数据压缩算法-DEFLATE
 DEFLATE是同时使用了LZ77算法与哈夫曼编码(Huffman Coding)的一个无损数据压缩算法。它最初是由Phil Katz为他的PKZIP归档工具第二版所定义的,后来定义在RFC1951规范中。
DEFLATE是同时使用了LZ77算法与哈夫曼编码(Huffman Coding)的一个无损数据压缩算法。它最初是由Phil Katz为他的PKZIP归档工具第二版所定义的,后来定义在RFC1951规范中。人们普遍认为DEFLATE不受任何专利所制约,并且在LZW(GIF文件格式使用)相关的专利失效之前,这种格式除了在ZIP文件格式中得到应用之外也在Gzip压缩文件以及PNG图像文件中得到了应用。
DEFLATE压缩与解压的源代码可以在自由、通用的压缩库zlib上找到。更高压缩率的DEFLATE是7-zip所实现的。AdvanceCOMP也使用这种实现,它可以对gzip、PNG、MNG以及ZIP文件进行压缩从而得到比zlib更小的文件大小。在Ken Silverman的KZIP与PNGOUT中使用了一种更加高效同时要求更多用户输入的DEFLATE程序。
关于无损数据压缩
无损数据压缩(Lossless Compression)指数据经过压缩后,信息不受损失,还能完全恢复到压缩前的原样。“无损”一词是相对于有损数据压缩,有损数据压缩只允许一个近似原始数据进行重建,以换取更好的压缩率。
在理解deflate之前, 先理解它的两个组成算法非常重要:Huffman 编码 和 LZ77压缩。
LZ77 算法
LZ77压缩算法靠查找重复的序列. 这里使用术语:”滑动窗口”,它的意思是:在任何的数据点上,都记录了在此之前的字符.32k的滑动窗口表示压缩器(解压器)能记录前32768个字符. 当下一个需要压缩的字符序列能够在滑动窗口中找到, 这个序列会被两个数字代替: 一个是距离,表示这个序列在窗口中的起始位置离窗口的距离, 一个是长度, 字符串的长度.数据被分割成不同的块, 每个块使用单一的压缩模式.如果压缩器要在这三种压缩模式中相互切换, 必须先结束当前的块, 重新开始一个新的块.
一、LZ77算法基本概念
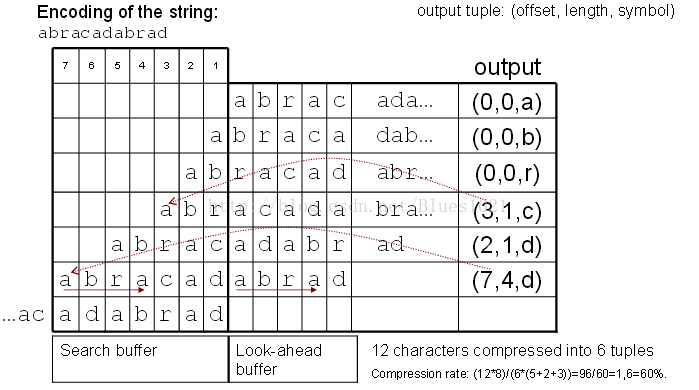
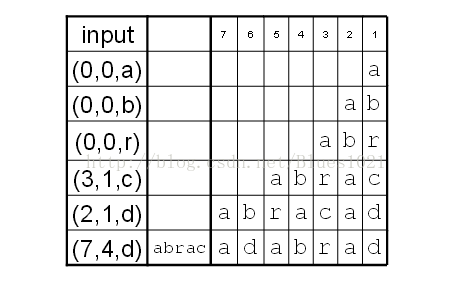
LZ77算法的说明网上很多,本文为个人见解,仅供参考。LZ77算法其实是字典压缩的一个变种,与字典压缩不同的是,它的字典是动态生成的并且只有一个,一般选取一定数量的最近压缩过数据。保存这些数据的结构叫做滑动窗口,所以LZ77有被常称作滑动窗口算法。至于这么生成字典的原因,其实很简单,因为我们认为一个要压缩的字符串很有可能与上下 文相关,也就是说很有可能在刚压缩的字符串中出现过。要压缩的字符串会与滑动窗口中的字符匹配并用三元组的形式来表示,以下的一个 LZ77的压缩例子,能很好的说明此算法的流程,这个例子网上有,本文只是更通俗易懂的展现之。
有一个要压缩的串abcdbbccaaabaeaaabaee
假设前面10个字符已经被压缩,并且设置滑动窗口为10个字符。
| 窗口 | 未压缩 | 相同字符串 | 相同字符串起始位置 | 相同字符串长度 | 相同字符串后一字符 | 压缩码 |
| abcdbbccaa | abaeaaabaee | ab | 0 | 2 | a | (0,2,a) |
| dbbccaaaba | eaaabaee | null | 0 | 0 | e | (0,0,e) |
| bbccaaabae | aaabaee | aaabae | 4 | 6 | e | (4,6,e) |
压缩码为(0,2,a)(0,0,e)(4,6,e)
算法其实原理就是这,至于后续工作请查阅其他资料。
加密和解压
压缩过程:

解压过程:

二、LZ77优化
使用可变偏移和长度域的元组相比固定长度的元组会更好,在小偏移和大小比较小的编码中会比较有优势。
当字符没有找到的时候不要输出(0,0,x),而是使用0|x或1|0的形式。
使用更加合适的结构体(例如tree,hash set)作为Search buffer或Look ahead buffer,这样可以允许更快的搜索或者更大的缓存。
给元组或者引用加上Huffman 编码,例如LZSS,LZB,LZH,LZR,LZFG,LZMA,Deflate压缩算法等。
改进的LZ77算法+Huffman算法压缩
gzip对于要压缩的文件,首先使用lz77算法进行压缩,对得到的结果再使用huffman编码的方法进行压缩。gzip的LZ77用了哈希容器。
三、Huffman编码
霍夫曼编码模型:思想是压缩数据出现概率高的用短编码,出现概率低的用长编码,且每个字符编码都不一样。压缩数据单个字符出现的概率抽象为叶子节点的权值,huffman树叶子节点到根节点的编码(是父节点左子节点那么填0,否则填1)
作为字符的唯一编码实现时候需要注意的规则:
1)最左的放置在左边,作为父节点的左节点。
2)每次都从没有设置父节点的所用节点中(叶子和分支节点一样对待),从数组小下标到大下标优先顺序遍历。
3)当前搜寻的次数i + n作为新生成的分支节点的数组下标。
实现的过程和具体算法思想:
两个数据结构:
一个是huffman树节点结构体,一个是从霍夫曼树叶子节点编码的结构体。
两个处理过程:
1)建立huffman树:
基本思想是:对于没有设置父节点的节点集选出最小的两个,最小的放置在左边,次小的放置在右边
设置好父节点和左右子节点关系,方便获得霍夫曼编码。
2) 从huffman树得到叶子节点的huffman编码:
基本思想:对于建立好的Huffman树的每个叶子节点,由编码的数组的末端也是从叶子节点最底端,往上遍历
如果是父节点的左节点那么用编码数组填1,如果是父节点的右节点那么编码数组填0,一直往上追溯到根节点。
四、deflate无损压缩解压算法(先Lz77压缩,然后huaffman编码)
deflate是zip压缩文件的默认算法,其实deflate现在不光用在zip文件中, 在7z, xz等其他的压缩文件中都用。实际上deflate只是一种压缩数据流的算法,任何需要流式压缩的地方都可以用。
deflate算法下的压缩器有三种压缩模型:
1. 不压缩数据, 对于已经压缩过的数据,这是一个明智的选择. 这样的数据会会稍稍增加, 但是会小于在其上再应用一种压缩算法.
2. 压缩, 先用Lz77, 然后用huffman编码. 在这个模型中压缩的树是Deflate 规范规定定义的, 所以不需要额外的空间来存储这个树.
3. 压缩, 先用LZ77, 然后用huffman编码. 压缩树是由压缩器生成的, 并与数据一起存储.
数据被分割成不同的块, 每个块使用单一的压缩模式. 如过压缩器要在这三种压缩模式中相互切换, 必须先结束当前的块, 重新开始一个新的块.
关于Lz77和huffman如何一起工作的细节需要更进一步的检查. 一旦原始数据被转换成了字符和长度距离对组成的串, 这些数据必须由huffman编码表示.
deflate中的解压:
读取二进制文件,构建huffmantree表,读取数据根据huffmantree生成字符(这些字符是符合LZ77算法的)。用LZ77解码,这个时候应该需要对窗口生成哈希表(数组+链表);对解压的数据,进行搜索匹配拷贝替换为相应的串即可。
gzip源码分析
main()中调用函数 treat_file()。
treat_file()中打开文件,调用函数 zip()。注意这里的 work的用法,这是一个函数指针。
zip()中输出gzip文件格式的头,调用 bi_init,ct_init,lm_init,其中在lm_init中将 head初始化清0。初始化strstart为0。从文件中读入64KB的内容到window缓冲区中。
由于计算strstart=0时的ins_h,需要0,1,2这三个字节和哈希函数发生关系,所以在lm_init中,预读0,1两个字节,并和哈希函数发生关系。
然后lm_init调用 deflate()。
deflate() gzip的LZ77的实现主要deflate()中。
GZIP ZLIB DEFLATE 文件格式
GZIP最早由Jean-loup Gailly和Mark Adler创建,用于UNIX系统的文件压缩。我们在Linux中经常会用到后缀为.gz的文件,它们就是GZIP格式的。现今已经成为Internet上使用非常普遍的一种数据压缩格式,或者说一种文件格式。HTTP协议上的GZIP编码是一种用来改进WEB应用程序性能的技术,大流量的WEB站点常常使用GZIP压缩技术来让用户感受更快的速度。
GZIP本身只是一种文件格式,其内部通常采用DEFLATE数据格式,而DEFLATE采用LZ77压缩算法来压缩数据。
GZIP文件由1到多个“块”组成,实际上通常只有1块。每个块包含头、数据和尾三部分,块的内部结构如下:
+---+---+---+---+---+---+---+---+---+---+========//========+===========//==========+---+---+---+---+---+---+---+---+
|ID1|ID2| CM|FLG| MTIME |XFL| OS| 额外的头字段 | 压缩的数据 | CRC32 | ISIZE |
+---+---+---+---+---+---+---+---+---+---+========//========+===========//==========+---+---+---+---+---+---+---+---+
1. 头部分
ID1与ID2:各1字节。固定值,ID1 = 31 (0x1F),ID2 = 139(0x8B),指示GZIP格式。 CM:1字节。压缩方法。目前只有一种:CM = 8,指示DEFLATE方法。 FLG:1字节。标志。
bit 0 FTEXT - 指示文本数据
bit 1 FHCRC - 指示存在CRC16头校验字段
bit 2 FEXTRA - 指示存在可选项字段
bit 3 FNAME - 指示存在原文件名字段
bit 4 FCOMMENT - 指示存在注释字段
bit 5-7 保留
MTIME:4字节。更改时间。UINX格式。 XFL:1字节。附加的标志。当CM = 8时,XFL = 2 - 最大压缩但最慢的算法;XFL = 4 - 最快但最小压缩的算法 OS:1字节。操作系统,确切地说应该是文件系统。有下列定义:
0 - FAT文件系统 (MS-DOS, OS/2, NT/Win32)
1 - Amiga
2 - VMS/OpenVMS
3 - Unix
4 - VM/CMS
5 - Atari TOS
6 - HPFS文件系统 (OS/2, NT)
7 - Macintosh
8 - Z-System
9 - CP/M
10 - TOPS-20
11 - NTFS文件系统 (NT)
12 - QDOS
13 - Acorn RISCOS
255 - 未知
额外的头字段:
(若 FLG.FEXTRA = 1)
+---+---+---+---+===============//================+
|SI1|SI2| XLEN | 长度为XLEN字节的可选项 |
+---+---+---+---+===============//================+
(若 FLG.FNAME = 1)
+=======================//========================+
| 原文件名(以NULL结尾) |
+=======================//========================+
(若 FLG.FCOMMENT = 1)
+=======================//========================+
| 注释文字(只能使用iso-8859-1字符,以NULL结尾) |
+=======================//========================+
(若 FLG.FHCRC = 1)
+---+---+
| CRC16 |
+---+---+
存在额外的可选项时,SI1与SI2指示可选项ID,XLEN指示可选项字节数。如 SI1 = 0x41 ('A'),SI2 = 0x70 ('P'),表示可选项是Apollo文件格式的额外数据。
2. 数据部分
DEFLATE数据格式,包含一系列子数据块,子块大致如下:
+......+......+......+=============//============+
|BFINAL| BTYPE | 数据 |
+......+......+......+=============//============+
BFINAL:1比特。0 - 还有后续子块;1 - 该子块是最后一块。 BTYPE:2比特。00 - 不压缩;01 - 静态Huffman编码压缩;10 - 动态Huffman编码压缩;11 - 保留。
各种情形的处理过程,请参考后面列出的RFC文档。
3. 尾部分
CRC32:4字节。原始(未压缩)数据的32位校验和。ISIZE:4字节。原始(未压缩)数据的长度的低32位。
GZIP中字节排列顺序是LSB方式,即Little-Endian,与ZLIB中的相反。
GZIP与ZLIB有着很深的渊源。有关ZLIB, GZIP以及DEFLATE等更加详细的说明,可参考RFC 1950-1952,从这些文档里也能找到其它的参考文献。
GZIP已成为GNU Project的一个组成部分。
附件:
[pdf]LZ77.JensMueller
C库:libdeflate
libdeflate 是一个用 C 语言编写的高性能库,专门用于快速的全缓冲区 DEFLATE 压缩和解压缩。它经过深度优化,在性能上通常显著优于广泛使用的 zlib 库。
核心特性与格式支持
libdeflate 支持以下三种基于 DEFLATE 算法的压缩格式:
DEFLATE (原始格式)
zlib (带有 zlib 包装的 DEFLATE)
gzip (带有 gzip 包装的 DEFLATE)
除了速度快,它还提供了可选的高压缩模式,其压缩比甚至能超过 zlib 的最高压缩等级(level 9)。
安装与使用
安装库文件 在 Debian/Ubuntu 等基于 Debian 的 Linux 发行版上,可以使用 apt 包管理器轻松安装。
# 安装核心库
apt update && apt install libdeflate0
开发文件:如果需要开发基于 libdeflate 的应用程序,请额外安装 libdeflate-dev 包,它包含了编译时所需的头文件和链接库。
命令行工具:libdeflate-tools 包提供了 libdeflate-gzip 和 libdeflate-gunzip 等命令行工具,可以作为标准 gzip 工具在某些场景下的替代品,但请注意它们可能不支持 GNU gzip 的所有不常用选项。
基本使用流程 使用 libdeflate 编程通常遵循以下步骤:
创建压缩器/解压器:调用库函数(如 libdeflate_alloc_compressor())初始化。
执行操作:调用相应的压缩(如 libdeflate_gzip_compress())或解压函数。
清理资源:操作完成后,使用 libdeflate_free_compressor() 释放资源。
应用场景
libdeflate 的高性能特性使其适用于多种场景:
数据存储:压缩文件或数据库记录以节省存储空间。
网络传输:压缩 HTTP 响应等网络数据,提升传输效率。
日志处理:实时压缩日志流,降低磁盘 I/O 压力。
软件开发:作为嵌入式压缩组件,用于游戏、工具软件等。
与其他库的对比
libdeflate 的设计目标是提供比 zlib 更快的实现。根据官方信息和相关测试,它在压缩和解压缩速度上都显著快于 zlib,尤其在 x86 架构的处理器上优势更为明显。