图形处理器-GPU
 图形处理器(英语:Graphics Processing Unit,缩写:GPU),又称显示核心(display core)、视觉处理器(video processor)、显示芯片(display chip)或图形芯片(graphics chip),是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上执行绘图运算工作的微处理器。以图形处理器为核心的主板扩展卡也称显示卡或“显卡”。
图形处理器(英语:Graphics Processing Unit,缩写:GPU),又称显示核心(display core)、视觉处理器(video processor)、显示芯片(display chip)或图形芯片(graphics chip),是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上执行绘图运算工作的微处理器。以图形处理器为核心的主板扩展卡也称显示卡或“显卡”。图形处理器是NVIDIA公司(NVIDIA)在1999年8月发表NVIDIA GeForce 256(GeForce 256)绘图处理芯片时首先提出的概念,在此之前,电脑中处理视频输出的显示芯片,通常很少被视为是一个独立的运算单元。而对手冶天科技(ATi)亦提出视觉处理器(Visual Processing Unit)概念。图形处理器使显卡减少对中央处理器(CPU)的依赖,并分担部分原本是由中央处理器所担当的工作,尤其是在进行三维绘图运算时,功效更加明显。图形处理器所采用的核心技术有硬件坐标转换与光源、立体环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等。
图形处理器可单独与专用电路板以及附属组件组成显卡,或单独一片芯片直接内嵌入到主板上,或者内置于主板的北桥芯片中,现在也有内置于CPU上组成SoC的。个人电脑领域中,在2007年,90%以上的新型台式机和笔记本电脑拥有嵌入式绘图芯片,但是在性能上往往低于不少独立显卡。但2009年以后,AMD和英特尔都各自大力发展内置于中央处理器内的高性能集成式图形处理核心,它们的性能在2012年时已经胜于那些低端独立显卡,这使得不少低端的独立显卡逐渐失去市场需求,两大个人电脑图形处理器研发巨头中,AMD以AMD APU产品线取代旗下大部分的低端独立显示核心产品线。而在手持设备领域上,随着一些如平板电脑等设备对图形处理能力的需求越来越高,不少厂商像是高通(Qualcomm)、PowerVR、ARM、NVIDIA等,也在这个领域“大显身手”。
GPU不同于传统的CPU,如Intel i5或i7处理器,其内核数量较少,专为通用计算而设计。相反,GPU是一种特殊类型的处理器,具有数百或数千个内核,经过优化,可并行运行大量计算。虽然GPU在游戏中以3D渲染而闻名,但它们对运行分析、深度学习和机器学习算法尤其有用。GPU允许某些计算比传统CPU上运行相同的计算速度快10倍至100倍。
历史
1970年代
ANTIC和CTIA芯片为Atari-8位电脑提供硬件控制的图形和文字混合模式,以及其他视频效果的支持。ANTIC芯片是一个特殊用途的处理器,用于映射文字和图形数据到视频输出。ANTIC芯片的设计师,Jay Miner随后为Amiga设计绘图芯片。
1980年代
Commodore Amiga是第一个于市场上包含映像显示功能在其视频硬件上的电脑,而IBM 8514图形系统是第一个植入2D显示功能的PC显卡。
Amiga是独一无二的,因为它是一个完整的图形加速器,拥有几乎所有的影像产生功能,包括线段绘画,区域填充,块图像传输,以及拥有自己一套指令集(虽然原始)的辅助绘图处理器。而在先前(和之后一段时间在大多数系统上),一般用途的中央处理器是要处理各个方面的绘图显示的。
1990年代
1990年代初期,Microsoft Windows的崛起引发人们对高性能、高清晰度二维位图运算(UNIX工作站和苹果公司的Macintosh原本是此领域的领导者)的兴趣。在个人电脑市场上,Windows的优势地位意味着台式机图形厂商可以集中精力发展单一的编程接口,图形设备接口。
1991年,S3 Graphics推出第一款单片机的2D图像加速器,名为S3 86C911(设计师借保时捷911的名字来命名,以表示它的高性能)。其后,86C911催生大量的仿效者:到1995年,所有主要的PC绘图芯片制造商都于他们的芯片内增加2D加速的支持。到这个时候,固定功能的Windows加速器的性能已超过昂贵的通用图形辅助处理器,令这些辅助处理器续渐消失于PC市场。

S3 Graphics ViRGE 显卡
在整个1990年代,2D图形继续加速发展。随着制造能力的改善,绘图芯片的集成水准也同样提高。加上应用程序接口(API)的出现有助执行多样工作,如供微软Windows 3.x使用的WinG图像程序库,和他们后来的DirectDraw接口,提供Windows 95和更高版本的2D游戏硬件加速运算。
在1990年代初期和中期,中央处理器辅助的即时三维图像越来越常见于电脑和电视游戏上,从而导致大众对由硬件加速的3D图像要求增加。早期于大众市场出现的3D图像硬件的例子有第五代视频游戏机,如PlayStation和任天堂64。在电脑范畴,显著的失败首先尝试低成本的3D绘图芯片为S3 ViRGE、ATI的3D Rage,和Matrox的Mystique。这些芯片主要是在上一代的2D加速器上加入三维功能,有些芯片为了便于制造和花费最低成本,甚至使用与前代兼容的针脚。起初,高性能3D图像只可经设有3D加速功能(和完全缺乏2D GUI加速功能)的独立绘图处理卡上运算,如3dfx的Voodoo。然而,由于制造技术再次获取进展,影像、2D GUI加速和3D功能都集成到一块芯片上。Rendition的Verite是第一个能做到这样的芯片组。
OpenGL是出现于90年代初的专业图像API,并成为在个人电脑领域上图像发展的主导力量,和硬件发展的动力。虽然在OpenGL的影响下,带起广泛的硬件支持,但在当时用软件实现的OpenGL仍然普遍。随着时间的推移,DirectX在90年代末开始受到Windows游戏开发商的欢迎。不同于OpenGL,微软坚持提供严格的一对一硬件支持。这种做法使到DirectX身为单一的图形API方案并不得人心,因为许多的图形处理器也提供自己独特的功能,而当时的OpenGL应用程序已经能满足它们,导致DirectX往往落后于OpenGL一代。
随着时间的推移,微软开始与硬件开发商有更紧密的合作,并开始针对DirectX的发布与图形硬件的支持。Direct3D 5.0是第一个增长迅速的API版本,而且在游戏市场中获得迅速普及,并直接与一些专有图形库竞争,而OpenGL仍保持重要的地位。Direct3D 7.0支持硬件加速坐标转换和光源(T&L)。此时,3D加速器由原本只是简单的栅格器发展到另一个重要的阶段,并加入3D渲染流水线。NVIDIA的GeForce 256(也称为NV10)是第一个在市场上有这种能力的显卡。硬件坐标转换和光源(两者已经是OpenGL拥有的功能)于90年代在硬件出现,为往后更为灵活和可编程的像素着色引擎和顶点着色引擎设置先例。
2000年到现在
随着OpenGL API和DirectX类似功能的出现,图形处理器新增可编程着色的能力。现在,每个像素可以经由独立的小程序处理,当中可以包含额外的图像纹理输入,而每个几何顶点同样可以在投影到屏幕上之前被独立的小程序处理。NVIDIA是首家能生产支持可编程着色芯片的公司,即GeForce 3(代号为NV20)。2002年10月,ATI发表了Radeon 9700(代号为R300)。它是世界上首个Direct3D 9.0加速器,而像素和顶点着色引擎可以执行循环和长时间的浮点运算,就如中央处理器般灵活,和达到更快的图像数组运算。像素着色通常被用于凸凹纹理映射,使对象透过增加纹理令它们看起来更明亮、阴暗、粗糙、或是偏圆及被挤压。
随着绘图处理器的处理能力增加,所以他们的电力需求也增加。高性能绘图处理器往往比目前的中央处理器消耗更多的电源。2017年3月10日后由于适用于个人研究使用的GPU发布,近年来也逐渐受到许多研究者及公司的关注并广泛用于深度学习。
绘图处理器公司
现时有许多公司生产绘图芯片。以台式机与笔记本电脑为例Intel、AMD和NVIDIA都是目前市场的领导者,分别拥有54.4%、24.8%和20.%的市场占有率。手机、平板电脑等移动设备方面,高通等公司有较高市占率。另外,硅统科技和Matrox等公司过去也曾生产图像芯片;英特尔也在2021年推出全新高性能显卡品牌 Intel Arc。
类型
独立显卡
独立显卡(Discrete Graphics Processing Unit,dGPU,简称独显)透过PCI Express、AGP或PCI等扩展槽界面与主板连接。
所谓的“独立(专用)”即是指独立显卡(或称专用显卡)内的RAM只会被该卡专用,而不是指显卡是否可从主板上独立移除。基于体积和重量的限制,供笔记本电脑使用的独立绘图处理器通常会透过非标准或独特的接口作连接。然而,由于逻辑接口相同,这些端口仍会被视为PCI Express或AGP,即使它们在物理上是不可与其他显卡互换的。一些特别的技术如NVIDIA的SLI、NVLink和AMD-ATI的CrossFire允许多个图形处理器共同处理影像信息,可令电脑的图像处理能力增加。
优点
相对集成显卡,独立显卡一般拥有更强劲的性能;
消耗的系统资源更少(目前的独立显卡都有独立的显示存储器);
拥有例如CUDA一类的在部分领域(例如影视后期等)可以起到辅助工作作用的处理单元。
缺点
购置计算机需要更多金钱;
消耗的功率更多,使电脑功率增加,体积更大;
部分低端独立显卡性能可能不如核心显卡。
集成绘图处理器
Intel GMA X3000 集成绘图芯片(被散热片覆盖)

集成绘图处理器(Integrated Graphics Processing Unit,iGPU)(或称内置显示核心)是集成在主板或CPU上的绘图处理器,运作时会借用部分的系统存储器。2007年装设集成显卡的个人电脑约占总出货量的90%[8],相比起使用独立显卡的方案,这种方案可能较为便宜,但性能也相对较低。从前,集成绘图处理器往往会被认为是不适合于执行3D游戏或精密的图形运算。然而,如Intel GMA X3000(Intel G965 芯片组)、AMD的Radeon HD 4290(AMD 890GX 芯片组)和NVIDIA的GeForce 8200(NVIDIA nForce 730a 芯片组)已有能力处理对系统需求不是太高的3D图像。当时较旧的集成绘图芯片组缺乏如硬件坐标转换与光源等功能,只有较新型号才会包含。
从2009年开始,集成GPU已经从主板移至CPU了,如Intel从Westmere微架构开始将Intel HD Graphics GPU集成到CPU至今,Intel将之称为处理器显示芯片。Intel Core极致版并没有集成绘图芯片。将GPU集成至处理器的好处是可以减低电脑功耗,提升性能。随着内显技术的成熟,目前的内显已经足够应付基本3D的需求,不过仍然依赖主板本身的RAM。AMD也推出了集成GPU的AMD APU、AMD Athlon和AMD Ryzen with Radeon Graphics。
独立供电
中、高端显卡有一、两个辅助电源插座,说明它功率很大,所以这两个辅助电源插座,必须插电源,不然显卡是不会工作的,显卡的外接电源接口是双6P的就一定全接上。
电脑主板上的PCI-E接口插槽,最大可以给显卡提供75W功率,在显卡需要的功率大于75W时,就会在独立显卡上加辅助电源插座,一个6PIN辅助电源插座,可以给显卡提供75W的功率,一个8PIN显卡辅助电源插座,可以提供电源功率在90W。
以七彩虹GTX1060显卡为例,1060显卡功耗为125W,所以是双6针的电源接口的,因为显卡需要独立供电,这显卡不但要通过PCI-E的主板插槽供电外,还得依靠显卡的电源接口来给显卡提供独立供电,所以说,这两个电源接口要完全接上,显卡才能正常供电,才可以正常运行;
另:显卡的供电方式有几种情况,A,节能版不用外接电源线;B,有一个6针的;C,有双6针的,D,有6+8供电也就是一个6针和一个8针的。
用于人工智能学习
人工智能要用GPU的主要原因是因为GPU拥有强大的并行计算能力,适合处理大规模的矩阵运算和向量计算,而这些计算在人工智能算法中非常常见。
在传统的中央处理器(CPU)中,每个核心通常只能处理一个任务,因此在处理大量数据时速度会相对较慢。而GPU拥有大量的计算单元(CUDA核心),可以同时执行许多相似的计算任务,因此能够在短时间内处理大量的数据。这对于机器学习和深度学习等人工智能任务来说非常重要,因为它们通常涉及大量的矩阵运算和向量计算。另外,人工智能算法中经常使用到深度神经网络,这些网络拥有大量的参数需要进行训练。传统的CPU在处理这些大规模神经网络时效率较低,而GPU能够通过并行计算加速神经网络的训练过程,从而大大缩短了训练时间。
也有像FuryGPU这种由爱好者从零开始构建的开源GPU硬件
迪伦-巴里(Dylan Barrie)想找出答案,并花了四年时间进行尝试。他的成果是一块完整的 GPU,理论上可以在 Windows 上运行旧版游戏软件。他是一名游戏开发人员和硬件爱好者。在过去 14 年的游戏行业职业生涯中,Barrie 主要专注于图形渲染的软件方面。不过,四年前他开始利用业余时间开发定制的全栈 GPU。

巴里说,从头开始创建图形卡的过程简直是地狱般的煎熬,但经过四年的不懈努力,终于可以与大家分享他的心血,现在附加卡的设计工作已基本完成。FuryGPU是基于 Xilinx Zynq UltraScale+ FPGA 设计的"真正的硬件 GPU"。该卡使用定制的印刷电路板,通过一个 PCIe 插槽与主机连接。
FuryGPU 可支持相当于 20 世纪 90 年代中期"高端"显卡的硬件功能,并为现代 Windows 版本提供完整的软件和驱动程序栈。该图形处理器可以以实时、可玩的帧速率渲染那个年代的游戏。巴利公司最终将通过开源许可发布硬件原理图、软件和驱动程序。
这位硬件自制者说,他决定从头开始制造图形处理器,因为他不知道 GPU 如何工作的"实际细节"。由于对软件方面的 3D 渲染过程"极为熟悉",巴里意识到创建 GPU 可能是一个虽然艰巨但可行的个人项目。
他花了"无数个小时"学习 FPGA 芯片如何工作,以及如何通过硬件描述、验证和实现语言SystemVerilog 来构建芯片设计。巴里说,设计 PCIe 图形卡的原理图是一项"艰巨的工作"。编写 Windows 驱动程序是该项目最痛苦的任务,这也许不足为奇。
开发人员编写了与 GPU 通信的自定义图形 API,并创建了管理显示和音频信号的 Windows 内核驱动程序。FuryGPU 可以以每秒 60 帧的"稳定"速度渲染《雷神之锤》(1996 年发布的初代),这对 90 年代的游戏玩家来说是一种真正的享受。
Barrie 计划在他的 FuryGPU 博客上撰写更多关于 GPU 制作冒险的文章,从显卡的纹理单元开始。他还希望优化他的定制《雷神之锤》构建版本,使其运行速度更快。
GPU激荡30年,性能暴增1539000倍
来源:内容由半导体行业观察(ID:icbank)编译自pc.watch,感谢所有参与者。
这些年,GPU已经成为全球热点。但GPU从哪里来?对此,当然存在争议,也并非不可能追溯到NEC的“μPD7220”、富士通的ARTC(HD63484)、TI的“TMS34010”、Intel的“82786”等,但我给出的答案是一个“配备独立 GPU 的显卡”。
然而,即使我只谈论IBM-PC及其兼容机,谈论IBM-PC的MDA和CGA也太长了。所以,最后我认为使用 DirectX 是可以的,即使是在 DirectX 7 之前。这就是发生的事情。嗯,既然叫GPU,我感觉这是一个门槛。因此想首先谈谈图形仅限于 2D 的时代。
PC市场启动的时代(1982-1989)
最初,具有显示功能的显卡(MDA、CGA、EGA、VGA、XGA、ATI的Small Wonder、Mach 8)没有配备任何加速功能)。
此时,争论的焦点仍然是“可以显示什么屏幕尺寸”和“可以同时显示多少种颜色”,而不是性能。
2D绘图性能争夺战开始的时代(1989~)
一旦游戏开始在 DOS 上运行,自然就会有竞争来让它们运行得尽可能快。这里脱颖而出的是 Tseng Labs 的“ET4000”,它在 BitBlt 上速度极快。当时大多数游戏都是以BitBlt格式绘制到VRAM上,因此ET4000价格便宜且速度快,因此销量非常好,其他厂商纷纷效仿。
这种追逐者的一个典型例子是 S3,即 1990 年发布的“86C911”,它在 DOS 上运行缓慢(以及后来发布的 Windows 3),但由于游戏速度异常快而受到欢迎。顺便说一句,DOS 很慢,因为 DOS/V 机械上很慢,但英文版本并没有那么慢。
后来,以前担任摄影师、最近成为生成式 AI 程序员的Kazuhisa Nishikawa发布了一个名为“DISPS3”的驱动程序,该驱动程序在 S3 芯片上高速运行,我记得这个问题得到了很大程度的缓解。是。在此之后,WDC、ATI等BitBlt都发布了高速图形芯片,几乎每周都有新产品上市。
然后,在1996年,Matrox推出了Millenium,再次改变了市场原则。BitBlt 并不是真的很快(后来发现了一个让它看起来很快的技巧,并受到了轻微的批评,但仅此而已),但 Windows 环境变得令人难以置信的快。

Windows 屏幕(现在称为桌面)实际上使用了大量的“线条绘制”。对于基于 BitBlt 的显卡,这会无休止地一次填充一个像素,因此它的速度是有限的(CPU 和图形芯片都加载),但 Millennium 已经先进了“直线绘制”、“圆弧绘制”、“区域填充”等2D绘图功能,所以在绘制直线时,CPU只要发出命令,然后图形芯片就会自动从起点到终点填充像素处理速度非常快。
这被证明是一种性能差异,特别是在拖动和摇动窗口时的反应速度方面,这导致了向 Millennium 的转变,尤其是在 Windows 用户中。
竞争对手是Weitek的P9000(1992年发布),但P9000本身是通用2D图形加速芯片,所以它具有VGA兼容性,很难使用。卡制造商试图通过在同一张卡上放置名为“OAK 087X”或 Wektek 的“W5186”的引导芯片来解决此问题,但这些芯片速度慢得不合理,尽管其在 DOS 环境中的性能是灾难性的),也是一种受欢迎的产品。
无硬件T&L的3D时代(1996-1999)
1996年,3Dfx发布了第一款产品Voodoo。配备此功能的显卡很快就流行起来。3D 对于当时的 PC 来说是一个相当新的概念。

3D 在工作站上流行已经有一段时间了(Silicon Graphics 在 1985 年发布了“Iris 2400”),但在此之前,众所周知 3D 仅适用于 PC。不过,微软在 1996 年随 DirectX 3 提供了第一个 3D 绘图 API Direct 3D,1996 年 3Dfx 提供了 Voodoo 和专用 API Glide。起初,Direct 3D 并不是很流行(嗯,在当时的水平上,这是可以理解的),很多游戏最终都跳上了 Glide。

随后,3Dfx发布了Vodoo 2。它变得非常流行,因为它可以通过使用 SLI(扫描线交错)操作两张 Voodoo 2 卡来显着提高性能。然而,3Dfx(最近将公司名称更改为 3dfx)在随后的Voodoo 3中遭遇了战略变化,导致该公司被其 OEM 合作伙伴彻底拒绝,并且由于Voodoo 3、4、5的延迟推出,其市场份额迅速下降。

另一方面,DirectX 3 在很多方面都有所欠缺,但随着 1997 年发布的 DirectX 5 和 1998 年发布的 DirectX 6,3D 功能得到了显着增强,许多供应商现在都在使用与 DirectX 兼容的硬件和软件版本。
除了新兴的 NVIDIA 和历史悠久的 ATI 之外,还有多家厂商进入该市场,包括 Imagination Technology、Rendition 和 Number Nine。英特尔也将在此时与C&T和Real3D合作推出“Intel 740”。当然,S3和Matrox也推出了产品,低价产品市场占有一定份额的Cirrus Logic也推出了产品。

然而,支持Direct 3D似乎比预想的更困难,大多数制造商都无法在这里展示足够的3D性能。唯一幸存下来并进入下一代的公司是 ATI、NVIDIA、S3 和 Matrox。我认为 Imagination 取得了不错的进展,但 Kryo 3 在改变业务并转向为移动设备提供 GPU IP 后却成为了一个幻影,有点遗憾。
更多关于3dfx Voodoo显卡
在IT历史的长河中,3dfx Voodoo显卡犹如一颗璀璨的星辰,闪耀着独特的光芒。1994年,3dfx成立。1995年11月,第一张针对3D游戏进行加速的图形加速卡Voodoo Graphics 3D亮相以来,开启了3D图形技术的新纪元。这款芯片以其先进的500nm工艺和50 MHz的运行速度,结合4MB的EDO显存,为当时的计算机带来了前所未有的3D视觉体验。1996年量产卡一经发售,便点燃了整个市场。

在那个游戏刚刚兴起的年代,Voodoo显卡成为了无数游戏玩家心中的神器。《Doom》和《Quake》等经典游戏在Voodoo显卡的支持下,呈现出在当时令人惊艳的画面效果,让玩家仿佛置身于一个真实的3D世界中。Voodoo显卡不仅推动了游戏行业的发展,更引领了整个3D图形技术的革新。

同等帧率下的Quake游戏,Voodoo能实现翻倍的分辨率以及几何级的发色数;一时间,几乎每个游戏玩家和硬件DIY爱好者,都以拥有一块Voodoo加速卡为荣。
对于硬件发烧友来说,3dfx Voodoo显卡不仅仅是一款显卡那么简单。它承载着他们对IT历史的热爱和追求,是他们心中永恒的经典。1996年,国内一块Voodoo卡价格高达2000多元,到了1998年,仍然要500元左右,并依然是大家的装机热门卡。
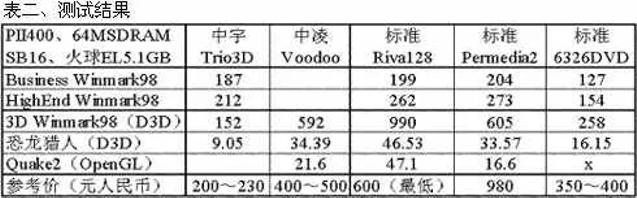
1998年,《电脑报》上对Voodoo卡装机方案的对比测评
后来者居上与游戏卡之王的衰落
然而,好景不长。随着Matrox、Nvidia和ATI等竞争对手的崛起,3dfx的市场地位逐渐受到威胁。特别是一年以后NVIDIA推出的Riva128显卡,凭借单卡多功能性以及游戏性能超过Voodoo 25%,对3dfx形成了巨大的压力。尽管随后Voodoo推出到了Voodoo5,但在NVIDIA发明GeForce256后的GPU时代,实在无力回天。
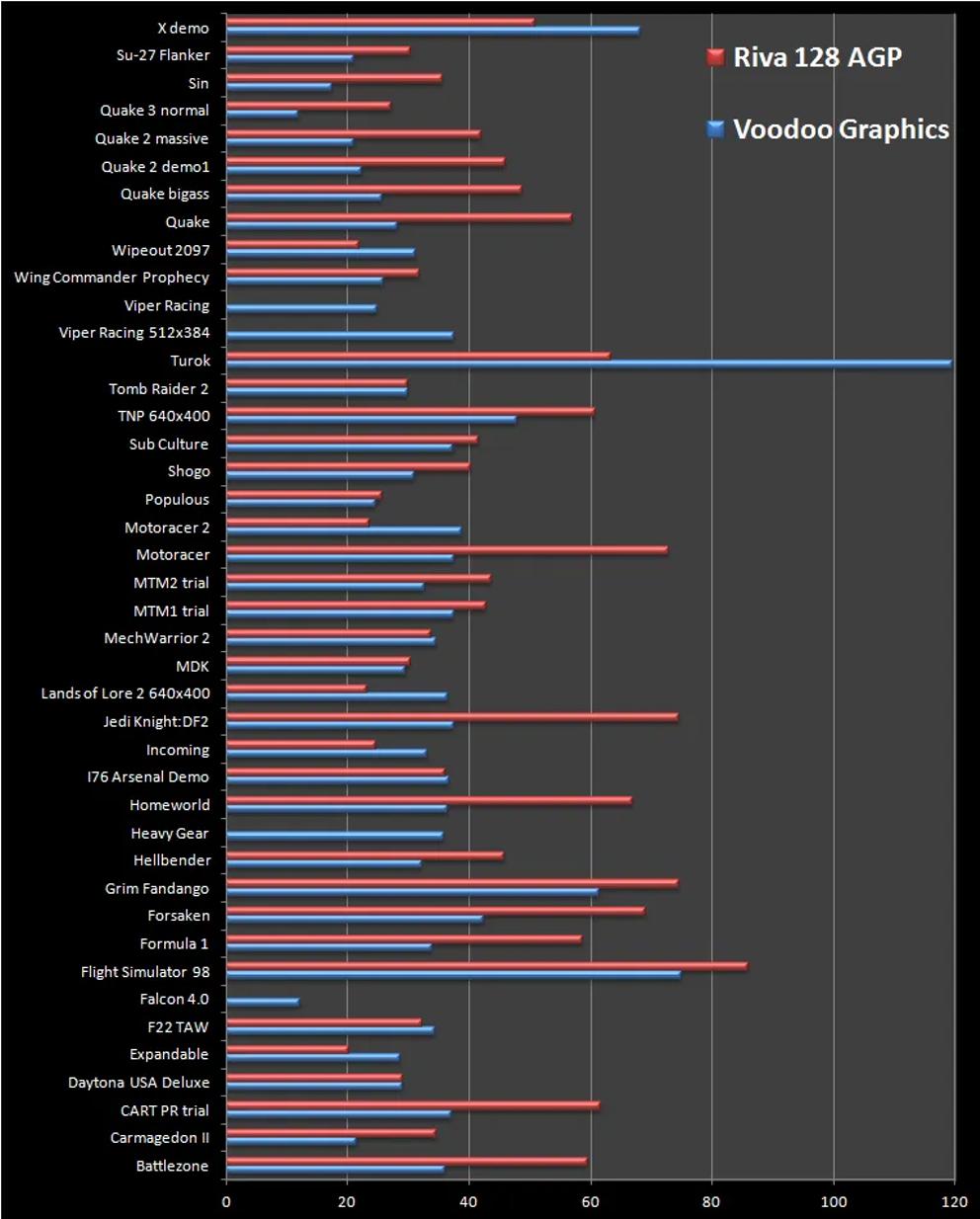
此外,微软Direct3D API的迅速崛起也对3dfx造成了致命打击。Direct3D API提供了更加高效、灵活的3D图形编程接口,使得开发者能够更加轻松地开发出高性能的3D游戏和应用程序。而3dfx在API支持方面相对滞后,逐渐失去了市场竞争力。最终在一系列收购失败、专利诉讼和产品发布延迟等问题的冲击下,3dfx走向了衰落。2000年12月,在推出了Voodoo5显卡后不久,3dfx正式宣布倒闭,并将资产转让给NVIDIA,以便更好解决遗留用户的服务问题。
Voodoo的玩家依然保持情怀
然3dfx公司已经不存在,但其技术和精神却如同不灭的火种,继续激励着PC技术爱好者和游戏玩家。许多3dfx的专利被Nvidia获得,这些专利不仅为Nvidia带来了技术上的优势,也使得3dfx的技术得以传承和发展。同时,许多3dfx的工程师也加入了Nvidia等公司,继续在3D图形领域发挥着自己的才华和智慧。另外在爱好者和创客社区中,3dfx的遗产也得以延续。2023年,一块原版Voodoo卡拍卖出1.5万美元价格。而爱好者也发起了VoodooX项目,通过改造和复现3dfx的经典显卡,让更多的人了解和体验3dfx技术的魅力。

被爱好者装上DVI接口和64MB显存的自制“VoodoX4900”。
硬件传输的3D时代(2000-2001)
1999 年 7 月,微软发布 DirectX 7。这里新安装的是硬件T&L(Transform & Lighting)功能。简而言之,顶点计算和光照计算都是在GPU端进行的。
NVIDIA 是第一个实现这一点的公司,于 1999 年发布了 GeForce 256,它是 RIVA TNT 和硬件 T&L 引擎的组合。该产品相比RIVA TNT提升了绘图性能,并且还配备了硬件T&L,使其成为非常受欢迎的产品。

虽然ATI的开发有点晚,但还是推出了基于Tseng Labs的ET6300的“RADEON”。从此,与NVIDIA合作的漫长的性能大战历史开始了。

S3实际上未能实现硬件T&L,被迫几乎退出GPU业务,导致其图形业务被VIA Technologies收购。Matrox通过发布Parhelia 512来挽回面子,但其发布被推迟到了2002年,而与此同时,NVIDIA和ATI发布了更先进的产品,无论是在功能上还是在性能上都无法再与之竞争。质量(和价格)。
毕竟从此时开始,市面上的显卡大部分都是由NVIDIA和ATI主导,并且这种情况一直延续到了今天。尽管S3在威盛旗下做了一些出色的工作,但该公司最终将业务重点转向芯片组集成GPU,并于2011年出售给威盛集团子公司HTC时结束了其业务。
可编程着色器的 DirectX 8 时代 (2001-2003)
随着 2001 年 DirectX 8 的出现,GPU 进入了一个新时代。这是一种称为“着色器”的新处理器的引入。
在DirectX 7之前,绘图引擎和T&L函数都是固定函数,游戏程序员无法修改它们。DirectX 8改为着色器,允许程序员自己改变处理内容。

ATI的“RADEON 8000”系列和NVIDIA的“GeForce3”和“GeForce4”系列对应DirectX 8。GeForce 4系列有高性能Ti和低价MX两种,我记得MX系列由于价格低廉而被广泛使用,但MX系列不兼容DirectX 8。

在 DirectX 8 中,着色器分为两种类型:执行顶点计算的顶点着色器和执行绘图的像素着色器,根据应用程序的不同,可能存在顶点着色器性能不足或性能下降的情况。像素着色器不足会有这种情况(尽管实际上,像素着色器更有可能出现性能不佳的情况)。
DirectX 9时代(2003-2007)Shader Model进化到2.0和3.0
微软在2002年宣布了一个新模型“Shader Model 2.0”。它现在已经能够运行更长的着色器程序,并通过更多类型的指令进行了增强。
NVIDIA的“GeForce FX”系列兼容DirectX 9,第一款产品“GeForce FX 5800”(根据一种理论,是由被NVIDIA收购的前3dfx设计团队设计的,但真相未知) ,而且风扇声音太大,以至于NVIDIA自嘲地形容它是吹风机(实际上它产生的热量太大,不得不配备这么吵的风扇),所以自然不受欢迎了。

在此之前发布的“RADEON 9700”系列更安静,性能也相同。但是NVIDIA在六个月后开始实施更合理的散热设计(大约从这个时候,ATI和NVIDIA都开始提倡风扇的安静性。原因之所以会发生这种情况,可能是因为 GeForce FX 5800 太令人痛苦了。

2004年,GeForce FX的内部结构被完全抛弃,取而代之的是类似ATI的结构,并且它还兼容Shader Model 3.0,它融合了32位算术精度、条件循环/分支、几何实例化、动态流控制等推出“GeForce 6”系列。
此后,两家公司将继续致力于提高速度和性能,同时缩小流程,但同时会对界面进行更改。简而言之,它是从AGP到PCI Express的更新。不过,随着当时的150-130nm工艺,PCI Express接口已经变得相当大。
NVIDIA现在已经发布了一款在基于AGP的芯片上带有AGP/PCI Express桥接器的产品,虽然ATI批评它“不是原生的” ,但ATI也在一些SKU的基于AGP的芯片上添加了AGP/PCI Express桥接器人们发现有些产品将 Express Bridge 集成在一个软件包中,因此它是两者兼而有之。最终,通过将小型化推进到 110 纳米左右的工艺,两家公司将能够原生支持 PCI Express。

顺便说一句,在此期间,威盛旗下的S3也在改进其核心,或者更确切地说是创建一个新的核心。它最初于 2002 年开发,代号 AlphaChrome,但由于兼容 DirectX 8/AGP 而没有商业化。2003年发布的“ DeltaChrome S8 ”与基于AlphaChrome的DirectX 9兼容,而2005年发布的“ DeltaChrome S18 ”则与PCI Express兼容。

DirectX 9代方面,从SiS图形部门分离出来的XGI于2003年发布了Volari,这是SiS一直在开发的Xaber核心。另外,XGI在成立时收购了Trident Microsystems,并将该公司开发的XP8核心添加到其产品阵容中,但该XP系列具有“着色器”配置,因此它具有相同的性能,而电路尺寸却只有一半。尽管该公司声称能够提供高性能,但实际投入运营时,效果只有一半,到2006年底,该公司几乎消失了,无法占领任何市场份额。

2006年,NVIDIA和ATI都将其产品过渡到90-80nm工艺。此外,着色器的数量将会增加,并且将会发布更高工作频率的产品。还有,虽然与GPU架构没有直接关系,但ATI在2006年7月被AMD收购,从此成为AMD的GPU。
这次收购在收购后几乎没有什么协同效应,但 ATI 无疑支持了该公司,从 2011 年 AMD 推出带有 Bulldozer 核心的 AMD FX 失去了 CPU 市场,到 2017 年凭借 Zen 核心复活了。事后看来,这次收购的用处与原来的 GPU 不同。
DirectX 第 10 代(2007-2009),成为统一着色器
如前所述,很难唯一确定应组合的顶点着色器和像素着色器的比例。2007 年的 DirectX 10 引入了统一着色器结构,将两者统一起来。程序员现在可以根据自己的喜好将可用的着色器分配给顶点计算和视频处理。
然而,关于 DirectX 10,NVIDIA 和 ATI 的意见并不一致。NVIDIA在2006年的GeForce 8000系列上就支持了DirectX 10,但推迟了对DirectX 10.1的支持,直到2009年的“GeForce 200M”系列,并且只有部分型号支持(GeForce GTS/GTX 200系列),最后仍然兼容DirectX 10 )。

另一方面,ATI在2007年使DirectX 10与“Radeon HD 2000”系列兼容,并在2008年使DirectX 10.1与次年发布的“Radeon HD 3000”系列兼容。本文详细介绍了与此相关的情况,但由于缺乏同步,应用程序在支持 DirectX 10(特别是 10.1)方面确实没有取得太大进展。

然而,DirectX 10 的主要变化是对 WDDM(Windows 显示驱动程序模型)的支持和几何着色器的实现,这增加了编程自由度,但并没有提高性能。另外,由于兼容操作系统是臭名昭著的Windows Vista或更高版本,用户的迁移速度很慢,因此DirectX 9兼容应用程序继续占据主导地位,因此这可能不是问题。制造工艺已向小型化发展至65nm/55nm,趋势是进一步提高性能。
顺便说一下,这代DirectX 10代也是显卡TDP超过150W的产品出现的时代。对于 PCI Express,最大供电最初设置为 150W,卡边缘为 75W,辅助电源连接器(6 针)为 75W,但这将超过此值。为此,PCI-SIG决定在2008年增加“PCI Express 225W/300W高功率CEM”。
另外,NVIDIA将结合 DirectX 10 推出CUDA 。最初,在GeForce FX一代中,CineFX引入了使用GPU进行视频处理的机制,但由于GeForce FX本身的故障而变得模糊,因此引入了类似GPGPU的扩展“Cg”,该扩展可以用于更多用途。一般方式。
AMD突破DirectX第11代(2009-2014)
微软将于 2009 年发布 DirectX 11。这个 DirectX 11 可以说是传统 3D 管线结构的巅峰版本,从某种意义上说,它也是当前版本,仍然有相当多的应用程序与 DirectX 11 兼容(好吧,如果你这么说吧,DirectX 9 也是如此)。

针对此,AMD发布了Radeon HD 5000系列,NVIDIA发布了GeForce 400系列,但是这款GeForce 400的首款产品GeForce GTX 480却因为过于激进而无法正常生产而引起了很大争议。我决定这么做。故事也讲到这里,但是当电路规模变大,为了节省双过孔的面积,将尺寸缩小到极限时,过孔失效的情况频发,生产出大量无法发挥功能的芯片。

AMD的Radeon HD 5870,同样采用台积电的40nm,没有这样的问题,所以这纯粹是NVIDIA的设计问题,重新设计的GeForce GTX 580解决了这个问题,但结果是产品的推出被不必要地推迟了大约半年。
然而到了这一代的后半段,人们越来越清楚地看到,即使GPU性能提升,DirectX渲染管线的结构也成为瓶颈,性能无法提升。
作为对策,AMD 提供了自己的 API,称为“Mantle”。它自 2013 年推出以来,已有多款游戏开始使用它。Kronos Group 还将在 2016 年发布与 Mantle 类似(但不兼容)的 Vulkan API,但在此之前,微软将在 2014 年发布与 Mantle 类似但开销较小的 DirectX 12。Mantle 最终被 DirectX 12 取代。

这个DirectX 11时代持续了大约5年,NVIDIA有3代:“GeForce 400/500”→“GeForce 600”→“GeForce 700”,而AMD有“Radeon HD 5000”→“Radeon HD 6000”→虽然有四代推出的产品中,从“Radeon HD 7000”到“Radeon RX 200”,工艺仅从40nm转向28nm,而架构方面,NVIDIA从Fermi到Kepler再到Maxwell,AMD也只有3代:TeraScale2 → TeraScale3 → GCN。

此外,为了扩大产品线,他们还混合了上一代产品的重新编号,值得注意的是,无论是高端产品还是中端产品,两家公司都没有显着提高中端产品的性能。这可能就是为什么在后面出现的图表中,2014年左右变化非常大的原因(尤其是下半部分与2010年左右差别不大)。
DirectX 第 12 代仍在使用(2014-2020)
随着DirectX 12的推出,两家公司都会推出与其兼容的新产品(NVIDIA的“GeForce 900”系列,AMD的“Radeon RX 200”系列),但虽然GPU架构发生了变化,但工艺仍然是28nm一代。最初,性能没有太大差异。

然而,2016 年,工艺转向 14-16nm 一代。这显着提高了性能。然而,当然,竞争对手也以同样的方式迁移了流程,因此在这里很难看到性能差异。至此,AMD和NVIDIA的策略明显分开。
NVIDIA以高端性能为目标,将Die做得尽可能大,因此针对消费市场推出了Die超过600平方毫米的产品。通过将GV100重新用于服务器而配备了815平方毫米的怪物骰子的“TITAN V”可能是一个例外。

另一方面,AMD采取了将尺寸控制在500平方毫米以下的策略,不包括“Radeon R9 Fury/Nano”,它可以称为配备HBM的实验产品,其尺寸巨大,达到596平方毫米。当然,这对于高端市场来说有些不尽如人意,但高端市场虽然可以获得较高的产品价格,但却很难批量生产。如果是这样,策略就是以低于该分数的成绩为目标。由于这是挖矿和一代AI的热潮,如果不是高端显卡首先热销本来是正确的,但结果却成为AMD GPU销量下滑的一个因素毫无疑问,确实如此。
顺便说一句,AMD从2019年开始将制造工艺转移到7nm一代,但NVIDIA已经转移到2020年,并且最新工艺仅限于GeForce RTX系列,因此GeForce GTX系列将使用12nm工艺直到最后。
迈向光线追踪时代(2018~)
最后一个大趋势是光线追踪的加入。这项技术于 2018 年 10 月宣布为 DXR(DirectX Ray Tracing),由微软和 NVIDIA 联合开发。另一方面,AMD则推迟到2020年推出Radeon RX 6000系列。这种延迟仍然存在,AMD 在 DXR 性能方面仍然远远落后于 NVIDIA。

虽然与 DXR 没有直接关系,但 NVIDIA 除了 DXR 相关的东西外,还配备了 GPU 内部用于 AI 处理的 Tensor 核心,并且在 2018 年,NVIDIA 推出了一种使用“DLSS”执行基于 AI 的超分辨率的方法(深度学习超级采样)”。

AMD 还将在 2021 年将其命名为“FSR(FidelityFX 超级分辨率)”,尽管会晚一些。

此外,2018 年加入英特尔的 Raja Koduri 开发的基于 Intel Arc 的 GPU 现在可以使用名为“XeSS(Xe Super Sampling)”的超分辨率技术,该技术也使用了 AI。然而这三者却有着完全不同的实施政策:
DLSS:基于人工智能。仅适用于 NVIDIA Tensor Core
FSR:基于算法。该代码以开源格式发布,并且与任何设备兼容,因此可以与 NVIDIA 或 Intel GPU 一起使用。Arm 最近成为热门话题,因为它基于此 FSR 代码向其 GPU提供了名为 ASR(精度超分辨率)的超级采样功能。
XeSS:虽然基于AI且代码未公开,但它是使用DirectX 12支持的Shader Model 6.4功能实现的,因此它不仅适用于Intel Arc,也适用于Radeon RX 6000及更高版本。
一种有些令人困惑的情况仍然存在。
回到芯片,我们终于进入了5nm一代。这里引人注目的是AMD,它是第一个使用chiplet配置的消费级GPU(NVIDIA继续采用单片配置)。
那么,30 年来 GPU 的速度到底有多快呢?
因此,我简要总结了 PC 图形的趋势。我确信还有很多缺失的故事,但如果我把它们全部捡起来,它最终会成为一本针叶林小说,所以请耐心等待。因此,我尝试收集一些有关配备3D功能的图形芯片/GPU的统计数据。
首先,如何衡量GPU性能,游戏的帧率才是最终的应用性能,它包含了GPU以外的很多因素。首先,不可能用这个作为指标,因为没有任何游戏可以在早期的“3D Rage”和当前的“GeForce RTX 4090”上运行并测量帧速率。因此,我决定使用可以与单独GPU进行比较的元素来计算它。
图1是“像素填充率”的比较。这表明生成图像的速度有多快,是 GPU 的基本性能特征之一。我认为 NVIDIA 的像素填充率往往略高,但大致相同。使用 NVIDIA 趋势曲线的值,在过去 30 年中性能提高了约 2,100 倍。换句话说,这是每年约29%的增幅。
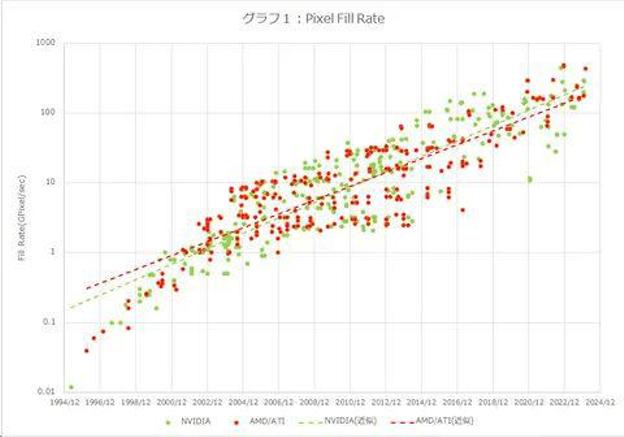
增长率出乎意料的低,可能是由于内存带宽的影响。所以图2是内存带宽的比较。这个数字甚至更低,NVIDIA 30 年来的增长率为 717 倍,而 AMD 仅为 240 倍。按年计算,NVIDIA 的年增长率仅为 24.5%,AMD 的年增长率仅为 20.1%,这被认为是阻碍他们发展的因素。因此,像素填充率和内存带宽增长之间的差距是通过缓存和架构(内存带宽压缩技术等)来补偿的。
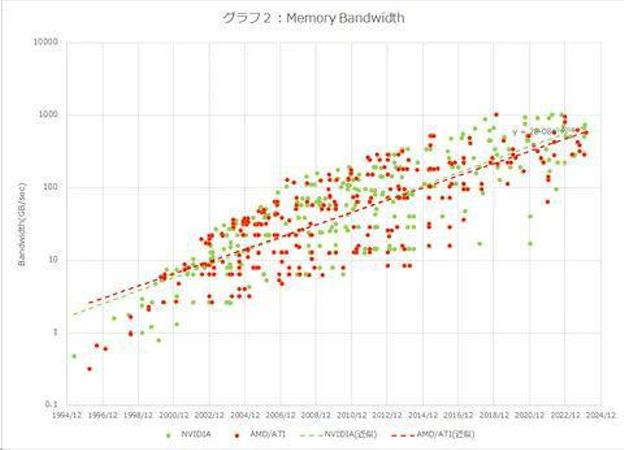
图3是“纹理填充率”的比较,它是纹理粘贴速度的指标。它不是 2D,但在 3D 中却很重要。NVIDIA 和 AMD 的近似值大致相同,在 30 年内大约增长了 6,400 倍。换句话说,它正以每年约34%的速度增长。之所以比Pixel Fill Rate略高,可能是因为很多情况下会在一个多边形上粘贴多个纹理。
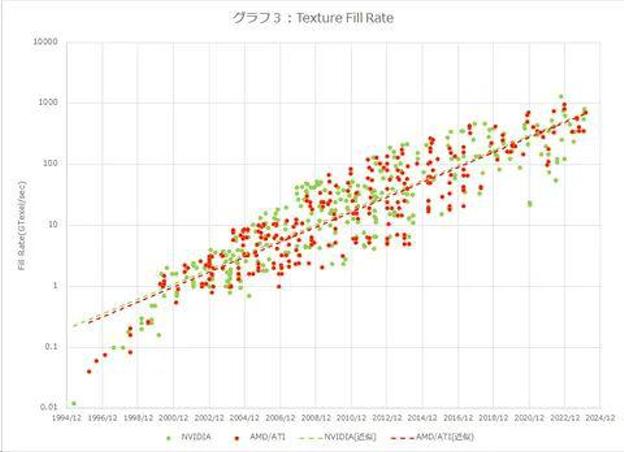
图4是FP32的计算性能比较。与 GPU 相比,它具有更多的 GPGPU 元素,但它是在忽略内存带宽限制并仅运行 GPU 的情况下可以获得多少性能的比较。这里,AMD的增长率高于NVIDIA,NVIDIA在30年间增长了514,000倍,AMD增长了1,539,000倍。年增长率分别为 55% 和 60.7%。
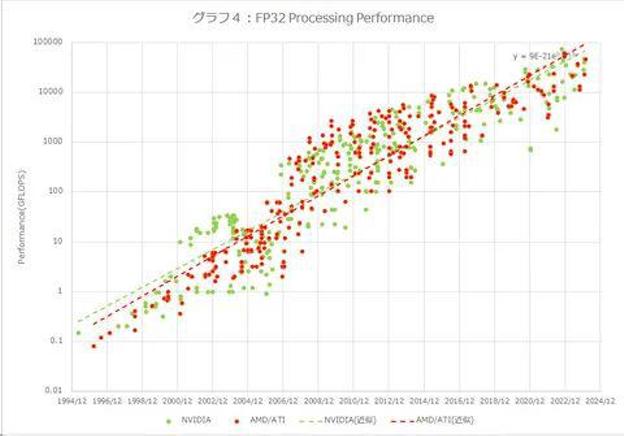
NVIDIA的增长之所以低一些,是因为它使用了相当数量的晶体管用于Tensor核心等。如果考虑到这个Tensor核心,我认为数字可能会增长得更快,但另一方面,它着色器的计算性能似乎很慢(由于 Tensor 核心消耗了晶体管)。我认为就 GPU 性能而言,图 4 可能是最接近实际情况的。
50年间CPU性能提升了7000万倍,即每年约44.5%,这意味着GPU性能提升速度超过了CPU。虽然与CPU相比,由于并行度高,性能更容易提升,但很难说未来性能提升的空间有多大,感觉事情要变得更艰难了。
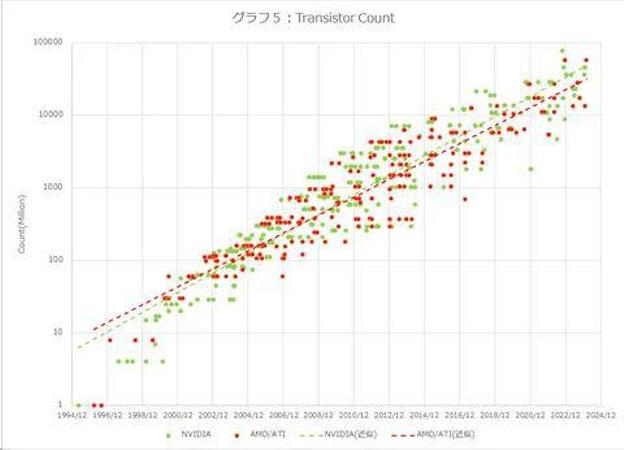
最后,虽然与性能没有直接关系,但图 5 显示了晶体管数量的比较。NVIDIA的增长也稍快一些,30年增长了19200倍,AMD约为6400倍。年增长率分别为38.9%和33.9%。
提高 GPU 性能的最大障碍是功耗和芯片尺寸。特别是,裸片尺寸具有严格的掩模版限制,虽然在结构上将着色器和其他部分制成chiplet相对容易,但将着色器部分分离成多个chiplet是困难的。如果类似 NUMA 的架构能够应用于 GPU,我们将能够克服这个问题。顺便说一句,这对于 GPGPU 来说是可以实现的,并且 Chiplet 已经投入实际使用,但是对于 GPU 来说却很难做到。