vmstat
 vmstat是一个十分有用的Linux系统监控工具,使用它可以得到关于进程、内存、内存分页、阻塞IO、Traps及CPU活动的信息。从名字可以知道vmstat是一个查看虚拟内存(Virtual Memory)使用状况的工具,是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控;可对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析。在文章尾部有关于Linux中虚拟内存相关内容。
vmstat是一个十分有用的Linux系统监控工具,使用它可以得到关于进程、内存、内存分页、阻塞IO、Traps及CPU活动的信息。从名字可以知道vmstat是一个查看虚拟内存(Virtual Memory)使用状况的工具,是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控;可对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析。在文章尾部有关于Linux中虚拟内存相关内容。Vmstat is a tool that tells quite a bit about the actual performance of your machine disk io, cpu, memory, wait states and more. This is a true measure of how your linux machine is handling load. Specifically it will diagnose the "why" a computer is slow by identifying “what” is bogged down. Usually you run vmstat for more than a few iterations and ignore the first one. Check Point has most of the really good tools removed, but this one is one that they let us have. It’s on every other flavor of linux I’ve tested too, so it’s a good idea to know how to use it.
vmstat用法
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
vmstat --help
usage: vmstat [-V] [-n] [delay [count]]
-V prints version.
-n causes the headers not to be reprinted regularly.
-a print inactive/active page stats.
-d prints disk statistics
-D prints disk table
-p prints disk partition statistics
-s prints vm table
-m prints slabinfo
-S unit size
delay is the delay between updates in seconds.
unit size k:1000 K:1024 m:1000000 M:1048576 (default is K)
count is the number of updates.
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量
-m:显示slabinfo
-n:只在开始时显示一次各字段名称
-s:静态显示内存相关统计信息及多种系统活动数量
delay:刷新时间间隔。如果不指定,只显示一条结果
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷
-d:显示磁盘相关统计信息
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte),默认单位为K(1024 bytes)
-V:显示vmstat版本信息
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
# vmstat 2 1
数字2表示每个两秒采集一次服务器状态,1表示只采集一次。实际上,在使用过程中会在一段时间内一直监控,不想监控直接结束vmstat就行了。
# vmstat 2
这表示vmstat每2秒采集数据,一直采集直到结束程序。
不加任何参数,vmstat命令只输出一条记录,这个数据是自系统上次重启之后到现在的平均数值。
显示活动(active)与非活动(inactive)的内存
# vmstat -a 2 10
显示各种事件计数器表和内存统计信息。
# vmstat -s
显示磁盘分区数据(disk partition statistics)
# vmstat -p sda2 2 10
vmstat with timestamps
使用-t参数可打印出时间戳:vmstat -t 1 5
使用-s参数可打印出相关的统计信息
vmstat command and -s switch displays summary of various event counters and memory statistics.
使用兆字节来展现统计
The vmstat displays memory statistics in kilobytes by default, but you can also display reports with memory sizes in megabytes with the argument -S M. Consider the following example.
vmstat -S M 1 5
相关的一次性统计
vmstat -D
vmstat -s
vmstat -m
首先运行一个默认命令,根据输出结果,解释下各个字段的含义,有助于下面的分析。
# vmstat -a
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free inact active si so bi bo in cs us sy id wa st
1 0 0 757496 64916 83772 0 0 85 7 56 42 1 3 96 0 0
各个字段对应的项含义如下(下面会分简单和详细两个版本)
procs
r:运行队列中进程数量,表示运行队列(就是说多少个进程真的分配到CPU),当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险,top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b:等待如IO之类在相关资源的进程数量,表示受到阻塞的进程。
memory(单位KB)
inact: 非活跃内存大小(当使用-a选项时显示)
active: 活跃的内存大小(当使用-a选项时显示)
swpd 虚拟内存已使用的大小,如果大于0,表示机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小。
buff 用作缓冲的内存大小。
cache 用作缓存的内存大小(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用)。
swap(单位:KB/秒)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
io(单位:块/秒)
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,例如读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
bi: 发送到块设备的块数
bo: 从块设备接收到的块数
in 每秒CPU的中断次数,包括时间中断。
cs 每秒上下文切换次数,例如调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大就要考虑调低线程或者进程的数目;例如在apache和nginx这种web服务器中,一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
cpu
us:用户CPU时间,在繁忙的服务器上,可以看到us接近100,r运行队列达到80。
sy:系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id:空闲 CPU时间,一般来说,id + us + sy = 100,一般认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wa:等待IO CPU时间。
Procs
r: The number of processes waiting for run time.
等待运行的进程数。如果等待运行的进程数越多,意味着CPU非常繁忙。如果该参数长期大于和等于逻辑cpu个数,则CPU资源可能存在较大的瓶颈。
b: The number of processes in uninterruptible sleep.
处在非中断睡眠状态的进程数。意味着进程被阻塞。主要是指被资源阻塞的进程对列数(比如IO资源、页面调度等),当这个值较大时,需要根据应用程序来进行分析,比如数据库产品,中间件应用等。
Memory
swpd: the amount of virtual memory used.
已使用的虚拟内存大小。如果虚拟内存使用较多,可能系统的物理内存比较吃紧,需要采取合适的方式来减少物理内存的使用。swapd不为0,并不意味物理内存吃紧,如果swapd没变化,si、so的值长时间为0,这也是没有问题的。
free: the amount of idle memory.
空闲的物理内存的大小(k表示)
buff: the amount of memory used as buffers.
用来做buffer(缓存,主要用于块设备缓存)的内存数,单位:KB
cache: the amount of memory used as cache.
用来做cache(缓存,主要用于缓存文件)的内存,单位:KB。作为page cache的内存数量,一般作为文件系统的cache;如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。
inact: the amount of inactive memory. (-a option)
inactive memory的总量
active: the amount of active memory. (-a option)
active memroy的总量
Swap
si: Amount of memory swapped in from disk (/s).
从磁盘交换到内存的交换页数量,单位:KB/秒。
so: Amount of memory swapped to disk (/s).
从内存交换到磁盘的交换页数量,单位:KB/秒
内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。当看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,这个是不正确的。不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
当内存的需求大于RAM的数量,服务器启动了虚拟内存机制,通过虚拟内存,可以将RAM段移到SWAP DISK的特殊磁盘段上,这样会出现虚拟内存的页导出和页导入现象,页导出并不能说明RAM瓶颈,虚拟内存系统经常会对内存段进行页导出,但页导入操作就表明了服务器需要更多的内存了, 页导入需要从SWAP DISK上将内存段复制回RAM,导致服务器速度变慢。
IO
bi: Blocks received from a block device (blocks/s).
每秒从块设备读入的数据总量(读磁盘)(KB/S),单位:块/秒,也就是读块设备。
bo: Blocks sent to a block device (blocks/s).
每秒写入到块设备的数据总量(写磁盘)(KB/S),单位:块/秒,也就是写块设备。
随机磁盘读写的时候,这两个值越大(如超出1M)就会发现CPU在IO等待的值也会越大。
System
in: The number of interrupts per second, including the clock.
每秒的中断数,包括时钟中断
cs: The number of context switches per second.
每秒的环境(上下文)切换次数。比如调用系统函数,就要进行上下文切换,而过多的上下文切换会浪费较多的cpu资源,这个数值应该越小越好。如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
CPU
These are percentages of total CPU time.
us: Time spent running non-kernel code. (user time, including nice time)
用户CPU时间(非内核进程占用时间)(单位为百分比)。us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期大于50%,需要考虑优化用户的程序。
sy: Time spent running kernel code. (system time)
系统使用的CPU时间(单位为百分比)。sy的值高时,说明系统内核消耗的CPU资源多,这并不是好的现象。us+sy的参考值为80%,如果该参考值大于 80 说明可能存在CPU不足。
id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
空闲的CPU的时间(百分比),在Linux 2.5.41之前,这部分包含IO等待时间。
wa: Time spent waiting for IO. Prior to Linux 2.5.41, shown as zero.
等待IO的CPU时间,在Linux 2.5.41之前,这个值为0。这个指标意味着CPU在等待硬盘读写操作的时间,用百分比表示。wait越大则机器io性能就越差,wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
命令行参数:
-a:显示活跃和非活跃内存
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息。
-S:使用指定单位显示,参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
vmstat [-a] [-n] [delay [ count]]
-a:显示活动内页
-n:头信息仅显示一次
注:inact和active的数据来自于/proc/meminfo
vmstat [-f] [-s] [-m]
-f:显示启动后创建的进程总数
-s:以表格方式显示事件计数器和内存状态
-m:显示slab信息
注:这些信息的分别来自于/proc/meminfo,/proc/stat和/proc/vmstat。
vmstat [-d]
-d:报告磁盘状态
注:这些信息主要来自于/proc/diskstats
merged:表示一次来自于合并的写/读请求,一般系统会把多个连接/邻近的读/写请求合并到一起来操作。
vmstat [-p disk partition]
-p:显示指定的硬盘分区状态
注:这些信息主要来自于/proc/diskstats
reads:来自于这个分区的读的次数
read sectors:来自于这个分区的读扇区的次数
writes:来自于这个分区的写的次数
requested writes:来自于这个分区的写请求次数
vmstat [-S unit]
-S:输出信息的单位
在Load Average(负载)高的情况下如何鉴别系统瓶颈。是CPU或是内存这类计算资源不足造成的,还是io不够快造成?
查看系统负载(进程运行情况的统计)
procs
r :运行和等待cpu时间片的进程数,如果长期大于1,说明cpu不足,需要增加cpu。
b :在等待资源的进程数,比如正在等待I/O、或者内存交换等。
memory
-----------memory----------
swpd free buff cache
0 496956 889516 4065648
swpd :切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
free :当前的空闲页面列表中内存数量(k表示)
buff :作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。
cache :作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。
swap
---swap--
si:由内存进入内存交换区数量。
so:由内存交换区进入内存数量。
io
-----io----
bi:从块设备读入数据的总量(读磁盘)(每秒kb)。
bo:块设备写入数据的总量(写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析。
system 显示采集间隔内发生的中断和上下文切换数
--system--
in:在某一时间间隔中观测到的每秒设备中断数。
cs:每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
CPU的使用状态(占用总CPU时间的百分比)
-----cpu------
us sy id wa st
51 0 0 99 1
us:用户方态式下所占用总 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。非内核代码所花费的时间(用户时间,包括nice time)。
sy:内核进程所占用的CPU时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。运行内核代码所花费的时间(系统时间)。
wa:IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。在 Linux 2.5.41 之前,包含在 idle 中。
id:cpu处在空闲状态的时间百分比。在 Linux 2.5.41 之前,这包括 IO 等待时间。
st:从虚拟机窃取的时间,在 Linux 2.6.11 之前,未知。
处理示例
录system项的每称的中断数(in)、每秒的上下文切换(cs)特别频繁时,容易就造成load avaerage会特别高。具体是哪个进程如何频繁的进行中断和上下文件的切换呢?这里使用pidstat -w 1 (每秒刷新输出上下文切换情况)。
有cswch(自愿的上下文切换)和nvcswch(非自愿的上下文切换)及对应的命令,看出vsftpd占用的文件交换比较多。可以看到这里显示的cs值和总值还是有比较大的差距,由于主机上启动了不止一个vsftpd进程,而且pidstat 通过1秒刷新的时候并不会显示所有,通过pidstat -w执行几次收集所有发现所有的vsftpd进程占用的cs值叠加和vmstat里的比较相近了。
处理方法有多种,现实中有些程序不好进行这样的修改的,又不让让进程在cpu之间频繁切换的,也有通过设置固定运行的CPU上进行调优的方法,如下两个进程运行在0-7号cpu上:
# taskset -c -p 6689
pid 6689's current affinity list: 0-7
# taskset -c -p 3580
pid 3580's current affinity list: 0-7
可以通过taskset让其固定在0-1号cpu上运行:
# taskset -c 0,1 -p 6689
这样做的原理是每当进程在切换到下一个cpu core上进会flush当前的cache数据,指定CPU时会减少这样的操作,增加进程的处理速度,这个对老的程序调优时比较有效。
Output is broken up into six sections:
1. procs
2. memory
3. swap
4. io
5. system
6. cpu
Procs
r: The number of processes waiting for run time.
b: The number of processes in uninterruptible sleep.
Memory
swpd: the amount of virtual memory used.
free: the amount of idle memory.
buff: the amount of memory used as buffers.
cache: the amount of memory used as cache.
inact: the amount of inactive memory.(-a option)
active: the amount of active memory.(-a option)
Swap
si: Amount of memory swapped in from disk (/s).
so: Amount of memory swapped to disk (/s).
IO
bi: Blocks received from a block device (blocks/s).
bo: Blocks sent to a block device (blocks/s).
System
in: The number of interrupts per second, including the clock.
cs: The number of context switches per second.
CPU
These are percentages of total CPU time.
us: Time spent running non-kernel code. (user time, including nice time)
sy: Time spent running kernel code. (system time)
id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle.
st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
procs
The first two columns give information about processes:
| r | Number of processes that are in a wait state. These processes are not doing anything but waiting to run. |
| b | Number of processes that were in sleep mode and were interrupted since the last update |
memory
The next four columns give information about memory:
| swpd | Amount of virtual memory used |
| free | Amount of idle memory |
| buff | Amount of memory used as buffers |
| cache | Amount of memory used as cache |
swap
The next two columns give information about swap:
| si | Amount of memory swapped in from disk (per second) |
| so | Amount of memory swapped out to disk (per second) |
Nonzero si and so numbers indicate that there is not enough physical memory and that the kernel is swapping memory to disk.
io
The first two columns give information about I/O (input-output):
| bi | Number of blocks per second received from a block device |
| bo | Number of blocks per second sent to a block device |
system
The next two columns give the following system information:
| in | Number of interrupts per second, including the clock |
| cs | Number of context switches per second |
cpu
The last five columns give the percentages of total CPU time:
| us | Percentage of CPU cycles spent on user processes. (user time, including nice time) |
| sy | Percentage of CPU cycles spent on system (kernel) processes. (system time) |
| id | Percentage of CPU cycles spent idle. Prior to Linux 2.5.41, this includes IO-wait time. |
| wa | Percentage of CPU cycles spent waiting for I/O. Prior to Linux 2.5.41, included in idle. |
| st | Percentage of CPU cycles stolen from a virtual machine. Prior to Linux 2.6.11, unknown. |
Commandline options
Additional information can be included by providing different options to the vmstat command. Some of the command-line options are listed:
| -a | Display active and inactive memory. |
| -f | Display the number of forks since boot. |
| -t | Add a time stamp to the output. |
| -d | Report the disk statistics. |
Field Description For Disk Mode
Reads:
| total | Total reads completed successfully |
| merged | grouped reads (resulting in one I/O) |
| sectors | Sectors read successfully |
| ms | milliseconds spent reading |
Writes:
| total | Total writes completed successfully |
| merged | grouped writes (resulting in one I/O) |
| sectors | Sectors written successfully |
| ms | milliseconds spent writing |
IO:
| cur | I/O in progress |
| s | seconds spent for I/O |
Field Description For Disk Partition Mode
| reads | Total number of reads issued to this partition |
| read sectors | Total read sectors for partition |
| writes | Total number of writes issued to this partition |
| requested writes | Total number of write requests made for partition |
Field Description For Slab Mode
| cache | Cache name |
| num | Number of currently active objects |
| total | Total number of available objects |
| size | Size of each object |
| pages | Number of pages with at least one active object |
虚拟内存运行原理简述
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。经管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)。
关于上下文切换
1、上下文切换的理解
什么是上下文件切换呢:A context switch (also sometimes referred to as a process switch or a task switch) is the switching of the CPU (central processing unit) from one process or thread to another.更详细的说明可以参看linfo站点或维基百科 。
context switch过高会导致CPU像个搬运工,频繁在寄存器和运行队列之间奔波,更多的时间花在了线程切换,而不是真正工作的线程上。直接的消耗包括CPU寄存器需要保存和加载,系统调度器的代码需要执行。间接消耗在于多核cache之间的共享数据。
2、引起上下文切换的原因
对于抢占式操作系统而言, 大体有几种:
当前任务的时间片用完之后,系统CPU正常调度下一个任务;
当前任务碰到IO阻塞,调度线程将挂起此任务,继续下一个任务;
多个任务抢占锁资源,当前任务没有抢到,被调度器挂起,继续下一个任务;
用户代码挂起当前任务,让出CPU时间;
硬件中断;
什么样的操作会引起CS,这里有一篇博文感觉写的很不错,虽然其中的代码部分并不是理解 。其中有如下几句话:Linux中一个进程的时间片到期,或是有更高优先级的进程抢占时,是会发生CS的,但这些都是我们应用开发者不可控的 ---前面一部分描述的很到位,后面一部分在系统层面和kernel 开发层面可以调用nice 或 renice进行设置优先级以保证某些程序优先在CPU中的占用时间,但也不能细化到CS层面。
站在开发者的角度,我们的进程可以主动地向内核申请进行CS 。操作方法为:休眠当前进程/线程;唤醒其他进程/线程。
3、上下文切换测试工具
1)、LMbench 是带宽(读取缓存文件、内存拷贝、读写内存、管道等)和反应时间(上下文切换、网路、进程创建等)的评测工具;
2)、micro-benchmark contextswitch 可以测试不同的CPU在最少多少ns可以进行一次上下文件切换,再转化为秒,我们可以确认该处理器每可以进行的上下文件切换数,该工具的使用可以参看tsuna的blog。
4、上下文切换的查看方法
sar -w ,这个只是能看出主机上总的上下文件切换的情况
# sar -w 1
proc/s Total number of tasks created per second.
cswch/s Total number of context switches per second.
同样,vmstat也可以查看总的上下文切换情况,不过vmstart输出的结果更多,便比通过对比发现问题:
# vmstat 3
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
2 0 7292 249472 82340 2291972 0 0 0 0 0 0 7 13 79 0
0 0 7292 251808 82344 2291968 0 0 0 184 24 20090 1 1 99 0
0 0 7292 251876 82344 2291968 0 0 0 83 17 20157 1 0 99 0
0 0 7292 251876 82344 2291968 0 0 0 73 12 20116 1 0 99 0
查看每个进程或线程的上下文件使用情况,可以使用pidstat命令或者通过查看proc 。
# pidstat -w 每个进程的context switching情况
# pidstat -wt 细分到每个threads
查看proc下的文件方法如下:
# pid=307
# grep ctxt /proc/$pid/status
voluntary_ctxt_switches: 41 #自愿的上下文切换
nonvoluntary_ctxt_switches:16 #非自愿的上下文切换
cswch/s: 每秒任务主动(自愿的)切换上下文的次数,当某一任务处于阻塞等待时,将主动让出自己的CPU资源。
nvcswch/s: 每秒任务被动(不自愿的)切换上下文的次数,CPU分配给某一任务的时间片已经用完,因此将强迫该进程让出CPU的执行权。
上下文切换部分零零碎碎先到这里吧,只是想说明上下文切换还是比较重要的一个指标的。nagios check_mk默认有对上下文的监控,其使用的方法是通过两/proc/stat文件里取到ctxt行,并取两个时间段之间的差值来确认。
# cat /proc/stat|grep ctxt
ctxt 111753007
5、Linux性能之cpu上下文切换过高的情景
平均负载在不同的场景会出现不同的负载升高:
1).cpu密集型进程,使用大量cpu会导致平均负载升高,此时这两者是一致的。
2).io密集型进程,等待io也会导致平均负载升高,但cpu不一定很高。
3).大量等待cpu的进程调度也会导致平均负载升高,此时cpu使用率也会比较高。
大量进程竞争cpu(即上述场景三),往往容易被忽略的,cpu虽然没有使用,只是在竞争也会发生负载吗?
Linux是一个多任务操作系统,它支持远大于cpu数量的任务同时运行,当然这些任务不是同时运行,而是系统在很短时间内,将cpu轮流分配给它们,造成多任务同时运行的错觉。而每个任务运行前,cpu需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好cpu寄存器和程序计数器:
1).cpu寄存器:是cpu内置的容量小、但速度极快的内存。
2).程序计数器:是用来存储cpu正在执行的指令位置、或者即将执行的下一条指令位置。他们都是cpu在运行任何任务前,必须的依赖环境,因此也被叫做cpu上下文。
3).cpu上下文切换:就是先前一个任务的cpu上下文(也就是CPU寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就保证原来任务的状态不受影响,让任务看起来还是连续运行。根据任务不同,cpu的上下文切换就可以分为不同的几个场景,进程上下文切换,线程上下文切换以及中断上下文切换。下面再铺开讲一些。
CPU上下文:
PC寄存器:存放着CPU正在执行的指令或者CPU将要执行的指令;其他寄存器是CPU身边速度极快的内存,保存着其他重要的信息。
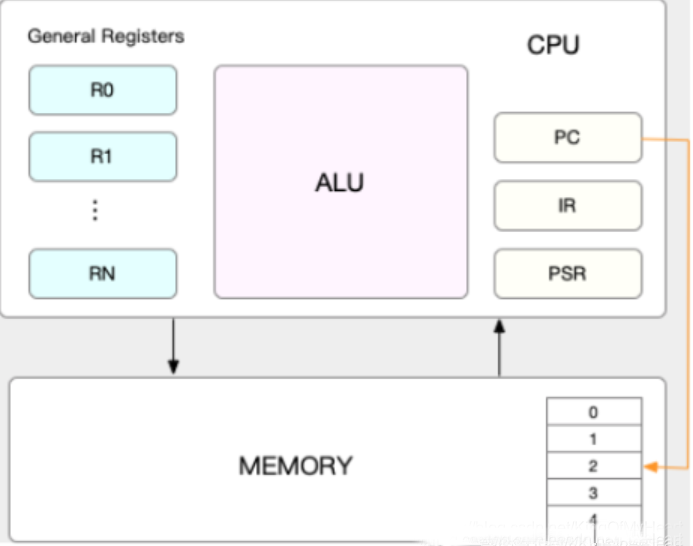
CPU上下文切换:由于任务(进程、线程或者中断)在CPU上执行时宏观看上去所有进程都在执行,实际上任务不可能独占CPU,是需要遵守CPU的调度算法,这个过程中任务是要不停的换进换出,而上下文指的就是这个某个任务执行所依赖的环境,这些信息是要被换进CPU或者换出CPU的。往往上下文的切换是比较耗时的,理想状态是更多时间花在任务的运行上,而不是上下文切换。以下是CPU上下文切换的几个场景:
系统调用带来的上下文切换:
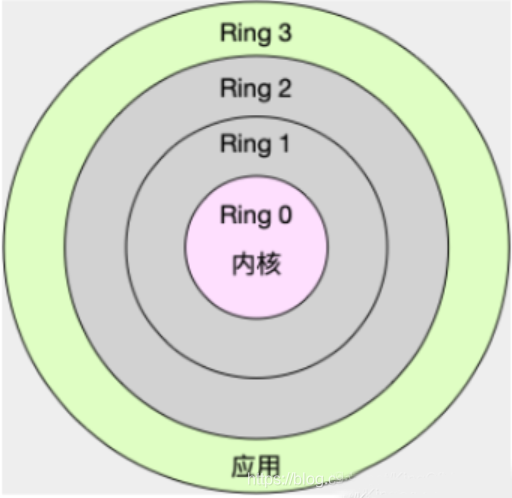
内核态:(Ring 0)执行内核代码,就是陷入内核,处于内核态。具有最高的权限,可以访问计算机的所有资源;
用户态:(Ring 3)执行用户的空间的代码,就是处于内核态;访问资源受限,需要时必须经过陷入内核,才能访问特权资源。
系统调用:内核帮管理着所有的宝贵的硬件资源,当上层应用程序需要一些硬件资源时,不能直接去取,而是需要通过操作系统预留的接口获取。此时执行用户态的代码已经不能满足了,因此将陷入内核,执行操作系统的代码,由操作系统去获取资源,然后以某种形式返回给们用户,这就是系统调用的大概过程。
系统调用详解
系统调用的上下文切换:
CPU正在执行我们的用户态代码,执行到系统调用时,触发中断,CPU将从用户态转到内核态,执行内核态代码,有没有想过CPU陷入内核前做了什么,执行完毕后又做了什么?
陷入内核前:保存当前进程的堆栈地址入栈保存,比如在用户态执行的位置等。然后将CPU寄存器的内容更新要执行的内核指令的内容,最后陷入内核,执行内核代码;
返回用户空间前:需要将内核给用户空间返回的资源,如句柄、文件描述符等保存下来,然后将CPU寄存器的内容更新为陷入内核前被压入栈的信息,然后接着执行用户态的指令。系统调用是在同一个进程中完成的。
一次系统调用需要进行两次的CPU上下文切换,实际上花费的时间是很可观的。
进程切换带来的CPU上下文切换:

Linux为每一个CPU维护一个就绪队列,将活跃进程(正在运行和正在等待CPU)按照优先级和等待CPU时间进行排序,选择最需要CPU的进程,即优先级较高和等待时间较长的进程使用CPU。
进程切换的几种常见的场景:
每个进程在CPU上执行时间被划分为好多块时间片,当某一次执行时对应的时间片用完了,这个进程就要被换下来,由调度程序根据进程的优先级和已经等待的时间决策,接下来哪个进程使用CPU;
进程运行时,发现系统的资源不够了,就会被挂起并被换下来,依然由调度程序根据进程的优先级和已经等待的时间决策,接下来哪个进程使用CPU;
当进程调用sleep等睡眠函数的时候,将自己主动的挂起,会被换下来,由调度程序根据进程的优先级和已经等待的时间决策,接下来哪个进程使用CPU;
此时有个优先级更高的进程需要紧急执行,此时当前CPU上的进程会被换下来;
发生硬件中断,当前CPU上的进程会被挂起,去执行对应的中断处理程序。
进程切换时做了什么:
先保存当前进程的虚拟内存、栈等信息,然后保存当前进程的内核状态和CPU寄存器内容。然后加载下一个进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
TLB:(Translation Lookaside Buffer)是Linux管理虚拟内存到物理内存的映射关系的。当虚拟内存更新以后,TLB也需要刷新,内存的访问也会随之变慢。
缓存刷新:
在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响影响共享缓存上的其他处理器的进程。
进程频繁的切换,进程上下文的更新时间/CPU真正运行进程时间比率会上升
使得缓存失效,命中率降低,缓存的内容也是要更新的,缓存失效可以说是很致命的
现在编程有一种手段就是禁止当前进程被换出CPU,这种方式存有争议。
线程的上下文切换:
线程的历史:在Linux上早期是没有线程这么一说的,后来可能是向其他操作系统看齐,出现了轻量级进程–也就是所看到的thread。所以,线程被看作是进程内的一条执行路径,不过当前进程内的所有线程是共享进程的数据、堆等资源的,线程有的只不过是本身所需的栈内存和一些寄存器罢了。从这里也体现了经常说的一句话:“进程是资源分配的基本单位,线程是CPU调度的基本单位”。
所谓的内核调度:实际上是线程的调度,单进程就是一个线程,此时划等号
进程只不过是给线程提供虚拟内存、共享数据等资源而已
线程切换的几个场景:
同一个进程内的线程切换,由于两个线程共享的是同一个进程的资源,所以大多数的资源是不需要切换的,需要切换的只是线程独有的栈数据和一些寄存器;不同进程的两个线程,此时等同于前面说到的进程的切换。当使用多线程编程时,同一个进程内的线程切换,耗时明显比多进程切换少得多。这也是为什么说多线程编程比多进程编程效率高的原因。但多线程的健壮性堪忧,如何抉择,还是得考虑实时的场景。
中断上下文的切换:
还有一种情况,就是为了快速响应硬件的事件,中断处理会打断进程的正常运行和调度,从而转到中断处理程序,来处理设备的事件。被打断的进程在换下来之前需要讲当前的状态保存下来,这样在中断结束以后恢复原来的状态。
中断上下文内容:
内核态中断服务程序执行所需的状态,包括CPU寄存器、内核堆栈、硬件中断参数等
由于中断会打断正常进程的调度和执行,所以大部分的中断处理程序都短小精悍,以便尽可能的执行完毕。不过,跟进程上下文切换一样,中断上下文的切换也需要消耗CPU,切换次数过多也会耗费大量的CPU。甚至严重降低系统的整体性能,所以中断次数过多的时,需要考虑中断是否给我们的系统带来严重的性能问题。
小结:
CPU上下文切换,时保证LInux系统正常工作的核心功能之一,一般情况下不需要我们特别的关注;但是过多的上下文切换,回把CPU事件消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正的运行时间,导致系统的性能大幅度的下降。
该文章最后由 阿炯 于 2023-11-22 10:05:21 更新,目前是第 2 版。