Linux内存管理入门
 Linux系统内存使用经验谈
Linux系统内存使用经验谈感谢Wiki论坛不知名的作者以及他写的FAQ:Linux Memory Management。
Linux的内存管理,实际上跟windows的内存管理有很相像的地方,都是用虚拟内存这个的概念,说到这里不得不说说MS,为什么在很多时候还有很大的物理内存的时候,却还是用到了pagefile。所以才经常要跟一帮人吵着说Pagefile的大小,以及如何分配这个问题,在Linux大家就不用再吵什么swap大小的问题,个人认为,swap设个512M已经足够了,如果你问说512M的SWAP不够用怎么办?只能说还是加内存吧,要不就检查你的应用,是不是真的出现了memory leak。在Linux下查看内存我们一般用命令'free'。
[root@freeoa ~]# free
total used free shared buffers cached
Mem: 386024 377116 8908 0 21280 155468
-/+ buffers/cache: 200368 185656
Swap: 393552 0 393552
下面是对这些数值的解释:
第二行(mem):
total:总计物理内存的大小。
used:已使用多大。
free:可用有多少。
Shared:多个进程共享的内存总额。
Buffers/cached:磁盘缓存的大小。
第三行(-/+ buffers/cached):
used:已使用多大。
free:可用有多少。
第四行就不多解释了。
区别:
第二行(mem)的used/free与第三行(-/+ buffers/cache) used/free的区别。
这两个的区别在于使用的角度来看,第一行是从OS的角度来看,因为对于OS,buffers/cached 都是属于被使用,所以他的可用内存是8908KB,已用内存是377116KB,其中包括,内核(OS)使用+Application(X,oracle,etc)使用的+buffers+cached.
第三行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。所以从应用程序的角度来说,可用内存=系统free memory+buffers+cached.
如上例:185656=8908+21280+155468
接下来解释什么时候内存会被交换,以及按什么方交换。当可用内存少于额定值的时候,就会开会进行交换。
如何看额定值(RHELv4.0):
#cat /proc/meminfo
交换将通过三个途径来减少系统中使用的物理页面的个数:
1.减少缓冲与页面cache的大小
2.将系统V类型的内存页面交换出去
3.换出或者丢弃页面(Application 占用的内存页,也就是物理内存不足)
事实上,少量地使用swap是不是影响到系统性能的。
Cache与Buffer
cache和buffer看起来好像是一种东西,Cache叫做缓存而Buffer叫做缓冲。在硬件概念中,Cache的用途是连接两种速度不同的设备,比如寄存器和内存、CPU和PCI-Bus、IDE总线和硬盘。Buffer的原意是类似弹簧的一种缓冲器,用来减轻或吸收冲击的震动的东西。Buffer是一种数据预存取的方式,它用于临时存储数据并以与接收速度不同的速度传输。Buffer的更新方式可以是按时间间隔自动刷新,而Cache则更讲究“命中率”,将当前时间段使用频繁的少量数据放到高速设备中方便读写。在程序开发中,固然没有什么高速、低速设备,不过数据源是可以有不同读写效率的。对于少量数据,文本文件的读写通常就要比数据库存取效率好,而同样是文本文件读写,在tmpfs上的效率就要比直接的磁盘IO效率好。Buffer更多地体现在进程通信和队列上,很多时候并不是因为接收方没有能力更快地读取,而是没有必要更快地读取。
下面是buffers与cached的区别。
buffers是指用来给块设备做的缓冲大小,他只记录文件系统的metadata以及 tracking in-flight pages.
Cached是用来给文件做缓冲。
那就是说:buffers是用来存储,目录里面有什么内容,权限等等。而cached直接用来记忆我们打开的文件,如果你想知道他是不是真的生效,你可以试一下,先后执行两次命令#man X ,你就可以明显的感觉到第二次的开打的速度快很多。
实验:在一台没有什么应用的机器上做会看得比较明显,记得实验只能做一次,如果想多做请换一个文件名。
#free
#man X
#free
#man X
#free
你可以先后比较一下free后显示buffers的大小,另一个实验:
#free
#ls /dev
#free
可以比较一下两个的大小,当然这个buffers随时都在增加,但你有ls过的话,增加的速度会变得快,这个就是buffers/chached的区别。
free 命令本身比较简单,所以这里的重点会放在如何通过 free 命令了解系统当前的内存使用状况,下面先解释一下输出的内容:
Mem 行(第二行)是内存的使用情况。
Swap 行(第三行)是交换空间的使用情况。
total 列显示系统总的可用物理内存和交换空间大小。
used 列显示已经被使用的物理内存和交换空间。
free 列显示还有多少物理内存和交换空间可用使用。
shared 列显示被共享使用的物理内存大小。
buff/cache 列显示被 buffer 和 cache 使用的物理内存大小。
available 列显示还可以被应用程序使用的物理内存大小。
我想只有在理解了一些基本概念之后,上面的输出才能帮助我们了解系统的内存状况。
buff/cache
先来提一个问题: buffer 和 cache 应该是两种类型的内存,但是 free 命令为什么会把它们放在一起呢?要回答这个问题需要我们做些准备工作,让我们先来搞清楚 buffer 与 cache 的含义。
buffer 在操作系统中指 buffer cache, 中文一般翻译为 "缓冲区"。要理解缓冲区,必须明确另外两个概念:"扇区" 和 "块"。扇区是设备的最小寻址单元,也叫 "硬扇区" 或 "设备块"。块是操作系统中文件系统的最小寻址单元,也叫 "文件块" 或 "I/O 块"。每个块包含一个或多个扇区,但大小不能超过一个页面,所以一个页可以容纳一个或多个内存中的块。当一个块被调入内存时,它要存储在一个缓冲区中。每个缓冲区与一个块对应,它相当于是磁盘块在内存中的表示(下图来自互联网):
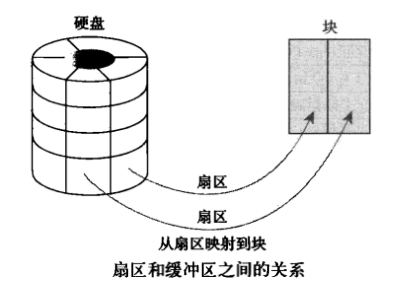
注意,buffer cache 只有块的概念而没有文件的概念,它只是把磁盘上的块直接搬到内存中而不关心块中究竟存放的是什么格式的文件。
cache 在操作系统中指 page cache,中文一般翻译为 "页高速缓存",它是内核实现的磁盘缓存。它主要用来减少对磁盘的 I/O 操作。具体地讲,是通过把磁盘中的数据缓存到物理内存中,把对磁盘的访问变为对物理内存的访问。页高速缓存缓存的是内存页面,缓存中的页来自对普通文件、块设备文件(这个指的就是 buffer cache)和内存映射文件的读写。
页高速缓存对普通文件的缓存我们可以这样理解:当内核要读一个文件(比如/etc/hosts)时,它会先检查这个文件的数据是不是已经在页高速缓存中了。如果在,就放弃访问磁盘,直接从内存中读取。这个行为称为缓存命中。如果数据不在缓存中,就是未命中缓存,此时内核就要调度块 I/O 操作从磁盘去读取数据。然后内核将读来的数据放入页高速缓存中。这种缓存的目标是文件系统可以识别的文件(比如 /etc/hosts)。页高速缓存对块设备文件的缓存就是我们在前面介绍的 buffer cahce。因为独立的磁盘块通过缓冲区也被存入了页高速缓存(缓冲区最终是由页高速缓存来承载的)。
到这里我们应该搞清楚了:无论是缓冲区还是页高速缓存,它们的实现方式都是一样的。缓冲区只不过是一种概念上比较特殊的页高速缓存罢了。那么为什么 free 命令不直接称为 cache 而非要写成 buff/cache? 这是因为缓冲区和页高速缓存的实现并非天生就是统一的。在 linux 内核 2.4 中才将它们统一。更早的内核中有两个独立的磁盘缓存:页高速缓存和缓冲区高速缓存。前者缓存页面,后者缓存缓冲区。当你知道了这些故事之后,输出中列的名称可能已经不再重要了。
free 与 available
在 free 命令的输出中,有一个 free 列,同时还有一个 available 列,这二者到底有何区别?
free 是真正尚未被使用的物理内存数量。至于 available 就比较有意思了,它是从应用程序的角度看到的可用内存数量。Linux 内核为了提升磁盘操作的性能,会消耗一部分内存去缓存磁盘数据,就是我们介绍的 buffer 和 cache。所以对于内核来说,buffer 和 cache 都属于已经被使用的内存。当应用程序需要内存时,如果没有足够的 free 内存可以用,内核就会从 buffer 和 cache 中回收内存来满足应用程序的请求。所以从应用程序的角度来说,available = free + buffer + cache。请注意,这只是一个很理想的计算方式,实际中的数据往往有较大的误差。
交换空间(swap space)
swap space 是磁盘上的一块区域,可以是一个分区,也可以是一个文件,所以具体的实现可以是 swap 分区也可以是 swap 文件。当系统物理内存吃紧时,Linux 会将内存中不常访问的数据保存到 swap 上,这样系统就有更多的物理内存为各个进程服务,而当系统需要访问 swap 上存储的内容时,再将 swap 上的数据加载到内存中,这就是常说的换出和换入。交换空间可以在一定程度上缓解内存不足的情况,但是它需要读写磁盘数据,所以性能不是很高。
现在的机器一般都不太缺内存,如果系统默认还是使用了 swap 是不是会拖累系统的性能?理论上是的,但实际上可能性并不是很大。并且内核提供了一个叫做 swappiness 的参数,用于配置需要将内存中不常用的数据移到 swap 中去的紧迫程度。这个参数的取值范围是 0~100,0 告诉内核尽可能的不要将内存数据移到 swap 中,也即只有在迫不得已的情况下才这么做,而 100 告诉内核只要有可能,尽量的将内存中不常访问的数据移到 swap 中。swappiness 的默认值是 60,如果我们觉着内存充足,可以在 /etc/sysctl.conf 文件中设置 swappiness:
vm.swappiness=10
如果系统的内存不足,则需要根据物理内存的大小来设置交换空间的大小。在虚拟内存都不够用且不能在扩充交换分区的情况下,在分区上创建交换文件来解决此问题(Linux Create and Use Swap File)。
查看现在内存(物理+虚拟)使用情况:
free -h
查看swap的使用情况:
swapon --show
NAME TYPE SIZE USED PRIO
/dev/dm-1 partition 2G 1950.1M -2
看上去已经很紧张了,但已经没有更多的硬盘空间来扩充其,但分区中还是有不少的空间。
创建交换文件(30G,与系统原有的一共32G):
dd if=/dev/zero of=/swapfile bs=1024 count=31457280
chmod 600 /swapfile
制作swap文件格式
mkswap /swapfile
开启并加入系统
swapon /swapfile && swapon --show
查看内存使用情况以确认上述操作是否成功
free -m
成功加入后可能是这样:
NAME TYPE SIZE USED PRIO
/dev/dm-1 partition 2G 1560.1M -2
/swapfile file 30G 0B -3
做成开机自加入
echo '/swapfile none swap sw 0 0' | tee -a /etc/fstab
调整swappiness
查看其值
cat /proc/sys/vm/swappiness
即时修改
sysctl vm.swappiness=10
OR
echo 10 > /proc/sys/vm/swappiness
永久修改
sysctl vm.swappiness=10
OR
echo 'vm.swappiness=10' >> /etc/sysctl.conf
关闭并清理swapfile
将其从系统中移除(如果可行的话)
swapoff -v /swapfile
从/etc/fstab中移除或注释
移除其文件
rm -fv /swapfile
内存泄漏
定义:一般我们常说的内存泄漏是指堆内存的泄漏。堆内存是指程序从堆中分配的,大小任意的(内存块的大小可以在程序运行期决定),使用完后必须显示释放的内存。应用程序一般使用malloc,realloc,new等函数从堆中分配到一块内存,使用完后,程序必须负责相应的调用free或delete释放该内存块,否则,这块内存就不能被再次使用,我们就说这块内存泄漏了。广义的说,内存泄漏不仅仅包含堆内存的泄漏,还包含系统资源的泄漏(resource leak),比如核心态HANDLE,GDI Object,SOCKET,Interface等,从根本上说这些由操作系统分配的对象也消耗内存,如果这些对象发生泄漏最终也会导致内存的泄漏。而且,某些对象消耗的是核心态内存,这些对象严重泄漏时会导致整个操作系统不稳定。所以相比之下,系统资源的泄漏比堆内存的泄漏更为严重。
泄漏的分类:
以发生的方式来分类,内存泄漏可以分为4类:
1. 常发性内存泄漏。发生内存泄漏的代码会被多次执行到,每次被执行的时候都会导致一块内存泄漏。
2.偶发性内存泄漏。发生内存泄漏的代码只有在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。
3.一次性内存泄漏。发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块仅且一块内存发生泄漏。比如,在类的构造函数中分配内存,在析构函数中却没有释放该内存,所以内存泄漏只会发生一次。
4.隐式内存泄漏。程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏。
从用户使用程序的角度来看,内存泄漏本身不会产生什么危害,作为一般的用户,根本感觉不到内存泄漏的存在。真正有危害的是内存泄漏的堆积,这会最终消耗尽系统所有的内存。从这个角度来说,一次性内存泄漏并没有什么危害,因为它不会堆积,而隐式内存泄漏危害性则非常大,因为较之于常发性和偶发性内存泄漏它更难被检测到。
从测试方面来讲:
如果Process\Private Bytes计数器和Process\Working Set计数器的值持续升高,同时Memory\Available bytes计数器的值缺却持续降低的话,说明很有可能是存在内存泄漏。
内存泄漏检测工具
1. ccmalloc-Linux和Solaris下对C和C++程序的简单的使用内存泄漏和malloc调试库。
2. Dmalloc-Debug Malloc Library.
3. Electric Fence-Linux分发版中由Bruce Perens编写的malloc()调试库。
4. Leaky-Linux下检测内存泄漏的程序。
5. LeakTracer-Linux、Solaris和HP-UX下跟踪和分析C++程序中的内存泄漏。
6. MEMWATCH-由Johan Lindh编写,是一个开放源代码C语言内存错误检测工具,主要是通过gcc的precessor来进行。
7. Valgrind-Debugging and profiling Linux programs, aiming at programs written in C and C++.
8. KCachegrind-A visualization tool for the profiling data generated by Cachegrind and Calltree.
9. Leak Monitor-一个Firefox扩展,能找出跟Firefox相关的泄漏类型。
10. IE Leak Detector (Drip/IE Sieve)-Drip和IE Sieve leak detectors帮助网页开发员提升动态网页性能通过报告可避免的因为IE局限的内存泄漏。
11. Windows Leaks Detector-探测任何Win32应用程序中的任何资源泄漏(内存,句柄等),基于Win API调用钩子。
12. SAP Memory Analyzer-是一款开源的JAVA内存分析软件,可用于辅助查找JAVA程序的内存泄漏,能容易找到大块内存并验证谁在一直占用它,它是基于 Eclipse RCP(Rich Client Platform),可以下载RCP的独立版本或者Eclipse的插件。
13. DTrace-即动态跟踪Dynamic Tracing,是一款开源软件,能在Unix类似平台运行,用户能够动态检测操作系统内核和用户进程,以更精确地掌握系统的资源使用状况,提高系统性能,减少支持成本,并进行有效的调节。
14. IBM Rational PurifyPlus-帮助开发人员查明C/C++、托管.NET、Java和VB6代码中的性能和可靠性错误。PurifyPlus 将内存错误和泄漏检测、应用程序性能描述、代码覆盖分析等功能组合在一个单一、完整的工具包中。
15. Parasoft Insure++-针对C/C++应用的运行时错误自动检测工具,它能够自动监测C/C++程序,发现其中存在着的内存破坏、内存泄漏、指针错误和I/O 等错误。并通过使用一系列独特的技术(SCI技术和变异测试等),彻底的检查和测试我们的代码,精确定位错误的准确位置并给出详细的诊断信息。能作为 Microsoft Visual C++的一个插件运行。
16. Compuware DevPartner for Visual C++ BoundsChecker Suite-为C++开发者设计的运行错误检测和调试工具软件。作为Microsoft Visual Studio和C++ 6.0的一个插件运行。
17. Electric Software GlowCode-包括内存泄漏检查,code profiler,函数调用跟踪等功能。给C++和.Net开发者提供完整的错误诊断,和运行时性能分析工具包。
18. Compuware DevPartner Java Edition-包含Java内存检测,代码覆盖率测试,代码性能测试,线程死锁,分布式应用等几大功能模块。
19. Quest JProbe-分析Java的内存泄漏。
20. ej-technologies JProfiler-一个全功能的Java剖析工具,专用于分析J2SE和J2EE应用程序。它把CPU、执行绪和内存的剖析组合在一个强大的应用中。JProfiler可提供许多IDE整合和应用服务器整合用途。JProfiler直觉式的GUI让你可以找到效能瓶颈、抓出内存泄漏、并解决执行绪的问题。
21. BEA JRockit-用来诊断Java内存泄漏并指出根本原因,专门针对Intel平台并得到优化,能在Intel硬件上获得最高的性能。
22. SciTech Software AB .NET Memory Profiler-找到内存泄漏并优化内存使用针对C#,VB.Net,或其它.Net程序。
23. YourKit .NET & Java Profiler-业界领先的Java和.NET程序性能分析工具。
24. AutomatedQA AQTime-AutomatedQA的获奖产品performance profiling和memory debugging工具集的下一代替换产品,支持Microsoft, Borland, Intel, Compaq 和 GNU编译器。可以为.NET和Windows程序生成全面细致的报告,从而帮助您轻松隔离并排除代码中含有的性能问题和内存/资源泄露问题。支持.Net 1.0,1.1,2.0,3.0和Windows 32/64位应用程序。
25. JavaScript Memory Leak Detector-微软全球产品开发欧洲团队(Global Product Development- Europe team, GPDE) 发布的一款调试工具,用来探测JavaScript代码中的内存泄漏,运行为IE系列的一个插件。
什么是系统资源?
当应用程序在Windows中运行时,Windows必须实时"跟踪"该应用程序的运行,并保留与之相关的许多信息,如按钮、光标、菜单的位置和位图、窗口的状况等,这些信息由Windows保留在一种叫堆的内存块中,堆的英文为Heap。简单地说,堆是采用特殊机制管理的内存块。由Windows的一个系统内核User.exe管理的堆叫做User资源堆(User Resource Heap),由另一个系统内核Gdi.exe管理的堆叫做GDI资源堆(Graphical Device Interface Resource Heap,简称GDI Resource Heap),User资源堆和GDI资源堆合称为系统资源堆(System Resource Heap),习惯上就把它们叫做系统资源(System Resource)。
微软将Windows的系统资源(堆)分为五个堆,其中User资源堆为三个,而GDI资源堆为两个。三个User资源堆分别是:16位的用户堆(User Heap,64KB);32位的窗口堆(Windows Heap,2MB);32位的用户菜单堆(User Menu Heap,2MB)。 两个GDI资源堆分别是:16位的GDI堆(GDI Heap,64KB);32位的GDI堆(GDI,2MB)。
从这里的系统资源分类和大小我们应该明白,不管CPU是P4还是486,内存是8M还是1G,所有Windows的用户都拥有同样大小的系统资源(堆),用户不能自已增加或减少系统资源的大小,这是由操作系统决定的,与硬件档次没有任何关系。Windows的User资源堆和GDI资源堆的可用(Free)空间称为可用 User资源和可用GDI资源,Windows中以百分数表示它们,用户可以选择 "开始/附件/系统工具/系统信息",来实时查看它们的大小。
内存管理内幕
Linux?程序员可以使用的内存管理技术进行概述,虽然关注的重点是C语言,但同样也适用于其他语言。文中将为您提供如何管理内存的细节,然后将进一步展示如何手工管理内存,如何使用引用计数或者内存池来半手工地管理内存,以及如何使用垃圾收集自动管理内存。
为什么必须管理内存
内存管理是计算机编程最为基本的领域之一。在很多脚本语言中,您不必担心内存是如何管理的,这并不能使得内存管理的重要性有一点点降低。对实际编程来说,理解您的内存管理器的能力与局限性至关重要。在大部分系统语言中,比如 C 和 C++,您必须进行内存管理。本文将介绍手工的、半手工的以及自动的内存管理实践的基本概念。
追溯到在 Apple II 上进行汇编语言编程的时代,那时内存管理还不是个大问题。您实际上在运行整个系统。系统有多少内存,您就有多少内存。您甚至不必费心思去弄明白它有多少内存,因为每一台机器的内存数量都相同。所以,如果内存需要非常固定,那么您只需要选择一个内存范围并使用它即可。不过,即使是在这样一个简单的计算机中,您也会有问题,尤其是当您不知道程序的每个部分将需要多少内存时。如果您的空间有限,而内存需求是变化的,那么您需要一些方法来满足这些需求:
* 确定您是否有足够的内存来处理数据。
* 从可用的内存中获取一部分内存。
* 向可用内存池(pool)中返回部分内存,以使其可以由程序的其他部分或者其他程序使用。
实现这些需求的程序库称为分配程序(allocators),因为它们负责分配和回收内存。程序的动态性越强,内存管理就越重要,您的内存分配程序的选择也就更重要。让我们来了解可用于内存管理的不同方法,它们的好处与不足,以及它们最适用的情形。
C 风格的内存分配程序
C 编程语言提供了两个函数来满足我们的三个需求:
* malloc:该函数分配给定的字节数,并返回一个指向它们的指针。如果没有足够的可用内存,那么它返回一个空指针。
* free:该函数获得指向由 malloc 分配的内存片段的指针,并将其释放,以便以后的程序或操作系统使用(实际上,一些 malloc 实现只能将内存归还给程序,而无法将内存归还给操作系统)。
物理内存和虚拟内存
要理解内存在程序中是如何分配的,首先需要理解如何将内存从操作系统分配给程序。计算机上的每一个进程都认为自己可以访问所有的物理内存。显然,由于同时在运行多个程序,所以每个进程不可能拥有全部内存。实际上,这些进程使用的是 虚拟内存。
只是作为一个例子,让我们假定您的程序正在访问地址为 629 的内存。不过,虚拟内存系统不需要将其存储在位置为 629 的 RAM 中。实际上,它甚至可以不在 RAM 中 —— 如果物理 RAM 已经满了,它甚至可能已经被转移到硬盘上!由于这类地址不必反映内存所在的物理位置,所以它们被称为虚拟内存。操作系统维持着一个虚拟地址到物理地址的转换的表,以便计算机硬件可以正确地响应地址请求。并且,如果地址在硬盘上而不是在 RAM 中,那么操作系统将暂时停止您的进程,将其他内存转存到硬盘中,从硬盘上加载被请求的内存,然后再重新启动您的进程。这样,每个进程都获得了自己可以使用的地址空间,可以访问比您物理上安装的内存更多的内存。
在 32-位 x86 系统上,每一个进程可以访问 4 GB 内存。现在,大部分人的系统上并没有 4 GB 内存,即使您将 swap 也算上,每个进程所使用的内存也肯定少于 4 GB。因此,当加载一个进程时,它会得到一个取决于某个称为系统中断点(system break)的特定地址的初始内存分配。该地址之后是未被映射的内存 —— 用于在 RAM 或者硬盘中没有分配相应物理位置的内存。因此,如果一个进程运行超出了它初始分配的内存,那么它必须请求操作系统“映射进来(map in)”更多的内存。(映射是一个表示一一对应关系的数学术语 —— 当内存的虚拟地址有一个对应的物理地址来存储内存内容时,该内存将被映射。)
基于 UNIX 的系统有两个可映射到附加内存中的基本系统调用:
* brk:brk() 是一个非常简单的系统调用。还记得系统中断点吗?该位置是进程映射的内存边界。 brk() 只是简单地将这个位置向前或者向后移动,就可以向进程添加内存或者从进程取走内存。
* mmap:mmap(),或者说是“内存映像”,类似于 brk(),但是更为灵活。首先,它可以映射任何位置的内存,而不单单只局限于进程。其次,它不仅可以将虚拟地址映射到物理的 RAM 或者 swap,它还可以将它们映射到文件和文件位置,这样,读写内存将对文件中的数据进行读写。不过,在这里,我们只关心 mmap 向进程添加被映射的内存的能力。 munmap() 所做的事情与 mmap() 相反。
如您所见, brk() 或者 mmap() 都可以用来向我们的进程添加额外的虚拟内存。在我们的例子中将使用 brk(),因为它更简单,更通用。
使用池式内存分配的益处如下所示:
* 应用程序可以简单地管理内存。
* 内存分配和回收更快,因为每次都是在一个池中完成的。分配可以在 O(1) 时间内完成,释放内存池所需时间也差不多(实际上是 O(n) 时间,不过在大部分情况下会除以一个大的因数,使其变成 O(1))。
* 可以预先分配错误处理池(Error-handling pools),以便程序在常规内存被耗尽时仍可以恢复。
* 有非常易于使用的标准实现。
池式内存的缺点是:
* 内存池只适用于操作可以分阶段的程序。
* 内存池通常不能与第三方库很好地合作。
* 如果程序的结构发生变化,则不得不修改内存池,这可能会导致内存管理系统的重新设计。
* 您必须记住需要从哪个池进行分配。另外,如果在这里出错,就很难捕获该内存池。
垃圾收集
垃圾收集(Garbage collection)是全自动地检测并移除不再使用的数据对象。垃圾收集器通常会在当可用内存减少到少于一个具体的阈值时运行。通常,它们以程序所知的可用的一组“基本”数据——栈数据、全局变量、寄存器——作为出发点。然后它们尝试去追踪通过这些数据连接到每一块数据。收集器找到的都是有用的数据;它没有找到的就是垃圾,可以被销毁并重新使用这些无用的数据。为了有效地管理内存,很多类型的垃圾收集器都需要知道数据结构内部指针的规划,所以为了正确运行垃圾收集器,它们必须是语言本身的一部分。
收集器的类型
* 复制(copying): 这些收集器将内存存储器分为两部分,只允许数据驻留在其中一部分上。它们定时地从“基本”的元素开始将数据从一部分复制到另一部分。内存新近被占用的部分现在成为活动的,另一部分上的所有内容都认为是垃圾。另外,当进行这项复制操作时,所有指针都必须被更新为指向每个内存条目的新位置。因此,为使用这种垃圾收集方法,垃圾收集器必须与编程语言集成在一起。
* 标记并清理(Mark and sweep):每一块数据都被加上一个标签。不定期的,所有标签都被设置为 0,收集器从“基本”的元素开始遍历数据。当它遇到内存时,就将标签标记为 1。最后没有被标记为 1 的所有内容都认为是垃圾,以后分配内存时会重新使用它们。
*增量的(Incremental):增量垃圾收集器不需要遍历全部数据对象。因为在收集期间的突然等待,也因为与访问所有当前数据相关的缓存问题(所有内容都不得不被页入(page-in)),遍历所有内存会引发问题。增量收集器避免了这些问题。
* 保守的(Conservative):保守的垃圾收集器在管理内存时不需要知道与数据结构相关的任何信息。它们只查看所有数据类型,并假定它们 可以全部都是指针。所以,如果一个字节序列可以是一个指向一块被分配的内存的指针,那么收集器就将其标记为正在被引用。有时没有被引用的内存会被收集,这样会引发问题,例如,如果一个整数域中包含一个值,该值是已分配内存的地址。不过,这种情况极少发生,而且它只会浪费少量内存。保守的收集器的优势是,它们可以与任何编程语言相集成。
Hans Boehm 的保守垃圾收集器是可用的最流行的垃圾收集器之一,因为它是免费的,而且既是保守的又是增量的,可以使用 --enable-redirect-malloc 选项来构建它,并且可以将它用作系统分配程序的简易替代者(drop-in replacement)(用 malloc/ free 代替它自己的 API)。实际上,如果这样做,您就可以使用与我们在示例分配程序中所使用的相同的 LD_PRELOAD 技巧,在系统上的几乎任何程序中启用垃圾收集。如果您怀疑某个程序正在泄漏内存,那么您可以使用这个垃圾收集器来控制进程。在早期,当 Mozilla 严重地泄漏内存时,很多人在其中使用了这项技术。这种垃圾收集器既可以在 Windows? 下运行,也可以在 UNIX 下运行。
垃圾收集的一些优点:
* 您永远不必担心内存的双重释放或者对象的生命周期。
* 使用某些收集器,您可以使用与常规分配相同的 API。
其缺点包括:
* 使用大部分收集器时,您都无法干涉何时释放内存。
* 在多数情况下,垃圾收集比其他形式的内存管理更慢。
* 垃圾收集错误引发的缺陷难于调试。
* 如果忘记将不再使用的指针设置为 null,那么仍然会有内存泄漏。
结束语
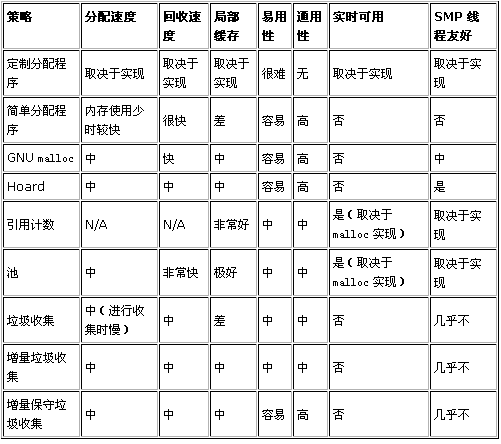
一切都需要折衷:性能、易用、易于实现、支持线程的能力等,这里只列出了其中的一些。为了满足项目的要求,有很多内存管理模式可以供您使用。每种模式都有大量的实现,各有其优缺点。对很多项目来说,使用编程环境默认的技术就足够了,不过当项目有特殊的需要时,了解可用的选择将会有帮助。下表对比了本文中涉及的内存管理策略。
表:内存分配策略的对比
Buffer和Cache概述
从字面意思来看,Buffer 是缓冲区,Cache 是缓存 。它们都用于在内存中临时存储数据,但这两种 “临时存储” 又有着明显的区别。就好像你出门旅行,会带一个行李箱和一个随身小包。行李箱可以类比为 Buffer,它用来存放暂时不用,但后续可能会用到的物品,这些物品就像等待传输到其他设备的数据。而随身小包就像 Cache,里面装着你随时可能会用到的东西,比如手机、钱包,这些物品就像被频繁访问的数据,放在小包里能让你快速拿到,就像数据被缓存起来能被快速读取一样。
在 Linux 系统中可以通过free命令来查看内存的使用情况 。打开终端,输入free -h(-h参数是为了让输出结果更易读),会看到类似的信息。在这些信息中,buff/cache这一列引起了人们的注意,它就是 Buffer 和 Cache 的内存使用总和。而实际上,free命令的统计数据是来自于/proc/meminfo这个文件 。用cat /proc/meminfo命令查看,会看到更详细的内存信息,其中Buffers和Cached这两个字段,分别对应着 Buffer 和 Cache 使用的内存大小 。
那么Buffers、Cached和SReclaimable具体是什么含义呢?Buffers是内核缓冲区用到的内存,它主要用于缓存磁盘的数据。比如当向磁盘写入数据时,数据不会立刻被写入磁盘,而是先存储在Buffers中,等积累到一定量或者满足特定条件时,再统一写入磁盘,这样可以减少磁盘 I/O 的次数,提高写入效率。Cached是内核页缓存和 Slab 用到的内存,主要用于缓存从文件读取的数据 。
当读取一个文件时,数据会被缓存到Cached中,如果下次再读取相同的文件内容,就可以直接从内存中获取,大大加快了读取速度 。SReclaimable是 Slab 的一部分,Slab 是内核中用于管理内存的一种机制,SReclaimable表示 Slab 中可回收的部分 。
Buffer与Cache工作原理
1.Buffer的工作原理
Buffer 就像是数据传输过程中的一个临时停靠站 。当计算机与不同速度的设备进行数据交换时,比如内存与硬盘之间,由于硬盘的读写速度相对内存来说非常慢,如果没有 Buffer,内存就需要一直等待硬盘完成数据传输,这会极大地浪费内存的性能 。而有了 Buffer,当内存要向硬盘写入数据时,数据会先被存储到 Buffer 中 。假设我们要将一个大文件写入硬盘,文件数据会按一定大小的块依次存入 Buffer 。
当 Buffer 中的数据达到一定量(比如一个磁盘块的大小),或者满足特定的写入条件(如操作系统的写入调度策略)时,这些数据就会被一次性写入硬盘 。这样做的好处是,减少了硬盘的读写次数 。因为如果每次有少量数据就直接写入硬盘,硬盘的磁头需要频繁移动来定位数据位置,这会花费大量时间 。而通过 Buffer 的缓冲,将分散的小写入操作合并成大的写入操作,大大提高了数据传输的效率 。
同时,在数据读取时,Buffer 也起着类似的作用 。当从硬盘读取数据时,硬盘会将数据先读取到 Buffer 中,内存再从 Buffer 中读取数据,这就避免了内存直接与速度较慢的硬盘频繁交互,保证了数据传输的稳定性和高效性 。
当应用程序请求从磁盘读取数据时,内核会先检查Buffer中是否已经存在相应的数据块。如果存在,内核会直接从Buffer返回数据,避免了对物理磁盘的读取。如果数据不在Buffer中,内核会将数据块从磁盘读取到Buffer中,并返回给应用程序。这样,Buffer在一定程度上减少了对磁盘的访问次数,提高了I/O性能。
相关系统参数
(1)dirty_ratio
echo 20 > /proc/sys/vm/dirty_ratio
或
sysctl -w vm.dirty_ratio=20
作用: dirty_ratio 参数定义了系统内存中脏页(已被修改但尚未写入磁盘)的最大比例。当脏页的比例达到或超过此值时,系统将启动同步写入操作,将脏页写入磁盘。
影响: 控制脏页的及时写入,适当设置有助于避免频繁的磁盘写入操作。
配置方式(参数的单位是百分比)
(2)dirty_background_ratio
echo 10 > /proc/sys/vm/dirty_background_ratio
或
sysctl -w vm.dirty_background_ratio=10
作用:dirty_background_ratio 参数定义了当脏页的比例超过此值时,系统会触发后台写入操作。后台写入是指将脏页异步地写入磁盘,不会引起进程阻塞。
影响: 控制后台写入的启动条件,避免系统过早地触发写入操作,从而提高系统性能。
配置方式, 可通过修改 /proc/sys/vm/dirty_background_ratio 文件或使用 sysctl 命令进行配置。(参数的单位是百分比)
2.Cache:加速系统的秘密武器
Cache 的工作原理基于程序的局部性原理,即程序在一段时间内访问的数据往往集中在一个较小的区域。它就像一个数据的“快速通道”,将经常访问的数据复制到内存中速度更快的区域 。以数据库查询为例,当我们执行一个数据库查询语句时,查询结果会被存储在 Cache 中 。如果下次再执行相同或相似的查询语句,系统会首先检查 Cache 中是否已经存在该结果 。如果存在,就直接从 Cache 中读取数据返回给用户,而不需要再次执行复杂的数据库查询操作 。这大大减少了数据访问的时间,提高了系统的响应速度 。
Cache 通常采用一些替换算法,如最近最少使用(LRU)算法,来决定当 Cache 空间不足时,哪些数据需要被替换出去 。LRU 算法会将最近一段时间内最少被访问的数据替换掉,这样可以保证 Cache 中始终保存着最有可能被再次访问的数据 。除了数据库查询,Cache 在 CPU 与内存之间也起着重要作用 。
由于 CPU 的运行速度远远快于内存,为了减少 CPU 等待内存数据的时间,在 CPU 和内存之间设置了 Cache 。CPU 首先会在 Cache 中查找需要的数据,如果找到(命中),就可以快速获取数据进行处理;如果没找到(未命中),才会从内存中读取数据,并将读取的数据同时存入 Cache 中,以便下次访问时能够更快获取 。
相关系统参数
(1)vfs_cache_pressure
echo 100 > /proc/sys/vm/vfs_cache_pressure
或
sysctl -w vm.vfs_cache_pressure=100
作用: vfs_cache_pressure 参数用于调整内核对 dentry 和 inode 缓存的倾向性。较大的值使内核倾向于回收 dentry,而较小的值使内核倾向于回收 inode。
影响: 控制文件系统缓存的回收策略,影响文件系统性能。较大的值有助于加速缓存的回收,从而释放内存。
配置方式: 可通过修改 /proc/sys/vm/vfs_cache_pressure 文件或使用 sysctl 命令进行配置。
例如:swappiness
echo 10 > /proc/sys/vm/swappiness
或
sysctl -w vm.swappiness=10
作用:swappiness 参数用于调整内核在内存不足时将数据移动到交换空间的倾向性。值的范围是 0 到 100,0 表示尽量不使用交换空间,100 表示尽量使用交换空间。
影响: 控制系统对交换空间的利用,较小的值有助于减少对交换空间的使用,提高整体性能。
配置方式: 可通过修改 /proc/sys/vm/swappiness 文件或使用 sysctl 命令进行配置。
3.Buffer和Cache的区别
(1)存储内容
Buffer存储的是I/O操作的数据块,通常是对物理设备的读写请求的中介。
Cache存储的是文件系统的数据块,包括文件的元数据和实际内容。
(2)读取方式
Buffer主要用于减少对物理设备的读写次数,通过缓存I/O操作提高性能。
Cache更侧重于文件系统的读取,通过缓存文件数据和元数据提高文件系统的整体读取速度。
(3)清理策略
Buffer中的数据通常被操作系统维护,不容易手动清理。
Cache的内容可以通过手动或自动的方式进行清理,以释放内存空间。
为了更直观地理解 Buffer 和 Cache 的工作方式,可通过几个实际案例来进行分析。在 Linux 系统中可以使用vmstat命令来实时监控内存和 I/O 的使用情况。打开终端,输入vmstat 1(1表示每秒输出一次数据)。这里的buff和cache分别对应 Buffer 和 Cache 使用的内存大小,单位是 KB ,bi和bo分别表示块设备读取和写入的大小,单位为块 / 秒 。由于 Linux 中块的大小是 1KB,所以这个单位也就等价于 KB/s 。
通过观察 vmstat 的输出,在dd命令运行时, Cache在不停地增长,而Buffer基本保持不变。再进一步观察I/O的情况,就会看到在 Cache 刚开始增长时,块设备 I/O 很少,bi 只出现了一次 几百KB/s,bo 则只有一次 4KB。而过一段时间后,才会出现大量的块设备写,比如 bo 变成了数万的值。当 dd 命令结束后,Cache 不再增长,但块设备写还会持续一段时间,并且多次 I/O 写的结果加起来,才是 dd 要写入的数据大小。
可行清理缓存
$ echo 3 > /proc/sys/vm/drop_caches
# 然后运行dd命令进行写测试比较合理一些
虽然同是写数据,写磁盘跟写文件的现象还是不同的。写磁盘时(也就是bo大于 0 时),Buffer和Cache都在增长,但显然Buffer的增长快得多。这说明写磁盘操作用到了大量的Buffer,这跟在文档中查到的定义是一样的。
对比两个案例会发现,写文件时会用到 Cache 缓存数据,而写磁盘则会用到 Buffer 来缓存数据。虽然文档上只提到Cache是文件读的缓存,但实际上Cache也会缓存写文件时的数据。
1.Buffer既可以用作“将要写入磁盘数据的缓存”,也可以用作“从磁盘读取数据的缓存”。
2.Cache既可以用作“从文件读取数据的页缓存”,也可以用作“写文件的页缓存”。
该文章最后由 阿炯 于 2025-07-22 11:06:48 更新,目前是第 4 版。