分布式文件系统-JuiceFS
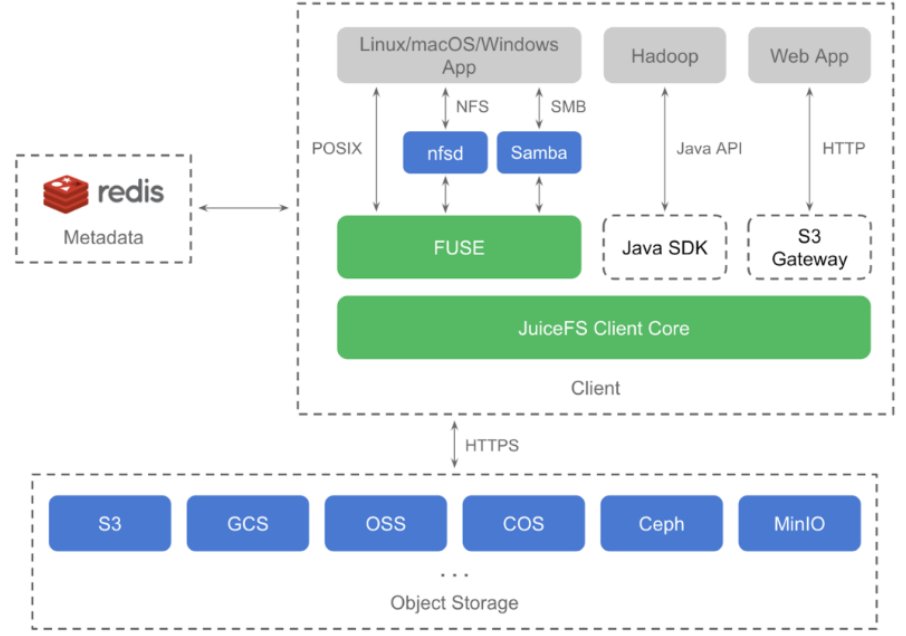
 JuiceFS 是基于 Redis 和对象存储构建的开源 POSIX 文件系统,针对云原生环境进行了设计和优化。通过使用广泛采用的 Redis 和 S3 作为持久性存储,JuiceFS 可以用作无状态中间件,以使许多应用程序轻松共享数据。采用Go语言开发并在AGPLv3协议下授权,2022年1月,Juicedata团队决定自v1.0起将许可更改为ApacheV2.0。
JuiceFS 是基于 Redis 和对象存储构建的开源 POSIX 文件系统,针对云原生环境进行了设计和优化。通过使用广泛采用的 Redis 和 S3 作为持久性存储,JuiceFS 可以用作无状态中间件,以使许多应用程序轻松共享数据。采用Go语言开发并在AGPLv3协议下授权,2022年1月,Juicedata团队决定自v1.0起将许可更改为ApacheV2.0。JuiceFS relies on Redis to store file system metadata. Redis is a fast, open-source, in-memory key-value data store and very suitable for storing the metadata. All the data will store into object storage through JuiceFS client.
JuiceFS 进行了架构升级,将元数据服务改造为支持多引擎的插件式架构,可以利用已有的开源数据库实现元数据存储。JuiceFS 目前选用 Redis 作为第一个开源存储引擎,未来还会增加 SQL 数据库、TiKV 等支持事务的 KV 数据库支持。
2021年1月11日, Juicedata 果汁数据科技宣布开源分布式文件系统 JuiceFS。
据悉在开源之前,JuiceFS 已经历经 4 年的持续迭代,并在几十家科技企业业务中应用,SaaS 使用量也持续快速增长,在刚刚过去的 2020 年实现了盈亏平衡。其开发团队认为,闭源的基础软件会限制使用者对它的深度理解,因此依靠 SaaS 产品的收入支撑和开源社区的力量,希望 JuiceFS 可以被更广泛使用。在创业之初,认为 SaaS 可以为用户提供最佳的体验,同时让更快地迭代产品,决定优先把 SaaS 做好。JuiceFS 已经在大数据、AI、容器平台、归档、备份等场景中形成最佳实践,公司相信找到了可持续发展的模式,有信心保障 JuiceFS 的长期运营。
JuiceFS Storage Format
The storage format of one file in JuiceFS consists of three levels. The first level called "Chunk". Each chunk has fixed size, currently it is 64MiB and cannot be changed. The second level called "Slice". The slice size is variable. A chunk may have multiple slices. The third level called "Block". Like chunk, its size is fixed. By default one block is 4MiB and you could modify it when formatting a volume (see following section). At last, the block will be compressed and encrypted (optional) store into object storage.
目前的突出功能包括:
完全兼容 POSIX:JuiceFS 是完全兼容 POSIX 的文件系统。现有的应用程序可以直接使用它。
性能:延迟可以低至几毫秒,并且吞吐量可以扩展到几乎无限。
Cloud Native:通过利用云对象存储,可以扩展存储和独立计算(也称为分解存储和计算架构)。
共享:JuiceFS 是一个共享文件存储,可以由多客户端读取和写入。
全局文件锁:JuiceFS 支持 BSD 锁(flock)和 POSIX 记录锁(fcntl)。
数据压缩:默认情况下,JuiceFS 使用 LZ4 压缩所有数据,也可以使用 Zstandard。
所支持的对象存储源:
Amazon S3
Google Cloud Storage
Azure Blob Storage
Alibaba Cloud Object Storage Service (OSS)
Tencent Cloud Object Storage (COS)
QingStor Object Storage
Ceph RGW
MinIO
Local disk
Redis
文件系统是计算机中一个非常重要的组件,为存储设备提供一致的访问和管理方式。在不同的操作系统中,文件系统会有一些差别,但也有一些共性几十年都没怎么变化:
1、文件以树形目录进行组织;
2、数据是以文件的形式存在,提供 Open、Read、Write、Seek、Close 等API 进行访问;
3、提供原子的重命名(Rename)操作改变文件或者目录的位置。
文件系统提供的访问和管理方法支撑了绝大部分的计算机应用,Unix 的“万物皆文件”的理念更是凸显了它的重要地位。JuiceFS 是一款开源分布式文件系统,创新的将对象存储作为底层存储介质,实现了存储空间的无限扩展。任何存入 JuiceFS 的文件都会按照特定规则被拆分成固定大小的数据块保存在对象存储,数据块的元数据则保存在 Redis、MySQL 等数据库中。
作者:苏锐,Juicedata 合伙人,作为1号成员参与创建分布式文件系统 JuiceFS,先通过全球公有云上的 SaaS 产品获得国内外几十家商业客户,之后于 2021 年 1 月 JuiceFS 开源。毕业于西安电子科技大学。在北航攻读硕士期间,作为早期工程师加入傲游(Maxthon)浏览器。08 年作为创始员工加入一家非盈利机构“多背一公斤”,将自助旅行和乡村教育支持创造性的结合起来构建线上社区,荣获奥地利 Prix Arts 数字社区金奖,也是第一个获得该奖项的中国项目。2010 年加入豆瓣,任职 Tech Lead。2014 年创立上门汽车服务品牌功夫洗车,并任 CEO 带领团队完成两轮融资。2017 年作为 1 号成员参与创建 JuiceFS 加入 Juicedata 开始新一次创业。
云原生文件存储技术,在苏锐的眼中是个不那么大众的细分技术领域。简单来说,云原生文件存储就是运用在云原生环境的存储技术,一般具有高可用性、强大的可扩展性、可靠性、动态部署等特性;并且针对公有云、私有云和混合云等不通过形态的平台,也有不同的解决方案。在其描述中,存储技术演化到今天,是跟随技术变迁进程的。在计算机发展之后,文件存储其实是一个很古老的传统领域。它的第一代产品诞生于 90 年代 —— 传统旧式的单体式存储,它与专有硬件和专有软件进行捆绑销售。
90 年代,上个网还需要拨号。当时的网络存储一般使用的是专有硬件设备方案(通常指 NAS,Network-Attached Storage,网络接入储存),通过特殊的高性能通讯硬件给其他应用提供访问接入。
1992 年 ,NetApp 诞生。它是这一代企业存储技术的代表,其产品形态就是软硬件一体的,发展至今 NetApp 成为这一行业的龙头。“那个时候,每家公司想要买存储容量,就必须买一个硬件柜子,里面插满了硬盘。在门户网站的时代,网站只能发布信息,这样的存储技术是够用的。” 苏锐表示。
2003 年,Google 的 GFS 开创了先河,第一次用普通的 x86 机器和普通硬盘搭建了大规模存储,分布式存储出现了。2005 年,这一成果与 MapReduce、BigTable 一起成为谷歌引爆大数据时代的“三驾马车”。
同样在 2005 年左右,Web2.0 产品形态涌现,其最大的特点是 UGC(User Generated Content,用户生产内容)。其中,以 Facebook、Twitter、人人网等社交网络为代表。这意味着,每天每个网民都在创造大量数据,互联网的数据量比上一个时代有了数量级上的提升,继续用“买柜子”的方式,根本满足不了这么大的数据需求。
于是,企业存储的“二代目” —— SDS(Softwere Defined Storage,软件定义存储)出现了。不同于 NAS,SDS 一般都在行业标准的 x86 系统上执行,消除了软件对于专有硬件的依赖性,大幅提高了灵活性。
在 2005~2009 年这段时间窗口,全球范围内诞生了很多的分布式文件系统的产品,比如 HDFS(Hadoop)、Ceph、GlusterFS 、MooseFS 等等,这些软件都得到了广泛应用。而且,值得注意的是,他们其中大多数都为开源软件。
SDS 是一个技术堆栈层,可以使用行业标准服务器提供服务
又一个十年后,移动互联网让互联网上的数据再次以数量级形态上升,让上一代的文件系统有点捉襟见肘了。此前,亚马逊推出 AWS 公有云,云计算搅动一潭春水。AWS S3(Simple Storage Service)赶上了好时候,它有弹性、可伸缩、想存多少就存多少,其拓展能力和成本优势立马让它脱颖而出,整个互联网的数据都在往 S3 上搬。但是,S3 在满足拓展能力的同时,相比之前的存储产品又舍弃了很多其他功能,比如丰富的访问接口、数据的强一致性保证、高性能的元数据访问、原生目录树结构、有原子性保证的 rename 等基础操作等。很多公司不得不做大量的工程改造才能把 S3 用起来,Juicedata 创始人刘洪清当时所在的 Databricks 就在其中。
2016 年,刘洪清给公司提案,要自研新的存储方案,以系统性地解决问题。当时的 Databricks 也还在创业初期,公司研发团队大多擅长分布式计算领域,认为还不适合投入分布式存储的研发。这个决定也促成了 JuiceFS 的诞生。换个角度说,是 S3 的短板促成了 JuiceFS 的诞生。在设计中,JuiceFS 是一款面向云原生环境设计的高性能分布式文件系统,为云环境设计,提供完备的 POSIX、HDFS 和 S3 API 兼容性。使用 JuiceFS 存储数据,数据本身会被持久化在对象存储(例如,Amazon S3),相对应的元数据可以按需持久化在 Redis、MySQL、TiKV、SQLite 等多种数据库中。
如果说 2005 年左右的那次的技术更迭期,是面向机房的。那么,这次(2015~2016年)存储技术的创新冲动则是由云时代开启的。“我们希望产品能在云上使用,但这些产品在架构上并不适合云,也发挥不出云的优势。而 S3 又存在功能上的不足,满足不了复杂的数据需求。如果能有一个全功能的文件存储,又同时能兼具 S3 的产品优势,就非常理想了。”苏锐表示。
2017 年 4 月,刘洪清和苏锐着手组建了 Juicedata。在他们的构想中,Juicedata 要解决过去文件系统在规模和能力上的一些限制,在云上提供一种新的体验,并且要继承以前几十年积累下来的文件系统上层构建的生态。
2021 年 1 月 11 日,JuiceFS 开源了,推出的开源版是一个建立在 Redis 和 S3 等对象存储(比如 AWS S3、阿里云 OSS)之上的开源 POSIX 文件系统。它是为云原生环境设计,通过把元数据和数据分别持久化到 Redis 和对象存储中,它相当于一个无状态的中间件,帮助各种应用通过标准的文件系统接口来共享数据。值得注意的是,Juicedata 将元数据引擎的相关代码进行了“可插拔”改造,引入了对关系型数据库和事务型 KV 存储的支持,解决了可靠性和可扩展性问题,用开放式的架构去支持社区里各种各样开源的存储引擎,让他们可以结合到 JuiceFS 上来用。
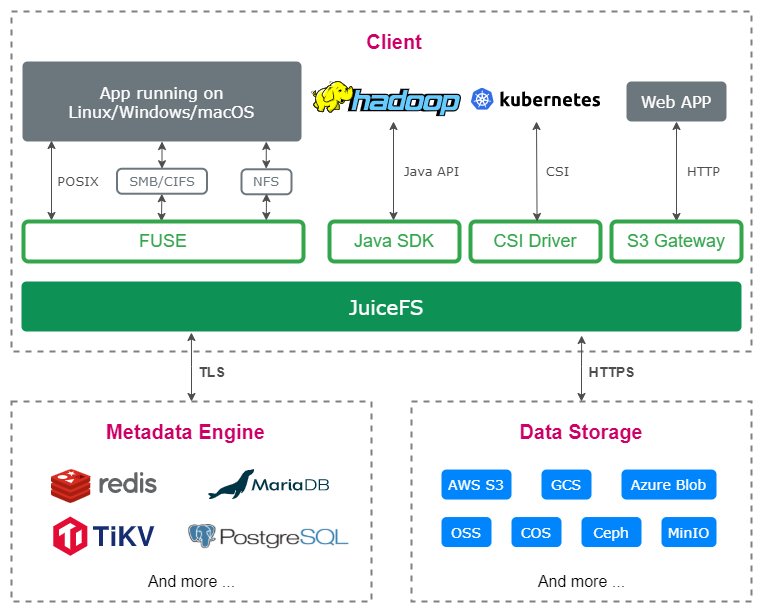
在 Juicedata 的设计中,Metadata Engine 和 Data Storage 里面很多组件可以相互替换
这样一来,社区版本的用户可以结合自己的场景去选择合适的引擎;同时,用户在其他存储引擎(比如 Redis、 MySQL 等)上积累的经验可以使他很快上手,大大降低了用户的使用门槛。目前, JuiceFS 的闭源引擎更多主打海量文件规模以及极致性能这样的场景。这个场景不是所有企业都有需求,多数企业从社区版就能满足自己的大部分业务需求,而一些特定业务则是需要企业版本支持。至此,JuiceFS 的社区版本和企业版本形成了一个较好的相互补充关系。
2022 年 1 月,Juicedata 团队决定自 JuiceFS v1.0 起将许可更改为 Apache 2.0。而此之前,他们一直采用 AGPLv3 许可证。“刚开源的时候,我们认为需要选择一个能够保护我们的许可证。因为我们看到这几年,一些知名的开源项目和云厂之间有一些纠纷。如果我们选择 AGPLv3,那么厂商就不能拿你的项目去做托管服务。”苏锐表示。此外,文件存储界使用最广泛也是 AGPLv3。但随着 JuiceFS 的不断迭代,有一些开源社区和开发者希望将 JuiceFS 作为存储底座,整合到自己的项目中,但 AGPLv3 与其他开源协议(比如 Apache 协议)的兼容性却不太好。为了建立更加丰富的生态,Juicedata 最终转向了 Apache 2.0 许可证。
JuiceFS 是为云环境设计的分布式文件系统,元数据和数据都可以借助已有的成熟组件来实现,避免重复造轮子,大大降低了复杂度,可以给用户提供简单易用且稳定可靠的统一文件存储方案。目前它已经支持 10 种以上元数据引擎和 30 种以上数据存储引擎,丰富的元数据和数据引擎选择使得用户可以灵活应对多变的企业环境和数据存储需求;同时 JuiceFS 兼容 POSIX、 HDFS、S3、WebDAV 访问协议,也可以在 Kubernetes 中作为持久卷(PV) 使用,完善的兼容性让数据能够在各个应用中流通自如。
问:JuiceFS 是依赖 redis、mysql 什么版本呢?如何考虑系统安全问题呢?
答:Redis 可以参考最佳实践,各种引擎用流行的版本都能支持,JuiceFS 会尽量兼容更多的引擎和版本。
问:JuiceFS 的对象存储相对传统的块存储分布式文件系统有啥优点?JuiceFS 的存储现在是针对什么业务场景使用的?
答:JuiceFS 是一个 object-based 的分布式文件系统,相比 block-based 有更好的弹性。Object Storage 可以认为是完全弹性的,但是 Block Storage 大多做不到。目前 JuiceFS 主要用在 大数据、AI、DevOps 和各种需要 NAS 的应用场景,在 juicefs.com 上可以看到很多案例和客户实践。
问:如果文件被拆分成固定大小的数据块,那这些数据块是怎么保证顺序的,以及数据库块的大小是固定的吗?会不会出现大量的内存碎片?读取的时候是不是要占用大量内存进行合并数据库?
答:比如想读 1GB 的文件,在存储中是 sequential read。如果全部读出来返回给请求端,更占内存,调用端的等待时间更长。都是 4K/64K/256K/1M 等容量去顺序读,以一个 streaming 的方式持续返回给调用端。所以 JuiceFS 把文件分成 block 存储不会影响性能。相反,还能提升性能。因为更容易通过并发方式同时读很多的 block 返回给调用端,当然获得高吞吐的同时,需要用一点内存资源来换。文件被分成很多 data block 存在对象存储中,每个 block key 会存在 meta engine 里(直接存太占空间了,设计上 16 个 block 为一个 chunk,存储 chunkid + offset)。block size 默认设为 4MiB 是最大值,实际会有小于该值的 block。碎片合并有的。读取的时候不用担心,各种存储系统在读的时候也都是按某个大小的 page/block 去读。
问:考虑到存取速度、修复难度以及迁移,对于底层文件系统的选择有什么推荐的吗?
答:存取速度容易判断,结合你的业务场景来测试评估就行了。我想说的是在分布式存储中,只用一些 Benchmark Tool 来看跑分和实际业务场景中的表现是有不同的,一定用业务场景来测试。迁移方面,通用流行的访问协议都不难,比如 JuiceFS 完全兼容 POSIX、HDFS、S3,还提供 juicesync 这个数据迁移工具,兼容几十种对象存储的 API。要考虑的是数据迁移中,业务的影响。
问:JuiceFS 的跨节点、机架、机房、区域的副本放置策略,可用性程度,能不能简单讲讲:一致性协议的实现以及涉及到元数据管理,主丛切换的及时性和正确性,最后就是各种突发情况下主从同步的策略,全面高效的负载均衡(空间/吞吐/副本)。
答:JuiceFS 社区版使用流行的数据库引擎,包括Redis、MySQL、PostgreSQL、TiKV这些,每一个都有很多运维的实践经验。部署和运维的方案都用这些数据库引擎社区推荐的,必要的地方 JuiceFS 会提供一些最佳实践,比如使用 Redis 做元数据引擎。
问:JuiceFS 是否提供开放 Key-Value Storage 的 API 接口,以及有哪些支持的程序设计语言?另外,对于有大量小文件写入的效率如何?
答:可以用 S3 API 读写 JuiceFS 数据,参考文档,如果以 POSIX 方式访问,各种编程语言都原生支持了。编程语言的 SDK 目前有 Java SDK(是兼容 HDFS API 的)。
问:对于大文件的拆分性能是如何?
答:JuiceFS 的优势所在,参照文档。
问:1.JuiceFS和 NAS NFS 存储有啥区别?JuiceFS 优势在哪里?2.JuiceFS 使用了什么设计模式?
答:1. 相比 NAS,JuiceFS 为云环境设计;弹性容量;更丰富的访问方式,包括 POSIX、HDFS、S3、K8s CSI;在 大数据、AI、DevOps 和众多需要 NAS 的场景上都适用,更高性价比 2. 参考架构设计采用元数据与数据分离的设计方案。
问:同 Ceph 是一类产品吗,如果是优势在哪里?
答:和 CephFS 是一类产品,详情可以参考文档。
问:看了一篇利用 JuiceFS 实现 mysql 数据备份性能提升 10 倍的文章 里面用到的 JuiceFS 自带的性能分析工具真的不错,希望老师能分享下它的设计和架构。
答:可以参考文档,然后再去看对应的代码实现。
问:JuiceFS 主要应用场景是什么呢?
答:JuiceFS 可以应用于大数据、AI、容器平台、DevOps 等场景,具体可以参考文档。
问:在官方文档中看到了 JuiceFS 和 Ceph、Alluxio 等产品的对比,但是感觉实际中的竞争对手可能是 MinIO 或者 OZone,请问是否做过与这2个产品的对比呢?最近在做对象存储的技术调研,主要是存储照片、音视频和文本文件等,麻烦给一些意见,感谢!
答:MinIO 和 OZone 都是对象存储。JuiceFS 是文件系统,可以使用他俩做后端的持久层服务。如果您的需求是存储和访问,没有计算、分析、训练等场景,应该直接用对象存储更适合。
问:请问下 JuiceFS 对于海量的小文件存储适合吗?性能如何?客户有历史文件,包括上亿的文件夹和文件。
答:使用 Redis 做元数据引擎推荐存储 2亿以内文件,使用 TiKV 适合更大规模。性能要看场景,对于训练等读为主的场景有 cache 机制加速,性能不错。如果 1 亿文件 Redis,MySQL,TiKV 都没有问题。要看你对哪个系统更熟悉,更有维护经验。性能方面要看业务场景、访问方式来做判断。
问:请问在底层实现上是如何保证分布式文件系统的文件完整性的?
答:简单说几点:1. 先写数据再写元数据,保证元数据写成功则数据完整;2. 元数据这边靠引擎的事务性来保证完整;3. 写进去之后 数据和元数据本身的可靠性分别依赖对象存储和元数据引擎来保证;4. 会使用对象存储提供的 checksum 能力。
问:这个是类似 Fastdfs 做文件存储的吗,有什么区别现在企业中哪个好用?
答:JuiceFS 面向云环境设计,在云环境中可以很容易用起来,也天然的做到弹性伸缩。在访问时支持 POSIX、HDFS、S3,在上面做应用开发更方便,尤其是组织各种 Pipeline。
问:如果数据库坏了,恢复了比如说一天前的备份,文件数据也能确保恢复到一天前的状态,并能持续工作下去吗?
答:可以部分恢复,各种数据库也都有更细粒度的容灾方案,比如 Redis AOF、MySQL Binlog,可以最大限度减少数据丢失风险。另一方面,生产环境上也会用主备策略。数据删除后,无论是元数据还是对象存储中的数据都会被删除。如果元数据恢复到之前一天的状态,数据不能被恢复,也是读不出来的。
问:有没有可能,在对象存储中也存一个类似 binlog 的概念的日志,当数据库数据丢失又未备份时,可以通过这个类似 binlog 的结构,还原整个数据库?
答:新版上增加了自动备份元数据到对象存储的功能,算是多一个备份。
问:我认为,分布式文件系统,依赖于关系型数据库,是设计思路错误。正确的应该是反过来,关系型数据库,依赖于分布式文件系统。这样在单个数据库中,对应的后台硬盘空间是无限的。无论应用系统有多少容量的数据,关系型数据库都可以在不分库、不分表的情况下,通过增加新磁盘、调整分布式文件系统配置参数,来解决问题。不知道苏老师怎么看?
答:理解您的说法,我也部分认可。JuiceFS 的架构设计在 High level 上与 Google File System 的那篇论文一直,采用元数据与数据分离管理的方式,也有很多其他的分布式文件系统用了这个思路。不同的地方时,在 Low level design 中,目前看到的大部分 DFS 面向裸磁盘设计。但放在云时代,我们重新抽象的去看这个问题,再结合我们自己十余年使用 DFS 的业务经验。DFS 承载了非常丰富的Workload,对于规模、性能、持久性、可用性、成本等不同维度的要求是不一样的。我们尝试回答一个问题:如何用一个产品更好、更灵活的满足更多、更丰富的业务场景?
然后,在 JuiceFS 的架构设计上,选择用对象存储做数据持久层(类似 chunk server,data node),因为对象存储提供了成熟的 scalebility、availibility、high throughput、low cost 三方面的优势,这正是数据持久层需要的核心能力。
元数据引擎做了插件式设计,Redis、MySQL、TiKV、FoundationDB 等有各自的优势,能满足不同的业务场景需求。选择这些成熟、流行的系统,另一个好处是在开发者中已经积累了大量的使用和运维经验,不用增加学习负担。这是 JuiceFS 设计社区产品的理念,友好的使用体验,低学习门槛,合适但无需极致(我们另有极致版的设计)。
最新版本:1.1
历时 13 个月的开发,JuiceFS v1.1 于2023年9月上旬正式发布,这是继 v1.0 版本后,第二个长期维护的稳定版(LTS),与 v1.0 完全兼容。
新功能快速浏览:大规模数据管理更轻松
JuiceFS 在大数据、机器学习等场景中被广泛使用,用户的数据规模不断扩大,其中不乏文件数超过 100 亿的集群,如何管理好这海量的文件是目前的挑战。为此 v1.1 引入了以目录为单位的空间使用统计,并新增如下功能:
目录配额:为目录设置配额限制,控制其大小和文件数,以防止个别用户占用过多资源影响整个系统的稳定性;
目录克隆:在需要复制大量文件的情境下,使用此功能可以仅拷贝元数据,实现快速复制目录及其内容,从而节省时间和空间;
快速查看用量信息:可以快速查看存储空间和文件数量的统计信息;
支持 FoundationDB 作为元数据引擎:这是一款由 Apple 公司开源的分布式数据库,具有高性能、高扩展性和高容错性的特点;
支持 GlusterFS 作为数据存储:进一步简化自建对象存储的扩容和运维问题。
更安全
减少权限安全隐患和防止误操作:在 mount 时通过 --root-squash 选项来将 root 用户映射为一个非特权用户;
可设置特殊标记位来控制文件的行为:在 mount 时通过 --enable-ioctl 选项开启对 ioctl 的部分支持,如 append only (a) 和 immutable (i) ;
防止因硬件异常导致的缓存数据错误:为本地缓存文件增加了完整性校验。
更稳定
解决与对接组件的兼容问题:
为 TiKV 添加独立的 GC 线程,解决其在没有部署 TiDB 组件时无法自行 GC 的问题
提升以 gateway 方式使用 JuiceFS,以及在 Hadoop 生态中使用时的兼容性
调整特定场景下的使用策略:
修复了高配机器上 FUSE 占用过多 CPU 问题
重构了数据对象清除控制方式,能更好地调节待删除对象的清理速度
增加了 cache-scan-internal 选项来自定义本地缓存的扫描时间,并且可以选择只在启动时扫描一次或完全关闭扫描
增加了 cache-eviction 选项来调整本地缓存清理策略
增加了 skip-dir-nlink 选项来减少在同一目录下并发创建目录导致的元数据事务冲突
修复可能导致客户端奔溃的 Bugs:
元数据引擎中某些值异常会导致客户端 panic
客户端在并发执行 truncate 和 release 操作时可能会死锁
更易用
一键收集诊断信息:提供一键生成诊断报告的功能,方便排查问题和提供反馈意见;
一键恢复回收站文件:可以一次性地恢复某段时间内所有被删除的文件,无需逐个操作;
无需挂载就可以进行数据同步:在使用 sync 工具时,新支持了 jfs:// 前缀来访问 JuiceFS 中的数据;
自动添加开机启动:在 mount 时加上 --update-fstab 选项,会自动在系统中添加相同挂载参数的开机启动;
提升了查看文件内部结构 info 命令的性能,且展示更多丰富有用的信息;
增强了 fsck 命令,使其在一定条件下能修复损坏的目录信息;
增强了垃圾回收 gc 命令,当待删除对象积累过多时可用其来执行手动清理;
进一步提升了数据同步命令 sync 的性能,并添加了多个策略参数来应对不同的需求。
更多生产环境验证:社区使用规模成倍增长
JuiceFS 社区版于 2021 年 1 月正式开源,在全球范围内获得了众多用户的关注与应用。在文件存储领域,JuiceFS 已经成为增长速度最快的项目之一,目前在 GitHub 上已获得 8.5K 颗星标 。 相比去年发布 JuiceFS v1.0 时,匿名上报的用户使用指标都有了大幅增长。其最初为大数据平台上云设计,同时随着 AI 技术的持续发展,JuiceFS 在 AI 领域也有了越来越多的应用和案例,包括自动驾驶、 AIGC、大语言模型等场景。目前,将 JuiceFS 应用于生产环境的用户包括有移动云、航天宏图、小米、vivo、百度、携程旅行、大疆、理想汽车、思谋科技、上汽集团、地平线、云知声、深势科技、商汤、Shopee、知乎、网易游戏、一面数据等企业,还有济南超算中心、国家天文数据中心等。
社区持续活跃,共建云原生生态
在过去的 13 个月中,社区版 JuiceFS 一直保持着高度活跃的状态。新增的 issue 数量达到 410 个,合并的 PR 数量为 920 个,贡献者人数更是达到了 102 人,较前一年增长 100%。社区用户的规模也在不断壮大,中文社区已建立了第 6 个微信群。社区交流活动也在积极推进,每两周举行一次线上 Office Hours 活动,每月举办一次 Meetup,确保用户可以通过多种渠道交流问题。值得一提的是,在过去一年中,JuiceFS 在海外也获得了越来越多的关注,海外用户贡献了 30% 的 Issues 和 24% 的 Pull Requests;在使用社区版的用户中,海外用户占比超 30%,其中美国 16.9%,欧洲 8.1%,亚洲 6.1%(中国大陆以外地区)。
JuiceFS 社区版采用 “Apache 2.0” 许可,使用户可以放心将 JuiceFS 应用于各种商业环境。这不仅允许用户根据自身需求进行二次改进,还便于与上下游应用进行更深度的融合,共建云原生生态。在 v1.1 版本中,JuiceFS 和 Fluid 在数据迁移、目录配额和 JuiceFSRuntime 等方面进行了多项优化。以下这些备受期待的功能将在未来的版本中逐步实现,欢迎大家一起来共建:
分布式数据缓存、支持 Kerberos 和 Ranger、挂载点平滑升级、POSIX ACLs、用户和组配额等。
v1.1 下载链接,升级注意事项。
项目主页:https://github.com/juicedata/juicefs