集群数据库Postgres-XL
 Postgres-XL 是一个通用的 ACID 开源的、可方便进行水平扩展的 SQL 数据库解决方案,基于 PostgreSQL 数据库构建。其可用于商业智能、大数据分析、Web 2.0、传统应用等场合。可非常灵活的应付各种高负载环境。Postgres-XL 全称为 Postgres eXtensible Lattice,是TransLattice公司及其收购数据库技术公司–StormDB的产品,基于Postgres-XC。Postgres-XL是一个横向扩展的开源数据库集群,具有足够的灵活性来处理不同的数据库任务,采用C/C++开发并在Mozilla Public License许可协议下授权。
Postgres-XL 是一个通用的 ACID 开源的、可方便进行水平扩展的 SQL 数据库解决方案,基于 PostgreSQL 数据库构建。其可用于商业智能、大数据分析、Web 2.0、传统应用等场合。可非常灵活的应付各种高负载环境。Postgres-XL 全称为 Postgres eXtensible Lattice,是TransLattice公司及其收购数据库技术公司–StormDB的产品,基于Postgres-XC。Postgres-XL是一个横向扩展的开源数据库集群,具有足够的灵活性来处理不同的数据库任务,采用C/C++开发并在Mozilla Public License许可协议下授权。XL的意思是:eXtensible Lattice,可以扩展的格子,即将PostgreSQL应用在多机器上的分布式数据库的形象化表达。Postgres-XL 是一个完全满足ACID的、开源的、可方便进行水平扩展的、多租户安全的、基于PostgreSQL的数据库解决方案。它可以非常灵活的应付各种负载,比如:
OLAP(通过MPP并行化)
OLTP
OLAP & OLTP
操作数据存储
Key-value存储,包括JSON格式
不同的应用场景:
支持商业智能应用(数据仓库&数据集市),因为PGXL支持MPP(Massively Parallel Processing)
Web2.0,数据库扩容的解决方案
遗留系统的数据库扩容的解决方案
新应用,可以先使用PostgreSQL,之后随着数据库变大使用PGXL扩容
PGXL底层为PostgreSQL,这意味着它支持所有支持PostgresSQL类型的驱动,包括:JDBC, ODBC, OLE DB, Python, Ruby, perl DBI, Tcl, and Erlang。
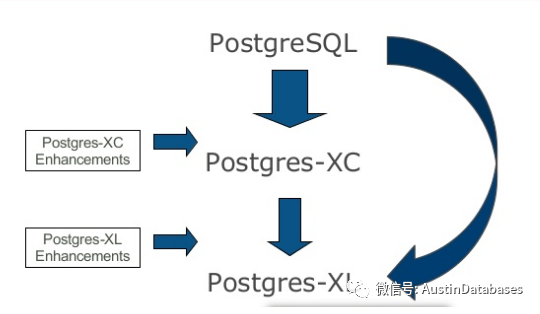
1994年,Postgre95发布,开源。
1996年,PostgreSQL继承了Postgre95,发布。
2010年,Postgres-XC发布。
2012年,前PGXC核心开发者创建StormDB公司,进行了一些改进,包括对MPP并行化的性能改进和多租户安全。
2013年,TransLattice收购了StormDB。
2014年,将项目开源,命名为Postgres-XL。
PGXL的架构师和开发者很多都是以前做PGXC的,PGXL的部分代码是从PGXC移植过来的。比起功能性,PGXL更强调稳定性, 正确性和性能。
PGXL增加了一些重要的性能提升,比如MPP和replan avoidance on the data nodes,这些都是PGXC没有的,PGXL的社区非常开放。
PGXC目前集中在OLTP的业务上面,PGXL则更加灵活,可以应用于很多不同种类的业务上,比如可以用在大数据处理领域,除此,在多租户的环境中,PGXL也更加安全。
PGXL是一系列PostgreSQL数据库的集群,在上层看来就像使用一个数据库一样。根据设计方案的不同,每张表可以是replicated或是distributed的形式。
功能特点
完全的ACID支持
可横向扩展的关系型数据库(RDBMS)
支持OLAP应用,采用MPP(Massively Parallel Processing:大规模并行处理系统)架构模式
支持OLTP应用,读写性能可扩展
集群级别的ACID与多租户安全
也可被用作分布式Key-Value存储
事务处理与数据分析处理混合型数据库
支持丰富的SQL语句类型,比如:关联子查询
支持绝大部分PostgreSQL的SQL语句
分布式多版本并发控制(MVCC:Multi-version Concurrency Control)
支持JSON和XML格式
缺少的功能
内建的高可用机制
使用外部机制实现高可能,如:Corosync/Pacemaker
有未来功能提升的空间
增加节点/重新分片数据(re-shard)的简便性
数据重分布(redistribution)期间会锁表
可采用预分片(pre-shard)方式解决,在同台物理服务器上建立多个数据节点,每个节点存储一个数据分片。
数据重分布时,将一些数据节点迁出即可
某些外键、唯一性约束功能
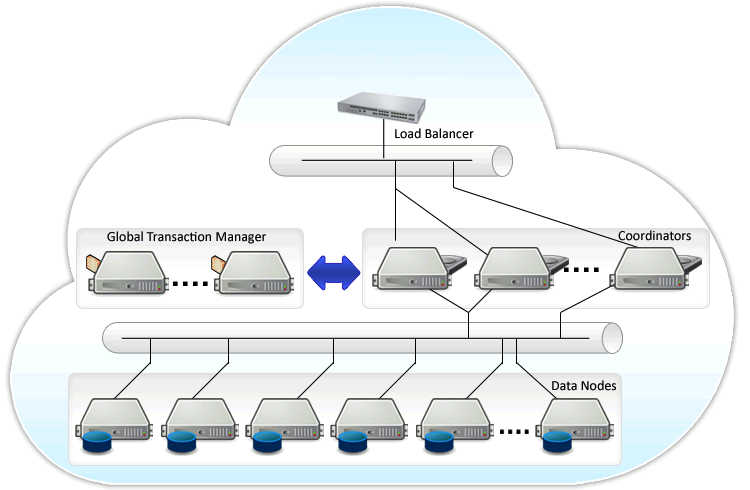
PGXL有三个主要组件,分别是GTM,Coordinator和Datanode:
GTM(Gloable Transaction Manager)负责提供事务的ACID属性;
Datanode负责存储表的数据和本地执行由Coordinator派发的SQL任务;
Coordinator负责处理每个来自Application的SQL任务,并且决定由哪个Datanode执行,然后将任务计划派发给相应的Datanode,根据需要收集结果返还给Application;
GTM通常由一台独立的服务器承担,因为GTM需要处理来自所有Coordinator和Datanode的事务请求。为了将Coordinator和Datanode上进程的请求和响应聚集到一台机器上,可以配置GTM-Proxy。GTM-Proxy会减少GTM的负载,同时会帮助处理GTM失效的情况。即便如此,GTM还是可能会发生单点失效问题,这时可以配置一个GTM-Standby节点作为GTM的备用节点,GTM可以有一个GTM Standby。
每台机器最好同时配置一个Coordinator和一个Datanode,这样既不用担心二者的负载均衡,而且可以降低网络流量。
可以对每个节点增加slave,就类似PostgreSQL的streaming replication一样。针对自动的failover,目前可以使用Corosync/Pacemaker,虽然它们现在还不是核心项目。
Postgres-XL架构
基于开源项目Postgres-XC
XL增加了MPP,允许数据节点间直接通讯,交换复杂跨节点关联查询相关数据信息,减少协调器负载。
多个协调器(Coordinator)
应用程序的数据库连入点
分析查询语句,生成执行计划
多个数据节点(DataNode)
实际的数据存储
数据自动打散分布到集群中各数据节点
本地执行查询
一个查询在所有相关节点上并行查询
全局事务管理器(GTM:Global Transaction Manager)
提供事务间一致性视图
部署GTM Proxy实例,以提高性能
1、协调器(Coordinator),协调员管理用户会话,并与GTM和数据节点进行交互。协调员解析,并计划查询,并给语句中的每一个组件发送下一个序列化的全局性计划。
处理客户端网络连接,是数据库的接入点
分析查询语句,生成执行计划,并将计划传递给数据节点实际执行
对数据节点返回的查询中间结果集执行最后处理
管理事务两阶段提交(2PC)
存储全局目录(Global Catalog)信息
2、数据节点(DataNode),数据节点是数据实际存储的地方。数据的分布可以由DBA来配置。为了提高可用性,可以配置数据节点的热备以便进行故障转移准备。
存储表和索引数据
只有协调器连接到数据节点
执行协调器下传的查询
两个数据节点间可建立一对一通讯连接,交换分布式表关联查询的相关信息
3、全局事务管理器(GTM),全局交易监测,确保群集范围内的事务一致性。GTM负责发放事务ID和快照作为其多版本并发控制的一部分。集群可选地配置一个备用GTM,以改进可用性。此外还可以在协调器间配置代理GTM, 可用于改善可扩展性,减少GTM的通信量。
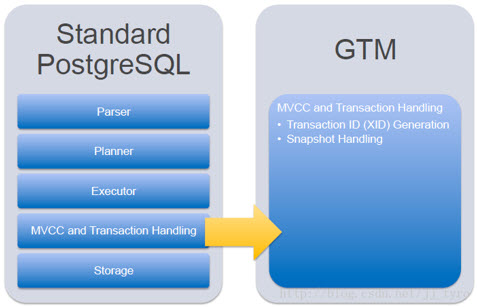
处理必须的MVCC任务
Transaction IDs 事务ID
Snapshots 数据快照,MVCC使用
管理全局性数据值
Timestamps 时间戳
Sequences 序列对象
全集群只有一个GTM节点,会有单点故障问题。解决方案:配置StranBy热备节点保证高可用
通过部署GTM Proxy,解决可能的GTM性能瓶颈
4、GTM Proxy

与协调器(Coordinator)和数据节点(DataNode)在一起运行
后端(协调器、数据节点)用它替代GTM,直接与它交互,它做为后端与GTM间的中间人
将对GTM的请求分组归集,多个请求一次提交给GTM
获取transaction ids(XIDs)范围
获取数据快照
比如:10个进程分别请求一个transaction id
它们每一个都连接到本地的GTM Proxy
GTM Proxy发送请求到GTM,一次申请10个XID
GTM锁定procarray数据结构,分配10个XID
GTM返回XID范围
GTM解除进程互斥锁
可扩展性
Postgres-XL(eXtensible Lattice),可以跨多个节点或者分区表,或复制它们。分区(或分布)表允许跨多个节点的写入可扩展性,以及大规模并行处理(MPP)大数据类型的工作负荷。复制的表是典型的不经常改变的静态数据。复制数据,允许读可扩展性。
完全ACID
Postgres-XL是一款完全符合ACID的事务型数据库。不仅为您提供任何时候都完全一致的视图,而且使用了集群范围的多版本并发控制(MVCC)。当你在Postgres-XL开始一个交易或查询时,你会看到整个集群范围内一致的数据。当你一个连接里读取你的数据时,甚至在没有任何锁定另一个连接里,你可以更新相同的表。归功于全球事务标识符和快照,这些连接正在使用他们自己的版本的行。读取器和写入器互相不阻塞对方。
Postgres-XL数据分布
Postgres-XL数据分布有两种模式: 复制表(Replicated Table)、分布表(Distributed Table)。
复制表(Replicated Table)
益用于只读和读多写很少的表
有时益用于数据仓库的维度表
如果协调器与数据节点一对一部署在同一台服务器,就会是本地数据读取,减少网络传送
对写入频繁的表严重不适用
每行记录复制到集群中所有的数据节点,每节点一份
分布表(Distributed Table)
益用于写入频率的表
益用于数据仓库的事实表
每行记录只存于一个数据节点
可用的分片策略方式
Hash
Round Robin
Modulo
Postgres-XL可用性
无单点故障
全局事务管理器采用热备方式
多个协调器间负载均衡
数据节点使用流式复制,复制数据到备节点
Postgres-XL性能
事务处理型(OLTP Transaction)性能
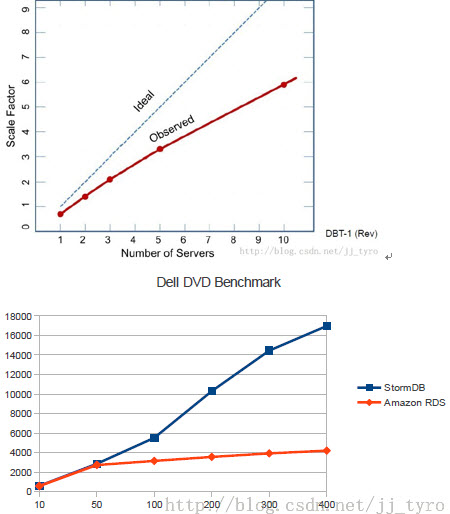
测试使用针对电子商务应用的TPC-W(DBT-1)基准测试模型。
协调层增加了30%的开销:在单节点(CPU4核)上,与简单地直接使用PostgreSQL相比,只有PostgreSQL性能的70%。
集群规模扩大到10个节点时,与单节点PostgreSQL相比,理论上应获得7倍性能提升,实际上达到6-6.4倍。
随着集群节点数的增加,打开的事务数、快照空间占用、可见性检查都会随之增长。
PostgreSQL、Postgres-XC、Postgres-XL之间的区别
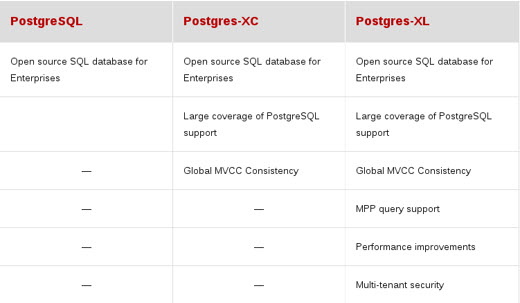
Postgres-XL 是一款Postgres-XC升级的产品, 如果说PGXC是在PG添加了集群的功能主打OLTP的功能为卖点,PGXL 是一款基于PGXC添加了OLAP功能的支持MPP架构的, 但不是简单的POSTGRESQL 单机的功能的堆叠,本身基于的是PG早期的9.5 ,目前最新的版本是Postgres-XL 10R1.1 的版本。
目前有些国产数据库是基于POSTGRES-XL来进行二次研发并推广上市的,实际上POSTGRES-XC是日本NTT电信在2010年的网格化数据库的计划,在2012年一个叫stormDB的公司在POSTGRES-XC 基础上增加了POSTGRES-XC的性能,包含MPP架构,在2013年stormDB被TransLattice 获得并在2014年将这个项目开源,变为POSTGRES-XL。
XC 和 XL 不同在于XC是将数据查询下推到datanode, 而XL使用的MPP架构。另一点的不同在于XC 主攻的方向是 OLTP, XL主攻的方向是OLAP
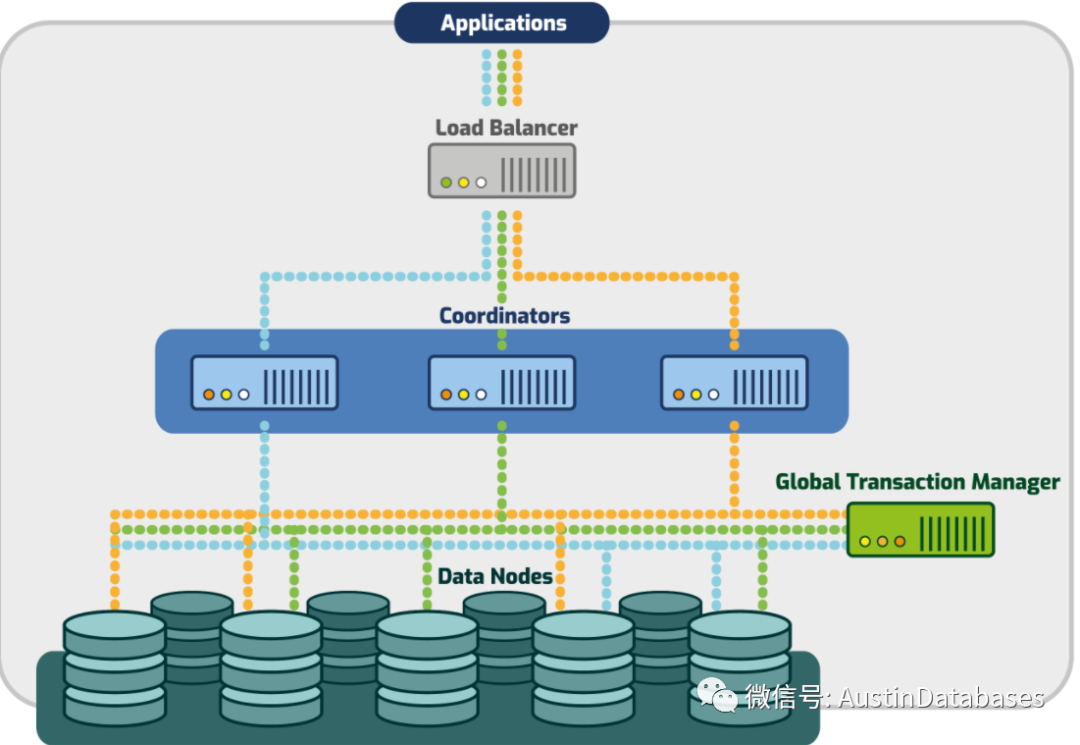
POSTGRES-XL 的主要完成的工作是从应用端接受语句或事务将这些执行的语句,通过coordinator 来对外提供一致性的视图来访问数据库,并且最大化的提供与POSTGRESQL 单机类似的事务处理的方式和数据的展示的方式。数据表被分割成多个片,存储在不同的data nodes,并且对于应用程序来说这些都是透明的。
在分布式成型中,主要的三种模式, 集中式,民主式,令牌式,POSTGRESQL-XL 主要还是使用集中式的方式来完成核心的问题的解决,这点与TIDB 使用PD 的方式类似。这样的方式高效,简单。这也符合简洁就是美的一种想法的理论。
POSTGRES-XL 核心的组件,GTM , Coordinator , datanoade 与TIDB 的 TIDB SERVER , PD , TIKV 也是类似的,目前的两大分布式流派,POSTGRES-XC与XL,以及 TIDB 的 NEW SQL 流派。
POSTGRES-XL 的核心 GTM ,Global Transaction Manager 与PD 功能一致,提供了事务的管理,以及事务的状态和数据的路由的功能。Coordinator相当于postgresql 单机中每个客户连接到数据库的backend process, 但Coordinator 不会存储数据仅仅是一个客户端,这与TIDB SERVER 的功能也是类似的。通过coordinator来获得全局事务ID和事务的SNAPSHOT,通过GXID来看到底哪些datanode可以获取需要的数据。Datanode本身存储数据并且不含有任何的全局的数据视图,根据GXID来完成SNAPSHOT 和数据的存取。
系统中核心的KEY应该是GTM, 主题 POSTGRES-XL并未在POSTGRESQL源码中修改的太多。
这里着重的说说GTM, GTM 功能就是控制事务,提供了有序性的全局时间戳,以及分配GXID 全局事务ID,并且所有事务的状态提供全局snapshot,而全局的SNAPSHOT状态也是通过GXID来实现的,防止其他事务来读取某些“大事务”未提交的行。这里通过记录每个事务的开始和结束时间来去提供SNAPSHOT,以及事务的可见性。
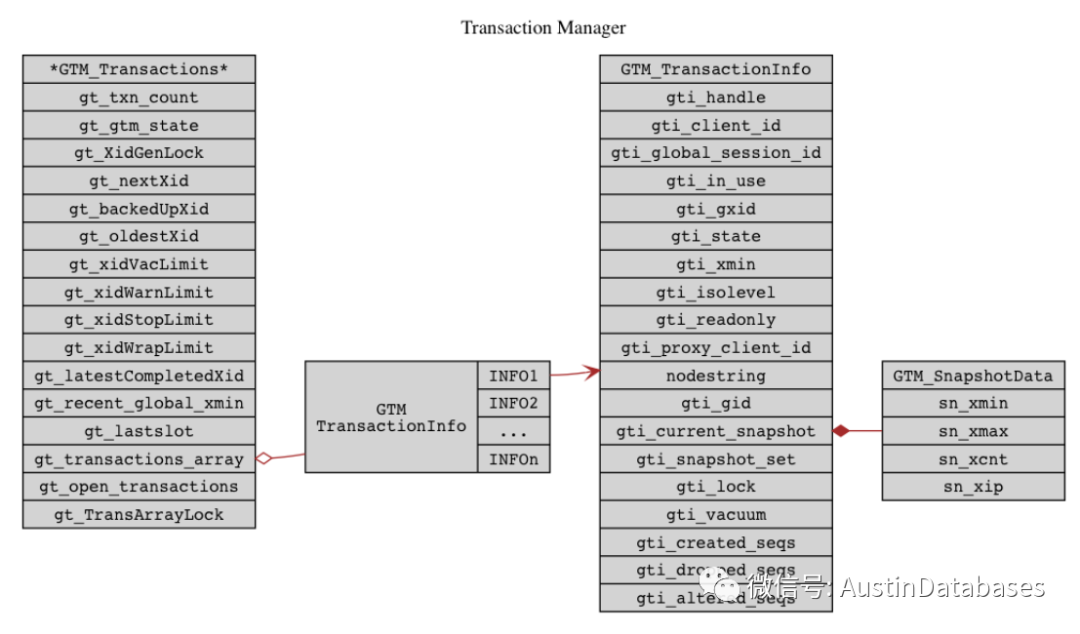
从左到右,每个事务都包含最左侧的信息通过右侧 gtm_transactionInfo 来进行全局事务的操控和snapshot的功能。gtm_snapshotdata 里面的信息是不是和POSTGRESQL 中每行的事务管理的方式类似。同时Postgres-XL是遵循MPP架构的分布式数据库,所以必须对所在数据存储节点进行管理,通过合理的管理来对数据进行有效的访问。
POSTGRES-XL在数据NODE中存储也分为

1、节点均存在数据
2、数据通过算法进行数据的分布
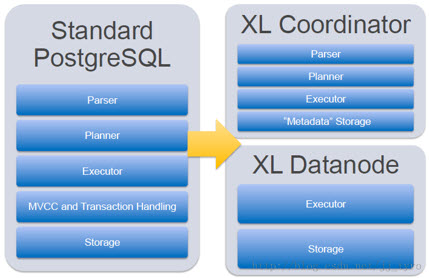
在标准的Standard PostgreSQL和POSTGRES-XL结构中
标准的PostgreSQL包含了
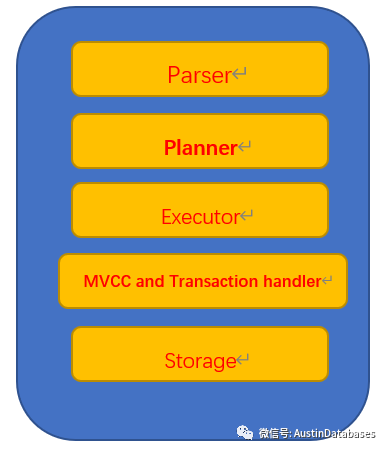
而 XL 系列将这些分别在 Coordinator 和 XL Datanode 完成
Coordinator
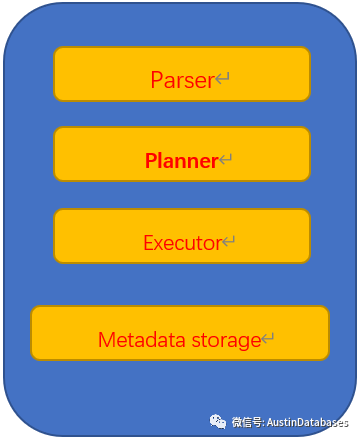
Datanode

所以在POSTGRES-XL 中建立表对于POSTGRES-XL 是非常重要的,如果数据表初始建立错误,或者数据分布有问题,则整体的性能不会太好。
特点总结:
1.支持OLTP高负载的支持
2.支持OLAP场景通过MPP并行的结构来满足OLAP的需求
3.分布式数据存储数据,或根据具体情况进行表复制存储
4.节点的扩展方便快捷,数据具有副本
5.支持多节点分布式数据查询,将数据查询的CPU与I/O使用率分散
6.支持复杂的SQL查询方式,类似单库的查询语句方式
7.基于POSTGRESQL streaming replicaition的数据复制方式
8.表的数据存储通过算法进行拆分到不同node或者表在所有的节点进行复制
9.系统本身不支持datanode 高可用,需要另外采用其他办法进行支持
10.需要的VIP的特性来支持coordinator出现故障后的访问,并且在coordinator中进行均衡负载
当然POSTGRES-XL应用的案例就是腾讯的微信的支付功能,想必POSTGRES-XL在二次开发后的厉害之处已经被证明了。
最新版本:10.1
第二象限公司(2ndQuadrant)近期发布了Postgres-XL最新版本10R1。本次发布的版本包括了很多近期PostgreSQL版本的新特性,例如:并行查询(PostgreSQL 9.6)和声明式分区(PostgreSQL 10),另外在性能上较之前版本也有很大的提升。该版本的主要提升总结如下:
声明式分区表
并行查询提升
明显的性能提升
监控和控制能力提升
顺序扫描、链接和聚合性能提升
vacuum时避免扫描不必要的列
新版本也包括一些既有bug的修复,如果想要查看详细信息,请参考官网release note。
官方主页:http://www.postgres-xl.org/