全文检索引擎-Sphinx
 Sphinx是一个使用C++开发并基于SQL的全文检索引擎,可以结合MySQL、PostgreSQL做全文搜索,其提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。Sphinx特别为一些脚本语言设计搜索API接口,如PHP、Python、Perl、Ruby等,同时为MySQL也设计了一个存储引擎插件。
Sphinx是一个使用C++开发并基于SQL的全文检索引擎,可以结合MySQL、PostgreSQL做全文搜索,其提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。Sphinx特别为一些脚本语言设计搜索API接口,如PHP、Python、Perl、Ruby等,同时为MySQL也设计了一个存储引擎插件。Sphinx is an open source full text search server, designed from the ground up with performance, relevance (aka search quality), and integration simplicity in mind. It's written in C++ and works on Linux (RedHat, Ubuntu, etc), Windows, MacOS, Solaris, FreeBSD, and a few other systems.
Sphinx lets you either batch index and search data stored in an SQL database, NoSQL storage, or just files quickly and easily — or index and search data on the fly, working with Sphinx pretty much as with a database server.
A variety of text processing features enable fine-tuning Sphinx for your particular application requirements, and a number of relevance functions ensures you can tweak search quality as well.
Searching via SphinxAPI is as simple as 3 lines of code, and querying via SphinxQL is even simpler, with search queries expressed in good old SQL.
Sphinx clusters scale up to billions of documents and tens of millions search queries per day, powering top websites such as Craigslist, DailyMotion, NetLog, etc.
版本2.0及之前以GPLv2协议授权,3.0及以上版本的源代码目前仅在FOSS或商业许可证延迟的情况下可用。
Performance and scalability
* Indexing performance. Sphinx indexes up to 10-15 MB of text per second per single CPU core, that is 60+ MB/sec per server (on a dedicated indexing machine).
* Searching performance. Searching through 1,000,000-document, 1.2 GB text collection that we use for everyday development and testing runs at 500+ queries/sec on a 2-core desktop machine with 2 GB of RAM.
* Scalability. Biggest known Sphinx cluster indexes almost 5 billion documents, resulting in over 6 TB of data. Busiest known one is, unsurpisingly, Craigslist, top-10 website in the US that serves 50+ million search queries/day.
Sphinx 单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。其创建索引的速度为:创建100万条记录的索引只需 3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。
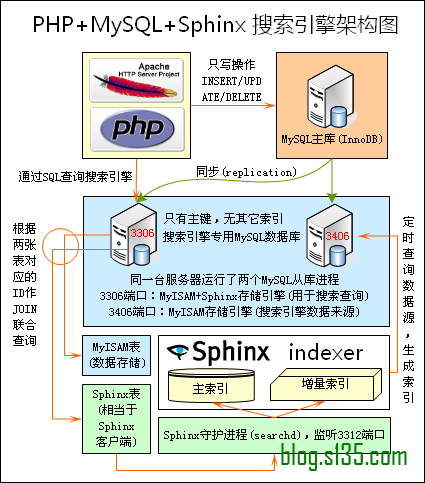
Features
* Batch and Real-Time full-text indexes. Two index backends that support both efficient offline index construction andincremental on-the-fly index updates are available.
* Non-text attributes support. An arbitrary number of attributes (product IDs, company names, prices, etc) can be stored in the index and used either just for retrieveal (to avoid hitting the DB), or for efficient Sphinx-side search result set post-processing.
* SQL database indexing. Sphinx can directly access and index data stored in MySQL (all storage engines are supported), PostgreSQL, Oracle, Microsoft SQL Server, SQLite, Drizzle, and anything else that supports ODBC.
* Non-SQL storage indexing. Data can also be streamed to batch indexer in a simple XML format called XMLpipe, or inserted directly into an incremental RT index.
* Easy application integration. Sphinx comes with three different APIs, SphinxAPI, SphinxSE, and SphinxQL. SphinxAPI is a native library available for Java, PHP, Python, Perl, C, and other languages. SphinxSE, a pluggable storage engine for MySQL, enables huge result sets to be shipped directly to MySQL server for post-processing. SphinxQL lets the application query Sphinx using standard MySQL client libary and query syntax.
* Advanced full-text searching syntax. Our querying engine supports arbitrarily complex queries combining boolean operators, phrase, proximity, strict order, and quorum matching, field and position limits, exact keyword form matching, substring searches, etc.
* Rich database-like querying features. Sphinx does not limit you to just keyword searching. On top of full-text search result set, you can compute arbitrary arithmetic expressions, add WHERE conditions, do ORDER BY, GROUP BY, use MIN/MAX/AVG/SUM, aggregates etc. Essentially, full-blown SQL SELECT is supported.
* Better relevance ranking. Unlike many other engines, Sphinx does not solely rely on 30-year-old statistical ranking that only considers keyword frequencies, nor limits you to it. By default, Sphinx additionally analyzes keyword proximity, and ranks closer phrase matches higher, with perfect matches ranked on top. Also, ranking is flexible: you can choose from a number of built-in relevance functions, tweak their weights by using expressions, or develop new ones.
* Flexible text processing. Sphinx indexing features include full support for SBCS and UTF-8 encodings (meaning that effectively all world's languages are supported); stopword removal and optional hit position removal (hitless indexing); morphology and synonym processing through word forms dictionaries and stemmers; exceptions and blended characters; and many more.
* Distributed searching. Searches can be distributed across multiple machines, enabling horizontal scale-out and HA (High Availability).
特性
高速索引 (在新款CPU上,近10 MB/秒);
高速搜索 (2-4G的文本量中平均查询速度不到0.1秒);
高可用性 (单CPU上最大可支持100 GB的文本,100M文档);
提供良好的相关性排名
支持分布式搜索;
提供文档摘要生成;
提供从MySQL内部的插件式存储引擎上搜索
支持布尔,短语, 和近义词查询;
支持每个文档多个全文检索域(默认最大32个);
支持每个文档多属性;
支持断词;
支持单字节编码与UTF-8编码;
最新版本:3.4
官方主页:http://sphinxsearch.com/