内存文件系统(ramdisk-ramfs-tmpfs)与Page Cache
 ramfs是什么
ramfs是什么ramfs是一个非常简单的文件系统,它输出Linux的磁盘缓存机制(页缓存和目录缓存)作为一个大小动态的基于内存的文件系统。
通常,所有的文件由Linux被缓存在内存中。页的数据从保持在周围以防再次需要的后备存储(一般被挂载的是块设备文件系统)中读取,并标记为可用(空闲) 以防虚拟内存系统(Virtual Memory System)需要这些内存作为别用。类似的,在数据写回后备存储时,数据一写回文件就立即被标记为可用,但周围的缓存被保留着直至VM(虚拟机)重新分配内存。一个类似的机制(目录缓存)极大的加快了对目录的访问。
ramfs并没有后备存储。文件写入ramfs象往常一样,来分配目录和页的缓存,但这里并没有地方可写回它们。这意味着页的数据不再标记为可用,因此当希望回收内存时,内存不能通过VM来释放。
实现ramfs所需的代码总量是极少的,因为所有的工作由现有的Linux缓存结构来完成。实际上,你现正在挂载磁盘缓存作为一个文件系统。据此,ramfs并不是一个可通过菜单配置项来卸载的可选组件,它可节省的空间是微不足道的。
ramfs和ramdisk
旧的"内存磁盘"机制在一个内存空间中创建一个合成块设备并使用它作为一个文件系统的后备存储。这个块设备是固定大小的以至于挂载在它上面的文件系统也是固定大小的。除创建和销毁目录外,使用一个内存磁盘并不需要从假的块设备到页缓存拷贝内存数据(和拷贝更改回退)。另外,它需要一个文件系统驱动 (如,ext2)来格式和解释这些数据。
与ramfs相比较,这些废弃的内存(和内存总线带宽)为CPU造成了不必要的工作并污染了 CPU缓存。(这里有个技巧通过使用页表单来避免这个拷贝,但是它们难以理解并且代价反而变的与拷贝一样昂贵。)更为重要的是,由于所有的文件都通过页和目录缓存进行访问,全部的工作ramfs都要执行。内存磁盘是简单且多余的,ramfs在内部更为简单。
另一个理由是:ramdisks是半过时的,它引进的回环设备提供一个更灵活和方便的方式从文件而不是从大块的内存中来创建一个合成块设备。参见losetup(8)来获得有关细节。
ramfs和tmpfs
ramfs 的一个不利之处是你将保留写回到ramfs的数据直至你填补所有的内存,并且VM不能释放它,因为VM考虑到文件将写回后备存储(而不是交换空间),但是 ramfs并不能获得任何的后备存储。据此,只有root(或者一个受信任的用户)可允许回写到一个ramfs挂载中。
一个ramfs派生出tmpfs来添加大小的限制以及回写数据到交换空间的能力。普通用户可以允许回写到tmpfs挂载中。参见Documentation/filesystems/tmpfs.txt来获得更多信息。
rootfs是什么
rootfs是一个特定的ramfs(或tmpfs,如果那被启用)的实例,它始终存在于2.6的系统。你不能卸载rootfs,这个理由近似于你不能杀死init进程。它小巧且简单的为内核确保某些列表不能为空,而不是拥有特定的代码来检查和处理一个空列表。
大多数的系统挂载另一个文件系统到rootfs并忽略它。一个空白ramfs实例的空间总量占用是极小的。
在Linux中可以将一部分内存mount为分区来使用,通常称之为RamDisk。RamDisk有三种实现方式:
第一种就是传统意义上的,可以格式化,然后加载。
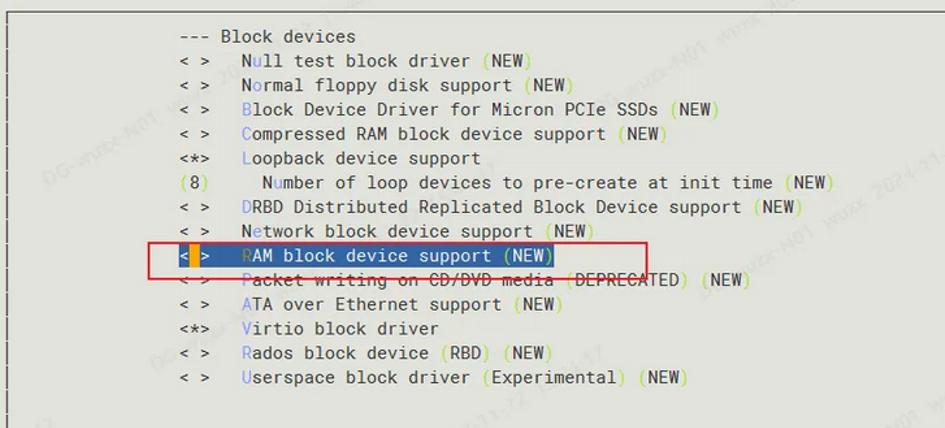
这在Linux内核2.0/2.2就已经支持,其不足之处是大小固定,之后不能改变。为了能够使用Ramdisk,我们在编译内核时须将block device中的Ramdisk支持选上,它下面还有两个选项,一个是设定Ramdisk的大小,默认是4096k;另一个是initrd的支持。如果对Ramdisk的支持已经编译进内核,我们就可以使用它了:
查看一下可用的RamDisk,查看使用ls /dev/ram*
首先创建一个目录,比如ramdisk,运行mkdir /mnt/ramdisk;
然后对/dev/ram0 创建文件系统,运行mke2fs /dev/ram0;
最后挂载 /dev/ram0,运行'mount /dev/ram /mnt/ramdisk',就可以象对普通硬盘一样对它进行操作了。
另两种则是内核2.4才支持的,通过ramfs或者tmpfs来实现:它们不需经过格式化,用起来灵活,其大小随所需要的空间而增加或减少。
ramfs顾名思义是内存文件系统,它它处于虚拟文件系统(VFS)层,而不像ramdisk那样基于虚拟在内存中的其他文件系统(ex2fs)。不能格式化,能够创建多个,在创建时能够指定其最大能使用的内存大小。假如您的Linux已将ramfs编译进内核,您就能够很容易地使用ramfs了。创建一个目录,加载ramfs到该目录即可。
因此它无需格式化,可以创建多个,只要内存足够,在创建时可以指定其最大能使用的内存大小。如果所用的Linux已经将ramfs编译进内核就可以很容易地使用ramfs了。创建一个目录,加载ramfs到该目录即可:
# mkdir /mnt/ramfs
# mount -t ramfs none /mnt/ramfs
缺省情况下,ramfs被限制最多可使用内存大小的一半,可以通过maxsize(以kbyte为单位)选项来改变。
# mount -t ramfs none /mnt/ramfs -o maxsize=2000 (创建了一个限定最大使用内存为2M的ramdisk)
tmpfs是一个虚拟内存文件系统,它不同于传统的用块设备形式来实现的ramdisk,也不同于针对物理内存的ramfs。
tmpfs可以使用物理内存,也可以使用交换分区。在Linux内核中,虚拟内存资源由物理内存(RAM)和交换分区组成,这些资源是由内核中的虚拟内存子系统来负责分配和管理。
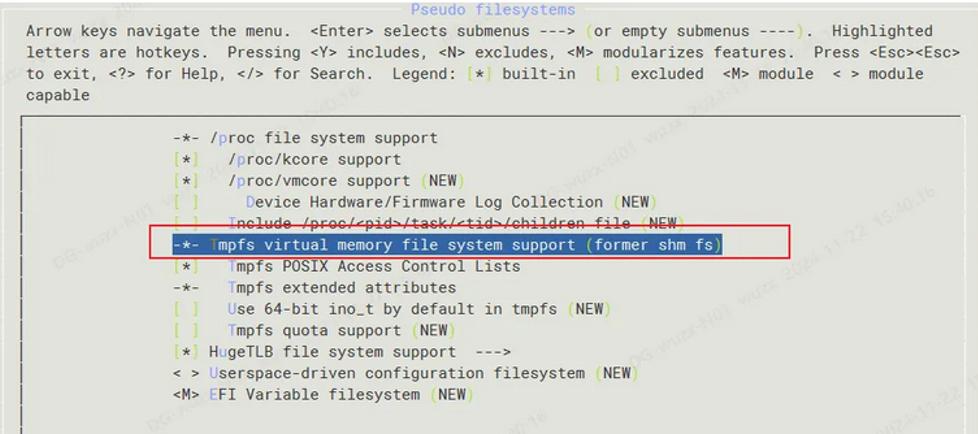
tmpfs向虚拟内存子系统请求页来存储文件,它同Linux的其它请求页的部分一样,不知道分配给自己的页是在内存中还是在交换分区中。同ramfs一样,其大小也不是固定的,而是随着所需要的空间而动态的增减。使用tmpfs,首先你编译内核时得选择"虚拟内存文件系统支持(Virtual memory filesystem support)" 。然后就可以加载tmpfs文件系统了:
# mkdir -p /mnt/tmpfs
# mount tmpfs /mnt/tmpfs -t tmpfs
同样可以在加载时指定tmpfs文件系统大小的最大限制:
# mount tmpfs /mnt/tmpfs -t tmpfs -o size=32m
使用df -aT命令可以看到有个/dev/shm目录,该目录的文件系统是tmpfs的,因此这个目录下的文件访问是非常快的,但是其大小可能不同机器都不一样,而且每次重启后文件也就丢失了。
Linux下内存文件系统有三个:
(1).ramdisk,使用前需要先创建文件系统,并且调整文件系统大小比较麻烦,需要修改内核引导参数并重新启动操作系统,在繁杂多变的应用与需要 7X24不间断运行的系统来说,并不是一个可以接受的选择.好处是自2.0版本起内核便支持。
(2).ramfs,使用前不需要去创建文件系统了,直接通过mount的方式即可挂载上来用,需要的时候可以使用"mount -o remount,maxsize=..."这种方式来调整大小。
(3).tmpfs,同ramfs在表面上基本上一样,不同于ramfs针对"物理内存",tmpfs是在虚拟内存下分配空间的,也就是说tmpfs实例中存储的文件既可能存在于物理内存中,也可能存在于交换分区中,具体存在哪里,是由"虚拟内存子系统"来调度的。
纯性能角度讲,ramfs会在进程占用内存使用较多的情况下会优于tmpfs,在没有交换分区或进程占用内存较小而不发生swap行为的情况下,两者性能不会有差异(这个结论没有实测过)。
基本情况介绍完毕,下面介绍tmpfs的应用。
0)根据需要创建挂载目录,例:
mkdir -p $DIR_TMP
1)挂载
mount my_tmpfs $DIR_TMP -t tmpfs -o size=512m
my_tmpfs这个名字需要起,一个标识而已,会出现在df 的Filesytem一列,起个别致点的名字比较容易被自己写的其它监控脚本找到,如果非要起个none或tmpfs之类的名字的话...反正系统默认挂载的tmpfs都比较喜欢用这两个名字,好坏自己琢磨吧.成功以后自己用df 看一下就知道了,写监控脚本时可以用"df -t tmpfs|grep ^my_tmpfs"来找到这一行.
2)调整
应用中如果感觉不合适,随时可以用mount命令调整
mount $DIR_TMP -o remount,size=1024m,nr_inodes=100k
nr_inodes为最大节点数,如果你的$DIR_TMP使用df命令查看明明有空间,却无法创建新文件(例如touch一个新文件),可能是文件节点用到上限了,可以用"df -i"命令来查看,如果是有空间但节点达到上限,就需要用nr_inodes来调整了.
其它可以调整的参数:
mode,uid,gid,
其它参数,参见mount命令的man page之OPTIONS一节中"-o"参数的说明.
3)卸载
umount $DIR_TMP
4)其它
mount 命令的man page中对tmpfs提及不多,详细一些的文档,请参阅内核文档Documentation/filesystems/tmpfs.txt(内核源代码目录内)
简言之
ramfs、是内存文件系统,不是真正的文件系统;
tmpfs、是文件系统;
ramdisk、是把内存当做硬盘使用。
Overview of ramfs and tmpfs on Linux
Using ramfs or tmpfs you can allocate part of the physical memory to be used as a partition. You can mount this partition and start writing and reading files like a hard disk partition. Since you’ll be reading and writing to the RAM, it will be faster.
When a vital process becomes drastically slow because of disk writes, you can choose either ramfs or tmpfs file systems for writing files to the RAM.

Both tmpfs and ramfs mount will give you the power of fast reading and writing files from and to the primary memory. When you test this on a small file, you may not see a huge difference. You’ll notice the difference only when you write large amount of data to a file with some other processing overhead such as network.
1. How to mount tmpfs
# mkdir -p /mnt/tmp
# mount -t tmpfs -o size=20m tmpfs /mnt/tmp
The last line in the following df -k shows the above mounted /mnt/tmp tmpfs file system.
# df -k
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda2 32705400 5002488 26041576 17% /
/dev/sda1 194442 18567 165836 11% /boot
tmpfs 517320 0 517320 0% /dev/shm
tmpfs 20480 0 20480 0% /mnt/tmp
2. How to mount ramfs
# mkdir -p /mnt/ram
# mount -t ramfs -o size=20m ramfs /mnt/ram
The last line in the following mount command shows the above mounted /mnt/ram ramfs file system.
# mount
/dev/sda2 on / type ext3 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
/dev/sda1 on /boot type ext3 (rw)
tmpfs on /dev/shm type tmpfs (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw)
fusectl on /sys/fs/fuse/connections type fusectl (rw)
tmpfs on /mnt/tmp type tmpfs (rw,size=20m)
ramfs on /mnt/ram type ramfs (rw,size=20m)
You can mount ramfs and tmpfs during boot time by adding an entry to the /etc/fstab.
3. ramfs vs tmpfs
Primarily both ramfs and tmpfs does the same thing with few minor differences.
* ramfs will grow dynamically. So, you need control the process that writes the data to make sure ramfs doesn't go above the available RAM size in the system. Let us say you have 2GB of RAM on your system and created a 1 GB ramfs and mounted as /tmp/ram. When the total size of the /tmp/ram crosses 1GB, you can still write data to it. System will not stop you from writing data more than 1GB. However, when it goes above total RAM size of 2GB, the system may hang, as there is no place in the RAM to keep the data.
* tmpfs will not grow dynamically. It would not allow you to write more than the size you’ve specified while mounting the tmpfs. So, you don’t need to worry about controlling the process that writes the data to make sure tmpfs doesn’t go above the specified limit. It may give errors similar to “No space left on device”.
* tmpfs uses swap.
* ramfs does not use swap.
4. Disadvantages of ramfs and tmpfs
Since both ramfs and tmpfs is writing to the system RAM, it would get deleted once the system gets rebooted, or crashed. So, you should write a process to pick up the data from ramfs/tmpfs to disk in periodic intervals. You can also write a process to write down the data from ramfs/tmpfs to disk while the system is shutting down. But, this will not help you in the time of system crash.
Table: Comparison of ramfs and tmpfs Experimentation tmpfs ramfs
Fill maximum space and continue writing Will display error Will continue writing
Fixed Size Yes No
Uses Swap Yes No
Volatile Storage Yes Yes
If you want your process to write faster, opting for tmpfs is a better choice with precautions about the system crash.
ramfs/rootfs/initramfs 小结
什么是ramfs
Ramfs是一个非常简单的文件系统,将Linux的磁盘缓存机制(页面缓存和目录项缓存)作为一个动态可调整大小的RAM文件系统。
通常Linux会将所有文件缓存在内存中,从文件系统挂载的块设备读取的数据页会被保留,以防再次需要,但标记为可释放,以便虚拟内存系统在需要内存时可以释放。类似地,写入文件的数据一旦写入存储设备就被标记为可释放,但为了缓存目的会保留,直到虚拟内存系统重新分配内存。目录项缓存也是类似的机制,这样极大地加快了对目录的访问速度。
使用ramfs时由于没有存储设备,在写入ramfs的文件会像往常一样分配目录项和页面缓存,但没有地方可以写入。这意味着这些页面永远不会被标记为可释放,因此在虚拟内存系统寻找内存进行回收时无法释放这些页面。
实现ramfs所需的代码量非常小,因为所有工作都是由现有的Linux缓存基础设施完成的。基本上,你是将磁盘缓存挂载为一个文件系统。
ram和ram disk
“ram disk”已经过时了,它是将RAM区域用作文件系统的存储创建了一个固定大小的块设备,使用ram disk需要将内存从虚拟块设备复制到页面缓存,以及创建和销毁dentries。此外,它还需要一个文件系统驱动程序(比如ext2)来格式化和解释数据。
与ramfs相比,这种方法浪费了内存,为CPU带来了不必要的工作,并且污染了CPU缓存。更重要的是,ramfs正在做的所有工作无论如何都必须发生,因为所有文件访问都经过页面和dentry缓存。RAM磁盘只是多余的,ramfs在内部要简单得多,另一个ramdisk过时的原因是,引入了回环设备,提供了一种更灵活和方便的方式来创建合成块设备,现在是从文件而不是从内存块中创建。
ramfs和tmpfs
ramfs有一个缺点是当不断向内存写入数据,直到填满所有内存,但是虚拟内存无法释放,因为虚拟内存认为文件应该写入存储设备(而不是交换空间),但ramfs没有任何存储设备。
为了解决这个问题,创建了一个ramfs衍生版本称为tmpfs,它增加了大小限制,并具有将数据写入交换空间的能力。普通用户可以被允许对tmpfs挂载点进行写访问。
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 83G 36G 46G 44% /
devtmpfs 32G 0 32G 0% /dev
tmpfs 32G 880K 32G 1% /dev/shm
tmpfs 32G 3.2G 29G 11% /run
tmpfs 32G 0 32G 0% /sys/fs/cgroup
/dev/vda1 453M 138M 288M 33% /boot
/dev/mapper/vg01-freeoa 200G 143G 58G 72% /freeoa
tmpfs 6.3G 0 6.3G 0% /run/user/0
什么是rootfs
rootfs是ramfs的一个特殊实例(或者如果启用了tmpfs,则是tmpfs),rootfs是无法卸载,原因与无法终止init进程的原因大致相同。
大多数系统只是在rootfs上挂载另一个文件系统并将其忽略。
如果启用了CONFIG_TMPFS,则rootfs将默认使用tmpfs而不是ramfs。要强制使用ramfs,请将“rootfstype=ramfs”添加到内核命令行。
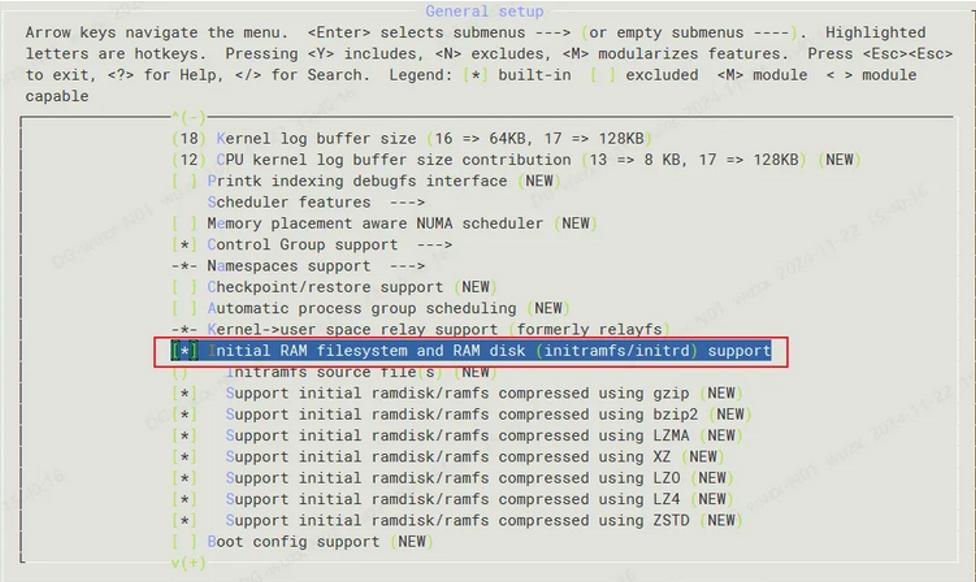
什么是initramfs?
initramfs是Linux内核中的一个gzipped “cpio”格式存档,当内核启动时会被解压到rootfs中。解压后,内核会检查rootfs中是否包含一个名为“init”的文件,如果有的话,内核会将其作为PID 1执行。如果找到了这个init进程,它将负责将系统完全启动,包括定位和挂载真正的根设备。
initramfs的主要作用是在内核启动时提供一个基本的、最小的文件系统,以便内核能够访问所需的驱动程序和工具。它通常比实际的根文件系统更小,因此可以更快地加载到内存中。这使得系统在启动过程中能够更快地完成初始化阶段,提高了系统的响应速度。
initramfs与initrd的不同:
1.initrd始终是一个单独的文件,而initramfs存档被链接到Linux内核映像中。
2.initrd文件是一个gzipped文件系统映像(如ext2,需要内核中内置的驱动程序),initramfs存档是一个gzipped cpio存档(类似于tar)。
3.内核的cpio解压缩代码不仅非常小,而且是__init文本和数据,在引导过程中可以丢弃。
4.initrd运行的程序(称为/init,而不是/init)进行了一些设置然后返回给内核,而来自initramfs的init程序不应该返回给内核。(如果/init需要将控制权交接,它可以用新的根设备覆盖/并执行另一个init程序。)
5.在切换到另一个根设备时,initrd会执行pivot_root然后卸载ramdisk。但initramfs是rootfs:你既不能pivot_root rootfs,也不能卸载它。相反,删除rootfs中的所有内容以释放空间(find -xdev / -exec rm '{}' ';'),用新的根设备覆盖rootfs(cd /newmount; mount --move . /; chroot .),将stdin/stdout/stderr连接到新的/dev/console,并执行新的init。由于这是一个非常挑剔的过程(并涉及在运行命令之前删除命令),klibc软件包引入了一个辅助程序(utils/run_init.c)来为您执行所有这些操作。大多数其他软件包(如busybox)将此命令命名为“switch_root”。
怎么制作initramfs?
dracut是一个广泛使用的工具,主要用于制作initramfs,也就是在系统启动前加载到内存中的一个临时文件系统。这个initramfs起着协助系统正确启动的作用,如果缺少这个环节,系统可能无法正常启动。它通过复制已安装的系统中的设备和文件,并将其与dracut框架进行整合,从而生成Linux启动映像(即initramfs,初始RAM文件系统)。
命令行工具:
dracut [--force] [/PATH/TO/new_image_name] [kernel version]
创建一个带有kernel版本号,为kernel使用的 initramfs 镜像。如果被省略,那么使用实际运行的内核版本号。如果被省略或为空,那么缺省的位置 /boot/initramfs-.img 被使用。
使用dracut命令生成initramfs映像的步骤如下:
输入以下命令以生成一个包含所有已安装的dracut模块和系统工具功能的通用initramfs映像:
dracut
如果你想指定需要添加的驱动模块,可以使用以下命令,例如module1、module2(位于/lib/modules目录下):
dracut --add-drivers module1 module2
若需列出系统上可用的所有dracut模块,可以使用以下命令:
dracut --list-modules
除了dracut,还可以使用mkintrd和mkinitramfs工具。
查看initramfs
lsinitrd /boot/initrd-xxx.img
解压查看
mkdir tmp
cd tmp
cp /boot/initrd-xxx.img initrd-xxx.img.gz
gunzip initrd-xxx.img.gz
cpio -i -d < initrd-xxx.img
Linux Page Cache的工作原理
自从诞生以来,Linux 就被不断完善和普及,目前它已经成为主流通用操作系统之一,使用得非常广泛,下面我们介绍一下 Linux 内核中文件 Cache 管理的机制。本节以 2.6 之后系列内核为基准,主要讲述工作原理、数据结构和算法,不涉及具体代码。
一、操作系统和文件 Cache 管理
操作系统是计算机上最重要的系统软件,它负责管理各种物理资源,并向应用程序提供各种抽象接口以便其使用这些物理资源。从应用程序的角度看,操作系统提供了一个统一的虚拟机,在该虚拟机中没有各种机器的具体细节,只有进程、文件、地址空间以及进程间通信等逻辑概念。这种抽象虚拟机使得应用程序的开发变得相对容易:开发者只需与虚拟机中的各种逻辑对象交互,而不需要了解各种机器的具体细节。此外,这些抽象的逻辑对象使得操作系统能够很容易隔离并保 护各个应用程序。
对于存储设备上的数据,操作系统向应用程序提供的逻辑概念就是"文件"。应用程序要存储或访问数据时,只需读或者写"文件"的一维地址空间即可,而这个地址空间与存储设备上存储块之间的对应关系则由操作系统维护。
在 Linux 操作系统中,当应用程序需要读取文件中的数据时,操作系统先分配一些内存,将数据从存储设备读入到这些内存中,然后再将数据分发给应用程序;当需要往文件中写数据时,操作系统先分配内存接收用户数据,然后再将数据从内存写到磁盘上。文件 Cache 管理指的就是对这些由操作系统分配,并用来存储文件数据的内存的管理。 Cache 管理的优劣通过两个指标衡量:一是 Cache 命中率,Cache 命中时数据可以直接从内存中获取,不再需要访问低速外设,因而可以显著提高性能;二是有效 Cache 的比率,有效 Cache 是指真正会被访问到的 Cache 项,如果有效 Cache 的比率偏低,则相当部分磁盘带宽会被浪费到读取无用 Cache 上,而且无用 Cache 会间接导致系统内存紧张,最后可能会严重影响性能。
Buffer Cache
Buffer cache是指磁盘设备上的raw data指不以文件的方式组织以block为单位在内存中的缓存,早在1975年发布的Unix第六版就有了它的雏形,Linux最开始也只有buffer cache。事实上,page cache是1995年发行的1.3.50版本中才引入的。不同于buffer cache以磁盘的block为单位,page cache是以内存常用的page为单位的,位于虚拟文件系统层VFS与具体的文件系统之间。
在很长一段时间内,buffer cache和page cache在Linux中都是共存的,但是这会存在一个问题:一个磁盘block上的数据,可能既被buffer cache缓存了,又因为它是基于磁盘建立的文件的一部分,也被page cache缓存了,这时一份数据在内存里就有两份拷贝,这显然是对物理内存的一种浪费。更麻烦的是,内核还要负责保持这份数据在buffer cache和page cache中的一致性。所以,现在Linux中已经基本不再使用buffer cache了。
读写操作
CPU如果要访问外部磁盘上的文件,需要首先将这些文件的内容拷贝到内存中,由于硬件的限制,从磁盘到内存的数据传输速度是很慢的,如果现在物理内存有空余,干嘛不用这些空闲内存来缓存一些磁盘的文件内容呢,这部分用作缓存磁盘文件的内存就叫做page cache。
用户进程启动read()系统调用后,内核会首先查看page cache里有没有用户要读取的文件内容,如果有cache hit,那就直接读取,没有的话cache miss再启动I/O操作从磁盘上读取,然后放到page cache中,下次再访问这部分内容的时候,就又可以cache hit,不用忍受磁盘的慢速了相比内存慢几个数量级。
和CPU里的硬件cache是不是很像?两者其实都是利用的局部性原理,只不过硬件cache是CPU缓存内存的数据,而page cache是内存缓存磁盘的数据,这也体现了memory hierarchy分级的思想。相对于磁盘,内存的容量还是很有限的,所以没必要缓存整个文件,只需要当文件的某部分内容真正被访问到时,再将这部分内容调入内存缓存起来就可以了,这种方式叫做demand paging按需调页,把对需求的满足延迟到最后一刻,很实用的。
page cache中那么多的page frames,怎么管理和查找呢?一个address_space结构体管理了一个文件在内存中缓存的所有pages。
这篇文章讲到,mmap映射可以将文件的一部分区域映射到虚拟地址空间的一个VMA,如果有5个进程,每个进程mmap同一个文件两次文件的两个不同部分,那么就有10个VMAs,但address_space只有一个。
每个进程打开一个文件的时候,都会生成一个表示这个文件的struct file,但是文件的struct inode只有一个,inode才是文件的唯一标识,指向address_space的指针就是内嵌在inode结构体中的。在page cache中,每个page都有对应的文件,这个文件就是这个page的owner,address_space将属于同一owner的pages联系起来,将这些pages的操作方法与文件所属的文件系统联系起来。
address_space结构体具体是怎样构成的:
struct address_space {
struct inode *host; /* Owner, either the inode or the block_device */
struct radix_tree_root page_tree; /* Cached pages */
spinlock_t tree_lock; /* page_tree lock */
struct prio_tree_root i_mmap; /* Tree of private and shared mappings */
struct spinlock_t i_mmap_lock; /* Protects @i_mmap */
unsigned long nrpages; /* total number of pages */
struct address_space_operations *a_ops; /* operations table */
...
}
host指向address_space对应文件的inode。
address_space中的page cache之前一直是用radix tree的数据结构组织的,tree_lock是访问这个radix tree的spinlcok现在已换成xarray。
i_mmap是管理address_space所属文件的多个VMAs映射的,用priority search tree的数据结构组织,i_mmap_lock是访问这个priority search tree的spinlcok。
nrpages是address_space中含有的page frames的总数。
a_ops是关于page cache如何与磁盘backing store交互的一系列operations。
address_space中的a_ops定义了关于page和磁盘文件交互的一系列操作,它是由struct address_space_operations包含的一组函数指针组成的,其中最重要的就是readpage()和writepage()。
struct address_space_operations {
int (*writepage)(struct page *page, struct writeback_control *wbc);
int (*readpage)(struct file *, struct page *);
/* Set a page dirty. Return true if this dirtied it */
int (*set_page_dirty)(struct page *page);
int (*releasepage) (struct page *, gfp_t);
void (*freepage)(struct page *);
...
}
之所以使用函数指针的方式,是因为不同的文件系统对此的实现会有所不同,比如在ext3中,page-->mapping-->a_ops-->writepage调用的就是ext3_writeback_writepage()。
struct address_space_operations ext3_writeback_aops = {
.readpage = ext3_readpage,
.writepage = ext3_writeback_writepage,
.releasepage = ext3_releasepage,
...
}
readpage()会阻塞直到内核往用户buffer里填充满了请求的字节数,如果遇到page cache miss,那要等的时间就比较长了取决于磁盘I/O的速度。既然访问一次磁盘那么不容易,那为什么不一次多预读几个page大小的内容过来呢?是否采用预读readahead要看对文件的访问是连续的还是随机的,如果是连续访问,自然会对性能带来提升,如果是随机访问,预读则是既浪费磁盘I/O带宽,又浪费物理内存。
那内核怎么能预知进程接下来对文件的访问是不是连续的呢?看起来只有进程主动告知了,可以采用的方法有madvise()和posix_favise(),前者主要配合基于文件的mmap映射使用。advise如果是NORMAL,那内核会做适量的预读;如果是RANDOM,那内核就不做预读;如果是SEQUENTIAL,那内核会做大量的预读。
预读的page数被称作预读窗口有点像TCP里的滑动窗口,其大小直接影响预读的优化效果。进程的advise毕竟只是建议,内核在运行过程中会动态地调节预读窗口的大小,如果内核发现一个进程一直使用预读的数据,它就会增加预读窗口,它的目标或者说KPI吧就是保证在预读窗口中尽可能高的命中率也就是预读的内容后续会被实际使用到。
Page cache缓存最近使用的磁盘数据,利用的是“时间局部性”原理,依据是最近访问到的数据很可能接下来再访问到,而预读磁盘的数据放入page cache,利用的是“空间局部性”原理,依据是数据往往是连续访问的。
Page cache这种内核提供的缓存机制并不是强制使用的,如果进程在open()一个文件的时候指定flags为O_DIRECT,那进程和这个文件的数据交互就直接在用户提供的buffer和磁盘之间进行,page cache就被bypass了,借用硬件cache的术语就是uncachable,这种文件访问方式被称为direct I/O,适用于用户使用自己设备提供的缓存机制的场景,比如某些数据库应用。
回写与同步
Page cache毕竟是为了提高性能占用的物理内存,随着越来越多的磁盘数据被缓存到内存中,page cache也变得越来越大,如果一些重要的任务需要被page cache占用的内存,内核将回收page cache以支持这些需求。
以elf文件为例,一个elf镜像文件通常由text(code)和data组成,这两部分的属性是不同的,text是只读的,调入内存后不会被修改,page cache里的内容和磁盘上的文件内容始终是一致的,回收的时候只要将对应的所有PTEs的P位和PFN清0,直接丢弃就可以了, 不需要和磁盘文件同步,这种page cache被称为discardable的。
而data是可读写的,当data对应的page被修改后,硬件会将PTE中的Dirty位置1参考这篇文章,Linux通过SetPageDirty(page)设置这个page对应的struct page的flags为PG_Dirty参考这篇文章,而后将PTE中的Dirty位清0。在之后的某个时间点,这些修改过的page里的内容需要同步到外部的磁盘文件,这一过程就是page write back,和硬件cache的write back原理是一样的,区别仅在于CPU的cache是由硬件维护一致性,而page cache需要由软件来维护一致性,这种page cache被称为syncable的。
何时会触发page的write back
分下面几种情况:
1、从空间的层面,当系统中"dirty"的内存大于某个阈值时。该阈值以在总共的“可用内存”中的占比"dirty_background_ratio"默认为10%或者绝对的字节数"dirty_background_bytes"给出,谁最后被写入就以谁为准,另一个的值随即变为0代表失效。这里所谓的“可用内存”,包括了free pages和reclaimable pages。
此外,还有"dirty_ratio"默认为20%和"dirty_bytes",它们的意思是当"dirty"的内存达到这个数量屋里太脏,进程自己都看不过去了,宁愿停下手头的write操作被阻塞,先去把这些"dirty"的writeback了把屋里打扫干净。而如果"dirty"的程度介于这个值和"background"的值之间10% - 20%,就交给后面要介绍的专门负责writeback的background线程去做就好了专职的清洁工。
2、从时间的层面,即周期性的扫描扫描间隔用dirty_writeback_ interval表示,以毫秒为单位,发现存在最近一次更新时间超过某个阈值的pages该阈值用dirty_expire_interval表示, 以毫秒为单位。
3、用户主动发起sync()/msync()/fsync()调用时。
可通过/proc/sys/vm文件夹查看或修改以上提到的几个参数:

centisecs是0.01s,因此上图所示系统的的dirty_background_ratio是10%,dirty_writeback_ interval是5s,dirty_expire_interval是30s。
来对比下硬件cache的write back机制。对于硬件cache,write back会在两种情况触发:
内存有新的内容需要换入cache时,替换掉一个老的cache line。你说为什么page cache不也这样操作,而是要周期性的扫描呢?
替换掉一个cache line对CPU来说是很容易的,直接靠硬件电路完成,而替换page cache的操作本身也是需要消耗内存的比如函数调用的堆栈开销,如果这个外部backing store是个网络上的设备,那么还需要先建立socket之类的,才能通过网络传输完成write back,那这内存开销就更大了。所以对于page cache,必须未雨绸缪,不能等内存都快耗光了才进行write back。
执行线程
2.4内核中用的是一个叫bdflush的线程来专门负责writeback操作,因为磁盘I/O操作很慢,而现代系统通常具备多个块设备比如多个disk spindles,如果bdflush在其中一个块设备上等待I/O操作的完成,可能会需要很长的时间,此时其他块设备还闲着呢,这时单线程模式的bdflush就成为了影响性能的瓶颈。而且,bdflush是没有周期扫描功能的,因此它需要配合kupdated线程一起使用。
于是在2.6内核中,bdflush和它的好搭档kupdated一起被pdflushpage dirty flush取代了。pdflush是一组线程,根据块设备的I/O负载情况,数量从最少2个到最多8个不等。如果1秒内都没有空闲的pdflush线程可用,内核将创建一个新的pdflush线程,反之,如果某个pdflush线程的空闲时间已经超过1秒,则该线程将被销毁。一个块设备可能有多个可以传输数据的队列,为了避免在队列上的拥塞congestion,pdflush线程会动态的选择系统中相对空闲的队列。
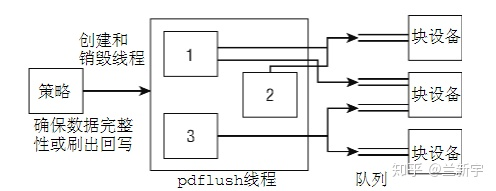
这种方法在理论上是很优秀的,然而现实的情况是外部I/O和CPU的速度差异巨大,但I/O系统的其他部分并没有都使用拥塞控制,因此pdflush单独使用复杂的拥塞算法的效果并不明显,可以说是“独木难支”。于是在更后来的内核实现中2.6.32版本,干脆化繁为简,直接一个块设备对应一个thread,这种内核线程被称为flusher threads。
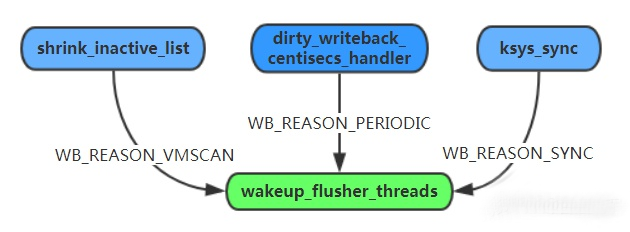
无论是内核周期性扫描,还是用户手动触发,flusher threads的write back都是间隔一段时间才进行的,如果在这段时间内系统掉电了power failure,那还没来得及write back的数据修改就面临丢失的风险,这是page cache机制存在的一个缺点。
前面介绍的O_DIRECT设置并不能解决这个问题,O_DIRECT只是绕过了page cache,但它并不等待数据真正写到了磁盘上。open()中flags参数使用O_SYNC才能保证writepage()会等到数据可靠的写入磁盘后再返回,适用于某些不容许数据丢失的关键应用。O_SYNC模式下可以使用或者不使用page cache.如果使用page cache,则相当于硬件cache的write through机制。
下面分别介绍文件 Cache 管理在 Linux 操作系统中的地位和作用、相关的数据结构、预读和替换、相关 API 及其实现。
二、文件 Cache 的地位和作用
文件 Cache 是文件数据在内存中的副本,因此文件 Cache 管理与内存管理系统和文件系统都相关:一方面文件 Cache 作为物理内存的一部分,需要参与物理内存的分配回收过程,另一方面文件 Cache 中的数据来源于存储设备上的文件,需要通过文件系统与存储设备进行读写交互。从操作系统的角度考虑,文件 Cache 可以看做是内存管理系统与文件系统之间的联系纽带。因此,文件 Cache 管理是操作系统的一个重要组成部分,它的性能直接影响着文件系统和内存管理系统的性能。
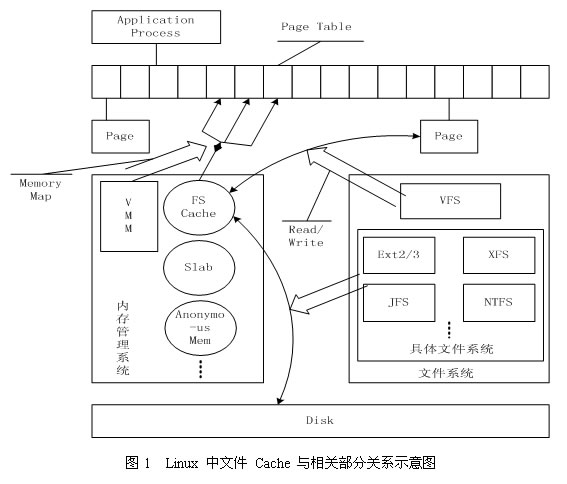
图1描述了 Linux 操作系统中文件 Cache 管理与内存管理以及文件系统的关系示意图。从图中可以看到,在 Linux 中,具体文件系统,如 ext2/ext3、jfs、ntfs 等,负责在文件 Cache和存储设备之间交换 数据,位于具体文件系统之上的虚拟文件系统VFS负责在应用程序和文件 Cache 之间通过 read/write 等接口交换 数 据,而内存管理系统负责文件 Cache 的分配和回收,同时虚拟内存管理系统(VMM)则允许应用程序和文件 Cache 之间通过 memory map的方式交换数据。可见,在 Linux 系统中,文件 Cache 是内存管理系统、文件系统以及应用程序之间的一个联系枢纽。
文件 Cache 相关数据结构
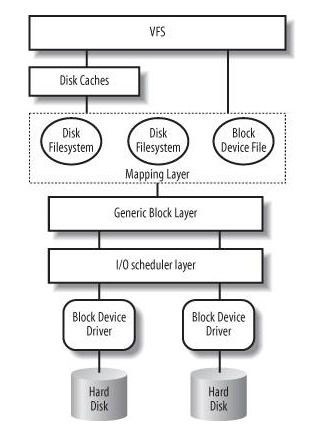
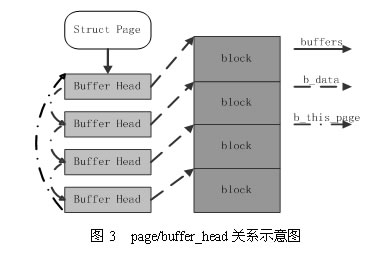
在 Linux 的实现中,文件 Cache 分为两个层面,一是 Page Cache,另一个 Buffer Cache,每一个 Page Cache 包含若干 Buffer Cache。内存管理系统和 VFS 只与 Page Cache 交互,内存管理系统负责维护每项 Page Cache 的分配和回收,同时在使用 memory map 方式访问时负责建立映射;VFS 负责 Page Cache 与用户空间的数据交换。而具体文件系统则一般只与 Buffer Cache 交互,它们负责在外围存储设备和 Buffer Cache 之间交换数据。Page Cache、Buffer Cache、文件以及磁盘之间的关系如图 2 所示,Page 结构和 buffer_head 数据结构的关系如图 3 所示。在上述两个图中,假定了 Page 的大小是 4K,磁盘块的大小是 1K。本文所讲述的,主要是指对 Page Cache 的管理。
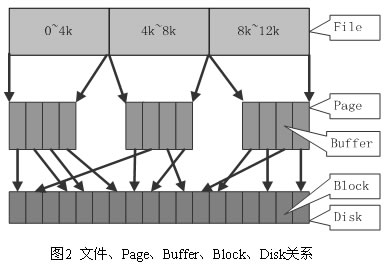
在 Linux 内核中,文件的每个数据块最多只能对应一个 Page Cache 项,它通过两个数据结构来管理这些 Cache 项,一个是 radix tree,另一个是双向链表。Radix tree 是一种搜索树,Linux 内核利用这个数据结构来通过文件内偏移快速定位 Cache 项,图 4 是 radix tree的一个示意图,该 radix tree 的分叉为4(22),树高为4,用来快速定位8位文件内偏移。Linux(2.6.7) 内核中的分叉为 64(26),树高为 6(64位系统)或者 11(32位系统),用来快速定位 32 位或者 64 位偏移,radix tree 中的每一个叶子节点指向文件内相应偏移所对应的Cache项。
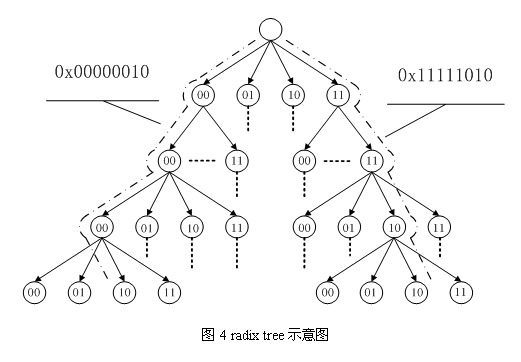
下面是一个Radix Tree实例:
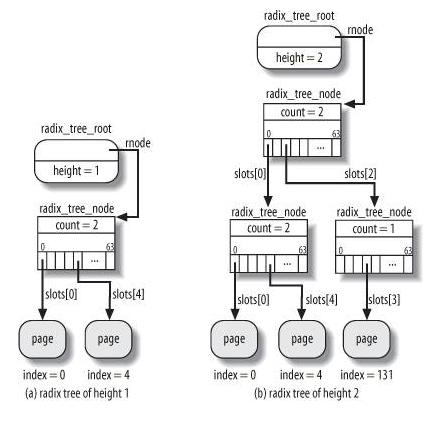
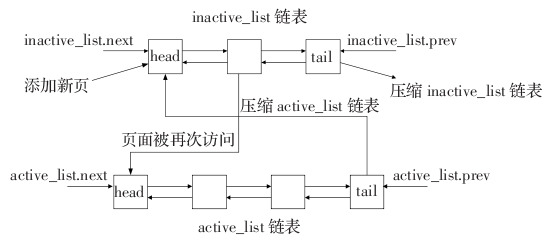
另一个数据结构是双向链表,Linux内核为每一片物理内存区域(zone)维护active_list和inactive_list两个双向 链表,这两个list主要用来实现物理内存的回收。这两个链表上除了文件Cache之外,还包括其它匿名(Anonymous)内存,如进程堆栈等。
文件Cache的预读和替换
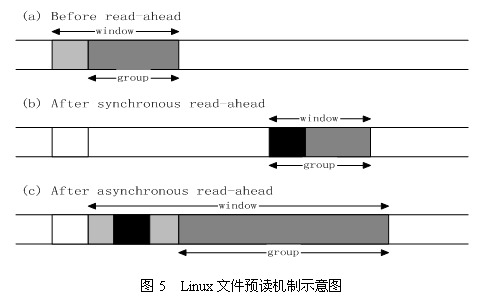
Linux内核中文件预读算法的具体过程是这样的:对于每个文件的第一个读请求,系统读入所请求的页面并读入紧随其后的少数几个页面(不少于一个页面,通常是三个页面),这时的预读称为同步预读。对于第二次读请求,如果所读页面不在Cache中,即不在前次预读的group中,则表明文件访问不是顺序访问,系统继续采用同步预读;如果所读页面在Cache中,则表明前次预读命中,操作系统把预读group扩大一倍,并让底层文件系统读入group中剩下尚不在Cache中的文件数据块,这时的预读称为异步预读。无论第二次读请求是否命中,系统都要更新当前预读group的大小。此外,系统中定义了一个window,它包括前一次预读的group和本次预读的group。任何接下来的读请求都会处于两种情况之一:第一种情况是所请求的页面处于预读window中,这时继续进行异步预读并更新相应的window和group;第二种情况是所请求的页面处于预读window之外,这时系统就要进行同步预读并重置相应的window和group。图5是Linux内核预读机制的一个示意图,其中a是某次读操作之前的情况,b是读操作所请求页面不在window中的情况,而c是读操作所请求页面在window中的情况。
Linux内核中文件Cache替换的具体过程是这样的:刚刚分配的Cache项链入到inactive_list头部,并将其状态设置为 active,当内存不够需要回收Cache时,系统首先从尾部开始反向扫描active_list并将状态不是referenced的项链入到 inactive_list的头部,然后系统反向扫描inactive_list,如果所扫描的项的处于合适的状态就回收该项,直到回收了足够数目的 Cache项。
文件Cache相关API及其实现
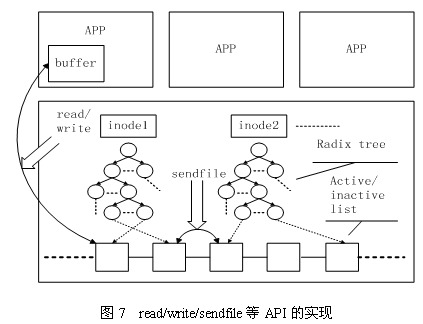
Linux内核中与文件Cache操作相关的API有很多,按其使用方式可以分成两类:一类是以拷贝方式操作的相关接口,如read/write/sendfile等,其中sendfile在2.6系列的内核中已经不再支持;另一类是以地址映射方式操作的相关接口,如 mmap等。
第一种类型的API在不同文件的Cache之间或者Cache与应用程序所提供的用户空间buffer之间拷贝数据,其实现原理如图7所示。
第二种类型的API将Cache项映射到用户空间,使得应用程序可以像使用内存指针一样访问文件,Memory map访问Cache的方式在内核中是采用请求页面机制实现的,其工作过程如图8所示。
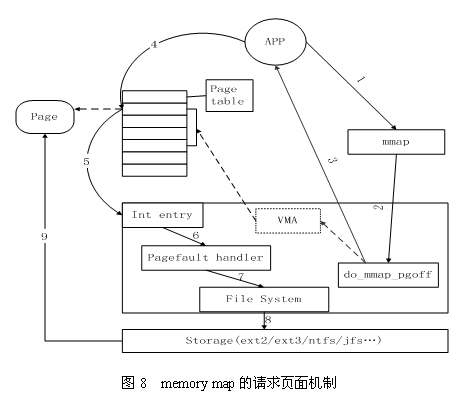
首先,应用程序调用mmap图中1,陷入到内核中后调用do_mmap_pgoff图中2。该函数从应用程序的地址空间中分配一段区域作为映射的内存地址,并使用一个VMAvm_area_struct结构代表该区域,之后就返回到应用程序图中3。当应用程序访问mmap所返回的地址指针时图中4,由于虚实映射尚未建立,会触发缺页中断图中5。之后系统会调用缺页中断处理函数图中6,在缺页中断处理函数中,内核通过 相应区域的VMA结构判断出该区域属于文件映射,于是调用具体文件系统的接口读入相应的Page Cache项图中7、8、9,并填写相应的虚实映射表。经过这些步骤之后,应用程序就可以正常访问相应的内存区域了。
小结
文件Cache管理是Linux操作系统的一个重要组成部分,同时也是研究领域一个很热门的研究方向。目前,Linux内核在这个方面的工作集中在开发更有效的Cache替换算法上,如LIRS(其变种ClockPro)、ARC等。
三、Linux Page Cache调优在Kafka中的应用
业务快速增长,每天需要处理万亿记录级数据量时。在读写数据方面,Kafka 集群的压力将变得巨大,而磁盘 IO 成为了 Kafka 集群最大的性能瓶颈。当出现入流量突增或者出流量突增情况,磁盘 IO 持续处于被打满状态,导致无法处理新的读写请求,甚至造成部分broker节点雪崩而影响集群的稳定。这严重的影响了集群的稳定,从而影响业务的稳定运行。对此需要对Linux操作系统的Page Cache参数进行优化。
Page Cache是针对文件系统的缓存,通过将磁盘中的文件数据缓存到内存中,从而减少磁盘I/O操作提高性能。对磁盘的数据进行缓存从而提高性能主要是基于两个因素:
磁盘访问的速度比内存慢好几个数量级毫秒和纳秒的差距;
被访问过的数据,有很大概率会被再次访问。
文件读写流程如下所示:
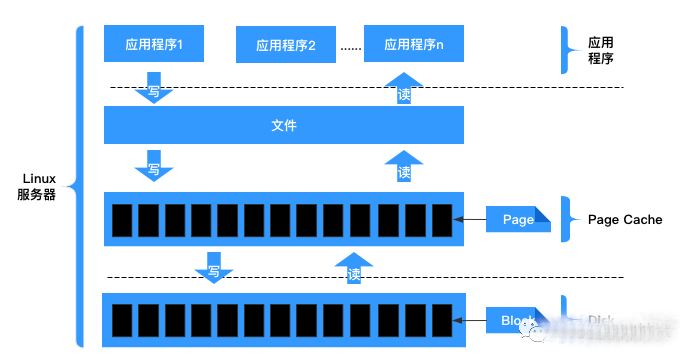
当内核发起一个读请求时例如进程发起read()请求,首先会检查请求的数据是否缓存到了Page Cache中。如果有,那么直接从内存中读取,不需要访问磁盘,这被称为cache命中cache hit;如果没有,即cache未命中cache miss,就必须从磁盘中读取数据。然后内核将读取的数据缓存到cache中,这样后续的读请求就可以命中cache了。
当内核发起一个写请求时例如进程发起write()请求,同样是直接往cache中写入,后备存储中的内容不会直接更新当服务器出现断电关机时,存在数据丢失风险。内核会将被写入的page标记为dirty,并将其加入dirty list中。内核会周期性地将dirty list中的page写回到磁盘上,从而使磁盘上的数据和内存中缓存的数据一致。
当满足以下两个条件之一将触发脏数据刷新到磁盘操作:
数据存在的时间超过了dirty_expire_centisecs默认300厘秒,即30秒时间;
脏数据所占内存 > dirty_background_ratio,也就是说当脏数据所占用的内存占总内存的比例超过dirty_background_ratio默认10,即系统内存的10%的时候会触发pdflush刷新脏数据。
page可以只缓存一个文件部分的内容,不需要把整个文件都缓存进来。
Page Cache缓存查看工具
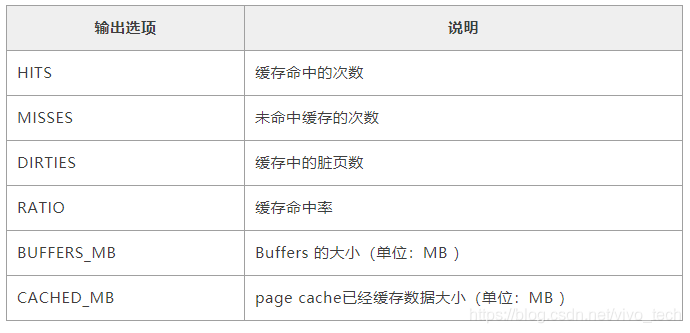
如何查看缓存命中率呢?在此可以借助一个缓存命中率查看工具 cachestat。
输出内容说明
回收Page Cache
执行脚本:echo 1 > /proc/sys/vm/drop_caches 这里可能需要等待一会,因为有应用程序正在写数据。缓存回收后,正常情况下,buff/cache应该是0的,不为0是因为有数据正在不停的写入。
四、参数调优
注意:不同硬件配置的服务器可能效果不同,所以具体的参数值设置需要考虑集群硬件配置。考虑的因素主要包括:CPU核数、内存大小、硬盘类型、网络带宽等。
1、查看Page Cache参数
执行命令 sysctl -a|grep dirty
2、操作系统Page Cache相关参数默认值
vm.dirty_background_bytes = 0 # 和参数vm.dirty_background_ratio实现相同功能,但两个参数只会有其中一个生效,表示脏页大小达到多少字节后开始触发刷磁盘
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0 # 和参数vm.dirty_ratio实现相同功能,但两个参数只会有其中一个生效,表示脏页达到多少字节后停止接收写请求,开始触发刷磁盘
vm.dirty_ratio = 20
vm.dirty_expire_centisecs = 3000 #这里表示30秒时间,单位:厘秒
vm.dirty_writeback_centisecs = 500 #这里表示5秒时间,单位:厘秒
3、如果系统中cached大量数据可能存在的问题
缓存的数据越多,丢数据的风险越大。
会定期出现IO峰值,这个峰值时间会较长,在这期间所有新的写IO性能会很差极端情况直接被hang住。
后一个问题对写负载很高的应用会产生很大影响。
4、如何调整内核参数来优化IO性能?
1)vm.dirty_background_ratio参数优化
当cached中缓存当数据占总内存的比例达到这个参数设定的值时将触发刷磁盘操作。把这个参数适当调小,这样可以把原来一个大的IO刷盘操作变为多个小的IO刷盘操作,从而把IO写峰值削平。对于内存很大和磁盘性能比较差的服务器,应该把这个值设置的小一点。
#设置方法1:
sysctl -w vm.dirty_background_ratio=1(临时生效,重启服务器后失效)
#设置方法2(永久生效):
echo vm.dirty_background_ratio=1 >> /etc/sysctl.conf
sysctl -p /etc/sysctl.conf
#设置方法3(永久生效):
#当然你还可以在/etc/sysctl.d/目录下创建一个自己的参数优化文件,把系统优化参数进行归类存放,然后设置生效,如:
touch /etc/sysctl.d/kafka-optimization.conf
echo vm.dirty_background_ratio=1 >> /etc/sysctl.d/kafka-optimization.conf
sysctl --system
2)vm.dirty_ratio参数优化
对于写压力特别大的,建议把这个参数适当调大;对于写压力小的可以适当调小;如果cached的数据所占比例这里是占总内存的比例超过这个设置,系统会停止所有的应用层的IO写操作,等待刷完数据后恢复IO。所以万一触发了系统的这个操作,对于应用来说影响非常大的。
3)vm.dirty_expire_centisecs参数优化
这个参数会和参数vm.dirty_background_ratio一起来作用,一个表示大小比例,一个表示时间;即满足其中任何一个的条件都达到刷盘的条件。
为什么要这么设计呢?我们来看一下以下场景:
如果只有参数 vm.dirty_background_ratio ,也就是说cache中的数据需要超过这个阀值才会满足刷磁盘的条件;
如果数据一直没有达到这个阀值,那相当于cache中的数据就永远无法持久化到磁盘,这种情况下,一旦服务器重启,那么cache中的数据必然丢失。
结合以上情况,所以添加了一个数据过期时间参数。当数据量没有达到阀值,但是达到了我们设定的过期时间,同样可以实现数据刷盘。这样可以有效的解决上述存在的问题,其实这种设计在绝大部分框架中都有。
4)vm.dirty_writeback_centisecs参数优化
理论上调小这个参数,可以提高刷磁盘的频率,从而尽快把脏数据刷新到磁盘上。但一定要保证间隔时间内一定可以让数据刷盘完成。
5)vm.swappiness参数优化
禁用swap空间,设置vm.swappiness=0
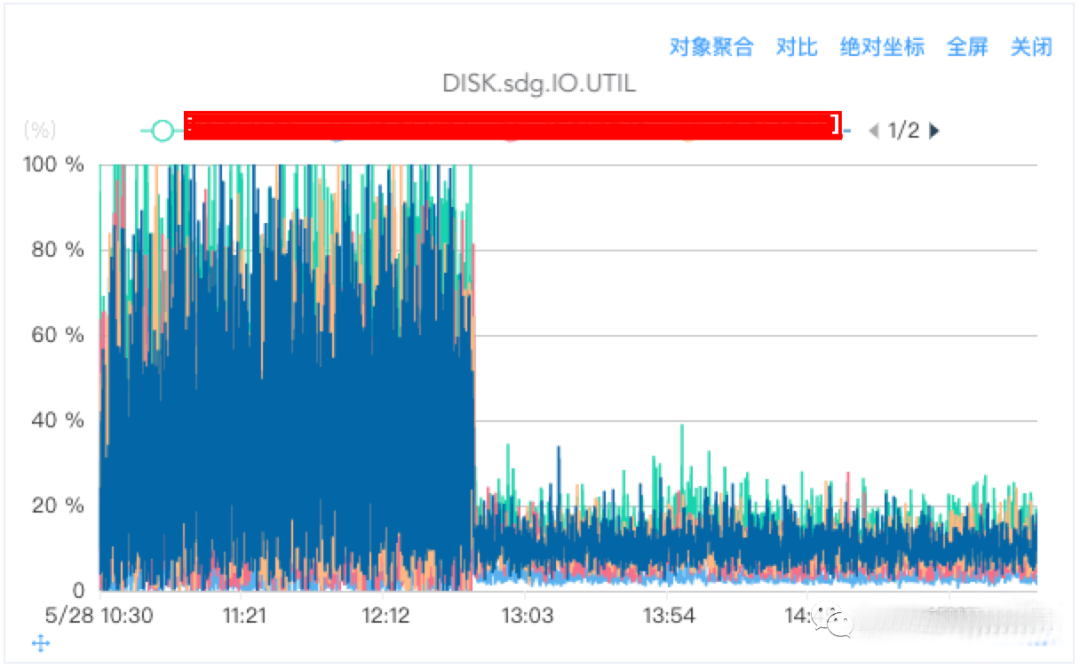
磁盘IO UTIL对比
从下图可以看出,优化前IO出现大量突刺,波动非常大,优化后IO使用率更加平滑。
小结
这里不同机型,不同硬件配置可能最终优化效果也不一样,但是参数变化的趋势应该是一致的。
1)当vm.dirty_background_ratio、vm.dirty_expire_centisecs变大时
出入流量抖动变大,出现大量突刺;
IO抖动变大,出现大量突刺,磁盘有连续打满的情况;
出入流量平均大小不受影响;
2)当vm.dirty_background_ratio、vm.dirty_expire_centisecs变小时
出入流量抖动变小,趋于平滑稳定,无突刺;
磁盘IO抖动变小,无突刺,磁盘IO无打满情况;
出入流量平均大小不受影响;
3)当vm.dirty_ratio变小低于10
出入流量隔一段时间出现一个明显的波谷;这是因为cache数据量超过vm.dirty_ratio设定的值将阻塞写请求,进行刷盘操作。
4)当vm.dirty_ratio变大时高于40,出入流量无明显的波谷,流量平滑;
5)当以下三个参数分别为对应值时,出入流量非常平滑,趋于一条直线;
vm.dirty_background_ratio=1
vm.dirty_ratio=80
vm.dirty_expire_centisecs=1000
五、buffer cache和page cache的区别
Page cache和buffer cache到底有什么区别呢?很多时候我们不知道系统在做IO操作的时候到底是走了page cache还是buffer cache?其实,buffer cache和page cache是Linux中两个比较简单的概念,在此对其简单说明:
Page cache是vfs文件系统层的cache,例如 对于一个ext3文件系统而言,每个文件都会有一棵radix树管理文件的缓存页,这些被管理的缓存页被称之为page cache,所以page cache是针对文件系统而言的。例如ext3文件系统的页缓存就是page cache。Buffer cache是针对块存储设备的,每个设备都会有一棵radix树管理数据缓存块,这些缓存块被称之为buffer cache。通常对于ext3文件系统而言,page cache的大小为4KB,所以ext3每次操作的数据块大小都是4KB的整数倍。Buffer cache的缓存块大小通常由块设备的大小来决定,取值范围在512B~4KB之间,取块设备大小的最大公约数。
Linux中Buffer cache性能问题一探究竟
1)、Buffer cache的作用
为了提高磁盘设备的IO性能,我们采用内存作为磁盘设备的cache。用户操作磁盘设备的时候,首先将数据写入内存,然后再将内存中的脏数据定时刷新到磁盘。这个用作磁盘数据缓存的内存就是所谓的buffer cache。在以前的Linux系统中,有很完善的buffer cache软件层,专门负责磁盘数据的缓存。在磁盘设备的上层往往会架构文件系统,为了提高文件系统的性能,VFS层同样会提供文件系统级别的page cache。这样就导致系统中存在两个cache,并且重叠在一起,显得没有必要和冗余。为了解决这个问题,在现有的Linux系统中对buffer cache软件层进行了弱化,并且和page cache进行了整合。Buffer cache和page cache都采用radix tree进行维护,只有当访问裸设备的时候才会使用buffer cache,正常走文件系统的IO不会使用buffer cache。
我们知道ext3文件系统的page cache都是以page页大小为单位的,那么buffer cache中缓存块大小究竟是多大呢?其对性能影响如何呢?这两天我在Linux-2.6.23平台上针对这个问题做了很多实验,得到了一些数据结果,并从源代码分析中得到设置缓存块大小的方法。在此对这个buffer cache的性能问题进行分析说明,供大家讨论。
2)、Buffer cache的性能问题
2.1 测试实验
首先让我们来做一个实验,在Linux-2.6.23平台上,采用dd工具对一个块设备进行顺序写操作,可以采用如下的命令格式:
dd if=/dev/zero of=/dev/sda2 bs=<request_size> count=100
采用该命令在不同buffer cache块(blk_size)大小配置的情况下测试不同请求大小(req_size)的IO性能,可以得到如下表所示的测试数据:

表:不同buffer cache块大小配置下的吞吐量
将表中的数据做成性能对比图,如下图所示:
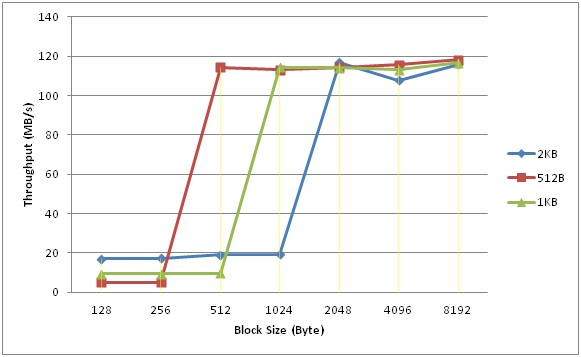
从图中可以看出,在请求大小小于Cache块大小的时候,Cache块越大,IO性能越高;但是,请求大小大于Cache块大小之后,性能都有明显的飞跃。
例如,当buffer cache块大小被配置成2KB时,小于2KB的块性能基本都在19MB/s左右;当buffer cache块大小被配置成512B时,小于512B的写性能都保持在5MB/s;当buffer cache块大小被配置成1024B时,小于1KB的写性能基本都保持在9.5MB/s上下。这就说明对于小于cache块大小的small_write,buffer cache越大,其性能会越好;反之,性能越差,这就是buffer cache的作用。
观察发现一旦请求大小大于等于cache块大小之后,性能急剧提升,由于测试工具的IO压力足够大,能够一下子将磁盘性能耗尽。这是为什么呢?其实,当请求块比较小时,对于cache块而言是“局部操作”,这种“局部操作”会引入buffer cache的数据读操作,并且数据读操作和用户写操作存在顺序关系,这就极大的影响了IO的写性能。因此,当请求大小大于cache块时,并且能够和Cache块对齐时,就能够充分利用磁盘的IO带宽,所以就产生了上图中所示的性能飞跃。
看到上图中的测试结果之后,我们就会想在实际应用中,我们该如何选择buffer cache的块大小?如果请求大小是512B时,显然将buffer cache块设置成512比较合适;如果请求大小是256B时,显然将buffer cache块设置成2KB比较合适。所以,个人认为块大小的设置还需要根据实际的应用来决定,不同的应用需要设置不同的块大小,这样才能使整体性能达到最佳。
2.2 Buffer cache块大小
Linux系统在创建块设备的时候是如何设置块大小的呢?这里面涉及到Linux针对块大小设置的一个小小算法。在此结合源码对Linux的这个方法加以说明。
总体来说,Linux决定buffer cache块大小采用的是“最大块大小”的设计思想。Linux根据块设备容量决定buffer cache的块大小,并且将值域限定在512B和4KB之间。当然这个值域内的元素不是连续的,并且都是2的幂。在这个值域的基础上取块设备大小的最大公约数,这个值就是buffer cache的块大小。这种算法的指导思想就是buffer cache的块越大越好,因此能够取2KB就不会选择512B。Linux中算法实现代码如下所示:
void bd_set_size(struct block_device *bdev, loff_t size){
unsigned bsize = bdev_logical_block_size(bdev);
bdev->bd_inode->i_size = size; //size为块设备大小
while (bsize < PAGE_CACHE_SIZE) { //bsize不能大于Page size
if (size & bsize)
break;
bsize <<= 1; //bsize只能取2的幂
}
bdev->bd_block_size = bsize;
/* 设置buffer cache块大小 */
bdev->bd_inode->i_blkbits = blksize_bits(bsize);
}
3)、小结
本文对buffer cache的性能问题进行了分析,通过实验发现当请求块比较小时,buffer cache块大小对IO性能有很大的影响。Linux根据块设备的容量采用“最大cache块”的思想决定buffer cache的块大小。在实际应用中,我们应该根据应用特征,通过实际测试来决定buffer cache块大小。
在内存页中,有一种叫专门用途的页面叫“缓冲区页”,专门用来放块缓冲区。而每个块缓存区由两部分组成:缓冲区首部(用数据结构buffer_head表示)及真正的缓冲区内容(即所存储的数据,这些数据就放在刚刚说到的缓冲区页中)。在缓冲区首部中,有一个指向数据的指针和一个缓冲区长度的字段。当一个块被调入到内存中,它要被存储在一个缓冲区中。每个缓冲区与一个块对应,它相当于磁盘块在内存中的表示。而文件在内存中由file结构体表示,而磁盘块在内存中是由缓冲区来进行表示的。由于内核处理块时需要一些信息,如块属于哪个设备与块对应于哪个缓冲区。所以每个缓冲区都有一个缓冲区描述符,称为buffer_head,它包含了内核操作缓冲区所需要的全部信息。
struct buffer_head {
unsigned long b_state; /* buffer state bitmap (see above) *缓冲区的状态标志/
struct buffer_head *b_this_page;/* circular list of page's buffers *页面中缓冲区/(一般一个页面会有多个块组成,一个页面中的块是以一个循环链表组成在一起的,该字段指向下一个缓冲区首部的地址。)
struct page *b_page; /* the page this bh is mapped to *存储缓冲区的页面/(指向拥有该块的页面的页面描述符)
sector_t b_blocknr; /* start block number *逻辑块号/
size_t b_size; /* size of mapping *块大小/
char *b_data; /* pointer to data within the page *指向该块对应的数据的指针/
struct block_device *b_bdev; //对应的块设备(通常是指磁盘或者是分区)
bh_end_io_t *b_end_io; /* I/O completion */
void *b_private; /* reserved for b_end_io *I/O完成的方法/
struct list_head b_assoc_buffers; /* associated with another mapping */
struct address_space *b_assoc_map; /* mapping this buffer is associated with *缓冲区对应的映射,即address_space/
atomic_t b_count; /* users using this buffer_head *表示缓冲区的使用计数/
};
buffer_head中有两个字段表示块的磁盘地址:b_bdev表示包含该块的块设备(通常是磁盘或者分区)及b_blocknr存放逻辑块号,也就是块在磁盘或分区中的编号,b_data字段表示块缓冲区数据在缓冲区页中的位置。b_state存放缓冲区的状态,例如BH_uptodate(缓冲区包含有效数据时候被置位),Bh_Dirty(缓冲区脏就置位),BH_New(如果相应的块刚被分配而还没被访问过就置位)。
只要内核必须单独访问一个块,就要涉及存放块缓冲区中的缓冲区页,并检查相应的buffer_head。
一个应用实例:如果虚拟文件系统要读1024个字节的inode块,内核并不是只分配一个单独的缓冲区,而是必须分配一整个页,从而存放4个缓冲区(假设页的大小为4k),这些缓冲区将存放块设备上相邻的四块数据。
它们之间的关系如下:(假定一个块是1K ,一个页是4K)
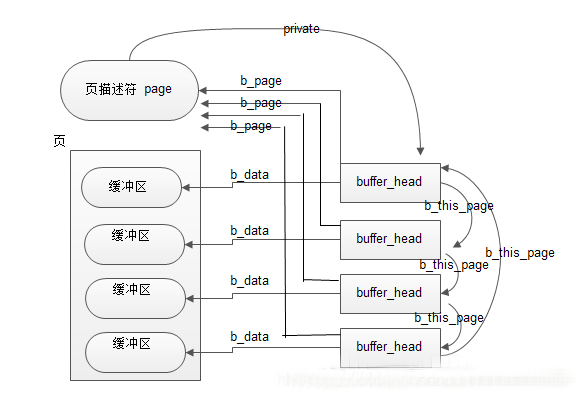
在一个缓冲页内所有块缓冲区大小必须相同,因此在80X86体系结构上,根据块的小大,一个缓冲区页可以包括1~8个缓冲区。如果一个页作为缓冲区页使用,那么与它的块缓冲区相关的所有缓冲区首部都被收集在一个单向循环链表中。page的private字段指向野种第一个块的buffer_head,每个buffer_head存放在b_this_page字段中,该字段是指向链表中的下一个缓冲区首部的指针。此外每个buffer_head还把page的地址存放在b_page字段中,整个图如上所示。
本节参考来源:
Linux Page Cache的工作原理
深入理解linux中的page cache
Linux Page Cache调优在Kafka中的应用
该文章最后由 阿炯 于 2024-12-25 14:54:24 更新,目前是第 2 版。