文件,可能是目录、链接、设备文件等)
grep "^-"
这里将长列表输出信息过滤一部分,只保留一般文件,如果只保留目录就是 ^d
wc -l
统计输出信息的行数,因为已经过滤得只剩一般文件了,所以统计结果就是一般文件信息的行数,又由于一行信息对应一个文件,所以也就是文件的个数
查看某目录大小:
du -hs
du的英文原义为“disk usage”,含义为显示磁盘空间的使用情况。
功能:统计目录(或文件)所占磁盘空间的大小。
语法:du [选项] [Names…]
说明:该命令逐级进入指定目录的每一个子目录并显示该目录占用文件系统数据块(1024字节)的情况。若没有给出Names,则对当前目录进行统计。
该命令的各个选项含义如下:
-s 对每个Names参数只给出占用的数据块总数。
-a 递归地显示指定目录中各文件及子孙目录中各文件占用的数据块数。若既不指定-s,也不指定-a,则只显示Names中的每一个目录及其中的各子目录所占的磁盘块数。
-b 以字节为单位列出磁盘空间使用情况(系统缺省以k字节为单位)。
-k 以1024字节为单位列出磁盘空间使用情况。
-c 最后再加上一个总计(系统缺省设置)。
-l 计算所有的文件大小,对硬链接文件,则计算多次。
-x 跳过在不同文件系统上的目录不予统计。
查看磁盘大小 :
df -ha
查看目录下所有目录名长度 :
find softs/ -type d | awk '{print length($0);print$0}'
查看block的大小以及修改方式参考
查看block的大小
# file -s /dev/sdb1 //把block或设备当做普通文件看待
/dev/sdb1: SGI XFS filesystem data (blksz 4096, inosz 512, v2 dirs)
# xfs_info /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=65536 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0 spinodes=0
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
注意:xfs_info只能用于xfs的文件系统,如果是ext系列文件系统请使用tune2fs。
修改block的大小,对xfs文件系统来说就需要用到mkfs.xfs这个格式化命令(操作前一定要备份!):
# mkfs -t xfs -b size=2048 /dev/sdb1
分区中还有空间但创建文件时提示空间不足
需要知道创建文件时,需要满足两个条件:1、磁盘上还有空间;2、inode号还有剩余。这两个条件可以分别使用"df -h"以及"df -i"查看使用情况。
如果所在的分区inode满了,可以将一些没用的文件或目录删除,释放inode号;也可以将部分文件备份到一个新分区,然后删除这些文件,释放inode号,再将备份分区挂载到原来的位置。每个文件都必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况,这会导致无法在硬盘上创建新文件,多发于海量小文件的情形。
inode号在xfs文件系统前(ext[2-4])都是在格式化之前就定下来的,例如ext4文件系统使用命令mkfs.ext4中的-N选项设置数量。但使用xfs文件系统时没有-N这个选项,不用担心,这时使用-i maxpct=n来调整inode区占整个分区的比例(默认n=25,即占用25%的空间大小)。而且似乎可以使用命令xfs_growfs在不重新格式化分区就可以增加inode区占整个分区的比例,从而增加inode总数。
# xfs_growfs -m 30 /dev/sdb1 //扩展inode占整个磁盘的容量
# df -i /dev/sdb1 //可以发现inode总量增加
注意:在增加inode占比时需要注意有没有空间,别在没有空间了还加inode区,显然这不会成功的。
在格式化是更改使用了命令:'mkfs.xfs -i size=num,maxpct=n /dev/sdb1'。-i选项代表对inode修改了,size设置一个inode大小,maxpct设置iNode区占比。