perl使用write函数来格式化(Format)报表输出
 perl有最好的文本数据处理能力,这是大家都知道的。它有一个相当于简单的命令行报表和图表输出,这个需要先声明格式:创建格式的文件句柄.然后由@,^,<,>,|这样的字符构成所谓的”报表格式”来输出图表。这样可以指定出行的外观,后面接数据项,最后用write来显示格式化的内容。
perl有最好的文本数据处理能力,这是大家都知道的。它有一个相当于简单的命令行报表和图表输出,这个需要先声明格式:创建格式的文件句柄.然后由@,^,<,>,|这样的字符构成所谓的”报表格式”来输出图表。这样可以指定出行的外观,后面接数据项,最后用write来显示格式化的内容。样例:
输出纪录格式输出象下边一样定义:
format NAME =
FORMLIST
.
第一部分,声明.如上.如果省略 NAME,上面的代码将定义格式输出 STDOUT。
第二部分,格式行FORMLIST 由一些有序的行组成,每一行都是下面三种类型中的一种:
1. 注释,以第一列为 # 来表示.
2. 一个格式行,用来定义一个输出行的格式,就是指上面讲的@,^,<,>,|这样的字符
3. 参数行,数据行,用来向前面的格式行中插入值,都是perl的变量
第三部分, 结束 “.”来表示.
格式行语法:
格式行中每个被替换的部分分别以 @ 或者 ^ 开头,这些行不作任何形式的变量代换。@ 字段(不要同数组符号 @ 相混淆)是普通的字段。
<, >,| 字段的长度通过在格式符号 @,^ 后跟随特定长度的 <, >,| 来定义,同时<,>,| 还分别表示,左对齐,右对齐,居中对齐。如果变量超出定义的长度,那么它将被截断。
^ 字段,用来进行多行文本块填充。
简单示例如下:
$text = "aaa bbb ccc";
format STDOUT =
first: ^<<<<
$text
second: ^<<<<
$text
third: ^<<<<
$text
.
write
这样它会输出如下:
first: aaa
second: bbb
third: ccc
它默认会对字符串$text进行分解,如split。当然是以$:的内容做分割符。
#(在 @ 或 ^ 后边) 右对齐的另外一种方式,在这些符号后面指定一个数字字段。你可以在这种区域中插入一个,来制定小数点的位置。如果这些区域的值包含一个换行符,那么只输出换行符前面的文本。如@.##就是输出二位小数。@* 可以被用来打印多行不截断的值,也就是多行没有格式化的输出。
格式 值域含义
@<<< 左对齐输出
@>>> 右对齐输出
@||| 中对齐输出
@##.## 固定精度数字
@* 多行文本
参数数据行
参数行指定参数的顺序必须跟相应的格式行的字段顺序一致,不同参数的表达式需要使用逗号分隔。
参数的数据可以是标量数据,也可以是函数的返回值。
参数行被处理之前所有的参数表达式都在列表环境中求值,因此单个列表表达式会产生多个列表元素。
通过使用圆括弧将表达式括起来,可以使表达式扩展到多行 (因此圆括弧必须是第一行的第一个标志)。这样就可以将值同相应的格式域对应起来方便阅读。
表达式中,空白字符 \n,\t,和 \f 总是被解释成单个空格
格式变量说明及其默认值
$~ 中 ($FORMAT_NAME) 当前格式名字(STDOUT)
$^ ($FORMAT_TOP_NAME) 当前页顶(STDOUT_TOP)
$% ($FORMAT_PAGE_NUMBER) 当前页号(0)
$= ($FORMAT_LINES_PER_PAGE) 每页中的行数(60)
$| ($FORMAT_AUTOFLUSH) 是否自动刷新输出缓冲区存储
$^L ($FORMAT_FORMFEED) 在每一页(除了第一页)表头之前需要输出的字符串存储在,即文件开始输出到新页(\f)
$: ($FORMAT_LINE_BREAK_CHARACTERS) 应开始分为多行的字符数(- \n)
注:这些变量以文件句柄为基础设定,因此需要 select 与特定格式关联的文件句柄来影响这些格式变量。解析如下:
调用输出
write
最后直接用write函数来显示格式化的文本内容。
多页报表
$% 当前输出的页面编号
$= 页中的行数
$- ($FORMAT_LINES_LEFT) 当前页还有多少剩下的行数(0)
在使用输出时,最好建一个表的顶部输出,这样看起来会好看很多。
下例将输出本地密码文件中用户信息,以报表的方式输出。
use v5.12;
my ($login,$pwd,$uid,$gid,$name,$home,$shell);
open FD,"</etc/passwd" or die "$?";
while(<FD>){
($login,$pwd,$uid,$gid,$name,$home,$shell)=split (":",$_);
$^ = 'STDOUT_TOP';
$~ = 'STDOUT';
$= = 14; #设置每页的行数
write;
}
format STDOUT_TOP =
@>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
"Page $%"
Passwd File
Login Pwd Uid Gid Name Home Shell
------------------------------------------------------------------
.
format STDOUT =
@<<<<<<<<<<<<@||||||| @<<<<<<@>>>> @>>>>>>>>>> @<<<<<<<<<<<< @<<<<<<<<<
$login,$pwd,$uid,$gid,$name,$home,$shell
.
format STDOUT =
@<<<<<<<<<<<<<<<<<< @||||||| @<<<<<<@>>>> @>>>> @<<<<<<<<<<<<<<<<<
$name,$login,$office,$uid,$gid, $home
.
在部分较长字段时,显示还有些纷乱。不过看上看像专业工具输出的那样。再给出一个从数据库读出数据显示的例子:
use v5.12;
use utf8;
use DBI;
use Encode;
use Time::Piece;
use Data::Dumper;
binmode(STDIN, ":encoding(utf8)");
binmode(STDOUT, ":encoding(utf8)");
# Init&Conn mysql db
my ($db,$dbhost,$dbuser,$dbpaswd)=('wcd','192.168.0.9','dbuser','freeoa.net');
#mysql obj attr
my %mydbattr=(RaiseError=>1, AutoCommit=>0,mysql_enable_utf8=>1,RaiseError=>1);
my ($id,$title,$alias,$issuedt,$hits);
#create database handle
my $dbh=DBI->connect_cached("DBI:mysql:database=$db;host=$dbhost",$dbuser,$dbpaswd,\%mydbattr) or die $DBI::errstr;
my $sth=$dbh->prepare("select id,title,alias,issue_dt,hits from freeoa.content limit 35;",{Slice => {}});
$sth->execute;
while (my $rec=$sth->fetchrow_hashref){
($id,$title,$alias,$issuedt,$hits)=($rec->{id},$rec->{title},$rec->{alias},$rec->{issue_dt},$rec->{hits});
$^ = 'STDOUT_TOP';
$~ = 'STDOUT';
$= = 15;
write;
}
format STDOUT_TOP =
@>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
"Page $%"
文章列表
ID Title Alias Issue-DT Hits
--------------------------------------------------------------------------------------------------------------
.
format STDOUT =
@|||| @<<<<<<<<<<<<<<<<< @<<<<<<<<<<<<<<<<< @>>>>>>>>>>>>>>>>>>> @<<<<
$id,$title,$alias,$issuedt,$hits
.
END {
$dbh->disconnect;
}
输出样式如下:
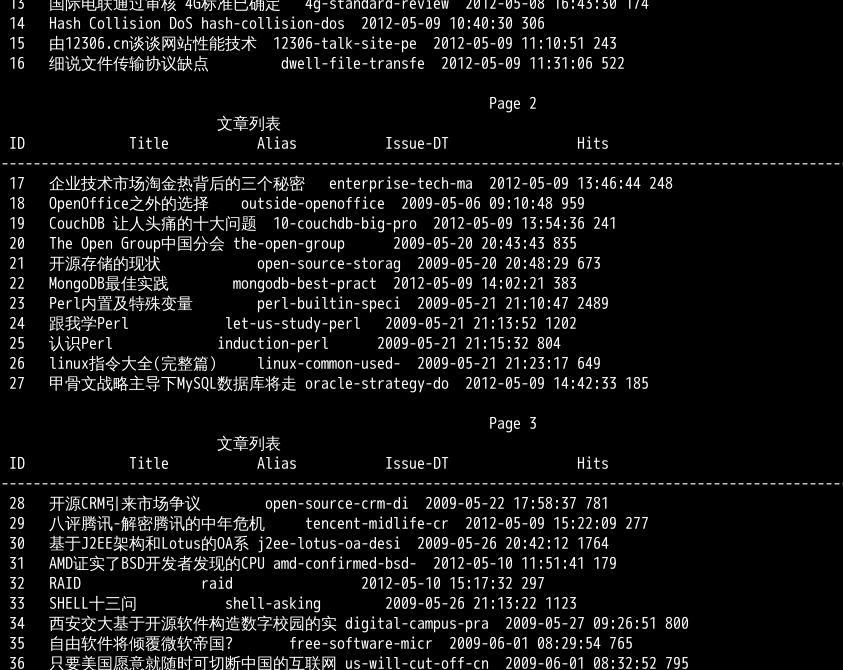
write 函数
write FILEHANDLE
write
这个函数写一条格式化了的记录(可能是多行)到声明的文件句柄,使用和该文件句柄相关联的 格式——参阅第七章里的“格式变量”一节。缺省时与文件句柄相关联的格式是和文件句柄同名的 那个。不过,一个文件句柄的格式可以在你 select 了该句柄以后修改 $~ 变量来修改:
$old_fh = select(HANDLE);
$~ = "NEWNAME";
select($old_fh);
或者说:
use IO::Handle
HANLDE->format_name("NEWNAME");
因为格式是放到一个包名字空间里的,所以如果该 format 是在另外一个包里声明的,那么你可能 不得不用该格式的全称:
$~ = "OtherPack::NEWNAEM";
表单顶部(Top-of-form)的处理是自动操作的:如果当前页里面没有足够的空间容纳格式化的 记录,那么通过写一个进纸符来续该页,这时候在新页上使用一个特殊的表单顶部格式,然后写该 记录。在当前页里余下的行数放在变量 $- 里,你可以把它设置为 0 以强迫在下一次 write 的 时候使用新的一页。(你可能先得 select 该文件句柄。)缺省时,页顶格式的名字就是文件句柄 后面加上 "_TOP",不过,一个文件句柄的格式可以在你 select 了该句柄以后修改 $~ 变量来 修改,或者说:
use IO::Handle;
HANDLE->format_top_name("NEWNAME_TOP");
如果没有声明 FILEHANDLE,那么输出就会跑到当前缺省的输出文件句柄,这个文件句柄初始时是 STDOUT,但是可以用单参数形式的 select 操作符修改。如果 FILEHANDLE 是一个表达式,那么 在运行时计算该表达式以决定实际的 FILEHANDLE。
如果声明的 format 或者当前的页顶 format 并不存在,那么抛出一个例外。糟糕的是,write 函数不是 read 的逆操作。用 print 做简单的字串输出。如果你找到这个函数 的原因是因为你想绕开标准 I/O,参阅 syswrite。
参考来源:
Perl5学习笔记-第十章-格式化输出
perlform
write