Inode
 inode (index node)是指在许多“类Unix文件系统”中的一种数据结构,用于描述文件系统对象(包括文件、目录、设备文件、socket、管道等)。每个inode保存了文件系统对象数据的属性和磁盘块位置。文件系统对象属性包含了各种元数据(如:最后修改时间) ,也包含用户组(owner )和权限数据。Unix先驱丹尼斯·里奇说,inode这个命名的来源可能是文件系统的存储组织为一个扁平数组,分层目录信息使用一个数作为文件系统这个扁平数组的索引值(index)。
inode (index node)是指在许多“类Unix文件系统”中的一种数据结构,用于描述文件系统对象(包括文件、目录、设备文件、socket、管道等)。每个inode保存了文件系统对象数据的属性和磁盘块位置。文件系统对象属性包含了各种元数据(如:最后修改时间) ,也包含用户组(owner )和权限数据。Unix先驱丹尼斯·里奇说,inode这个命名的来源可能是文件系统的存储组织为一个扁平数组,分层目录信息使用一个数作为文件系统这个扁平数组的索引值(index)。文件系统创建(格式化)时,就把存储区域分为两大连续的存储区域。一个用来保存文件系统对象的元信息数据,这是由inode组成的表,每个inode默认是256字节或者128字节。另一个用来保存“文件系统对象”的内容数据,划分为512字节的扇区,以及由8个扇区组成的4K字节的块。块是读写时的基本单位。一个文件系统的inode的总数一般情况下是固定的。这限制了该文件系统所能存储的文件系统对象的总数目。典型的情况下,所有inode占用了文件系统1%左右的存储容量。
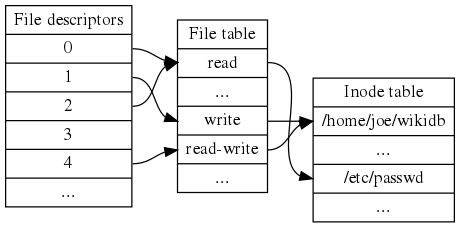
Unix上的文件描述符、文件表与inode表
文件系统中每个“文件系统对象”对应一个“inode”数据,并用一个整数值来辨识。这个整数常被称为inode号码(“i-number”或“inode number”)。由于文件系统的inode表的存储位置、总条目数量都是固定的,因此可以用inode号码去索引查找inode表。
Inode存储了文件系统对象的一些元信息,如所有者、访问权限(读、写、执行)、类型(是文件还是目录)、内容修改时间、inode修改时间、上次访问时间、对应的文件系统存储块的地址等等。知道了1个文件的inode号码,就可以在inode元数据中查出文件内容数据的存储地址。文件名与目录名是“文件系统对象”便于使用的别名。一个文件系统对象可以有多个别名,但只能有一个inode,并用这个inode来索引文件系统对象的存储位置。
1).inode不包含文件名或目录名的字符串,只包含文件或目录的“元信息”。
2).Unix的文件系统的目录也是一种文件。打开目录,实际上就是读取“目录文件”。目录文件的结构是一系列目录项(dirent)的列表。每个目录项,由两部分组成:所包含文件或目录的名字,以及该文件或目录名对应的inode号码。
3).文件系统中的一个文件是指存放在其所属目录的“目录文件”中的一个目录项,其所对应的inode的类别为“文件”;文件系统中的一个目录是指存放在其“父目录文件”中的一个目录项,其所对应的inode的类别为“目录”。可见,多个“文件”可以对应同一个inode;多个“目录”可以对应同一个inode。
4).文件系统中如果两个文件或者两个目录具有相同的inode号码,那么就称它们是“硬链接”关系。实际上都是这个inode的别名。换句话说,一个inode对应的所有文件(或目录)中的每一个,都对应着文件系统某个“目录文件”中唯一的一个目录项。
5).创建一个目录时,实际做了3件事:在其“父目录文件”中增加一个条目;分配一个inode;再分配一个存储块,用来保存当前被创建目录包含的文件与子目录。被创建的“目录文件”中自动生成两个子目录的条目,名称分别是:“.”和“..”。前者与该目录具有相同的inode号码,因此是该目录的一个“硬链接”。后者的inode号码就是该目录的父目录的inode号码。所以,任何一个目录的"硬链接"总数,总是等于它的子目录总数(含隐藏目录)加2。即每个“子目录文件”中的“..”条目,加上它自身的“目录文件”中的“.”条目,再加上“父目录文件”中的对应该目录的条目。
6).通过文件名打开文件,实际上是分成三步实现:首先,操作系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。
Linux系统使用struct inode作为数据结构名称。BSD派生的系统使用vnode名称,其中v表示“virtual file system”。
POSIX inode
POSIX 标准强制规范的文件系统的行为受到传统 UNIX 文件系统的深刻影响。可以用短语“文件序列号”来形容inode,定义为文件系统范围的唯一文件标识符。上述的文件序列号和包含此文件的设备ID一起,在整个系统上对应唯一的文件。在POSIX系统上,可使用stat系统调用获取文件的下列属性:
1).以字节为单位表示的文件大小。
2).设备ID,标识容纳该文件的设备。
3).文件所有者的User ID。
4).文件的Group ID
5).文件的模式(mode),确定了文件的类型,以及它的所有者、它的group、其它用户访问此文件的权限。
6).额外的系统与用户标志(flag),用来保护该文件。
7).3个时间戳,记录了inode自身被修改(ctime, inode change time)、文件内容被修改(mtime, modification time)、最后一次访问(atime, access time)的时间。
8).1个链接数,表示有多少个硬链接指向此inode。
9).到文件系统存储位置的指针。通常是1K字节或者2K字节的存储容量为基本单位。
可以查询一个文件的inode号码及一些元信息。
其它
1).一个文件系统对象可以有多个名字,这些具有硬链接关系的文件系统对象名字具有相同的inode号码,彼此是平等的。即首个被创建的文件并没有特殊的地位。这与符号链接不同。一个符号链接文件有自己的inode,符号链接文件的内容是它所指向的文件的名字。因此删除符号链接所指向的文件,将导致这个符号链接文件在访问时报错。
2).删除一个文件或目录,实际上是把它的inode的链接数减1。这并不影响指向此inode的别的硬链接。
3).一个inode如果没有硬链接,此时inode的链接数为0,文件系统将回收该inode所指向的存储块,并回收该inode自身。
4).从一个inode,通常是无法确定是用哪个文件名查到此inode号码的。打开一个文件后,操作系统实际上就抛掉了文件名,只保留了inode号码来访问文件的内容。库函数getcwd()用来查询当前工作目录的绝对路径名。其实现是从当前工作目录的inode逐级查找其上级目录的inode,最后拼出整个绝对路径的名字。
5).历史上,对目录的硬链接是可能的。这可以使目录结构成为一个有向图,而不是通常的目录树的有向无环图。一个目录甚至可以是自身的父目录。现代文件系统一般禁止这些混淆状态,只有根目录保持了特例:根目录是自身的父目录。这项限制最著名的一个例外可在Mac OS X(10.5或更高版本)上找到:它允许超级用户创建目录的硬链接。
6).一个文件或目录在文件系统内部移动时,其inode号码不变。文件系统碎片整理可能会改变一个文件的物理存储位置,但其inode号码不变。非UNIX的FAT及其派生的文件系统是无法实现inode不变这一特点。
7).inode文件系统中安装新库十分容易。当一些进程正在使用一个库时,其它进程可以替换该库文件名字的inode号码指向新创建的inode,随后对该库的访问都被自动引导到新inode所指向的新的库文件的内容。这减少了替换库时重启系统的需要。而旧的inode的链接数已经为0,在使用旧库的进程结束后,旧的inode与旧库文件会被系统自动回收。
8).一些文件系统,由于inode表在文件系统创建时就已经确定并且不能再动态增加,新增的文件数量可能会用尽inode。这导致文件系统还有空闲的存储空间,但已经没有空闲的inode可供使用了。例如,一个电子邮件服务器可能会被大量的小文件用尽所有inode,但是却没有填满文件存储空间。部分文件系统,如JFS和XFS,能够动态地增加inode,因此不会用尽inode。
系统管理员使用的很多程序往往用inode号码来替代文件名来访问文件系统。例如磁盘完整性检查程序fsck或pfiles。因此inode号码与文件全路径名的互查是需要的。可以用find带参数选项-inum,ls带参数选项'-i'做到。
文件储存在硬盘上,硬盘的最小存储单位叫做”扇区”(Sector)。每个扇区储存512字节(相当于0.5KB)。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个”块”(block)。这种由多个扇区组成的”块”,是文件存取的最小单位。”块”的大小,最常见的是4KB,即连续八个 sector组成一个 block。文件数据都储存在”块”中,那么很显然,还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode。Linux中目录的数据块中的每一项中都包含了文件名和其对应的inode。inode记录了文件的属性以及该文件实际存储位置,即数据块号(block number),每一个block(常见大小4KB),通过inode可以实现文件的查找定位。inode是Linux中的,Unix中是vnode。基本上,inode包含的信息至少有如下这些:
(1)文件的类型
(2)文件访问权限;
(3)文件的所有者与组;
(4)文件的大小;
(5)链接数,即指向该inode的文件名总数;
(6)文件的状态改变时间(ctime)、最近访问时间(atime)和最近修改时间(mtime);
(7)文件特殊属性,SUID、SGID和SBIT;
(8)文件内容的真正指向(pointer)。
可以用stat命令,查看某个文件的inode信息。inode的数量与大小在磁盘格式化的时候就已经固定了,inode的特点有:
(1)每一个inode的大小均固定为128B。可以通过命令dumpe2fs来显示ext2/ext3/ext4文件系统信息。
$ dumpe2fs -h /dev/sda1 | grep "Inode size"
dumpe2fs 1.41.12 (17-May-2010)
Inode size:128
(2)每个文件都只占用一个inode。因此文件系统能够建立的文件数量与inode数量有关。系统读取档案时需要先找到inode,并分析inode所记录的权限与用户是否符合,若符合才能够开始实际读取block的内容。
操作系统读取磁盘文件的流程是这样的:
(1)根据给定的文件的所在目录,获取该目录的数据实体,根据数据实体中的数据项,找到对应文件的inode;
(2)根据文件inode,找到inodeTable;
(3)根据inodeTable中的对应关系,找到对应的block;
(4)读取文件。
系统读取磁盘文件流程示意图如下:
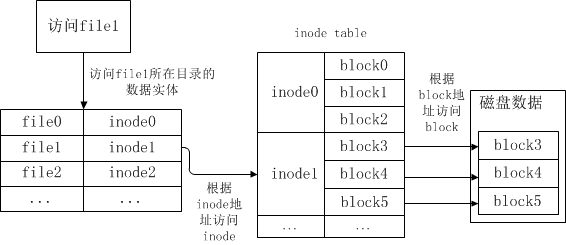
举例来说,如果想要读取/etc/freeoa文件,读取流程如下:
(1)获取根目录/的inode。透过挂载点的信息找到根目录的inode号为2;
ll -di /
2 dr-xr-xr-x 19 root root 4096 Feb 14 09:32 /
(2)根据根目录的inode,找到根目录的数据实体block,可以理解为一个文件到inode号的映射表,找到目录etc的inode号;
ll -di /etc
786433 drwxr-xr-x 98 root root 12288 Feb 13 17:18 /etc
(3)根据目录etc的inode号,读取目录etc的数据实体block,并找到文件freeoa的inode号;
ll -i /etc/freeoa
787795 -rw-r--r-- 1 root root 1552 Jan 4 14:56 /etc/freeoa
(4)根据/etc/freeoa文件的inode号,即可获取/etc/freeoa文件的数据实体block,完成文件的读取。
Inode的优点
(1)对于有些无法删除的文件可以通过删除inode节点来删除;
(2)移动或者重命名文件,只是改变了目录下的文件名到inode的映射,并不需要实际对硬盘操作;
(3)删除文件的时候,只需要删除inode,不需要实际清空那块硬盘,只需要在下次写入的时候覆盖即可(这也是为什么删除了数据可以进行数据恢复的原因之一);
(4)打开一个文件后,只需要通过inode来识别文件。
参考:
关于inode