企业级SQL on Hadoop方案-Pivotal HDB
 过去五年里,许多企业已慢慢开始接受 Hadoop 生态系统,将它用作其大数据分析堆栈的核心组件。尽管 Hadoop 生态系统的 MapReduce 组件是一个强大的典范,但随着时间的推移,MapReduce 自身并不是连接存储在 Hadoop 生态系统中的数据的最简单途径,企业需要一种更简单的方式来连接要查询、分析、甚至要执行深度数据分析的数据,以便发掘存储在 Hadoop 中的所有数据的真正价值。SQL 在帮助各类用户发掘数据的商业价值领域具有很长历史。
过去五年里,许多企业已慢慢开始接受 Hadoop 生态系统,将它用作其大数据分析堆栈的核心组件。尽管 Hadoop 生态系统的 MapReduce 组件是一个强大的典范,但随着时间的推移,MapReduce 自身并不是连接存储在 Hadoop 生态系统中的数据的最简单途径,企业需要一种更简单的方式来连接要查询、分析、甚至要执行深度数据分析的数据,以便发掘存储在 Hadoop 中的所有数据的真正价值。SQL 在帮助各类用户发掘数据的商业价值领域具有很长历史。Hadoop 上的 SQL 支持一开始是 Apache Hive,一种类似于 SQL 的查询引擎,它将有限的 SQL 方言编译到 MapReduce 中。Hive 对 MapReduce 的完全依赖会导致查询的很大延迟,其主要适用场景是批处理模式。另外,尽管 Hive 对于 SQL 的支持是好的开端,但对 SQL 的有限支持意味着精通 SQL的用户忙于企业级使用案例时,将遇到严重的限制。它还暗示着庞大的基于标准SQL的工具生态系统无法利用Hive。值得庆幸的是,在为SQL on Hadoop提供更好的解决方案方面已取得长足进展。
Hadoop本地SQL 和Pivotal HDB是新一代高级分析和机器学习技术。它能将 Hadoop 转换为企业分析数据库,从而直接在Hadoop中简化管理、扩展数据访问分析范围、移动分析工作负载。Pivotal HDB是一款弹性SQL 查询引擎,它结合了优秀的MPP式分析性能、以ANSI标准稳定兼容SQL、并集成了MADlib的机器学习技术,可以大大提高临时查询和预测分析的速度。Pivotal HDB的研发团队有着十多年的Pivotal Greenplum Database™和PostgreSQL等开源项目的经验,因此产品非常注重用户体验。Pivotal HDB的所有操作都在本地进行,这样能简化集群资源的系统管理。
快速得出有效数据结论
直接在 Hadoop 中使用整个数据集能更精确地运行预测分析、更大规模地实时查询、更快地完成分析任务。
高效集成SQL BI工具
Pivotal HDB囊括了一系列数据分析和数据可视化工具,例如 SAS、Tableau 等。它能善用现有的 SQL 技能加强性能,在Hadoop中加快请求执行速度。
在数据库中集成高级分析和机器学习
Pivotal HDB直接在Hadoop数据中操作,运用高级统计功能和算法,快速且大规模地得出数据关系、模板、趋势。
对一流的SQL on Hadoop方案应有什么期待
下表显示了一流的SQL on Hadoop所需要的功能以及企业如何可以将这些功能转变为商业利润。从传统上意义上说,这些功能中的大部分在分析数据仓库都能找到。
功能 业务好处
丰富且合规的 SQL支持 功能强大的可移植 SQL 应用程序。能够利用基于 SQL 的数据分析和数据可视化工具的大型生态系统
符合 TPC-DS 规格 TPC-DS 帮助确保所有级别的 SQL 查询得到处理,从而广泛支持各种使用案例并避免企业级实施期间出现意外。
灵活高效的连接 以显著降低的拥有成本摆脱企业数据仓库工作负载
线性可扩展性 以显著降低的拥有成本摆脱企业数据仓库工作负载
一体化深度分析与机器学习功能 以 SQL 需要的统计学、数学和机器学习算法启用使用案例
数据联合能力 在实施端对端分析使用案例过程中,利用多种企业和外部数据资产降低数据重构成本
高可用性和容错功能 确保业务连续性并摆脱更多来自企业数据仓库的关键业务分析
原生 Hadoop 文件格式支持 减少的 ETL 和数据移动直接使分析解决方案的拥有成本更低
表 1:一流的SQL on Hadoop方案所带来的功能和业务好处
传统的SQL on Hadoop的实现方式
数据分析供应商和开源社区采取了各种方法实现SQL on Hadoop。有些供应商已投资从头构建分布式SQL on Hadoop 引擎。其他供应商则已投资优化 Apache Hive 来缩小 Hive 与传统 SQL 引擎之间的性能落差。开源社区使用 Apache Drill 来提供延迟时间更短的交互性查询功能。最新的开源产品是 SparkSQL,它支持使用 SQL 查询 Spark 中的结构化数据。

图 1:传统的SQL on Hadoop选项
Pivotal 的企业版SQL on Hadoop方案
Pivotal 的企业版SQL on Hadoop方案是基于10 多年来产品开发的成果价值,即投资研发 Greenplum Database——Pivotal 的旗舰分析数据仓库。Pivotal 正是利用这一代码基础和深度数据管理专业知识来构建了业内最好的SQL on Hadoop企业引擎。然后,我们使用业内唯一一款基于代价的查询优化框架来增强其性能,该框架专为 HDFS 量身打造。

图 2:将基于 MPP 的分析数据仓库用于企业版的SQL on Hadoop方案
该SQL on Hadoop的企业级产品称为 HDB,全称 Hadoop With Query(带查询 Hadoop)。HDB 使企业能够获益于经过锤炼的基于 MPP 的分析功能及其查询性能,同时利用 Hadoop 堆栈。HDB 可与其它传统的SQL on Hadoop引擎共存于一个分析堆栈,如图 1 所示。让我们考虑一流SQL on Hadoop企业版的各个方面,并将之与 HDB 相比较:
丰富且完全兼容的SQL标准 on Hadoop
HDB 是 100% 符合 ANSI SQL 规范并且支持 SQL ‘92, ‘99, 2003 OLAP 以及基于 Hadoop 的 PostgreSQL。它包含关联子查询、窗口函数、汇总与数据库、广泛的标量函数与聚合函数的功能。用户可通过 ODBC 和 JDBC 连接 HDB。对企业来说,好处是有一个庞大的商业智能、数据分析和数据可视化工具生态系统,由于该系统完全符合 SQL 支持规范,因此打开后立即可与 HDB 配合使用。另外,越过 HDB 编写的分析应用程序可以轻松移植到其它符合 SQL规范的数据引擎上,反之亦然。这可以防止供应商锁定企业并在控制业务风险的同时促进创新。
TPC-DS 合规规范
TPC-DS 针对具有各种操作要求和复杂性的查询定义了 99 个模板(例如,点对点、报告、迭代、OLAP、数据挖掘)。成熟的基于 Hadoop 的 PostgreSQL 系统需要支持和正确执行多数此类查询,以解决各种不同分析工作负载和使用案例中的问题。基准测试是通过 TPC-DS 中的 99 个模板生成的 111 个查询来执行的。依据符合两个要求受支持的查询个数,以下条形图显示了一些基于 SQL on Hadoop常见系统的合规等级:1. 每个系统可以优化的查询个数(如,返回查询计划)以及 2. 可以完成执行并返回查询结果的查询个数。
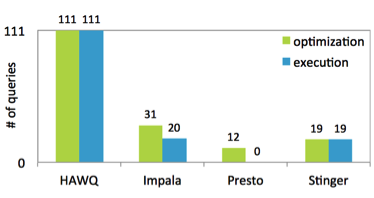
图 3:从 TPC-DS 套件返回的已完成查询个数。
HDB 的扩展性的SQL 支持能力是基于数据仓库的代码库,HDB 成功完成了全部 111 个查询。这些结果的详细信息公布在关于大数据模块化查询优化器架构的的 ACM Sigmod 数据管理国际会议的文件中。
有了SQL on Hadoop方案,可实现灵活高效的连接
HDB 吸收了最先进的基于代价的 SQL 查询优化器,在SQL on Hadoop领域是行业先锋。该查询优化器以针对大数据模块化查询优化器架构中的研究结果为基础而设计。
HDB 能够制定执行计划,可优化使用 Hadoop 集群的资源,而不计查询的复杂程度或数据的大小。还可以针对特定环境配置优化器内的成本函数,如:版本、硬件、CPU、IOPS 等。
HDB 已经过验证,能够快速为涉及超过 50个关联表的高要求查询找到理想查询计划,从而成为业内最佳的SQL on Hadoop数据发现与查询引擎。这就使企业能够使用 HDB 以显著降低的成本来降低用于大量数据分析的传统企业数据仓库工作负载要求。
利用线性可扩展性,加速 Hadoop 查询
HDB 为 PB 级SQL on Hadoop操作专门设计。数据直接存储在 HDFS 上,并且 SQL 查询优化器中已经为基于HDFS的文件系统性能特征进行过细致的优化。
SQL on Hadoop的主要设计目标是在 Hadoop 上执行 SQL 连接时最大程度地降低数据传输的开销。HDB 采用 Dynamic pipelining 来解决这一关键要求,使基于 HDFS 的数据适用于交互式查询。Dynamic pipelining 是一种并行数据流框架,结合了以下独特的技术:
适应性高速 UDP 互联技术,
操作运行时执行环境,是所有 SQL 查询的基础,并针对大数据工作负载进行了调整
运行时资源管理层,它确保查询的完整性,即使在重度负载集群里出现其它要求极高的查询
无缝数据分配机制,它将经常用于特定查询的部分数据集集中起来
大数据模块化查询优化器架构中突出的性能分析显示,对于基于 Hadoop 的分析与数据仓储工作负载,HDB 要比现有 Hadoop 查询引擎快一或两个数量级。这些性能改进主要归功于 Dynamic pipelining 和 HDB 内基于成本的查询优化器的强大功能。这使 HDB 能够帮助企业以显著降低的成本摆脱企业数据仓库工作负载。
一体化深度分析与机器学习功能
除表连接与聚合外,数据分析通常还需要使用统计学、数学和机器学习算法,如拟合和主成分分析等,这些代码需要进行重构,以便在并行环境中高效运行。这正在成为SQL on Hadoop 方案的基本要求。
HDB 利用可扩展数据库内分析的开源库 MADLib 来提供这些功能,从而通过用户定义的函数扩展 SQL on Hadoop能力。MADLib 还支持在 PL/R、PL/Python 和 PL/Java 环境中实施用户定义的函数来指定自定义机器学习能力。对于有此类需求的用户场景来说,这将使其能在通常的分析型工作负载中嵌入高级机器学习的分析能力。
SQL on Hadoop的数据联合能力
SQL on Hadoop可以联合外部数据源数据,提供更多灵活性,能够将各种来源的数据结合起来进行分析。数据通常是跨其它分析/企业数据仓库、HDFS、Hbase 以及 Hive 实例进行联合的,且需要利用基于 SQL on Hadoop 实施所固有的并行性。HDB 通过名为 Pivotal eXtension Framework (PXF) 的模块提供数据联合功能。除了常见的数据联合功能外,PXF 还利用SQL on Hadoop 提供其它具有行业特色的能力:
任意大数据集低延迟:PXF 使用智能抓取,其过滤器下推到Hive 和 Hbase。查询工作负载被下推到联合数据堆栈,从而尽可能减少数据移动和改善延迟性能,尤其是对于交互式查询而言。
可扩展且可自定义:PXF 提供框架 API 以便客户为其自有数据堆栈开发新的连接器,进而增强数据引擎的松散耦合和避免实施端对端分析使用案例时常常需要执行的数据重构操作。
高效:PXF 利用 ANALYZE 可收集外部数据的统计资料。这样可通过基于代价的优化器优化联合数据源统计信息,帮助联合环境构建更高效的查询。
SQL on Hadoop 的高可用性和容错能力
HDB 支持各种事务,是 SQL on Hadoop方案的首选。事务允许用户隔离 Hadoop 上的并行活动并在出错时进行回滚。HDB 的容错性、可靠性和高可用性三个特点能容忍磁盘级与节点级故障。这些能力可确保业务的连续性,并且实现了将更多关键业务分析迁移到到 HDB上运行。
原生 Hadoop 文件格式支持
HDB 在 Hadoop 中支持 AVRO、Parquet 和本地 HDFS 文件格式。这在最大程度上减少了数据摄取期间对 ETL 的需求,并且利用 HDB 实现了 schema-on-read(读时模式)类处理。对 ETL 和数据移动需求的减少直接有助于降低分析解决方案的拥有成本。
通过Apache Ambari进行原生的Hadoop管理
Pivotal HDB使用Apache Ambari作为管理和配置的基础,合适的Ambari插件可以使得Hawq像其他的通用Hadoop服务一样被Ambari来管理,所以IT管理团队不再需要两套管理界面-一套管理Hadoop,一套管理Pivotal HDB。这样可以使得企业专注于功能场景最小化支持所需的工作量,例如配置和管理。同时,Ambari是完全的Hadoop开源管理和配置工具,消除了供应商绑定和减低商业风险。
Hortonworks Hadoop兼容
为了更进一步的跟进开放数据联盟ODP的步伐,Pivotal HDB可以与Hortonworks HDP大数据体系无缝兼容,使得企业在已经投资的Hortonworks 大数据平台上感受到业界最先进的SQL on Hadoop方案带来的所有好处,Pivotal HDB也同时支持Pivotal自己的Hadoop发行版 Pivotal HD。
一流基于 SQL on Hadoop
Pivotal 大量投资于基于 SQL on Hadoop,使企业能够将 Hadoop 的用途从主要用于存储结构化和非结构化数据和 ETL 工作负载的数据湖扩展到通过 Hadoop 实施更多分析数据仓库工作负载。
公司介绍
Pivotal成立于2013年4月,由EMC、VMware和GE投资成立,专注于帮助企业在数字化时代变革所需的PaaS云计算、大数据基础平台和平台上的极限编程。在开源PaaS云、大数据和敏捷开发领域颇有建树。
Pivotal中国研发自成立以来,发展迅速,其团队成员分布在北京和上海两地,目前正致力于以下产品的研发和服务的提供:Pivotal Labs极限编程咨询,基于Cloud Foundry的PWS (Pivotal Web Service) Greenplum Database(GPDB)和Pivotal HDB (基于Apache HAWQ)。
最新版本:2.2
官方主页:https://pivotal.io/
项目主页:https://pivotal.io/cn/pivotal-hdb