Hadoop 分布式存储系统-Ozone
 Ozone 是 Apache Hadoop 社区的新一代分布式存储系统,它的出现满足了大量小文件的存储问题,解决了 Hadoop 分布式文件系统在可扩展性上的缺陷。作为 Hadoop 生态圈的一款新的对象存储系统,能够支持百亿甚至千亿级文件规模的存储。采用Java开发并在ApacheV2.0协议下授权。
Ozone 是 Apache Hadoop 社区的新一代分布式存储系统,它的出现满足了大量小文件的存储问题,解决了 Hadoop 分布式文件系统在可扩展性上的缺陷。作为 Hadoop 生态圈的一款新的对象存储系统,能够支持百亿甚至千亿级文件规模的存储。采用Java开发并在ApacheV2.0协议下授权。Ozone is a scalable, redundant, and distributed object store for Hadoop. Apart from scaling to billions of objects of varying sizes, Ozone can function effectively in containerized environments such as Kubernetes and YARN.
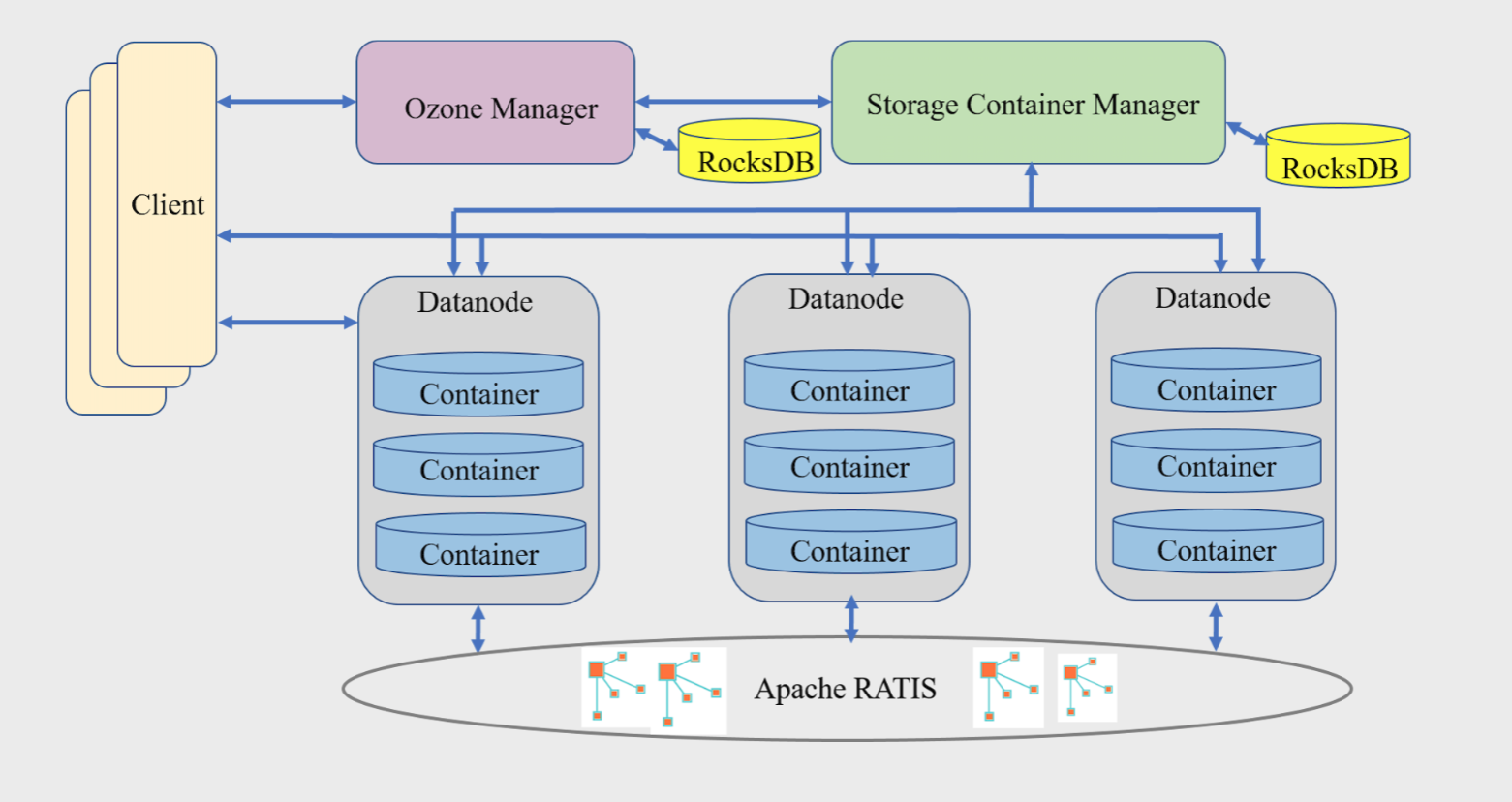
Applications using frameworks like Apache Spark, YARN and Hive work natively without any modifications. Ozone is built on a highly available, replicated block storage layer called Hadoop Distributed Data Store (HDDS).
Ozone 1.0.0 除了支持 Hadoop Compatible FileSystem、Hadoop 2.x 以及 Hadoop3.x 环境,还兼容 Hadoop 生态的 Kerberos 认证体系,支持数据的用户无感知加密存放和 Ranger 授权集成、GDPR “Right to Erasure”以及网络构架感知。
根据腾讯介绍,腾讯云大数据团队在 Ozone 项目上主导完成了集群网络拓扑感知的开发,以及数据写入 Multi-Raft Pipeline 功能的开发。同时,主导的 StorageContainerManager (SCM) 高可用 HA 功能也正在开发中。
以集群网络拓扑感知来说,在传统的大数据构架下,有了网络拓扑结构,计算引擎的调度器可以将任务调度到离数据最近的节点来获取“数据的局部性”。即便是新兴的计算存储分离构架,同样也需要集群网络拓扑信息,来保证数据的故障容错能力和高可用性。
腾讯团队 Ozone 项目负责人陈怡介绍,在 Ozone 的 Alpha 版本发布后,腾讯内部的大数据平台上线了 Ozone 生产集群,承接了一部分业务的数据存储。随着数据服务体量的增加,逐渐发现 Ozone 写入性能显现出了一定的波动和瓶颈。基于这个发现,腾讯 Ozone 项目组设计并开发了数据写入 Multi-Raft Pipeline 功能,显著提升了 Ozone 的写入吞吐量和性能。
为了确保 Ozone 和 Hive、Spark 与 Impala 等计算框架的无缝对接,Ozone 1.0.0 与这几大平台进行了集成测试,TPC-DS 的测试表明,在 100GB 和 1TB 两种数据量大小下,Ozone 总体比 HDFS 有 3.5% 的优势。
最新版本:1.0
经过 2 年多的社区持续开发和内部 1000+ 节点的实际落地验证,Ozone 1.0.0 终于于2020年9月发行。1.0.0 意味着该系统已经具备在大规模生产环境下实际部署的能力。
项目主页:http://hadoop.apache.org/ozone/