Perl IO操作之文件读写
 IO对象和IO::Module家族模块
IO对象和IO::Module家族模块无论是哪种高级编程语言,都提供了较底层的操作系统层IO能力,也提供了更高层次的封装来实现语言级别的IO能力。像文件描述符这种东西,是属于操作系统层的,比较底层,它是操作系统负责管理的资源。对于Perl来说,文件句柄是Perl提供的比文件描述符更上一层的Perl IO层次的东西,文件句柄直接指向文件描述符(非一一对应关系,可以多个文件句柄指向同一个文件描述符),但是文件句柄层到文件描述符层的中间有一些由Perl IO提供的特性,毕竟封装了底层就要比底层功能更丰富、操作更方便,比如IO Buffer是属于Perl IO层的。
以上是IO全局上的概念,先了解即可,后面的文章会对其进行解释。这里先了解下Perl提供的IO方面的东西:
sysFUNC:这类函数是操作系统层的IO操作,如sysread、sysopen、sysseek、syswrite等
open:打开文件句柄,根据给定参数的不同,以不同层次的方式打开文件句柄
IO::Module:Perl提供的面向对象的IO接口,简化IO操作,包括:
IO::Handle:提供文件句柄类的通用接口
IO::File:提供文件操作类的通用接口
IO::Dir:提供目录操作类的通用接口
IO::Pipe:提供管道类的接口
IO::Socket:提供套接字类的接口
IO::Seekable:为IO对象提供基于Seek操作的接口
IO::Select:提供select系统调用的面向对象接口
IO::Poll:提供poll系统调用的面向对象接口
IO:将上面几种模块整合到了这一个模块中
对于支持面向对象的语言来说,一般文件句柄都会被抽象成一个IO对象来简化IO操作(对于Perl,就是变量类型的文件句柄),通过这个对象可以直接跨模块调用不同模块中的方法。例如Perl中以变量方式提供open的文件句柄可以创建一个IO对象,只要导入了IO::Handle模块,这个IO对象就能自动使用IO::Handle模块中的方法,而不需要再从IO::Handle创建一个IO对象。
use IO::Handle;
# IO对象: $fh
open my $fh, ">", "test.log" or die "open failed: $!";
# 直接调用IO::Handler中的方法
$fh->autoflush(1);
# 调用IO::Handler中的print函数
$fh->print("hello world\n");
实际上通过open、sysopen或者上述IO家族模块的某些模块都可以创建IO对象(文件句柄对象),其中IO家族的模块可以创建匿名文件句柄,匿名的文件句柄对象可以在后续任何需要的时候通过open绑定到某个具体的文件上。例如:
use IO::Handle;
my $fh = IO::Handle->new();
open $fh, "file.txt" or die "open failed: $!";
# 等价于
open my $fh, "file.txt" or die "open failed: $!";
另外需要注意的是,自己通过open创建的裸文件句柄(即非变量类型的文件句柄)不是文件句柄对象,就像自己创建了一个LOG句柄,它无法直接使用LOG->autoflush(1);。
关于open相关的介绍,参见前面列出的基础文章,关于操作系统层IO的sysFUNC函数,在后面以单独的文章介绍。所以,这里先介绍IO::家族的部分模块。
IO::Handle简介
IO::Handle提供了很多文件句柄类的通用操作,比如new()创建匿名的文件句柄对象,autoflush()函数设置自动刷新(即替代select FH;$| = 1;),等等。它也是所有IO家族模块的基本组成模块,而且一般不会直接使用IO::Handle来创建IO对象,而是通过其它IO模块创建IO对象然后继承这个模块里的方法。例如,通过new()方法创建匿名文件句柄:
my $fh = IO::Handle->new();
IO::Handle提供了很多基础操作,可以查看perldoc手册perldoc IO::Handle了解其属性,在后面的内容或文章中会逐渐介绍其中的部分功能。
IO::File
该模块提供了操作文件的通用接口,主要是以不同模式打开文件句柄的方法,而其它操作数据的方法都从IO::Handle中继承。先看例子:
use IO::File;
# 先创建匿名句柄,再open打开
$fh = IO::File->new();
if ($fh->open("< file")) {
print <$fh>;
$fh->close;
}
# 直接以单个参数方式创建并打开文件句柄
$fh = IO::File->new("> file");
if (defined $fh) {
print $fh "bar\n";
$fh->close;
}
# 直接以两个参数方式创建并打开文件句柄
$fh = IO::File->new("file", "r");
if (defined $fh) {
print <$fh>;
undef $fh; # 将自动关闭文件句柄
} # 等价于出了作用域范围
# 直接以flag的方式创建并打开文件句柄
$fh = IO::File->new("file", O_WRONLY|O_APPEND);
if (defined $fh) {
print $fh "corge\n";
$pos = $fh->getpos;
$fh->setpos($pos);
undef $fh; # automatically closes the file
}
autoflush STDOUT 1;
关于IO::File模块中的new和open方法:
new([FILENAME [,MODE [,PERMS]]])
open(FILENAME [,MODE [,PERMS]])
open(FILENAME, IOLAYERS)
new()方法和open()方法都能创建并打开文件句柄,当new()没有参数时,表示创建一个匿名句柄,当有任何参数时,都将调用open并传递参数给open。
open()可以接收单个、两个、三个参数,单参数的open()将直接调用内置open()函数。两个或三个参数时,第一个参数是文件名(可以包含特殊符号),第二个参数是open的模式。
如果open接收到了类似于> +< >>等方式的模式时,或者接收到了ANSI C fopen()的字符串格式的模式w r+a等,它将调用内置open()函数并自动保护好一些特殊符号以免出错。
如果open接收到了数值格式的模式,则调用sysopen()函数并传递数值模式给它,例如0666。
如果open中包含了:符号,则将所有3个参数都传递给3参数方式的内置open()函数。
open还支持Fcntl模块中定义的O_XXX模式,例如O_RDONLY、O_CREAT等。
它们之间的对应关系如下:
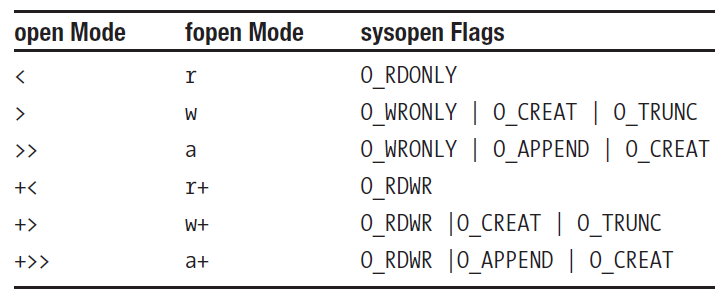
不难发现,O_RDONLY、O_WRONLY或O_RDWR是三个基本的模式,任何一种模式都至少指定它们中的一个。
IO::File还支持指定binmode来支持二进制读、写操作,详细内容参见perldoc -f binmode。
最后,IO::File的new_tmpfile()方法可以在/tmp目录下创建并打开这个临时文件,这个临时文件和普通意义上的临时文件有些不同,它是直接创建一个文件,然后一直保持打开,并立即删除它,也就是说它是匿名的文件。这样在操作系统上就看不到这个文件,但是却可以对这个临时文件进行IO,从而实现真正意义上的临时文件。如果创建成功,它返回IO对象,否则销毁IO对象。
显然,这个创建就被删除的临时文件只有在同时提供读、写能力时才有意义,只读或者只写是没有意义的。例如:
use strict;
use warnings;
use IO::File;
use IO::Handle;
# 创建临时文件
my $tmp_file = IO::File->new_tmpfile();
$tmp_file->autoflush(1);
# 这个临时文件已经被删除了
system("lsof -n -p $$ | grep 'deleted'");
# 写入一点数据
$tmp_file->say("Hello World1");
$tmp_file->say("Hello World2");
$tmp_file->say("Hello World3");
$tmp_file->say("Hello World4");
# 指针移动到临时文件的头部来读取数据
seek($tmp_file, 0, 0);
while(<$tmp_file>){
print "Reading from tmpfile: $_";
}
执行结果:
perl 22583 root 3u REG 0,2 0 2533274790579481 /tmp/PerlIO_ns1KST (deleted)
Reading from tmpfile: Hello World1
Reading from tmpfile: Hello World2
Reading from tmpfile: Hello World3
Reading from tmpfile: Hello World4
其实内置函数open()或者IO::File的open()方法也能创建同样的临时文件,只需要将open()的文件名参数指定为undef即可,由于指定了undef文件名,所以open()只能是三参数模式的。例如:
open LOG, "+<", undef or die "open failed: $!";
read()函数
read()函数用于从文件句柄中读取指定字节数的数据并写入到一个标量中;如果文件句柄是以Unicode方式打开的,则表示读取指定字符数而非字节数。有两种read方式:
read FH, $var, len
read FH, $var, len, offset
三参数的read表示从FH文件句柄中读取len字节长度的数据放进标量变量$var中。四参数的read稍后解释,例如:
use strict;
use warnings;
# 打开标准输入
open my $fh, "<-" or die "open failed: $!";
my $var;
my $rd_cnt = read $fh, $var, 8; # 读取8个字节到$var
print "$var\n";
执行:
$ echo "hello malongshuai" | perl read.pl -
hello ma
read返回所读取到的字节数,如果读取时已经到了文件尾部,则返回0,如果read出错了则返回undef。所以,循环read的时候,可以通过下面的代码来判断是否到了文件尾部或出错。具体可见下面四参数循环read的示例用法。
if(not defined $res){
print "Error: $!\n";
}else {
print "read Over\n";
}
四参数的read第四个参数则是读取数据后写进变量时从变量的哪个offset开始写,注意offset不是控制从文件句柄的哪个位置读,而是控制向变量的哪个位置开始写。三参数的read是每次都写入到变量的头部。
由于写入到变量中的数据字节数是不定的,可能当前变量中的数据长度比写入的字节长度短、长,这时新的变量将自动扩容或收缩。例如,当前$var="abcde",向其中写入"ABCDEFG"将扩展为7个字节以便存放"FG"这两个字符,向其中写入"ABC"将收缩为3个字符长度。例如从一段数据中循环读取数据,并每次读取8个字节保存到变量中。
use strict;
use warnings;
my $var;
my $res;
while($res = (read DATA, $var, 8, 0)){
chomp $var;
print "writed $res bytes to \$var: $var\n";
}
if(not defined $res){
print "Error: $!\n";
} else {
print "read Over\n";
}
__DATA__
abcdefg ABCDEFG
hijklmn HIJKLMN
bye
由于可以通过offset指定从哪里开始写数据,所以当前的变量长度可能比offset的值更小,这时将自动使用\0(即空字符)填充到指定长度以便追加数据。如果offset的值为负数,则表示从变量的尾部向前计数,-1表示从倒数第一个字节开始追加(覆盖倒数第一个字节)。
use strict;
use warnings;
# 打开标准输入
open my $fh, "<-" or die "open failed: $!";
my $var;
# 从标准输入中读取数据,并先向$var里写入6个字节
read $fh, $var, 6;
my $res;
# 循环写入,每次从$var中offset=6的位置开始写入8个字节
# 也就是在变量中追加新读取的8个字节
while($res = (read DATA, $var, 8, 6)){
chomp $var;
print "writed $res bytes to \$var: $var\n";
}
__DATA__
abcdefg ABCDEFG
hijklmn HIJKLMN
bye
执行:
$ echo "hello malong" | perl read1.pl
writed 8 bytes to $var: hello abcdefg
writed 8 bytes to $var: hello ABCDEFG
writed 8 bytes to $var: hello hijklmn
writed 8 bytes to $var: hello HIJKLMN
writed 4 bytes to $var: hello bye
write()函数
随机读写文件
随机读写
如果一个文件句柄是指向一个实体文件的,那么就可以对它进行随机数据的访问(包括随机读、写),随机访问表示可以读取文件中的任何一部分数据或者向文件中的任何一个位置处写入数据。实现这种随机读写的功能依赖于一个文件读写位置指针(file pointer)。
当一个文件句柄关联到了一个实体文件后,就可以操作这个文件句柄,比如通过这个文件句柄去移动文件的读写指针,当这个指针指向第100个字节位置处时,就表示从100个字节处开始读数据,或者从100个字节处开始写数据。
可以通过seek()函数来设置读写指针的位置,通过tell()函数来获取文件读写指针的位置。如果愿意的话,IO::Seekable模块同样提供了一些等价的面向对象的操作方法,不过它们只是对seek、tell的一些封装,用法和工作机制是完全一样的。
需要注意的是,虽说文件读写指针不是属于文件句柄的,但通过文件句柄去操作读写指针的时候,可以认为指针是属于句柄的。例如,同一个文件的多个文件句柄的读写指针是独立的,如果文件A上同时打开了A1和A2两个文件句柄,那么在A1上设置的读写指针不会影响A2句柄的读写指针。
seek跳转文件指针位置
通过seek()函数,可以让文件的指针随意转到哪个位置。注意还有一个sysseek()函数,它们的工作层次不同:seek()是工作在buffer上的,sysseek()是底层无buffer的。
seek FILEHANDLE, POSITION, WHENCE
seek()有三个参数:
第一个参数是文件句柄
第二个参数是正负整数或0,它的意义由第三个参数决定
第三个参数是flag,用来表明相对与哪个位置进行跳转的,值可以是0、1和2。如果导入了Fcntl模块的seek标签(即use Fcntl qw(:seek)),则可以使用0、1、2对应的常量SEEK_SET、SEEK_CUR、SEEK_END来替代0、1、2
第三个参数的值决定第二个参数的意义。如下:
seek 意义
-----------------------------------------------------------------
seek FH, $pos, 0 以相对于文件开头的位置跳转$pos个字节,
seek FH, $pos, SEEK_SET 即直接按照绝对位置的方式设置指针位置。
pos不能是负数,否则表示跳转到文件头的
前面,这会使得seek失败而返回0。例如
`seek FH, 0, 0`表示跳转到开头(第一个
字节前),`seek FH, 10, 0`表示跳转到第10字节前
seek FH, $pos, 1 以相对于当前指针的位置向前(pos为正数)、
seek FH, $pos, SEEK_CUR 向后(pos为负数)跳转pos个字节,pos=0表
示保持原地不动。例如`seek FH, 60, 1`
表示指针向右(向前)移动60个字节。如果移
动到超出文件的位置并从这里写入数据,将
以空字节`\0`填充直到那个位置
seek FH, $pos, 2 以相对于文件尾部的位置跳转$pos个字节。
seek FH, $pos, SEEK_END 如果pos为负数,表示向文件头方向移动pos
个字节,如果pos为0则表示保持在尾部不动,
如果pos大于0且要写入,则会以空字节`\0`
填充直到那个位置。例如`seek FH, -60, 2`
表示从文件尾部向文件头部移动60个字节
seek在成功跳转成功时返回true,否则返回0值,例如想要跳转到文件头的前面,这时返回0且将指针放置到文件的结尾。比如用seek来创建一个大文件:
open BIGFILE, ">", "bigfile.txt";
seek BIGFILE, 100*1024, 0; # 100K
syswrite BIGFILE, 'endendend' # 100k + 9bytes
close BIGFILE
跳转超出文件尾部后,如果要真的让文件扩充,需要在结尾的地方写入一点数据,否则不会填充。这就相当于用类似于下面的dd命令创建一个稀疏大文件一样。
dd if=/dev/zero of=bigfile seek=100 count=1 bs=1K
tell()函数获取文件指针位置
tell FILEHANDLE
tell函数获取给定文件句柄当前文件指针的位置。
唯一需要注意的一点是,如果文件句柄指向的文件描述符不是一个实体文件,比如套接字句柄,tell将返回-1。注意不是返回undef,尽管我们可能更期待它返回undef来判断。
$pos = tell MYHANDLE;
print "POS is", $pos > -1 ? $pos : "not file", "\n";
IO::Seekable
IO::Seekable模块提供了seek和tell的封装方法。例如:
$fh->seek($pos, 0); # SEEK_SET
$fh->seek($pos, SEEK_CUR);
$pos = $fh->tell();
seek在EOF处读
就像实现tail -f一样监控每秒写入到文件尾部的数据并输出。如果使用seek来实现这个功能的话,参考如下:
use strict;
use warnings;
die "give me a file" unless(@ARGV and -f $ARGV[0])
open my $taillog, $ARGV[0];
while(1){
while(<$tailog>){print "$.: $_";}
seek $taillog, 0, 1;
sleep 1;
}
上面的程序中,先读取出文件中的数据,然后将文件的指针保持在原地以便下次循环继续从这里开始读取,睡一秒后继续,这个逻辑并不难。当然对于上面简单的tail -f来说,根本没使用seek的必要,但是这提供了一种连续从尾部读取数据的思路。
seek在EOF处写
典型的是写日志文件,要不断地向文件尾部追加一行行日志数据。但是,多个进程可能会互相覆盖数据,因为不同进程的写真正是互相独立的,谁也不知道谁的指针在哪里。如果使用的是追加式写入方式,则多进程间不会出现数据覆盖的问题,因为每次append数据之前都会将指针放到文件的最结尾处。但是多个进程的append无法保证每行数据写入的顺序。如果要保证某进程某次两行数据的写入是紧连在一起的,那么需要使用锁的方式,例如使用flock文件锁。下面是一个简单的日志写入程序示例:
use strict;
use warnings;
use Fcntl qw(:flock :seek);
sub logtofile {
die "give me two args" if @_ < 1;
my $logfile = shift;
my @msg = @_;
open LOGFILE, ">>", $logfile or die "open failed: $!";
flock LOGFILE, LOCK_EX;
seek LOGFILE, 0, SEEK_END;
print LOGFILE @msg;
close LOGFILE;
}
logtofile "/tmp/mylog.log", "msgA\n", "msgB\n", "msgC\n";
truncate截断文件
如果要截断文件为某个空间大小,直接使用truncate()函数即可(shell下也有truncate命令来截断文件)。
它的第一个参数是文件句柄,第二个参数是截断后的文件大小,单位字节。注意,truncate是从当前指针位置开始向后截断的,其指针前面(左边)的数据不会动但是会计算到截断后的大小。如果指定的截断大小超过文件大小,则会使用空字节\0填充到给定大小(这个行为默认没有定义)。
因为要截断,这个文件句柄的模式必须是可写的,且如果是使用">"模式,将首先被截断为空文件。所以应该使用+<、>>、+>>这类模式。为了保证截断效果,如果使用的是后两种open模式,应该在每次截断前使用"seek"将指针指到文件的头部。例如,截断文件为100字节大小。
open FILE, ">>", "bigfile";
seek FILE, 0, 0;
truncate FILE, 100;
close FILE;
按行截断文件
truncate只能按字节截断文件,不过有时候我们想按照行数来截断文件。
例如想要保留前10行数据。实现的逻辑很简单,先按行读取10行(判断行号或使用一个行号计数器),然后记录下当前的指针位置,最后使用truncate截断到这个位置。
use strict;
use warnings;
die "give me a file" unless @ARGV;
die "give me a line num" unless (defined($ARGV[1]) and $ARGV[1] >= 0);
my $file = $ARGV[0];
my $trunc_to = int($ARGV[1]);
# 读取到前X行
open READ, $file or die "open failed: $!";
while(<READ>){
last if $. == $trunc_to;
}
my $trunc_size = tell READ;
exit if $. < $trunc_to; # total line less than $trunc_to
close READ;
# truncate
open WRITE, "+<", $file or die "open failed: $!";
truncate WRITE, $trunc_size or die "truncate failed: $!";
close WRITE;
文件锁
文件锁概述
当多个进程或多个程序都想要修同一个文件的时候,如果不加控制,多进程或多程序将可能导致文件更新的丢失。例如进程1和进程2都要写入数据到a.txt中,进程1获取到了文件句柄,进程2也获取到了文件句柄,然后进程1写入一段数据,进程2写入一段数据,进程1关闭文件句柄,会将数据flush到文件中,进程2也关闭文件句柄,也将flush到文件中,于是进程1的数据被进程2保存的数据覆盖了。所以,多进程修改同一文件的时候,需要协调每个进程:
1.保证文件在同一时间只能被一个进程修改,只有进程1修改完成之后,进程2才能获得修改权;
2.进程1获得了修改权,就不允许进程2去读取这个文件的数据,因为进程2可能读取出来的数据是进程1修改前的过期数据。
这种协调方式可以通过文件锁来实现。文件锁分两种,独占锁(写锁)和共享锁(读锁)。当进程想要修改文件的时候,申请独占锁(写锁),当进程想要读取文件数据的时候,申请共享锁(读锁)。
独占锁和独占锁、独占锁和共享锁都是互斥的。只要进程1持有了独占锁,进程2想要申请独占锁或共享锁都将失败(阻塞),也就保证了这一时刻只有进程1能修改文件,只有当进程1释放了独占锁,进程2才能继续申请到独占锁或共享锁。但是共享锁和共享锁是可以共存的,这代表的是两个进程都只是要去读取数据,并不互相冲突。
独占锁 共享锁
独占锁 × ×
共享锁 × √
文件锁:flock和lockf
Linux上的文件锁类型主要有两种:flock和lockf,后者是fcntl系统调用的一个封装。它们之间有些区别:
1.flock来自BSD,而fcntl或lockf来自POSIX,所以lockf或fcntl实现的锁也称为POSIX锁;
2.flock只能对整个文件加锁,而fcntl或lockf可以对文件中的部分加锁,即粒度更细的记录锁;
3.flock的锁是劝告锁,lockf或fcntl可以实现强制锁。所谓劝告锁,是指只有多进程双方都遵纪守法地使用flock锁才有意义,某进程使用flock,但另一进程不使用flock,则flock锁对另一进程完全无限制;
4.flock锁是附加在(关联在)文件描述符上的(见下文更深入的描述),而lockf是关联在文件实体上的。
文后将详细分析flock锁在文件描述符上的现象。Perl中主要使用flock来实现文件锁,也是本节的主要内容。
Perl的flock
flock FILEHANDLE, flags;
flock两个参数,第一个是文件句柄,第二个是锁标志。
锁标志有4种,有数值格式的1、2、8、4,在导入Fcntl模块的:flock后,也支持字符格式的LOCK_SH、LOCK_EX、LOCK_UN、LOCK_NB。
字符格式 数值格式 意义
-----------------------------------
LOCK_SH 1 申请共享锁
LOCK_EX 2 申请独占锁
LOCK_UN 8 释放锁
LOCK_NB 4 非阻塞模式
独占锁和独占锁、独占锁和共享锁是冲突的。所以当进程1持有独占锁时,进程2想要申请独占锁或共享锁默认将被阻塞。如果使用了非阻塞模式,那么本该阻塞的过程将立即返回,而不是阻塞等待其它进程释放锁。非阻塞模式可以结合共享锁或独占锁使用。所以有下面几种方式:
use Fcntl qw(:flock);
flock $fh, LOCK_SH; # 申请共享锁
flock $fh, LOCK_EX; # 申请独占锁
flock $fh, LOCK_UN; # 释放锁
flock $fh, LOCK_SH | LOCK_NB; # 以非阻塞的方式申请共享锁
flock $fh, LOCK_EX | LOCK_NB; # 以非阻塞的方式申请独占锁
flock在操作成功时返回true,否则返回false。例如在申请锁的时候,无论是否使用了非阻塞模式,只要没申请到锁就返回false,否则返回true,而在释放锁的时候,成功释放则返回true。例如两个程序(不是单程序内的两个进程,这种情况后面分析)同时运行,其中一个程序写a.txt文件,另一个程序读a.txt文件,但要保证先写完再读。
程序1的代码内容:
use strict;
use warnings;
use Fcntl qw(:flock);
open my $fh, '>', "a.txt" or die "open failed: $!";
flock $fh, LOCK_EX;
print $fh, "Hello World1\n";
print $fh, "Hello World2\n";
print $fh, "Hello World3\n";
flock $fh, LOCK_UN;
程序2的代码内容:
use strict;
use warnings;
use Fcntl qw(:flock);
open my $fh, '<', "a.txt" or die "open failed: $!";
# 非阻塞的方式每秒申请一次共享锁,只要没申请成功就返回false
until(flock $fh, LOCK_SH | LOCK_NB){
print "waiting for lock released\n";
sleep 1;
}
while(<$fh>){
print "readed: $_";
}
flock $fh, LOCK_UN;
fork、文件句柄、文件描述符和锁的关系
在开始之前,先看看在Perl中的fork、文件句柄、文件描述符、flock之间的结论。
1.文件句柄是指向文件描述符的,文件描述符是指向实体文件的(假如是实体文件的描述符的话)
2.fork只会复制文件句柄,不会复制文件描述符,而是通过复制的不同文件句柄指向同一个文件描述符而实现文件描述符共享
3.通过引用计数的方式来计算某个文件描述符上文件句柄的数量
4.close()一次表示引用数减1,直到所有文件句柄都关闭了即引用数为0时,文件描述符才被关闭
5.flock是附在文件描述符上的,不是文件句柄也不是实体文件上的。(实际上,flock是在vnode/generic-inode上的,它比fd底层的多(fd->fd table->open file table->vnode/g-inode),只不过对于perl的fork而言,因为不会复制文件描述符,使得将flock认为附在文件描述符上也没什么问题,只有open操作才会在vnode上检测flock的互斥性,换句话说,在perl中只有多次open才需要考虑flock的互斥性)
6.flock是进程级别的,不适用于在多线程中使用它来锁互斥
7.所以fork后的父子进程在共享文件描述符的同时也会共享flock锁
8.flock $fh, LOCK_UN会直接释放文件描述符上的锁
9.当文件描述符被关闭时,文件描述符上的锁也会自动释放。所以使用close()去释放锁的时候,必须要保证所有文件句柄都被关闭才能关闭文件描述符从而释放锁
10.flock(包括加锁和解锁)或close()都会自动flush IO Buffer,保证多进程间获取锁时数据同步
11.只要持有了某个文件描述符上的锁,在这把锁释放之前,自己可以随意更换锁的类型,例如多次flock从EX锁变成SH锁
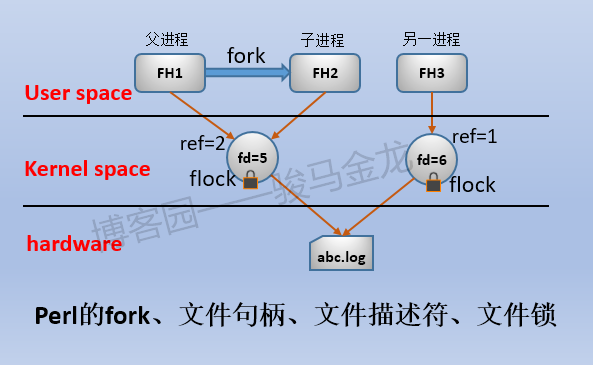
(图注:fd是用户空间的内容,图中放在内核层是为了概括与之关联的内核层的几个结构:fd对应内核层的这几个结构)
下面是正式介绍和解释。
在C或操作系统上的fork会复制(dup)文件描述符,使得父子进程对同一文件使用不同文件描述符。但Perl的fork只会复制文件句柄而不会复制文件描述符,父子进程的不同文件句柄会共享同一个文件描述符,并使用引用计数的方式来统计有多少个文件句柄在使用这个文件描述符。
之所以复制文件句柄是因为文件句柄在Perl中是一种变量类型,在不同作用域内是互相独立的。而文件描述符对Perl来说相对更底层一些,属于操作系统的数据资源,对Perl来说是属于可以共享的数据。
也就是说,如果只fork了一次,那么父子进程的两个文件句柄都共享同一个文件描述符,都指向这个文件描述符,这个文件描述符上的引用计数为2。当父进程close关闭了该文件描述符上的一个文件句柄,子进程需要也关闭一次才是真的关闭这个文件描述符。
不仅如此,由于文件描述符是共享的,导致加在文件描述符上的锁(比如flock锁)在父子进程上看上去也是共享的。尽管只在父子某一个进程上加一把锁,但这两个进程都将持有这把锁。如果想要释放这个文件描述符上的锁,直接unlock(flock $fh, LOCK_UN)或关闭文件描述符即可。
但是注意,close()关闭的只是文件描述符上的一个文件句柄引用,在文件描述符真的被关闭之前(即所有文件句柄都被关掉),锁会一直存在于描述符上。所以,很多时候使用close去释放时的操作(之所以使用close而非unlock类操作,是因为unlock存在race condition,多个进程可能会在释放锁的同时抢到那个文件的锁),可能需要在多个进程中都执行,而使用unlock类的操作只需在父子中的任何一进程中即可释放锁。
例如分析下面的代码中父进程三处加独占锁位置(1)、(2)、(3)对子进程中加共享锁的影响。
use Fcntl qw(:flock);
open my $fh, ">", "a.log";
# (1) flock $fh, LOCK_EX;
# 这里开始fork子进程
my $pid = fork;
# (3) flock $fh, LOCK_EX;
unless($pid){
# 子进程
# flock $fh, LOCK_SH;
}
# 父进程
# (2) flock $fh, LOCK_EX;
首先分析父进程在(3)处加锁对子进程的影响。(3)是在fork后且进入子进程代码段之前运行的,也就是说父子进程都执行了一次flock加独占锁,显然只有一个进程能够加锁。但无论是谁加锁了,这个描述符上的锁对另一个进程都是共享的,也就是两个进程都持有EX锁,这似乎违背了我们对独占锁的独占性常识,但并没有,因为实际上文件描述符上只有一个锁,只不过这个锁被两个进程中的文件句柄持有了。因为子进程也持有EX锁,自己可以直接申请SH锁实现自己的锁切换,如果父进程这时还没有关闭文件句柄或解锁,它也将持有SH锁。
再看父进程中加在(1)或(2)处的独占锁,他们其实是等价的,因为在有了子进程后,无论在哪里加锁,锁(文件描述符)都是共享的,引用计数都会是2。这时子进程要获取共享锁是完全无需阻塞的,因为它自己就持有了独占锁。
也就是说,上面无论是在(1)、(2)还是(3)处加锁,在子进程中都能随意无阻塞换锁,因为子进程在换锁前已经持有了这个文件描述符上的锁。
那么上面的示例中,如何让子进程申请互斥锁的时候被阻塞?只需在子进程中打开这个文件的新文件句柄即可,它会创建一个新的文件描述符,在两个文件描述符上申请锁时会检查锁的互斥性。但是必须记住,要让子进程能成功申请到互斥锁,必须在父进程中unlock或者在父子进程中都close(),往往我们会忘记在子进程中也关闭文件句柄而导致文件描述符继续存在,其上的锁也继续保留,从而导致子进程在该文件描述符上持有的锁阻塞了自己去申请其它描述符的锁。
例如下面在子进程中打开了新的$fh1,且父子进程都使用close()来保证文件描述符的关闭、锁的释放。当然也可以直接在父或子进程中使用一次flock $fh, LOCK_UN来直接释放锁。
use Fcntl qw(:flock);
open my $fh, ">", "a.log";
# (1) flock $fh, LOCK_EX;
# 这里开始fork子进程
my $pid = fork;
# (3) flock $fh, LOCK_EX;
unless($pid){
# 子进程
open $fh1, ">", "a.log";
close $fh; # close(1)
# flock $fh1, LOCK_SH;
}
# 父进程
# (2) flock $fh, LOCK_EX;
close $fh; # close(2)
操作系统层次的IO
sysopen()
open()和sysopen()都打开文件句柄,open()是比较高层次的打开文件句柄,sysopen()相对要底层一点。但它们打开的文件句柄并没有区别,只不过sysopen()有一些自己的特性:可以使用几个open()没有的flag,可以指定文件被创建时的权限等。
一定要注意的是,io buffer和open()、sysopen()无关,而是和读、写的方式有关,例如read()、getc()以及行读取都使用io buffer,而sysread、syswrite则直接绕过io buffer。
例如:
sysopen HANDLE, "file.txt", O_RDONLY;
open HANDLE, $filename, O_WRONLY|O_CREAT, 0644;
open HANDLE, $filename, O_WRONLY|O_CREAT, S_IRUSR|S_IWUSR|S_IRGRP|S_IROTH;
其中sysopen支持的flag部分有以下几种:
# 三种基本读写模式
O_RDONLY、O_RDWR、O_WRONLY
# 配合基本读写模式的额外模式
O_APPEND
O_TRUNC
O_CREAT
O_EXCL 只能配合CREAT使用,只有文件不存在时才创建,文件存在时直接失败而不是打开它
O_BINARY 二进制模式,表示不做换行符转换
O_TEXT 文本模式,表示做换行符转换
O_NONBLOCK 非阻塞模式
O_NDELAY 同上,另一种表示方式,为了可移植性,建议使用上面的模式
非阻塞读写
sysopen()比open()多出的一个好用的特性就是O_NONBLOCK;在使用非阻塞的IO时,可以在等待过程中去执行其它任务。但是需要明确一点,对于普通文件的读写,如果没有使用文件锁,那么没有必要使用O_NONBLOCK,因为内核缓冲区的存在使得对普通文件的读写不可能会出现阻塞问题。例如:
use Fcntl;
open HANDLE, '/dev/ttyS0', O_RDONLY | O_NONBLOCK;
# sysread一个字符,但不会阻塞
my $key;
while(sysread HANDLE, $key, 1){
if (defined $key){
print "got $key\n";
}else{
do other tasks;
}
sleep 1;
}
close HANDLE;
O_NONBLOCK在无法成功返回时,将返回EAGAIN,并设置给$!变量。所以更优写法如下:
use Fcntl;
open HANDLE, '/dev/ttyS0', O_RDONLY | O_NONBLOCK;
# sysread一个字符,但不会阻塞
my $key;
while(sysread HANDLE, $key, 1){
if (defined $key){
print "got $key\n";
}else{
if($! == 'EAGAIN'){
do other tasks;
sleep 1;
}else{
warn "Error read: $!";
last;
}
}
}
close HANDLE;
IO::File自动探测(sys)open
使用IO::File模块的new()方法可以根据提供的参数方式自动探测要调用open()还是sysopen()来打开文件句柄:
1.如果使用字符串的模式(< > >> +> +< +>>),则调用open()
2.如果使用数值格式或O_XXX或使用了权限位,则调用sysopen()
例如:
# open()
my $fh = IO::File->new($filename, "+<");
# sysopen()
my $fh = IO::File->new($filename, O_RDWR);
my $fh = IO::File->new($file, O_RDWR, 0644);
sysread()
sysread()实现操作系统层的读操作,它通过read()系统调用直接读取文件描述符,会直接绕过IO Buffer层。
sysread FILEHANDLE,SCALAR,LENGTH,OFFSET
sysread FILEHANDLE,SCALAR,LENGTH
表示从FILEHANDLE文件句柄中读取LENGTH字节长度的数据保存到标量SCALAR中,如果指定了OFFSET,则从标量的OFFSET位置处开始写入读取到的数据。sysread()的返回值是读取到的字节数。下面是一个结合O_NONBLOCK修饰符的sysread()。
use strict;
use warnings;
use Fcntl;
sysopen my $fh, $ARGV[0], O_RDONLY | O_NONBLOCK or die "open failed: $!";
my $data;
my $size = sysread $fh, $data, 20;
if ($size == 20 ){
# 已读取20字节
# 继续读取30字节追加到$data尾部
$size += sysread $fh, $data, 30, 20;
print "已读数据为: $data\n";
if($size < 50){
print "文件大小为$size,数据不足50字节\n";
}else{
print "已读字节数:$size\n";
}
}elsif($size > 0) {
print "文件大小为$size,数据不足20字节\n";
}else{
print "空文件\n";
}
在上面的代码中,主要是sysread()和O_NONBLOCK需要解释下。如果没有O_NONBLOCK,那么sysread()在读取不到20字节、50字节时将被阻塞等待。但现在的情况下,如果数据不足20、50字节时,sysread()将直接返回,并返回读取到的字节数(小于20或30)。
这里如果sysread()替换成read(),它们的区别是,sysread()只读取20或50字节数据,不会多读任何一个字节,而read()则可能多读一些数据到IO Buffer中,但是只取其中的20或50字节,剩余的数据遗留在IO Buffer中。
于是文件IO的指针就出现了不同值,对于sysread,他的指针就是20或50位置处,但是read()读取数据时,底层的文件指针将可能出现在1000字节处,但IO buffer中的IO指针将在20或50处。根据这个差值,可以计算出IO Buffer中保存了多少字节的数据。见后文sysseek()。
最后注意,不存在syseof()这样的函数来判断是否读取到了文件的结尾。但可以通过读取数据的返回值(即读了多少字节)来判断是否到了文件结尾。
syswrite()
syswrite()实现操作系统层的写操作,它通过write()系统调用直接向文件描述符中写入数据,它会直接绕过IO Buffer层。
syswrite FILEHANDLE,SCALAR
syswrite FILEHANDLE,SCALAR,LENGTH
syswrite FILEHANDLE,SCALAR,LENGTH,OFFSET
如果只有两个参数,则直接将标量SCALAR代表的数据写入到FILEHANDLE中,如果指定了LENGTH,则从SCALAR中取LENGTH字节长度的数据写入到FILEHANDLE中,如果指定了OFFSET,则表示从标量的OFFSET处开始截取LENGTH长度的数据写入到FILEHANDLE中。OFFSET可以指定为负数,这表示从尾部开始数写入OFFSET个字节的数据。如果LENGTH大于从OFFSET开始计算可以获取到的数据,则能获取到多少数据就写入多少数据。
syswrite()返回实际写入的字节数,如果出错了则返回undef,例如:
# 写入abcdef
syswrite STDOUT, "abcdef";
# 写入abc
syswrite STDOUT, "abcdef", 3;
# 写入cde
syswrite STDOUT, "abcdef", 3, 2;
# 写入cde
syswrite STDOUT, "abcdef", 3, -4;
实际上,不使用syswrite(),直接使用print也可以绕过io buffer,但前提是设置文件句柄的IO层为unix层,因为unix层是文件句柄到文件描述符的最底层,它会禁用所有上层,包括buffer。
binmod(FILEHANDLE, ":unix");
例如下面的例子中,在10秒内将每秒输出一个点,如果把binmode那行删除,将在10秒之后一次性输出10个点。如果删除binmode,还可以将print "."改为syswrite STDOUT, ".";,它将同样每秒输出一个点。
binmode(STDOUT, ":unix");
for (0..9){
print "."; # syswrite STDOUT, ".";
sleep 1;
}
print "\n";
sysseek()
sysseek FILEHANDLE,POSITION,WHENCE
sysseek()通过lseek()系统调用设置或返回IO指针的位置,它直接绕过IO Buffer操作文件描述符。它和seek()的语法上没什么区别:
# seek using whence numbers
sysseek HANDLE, 0, 0; # rewind to start
sysseek HANDLE, 0, 2; # seek to end of file
sysseek HANDLE, 20, 1; # seek forward 20 characters
# seek using Fcntl symbols
use Fcntl qw(:seek);
sysseek HANDLE, 0, SEEK_SET; # rewind to start
sysseek HANDLE, 0, SEEK_END; # seek to end of file
sysseek HANDLE, 20, SEEK_CUR; # seek forward 20 characters
sysseek()返回设置IO指针位置后的新位置。例如原来IO指针位置为第三个字节处,向前移动5字节后,sysseek()将返回8。所以,可以通过sysseek()来实现tell()函数的功能,只需将sysseek()相对于当前位置移动0字节即可:
sysseek(HANDLE, 0, SEEK_CUR);
除了绕过IO buffer,sysseek()和seek()基本相同。但正是它绕过了io buffer,导致了sysseek()和tell()的结果可能大不一样,tell()获取的是IO Buffer中IO指针的位置,而sysseek(HANDLE, 0, SEEK_CUR)获取的是文件描述符层次的IO指针位置。所以在使用IO Buffer类的读函数时,可以通过sysseek() - tell()计算出缓冲在IO Buffer中的数据比缓冲在page cache中的数据少多少字节。这种额外缓冲一些数据到page cache的行为称为"预读"(readahead()),它带来的好处是可能会减少后续读操作阻塞的时间。
下面是一个说明tell()和sysseek()区别的示例:
use strict;
use warnings;
use 5.010;
use Fcntl q(:seek);
open my $fh, "<", "abc.log";
my $readed;
read $fh, $readed, 5;
print "tell pos: ", tell($fh);
print "sysseek pos: ", sysseek($fh, 0, SEEK_CUR);
向abc.log中写入10个字节(实际为11个字节,因为echo自动加换行符)的数据:
$ echo "0123456789" >abc.log
执行上面的Perl程序:
tell pos: 5
sysseek pos: 11
上面的程序中,使用read()函数读取了5个字节数据,但是read()是使用IO Buffer的,它会从磁盘文件中多读取一些数据放到page cache中,例如这里最多只能读11字节到page cache,然后从page cache中读取指定数量5字节的数据到IO buffer中供read读取并保存到$readed标量中。因为文件描述符已经读取了11个字节的数据,所以sysseek()的返回值为11,而tell()则是io buffer中读取数据的位置,即5字节。所以在read()结束后,page cache中还剩下6字节的数据供后续读操作放入到io buffer中。
Perl官方的函数手册页中指出:tell()函数不要对sysread()、syswrite()或sysseek()操作过的文件句柄使用tell()(或其他缓冲I/O操作)。这些函数会忽略缓冲,而tell()则不会。
sysseek()绕过正常缓冲IO,因此将其与sysread以外的操作句柄(例如<>或read())方法如:print、write、seek、tell或eof混合可能会导致混淆。
IO::Handle:sync()
从perl的文件句柄到操作系统的文件描述符,再从文件描述符到设备上的实体文件,两个层次之间都有各自的buffer层。
+--------------------------+
| FileHandle |
+--------------------------+
|
| Perl IO Buffer
v
+--------------------------+
| File Description |
+--------------------------+
|
| page cache/buffer cache
v
+--------------------------+
| (dev)disk |
+--------------------------+
其中文件描述符是操作系统的资源,从文件描述符到硬件设备之间的缓冲(page cache),可以通过fsync()来刷,但Perl文件句柄层的IO Buffer,操作系统显然不负责这个属于Perl IO的上层缓冲。
Perl的IO::Handle中提供了刷缓冲的方法:
flush():将Perl IO Buffer中的数据刷到文件描述符
IO Buffer中未读取完的数据被丢弃
IO Buffer中未写入完成的数据立即写入到文件描述符,写入完成后flush才成功
sync():实现和系统调用fsync()相同的功能,将文件描述符到设备文件之间的缓冲刷盘
本文总结自骏马金龙的个人博客,感谢原作者。