分布式文件系统-SeaweedFS
 SeaweedFS 是一款易用、可扩展、高伸缩性的分布式文件系统。作为支持全 POSIX 文件系统语义替代,Seaweed-FS 选择仅实现 key-file 的映射,类似 "NoSQL",也可以说是 "NoFS",采用Go语言开发。
SeaweedFS 是一款易用、可扩展、高伸缩性的分布式文件系统。作为支持全 POSIX 文件系统语义替代,Seaweed-FS 选择仅实现 key-file 的映射,类似 "NoSQL",也可以说是 "NoFS",采用Go语言开发。SeaweedFS is an independent Apache-licensed open source project with its ongoing development made possible entirely thanks to the support of these awesome backers. If you'd like to grow SeaweedFS even stronger, please consider joining our sponsors on Patreon.
两大特性:
1、成存储上亿的文件
2、快速响应与在线服务
SeaweedFS的设计原理是基于 Facebook 的图片存储系统的论文Facebook-Haystack。
SeaweedFS仅花费 40 字节的硬盘来存储每个文件的元数据。它的文件ID就是文件的唯一标识,这个ID是每3部分存在的。
其中"fid":"5,019d90e79a"就是 Fid,Fid 由三个部分组成 [VolumeId, NeedleId, Cookie] 组成。
VolumeId: 1 32bit 存储的物理卷的Id
NeedleId: 01 64bit 全局唯一NeedleId,每个存储的文件都不一样(除了互为备份的)。
Cookie: 9d90e79a 32bit Cookie值,为了安全起见,防止恶意攻击。
Architecture
Usually distributed file systems split each file into chunks, a central master keeps a mapping of filenames, chunk indices to chunk handles, and also which chunks each chunk server has.
通常分布式文件系统将每个文件分成块,主节点(master)保存文件名、块索引到块句柄的映射,以及每个存储服务器上有哪些块。
The main drawback is that the central master can't handle many small files efficiently, and since all read requests need to go through the chunk master, so it might not scale well for many concurrent users.
主要的缺点是主节点(master)不能有效地处理过多小文件,而且由于所有的读取请求都需要经过存储主机,因此对于多用户并发来说,它可能无法很好地扩展。
Instead of managing chunks, SeaweedFS manages data volumes in the master server. Each data volume is 32GB in size, and can hold a lot of files. And each storage node can have many data volumes. So the master node only needs to store the metadata about the volumes, which is a fairly small amount of data and is generally stable.
Seaseedfs管理主节点(master)中的数据卷,而不是管理块。每个数据卷的大小为32GB,可以容纳大量文件,且每个存储节点可以有多个数据卷。因此主节点只需要存储关于卷的元数据,这是一个相当小的数据量,并且通常是稳定的。
The actual file metadata is stored in each volume on volume servers. Since each volume server only manages metadata of files on its own disk, with only 16 bytes for each file, all file access can read file metadata just from memory and only needs one disk operation to actually read file data.
实际的文件元数据存储在卷服务器上的每个卷中。由于每个卷服务器只管理自己磁盘上的文件元数据,每个文件只有16个字节,所以所有文件访问都可以只从内存读取文件的元数据,一般只需一次磁盘操作即可实际读取到文件数据。
For comparison, consider that an xfs inode structure in Linux is 536 bytes.
为了进行比较,考虑一下Linux中的xfs的inode结构设定为536字节。
Master Server and Volume Server|主节点与卷存储服务器
The architecture is fairly simple. The actual data is stored in volumes on storage nodes. One volume server can have multiple volumes, and can both support read and write access with basic authentication.
架构其实很简单。实际数据存放在存储节点上的卷中,一个卷服务器可以有多个卷,并且都可以通过基本身份验证支持读写访问。
All volumes are managed by a master server. The master server contains the volume id to volume server mapping. This is fairly static information, and can be easily cached.
所有卷都由主服务器管理。主服务器包含卷id到卷服务器的映射。这是静态的信息,可以很容易地缓存。
On each write request, the master server also generates a file key, which is a growing 64-bit unsigned integer. Since write requests are not generally as frequent as read requests, one master server should be able to handle the concurrency well.
对于每个写请求,主服务器还生成一个文件id之类的键,这是一个增长的64位无符号整数。由于写请求通常不像读请求那样频繁,一个主节点服务器应该能够很好地处理并发。
Write and Read files|文件读写
When a client sends a write request, the master server returns (volume id, file key, file cookie, volume node url) for the file. The client then contacts the volume node and POSTs the file content.
当客户机发送写请求时,主服务器将返回文件的(卷id、文件NeedleId、文件cookie、卷节点url)。然后,客户机联系卷节点并上传文件内容。
When a client needs to read a file based on (volume id, file key, file cookie), it asks the master server by the volume id for the (volume node url, volume node public url), or retrieves this from a cache. Then the client can GET the content, or just render the URL on web pages and let browsers fetch the content.
当客户机需要根据(卷id、文件NeedleId、文件cookie)读取文件时,它会通过卷id向主服务器请求(卷节点url、卷节点公共url),或从缓存中检索该文件。然后客户端可以获取内容,或者只是在网页上呈现URL,让浏览器来获取内容。
Storage Size|存储大小
In the current implementation, each volume can hold 32 gibibytes (32GiB or 8x2^32 bytes). This is because we align content to 8 bytes. We can easily increase this to 64GiB, or 128GiB, or more, by changing 2 lines of code, at the cost of some wasted padding space due to alignment.
在当前的实现中,每个卷可以容纳32GiB(32GiB或8x2^32字节),这是因为我们将内容与8字节对齐。我们可以很容易地将其增加到64GiB、128GiB或者更多,只需更改2行代码,代价是由于对齐而浪费了一些填充空间。
There can be 4 gibibytes (4GiB or 2^32 bytes) of volumes. So the total system size is 8 x 4GiB x 4GiB which is 128 exbibytes (128EiB or 2^67 bytes).
可以有4 GiB(4GiB或2^32字节)的卷。因此,系统的总大小是8 x 4GiB x 4GiB,即128exbibytes(128EiB或2^67字节)。
Each individual file size is limited to the volume size.
每个单独的文件大小仅限于卷大小。
Saving memory|节省内存
All file meta information stored on an volume server is readable from memory without disk access. Each file takes just a 16-byte map entry of <64bit key, 32bit offset, 32bit size>. Of course, each map entry has its own space cost for the map. But usually the disk space runs out before the memory does.
存储在卷服务器上的所有文件元数据信息都可以从内存读取,而无需磁盘访问。每个文件只接受一个16字节的映射<64bit key,32bit offset,32bit size>。当然,每个映射条目都有自己的空间成本。但通常磁盘空间在内存用完之前就用完了。
与其它类似的文件系统相比较
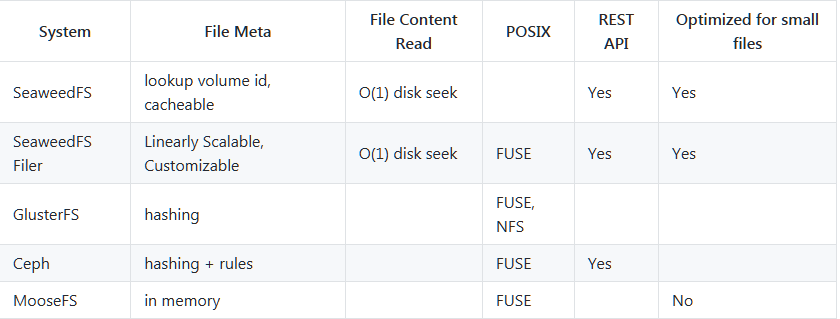
通过Filer模块可以实现FUSE来支持挂载
Optional Filer can support directories and POSIX attributes. Filer is a separate linearly-scalable stateless server with customizable metadata stores, e.g., MySql, Postgres, Mongodb, Redis, Cassandra, Elastic Search, LevelDB, MemSql, TiDB, Etcd, CockroachDB, etc.
可选的文件管理器可以支持目录和POSIX属性。Filer是一个独立的线性可扩展无状态服务器,具有可定制的元数据存储源,例如:MySql、Postgres、Mongodb、Redis、Cassandra、Elastic Search、LevelDB、MemSql、TiDB、Etcd、CockroachDB等。
最新版本:2.0
2020年9月,该版本更新内容如下:
HDFS 1.4.7:添加fs.seaweed.buffer.size选项
Shell:添加 volumeServer.leave 命令及volumeServer.evacuate 命令
S3 API Gateway
添加对 PostPolicy API 的支持
将指标发送到 Prometheus 网关。
适用于 Seaweed 的更新的 grafana 仪表板增加了 S3 指标以及可能在 AWS 中运行的 cost。
Filer
增加通过 http POST 创建空目录的功能。
gRPC server 还支持 ip.bind
Mongodb 更新错误
Docker:为 large disk version 添加 image。docker pull chrislusf/seaweedfs:2.00_large_disk
WebDAV:支持大于 2GB 的文件
Volume:从一开始就从主服务器加载配置,以在weed server运行模式下支持 cloud tier
更多更新说明请参考这里。
最新版本:3.0
SeaweedFS 3.0 于2022年4月下旬发布,此版本删除了编译时不常用的大尺寸库,包括:“elastic、gocdk、sqlite、hdfs”。如果需要,请直接使用 Makefile 编译这些库。其他改动如下:
Shell
按集合和卷 ID 划分 shell 真空卷 #2936
volume.list 添加新选项:通过集合名称模式或通过 volumeId 显示只读卷 #2940
Filer
修复读取错误时的 http 响应错误代码 #2960
Volume
修复在卷服务器有多个目录时,删除卷或卸载卷时的错误
Minor
Helm Charts:使用 leveldb2 的文件管理器可能会丢失数据 #2935
更多信息请参考更新公告。
项目主页:https://github.com/chrislusf/seaweedfs