MessagePack
 MessagePack是一种高效的二进制序列化格式。它允许像JSON一样可在多个语言之间交换数据,但它更小并且更快,更轻便更灵活的一种数据交换协议。在Apache协议下授权使用。
MessagePack是一种高效的二进制序列化格式。它允许像JSON一样可在多个语言之间交换数据,但它更小并且更快,更轻便更灵活的一种数据交换协议。在Apache协议下授权使用。It's like JSON. but fast and small.
MessagePack is an efficient binary serialization format. It lets you exchange data among multiple languages like JSON. But it's faster and smaller. Small integers are encoded into a single byte, and typical short strings require only one extra byte in addition to the strings themselves.
从官方定义中,可以有如下的结论:
MessagePack是一个二进制序列化格式,因而它序列化的结果可以在多个语言间进行数据的交换。
从性能上讲,它要比json的序列化格式要好。
从结果大小上讲,它要比json的序列化结果要小。
在配合像LZ4这类压缩功能,可以实现超快速序列化和二进制占用空间小。可用于游戏,分布式计算,微服务,数据存储到Redis等。序列化目标必须标记[MessagePackObject]和[Key], Key类型可以选择int或字符串。如果Key类型是int,则使用序列化格式为数组,如果Key类型是字符串,则使用序列化格式为键值对。
它的数据格式与json类似,但是在存储时对数字、多字节字符、数组等都做了很多优化,减少了无用的字符,二进制格式,也保证不用字符化带来额外的存储空间的增加。以下是官网给出的简单示例图:
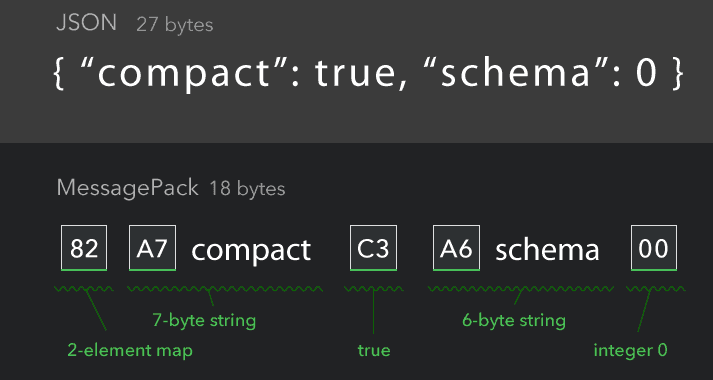
图上这个json长度为27字节,但是为了表示这个数据结构,它用了9个字节就是那些大括号、引号、冒号之类的,他们是白白多出来的来表示那些额外添加的无意义数据。msgpack的优化在图上展示的也比较清楚了,省去了特殊符号,用特定编码对各种类型进行定义,比如上图的A7,其中前四个bit A就是表示str的编码,而且它表示这个str的长度只用半个字节就可以表示了,也就是后面的7,因此A7的意思就是表示后面是一个7字节长度的string。有人可能就会问了,对于长度大于15二进制1111的string怎么表示呢?这就要看messagepack的压缩原理了。
MessagePack is a computer data interchange format. It is a binary form for representing simple data structures like arrays and associative arrays. MessagePack aims to be as compact and simple as possible.
数据类型与语法
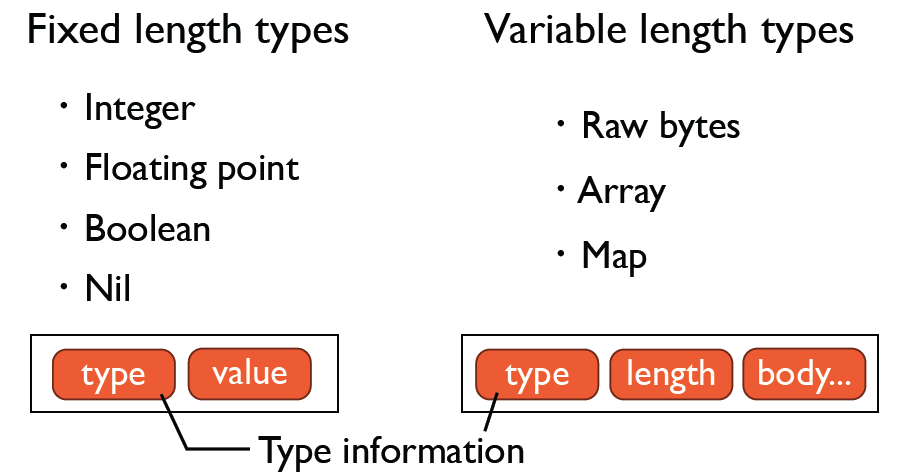
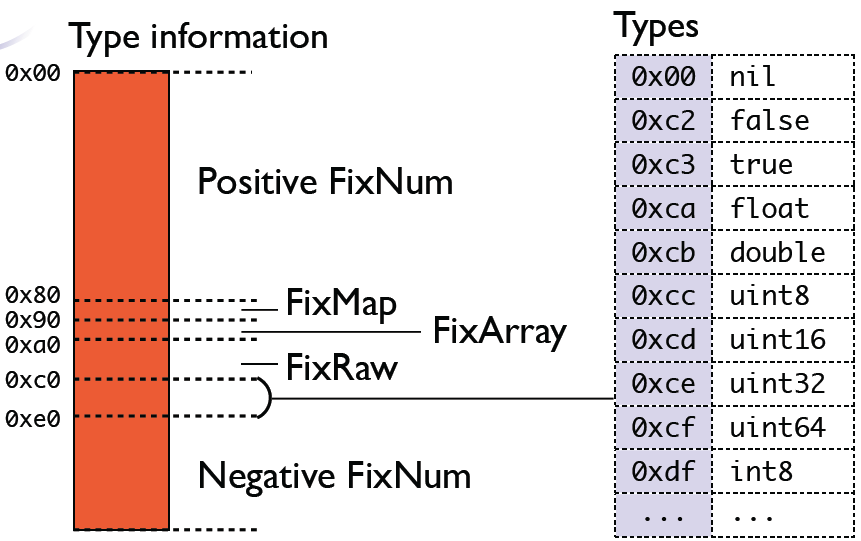
类型体系是MessagePack的基础,也是MessagePack在序列化后比json占用空间小的关键。当前包含的type有如下几类:
Data structures processed by MessagePack loosely correspond to those used in JSON format. They consist of the following element types:
nil
bool, boolean (true and false)
int, integer (up to 64 bits signed or unsigned)
float, floating point numbers (IEEE single/double precision)
str, UTF-8 string
bin, binary data (up to 232-1 bytes)
array
map, an associative array
ext (arbitrary data of an application-defined format, up to 232-1 bytes)
timestamp (ext type = -1) (up to 32-bit seconds and 64-bit nanoseconds)
MessagePack的直接竞争对手为JSON、YAML、BSON、Protocol Buffers、Thrift、Avro这些等。但是官方并没有提MessagePack和Google Pb的对比,实际上从空间和时间两个方面对比,Pb均要优于MessagePack,但Pb相对MessagePack 的缺点是支持的语言种类比较少,需要编写专门的.proto文件,使用上没有MessagePack方便。
这个类型体系将我们在代码开发中用到的数据格式进行了映射,并且通过Extension这个类型给使用者留出了自由扩充的空间,但由于表示形式的限制,当前Extension最多有127个。每一种类型能够表示的范围可以查看MessagePack规范中的Limitation部分和Extension types部分。
格式
在MessagePack中一个value的组成格式是这样的:类型[长度][data]。下面列出几个示例,详细完整的描述请看附录中的MessagePack规范。
1)、常量型
比如对于null、true、false这三个值,在MessagePack会被固定的映射为如下的值。
format name | first byte (in binary) | first byte (in hex) |
nil | 11000000 | 0xc0 |
false | 11000010 | 0xc2 |
true | 11000011 | 0xc3 |
2)、int型包含有符号整数和无符号整数
示例如下:
0xcc表示当前的值的类型是无符号整数并且长度不超过8个bit,具体的值内容需要通过后续8个bit位的内容来计算
0xcd表示当前的值的类型是无符号整数并且长度不超过16个bit,具体的值内容需要通过后续16个bit位的内容来计算
0xd0表示当前的值的类型是有符号整数并且长度不超过8个bit,具体的值内容需要通过后续8个bit位的内容来计算
0xd1表示当前的值的类型是有符号整数并且长度不超过16个bit,具体的值内容需要通过后续16个bit位的内容来计算
uint 8 stores a 8-bit unsigned integer
+--------+--------+
| 0xcc |ZZZZZZZZ|
+--------+--------+
uint 16 stores a 16-bit big-endian unsigned integer
+--------+--------+--------+
| 0xcd |ZZZZZZZZ|ZZZZZZZZ|
+--------+--------+--------+
int 8 stores a 8-bit signed integer
+--------+--------+
| 0xd0 |ZZZZZZZZ|
+--------+--------+
int 16 stores a 16-bit big-endian signed integer
+--------+--------+--------+
| 0xd1 |ZZZZZZZZ|ZZZZZZZZ|
+--------+--------+--------+
3)、字符串
0xd9表示当前的值的类型是字符串并且长度不超过(2^8)-1个bytes,具体的长度需要通过后续8个bit位的内容来计算,字符串的具体内容是后续长度的byte所表示的内容
0xda表示当前的值的类型是字符串并且长度不超过(2^16)-1个bytes,具体的长度需要通过后续16个bit位的内容来计算,字符串的具体内容是后续长度的byte所表示的内容
str 8 stores a byte array whose length is upto (2^8)-1 bytes:
+--------+--------+========+
| 0xd9 |YYYYYYYY| data |
+--------+--------+========+
str 16 stores a byte array whose length is upto (2^16)-1 bytes:
+--------+--------+--------+========+
| 0xda |ZZZZZZZZ|ZZZZZZZZ| data |
+--------+--------+--------+========+
4)、数组
0xdc表示当前的值的类型是数组并且长度不超过(2^16)-1个元素,具体的长度需要通过后续16个bit位两个byte的内容来计算,计算出来的值就是数组元素的个数
0xdd表示当前的值的类型是数组并且长度不超过(2^32)-1个元素,具体的长度需要通过后续32个bit位4个byte的内容来计算,计算出来的值就是数组元素的个数
array 16 stores an array whose length is upto (2^16)-1 elements:
+--------+--------+--------+~~~~~~~~~~~~~~~~~+
| 0xdc |YYYYYYYY|YYYYYYYY| N objects |
+--------+--------+--------+~~~~~~~~~~~~~~~~~+
array 32 stores an array whose length is upto (2^32)-1 elements:
+--------+--------+--------+--------+--------+~~~~~~~~~~~~~~~~~+
| 0xdd |ZZZZZZZZ|ZZZZZZZZ|ZZZZZZZZ|ZZZZZZZZ| N objects |
+--------+--------+--------+--------+--------+~~~~~~~~~~~~~~~~~+
5)、小结
Serialization:type to format conversion
source types | output format |
Integer | int format family (positive fixint, negative fixint, int 8/16/32/64 or uint 8/16/32/64) |
Nil | nil |
Boolean | bool format family (false or true) |
Float | float format family (float 32/64) |
String | str format family (fixstr or str 8/16/32) |
Binary | bin format family (bin 8/16/32) |
Array | array format family (fixarray or array 16/32) |
Map | map format family (fixmap or map 16/32) |
Extension | ext format family (fixext or ext 8/16/32) |
If an object can be represented in multiple possible output formats, serializers SHOULD use the format which represents the data in the smallest number of bytes.
Deserialization: format to type conversion
source formats | output type |
positive fixint, negative fixint, int 8/16/32/64 and uint 8/16/32/64 | Integer |
nil | Nil |
false and true | Boolean |
float 32/64 | Float |
fixstr and str 8/16/32 | String |
bin 8/16/32 | Binary |
fixarray and array 16/32 | Array |
fixmap map 16/32 | Map |
fixext and ext 8/16/32 | Extension |
6)、为什么MessagePack比json序列化使用的字节流更少
直观对比
可以通过下图的两张图简单进行下对比,第一张图是同一个数据类型的内容用json和messagepack序列化的结果。
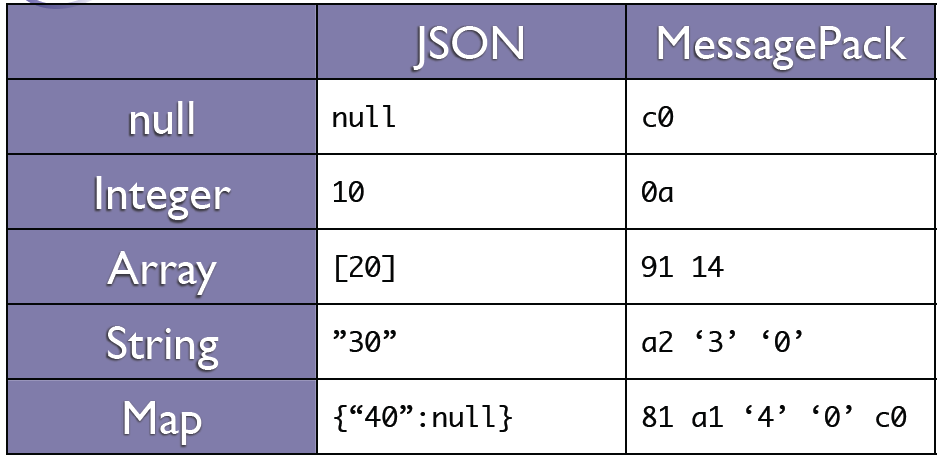
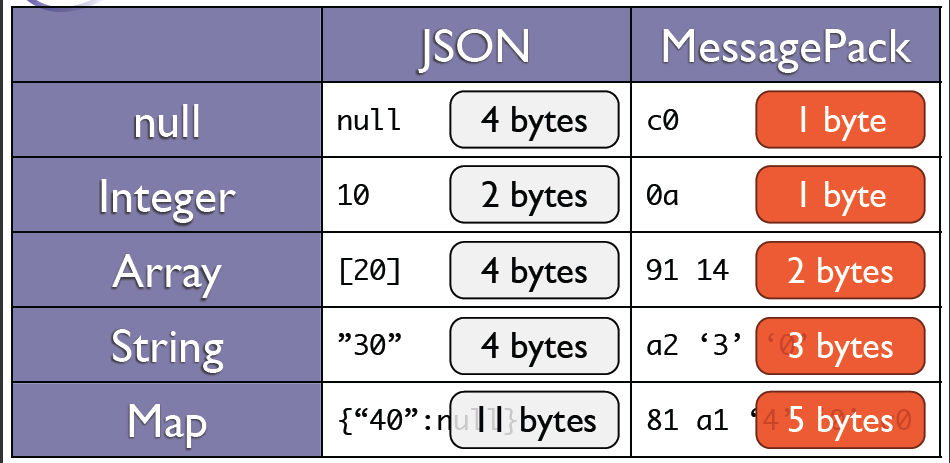
从第二张图可以明显看到messagepack要比json占用的空间更少。在Perl中对比了另外两种格式类型的大小:
say length(JSON::XS::encode_json({a=>1, b=>2})); # => 13
say length(Storable::nfreeze({a=>1, b=>2})); # => 21
say length(Data::MessagePack->pack({a=>1, b=>2})); # => 7
MessagePack的压缩原理
核心压缩方式可参看官方说明(messagepack specification),概括来讲就是:
true、false 之类的:这些太简单了,直接给1个字节,0xc3 表示true,0xc2表示false。
不用表示长度的:就是数字之类的,他们天然是定长的,是用一个字节表示后面的内容是什么,比如用0xcc 表示这后面,是个uint 8,用oxcd表示后面是个uint 16,用 0xca 表示后面的是个float 32)。对于数字做了进一步的压缩处理,根据大小选择用更少的字节进行存储,比如一个长度<256的int,完全可以用一个字节表示。
不定长的:比如字符串、数组、二进制数据bin类型,类型后面加 1~4个字节,用来存字符串的长度,如果是字符串长度是256以内的,只需要1个字节,MessagePack能存的最长的字符串,是(2^32 -1 ) 最长的4G的字符串大小。
高级结构:MAP结构,就是k-v 结构的数据,和数组差不多,加1~4个字节表示后面有多少个项。
Ext结构:表示特定的小单元数据。也就是用户自定义数据结构。
我们看一下官方给出的stringformat示意图
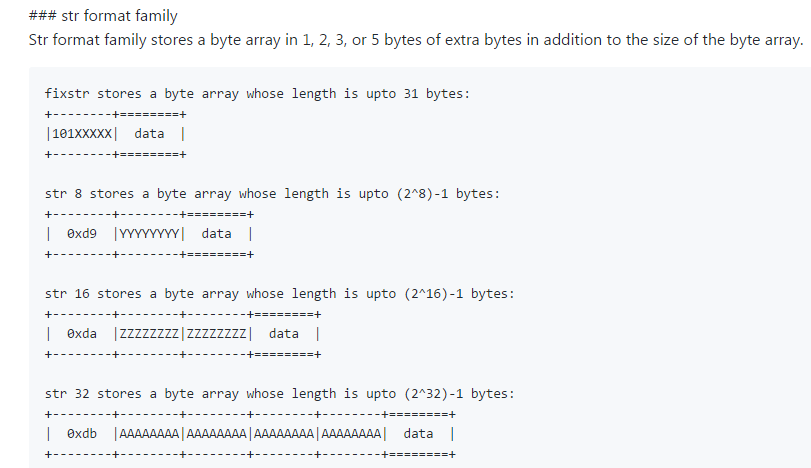
对于上面的问题,一个长度大于15也就是长度无法用4bit表示的string是这么表示的:用指定字节0xD9表示后面的内容是一个长度用8bit表示的string,比如一个160个字符长度的字符串,它的头信息就可以表示为D9A0。
这里值得一提的是Ext扩展格式,正是这种结构才保证了messagepack的完备性,因为实际的数据接口中自定义结构是非常常见的,简单的已知数据类型和高级结构map、array等并不能满足需求,因此需要一个扩展格式来与之配合。比如一个下面的接口格式:
{
"error_no":0,
"message":"",
"result":{
"data":[
{
"datatype":1,
"itemdata":
{//共有字段45个
"sname":"\u5fae\u533b",
"packageid":"330611",
…
"tabs":[
{
"type":1,
"f":"abc"
},
…
]
}
},
…
],
"hasNextPage":true,
"dirtag":"soft"
}
}
怎么把tabs中的子数据作为一个整体写入itemdata这个结构中呢?itemdata又怎么写入它的上层数据结构data中?这时Ext出马了。我们可以自定义一种数据类型,指定它的Type值,当解析遇到这个type时就按我们自定义的结构去解析了。
参考来源:
MessagePack简析
MessagePack简介及使用
快速序列化组件MessagePack介绍
最新版本:0.4.5
MessagePack implementation for PostgreSQL written in PL/pgSQL.
官方主页:
http://msgpack.org/
https://github.com/msgpack