64位ARM处理器(AArch64)意味着什么
 64位计算的历史相当丰富有趣。Cray等公司在70年代就已经开始在自己的系统当中使用64位寄存器,但真正纯粹的64位计算直到90年代才真正到来。首先是MIPS的R4000,然后是DEC的Alpha处理器。到90年代中期,英特尔和Sun都已经拥有64位设计。而对于消费者来说,真正的转折点是AMD在2003年发布了一款兼容英特尔32位x86处理器的64位PC处理器。
64位计算的历史相当丰富有趣。Cray等公司在70年代就已经开始在自己的系统当中使用64位寄存器,但真正纯粹的64位计算直到90年代才真正到来。首先是MIPS的R4000,然后是DEC的Alpha处理器。到90年代中期,英特尔和Sun都已经拥有64位设计。而对于消费者来说,真正的转折点是AMD在2003年发布了一款兼容英特尔32位x86处理器的64位PC处理器。
再向前快进10年,PC销量不断下滑,大部分智能手机和平板电脑都拥有了主频在1-2GHz之间的多核心处理器。但它们使用的都是32位架构,而非现代PC 和服务器所使用的64位架构。到现在为止,这都是可以接受的。智能手机并不会去和PC拼性能,这些处理器需要足够节能,以实现续航的最大化。但随着设备的发展和新技术——语音识别、3D游戏和高分辨率显示屏——逐渐普及,32位处理器的能力已经渐渐被推到了极限。

ARM 看到了64位节能处理器的需求,并在正式发布ARMv8-A架构(首个包含64位指令集的ARM架构)之前就早早开始了新设计的开发,还从其他选择发展 64位技术的芯片设计厂商那里学习到了经验和教训。ARM的新款64位架构具备对于旗下32位架构的全面兼容,这意味着如果处理器运行于64位系统,它就可以运行未修改的ARMv7 32位二进制文件。对于Android来说,这意味着一旦内核被移植到64位(多亏了Linaro,它们已经如此了),系统的其余部分,从核心库到应用再 到游戏,都是可以在32位或64位之间进行切换的。
去年,苹果凭借着iPhone 5s的全新64位A7处理器震惊了整个移动领域。A7采用了苹果设计的ARMv8双核处理器,名为Cyclone。它使用了两个64KB L1缓存(供两个核心分别使用),一个1MB L2缓存(被两个核心所分享)和一个4MB L3缓存(为整个SoC所用)。苹果拥有ARM架构授权,这意味着它可以从头开始设计自己的处理器,但前提是这些处理器必须是ARM兼容的。ARM拥有一套测试套件,用以检查这些处理器是否具备兼容性。
在未来几个月里将会看到高通、联发科和三星纷纷推出自己的64位ARM处理器。再考虑到Android在64位化的努力,用不了多久我们就将看到运行于64位Android系统的64位设备了。但对于开发者和终端用户来说,64位处理器意味着什么呢?
受益于ARM的64位架构
每一部CPU的中心都是一套寄存器,他们都是用以存储数字和地址的内部存储插槽。当执行复杂任务时,这些插槽会被反复使用。如果所有的寄存器都处于占用状态,那么处理的唯一方式是将其中一个寄存器存储在内存当中,使用寄存器进行下一个任务,然后再从内存当中重新载入之前的值。对于人类来说,这一切都发生在一瞬间。但对于处理器来说,这实际上是一个非常耗时的顺序,并不十分效率。
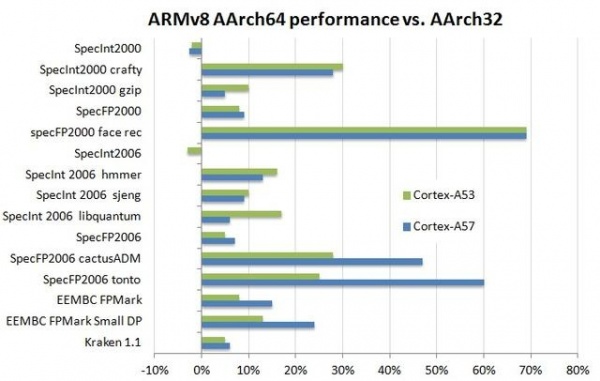
32位ARMv7架构拥有15个通用的寄存器,每一个都有32位 宽。而ARMv8架构拥有31个通用寄存器,每一个为64位宽。这就意味着优化代码使用内部寄存器的频率应该要比内存更高,同时也可以保留更大的数字和地址。结果就是,ARM的64位处理器在运行速度上会更快一些。在能效上,64位寄存器的使用并不会提升功耗。在某些情况下,64位核心执行部分任务的速度会更快一些,由于运行时间的减少,这也就会使其显得比32位核心更加节能。

寻址(Addressing)是64位处理器的另一个层面。在PC和服务器领域,32位的局限主要在可访问的内存上。如果想要使用超过4GB的内存,就需要使用64位处理器。因为可以使用大物理地址拓展(LPAE),某些ARMv7处理器能够使用超过4GB内存,所以严格来讲,内存的限制并不是ARM处理器所遭遇的问题。由于LPAE的存在,Cortex-A15处理器能够处理1024GB内存,而64位的处理能力更是高达200万TB。因此在短时间内, 任何一部智能手机都不需要完整的64位寻址。追求永远都不会被用到的寻址空间是毫无意义的,因此ARMv8架构采用了48位寻址,这已经是256TB了。
虽然没有什么程序或游戏会用到TB级别的内存,但在另一方面,这种寻址能力又非常重要。现代3D游戏通常都带有大量的资源,当拥有超过4GB的可访问空间时,这些资源能够被更加轻松地进行内存映射。这样一来,游戏的运行速度会得到提升,并让直接访问游戏多媒体资源成为可能。
不只是智能手机和平板
ARM 上64位计算的好处并不仅限于智能手机和平板电脑。ARM的生态系统很广阔,其处理器也被许多不同类型的设备所使用。服务器市场是ARM处理器影响力有限的一个领域。信息时代的发展让维持数据中心所消耗的能源持续快速增长,而任何能够降低能源使用的技术都是对于资金和自然资源的节省。除了节能之外,在服务器当中使用64位ARM芯片还有其他的好处。这些服务器都会被动散热,这意味着你可以将它们集中在一起,而无需担心会发生过热的情况。这样一来,用于散热上的花费也将有所降低。
至于服务器软件,Linux这样的操作系统已经是64位的了,其主线内核当中也已经加入了对于ARMv8的支持。这也就是说,制作运行于64位Linux、ARM处理器的服务器并不会很困难。
小结
多亏了ARM,64位的移动计算时代就要到来了。这些新的处理器不仅速度更快,还为移动平台开启了更多的可能性。从32位向64位的迁移道路已经被铺就,无论是什么操作系统,开发者从32位进入64位都不会有任何意外。在未来一段时间里,ARM的合作伙伴都将推出Cortex-A53和Cortex-A57处理器。当中有的会采用双核或四核的标准配置,也有的会选择big.LITTLE配置。但有一点是肯定的,那就是这对于ARM和普通用户来说都是一个激动人心的时刻。
AArch64是ARMv8 架构的一种执行状态,ARMv8是ARM版本升级以来最大的一次改变,其架构继承以往ARMv7与之前处理器技术的基础,除了现有的16/32bit的Thumb2指令支持外,也向前兼容现有的A32(ARM 32bit)指令集,扩充了基于64bit的AArch64架构,除新增A64(ARM 64bit)指令集外,也扩充了现有的A32(ARM 32bit)和T32(Thumb2 32bit)指令集。
为了更广泛地向企业领域推进,需要引入 64 位构架的同时也需要在 ARMv8 架构中引入新的 AArch64 执行状态。AArch64 不是一个单纯的 32 位 ARM 构架扩展,而是 ARMv8 内全新的构架,完全使用全新的 A64 指令集。这些都源自于多年对现代构架设计的深入研究。更重要的是,AArch64 作为一个分离出的执行状态,意味着一些未来的处理器可能不支持旧的 AArch32 执行状态。虽然最初的 64 位 ARM 处理器将会完全向后兼容,但可以大胆且前瞻性地将 AArch64 作为在 ARMv8 处理器中唯一的执行状态。在这些系统中将不支持 32 位执行状态,这将使许多有益的实现得到权衡,如默认情况下,使用一个较大的 64K 大小的页面,并会使得纯净的 64 位 ARM 服务器系统不受遗留代码的影响。立即进行这种划分是很重要的,因为有可能在未来几年内将出现仅支持 64 位的服务器系统。没有必要在新的 64 位架构中去实现一个完整的 32 位流水线,这将会提高未来 ARM 服务器系统的能效。这样AArch64作为在 Fedora ARM 项目中被支持的 ARM 构架是一个很自然的过程:armv5tel、armv7hl、aarch64。新的架构被命名为:aarch64,这同 ARM 自己选择的主线命名方式保持一致,同时也考虑到了 ARM 架构名与 ARM 商标分开的期望。
ARMv8-A 将 64 位架构支持引入 ARM 架构中,其中包括:
64 位通用寄存器、SP(堆栈指针)和 PC(程序计数器)
64 位数据处理和扩展的虚拟寻址
两种主要执行状态:
AArch64 - 64 位执行状态,包括该状态的异常模型、内存模型、程序员模型和指令集支持
AArch32 - 32 位执行状态,包括该状态的异常模型、内存模型、程序员模型和指令集支持
这些执行状态支持三个主要指令集
A32(或 ARM):32 位固定长度指令集,通过不同架构变体增强部分 32 位架构执行环境现在称为 AArch32。
T32 (Thumb) 是以 16 位固定长度指令集的形式引入的,随后在引入 Thumb-2 技术时增强为 16 位和 32 位混合长度指令集。部分 32 位架构执行环境现在称为 AArch32。
A64:提供与 ARM 和 Thumb 指令集类似功能的 32 位固定长度指令集。随 ARMv8-A 一起引入,它是一种 AArch64 指令集。
ARM ISA 不断改进,以满足前沿应用程序开发人员日益增长的要求,同时保留了必要的向后兼容性,以保护软件开发投资。在 ARMv8-A 中,对 A32 和 T32 进行了一些增补,以保持与 A64 指令集一致。
A64新的指令和寄存器
固定大小32位操作码,清除基于5位寄存器说明符的解码表;
可以拥有32位或者64位参数;
地址设定为64位,主要针对LP64和LLP64数据模型;
比AArch32拥有更少的条件指令,条件指令有:分支,比较,选择;
没有LDM/STM(用于批量从内存中读取或者写入数据)指令,添加LDP/STP指令来操作以降低复杂性及功耗;
支持先进的SIMD(Single-Instruction,Multiple-Data:单指令多数据)和(FP浮点);
支持加密技术;
可随时访问31个通用的64位寄存器(X0-X30),没有banked(banked是指一个寄存器不同模式下会对应不同的物理地址)的通用寄存器,堆栈指针(SP),PC不是通用寄存器,附加专用的零寄存器(Xzr);
AArch32状态是使用CPSR来存储当前process执行状态,AArch64定义了一组PSTATE寄存器用以保存PE(Processing Element)状态;AArch32和AArch64之间的切换只能通过发生异常或者系统Reset来实现,A32 -> T32之间是通过BX指令切换的;在ARMv8 64bit出现之前,所使用的都是32位寻址,每个地址单位对应内存一个字节单元(B),所以最大的寻址范围为2^32B = 4GB,但是实际当中,内存设备有可能远远大于4GB内存空间,以前通过LPAE(大物理地址扩展)实现地址的扩展,可以支持最大2^40的地址寻址范围,ARMv8理论上最高可以提供提供了2^64个虚拟地址,但是超过16 Exabyte (2^4 * 2^60)意义并不大,所以选择跟x86一样,可以使用最大支持2^48虚拟地址的寻址范围就足够;
Armv8是Armv7之后的一个重要架构更新,其中一个主要的变化是引入了64的架构,即AArch64,因此AArch64状态只有在Armv8架构中才有。而且在AArch64状态下执行的代码只能使用A64指令集。当然ARM为了维持整个生态参与者的利益,Armv8还是保持与现有32位体系结构兼容性的AArch32,即Armv8之前的Armv7配置文件定义的那套设计规范。AArch32今天不会进行具体介绍,重点是AArch64,但是不管怎么变最本质的规则是不会变的,ARM对所有硬件资源的操作,都抽象成对寄存器的操作,寄存器隐藏了硬件的具体操作细节提供配置的接口,硬件处理器拿着这些配置负责具体的执行。下面具体看一下在AArch64状态的一些主要技术细节:
1、AArch64状态下的寄存器

2、异常级别

3、链接寄存器

4、堆栈指针寄存器

5、预留的核心寄存器名字

6、预留的扩展的寄存器名字

7、程序计数器

8、带条件的执行

9、Q标志

10、进程状态

11、保存的程序状态寄存器(SPSR)

12、A64指令集

牛犁heart剖析ARM最新编程架构模型之AArch64体系
自从 Acorn 公司于 1983 年开始发布第一个版本,到目前为止,有九个主要版本,版本号由 1 到 9 表示。2011 年,Acorn 公司发布了 ARMv8 版本。ARMv8 是首款支持 64 位指令集的 ARM 处理器架构,它兼容了 ARMv7 与之前处理器的技术基础,同样它也兼容现有的 A32(ARM 32bit)指令集,还扩充了基于 64bit 的 AArch64 架构。
ARMv8 一共定义了哪几种架构,一共有三种:
1、ARMv8-A(Application)架构,支持基于内存管理的虚拟内存系统体系结构(VMSA),支持A64、A32和T32指令集,主打高性能,在我们的移动智能设备中广泛应用。
2、RMv8-R(Real-time)架构,支持基于内存保护的受保护内存系统架构(PMSA),支持 A32 和 T32 指令集,一般用于实时计算系统。
3、ARMv8-M(Microcontroller 架构),是一个压缩成本的嵌入式架构,而且需要极低延迟中断处理。它支持 T32 指令集的变体,主打低功耗,一般用于物联网设备。
AArch64 只是 ARMv8-A 架构下的一种执行状态,“64”表示内存或者数据都保存在 64 位的寄存器中,并且它的基本指令集可以用 64 位寄存器进行数据运算处理。
一款处理器要运行程序和处理数据,必须要有一定数量的寄存器。特别是基于 RISC(精简指令集)架构的 ARM 处理器,寄存器数量非常之多,因为大量的指令操作的就是寄存器。
ARMv8-AArch64 体系下的寄存器简单可以分为以下三类:通用寄存器、特殊寄存器、系统寄存器。
AArch64、AArch32 体系都是简称,从严格意义上说,它们应该是处理器的两种执行方式或者状态。AArch64 体系执行 A64 指令集,这个指令集是全 64 位的;AArch32 体系则可以执行 A32 指令集和 T32 指令集。CPU 的工作模式并没有差异。
ARM 的 CPU 一共有 7 种不同工作模式,根据权限和状态,以及进入工作模式的方法等方面的不同,下面用表格的方式做了梳理。相比 x86 系统,AArch64 的 CPU 工作模式更加多样。
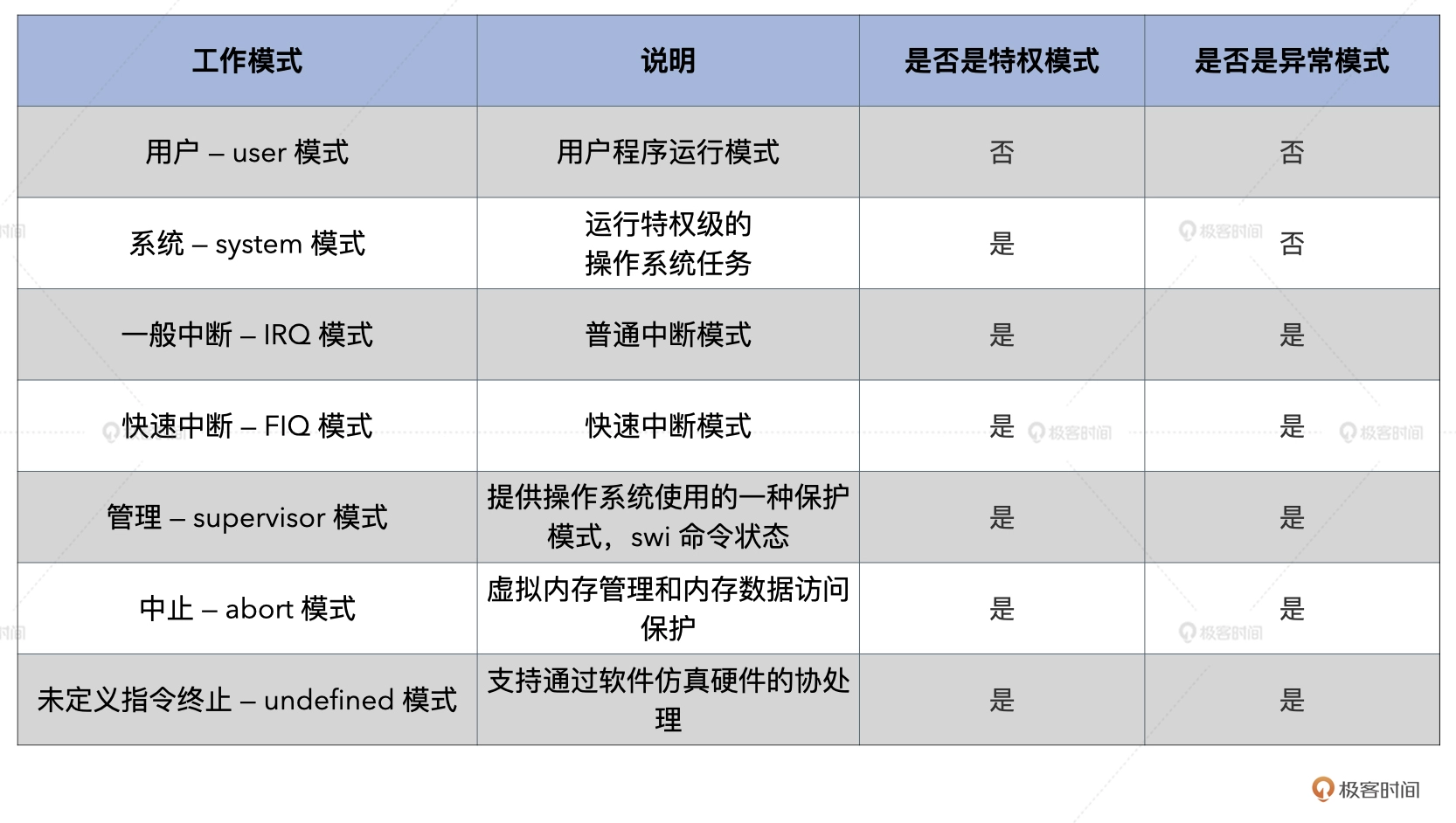
在 7 种模式中,除了用户模式之外的模式,被统称为 Privileged Modes(特权模式)。
首先,大多数的应用程序是运行在用户模式下的,在用户模式下,是不能够访问受保护的系统资源的。此外,应用程序也无法进行处理器模式的切换的。这样就做到了应用程序和内核程序的权力分隔,确保应用程序不能破坏操作系统。
一旦代码的执行流,切换到特权模式下,其代码就可以访问全部的系统资源了,代码也可以随时进行处理器模式的切换。而且只有在特权模式下,CPU 的部分内部寄存器才可以被读写。这里的代码就是指内核代码。
其次,系统模式也是特权模式,代码也是可以访问全部系统资源,也可以随时进行处理器模式的切换,主要供操作系统任务使用。系统模式和用户模式可以访问到的寄存器是同一套的,区别就是它是特权模式,不受用户模式的限制,一般系统模式用于调用操作系统的系统任务。
最后,特权模式下,除系统模式之外的其他五种模式就是异常模式。异常模式一般是在用户的应用程序发生中断异常时,随着特定的异常而进入的,比如之前我们讲过的硬件中断和软件中断,每种异常模式都有对应的一组寄存器,用来保证用户模式下的状态不被异常破坏。这样可以大大减小处理异常的时间,因为不用保存大量用户态寄存器。
处理器如何切换工作模式
工作模式切换大概分两种情况,一是软件控制,通过修改相应的寄存器或者执行相应的指令;二是当外部中断或是异常发生时,也会导致 CPU 工作模式的切换。当 CPU 发生中断或者异常时,CPU 进入相应的异常模式时,以下工作由 CPU 自动完成:
1.在异常模式的 R14 中,保存前一个工作模式里,下一条即将执行的指令地址;
2.将 CPSR 的值复制到异常模式的 SPSR 中;
3.将 CPSR 的工作模式设为该异常模式对应的工作模式;
4.令 PC 值等于这个异常模式在异常向量表中的地址,即跳转去执行异常向量表中的相应指令。
处理完中断或者异常,就需要从中断或者异常中返回到发生中断或者异常的位置,继续执行程序。这个从异常工作模式退回到之前的工作模式时,需要由软件来完成后面这两项工作:
1.将异常模式的 R14 减去一个适当的值(4 或 8)后,赋给 PC 寄存器;
2.将异常模式 SPSR 的值赋给 CPSR;
AArch64 体系如何处理中断
现在来看看 AArch64 体系是如何处理中断的,首先我们要搞清楚中断和异常的区别,然后了解它们的处理过程,最后再研究一下中断向量表。
异常和中断
有时习惯于把异常(Exception)和中断(Interrupt)理解成一回事儿。但是对 ARM 来说,官方文档用了 Exception 这个术语来描述广义上的中断,包括异常(Exception)和中断(Interrupt),Exception 和 Interrupt 的执行机制都是一样的,只是触发方式有区别。
这里的异常,切入的视角是处理器被动接收到了异常。异常通常表现为错误,比如 CPU 执行了未知指令,但 CPU 明显不能执行这个指令,所以就会产生错误。再比如说,CPU 访问了不能访问的内存,这也是错误的。你会发现,共同点是异常都是同步的,不修改程序下次同样会发生。而中断对应的视角是处理器主动申请,你可以当作是异步的异常,因外部事件产生。中断分为三种,它们分别是 IRQ、FIQ 和 SError。IRQ、FIQ 通常是连接到外部中断信号,当外部设备发出中断信号时,CPU 就能对此作出响应并处理外部设备需要完成的操作。
中断处理
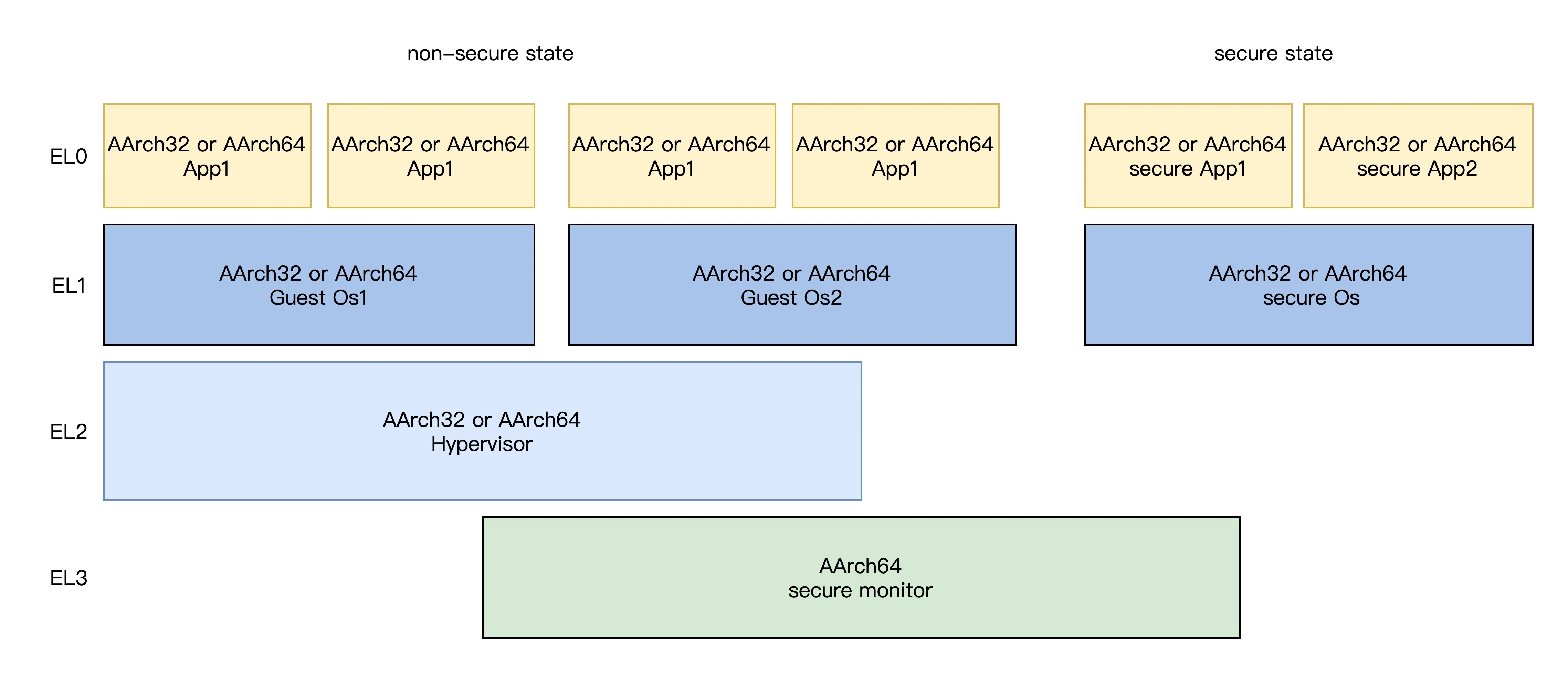
在了解中断处理之前,首先要搞明白异常级别。在全局 ARMV8-A 体系结构中,定义了四个异常级别(Exception Level)从 EL0 到 El3,每个异常级别的权限不同,你不妨想像一下 x86 CPU 的 R3~R0 特权级。
只不过 ARMV8-A 体系结构下 EL0 为最低权限模式,也就是对应用户态,处理的是应用程序;EL1 处理的是 OS 内核层,对应的是内核态;EL2 是 Supervisor 模式,处理的则是可以跑多个虚拟 OS 内核的管理软件,对应的是虚拟机管理态,它是可选的,如 Hypervisor 用于和 virtualization 扩展;EL3 运行的是安全管理(Secure Monitor),处理的是监控态,用于 security 扩展。
开发通用的操作系统内核只需要使用到 EL1,EL2 两个异常级别;画了一幅 EL 模型图如下所示:
现在来看看中断或者异常发生时,EL 级别的切换,这里分为两种情况。
第一种是高级别向低级别切换,这种方式通过修改 PSTATE 寄存器中的值来实现,EL 异常级别就保存在这个寄存器中;第二种是低级别向高级别切换,通过触发中断或者异常的方式进行切换的。
在这两种切换过程中,如果高级的状态是 AArch64,低级的可以是 AArch64 或者 AArch32,也就是可以向下兼容;如果高级的是 AArch32,那么低级的也一定要是 AArch32。
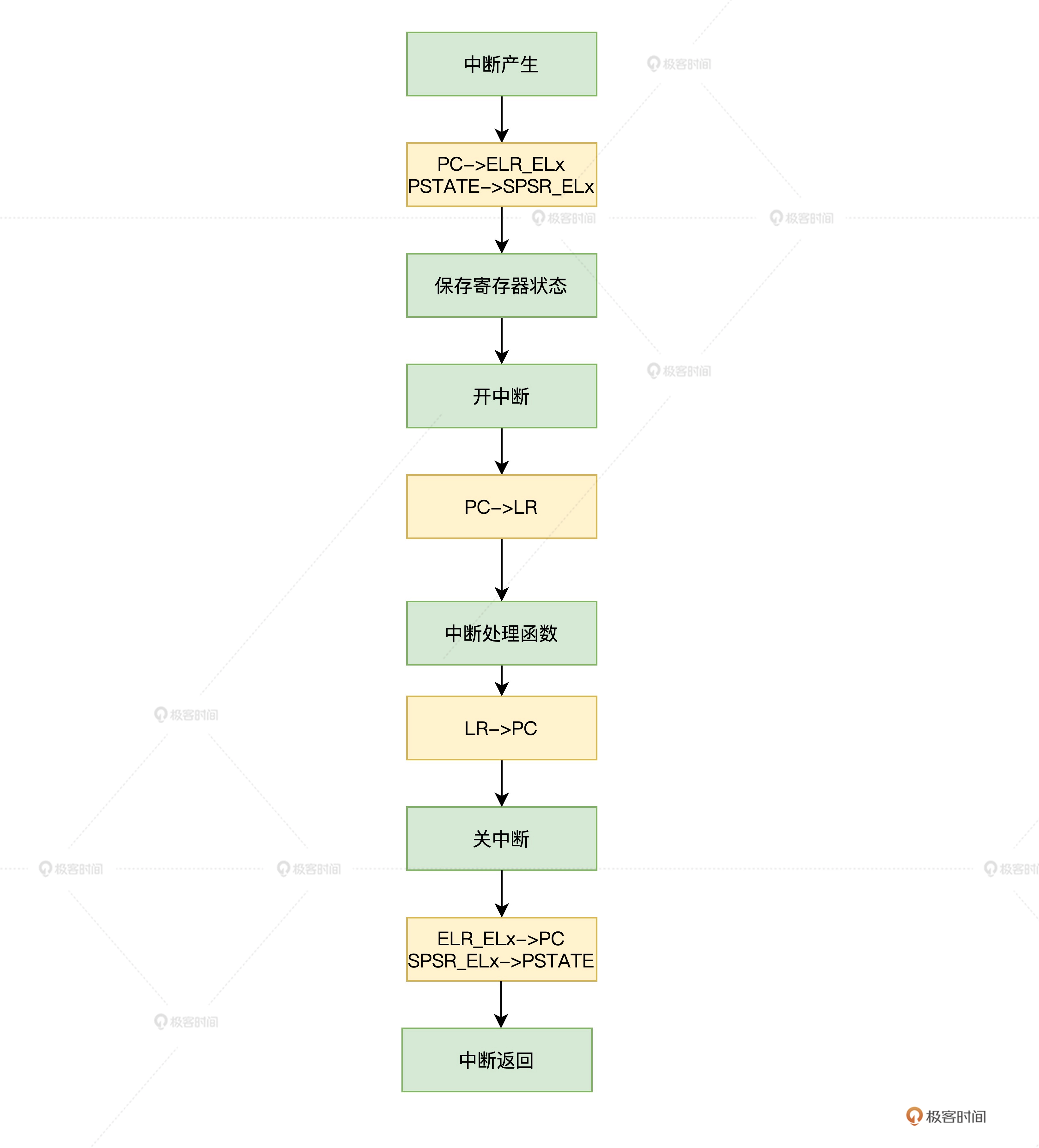
当一个中断或者异常触发后,CPU 的操作流程如下所示:
1.更新 SPSR_ELx 寄存器,即当前的 PSTATE 寄存器的信息存储在 SPSR_ELx 寄存,以便中断结束时恢复到 PSTATE 寄存器。
2.更新 PSTATE 寄存器以反映新的处理器状态,这个过程中,中断级别可能会发生变化。
3.发生中断时的下一条指令地址存储在 ELR_ELx 寄存器中,以便中断返回后,能继续运行。
4.当中断处理完成后,由高级别返回低级别时,需要使用 ERET 指令返回。
Interrup流程:
中断向量表
当中断或者异常发生后,CPU 进行相应的操作后,必须要跳转到相应的地址开始运行相应的代码,进行中断或者异常的处理,这个地址就是中断向量。由于有多个中断或者异常,于是就形成了中断向量表。
在 AArch64 中,每个中断或者异常触发时会产生 EL 级别切换。通常在 EL0 级别调用 svc 指令,触发一个同步异常,CPU 则会切换到 EL1 级别;如果在 EL0 级别来了一个 IRQ 或 FIQ,就会触发一个异步中断,CPU 会根据 SCR 寄存器中的中断配置来决定切换 EL1 或 EL2 或 EL3 级别,同时也会区分 EL 级别使用的是 AArch64,还是 AArch32 的指令集。
16 个向量的分类和偏移地址在向量表中的关系如下所示:
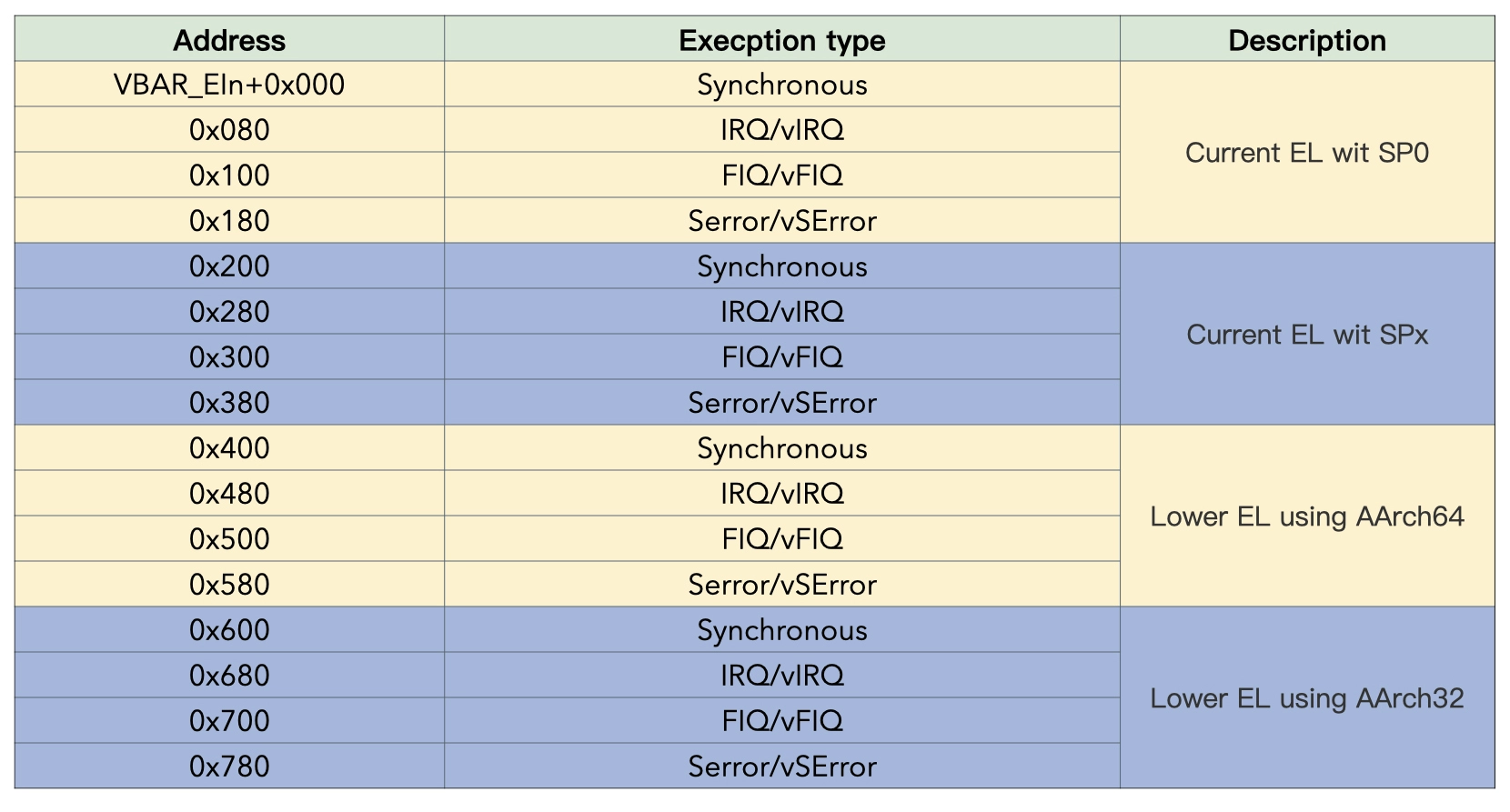
上表中分了四个小表,小表中的每一个 entry 由不同的中断的类型(IRQ,FIQ,SError,Synchronous)决定。具体使用哪一个小表由以下几个条件决定:
1、如果中断发生在同一中断级别,并且使用的栈指针是 SP_EL0,则使用 SP_EL0 这张表
2、如果中断发生在同一中断级别,并且使用的栈指针是 SP_EL1/2/3,则使用 SP_EL 这张表。
3、如果中断发生在较低的中断级别,使用的小表则为下一个较低级别(AArch64 或 AArch32)的执行状态。
有了这些硬件机制的支持,就可以完美支持现代意义中的操作系统了。
AArch64 体系如何访问内存
无论是操作系统内核代码还是应用程序代码,它们都是放在内存中的,CPU 要执行相应的代码指令,就要访问内存。访问内存有两大关键,一是寻址,这表现为内存的地址空间;第二个关键点是内存空间的保护,即内存地址的映射和转换。
AArch64 体系下的地址空间
对于工作在 AArch64 体系下的 CPU 来说,没有启动 MMU 的情况下,ARM 的 CPU 发出的地址,就是物理地址直接通过这个寻址内存空间。
但别以为 AArch64 体系下有 64 位的寄存器能发出 64 位的地址,就一定能寻址 64 位地址空间的内存。其实实际只能使用 52 位或者 48 位的地址,这里只讨论使用 48 位地址的情况。如果启用了 MMU,那么 CPU 会通过虚拟地址寻址,MMU 负责将虚拟地址转换为物理地址,进而访问实际的物理地址空间。这个过程如下图所示。
AArch64虚拟地址空间:
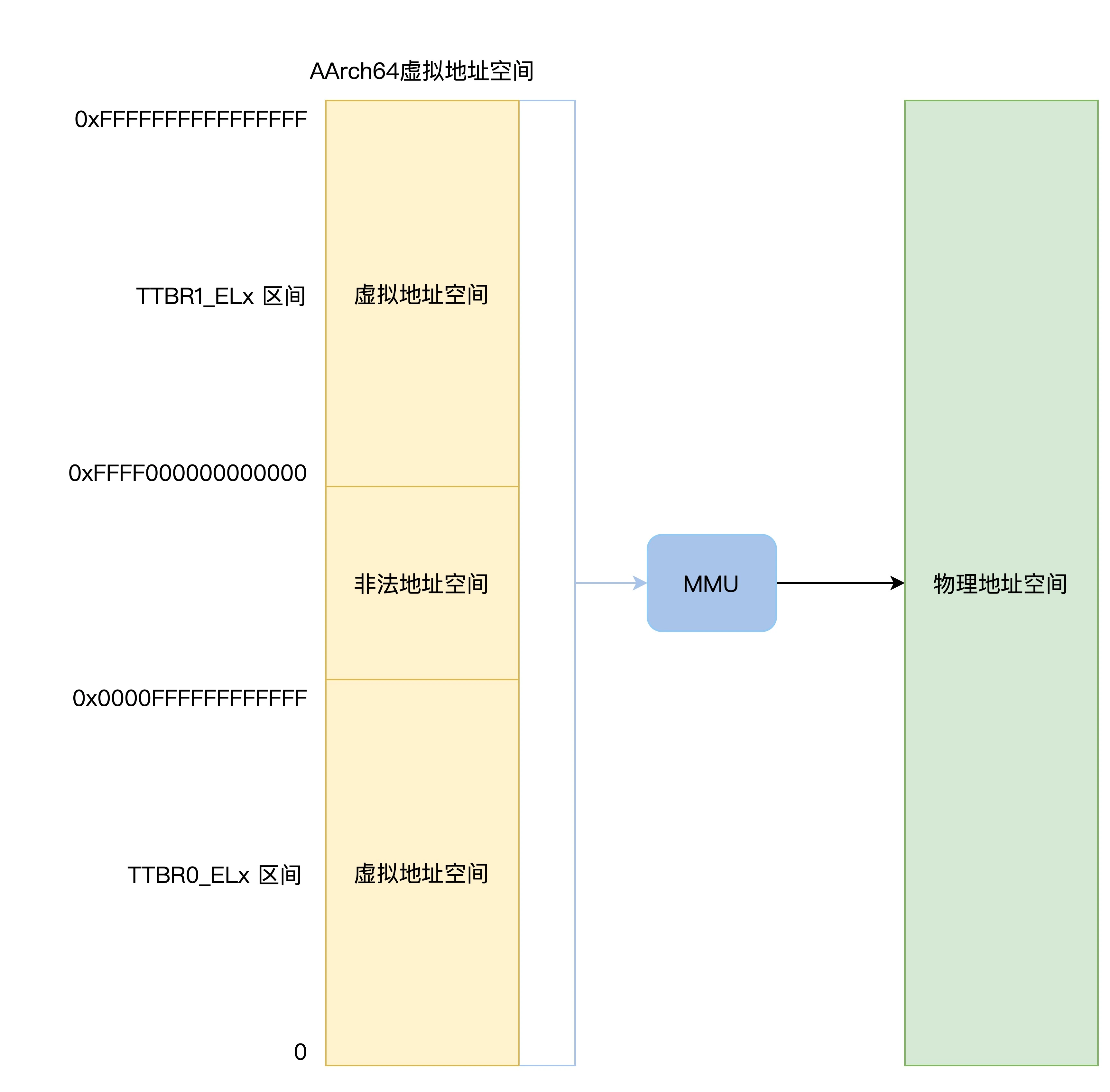
上图中可以发现,如果 CPU 发出的虚拟地址在 0x0~0x0000ffffffffffff 范围内,MMU 就会使用 TTBR0_ELx 寄存器指向的地址转换表进行物理地址的转换;如果 CPU 发出的虚拟地址在 0xffff000000000000~0xffffffffffffffff,MMU 使用 TTBR1_ELx 寄存器指向的地址转换表进行物理地址的转换。虚拟地址究竟是如何转换成物理地址的呢?
AArch64 体系下地址映射和转换
按照以往的经验来看,这里肯定是有一张把虚拟地址转化为物理地址的表,给出一个虚拟地址,通过查表就可以查到物理地址。但是实际过程却不是这么简单,在这里通常要有一个多级的查表过程。
MMU 将虚拟地址映射到物理地址是以页(Page)为单位的,ARMv8 架构的 AArch64 体系可以支持 48 位虚拟地址,并配置成 4 级页表(4K 页),或者 3 级页表(64K 页)。
例如,虚拟地址 0xb7001000~0xb7001fff 是一个页,可能被 MMU 映射到物理地址 0x2000~0x2fff,物理内存中的一个物理页面也称为一个页框(Page Frame)。
那么 MMU 执行地址转换的过程是怎样呢?看一看 4K 页表的情况下,虚拟地址转换物理地址的逻辑图。
虚拟地址转化:
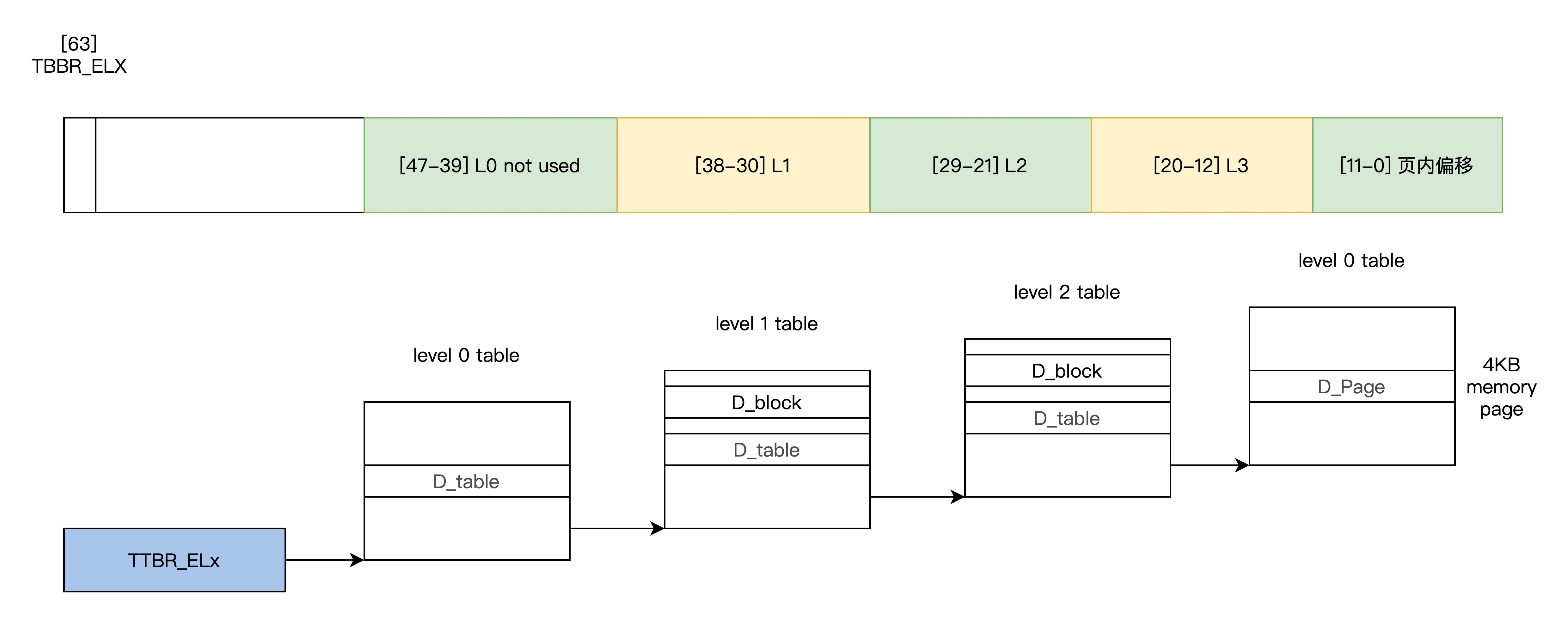
结合上图可以看到,首先要将 64 位的虚拟内存分成多个位段,这些位段就是用来索引不同级别页表中的 entry 的。那么 MMU 是如何具体操作的呢,一共分五步。
第一步从虚拟地址位段[47:39]开始,用来索引 0 级页表,0 级页表的物理基地址存放在 TTBR_ELx 寄存器中,以虚拟地址位段[47:39]为索引,找到 0 级页表中的某个 entry,该 entry 会返回 1 级页表的基地址。
第二步,接着之前找到的 1 级页表的基地址,现在可以用虚拟地址位段[38:30]索引到 1 级页表的某个 entry,该 entry 在 4KB 页表情况下,返回的是 2 级页表的基地址。
然后到了第三步,有了 2 级页表基地址,就可以用虚拟地址位段[29:21]作为索引找到 2 级页表中的某个 entry,该 entry 返回 3 级页表的基地址。
再然后是第四步,有了 3 级页表基地址,则用虚拟地址位段[20:12]作为索引找到 3 级页表中的某个 entry,该 entry 返回的是物理内存页面的基地址。
最后一步,得到物理内存页面基地址,用虚拟地址剩余的位段[11:0]作为索引,就能访问到 4KB 大小的物理内存页面内的某个字节了。
这个过程从 TTBR_ELx 寄存器开始到 0 级页表,接着到 1 级页表,然后到 2 级页表,再然后到 3 级页表,最终到物理页面,CPU 一次寻址,其实是五次访问物理内存。这个过程完全是由硬件处理的,每次寻址时 MMU 就自动完成前面这五步,不需要我们编写指令来控制 MMU,但是我们要保证内核维护正确的页表项。
有了 MMU 硬件转换机制,操作系统只需要控制页表就能控制内存的映射和隔离了。