Linux系统性能优化思路及方法一览
 一、影响 linux 性能的各种因素
一、影响 linux 性能的各种因素1、系统硬件资源
(1)CPU
如何判断多核 CPU 与超线程,消耗 CPU 的业务:动态 web 服务、mail 服务。
(2)内存
物理内存与 swap 的取舍,选择 64 位 Linux 操作系统。消耗内存的业务:内存数据库(redis/hbase/mongodb)。
(3)磁盘 IO
RAID 技术(RAID0/1/5/01/10),SSD 磁盘。消耗磁盘的业务:数据库服务器。
(4)网络带宽
网卡/交换机的选择,操作系统双网卡绑定。消耗带宽的业务:hadoop 平台、视频业务平台。
2、操作系统相关资源
(1)系统安装优化
磁盘分区、RAID 设置、swap 设置
(2)内核参数优化
ulimit -n(最大打开文件数)
ulimit -u(最大用户数)
(3)文件系统优化
ext2:Linux 下标准文件系统,无日志记录(inode)功能。
ext3:在ext2 基础上增加了日志记录功能(inode),仅支持 32000 个子目录。
ex4:ext3 的后续版本,Linux2.6.28 内核开始支持。无限子目录支持,快速 fsck。
xfs:高性能文件系统,Linux3.10 内核开始默认支持。
建议:读操作频繁,同时小文件众多的应用:首选 ext4 文件系统,接下来依次是 xfs、ext3;写操作频繁的应用,首选是 xfs,接下来依次是 ext4 和 ext3;对性能、数据安全要求高的业务,ext3 是比较好的选择。
3、程序问题
此类问题需要开发人员查看代码,介入处理。但作为运维人员需要给出程序问题的有力证据。
二、Linux 性能优化工具
系统状态分析及采集工具集Sysstat是业界推荐的工具,非常值得关注和使用。
1、CPU 性能评估工具
(1)vmstat(系统默认自带)
利用 vmstat 命令可以对操作系统的内存信息、进程状态、CPU活劢等进行监视。常用方式:vmstat 2 3
表示每 3 秒更新一次输出信息,统计 5 次后停止输出。
对上面每项的输出解释如下:
procs
r 列表示运行和等待 cpu 时间片的进程数, 这个值如果长期大于系统CPU 的个数,说明 CPU 不足,需要增加 CPU。
b 列表示在等待资源的进程数,比如正在等待 I/O、或者内存交换等。
memory
swpd 列表示切换到内存交换区的内存数量(以 k为单位) 。如果 swpd 的值不为0,或者比较大,只要 si、so 的值长期为 0,这种情况下一般不用担心,不会影响系统性能。
free列表示当前空闲的物理内存数量(以 k为单位)
buff 列表示 buffers cache的内存数量,一般对块设备的读写才需要缓冲。
cache列表示 Page Cached 的内存数量,一般作为文件系统 cached,频繁访问的文件都会被 cached,如果 cache 值较大,说明 cached 的文件数较多,如果此时 IO 中 bi比较小,说明文件系统效率比较好。
swap
si列表示由磁盘调入内存,也就是内存进入内存交换区的数量。
so 列表示由内存调入磁盘,也就是内存交换区进入内存的数量。
一般情况下, si、 so 的值都为 0, 如果 si、 so 的值长期不为 0, 则表示系统内存不足。需要增加系统内存。
IO 项显示磁盘读写状况
Bi列表示从块设备读入数据的总量(即读磁盘)(每秒 kb) ;
Bo 列表示写入到块设备的数据总量(即写磁盘)(每秒 kb)。
设置的 bi+bo 参考值为 1000,如果超过 1000,而且 wa值较大,则表示系统磁盘 IO 有问题,应该考虑提高磁盘的读写性能。
system 显示采集间隔内发生的中断数
in 列表示在某一时间间隔中观测到的每秒设备中断数。
cs 列表示每秒产生的上下文切换次数。
上面这 2 个值越大,会看到由内核消耗的 CPU 时间会越多。
CPU 项显示了 CPU 的使用状态,此列是关注的重点。
us 列显示了用户进程消耗的 CPU 时间百分比。us 的值比较高时,说明用户进程消耗的 cpu 时间多,但是如果长期大于 50%,就需要考虑优化程序或算法。
sy列显示了内核进程消耗的 CPU 时间百分比。Sy的值较高时,说明内核消耗的CPU 资源很多。
根据经验, us+sy的参考值为 80%, 如果 us+sy大于 80%说明可能存在 CPU 资源不足。
id 列显示了 CPU 处在空闲状态的时间百分比。
wa 列显示了 IO 等待所占用的 CPU 时间百分比。wa 值越高,说明 IO 等待越严重,根据经验,wa 的参考值为 20%,如果 wa 超过 20%,说明 IO 等待严重,引起 IO 等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者磁盘控制器的带宽瓶颈造成的(主要是块操作) 。
综上所述, 在对 CPU 的评估中, 需要重点注意的是procs 项 r 列的值和 CPU 项中 us、sy和 id 列的值。
(2)iostat
iostat 是 I/O statistics(输入/输出统计)的缩写,主要的功能是对系统的磁盘 I/O 操作进行监视。常用方式:iostat -c 3 5
其中,-c 表示显示CPU 的使用情况,-d:显示磁盘的使用情况。
(3)uptime 命令
uptime是监控系统性能最常用的一个命令,主要用来统计系统当前的运行状况,输出的信息依次为:系统现在的时间、系统从上次开机到现在运行了多长时间、系统目前有多少登陆用户、系统在一分钟内、五分钟内、十五分钟内的平均负载。
2、内存性能评估
(1)free 命令
free 命令是监控 linux 内存使用状况最常用的指令,常见用法:free –m
“free –m”表示以 M为单位查看内存使用情况,在这个输出中,我们重点关注的应该是 free 列与 cached 列的输出值,由输出可知,此系统共 8G 内存,系统空闲内存还有925M,其中,Buffer Cache 占用了 243M,Page Cache 占用了 6299M,由此可知系统缓存了很多的文件和目录,而对于应用程序来说,可以使用的内存还有 7468M,当然这个 7468M 包含了 Buffer Cache 和 Page Cache 的值。在 swap 项可以看出,交换分区还未使用。所以从应用的角度来说,此系统内存资源还非常充足。
一般有这样一个经验公式:应用程序可用内存/系统物理内存>70%时,表示系统内存资源非常充足,不影响系统性能,应用程序可用内存/系统物理内存<20%时,表示系统内存资源紧缺,需要增加系统内存,20%<应用程序可用内存/系统物理内存<70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能。
(2)sar/pidstat
此两个命令主要用于监控全部或指定进程占用系统资源的情况,如 CPU,内存、设备IO。三个公用参数:-u(获取 CPU 状态) 、-r(获取内存状态) 、-d(获取磁盘)
常用组合:
sar -u 3 获取 cpu 3 秒内的状态
pidstat -r –p 1 3 获取内存 3 秒内的状态
其中:
Kbmemfree 表示空闲物理内存大小,kbmemused 表示已使用的物理内存空间大小,%memused 表示已使用内存占总内存大小的百分比,kbbuffers 和 kbcached 分别表示Buffer Cache 和 Page Cache 的大小,kbcommit 和%commit 分别表示应用程序当前使用的内存大小和使用百分比。可以看出 sar 的输出其实与 free的输出完全对应,不过 sar 更加人性化,不但给出了内存使用量,还给出了内存使用的百分比以及统计的平均值。从%commit 项可知,此系统目前内存资源充足。
3、磁盘性能评估
(1)iostat –d 组合
iostat –d 2 3
通过“iostat –d”命令组合也可以查看系统磁盘的使用状况:
Blk_read/s 表示每秒读取的数据块数。
Blk_wrtn/s 表示每秒写入的数据块数。
Blk_read 表示读取的所有块数。
Blk_wrtn 表示写入的所有块数。
(2)pidstat -d -p 31887 3
(3)sar -d 2 3
通过“sar –d”组合,可以对系统的磁盘 IO 做一个基本的统计:
DEV 表示磁盘设备名称。
tps 表示每秒到物理磁盘的传送数,也就是每秒的 I/O 流量。一个传送就是一个 I/O 请求,多个逻辑请求可以被合并为一个物理 I/O 请求。
rd_sec/s 表示每秒从设备读取的扇区数(1 扇区=512 字节)。
wr_sec/s 表示每秒写入设备的扇区数目。
avgrq-sz 表示平均每次设备 I/O 操作的数据大小(以扇区为单位) 。
avgqu-sz 表示平均 I/O 队列长度。
await 表示平均每次设备 I/O 操作的等待时间(以毫秒为单位) 。
svctm表示平均每次设备 I/O 操作的服务时间(以毫秒为单位) 。
%util表示一秒中有百分之几的时间用于 I/O 操作。
Linux 中 I/O 请求系统与现实生活中超市购物排队系统有很多类似的地方,通过对超市购物排队系统的理解,可以很快掌握 linux 中 I/O 运行机制。比如:
avgrq-sz 类似于超市排队中每人所买东西的多少。
avgqu-sz 类似于超市排队中单位时间内平均排队的人数。
await 类似于超市排队中每人的等待时间。
svctm类似于超市排队中收银员的收款速度。
%util类似于超市收银台前有人排队的时间比例。
对于磁盘 IO 性能,一般有如下评判标准:正常情况下 svctm 应该是小于 await 值的,而 svctm 的大小和磁盘性能有关,CPU、内存的负荷也会对 svctm值造成影响,过多的请求也会间接的导致 svctm值的增加。
await 值的大小一般取决于 svctm 的值和 I/O 队列长度以及 I/O 请求模式,如果 svctm的值与 await 很接近,表示几乎没有 I/O 等待,磁盘性能很好,如果 await 的值远高于 svctm的值,则表示 I/O 队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。
%util 项的值也是衡量磁盘 I/O 的一个重要指标,如果%util 接近 100%,表示磁盘产生的 I/O 请求太多,I/O 系统已经满负荷的在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能,可以通过优化程序或者通过更换更高、更快的磁盘来解决此问题。
4、网络性能评估
(1)ping 命令
在这个输出中,time值显示了两台主机之间的网络延时情况,如果此值很大,则表示网络的延时很大,单位为毫秒。在这个输出的最后,是对上面输出信息的一个总结,packet loss 表示网络的丢包率,此值越小,表示网络的质量越高。
(2)netstat 命令
netstat –i (查看路由情况)
netstat –r(查看网络接口状态)
(3)mtr/traceroute 命令
跟踪网络路由状态,推荐使用 mtr,动态跟踪网络路由,用于排除网络问题非常方便。
三、系统性能分析标准
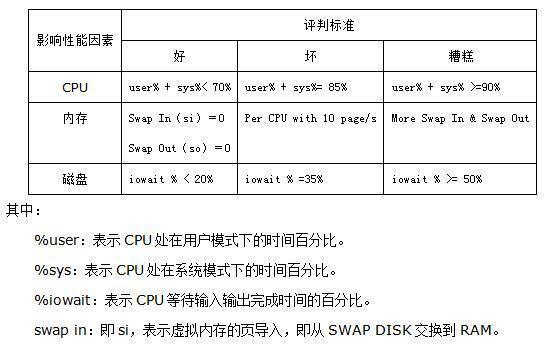
四、问题综合分析
分析问题的方法论
套用5W2H方法,可以提出性能分析的几个问题:
1.What-现象是什么样的
2.When-什么时候发生
3.Why-为什么会发生
4.Where-哪个地方发生的问题
5.How much-耗费了多少资源
6.How to do-怎么解决问题
系统负载
Load 就是对计算机干活多少的度量(WikiPedia:the system Load is a measure of the amount of work that a compute system is doing)简单的说是进程队列的长度。Load Average 就是一段时间(1分钟、5分钟、15分钟)内平均Load。
分析工具及其使用方式
uptime、top、vmstat //查看负载情况
strace -c -p pid //统计系统调用耗时情况
strace -T -e epoll_wait -p pid //跟踪指定的系统操作例如epoll_wait
dmesg //查看内核日志信息
CPU
针对应用程序通常关注的是内核CPU调度器功能和性能。线程的状态分析主要是分析线程的时间用在什么地方,而线程状态的分类一般分为:
1.on-CPU:执行中,执行中的时间通常又分为用户态时间user和系统态时间sys。
2.off-CPU:等待下一轮上CPU,或者等待I/O、锁、换页等等,其状态可以细分为可执行、匿名换页、睡眠、锁、空闲等状态。
如果大量时间花在CPU上,对CPU的剖析能够迅速解释原因;如果系统时间大量处于off-cpu状态,定位问题就会费时很多。但是仍然需要清楚一些概念:处理器、核心、硬件线程、CPU内存缓存、时钟频率、每指令周期数CPI和每周期指令数IPC、CPU指令、使用率、用户与内核时间、调度器、运行队列、抢占、多进程、多线程、字长。
分析工具
uptime,vmstat,mpstat,top,pidstat只能查询到cpu及负载的的使用情况。
perf可以跟着到进程内部具体函数耗时情况,并且可以指定内核函数进行统计。
用方式
top //查看系统cpu使用情况
mpstat -P ALL 1 //查看所有cpu核信息
vmstat 1 //查看cpu使用情况以及平均负载
pidstat -u 1 -p pid //进程cpu的统计信息
perf top -p pid -e cpu-clock //跟踪进程内部函数级cpu使用情况
内存
内存是为提高效率而生,实际分析问题的时候,内存出现问题可能不只是影响性能,而是影响服务或者引起其他问题。同样对于内存有些概念需要清楚:
主存、虚拟内存、常驻内存、地址空间、OOM、页缓存、缺页、换页、交换空间、交换、用户分配器libc、glibc、libmalloc和mtmalloc、内核级Slub分配器
分析工具
free,vmstat,top,pidstat,pmap只能统计内存信息以及进程的内存使用情况。
valgrind可以分析内存泄漏问题。
dtrace动态跟踪。需要对内核函数有很深入的了解,通过D语言编写脚本完成跟踪。
使用方式
free -m //查看系统内存使用情况
vmstat 1 //虚拟内存统计信息
top //查看系统内存情况
pidstat -p pid -r 1 //每秒(1s)采集并获取内存的统计信息
pmap -d pid //查看进程的内存映像信息
//检测程序内存问题
valgrind --tool=memcheck --leak-check=full --log-file=./log.txt ./应用程序名
硬盘IO
硬盘通常是计算机最慢的子系统,也是最容易出现性能瓶颈的地方,因为磁盘离 CPU 距离最远而且 CPU 访问磁盘要涉及到机械操作,比如转轴、寻轨等。访问硬盘和访问内存之间的速度差别是以数量级来计算的,就像1天和1分钟的差别一样。要监测 IO 性能,有必要了解一下基本原理和 Linux 是如何处理硬盘和内存之间的 IO 的。在理解磁盘IO之前,同样我们需要理解一些概念,例如:
文件系统、VFS、文件系统缓存、页缓存page cache、缓冲区高速缓存buffer cache、目录缓存、inode(缓存)、noop调用策略
分析工具及其使用方式
iotop //查看系统io信息
iostat -d -x -k 1 10 //统计io详细信息
pidstat -d 1 -p pid //查看进程级io的信息
//查看系统IO的请求,比如可以在发现系统IO异常时,可以使用该命令进行调查,就能指定到底是什么原因导致的IO异常
perf record -e block:block_rq_issue -ag
perf report
网络
网络的监测是所有 Linux 子系统里面最复杂的,有太多的因素在里面,比如:延迟、阻塞、冲突、丢包等,更糟的是与主机相连的路由器、交换机、无线信号都会影响到整体网络并且很难判断是因为 Linux 网络子系统的问题还是别的设备的问题,增加了监测和判断的复杂度。现在使用的所有网卡都称为自适应网卡,意思是说能根据网络上的不同网络设备导致的不同网络速度和工作模式进行自动调整。
分析工具及其使用方式
netstat -s //显示网络统计信息
netstat -nu //显示当前UDP连接状况
netstat -apu //显示UDP端口号的使用情况
//统计机器中网络连接各个状态个数
netstat -a | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
ss -t -a //显示TCP连接
ss -s //显示sockets摘要信息
ss -u -a //显示所有udp sockets
sar -n TCP,ETCP 1 //tcp,etcp状态
sar -n DEV 1 //查看网络IO
tcpdump -i eth1 host 192.168.1.1 and port 80 //抓包以包为单位进行输出
tcpflow -cp host 192.168.1.1 //抓包以流为单位显示数据内容
综合工具一览
stress 是一个 Linux 系统压力测试命令工具,用作异常进程模拟平均负载升高的场景。–cpu cpu压测选项,-i io压测选项,-c 进程数压测选项,–timeout 执行时间。
sysbench 来模拟系统多线程调度切换的情况
显示平均负载:uptime、top,显示的顺序是最近1分钟、5分钟、15分钟,从此可以看出平均负载的趋势。
sysstat 包含了常用的 Linux 性能工具,用来监控和分析系统是的性能,找出平均负载升高的根源,包括几个命令 mpstat 和 pidstat,iostat。
mpstat:多核cpu性能分析工具,-P ALL监视所有cpu,cswch ,表示每秒自愿上下文切换的次数,nvcswch ,表示每秒非自愿上下文切换的次数。
pidstat:进程性能分析工具,-u 显示cpu利用率
iostat:IO性能分析工具
vmstat 是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数。
cs(context switch)是每秒上下文切换的次数。
in(interrupt)则是每秒中断的次数。
r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。
b(Blocked)则是处于不可中断睡眠状态的进程数。
/proc/interrupts 系统中断次数
/proc/stat 系统进程整体的统计信息
perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数。perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。在实际使用中,我们还经常为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题。
pstree 就可以用树状形式显示所有进程之间的关系。
execsnoop 就是一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。
dstat 可以同时查看 CPU 和 I/O 这两种资源的使用情况,便于对比分析。
一般来说,先通过uptime查看系统负载,然后使用mpstat结合pidstat来初步判断到底是cpu计算量大还是进程争抢过大或者是io过多,接着使用vmstat分析切换次数,以及切换类型,来进一步判断到底是io过多导致问题还是进程争抢激烈导致问题。
五、从内核开始调优
Linux内核的默认配置考虑的是通用性,但服务器往往有特定的使用场景,比如高并发Web服务、数据库服务器、文件服务器等等,每种场景的优化重点都不一样。可以从网络参数、内存管理、进程调度、文件系统、IO调度、内核模块与服务、监控和调试等方面来直接进行优化;也可以通过实际案例来进行针对性、场景化(云、容器)的综合优化,以及使用测试工具来验证等方面。
网络参数优化 - 让数据传输更顺畅
网络优化是最常遇到的需求,特别是做Web服务的时候。TCP连接数限制经常是个大问题。默认情况下,系统的文件描述符限制比较保守,高并发场景下很容易成为瓶颈。
# 查看当前限制
ulimit -n
# 临时修改
ulimit -n 65535
# 永久修改需要编辑 /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
仅改这个还不够,还得调整内核的网络参数。一般会这样配置:
# 编辑 /etc/sysctl.conf
#设置系统级别的socket监听队列的最大长度,当应用程序调用listen()时,backlog参数不能超过这个值。提高此值可以允许更多的连接请求排队等待处理
net.core.somaxconn = 32768
#网络设备接收数据包的队列最大长度,当网络接口接收数据包的速度超过内核处理速度时,数据包会在此队列中排队
net.core.netdev_max_backlog = 32768
#设置SYN_RECV状态的连接队列最大长度,控制处于半连接状态的TCP连接数量,防止SYN flood攻击
net.ipv4.tcp_max_syn_backlog = 32768
#设置TCP连接在FIN-WAIT-2状态的超时时间,缩短TIME_WAIT状态的持续时间,更快释放连接资源
net.ipv4.tcp_fin_timeout = 10
#设置TCP keepalive探测的间隔时间,更频繁地检测死连接,及时清理无效连接
net.ipv4.tcp_keepalive_time = 1200
#设置系统中TIME_WAIT状态连接的最大数量,限制TIME_WAIT连接数,防止占用过多系统资源
net.ipv4.tcp_max_tw_buckets = 32768
这里面每个参数都有它的作用。比如somaxconn控制的是监听队列的最大长度,如果应用连接数很高,这个值设小了就会导致连接被拒绝。
tcp_fin_timeout一般设置得比较小,因为TIME_WAIT状态的连接太多会占用大量资源。当然这个值也不能设得太小,否则可能会有问题。
内存管理优化
内存这块的优化主要集中在几个方面。交换分区的使用策略是个重点,常见将swap作为内存不够时的备用方案,其实不完全是这样。Linux会根据swappiness参数来决定什么时候使用swap。
# 查看当前值
#cat /proc/sys/vm/swappiness
30
# 修改为10(默认通常是60)
#echo 10 > /proc/sys/vm/swappiness
一般把这个值设置得比较低,特别是数据库服务器。因为数据库对延迟很敏感,一旦数据被swap到磁盘,性能就会急剧下降。
内存回收策略也很重要:
vm.dirty_ratio = 10
vm.dirty_background_ratio = 5
vm.dirty_expire_centisecs = 3000
vm.dirty_writeback_centisecs = 500
这几个参数控制的是脏页的回写策略。脏页就是在内存中被修改但还没写入磁盘的数据页。如果脏页太多,系统性能会受影响;但如果回写太频繁,磁盘IO压力又会很大。在处理一个文件服务器的性能问题,发现写入大文件时系统会卡顿。后来发现是脏页比例设置得太高,导致积累了大量脏页,集中回写时把磁盘IO打满了。调整这几个参数后问题就解决了。
进程调度优化
CPU调度器的优化相对来说比较少用到,但在某些场景下效果很明显。Linux有几种调度器可以选择,默认的CFS(完全公平调度器)适合大部分场景,但如果你的应用对延迟要求很高,可能需要调整一些参数。
# 查看当前调度策略
#cat /proc/sys/kernel/sched_*
...
# 调整时间片长度
echo 1000000 > /proc/sys/kernel/sched_latency_ns
调度器相关参数解释
1. sched_autogroup_enabled = 0
• 作用:控制是否启用自动分组调度
• 值:0表示禁用,1表示启用
• 影响:禁用后所有进程在同一调度组中竞争CPU
2. sched_cfs_bandwidth_slice_us = 5000
• 作用:CFS带宽控制的时间片长度(微秒)
• 默认值:5000微秒(5毫秒)
• 影响:控制cgroup带宽限制的精度
3. sched_child_runs_first = 0
• 作用:控制fork后是否让子进程优先运行
• 值:0表示父进程优先,1表示子进程优先
• 影响:影响进程创建后的调度顺序
4. sched_latency_ns = 4194304
• 作用:CFS调度器的目标延迟时间(纳秒)
• 值:4194304纳秒 ≈ 4.19毫秒
• 影响:所有可运行进程至少运行一次的时间周期
5. sched_migration_cost_ns = 100
• 作用:进程迁移的成本估算(纳秒)
• 影响:影响负载均衡时进程在CPU间的迁移决策
6. sched_min_granularity_ns = 1000000
• 作用:进程运行的最小时间粒度(纳秒)
• 值:1000000纳秒 = 1毫秒
• 影响:保证每个进程至少运行的时间
7. sched_nr_migrate = 32
• 作用:负载均衡时单次迁移的最大进程数
• 影响:控制负载均衡的开销和效果
8. sched_rr_timeslice_ms = 100
• 作用:SCHED_RR调度策略的时间片长度(毫秒)
• 影响:实时轮转调度的时间片大小
9. sched_rt_period_us = 1000000
• 作用:实时调度的周期时间(微秒)
• 值:1000000微秒 = 1秒
• 影响:实时进程调度的时间窗口
10. sched_rt_runtime_us = 950000
• 作用:实时进程在一个周期内可使用的最大CPU时间(微秒)
• 值:950000微秒 = 0.95秒
• 影响:限制实时进程的CPU使用,为普通进程保留5%的CPU时间
11. sched_schedstats = 0
• 作用:控制是否启用调度统计信息收集
• 值:0表示禁用,减少统计开销
12. sched_tunable_scaling = 1
• 作用:控制调度参数是否根据CPU数量自动缩放
• 值:1表示启用对数缩放
13. sched_wakeup_granularity_ns = 15000000
• 作用:唤醒抢占的粒度控制(纳秒)
• 值:15000000纳秒 = 15毫秒
• 影响:控制进程被唤醒时是否能抢占当前运行的进程
调度器参数较少改动,除非遇到特殊需求。因为其影响面比较大,改不好可能会影响整个系统的稳定性。倒是进程优先级的调整用得比较多。对于关键业务进程,可以通过nice值来提高优先级:
# 启动时设置优先级
nice -n -10 ./freeoa_service
# 运行时调整
renice -10 -p 进程ID
文件系统优化
文件系统这块的优化主要看你用的是什么文件系统。
ext4的话,挂载参数很重要:
# /etc/fstab 中的配置示例
/dev/sda1 /data ext4 defaults,noatime,nodiratime,barrier=0 0 2
noatime参数可以避免每次读取文件时更新访问时间,对于读多写少的场景能提升不少性能。barrier=0可以提高写入性能,但要确保硬件有电池保护,否则可能有数据丢失风险。数据库服务器更推荐使用xfs文件系统,它在大文件和高并发场景下表现更好。
# 格式化为xfs
mkfs.xfs -f /dev/sda1
# 挂载时的优化参数
mount -t xfs -o noatime,nodiratime,logbufs=8,logbsize=256k /dev/sda1 /data
IO调度器选择
IO调度器的选择对性能影响很大,特别是在高IO负载的场景下。
Linux提供了几种IO调度器:
# 查看当前调度器
cat /sys/block/sda/queue/scheduler
# 修改调度器
echo deadline > /sys/block/sda/queue/scheduler
对于SSD一般推荐使用noop或者deadline调度器,因为SSD没有机械磁盘的寻道时间,复杂的调度算法反而会增加延迟。
传统机械硬盘的话,cfq调度器通常是个不错的选择,它能保证各个进程的IO请求相对公平。一个案例中的数据库服务器使用的是SSD,但IO调度器还是默认的cfq,导致数据库响应时间不稳定。改成deadline后,响应时间的波动明显减小了。
内核模块和服务优化
系统启动时会加载很多内核模块和服务,但并不是所有的都是必需的。可以通过以下命令查看当前加载的模块:
lsmod
对于不需要的模块,可以加入黑名单:
# 编辑 /etc/modprobe.d/blacklist.conf
blacklist 模块名
系统服务也是一样,可以关闭不必要的服务:
# 查看所有服务状态
systemctl list-units --type=service
# 关闭不需要的服务
systemctl disable 服务名
systemctl stop 服务名
注意:关闭服务前一定要确认它的作用,别把重要的服务给关了。
监控和调试工具
优化完了还得有监控手段,不然怎么知道效果如何?常用的监控工具有这些:
# 系统整体性能
top, htop, atop
# 网络监控
iftop, nethogs, ss
# 磁盘IO监控
iotop, iostat
# 内存使用情况
free, vmstat
# 进程跟踪
strace, ltrace
perf工具特别好用,可以分析系统的性能瓶颈:
# 采样系统性能
perf record -g ./your_program
# 查看报告
perf report
通过perf可以看到哪些函数占用CPU最多,对于性能优化很有帮助。
实际案例分享
分享一个真实的优化案例。一个电商客户在高峰期间服务器压力巨大,经常出现响应超时。接到求助后,第一时间上去看了看系统状态。通过监控发现,CPU使用率不高,内存也够用,但网络连接数接近上限,而且TIME_WAIT状态的连接特别多。分析后发现主要问题在于:
1. 文件描述符限制太小
2. TCP参数没有针对高并发场景优化
3. 应用层面的连接池配置不合理
优化步骤是这样的:
调整系统参数:
# 增加文件描述符限制
echo "* soft nofile 65535" >> /etc/security/limits.conf
echo "* hard nofile 65535" >> /etc/security/limits.conf
# 优化TCP参数
echo "net.ipv4.tcp_tw_reuse = 1" >> /etc/sysctl.conf
echo "net.ipv4.tcp_fin_timeout = 10" >> /etc/sysctl.conf
echo "net.core.somaxconn = 32768" >> /etc/sysctl.conf
sysctl -p
同时建议应用团队调整了连接池的配置,增加了连接复用。优化后系统的并发处理能力提升了40%多,成功撑过了流量高峰。
注意事项和踩坑经验
做内核优化有几个要特别注意的地方。参数不是越大越好。过有人觉得缓冲区大一点总是好的,结果把各种buffer都设得很大,反而导致内存不够用。修改前一定要备份原始配置。每次修改前都会把原来的值记录下来,万一有问题可以快速回滚。
# 修改前先备份
cp /etc/sysctl.conf /etc/sysctl.conf.backup.$(date +%Y%m%d)
测试要充分。内核参数的影响往往不是立竿见影的,需要在实际负载下运行一段时间才能看出效果。一般会先在测试环境验证,然后在生产环境小范围试点,最后才全面推广。不要一次改太多参数。如果同时修改很多参数,出了问题很难定位是哪个参数导致的。建议是每次只改一两个相关的参数,观察一段时间后再继续。还有就是要考虑业务特点。同样的优化参数,在不同的业务场景下效果可能完全不同。比如对于批处理任务,可能更关注吞吐量;但对于在线服务,延迟可能更重要。
不同场景的优化重点
Web服务器的优化重点通常在网络和并发连接数上。除了前面提到的TCP参数,还要关注Apache或Nginx的配置。数据库服务器就不一样了,内存和磁盘IO是关键。一般会把swappiness设得很低,甚至直接关闭swap。同时调整内存分配策略:
vm.overcommit_memory = 2
vm.overcommit_ratio = 80
这样可以避免系统过度分配内存导致OOM killer被触发。文件服务器的话,磁盘IO和文件系统参数是重点。除了前面说的挂载参数,还可以调整读写缓存:
vm.dirty_ratio = 15
vm.dirty_background_ratio = 5
缓存服务器(比如Redis、Memcached)对内存延迟特别敏感,可能需要调整NUMA相关的参数:
# 查看NUMA信息
numactl --hardware
# 绑定进程到特定NUMA节点
numactl --cpunodebind=0 --membind=0 redis-server
自动化优化脚本
手动一个个改参数太麻烦了,我写了个脚本来自动化这个过程:
#!/bin/bash
# 系统优化脚本
# 备份原始配置
cp /etc/sysctl.conf /etc/sysctl.conf.backup.$(date +%Y%m%d)
# 网络优化
cat >> /etc/sysctl.conf << EOF
# 网络优化参数
net.core.somaxconn = 32768
net.core.netdev_max_backlog = 32768
net.ipv4.tcp_max_syn_backlog = 32768
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_keepalive_time = 1200
EOF
# 内存优化
cat >> /etc/sysctl.conf << EOF
# 内存优化参数
vm.swappiness = 10
vm.dirty_ratio = 10
vm.dirty_background_ratio = 5
EOF
# 应用配置
sysctl -p
echo "优化完成,建议重启系统使所有配置生效"
当然这只是个基础版本,实际使用时还要根据具体场景来调整。
性能测试和验证
优化完了怎么验证效果呢?一般会用几种方法,压力测试是必不可少的,对于Web服务常用ab或者wrk。
# MySQL压力测试
sysbench oltp_read_write --mysql-host=localhost --mysql-user=root --mysql-password=password --mysql-db=test --tables=10 --table-size=100000 run
网络性能可以用iperf:
# 服务端
iperf -s
# 客户端
iperf -c server_ip -t 60
除了压力测试,日常监控也很重要。会设置一些关键指标的监控,比如连接数、响应时间、CPU使用率等。一旦发现异常,就能及时处理。
容器化环境的特殊考虑
现在很多应用都跑在容器里,容器化环境的内核优化有些特殊之处。Docker容器默认会继承宿主机的内核参数,但有些参数是容器级别的,需要在容器启动时指定:
# 启动容器时调整参数
docker run --sysctl net.core.somaxconn=32768 --sysctl net.ipv4.tcp_keepalive_time=600 your-image
Kubernetes环境下可以通过securityContext来设置:
apiVersion: v1
kind: Pod
spec:
securityContext:
sysctls:
- name: net.core.somaxconn
value: "32768"
- name: net.ipv4.tcp_keepalive_time
value: "600"
不过要注意,不是所有的内核参数都能在容器里修改,有些涉及到安全的参数是受限制的。
云环境的优化策略
在云环境下,有些优化策略需要调整。比如在AWS EC2上,网络性能跟实例类型关系很大。小实例的网络带宽有限,再怎么优化TCP参数也提升不了多少。这时候可能需要考虑升级实例类型。云硬盘的IOPS也是有限制的,特别是gp2类型的EBS,IOPS跟存储容量相关。如果IO是瓶颈,可能需要换成io1或者gp3类型。还有就是云厂商通常会提供一些优化建议,比如AWS的Enhanced Networking,阿里云的多队列网卡等,这些特性要充分利用起来。
监控和告警设置
优化不是一次性的工作,需要持续监控和调整。一般会设置这些监控指标:
系统层面:
• CPU使用率和负载
• 内存使用率和swap使用情况
• 磁盘IO和使用率
• 网络流量和连接数
应用层面:
• 响应时间和吞吐量
• 错误率
• 连接池状态
• 缓存命中率
告警阈值不要设得太敏感,否则会有很多误报。先设置得宽松一点,运行一段时间后根据实际情况再调整。
版本升级的考虑
Linux内核版本的选择也很重要。新版本通常会有性能改进和新特性,但稳定性可能不如LTS版本。对于生产环境一般推荐使用LTS版本,比如目前的5.4或5.15。这些版本经过了长期的测试和验证,bug相对较少。不过如果应用需要某些新特性,比如eBPF、io_uring等,可能就需要使用较新的内核版本,此时要做好充分的测试。升级内核前一定要做好备份和回滚准备。
六、性能压力测试指南参考
对 CPU、内存、网络和 I/O 进行压力测试是至关重要的环节。通过这些测试可以深入了解系统在不同负载下的表现,发现潜在的性能瓶颈,为系统优化和升级提供有力依据。实际生产环境中,某个功能正式上线前,在UAT环境先做压测是非常重要且必须要做的工作。在进行压力测试前,需要做好充分的准备工作。首先,要确保测试环境的稳定性,避免其他无关进程对测试结果产生干扰,可通过ps、top等命令查看并关闭不必要的进程。其次,需记录系统的初始状态,包括 CPU 使用率、内存占用、网络带宽和 I/O 响应时间等,以便与测试后的结果进行对比分析。同时要选择合适的测试工具,不同的测试目标对应不同的工具,需根据实际需求进行挑选。
CPU 压力测试,CPU 是系统的核心部件,其性能直接影响系统的整体运行速度。常用的 CPU 压力测试工具有stress和sysbench。使用stress工具时,可通过命令stress -c N来模拟 N 个 CPU 核心的满负载情况,其中 N 为需要模拟的 CPU 核心数量。例如,stress -c 4表示让 4 个 CPU 核心处于满负载状态。在测试过程中,可使用top或htop命令实时监控 CPU 的使用率、负载平均值等指标。
sysbench工具则更加强大,它可以进行多线程的 CPU 性能测试。执行命令sysbench cpu --cpu-max-prime=20000 run,该命令会通过计算质数来消耗 CPU 资源,--cpu-max-prime参数指定了最大质数,数值越大,测试时间越长,对 CPU 的压力也越大。测试结束后,会输出 CPU 的测试结果,包括每秒完成的计算次数等。
在进行 CPU 压力测试时,需要注意测试时间不宜过长,以免对系统硬件造成损坏。一般来说,测试时间控制在几分钟到几十分钟即可。同时,要观察系统是否出现卡顿、响应缓慢等情况,这些都是 CPU 性能不足的表现。
内存压力测试,内存是系统运行程序和存储数据的重要区域,内存不足会导致系统频繁进行 swap 操作,严重影响系统性能。内存压力测试工具主要有stress和memtester。
stress工具同样可以用于内存压力测试,命令stress -m N --vm-bytes M表示创建 N 个进程,每个进程分配 M 大小的内存。例如,stress -m 2 --vm-bytes 512M会创建 2 个进程,每个进程分配 512M 内存。测试过程中,可通过free -h命令查看内存的使用情况,包括总内存、已使用内存、空闲内存和 swap 分区的使用情况。
memtester工具专门用于内存稳定性测试,它可以检测内存是否存在故障。使用命令memtester M N,其中 M 为测试的内存大小,N 为测试次数。例如,memtester 1G 2表示对 1G 内存进行 2 次测试。该工具会进行多种内存操作测试,如随机数据写入、读取等,测试结束后会输出是否有错误发生。
进行内存压力测试时,要注意避免分配超过系统实际内存容量过多的内存,以免导致系统崩溃。同时,要关注 swap 分区的使用情况,如果 swap 分区使用率过高,说明系统内存不足,需要考虑增加内存容量。
网络压力测试,网络是系统与外部进行数据交互的通道,网络带宽、延迟和丢包率等指标直接影响网络应用的性能。网络压力测试工具主要有iperf和netperf。
iperf是一款常用的网络带宽测试工具,支持 TCP 和 UDP 协议。使用时需要在服务器端和客户端分别运行命令。在服务器端执行iperf -s,启动服务器模式;在客户端执行iperf -c 服务器IP,连接服务器进行测试。测试结果会显示带宽、传输速率等信息。如果要进行 UDP 测试,可在客户端命令中添加-u参数,如iperf -c 服务器IP -u -b 100M,表示以 100M 的带宽进行 UDP 测试。
netperf工具可以测试不同网络协议下的性能,如 TCP 流测试、UDP 请求 / 响应测试等。服务器端运行netserver命令启动服务,客户端执行netperf -H 服务器IP -t 测试类型,其中测试类型可以是TCP_STREAM、UDP_RR等。例如,netperf -H 192.168.1.100 -t TCP_STREAM会进行 TCP 流测试,输出传输速率等指标。
网络压力测试时,要确保测试环境的网络连接稳定,避免其他网络流量干扰测试结果。可以在不同的网络负载情况下进行测试,如空闲时段和高峰时段,以全面了解网络性能。
I/O 压力测试,I/O 包括磁盘 I/O 和文件系统 I/O,I/O 性能不足会导致数据读写缓慢,影响系统的响应速度。常用的 I/O 压力测试工具有dd、fio。
dd命令是一个简单的 I/O 测试工具,可用于测试磁盘的读写速度。测试写入速度的命令为dd if=/dev/zero of=testfile bs=1G count=1 oflag=direct,其中if=/dev/zero表示输入源为零数据,of=testfile表示输出文件为 testfile,bs=1G表示块大小为 1G,count=1表示写入 1 个块,oflag=direct表示直接写入磁盘,不经过缓存。测试完成后,会输出写入速度。测试读取速度时,可使用命令dd if=testfile of=/dev/null bs=1G count=1 iflag=direct。
fio是一款功能强大的 I/O 测试工具,支持多种 I/O 模式和测试场景。可以通过编写配置文件来定义测试参数,如测试文件、块大小、读写模式、线程数等。例如,创建一个名为fio_test.conf的配置文件,内容如下:
[test]
filename=/tmp/testfile
direct=1
rw=randwrite
bs=4k
size=1G
numjobs=4
runtime=60
其中,filename指定测试文件,direct=1表示直接 I/O,rw=randwrite表示随机写入,bs=4k表示块大小为 4k,size=1G表示测试文件大小为 1G,numjobs=4表示 4 个线程,runtime=60表示测试时间为 60 秒。执行命令fio fio_test.conf即可进行测试,测试结果会详细显示 I/O 吞吐量、响应时间等指标。
进行 I/O 压力测试时,要选择合适的测试文件和目录,避免对系统关键文件和分区进行测试。同时要注意测试过程中磁盘的温度,避免长时间高负载测试导致磁盘损坏。
通过以上对 CPU、内存、网络和 I/O 的压力测试,可以全面了解 Linux 系统的性能状况,为系统的优化和升级提供可靠的参考。在真实生产环境测试过程中,应根据具体的应用场景和需求,选择合适的测试工具和参数,以获得准确的测试结果。