面向文档的数据库-CouchDB
 Apache CouchDB 是一个面向文档的数据库管理系统。它提供以 JSON 作为数据格式的 REST 接口来对其进行操作,并可以通过视图来操纵文档的组织和呈现。CouchDB一种半结构化面向文档的分布式,高容错的数据库系统,其提供RESTFul HTTP/JSON接口。其拥有MVCC特性,用户可以通过自定义Map/Reduce函数生成对应的View。在CouchDB中,数据是以JSON字符的方式存储在文件中,CouchDB 是 Apache 基金会的顶级开源项目,其争品为另一个分布式文档存储数据库:MongoDB。
Apache CouchDB 是一个面向文档的数据库管理系统。它提供以 JSON 作为数据格式的 REST 接口来对其进行操作,并可以通过视图来操纵文档的组织和呈现。CouchDB一种半结构化面向文档的分布式,高容错的数据库系统,其提供RESTFul HTTP/JSON接口。其拥有MVCC特性,用户可以通过自定义Map/Reduce函数生成对应的View。在CouchDB中,数据是以JSON字符的方式存储在文件中,CouchDB 是 Apache 基金会的顶级开源项目,其争品为另一个分布式文档存储数据库:MongoDB。CouchDB落实到最底层的数据结构就是两类B+ Tree。
Apache CouchDB is a document-oriented database that can be queried and indexed in a MapReduce fashion using JavaScript. CouchDB also offers incremental replication with bi-directional conflict detection and resolution.
CouchDB provides a RESTful JSON API than can be accessed from any environment that allows HTTP requests. There are myriad third-party client libraries that make this even easier from your programming language of choice. CouchDB’s built in Web administration console speaks directly to the database using HTTP requests issued from your browser.
CouchDB is written in Erlang, a robust functional programming language ideal for building concurrent distributed systems. Erlang allows for a flexible design that is easily scalable and readily extensible.
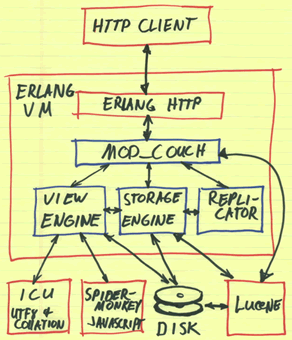
与现在流行的关系数据库服务器不同,CouchDB 是围绕一系列语义上自包含的文档而组织的。其中的文档是没有模式的(schema free),也就是说并不要求文档具有某种特定的结构。它的这种特性使得相对于传统的关系数据库而言,有自己的适用范围。一般来说,围绕文档来构建的应用都比较适合使用 CouchDB 作为其后台存储。CouchDB 强调其中所存储的文档,在语义上是自包含的。这种面向文档的设计思路,更贴近很多应用的问题域的真实情况;对于这类应用,使用它的文档来进行建模,会更加自然和简单。与此同时,CouchDB 也提供基于 MapReduce 编程模型的视图来对文档进行查询,可以提供类似于关系数据库中 SQL 语句的能力。它对于很多应用来说,提供了关系数据库之外的更好的选择。
CouchDB是一个文档数据库,它是一个支持复制的(Replecated)文档数据库,具有REST接口,也就是说可以在 HTTP上,用标准的GET、PUT、POST动词去访问。而且它用JavaScript作为查询语言去建立数据视图(View)。在SQL数据库里,你要定义各种表和表中的数据类型及大小,CouchDB不一样,它是没有Schema的。在CouchDB里,每个文档都是独立的对象,可以是任意的 JSON结构。这是技术上的表述。那么它的优点在哪里呢?它有利于构建很多协作型的应用,很多Web应用都是围绕着文档、上下文、任务、Bug报告,诸如此类的东西。这些就是CouchDB最擅长的方面。
特性
* RESTFul API:HTTP GET/PUT/POST/DELETE + JSON
* 基于文档存储,数据之间没有关系范式要求
* 每个数据库对应单个个文件(以JSON保存),Hot backup
* MVCC(Multi-Version-Concurrency-Control),读写均不锁定数据库
* 用户自定义View
* 内建备份机制
* 支持附件
* 使用Erlang开发
原理
在CouchDB中,Database表示一个数据库,每个Database对应一个"Storage"(后缀为.couch)以及多个View Index(用来存储View结果支持query)。
Database Storage中可以存储任意的Document,用户可以在Database中自定义View,方便对数据进行查询, View 默认使用JavaScript进行定义,定义好的相关函数保存在 design document中,而View对应的具体数据是保存在View Index文件中。我们可以通过HTTP API请求Database,Document,View,可以进行简单的Query,以及其他各种系统相关的信息。
让人头痛的几大问题
下面十条内容来自paperplanes的博主Mathias Meyer在2010年5月的博客,他也是一位NoSQL的实践者,CouchDB就是其钟爱的数据库之一。正所谓爱之深恨之切,在使用CouchDB的过程中,他发现很多不顺手的地方,就是下面列举的十大问题。
View是在读时更新的
我们知道CouchDB不支持动态查询,也就是说你的每个查询,都需要事先创建一个对应的View,创建View是很快的,即使你的数据集很大,这 是因为CouchDB并不在创建View的时候就建立View索引,而是在读取的时候来做这个事。当在一个View上执行一次读操作时,CouchDB会 对比当前View中的索引更新时间与最后写操作时间,如果发现在索引更新之后又有写操作,那么会把这段时间的写操作合并到索引中再返回给客户端。
你可以想象到,如果数据集非常大,你创建完View后的第一次读取会是多慢。同样的,如果你两次读操作间隔期间有太多的写操作,那么也会导致读操作 非常慢,有的朋友通过cron任务定时对View进行查询,从而触发定时的索引更新操作,以减少真正读操作需要等待的时间,不得不说这真是蛋疼。这一切, 都是因为CouchDB的View是在读时更新导致的。
而实际上,如果你不愿意等待CouchDB去更新完索引后再返回数据,你也可以通过stale=ok参数指定它返回老数据即可,不用做更新操作。但 我们不能总是访问老数据,作者希望可以通过指定查询先返回老的数据,再进行相应的索引更新操作。而实际上这一功能已经在1.1.0版本中实现了,在 1.1.0版本中,添加了一个stale=update_after的指定,可以实现返回老数据后再在后台更新的功能。
缺乏自动压缩功能
CouchDB采用了append-only的方法进行数据更新,也就是所有数据的写操作,都不会修改原来的数据文件,而是追加上新的版本来实现。 这使得CouchDB能够实现对同一条数据保存多个版本。也使得CouchDB的数据文件永远不会被改花掉。因为它永远在做append操作,即使出现问 题,只要去掉尾巴上一某一段数据就能回到之前某个时间的数据快照。
然而,这些好的特性必然需要付出代价,这代价就是数据大小会只增不减的膨胀。所以,数据压缩工作是迟早都得做的事。但是CouchDB并没有提供数据自动压缩的功能。这让人很郁闷。
不支持局部更新
局部更新的意思就是,不更新整条数据,只更新其它某个属性或字段。这个看似天经地义的功能,在CouchDB里却没有。在CouchDB中,所有的update操作都需要对整条数据进行更新。
缺乏内存的扩展性支持
CouchDB的同步机制是很牛X的,这几乎是它的杀手级功能。你可以随意在集群中添加删除节点, 可以随意指定Master和Slave的角色, 数据都会很好的同步到所有节点上。能达到这样的效果,是由CouchDB本身的机制决定的。然而,我们并不能做跨节点的读写操作。
在这方面,CouchDB-lounge算是一个尝试,但是它把整个架构复杂化了,我感觉不太舒服。
分页实现起来会很奇怪
如果你要对CouchDB中的数据进行分页展示,这会比较麻烦,在《CouchDB权威指南》中有一个对分页的实现,但是这个实现给人感觉非常别扭。如果你要在CouchDB中实现分页的话,最好还是用那个“获取更多”按钮的方式来做。
范围查询使用不太方便
如果你的key是这样的['123', '2010/07/21'],其中前一部分为查询的key,后一部分为时间,用于保证记录的顺序性。这时候你要查询所有’123′开头的记录时,就需要指 定起始条件为 ['123'],并且还必须指定一个终止条件为['123',{}],这样让人感觉用起得很不方便。
CommonJS无法用于mapreduce函数中
在CouchDB 0.11版本中,CommonJS已经可以用在view函数上,但是一直不能用在mapreduce函数中。这让我总是重复一些写过的代码。
缺乏document之间完备的包含关系
在CouchDB 0.11中,map函数可以通过{_id: doc.other_id}的方式包含另外一个document的引用,在查询时能够获取到对应这个文档的id,但是再进一步,如果我想再获取被包含的这 个文档的属性,那就没办法了。希望能够有办法通过当前集合的查询,获取并返回这个包含的文档的某些属性。
读操作总是会落到磁盘上
CouchDB没有实现自己的缓存。在写操作中,你可以通过delay commit的方式将写操作延迟同步,这样就避免了每次写操作就需要写磁盘。但除此之外,CouchDB没有做任何缓存。对于移动设备上的CouchDB 来说,写磁盘可能会好一些,毕竟移动设备上的flash设备比服务器上的传统磁盘性能要好一些。
没用的错误信息
CouchDB的错误信息经常让人摸不着头脑,根本就看不明白错误出在哪里。比如下面这一段,你能告诉我它说明了什么问题吗。
{<0.84.0>,supervisor_report,
[{supervisor,{local,couch_secondary_services}},
{errorContext,start_error},
{reason,
{'EXIT',
{undef,
[{couch_auth_cache,start_link,[]},
{supervisor,do_start_child,2},
{supervisor,start_children,3},
{supervisor,init_children,2},
{gen_server,init_it,6},
{proc_lib,init_p_do_apply,3}]}}},
{offender,
[{pid,undefined},
{name,auth_cache},
{mfa,{couch_auth_cache,start_link,[]}},
{restart_type,permanent},
{shutdown,brutal_kill},
{child_type,worker}]}]}}
好了,大概就这些吧。虽然上面说了这么多CouchDB让人不爽的地方,但是总的来说,我还是很喜欢CouchDB的,虽然有上面一些让人不爽的地 方,但是它还是能帮我处理很多问题。所以争论一个东西是否要用,并不是看它能不能满足所有需求,而是看它能不能满足你要的核心需求就行了。
来源:http://www.paperplanes.de
译文:http://blog.nosqlfan.com/html/3667.html
最新版本:3.2
CouchDB 3.2于2021年10月中旬发布,值得关注的更新包括:
couch_sever 模块现在是分片的。尽管遵循高并发进程的架构,以前的版本中使用的 couch_server 模块是一个单一的 Erlang 进程,在繁忙的节点上,可能会成为一个瓶颈。CouchDB 3.2.0 引入了一个 couch_server_N 模块,有效地消除了瓶颈。复制调度程序管理在任何时间运行哪些复制。这对于复制总量多于配置为并发运行的设置非常重要。以前,复制调度器会以轮流方式迭代所有的复制,并给它们同等的时间来运行。CouchDB 3.2.0 引入了一个公平分享的选项,允许你使用多个复制器数据库,每个都有不同的相对优先级。
支持 Erlang 23 和 24 版本,放弃对 19 版本的支持
支持 SpiderMonkey 78 和 86 版本
解决了 CVE-2021-2838295
支持通过 regex 指定密码要求
在几乎所有情况下,日志不再包括凭证
更加细化的 CSP 配置
通过 .devcontainer,更容易对 3.x 系列进行开发设置
使得自动压缩不那么激进,在繁忙的集群中节省了 CPU 和 I/O
包括用于高级诊断的 weatherreport 模块
包括一个专门的 Prometheus 端点,用于统计和度量
所有的 JS 测试都已经迁移到 Elixir
更多详情可查看此处。
项目主页:http://couchdb.apache.org/index.html
该文章最后由 阿炯 于 2023-12-05 14:52:53 更新,目前是第 2 版。