编译器架构-LLVM
 LLVM 是 Low Level Virtual Machine(低级虚拟机)的简称,这个库提供了与编译器相关的支持,可以作为多种语言编译器的后台来使用。能够进行程序语言的编译期优化、链接优化、在线编译优化、代码生成。LLVM的项目是一个模块化和可重复使用的编译器和工具技术的集合,是伊利诺伊大学的一个研究项目,提供一个现代化的,基于SSA的编译策略能够同时支持静态和动态的任意编程语言的编译目标。自那时以来,已经成长为LLVM的主干项目,由不同的子项目组成,其中许多正在生产中使用的各种商业和开源的项目,以及被广泛用于学术研究。
LLVM 是 Low Level Virtual Machine(低级虚拟机)的简称,这个库提供了与编译器相关的支持,可以作为多种语言编译器的后台来使用。能够进行程序语言的编译期优化、链接优化、在线编译优化、代码生成。LLVM的项目是一个模块化和可重复使用的编译器和工具技术的集合,是伊利诺伊大学的一个研究项目,提供一个现代化的,基于SSA的编译策略能够同时支持静态和动态的任意编程语言的编译目标。自那时以来,已经成长为LLVM的主干项目,由不同的子项目组成,其中许多正在生产中使用的各种商业和开源的项目,以及被广泛用于学术研究。The LLVM Project is a collection of modular and reusable compiler and toolchain technologies. Despite its name, LLVM has little to do with traditional virtual machines, though it does provide helpful libraries that can be used to build them.
LLVM began as a research project at the University of Illinois, with the goal of providing a modern, SSA-based compilation strategy capable of supporting both static and dynamic compilation of arbitrary programming languages. Since then, LLVM has grown to be an umbrella project consisting of a number of different subprojects, many of which are being used in production by a wide variety of commercial and open source projects as well as being widely used in academic research. Code in the LLVM project is licensed under the "UIUC" BSD-Style license.
LLVM 是 Illinois 大学发起的一个开源项目,和之前为大家所熟知的JVM 以及 .net Runtime这样的虚拟机不同,这个虚拟系统提供了一套中立的中间代码和编译基础设施,并围绕这些设施提供了一套全新的编译策略(使得优化能够在编译、连接、运行环境执行过程中,以及安装之后以有效的方式进行)和其他一些非常有意思的功能。
它以C++写成,包含一系列模块化的编译器组件和工具链,用来开发编译器前端和后端。它是为了任意一种编程语言而写成的程序,利用虚拟技术创造出编译时期、链接时期、执行时期以及“闲置时期”的优化。最早以C/C++为实现对象,而目前它已支持包括ActionScript、Ada、D语言、Fortran、GLSL、Haskell、Java字节码、Objective-C、Swift、Python、Ruby、Crystal、Rust、Scala以及C#等语言。主要以BSD许可来发展的开源软件。自9.0.0版本开始,LLVM使用带有LLVM额外条款的Apache许可证2.0版进行授权。而从2019年10月开始,LLVM项目的代码托管正式迁移到了GitHub。
对于普通的开发人员来说,LLVM计划提供了越来越多的可以使用、编译器以外的其他工具。例如代码静态检查工具 LLVM/Clang Static Analyzer,是一个名为 Clang 的子项目,能够使用同样的 Makefile 生成 HTML 格式的分析报告。
LLVM从一个学术研究项目进化成C、C++和Objective C编译器的通用后端。成功的关键是性能和适应能力,两者都得益于LLVM独特的设计和实现。LLVM项目主要作者Chris Lattner在Dr.Dobb's上刊文讲述了LLVM的设计。称Clang编译器相比GCC编译器具有不少优势,因为LLVM提供了某些独一无二的能力。LLVM区别于其它编译器的主要地方是其内部架构。从 2000年起,LLVM就设计作为一套可复用库,拥有定义明确的接口。而当时开源语言的实现是设计作为特定目的的工具,使用单一可执行文件,如GCC就很 难复用静态编译器中的解析器,脚本语言也是如此。
Features
Front-ends for C, C++, Objective-C, Fortran, etc based on the GCC 4.2 parsers. They support the ANSI-standard C and C++ languages to the same degree that GCC supports them. Additionally, many GCC extensions are supported.
A stable implementation of the LLVM instruction set, which serves as both the online and offline code representation, together with assembly (ASCII) and bytecode (binary) readers and writers, and a verifier.
A powerful pass-management system that automatically sequences passes (including analysis, transformation, and code-generation passes) based on their dependences, and pipelines them for efficiency.
A wide range of global scalar optimizations.
A link-time interprocedural optimization framework with a rich set of analyses and transformations, including sophisticated whole-program pointer analysis, call graph construction, and support for profile-guided optimizations.
An easily retargettable code generator, which currently supports X86, X86-64, PowerPC, PowerPC-64, ARM, Thumb, SPARC, Alpha, CellSPU, MIPS, MSP430, SystemZ, and XCore.
A Just-In-Time (JIT) code generation system, which currently supports X86, X86-64, PowerPC and PowerPC-64.
Support for generating DWARF debugging information.
A C back-end useful for testing and for generating native code on targets other than the ones listed above.
A profiling system similar to gprof.
A test framework with a number of benchmark codes and applications.
APIs and debugging tools to simplify rapid development of LLVM components.
LLVM提供了一套适合编译器系统的中间语言(Intermediate Representation,IR),有大量变换和优化都围绕其实现。经过变换和优化后的中间语言,可以转换为目标平台相关的汇编语言代码。LLVM可以和GCC工具链一起工作,允许它与为该项目编写的大量现有编译器一起使用。LLVM还可以在编译、链接时生成可重新定位的代码(Relocatable Code),甚至在运行时生成二进制机器码。LLVM的中间语言与具体的语言、指令集、类型系统无关,其中每条指令都是静态单赋值形式(SSA),即每个变量只能被赋值一次。这有助于简化变量之间的依赖分析。LLVM允许静态编译代码,或者通过实时编译(JIT)机制将中间表示转换为机器码(类似Java)。
它支持与语言无关的指令集架构及类型系统。每个在静态单赋值形式(SSA)的指令集代表着,每个变量(被称为具有类型的寄存器)仅被赋值一次,这简化了变量间相依性的分析。LLVM允许代码被静态的编译,包含在传统的GCC系统底下,或是类似JAVA等后期编译才将IF编译成机器代码所使用的即时编译(JIT)技术。它的类型系统包含基本类型(整数或是浮点数)及五个复合类型(指针、数组、向量、结构及函数),在LLVM具体语言的类型建制可以以结合基本类型来表示,举例来说,C++所使用的class可以被表示为结构、函数及函数指针的数组所组成。
LLVM JIT编译器可以优化在执行时期时程序所不需要的静态分支,这在一些部分求值(Partial Evaluation)的案例中相当有效,即当程序有许多选项,而在特定环境下其中多数可被判断为是不需要。根据2011年的一项测试,GCC在执行时期的性能平均比LLVM高10%。而2013年测试显示,LLVM可以编译出接近GCC相同性能的执行码。
英特尔将为其 C/C++ 编译器全面采用 LLVM
2021年8月消息,英特尔的长期编译器专家 James Reinders 在一篇博客中透露,他们将在下一代英特尔 C/C++ 编译器中使用 LLVM 开源基础架构;并分享了一些相关信息。LLVM 有助于我们实现为英特尔架构提供最佳 C/C++ 编译器的目标。最新的英特尔 C/C++ 编译器使用 LLVM,可提供更快的编译时间、更好的优化、增强的标准支持,以及对 GPU 和 FPGA 卸载的支持......采用 LLVM 的好处很多,将提供从经典编译器升级到基于 LLVM 的编译器的建议。致力于使其尽可能的无缝,同时为使用英特尔编译器的开发者带来众多好处。
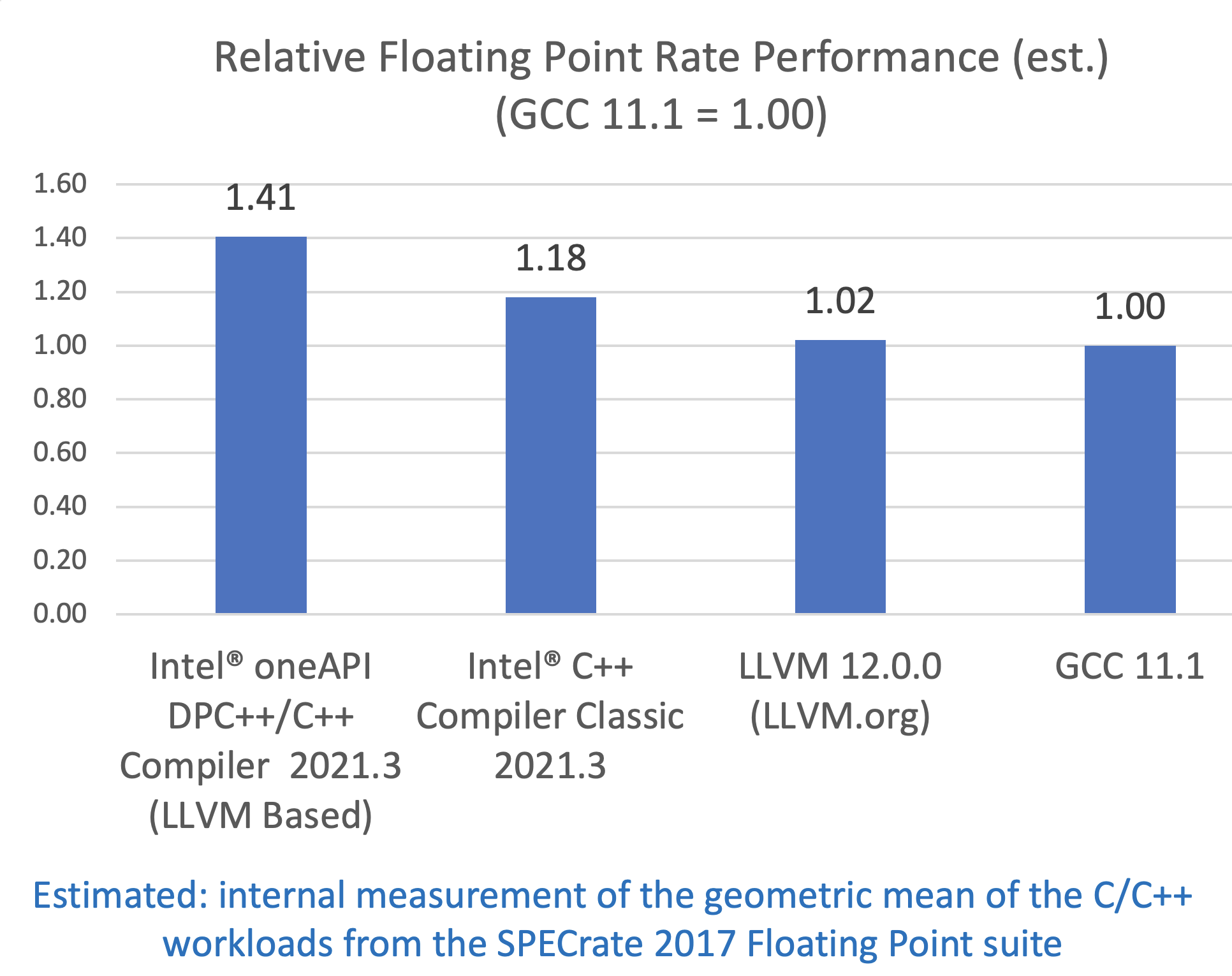
在构建时间方面,英特尔工程师报告称,新的基于 LLVM 的 oneAPI DPC++/C++ Compiler 2021.3 的构建时间相较他们的经典 C++ 编译器要减少了 14%。虽然经典英特尔 C++ 编译器一直比上游的 LLVM 和 GCC 快,但 oneAPI DPC++/C++ Compiler 2021.3 可提供比 GCC 11.1 快 41% 的性能。且新的基于 LLVM 的编译器的浮点性能比 ICC 高约 19%。
James 表示在基于 LLVM 的编译器中专注于新功能和硬件支持。包括在其中添加了对 GPU 和 FPGA 的高度优化支持,同时继续致力于提供 CPU 优化。其基于 LLVM 的编译器将支持 SYCL、C++20、OpenMP 5.1 和 OpenMP GPU 目标设备支持。鼓励用户通过现在转向我们基于 LLVM 的 C/C++ 编译器来利用更快的构建时间、更高级别的优化和新功能。英特尔长期致力于 LLVM,以帮助持续创新以及我们对行业领先优化的不懈追求。并建议所有新项目都使用基于 LLVM 的英特尔 C/C++ 编译器,现有项目也应计划在今年迁移到新的编译器。James 称,在未来的某个时间点,经典 C/C++ 编译器将进入"Legacy Product Support"模式。这标志着对经典编译器基础的定期更新结束,它们将不再出现在 oneAPI 工具包中。
全新的基于 LLVM 的 Intel C/C++ 已与经典版本达到同等水平,基于 LLVM 的 C/C++ 提供了我们拥有的最佳优化技术。我们建议所有用户现在就尝试新的 C/C++ 编译器,享受好处并提供反馈。此外,基于 LLVM 的英特尔 Fortran 编译器也正在进行中。目前,已有一个基于 LLVM 的 Fortran 编译器测试版提供了对 Fortran 的广泛支持,还有一些功能仍在开发中。
基于中间表示 IR 的 JIT 编译
JIT 编译
即"Just-in-time compilation(即时编译)"。中文语境中,似乎找不到“just-in-time(JIT)”对应的中文翻译(常见被勉强译为“即时”)。如果在制造领域,则代表着某种“精确制造”,“零库存制造”之意。就是很准确,很即时,一点也不浪费,需要多少立即安排恰好的资源,提供/生产多少的概念;而在编译领域,就作为“动态编译/运行时编译”的核心,恰好与 c/c++ 的传统“静态编译”模式(同时也是“提前编译”模式),作为对应。
动态编译技术
因此,Just-in-time(JIT)”编译,在执行时(runtime),应对即将运行的程序,进行即时的恰好的编译。它是“一边运行一边编译的”,也是“即时编译即将运行的(那段执行)”。它是“动态编译(dynamic compilation)”,或“运行时编译(runtime compilation)”。需要即刻执行的部分,可以是 per 文件(依赖每份文件),per 函数,甚至任何代码片段的。
转译的两种传统形式
“静态提前编译”(比如 c/c++ 传统编译),与“(运行时的,甚至可能是源码逐行的)解释”(比如传统解释语言 Basic),因此被“JIT 编译”完美融合了。
JIT 编译,首先“静态提前编译”产生“中间表示”,然后运行时(runtime),通过 JIT 编译该“中间表示(IR)”,产生 per target 机器码。这样JIT 编译就兼具“静态提前编译”的强大,以及“运行时解释”的弹性。“IR”也可能单纯解释,那这样就与 JIT 编译无关了,但这也是 application 的某种模式。
尽管 JIT(编译)技术老早就出现雏形,Ken Thompson(C语言前身 B 语言的发明者)就在某个应用中,关于正则表达式的 runtime 表示,进行过使用。但实际 JIT 编译技术正式应用,应当算作约 1994 年的 JVM 的引入(以及新发明的语言 Java)。中间表示(IR)在 JVM,即 Java 虚拟机(virtual machine)上,被(动态的,运行时的方式)编译或解释。与之对应的,是 MS 的 .net 平台。此外 JIT 技术还应用于后来的 Python。另据早年的一些技术资料:Java/JVM(Java runtime 环境)/JIT 的设计初衷是针对所有的“硬件芯片(指令集)平台”的设计,即打算统一在芯片(处理器)之上的,中间环境(平台)。目前来看与其初衷发生偏移。
基于中间表示 IR 的 LLVM 编译链项目
LLVM 缩略语联想其同样发生命运偏移的,LLVM 本意应指“Low Level Virtual Machine(低端虚拟机)”。这直觉上,简直就是 Java VM 初衷的翻版。但无论其初衷如何,这个缩略语的联想,被完全废止了。毕竟,LLVM 现在纯粹是编译链(的工具集合)的, (所谓“伞形”)开源项目组合(因此与 JIT 编译引入的 VM/runtime environment 不同)。但不得不说,LLVM 与传统(概念上的)虚拟机(VM)没有半点关系”。
中间表示(intermediate representations / IR)
从“中间表示(IR)”的角度来看,IR 是整个 JIT 的核心(两个阶段性的编译步骤,前者的静态编译产物 IR,被后者动态即时编译,即运行时编译,生成 target 的机器码)。对于 Java 而言,这个“中间表示(IR)”,就是 bytecode(因其独立性,所以 Java 才能跨平台)。
LLVM/IR 之不同(LLVM 之 IR 是语言独立的)
(1)JIT 的 IR(即 bytecode),并非“人类可读的源码”。它是由紧凑的数字编码,常量,引用(通常是数字寻址的),编译器分析后的编码结果。它是类型,(数据类型/函数)作用域,以及程序对象的嵌入深度等,语法分析的表现物。
(2)对待“中间表示(IR)”,LLVM 与 JIT 的处理方式出现了分道扬镳。如前述,JIT 通过“运行时环境”,或 “虚拟机(VM)”,针对不同的 target 进行生成机器码。它是“动态的”,或者说是“运行时的”编译。而正如 LLVM 极力摆脱的,关于“VM”的初学者联想。它不再与 VM (平台执行时编译)相关,而仅仅是,进一步编译 IR,生成更具表现力的机器码。
(3)LVM 的“中间表示(IR)”,被定义为:低层编程语言(类似汇编)。
讨论:似乎可以这样理解,LLVM 实现的是某种纯粹的编译(链)技术。即将原始的静态编译过程,分解为两个部分:首先编译“IR(RISC 指令集的,类汇编的底层编程语言)”,以及基于 IR 的继续编译过程(生成物为机器码)。这种对 IR 的编译,不强调需要 VM(某种虚拟的独立平台)来实现。
(4)LLVM 的 IR 可以有三种等价的表示,包括:(a)人类可读汇编格式;(b)适配前端的载入内存格式;(c)为序列化使用的紧凑 bitcode 格式。
关于Clang:Clang 是编译器,是 LLVM (编译链伞形开源项目的)前端(用于编译 c/c++,由于是 Apple 公司支持的产品,还支持编译 object c/c++);它的地位几乎等同于传统的 GNU 之 gcc。但与 gcc 不同之处,clang 产生“低层的,类汇编的”中间表示/IR(RISC)。非常重要的不同之处,还在于两者许可证不同(GPL 与 Apache License)。
不同的许可证对于商业公司来说意义完全不同,持续使用 GNU,或者说使用它的编译链 GCC,似不可行。且不说研发投入浪费(对 GPL 版权的源码进行任何修改,或者说任何层次的衍生物,必须被迫开源公布)。最早的 LLVM 的许可证是 UIUC(Lattner 所在院校),它使用的是 BSD-like。在 v9.0.0 后成为 Apache License 2.0(似乎比 BSD 略微严格了一点点,修改的文件需要附上版权说明)。无论哪种,它们都是允许商业闭环使用的。现在无论是新的芯片处理器公司发布新架构(比如时新的 RISC5),还是哪怕小型团队无论出于学研还是商业目的,发布的任何编程语言的新编译器,这些个产品,只要基于开源的 LLVM,那都是可商业闭环使用的(不用公布任何源码)。
LLVM 的强调重点已转向如下内容:LLVM 的 IR 是语言独立的,LLVM 的“前端”是基于(不同)语言的编译器(用来生成独立的中间表示/ IR)。
Clang与GCC 的性能比较
(1)早期的 Clang 在内存使用与编译速度上,对比 GCC 有着惊人的提升。2007年的某个比较数据是:Clang 具有2倍的速度,而仅使用 1/6 的内存。
(2)但在 2016 ~ 2019 年左右,两者之间的(未优化的 C 代码编译)性能差距不再明显,互有胜负。
(3)对 Clang 最坚定的支持者是 FreeBSD。在 2016 年,Clang 成为 Andriod(默认)编译器,以及 2019 年,Clang 支持 RISC5。比较出名的产品来自 2018 年的 Google chrome, 以及 Mozilla Firefox。Clang v3.8 支持 OpenMP,也算一个重要里程碑。
LLVM 16 默认标准从 C++14 转为 C++17
2017 年 12 月,一则提议将 LLVM/Clang 的 C++ 默认方言(default dialect)从 GNU++98 切换到 GNU++14 ,一直持续到2022年9月的 LLVM/Clang 15 版本,而 GCC 在 GCC 11 版本就已将默认标准设为 GNU++ 17 。在 LLVM 15.0 发布后,LLVM/Clang 16.0 版本即将迎来一个重大变化:GNU++17 将成为 LLVM 默认的 C++ 和 ObjectiveC++ 版本。
Clang 的 C++17 支持非常稳定了,只有一些微小的细节需要修复。事实上,Apple 的 DriverKit 已经在上游 LLVM 中进行了更改(D121911 [Clang] 添加 DriverKit 支持 ),默认使用 GNU++17 而不是 GNU++14。目前相关的补丁已经发布,没有突发状况,默认标准转为 GNU++ 17 应该是板上钉钉的事情。切换默认版本之后,对于当前与 C++17 不兼容且依赖默认值的 C++ 代码库,则需要设置 -std=gnu ++14 或更早版本,以保持与默认值的兼容性。
最新版本:3.8
此版本是 LLVM 社区辛苦开发六个月的结果,包括大量bug修复,优化改进,Clang 支持更多被提议的C++1z功能,更好的原生 Windows 兼容性,本地对象文件中嵌入 LLVM IR,绑定 Go 等等,更多内容请看发行说明。
最新版本:5.0
LLVM 5.0.0 已正式发布。LLVM 前不久改变了版本方案,每发布一个大版本将增加一个版本号,小版本号变化主要是同一分支的更新。这个版本是社区在过去六个月里工作的结果,主要包括以下内容:
支持 C++17
支持协同例程(co-routines)
改进的优化新的编译器警告,许多错误修复等。
最新版本:7.0
7.0.0 版本包含有关 SVN 修订版 338536 主干上的工作与在发布分支上的工作,这是社区过去六个月工作的结果,主要包括:
Clang 功能多元化:使用基于 ELF 的 x86/x86_64 目标的“target”属性
改进在 clang-cl 中支持 PCH
初步支持 DWARF v5与OpenCL C++支持
FreeBSD 支持 MSan、X-Ray 和 libFuzzer
UBSan 检查隐式转换
很多 lld 中修复了长尾兼容性问题,为目前正在生产的 ELF、COFF 和 MinGW 做好准备
新工具 llvm-exegesis、llvm-mca 和 diagtool
其它优化、改进的诊断和 bug 修复
最新版本:9.0
LLVM 9.0 已经发布,LLVM 9.0 与 Clang9.0 C/C++ 编译器一起发布,该版本的主要亮点内容如下:
支持 ASM Goto,例如,使用 Clang 为 x86_64 构建主线 Linux 内核
RISC-V target 不再是实验性,而是默认构建的
对 OpenCL 实验性支持 C++
其它改进包括 AMD Navi 支持、AMDGPU LLVM 编译器后端增强、AMD Zen 2 "znver2" 支持和新的 Intel CPU 功能等内容。另外还有许多 bug 修复、优化和诊断改进。详情见发行说明。
最新版本:12.0
LLVM 12.0.0 现已于2021年4月中旬发布,本次更新内容主要包括 bug 修复和一些小型功能优化,部分更新内容
ConstantPropagation 传递已删除,用户应改用 InstSimplify 传递
添加了 byref 属性,以更好地表示 amdgpu_kernel 调用约定的参数传递
为 sret 属性添加了类型参数,以继续支持删除指针元素类型的工作
llvm.experimental.vector.reduce 内部函数家族已重命名,以删除名称中的 “experimental”
内部的 llvm-build Python 脚本和用于描述 LLVM 组件结构的相关 LLVMBuild.txt 文件已经被删除,取而代之的是一种纯粹的 CMake 方法,每个组件都会在创建的目标中存储额外的属性。一旦所有组件被定义,就会根据这些属性解析库依赖性并产生 llvm-config 所期望的 header
新的 "TableGen 程序员参考" 取代了 "TableGen 语言介绍" 和 "TableGen 语言参考“ 文档
Windows 生成数据方面:优化了展开数据,并在可能的情况下以打包形式写入展开数据,与 LLVM 11相比,展开数据(pdata 和 xdata 节)的大小减少了约60%。针对 Windows 调整了 prologs/epilogs 的生成
支持使用 .seh_* 汇编器指令创建 Windows 解卷数据
为 Windows 目标产生适当的程序集输出,包括 :lo12: relocation specifiers
将 MSVC 目标的汇编注释字符串改为/(与 MinGW 和 ELF 目标一致),使用 ; 作为语句分隔符
详情请查看更新公告。
最新版本:13.0
LLVM 13.0.0 现已于2021年10月上旬发布,本次更新内容主要包括 bug 修复和一些小型功能优化。主要更新内容:
Flang 作为 Fortran 前端现在包含在官方 LLVM 二进制包中
LLDB 可执行文件现在包含在官方预构建的 LLVM 二进制文件包中
对 Armv9-A 领域管理扩展 (RME) 和可扩展矩阵扩展 (SME) 的初始组装支持
在 Clang 中对 OpenCL 内核语言支持进行了许多改进,包括如果未指定其他版本,则默认使用 OpenCL C 版本 1.2。 “.clcpp”文件扩展名现在也支持用于 OpenCL 文件的 C++。还支持许多新的 OpenCL 扩展以及 OpenCL C 3.0
Clang 现在支持来自 OpenMP 5.1 的循环转换指令
改进 clang-format 工具
改进 Clang 静态分析器
LLVM-MCA 机器分析器现在支持有序处理器
LLDB 现在支持 AArch64 SVE 寄存器访问、AArch64 指针身份验证,并支持使用 MTE 进行调试
Libcxx 现在在使用 MinGW 的 Windows 上包含 std::filesystem 功能完整支持,并具有可用的 C++20 概念库支持和其他实现的 C++20 功能
AMDGPU 后端支持 GFX1013 RDNA2 APU
添加了 AMD Zen 3 调度程序模型
详情请查看更新公告
最新版本:15.0
LLVM 15 现已于2022年9月中旬正式发布,带来了许多 x86 相关的安全特性、对 Armv9 的支持、来自微软的实验性 HLSL 和 DirectX 支持,以及支持更多的 RISC-V 指令等功能。其变化包括:
支持 Armv9-A、Armv9.1-A 和 Armv9.2-A 架构。还增加了对 Arm Cortex-M85 CPU 的支持
实验性的 DirectX 后端,DirectX 后端针对 DXIL 架构,用于 DirectX GPU 着色器程序
支持 AMD Zen 2 和更新的 CPU 上的 RDPRU 指令
一个用于 Debuginfod 的 HTTP 服务器
初步的 SPIR-V 后端工作
在支持 SSE2 的 x86 CPU 上支持 half 类型,作为 _Float16 类型的一部分添加到 Clang 中
LLVM 现在为 LLVM IR 使用不透明的指针
索尼开始向上游贡献 PlayStation 5 编译器 target
完成初始 DirectX/HLSL target 代码
完成初始 LoongArch CPU 架构代码
对 AMD RDNA3/GFX11 图形硬件的初始编译器支持
更多详情可查看此处。
最新版本:16.0
LLVM 16 已正式于2023年3月下旬发布。16.0 中添加了许多令人兴奋的功能,包括更快的 LLD 链接、Zstd 压缩的调试部分、稳定其 LoongArch 支持、默认为 Clang 的 C++17 等等。下面是 LLVM 16 的主要变化:
Clang 的默认 C++ 标准现在是 GNU++17,而不是 GNU++14/C++14
实现更多 C++20 功能,以及对现有 C++20 功能的错误修复,并为 C++2b 功能做一些准备
实现了更多 C2X 功能
各种 Clang 16 编译器诊断改进
与 LLVM 15 相比,LLVM 16 的 LLD 链接器对 ELF 对象的链接速度要快得多
LLVM 16 LLD 现在也支持 Zstd 压缩,类似于 GCC 13 的 Zstd 支持
LLVM 的 LoongArch CPU 后端已升级为 “实验性”,现在默认启用。还有初始的 LoongArch JITLink 支持和启用的其他功能。LLVM 的 LLDB 调试器还支持调试 LoongArch 64 位二进制文件以及 Clang 编译器支持
LLVM 16.0 支持新的英特尔 x86 ISA 扩展,包括 AMX-FP16、CMPCCXADD、AVX-IFMA、AVX-VNNI-INT8 和 AVX-NE-CONVERT
支持的新 Intel CPU 目标是 Raptor Lake、Meteor Lake、Emerald Rapids、Sierra Forest、Granite Rapids 和 Grand Ridge
提供对带有 -march=znver4 的 AMD Zen 4 处理器的初始支持
LLVM 的 RISC-V 后端增加了对许多新扩展的支持,例如 Zca、Zbe、Zbf、Zbm、Zbp、Zbr 和 Zbt
LLVM 16 添加了对 Arm Cortex-A715 / Cortex-X3 / Neoverse-V2 内核的支持
LLVM 16 的 AArch64 后端现在支持函数多版本控制 (FMV),允许采用自定义代码路径,以根据运行时 CPU / 功能优化性能
删除了对 Armv2A / Armv2A / Armv3 / Armv3M 架构的支持
LLVM 16 的 libc++ C++ 标准库增加了对更多 C++20 和 C++23 功能的支持
更多内容可以查看 LLVM 16 的发行说明。
LLVM 16.0.1 已于2023年4月上旬发布,系 LLVM 16 大版本的修复版本,处理了一些版本早期的 Bug,并提供了一些新的功能。LLVM 16 采用了新的发布时间表,每两周发布一个新的错误修复版本 (14.0.x)。14.0.5 是计划中的最后一个版本,但如果在 14.0.5 中发现严重问题,可能会发布 14.0.6。该版本提供了一些新特性,比如支持 RISC-V 上的模拟 TLS,支持 AVX 中 BF16 的加载/存储,以及其他随机修复:
[AArch64] 修复 COFF 的折叠地址偏移上限
[compiler-rt] [scudo] 在 x86 可用时使用 -mcrc32 6 个
[AARCH64] ssbs 默认为 cortex-x1、cortex-x1c、cortex-a77 启用
[libc++] 在细节 header 中定义 namespace views
[X86] lowerV8I16Shuffle - 使用明确的 SmallVector<SDValue, 4> 宽度来避免 MSVC AVX 对齐错误
[clang-repl] 向底层执行引擎添加一个访问器
[AArch64] 为每个可变参数使用正确的调用约定
[SelectionDAG] 常量折叠时不要创建非法类型的节点
[AArch64] 在注册符号之前允许.variant_pcs
[VectorCombine] 在跨越地址空间边界时插入 addrspacecast
[ELF] 修复 COMMON 位于 SHT_PROGBITS 输出部分时的 llvm_unreachable 故障
[Object][test] 修复 invalid.test
[llvm-objdump] --private-headers:将错误更改为动态部分转储的警告
完整的更新项请在发行公告中查看。
官方主页:http://llvm.org/