Linux cgroup 使用参考
 Control Groups 即Cgroup,它旨在通过一系列文件接口的方式实现对于进程的资源隔离。同时由于它映射成了一个文件系统,就拥有了文件系统的优势--嵌套管理的优势。在系统运行过程需要分配好的特定比例的 CPU、IO、内存、网络等资源,这就是 controller group ,简称为 cgroup ,最初由 Google 工程师提出,后来被整合进 Linux 内核中。cgroup 本身提供了将进程进行分组化管理的功能和接口的基础结构。
Control Groups 即Cgroup,它旨在通过一系列文件接口的方式实现对于进程的资源隔离。同时由于它映射成了一个文件系统,就拥有了文件系统的优势--嵌套管理的优势。在系统运行过程需要分配好的特定比例的 CPU、IO、内存、网络等资源,这就是 controller group ,简称为 cgroup ,最初由 Google 工程师提出,后来被整合进 Linux 内核中。cgroup 本身提供了将进程进行分组化管理的功能和接口的基础结构。---------------------------------------------------------------
一、cgroup介绍
据官方文档介绍,rhel6为内核准备了一个新特性(资源控制),也即cgroup,该服务的软件包是libcgroup。使用它之后就可以比较灵活的分配资源,例如:CPU时间片、系统内存、网络带宽等。这个是被cgconfig服务所控制的,如果此服务没有启动,在根目录下的cgroup文件夹里就不会存在相关的内容。
[root@freeoa]#/etc/init.d/cgconfig status
[root@freeoa]#/etc/init.d/cgconfig stop
[root@freeoa]#ls /cgroup
启动此服务之后,就会在/cgroup目录下面多出一些内容。
[root@freeoa cgroup]# /etc/init.d/cgconfig restart
Stopping cgconfig service: [ OK ]
Starting cgconfig service: [ OK ]
[root@freeoa cgroup]# cd /cgroup && ls
blkio cpu cpuacct cpuset devices freezer memory net_cls
cgroup各个模块(子系统)的介绍
cgroup类似与进程,他们是分等级的,各个属性都是从父进程那里继承过来。cgroup包含了多个孤立的子系统,每一个子系统代表一个单一的资源。rhel6中一共准备了9个子系统,以下是每个子系统的详细说明:
blkio -- 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
cpu -- 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
cpuacct -- 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
cpuset -- 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
devices -- 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
freezer -- 这个子系统挂起或者恢复 cgroup 中的任务。
memory -- 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成由那些任务使用的内存资源报告。
net_cls -- 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
net_prio – 此子系统提供了一种动态设置每个网络接口的网络流量优先级的方法。
ns -- 名称空间子系统。
以上多个子系统之间也存在着一定的关系,详情参阅官方文档。
如何查看当前操作系统是否支持cgroupv2,
grep cgroup /proc/filesystems
如果支持cgroupv2,将会有如下的输出:
nodev cgroup
nodev cgroup2
如果只支持cgroupv1则只有第一行。
---------------------------------------------------------------
二、cgroup的使用参考一
1、cgroup的安装:
在安装系统的时候,默认已经安装了libcgroup软件包,如果没有安装可以使用以下命令进行安装:
[root@freeoa /]# rpm -q libcgroup
libcgroup-0.36.1-6.el6.x86_64
如果没有安装请用yum安装。
2、cgroup服务的控制
将其更改为伴随系统的启动而启动
[root@freeoa /]# chkconfig --list cgconfig
cgconfig 0ff 1ff 2ff 3ff 4ff 5ff 6ff
[root@freeoa /]# chkconfig cgconfig on
[root@freeoa /]# chkconfig --list cgconfig
cgconfig 0ff 1ff 2n 3n 4n 5n 6ff
服务的停止和启动
[root@freeoa cgroup]# /etc/init.d/cgconfig stop/start
3、cgroup的配置文件cgconfig.conf文件介绍
在cgconfig.conf文件中,主要包含了两个主要类型:mount和group。mount是指创建以及挂载哪些层次为虚拟文件系统,并附上子系统的层次结构。cgconfig.conf文件的内容如下所示:
[root@freeoa /]# cat /etc/cgconfig.conf | more
# Copyright IBM Corporation. 2007
# This program is free software; you can redistribute it and/or modify it
# under the terms of version 2.1 of the GNU Lesser General Public License
# as published by the Free Software Foundation.
#
# This program is distributed in the hope that it would be useful, but
# WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
#
# See man cgconfig.conf for further details.
#
# By default, mount all controllers to /cgroup/<controller>
mount {
cpuset = /cgroup/cpuset;
cpu = /cgroup/cpu;
cpuacct = /cgroup/cpuacct;
memory = /cgroup/memory;
devices = /cgroup/devices;
freezer = /cgroup/freezer
......省略
例如cpuset=/cgroup/cputest就可以理解为以下几条命令
[root@freeoa /]# mount -t cgroup -o cpuset cpuset /cgroup/cpuset
mount: cpuset already mounted or /cgroup/cpuset busy
[root@freeoa /]# umount /cgroup/cpu
cpu/ cpuacct/ cpuset/
[root@freeoa /]# umount /cgroup/cpuset
[root@freeoa /]# mount -t cgroup -o cpuset cpuset /cgroup/cpuset
4、与cgroup相关的几个命令
lssubsys--显示已经存在的子系统。
[root@freeoa /]# lssubsys -am
cpu /cgroup/cpu
cpuacct /cgroup/cpuacct
memory /cgroup/memory
devices /cgroup/devices
freezer /cgroup/freezer
net_cls /cgroup/net_cls
blkio /cgroup/blkio
cpuset /cgroup/cpuset
ns
如上所示,除ns子系统没有在/etc/cgconfig.conf文件里设置外,其他的都挂载在对应的目录下面。使用lscgroup指令可显示所有的cgroup。
[root@freeoa /]# lscgroup
cpu:/
cpuacct:/
memory:/
devices:/
freezer:/
net_cls:/
blkio:/
cpuset:/
5、挂载与卸载子系统层次
如上所示,各个模块均以挂载与对于的目录下面,以下卸载了cpu子系统层次:
[root@freeoa /]# umount /cgroup/cpu
[root@freeoa /]# lssubsys -am #(-a代表所有,-m代表显示挂载点)
cpuacct /cgroup/cpuacct
memory /cgroup/memory
devices /cgroup/devices
freezer /cgroup/freezer
net_cls /cgroup/net_cls
blkio /cgroup/blkio
cpuset /cgroup/cpuset
ns
cpu
其他的卸载与挂载都一样,使用以下命令将其挂载回去:
[root@freeoa /]# mount -t cgroup -o cpu cpu /cgroup/cpu
[root@freeoa /]# lssubsys -am
cpuacct /cgroup/cpuacct
memory /cgroup/memory
devices /cgroup/devices
freezer /cgroup/freezer
net_cls /cgroup/net_cls
blkio /cgroup/blkio
cpuset /cgroup/cpuset
cpu /cgroup/cpu
ns
6、创建一个自定义的cgroup
这里要用到cgcreate命令,具体用法如下所示,先来看个示例:
[root@freeoa /]# cgcreate
Usage is cgcreate -t <tuid>:<tgid> -a <agid>:<auid> -g <list of controllers>:<relative path to cgroup>
[root@freeoa /]# cgcreate -g cpu,net_cls:/test-subgroup
[root@freeoa /]# lssubsys -am
cpuacct /cgroup/cpuacct
memory /cgroup/memory
devices /cgroup/devices
freezer /cgroup/freezer
net_cls /cgroup/net_cls
blkio /cgroup/blkio
cpuset /cgroup/cpuset
cpu /cgroup/cpu
ns
没有出来看到么。其实挂载上去之后,使用lssubsys命令是看不到的。因为创建完了之后,系统还不能挂载,因为挂载点不存在,等挂载点创建了之后,系统会自动挂载上去的。
7、删除cgroup
[root@freeoa /]# cgdelete
Usage is cgdelete [-r] <list of controllers>:<relative path to cgroup> [...]
---------------------------------------------------------------
三、cgroup的使用参考二
下面再介绍如何通过 libcgroup-tools 创建分组并设置资源配置参数。
1. 创建控制组群
可以通过如下方式创建以及删除群组,创建后会在 cpu 挂载目录下 /sys/fs/cgroup/cpu/ 目录下看到一个新的目录 test,这个就是新创建的 cpu 子控制组群。
# cgcreate -g cpu:/test
# cgdelete -g cpu:/test
2. 设置组群参数
cpu.shares 是控制 CPU 的一个属性,更多的属性可以到 /sys/fs/cgroup/cpu 目录下查看,默认值是 1024,值越大,能获得更多的 CPU 时间。
# cgset -r cpu.shares=512 test
3. 将进程添加到控制组群
可以直接将需要执行的命令添加到分组中。
----- 直接在cgroup中执行
# cgexec -g cpu:small some-program
----- 将现有的进程添加到cgroup中
# cgclassify -g subsystems:path_to_cgroups pidlist
例如,想把 sshd 添加到一个分组中,可以通过如下方式操作。
# cgclassify -g cpu:/test `pidof sshd`
# cat /sys/fs/cgroup/cpu/test/tasks
就会看到相应的进程在这个文件中。
-------------------------------
CPU
在 CGroup 中,与 CPU 相关的子系统有 cpusets、cpuacct 和 cpu 。
cpuset 用于设置 CPU 的亲和性,可以限制该组中的进程只在(或不在)指定的 CPU 上运行,同时还能设置内存的亲和性,一般只会在一些高性能场景使用。另外两个:cpuaccct 和 cpu 保存在相同的目录下,其中前者用来统计当前组的 CPU 统计信息。
这里简单介绍 cpu 子系统,包括怎么限制 cgroup 的 CPU 使用上限及与其它 cgroup 的相对值。
cpu.cfs_period_us & cpu.cfs_quota_us
其中 cfs_period_us 用来配置时间周期长度;cfs_quota_us 用来配置当前 cgroup 在设置的周期长度内所能使用的 CPU 时间数,两个文件配合起来设置 CPU 的使用上限。
两个文件单位是微秒,cfs_period_us 的取值范围为 [1ms, 1s],默认 100ms ;cfs_quota_us 的取值大于 1ms 即可,如果 cfs_quota_us 的值为 -1(默认值),表示不受 cpu 时间的限制。
下面是几个例子:
----- 1.限制只能使用1个CPU,每100ms能使用100ms的CPU时间
# echo 100000 > cpu.cfs_quota_us
# echo 100000 > cpu.cfs_period_us
------ 2.限制使用2个CPU核,每100ms能使用200ms的CPU时间,即使用两个内核
# echo 200000 > cpu.cfs_quota_us
# echo 100000 > cpu.cfs_period_us
------ 3.限制使用1个CPU的50%,每100ms能使用50ms的CPU时间,即使用一个CPU核心的50%
# echo 50000 > cpu.cfs_quota_us
# echo 100000 > cpu.cfs_period_us
cpu.shares
用于设置相对值,这里针对的是所有 CPU (多核),默认是 1024,假如系统中有两个 A(1024) 和 B(512),那么 A 将获得 1024/(1204+512)=66.67% 的 CPU 资源,而 B 将获得 33% 的 CPU 资源。对于 shares 有两个特点:
如果A不忙,没有使用到66%的CPU时间,那么剩余的CPU时间将会被系统分配给B,即B的CPU使用率可以超过33%;
添加了一个新的C,它的shares值是1024,那么A和C的限额变为1024/(1204+512+1024)=40%,B的资源变成了20%;
也就是说,在空闲时 shares 基本上不起作用,只有在 CPU 忙的时候起作用。但是这里设置的值是需要与其它系统进行比较,而非设置了一个绝对值。
下面演示一下如何控制CPU的使用率。
----- 创建并查看当前的分组
# cgcreate -g cpu:/small
# ls /sys/fs/cgroup/cpu/small
----- 查看当前值,默认是1024
# cat /sys/fs/cgroup/cpu/small/cpu.shares
# cgset -r cpu.shares=512 small
----- 执行需要运行的程序,或者将正在运行程序添加到分组
# cgexec -g cpu:small ./foobar
# cgclassify -g cpu:small <PID>
----- 设置只能使用1个cpu的20%的时间
# echo 50000 > cpu.cfs_period_us
# echo 10000 > cpu.cfs_quota_us
----- 将当前bash加入到该cgroup
# echo $$
5456
# echo 5456 > cgroup.procs
----- 启动一个bash内的死循环,正常情况下应该使用100%的cpu,消耗一个核
# while :; do echo test > /dev/null; done
注意,如果是在启动进程之后添加的,实际上 CPU 资源限制的速度会比较慢,不是立即就会限制死的,而且不是严格准确。如果起了多个子进程,那么各个进程之间的资源是共享的。
其它
可以通过如下命令查看进程属于哪个 cgroup 。
# ps -O cgroup
# cat /proc/PID/cgroup
-------------------------------
内存
相比来说,内存控制要简单的多,只需要注意物理内存和 SWAP 即可。
----- 创建并查看当前的分组
# cgcreate -g memory:/small
# ls /sys/fs/cgroup/memory/small
----- 查看当前值,默认是一个很大很大的值,设置为1M
# cat /sys/fs/cgroup/memory/small/memory.limit_in_bytes
# cgset -r memory.limit_in_bytes=10485760 small
----- 如果开启了swap之后,会发现实际上内存只限制了RSS,设置时需要确保没有进程在使用
# cgset -r memory.memsw.limit_in_bytes=104857600 small
----- 启动测试程序
# cgexec -g cpu:small -g memory:small ./foobar
# cgexec -g cpu,memory:small ./foobar
可以使用 x="a"; while [ true ];do x=$x$x; done; 命令进行测试。
内存回收
在通过 memory.usage_in_bytes 查询当前 cgroup 的内存资源使用情况时,如果对比当前组中进程的 RSS 资源时,可能会发现,前者要远大于后者。甚至于,当前 cgroup 中已经没有了进程,但是其内存使用量仍然很大。
构造的测试场景如下,其中 cgroup 仍然使用上述创建的组。
$ cat memory.usage_in_bytes
0
$ cgexec -g cpu:small -g memory:small dd if=/dev/sda1 of=/dev/null count=10M
10485760+0 records in
10485760+0 records out
5368709120 bytes (5.4 GB) copied, 33.8483 s, 159 MB/s
$ cat memory.usage_in_bytes
4930969600
实际这与内核处理系统内存时的机制一样,在内存足够的情况下,默认不会自动释放内存。所以看到的内存使用情况与实际不符。这样带来的问题时,如果开始设置的内存空间为 1G ,当前使用了 700M (实际 300M),当前如果想限制到 500M ,如果内存不能被回收那么可能会报错。
$ echo 524288000 > memory.limit_in_bytes
上述占用空间较大的是 buffer ,通过上述方式设置是可以被回收掉。
对于上述的场景,如果要回收所有的内存,有两种方式:
----- 释放的是系统的Buffer和Cache
# echo 3 > /proc/sys/vm/drop_caches
----- 需要保证该cgroup组下面没有进程,否者会失败
# echo 0 > memory.force_empty
OOM
当进程试图占用的内存超过了 cgroups 的限制时,会触发 out of memory 导致进程被强制 kill 掉。
----- 关闭默认的OOM
# echo 1 > memory.oom_control
# cgset -r memory.oom_control=1 small
注意,及时关闭了 OOM,对应的进程会处于 uninterruptible sleep 状态。
-------------------------------
磁盘
可以通过 blkio 进行设置,不过只能针对设备限速,例如可以设置 /dev/sda 而无法设置具体的分区。
----- 查看并选择其中的一个
# df -h
----- 直接读取某个磁盘分区
# dd if=/dev/sda1 of=/dev/null
可以通过 iotop 查看,因为是单纯的读取,其速度一般可以达到 100M/s 以上。
----- 新建一个cgroup的分组
# mkdir /sys/fs/cgroup/blkio/foobar
# cd /sys/fs/cgroup/blkio/foobar
----- 配置读取某个磁盘的最大速度,也就是1M
# echo '8:0 1048576' > blkio.throttle.read_bps_device
上述配置中的 8:0 为设备的主次设备号,可以通过 ls -l /dev/sda 查看。
在 blkio 中,除了设置,还可以监控 IO 的使用情况,所以大部分的文件都是只读的,可以配置的只有如下的几个:
blkio.throttle.read_bps_device
blkio.throttle.read_iops_device
blkio.throttle.write_bps_device
blkio.throttle.write_iops_device
blkio.weight
blkio.weight_device
其中 throttle 是用来配置流量限速的,而 weight 则是配置权重信息。blkio 子系统里还有很多统计项,用来监控当前 cgroup 的使用情况。
---------------------------------------------------------------
四、cgroup的相关排错
-------------------------------
cgroup的cpuset问题
生产中需要将某个进程强制绑定到一个指定的CPU core中,首先考虑就是这个可以直接通过cgroup的cpuset配置来实现。
先建立一个cgroup的group
root@freeoa:/sys/fs/cgroup/cpuset# cgcreate -g cpuset:foacupset
root@freeoa:/sys/fs/cgroup/cpuset# ls /sys/fs/cgroup/cpuset/ | grep test
foacupset
cpuset下面,有一个名叫foacupset的目录已经建好。现在就修改cpuset.cpus的设定,将属于该策略的所有进程都绑定到cpu的第9个core去执行。
root@freeoa:/sys/fs/cgroup/cpuset# cd /sys/fs/cgroup/cpuset/foacupset/
root@freeoa:/sys/fs/cgroup/cpuset/foacupset# echo 9 > cpuset.cpus
root@freeoa:/sys/fs/cgroup/cpuset/foacupset# cat cpuset.cpus
现在问题来了,当尝试执行cgexe用foacupset策略去起一个进程的时候,出现了问题:
root@freeoa:/sys/fs/cgroup/cpuset/foacupset# cgexec -g cpuset:foacupset sleep 1
cgroup change of group failed
cgroup change of group failed 进程无法切换到指定的cgroup
开始以为打开的方法不对,google了一下发现redhat,suse,arch,debian的社区都有类似的bug汇报,最终找到了Redhat官方的cgroup解释:Some subsystems have mandatory parameters that must be set before you can move a task into a cgroup which uses any of those subsystems. For example, before you move a task into a cgroup which uses the cpuset subsystem, the cpuset.cpus and cpuset.mems parameters must be defined for that cgroup.
作为CPUset策略生效的必要条件,cpus和Mems必须强制指定。cpus是指进程被绑定的内核,而Mems则表示cpu的NUMA内存节点。问题算是找到了,解决就比较容易了:
root@freeoa:/sys/fs/cgroup/cpuset/foacupset# echo 0-1 > cpuset.mems
root@freeoa:/sys/fs/cgroup/cpuset/foacupset# cgexec -g cpuset:foacupset ls /
也就是说,作为 cpuset 策略生效的必要条件,cpus 和 mems 必须强制指定,分别表示进程被绑定的内核,以及 cpu 的 NUMA 内存节点。
# echo "0" > /sys/fs/cgroup/cpuset/small/cpuset.mems
# cgexec -g cpuset:small sleep 1
注意,在设置 cpuset.mems 需要保证对应的 NUMA 是存在的,可以通过 numactl -H 查看。在内核中可以通过 CPUSET 限制进程只使用某几个 CPU,更准确的说是多少个几个逻辑核。实际上在 Linux 内核中,资源调度的单位是逻辑核,如果开启了超线程 (Hyper-Threading),那么单个 CPU 物理核会模拟出 2 个逻辑核。CPU 相关的信息可以通过 /proc/cpuinfo 查看,例如:
----- 物理 CPU 数量
$ cat /proc/cpuinfo | grep "physical id" | sort | uniq
----- 每块 CPU 的核心数
$ cat /proc/cpuinfo | grep "cores" | uniq
----- 查看主机总的逻辑线程数
$ cat /proc/cpuinfo | grep "processor" | wc -l
-------------------------------
Read-only file system
mkdir: cannot create directory '/sys/fs/cgroup/cpu_limit': Read-only file system
I remounted the offending filesystems with mount -o remount,rw (mount -o remount,rw /) and mount -o remount,rw /sys/fs/cgroup. re-typing mount returned all filesystems as writable.
---------------------------------------------------------------
五、使用实例与配置文件
对mongodb的备份指令限制cpu使用率,以平均系统的计算和i/o资源。
mkdir /sys/fs/cgroup/cpu/monbaklimit
50%使用率
echo 100000 > /sys/fs/cgroup/cpu/monbaklimit/cpu.cfs_period_us
echo 50000 > /sys/fs/cgroup/cpu/monbaklimit/cpu.cfs_quota_us
10%使用率
echo 100000 > /sys/fs/cgroup/monbaklimit/cpu.cfs_period_us
echo 10000 > /sys/fs/cgroup/monbaklimit/cpu.cfs_quota_us
/usr/bin/cgexec -g cpu:monbaklimit top
cgroup change of group failed
/usr/bin/cgexec -t root:root -a root:root -g cpu:cpu_limit top
在配置文件中的写法:
mount {
memory = /cgroup/memory;
cpuset = /cgroup/cpuset;
cpu = /cgroup/cpu;
}
group cpu_limit {
perm {
task {
uid = root;
gid = root;
}
admin {
uid = root;
gid = root;
}
}
}
为hadoop应用准备的cgconfig.conf文件:
###
mount{
memory = /cgroup/memory;
cpuset = /cgroup/cpuset;
cpu = /cgroup/cpu;
}
#
group hadoop-node/default {
perm {
task {
uid = hadoop;
gid = hadoop;
}
admin {
uid = root;
gid = root;
}
}
memory {
memory.limit_in_bytes="32G";
memory.memsw.limit_in_bytes="32G";
}
}
group hadoop-tasktracker {
perm {
task {
uid = hadoop;
gid = hadoop;
}
admin {
uid = root;
gid = root;
}
}
memory {
memory.limit_in_bytes="32G";
memory.memsw.limit_in_bytes="32G";
}
cpuset {
cpuset.cpus = 2-15;
cpuset.mems = 0-1;
}
}
group cpu-storage{
perm{
task{
uid = freeoa;
gid = freeoa;
}
admin{
uid = root;
gid = root;
}
}
cpu{
cpu.shares = 256;
}
}
group cpu-status{
perm{
task{
uid = freeoa;
gid = freeoa;
}
admin{
uid = root;
gid = root;
}
}
cpu{
cpu.shares = 256;
}
}
cgroups是分层次(类似于文件系统的树状结构)的,因此可以创建任意数量的子组,普通用户希望在名为foo的新子组下运行bash shell:
cgcreate -g memory,cpu:groupname/foo
cgexec -g memory,cpu:groupname/foo bash
查看系统中已有的控制组(only meaningful for legacy (v1) cgroups):
cat /proc/self/cgroup
11:memory:/groupname/foo
6:cpu:/groupname/foo
为此内存控制组(groupname)创建新的子目录,将此组中所有进程的内存使用限制为10 MB:
echo 10000000 > /sys/fs/cgroup/memory/groupname/foo/memory.limit_in_bytes
请注意,内存限制仅适用于RAM使用——一旦任务进程达到此限制,它们将开始使用交换分区。但这不会显著影响其它进程的性能。同样可以更改此组的CPU使用优先级("shares")。默认情况下,所有组都有1024个共享。拥有100股的使用组将获得约10%的CPU时间:
$ echo 100 > /sys/fs/cgroup/cpu/groupname/foo/cpu.shares
可以通过列出cgroup找到更多可调参数或统计信息目录,也可以更改已运行进程到cgroup中。如将所有“bash”命令移动到此组:
pidof bash
1324 1326
cgclassify -g memory,cpu:groupname/foo `pidof bash`
cat /proc/1324/cgroup
11:memory:/groupname/foo
6:cpu:/groupname/foo
Persistent cgroup configuration|固化cgroup配置
如果希望在系统启动时能自动创建cgroup规则,可以在/etc/cgconfig.conf中定义这些规则。比如"groupname"可使用用户:$USER和组: $GROUP来限制任务的添加,在其下定义相关的子组:"groupname/foo":
group groupname{
perm {
#who can manage limits
admin{
uid = $USER;
gid = $GROUP;
}
#who can add tasks to this group
task {
uid = $USER;
gid = $GROUP;
}
}
# create this group in cpu and memory controllers
cpu { }
memory { }
}
group groupname/foo {
cpu {
cpu.shares = 100;
}
memory {
memory.limit_in_bytes = 10000000;
}
}
'/sys/fs/cgroup/'这个包含了多个的控制器的子级目录可在引导时自动创建和挂载于虚拟文件系统下,通过$CONTROLLER-NAME {}命令来创建新的控制组,如果想在其它目录下创建,可在'/etc/cgconfig.conf'中添加:
mount {
cpuset = /your/path/groupname;
}
这个与下面的操作步骤同理:
# mkdir /your/path/groupname
# mount -t /your/path -o cpuset groupname /your/path/groupname
---------------------------------------------------------------
六、CentOS 7的使用方式参考
在 CentOS 7 中,已经通过 systemd 替换了之前的 cgroup-tools 工具,为了防止两者冲突,建议只使用 systemd ,只有对于一些不支持的,例如 net_prio ,才使用 cgroup-tools 工具。在 CentOS 7 中需要通过 yum install libcgroup libcgroup-tools 安装额外的 cgroup 工具,对系统来说,默认会挂载到 /sys/fs/cgroup/ 目录下。
----- 查看系统已经存在cgroup子系统及其挂载点
# lssubsys -am
----- 或者通过mount查看cgroup类型的挂载点
# mount -t cgroup
----- 可以命令行挂载和卸载子系统,此时再次执行上述命令将看不到memory挂载点
# umount /sys/fs/cgroup/memory/
----- 挂载cgroup的memory子系统,其中最后的cgroup参数是在/proc/mounts中显示的名称
# mount -t cgroup -o memory cgroup /sys/fs/cgroup/memory/
# mount -t cgroup -o memory none /sys/fs/cgroup/memory/
另外,在 CentOS 中有 /etc/cgconfig.conf 配置文件,该文件中可用来配置开机自动启动时挂载的条目:
mount {
net_prio = /sys/fs/cgroup/net_prio;
}
然后,通过 systemctl restart cgconfig.service 重启服务即可。CentOS 7 中默认的资源隔离是通过 systemd 进行资源控制的,systemd 内部使用 cgroups 对其下的单元进行资源管理,包括 CPU、BlcokIO 以及 MEM,通过 cgroup 可以 。systemd 的资源管理主要基于三个单元 service、scope 以及 slice:
service:通过 unit 配置文件定义,包括了一个或者多个进程,可以作为整体启停。
scope:任意进程可以通过 fork() 方式创建进程,常见的有 session、container 等。
slice:按照层级对 service、scope 组织的运行单元,不单独包含进程资源,进程包含在 service 和 scope 中。
常用的 slice 有
A) system.slice,系统服务进程可能是开机启动或者登陆后手动启动的服务,例如crond、mysqld、nginx等服务;
B) user.slice 用户登陆后的管理,一般为 session;
C) machine.slice 虚机或者容器的管理。
对于 cgroup 默认相关的参数会保存在 /sys/fs/cgroup/ 目录下,当前系统支持的 subsys 可以通过 cat /proc/cgroups 或者 lssubsys 查看。常用命令可以参考如下。
----- 查看slice、scope、service层级关系
# systemd-cgls
----- 当前资源使用情况
# systemd-cgtop
----- 启动一个服务
# systemd-run --unit=name --scope --slice=slice_name command
unit 用于标示,如果不使用会自动生成一个,通过systemctl会输出;
scope 默认使用service,该参数指定使用scope ;
slice 将新启动的service或者scope添加到slice中,默认添加到system.slice,也可以添加到已有slice(systemctl -t slice)或者新建一个。
# systemd-run --unit=toptest --slice=test top -b
# systemctl stop toptest
----- 查看当前资源使用状态
$ systemctl show toptest
各服务配置保存在 /usr/lib/systemd/system/ 目录下,可以通过如下命令设置各个服务的参数。
----- 会自动保存到配置文件中做持久化
# systemctl set-property name parameter=value
----- 只临时修改不做持久化
# systemctl set-property --runtime name property=value
----- 设置CPU和内存使用率
# systemctl set-property httpd.service CPUShares=600 MemoryLimit=500M
另外,在 213 版本之后才开始支持 CPUQuota 参数,可直接修改 cpu.cfs_{quota,period}_us 参数,也就是在 /sys/fs/cgroup/cpu/ 目录下。
---------------------------------------------------------------
七、Ubuntu基于用户的cgroup设置(该部分转自于互联网,感谢原作者)
作为Linux内核级别的资源限制设置,cgroup在近些年特别是容器技术兴起的现在,也越来越多的被重新提及。作为cgroup本身来说,它完全可以被用来限制基于任何用户或者是任何应用程序的资源限制。
首先,假设有这样一个应用场景:我和某位仁兄共享某台4core+4G+Ubuntu1404主机做开发机,这位仁兄不太讲公德,一直用这台机器从事挖矿等大规模计算活动,严重影响到了我的日常使用。于是鉴于他出了1/4的钱的份上,我决定只能让他的账户使用4core中的一个,以及1G内存,同时尽可能的限制他的挖矿进程。
既然说到Ubuntu,要吐槽的是,它对于cgroup的默认支持真心不完善,非但不能学习Redhat系简单粗暴的默认支持开启,甚至连cgroup的支持也分为几个包来实现。首先是把依赖包安装好。
#apt-get update
...
# apt-get install cgroup-bin
cgroup-bin会连带安装的依赖包中有个叫cgroup-lite包。从字面上来说,它只提供了最基础的cgroup功能,并不能直接提供基于用户,或者应用的自动cgroup分组。如果您只需要基础的cgroup功能的话cgroup-lite就够了。然后就是准备cgroup的配置,即预先配置好几个cgroup组,用来标记资源配额。这里我们沿用Redhat系的规则:vim /etc/cgconfig.conf
group my_2b_mate{ # cgroup 的名称
cpuset { # 资源类型,cpuset
cpuset.cpus = 0-1; # 只能使用cpu 0 - 1
cpuset.mems = 0; # cgroup有cpuset问题,可参见下文
}
}
group his_2b_app{
cpu { #类型是cpu,和cpuset可不是一回事
cpu.shares = 1; #调度公平度,默认是1024,越小优先级越低
}
}
然后就是把这个cgroup的配置启用
# cgconfigparser -l /etc/cgconfig.conf
# ls /sys/fs/cgroup/cpu
..... his_2b_app
# ls /sys/fs/cgroup/cpuset
...... my_2b_mate
然后就是将用户/应用和cgroup绑定:vim /etc/cgrules.conf
friend cpuset my_2b_mate
#这里有3个项目,分别是用户名、控制器类型和cgroup名称
friend:wakuang cpu his_2b_app
#我们将会对用户friend的wakuang进程启用cpu:his_2b_app规则
将它启用起来:
# cgrulesengd
这条命令事实上是一个服务,它会自动监控符合规则的进程,然后将这些进程配置到对应的cgroup策略中从而达到限制资源的目的。
话说这个cgroup-bin自带了一个example文件夹,它位于/usr/share/doc/cgroup-bin/examples目录下,其中有一个cgred明显就是一个service的启动命令,在试着启动它的时候缺发觉这脚本根本就无法使用。好在这几个命令真心的不复杂,我强忍着吐槽的心情,决定自己在cgroup-lite的启动脚本添加对应的启动命令。
vim /etc/init/cgroup-lite.conf
description "mount available cgroup filesystems"
author "Serge Hallyn"
start on mounted MOUNTPOINT=/sys/fs/cgroup
pre-start script
test -x /bin/cgroups-mount || { stop; exit 0; }
test -d /sys/fs/cgroup || { stop; exit 0; }
/bin/cgroups-mount
####New added
cgconfigparser -l /etc/cgconfig.conf
cgrulesengd
####end
end script
post-stop script
if [ -x /bin/cgroups-umount ]
then
/bin/cgroups-umount
fi
end script
这样就可以简单的通过service cgroup-lite start/stop来自动的载入对应的cgroup配置和配额规则了。
其实对于现实中的很多应用场景其实或多或少的都会有存在进程之间抢占系统资源的问题,例如LNMP的经典组合,MySQL,Php-fpm,Nginx混部的同时MySQL很容易和php-fpm争抢内存、和nginx争抢IO。通过限制进程对的资源的访问优先权可以很容易的达到人为干预调度的功能。
也不得不承认在redhat上只要在/etc/cgconfig.conf和/etc/cgrules.conf里修改对应的配置就可以了,省却了很多麻烦,这一点Ubuntu和Redhat还是有些差距的。
---------------------------------------------------------------
八、cgroup 的整体结构概述
子系统目前有下列几种:
devices 设备权限
cpuset 分配指定的 CPU 和内存节点
cpu 控制 CPU 占用率
cpuacct 统计 CPU 使用情况
memory 限制内存的使用上限
freezer 暂停 Cgroup 中的进程
net_cls 配合 tc(traffic controller)限制网络带宽
net_prio 设置进程的网络流量优先级
huge_tlb 限制 HugeTLB 的使用
perf_event 允许 Perf 工具基于 Cgroup 分组做性能检测
创建层级通过 mount -t cgroup -o subsystems name /cgroup/name,/cgroup/name 是用来挂载层级的目录(层级结构是通过挂载添加的),-o 是子系统列表,比如 -o cpu,cpuset,memory,name 是层级的名称,一个层级可以包含多个子系统,如果要修改层级里的子系统重新 mount 即可。子系统和层级之间满足几个关系:
同一个 hierarchy 可以附加一个或多个 subsystem
一个 subsystem 可以附加到多个 hierarchy,当且仅当这些 hierarchy 只有这唯一一个 subsystem
系统每次新建一个 hierarchy 时,该系统上的所有 task 默认构成了这个新建的 hierarchy 的初始化 cgroup,这个 cgroup 也称为 root cgroup。对于你创建的每个 hierarchy,task 只能存在于其中一个 cgroup 中,即一个 task 不能存在于同一个 hierarchy 的不同 cgroup 中,但是一个 task 可以存在在不同 hierarchy 中的多个 cgroup 中。如果操作时把一个 task 添加到同一个 hierarchy 中的另一个 cgroup 中,则会从第一个 cgroup 中移除
/proc/self 对应的是当前进程的 proc 目录,比如当前进程 pid 是1,那么/proc/1和/proc/self是等价的。运行man proc可以看到/proc/self/cgroup的解释。
/proc/[pid]/cgroup (since Linux 2.6.24)
This file describes control groups to which the process/task belongs. For each cgroup hierarchy there is one entry containing colon-separated fields of the form:
5:cpuacct,cpu,cpuset:/daemons
The colon-separated fields are, from left to right:
1. hierarchy ID number
2. set of subsystems bound to the hierarchy
3. control group in the hierarchy to which the process belongs
This file is present only if the CONFIG_CGROUPS kernel configuration option is enabled.
这个展示的是当前进程属于的 control groups, 每一行是一排 hierarchy,中间是子系统,最后是受控制的 cgroup,可以通过这个文件知道自己所属于的cgroup。
cpu 子系统
cpu子系统是对CPU时间配额进行限制的子系统,属性在这里列举一下
cpu.cfs_period_us 完全公平调度器的调整时间配额的周期
cpu.cfs_quota_us 完全公平调度器的周期当中可以占用的时间
cpu.stat 统计值
nr_periods 进入周期的次数
nr_throttled 运行时间被调整的次数
throttled_time 用于调整的时间
cpu.share cgroup中cpu的分配,如果a group是100,b group是300,那么a就会获得1/4,b就会获得3/4的CPU。
CFS 调度器
接下来看一下对于 CPU 的限制是如何做到的,这要补充一下 CFS(完全公平调度器) 的相关的内容。
CFS 保证进程之间完全公平获得 CPU 的份额,和我们传统的操作系统的时间片的理念不同,CFS 计算进程的 vruntime (其实就是总时间中的比例,并且带上进程优先级作为权重),来选择需要调度的下一个进程。用户态暴露的权重就是nice值,这个值越高权重就会低,反之亦然(坊间的解释是 nice 的意思就是我对别的进程很 nice ,所以让别的进程多运行一会儿,自己少运行一会儿)。
CFS主要有几点,时间计算,进程选择,调度入口。
时间计算
先看下面这句话:Linux is a multi-user operating system. Consider a scenario where user A spawns ten tasks and user B spawns five. Using the above approach, every task would get ~7% of the available CPU time within a scheduling period. So user A gets 67% and user B gets 33% of the CPU time during their runs. Clearly, if user A continues to spawn more tasks, he can starve user B of even more CPU time. To address this problem, the concept of “group scheduling” was introduced in the scheduler, where, instead of dividing the CPU time among tasks, it is divided among groups of tasks.
总结来说 CPU 的时间并不是分给独立的 task 的,而是分给 task_group 的,这样防止用户 A 的进程数远远大于 B 而导致 B 饥饿的情况。这一组task通过 sched_entity 来表示。能够导致进程分组的方式一种是把进程划入一个cgroup,一种是通过set_sid()系统调用的新session中创建的进程会自动分组,这需要CONFIG_SCHED_AUTOGROUP编译选项开启。
cpuacct 子系统
cpuacct 比较简单,因为主要是一些统计信息
cpuacct.stat cgroup 及子消耗在用户态和内核态的CPU循环次数
cpuacct.usage cgroup 消耗的CPU总时间
cpuacct.usage_percpu cgroup在每个CPU上消耗的总时间
cpuset 子系统
cpuset 子系统用于分配独立的内存节点和CPU节点,这个主要应用与NUMA结构里面,多内存节点属于该结构。
memory 子系统
memory 子系统的参数比较多
memory.usage_in_bytes # 当前内存中的 res_counter 使用量
memory.memsw.usage_in_bytes # 当前内存和交换空间中的 res_counter 使用量
memory.limit_in_bytes # 设置/读取 内存使用量
memory.memsw.limit_in_bytes # 设置/读取 内存加交换空间使用量
memory.failcnt # 读取内存使用量被限制的次数
memory.memsw.failcnt # 读取内存和交换空间使用量被限制的次数
memory.max_usage_in_bytes # 最大内存使用量
memory.memsw.max_usage_in_bytes # 最大内存和交换空间使用量
memory.soft_limit_in_bytes # 设置/读取内存的soft limit
memory.stat # 统计信息
memory.use_hierarchy # 设置/读取 层级统计的使能
memory.force_empty # trigger forced move charge to parent?
memory.pressure_level # 设置内存压力通知
memory.swappiness # 设置/读取 vmscan swappiness 参数?
memory.move_charge_at_immigrate # 设置/读取 controls of moving charges?
memory.oom_control # 设置/读取 内存超限控制信息
memory.numa_stat # 每个numa节点的内存使用数量
memory.kmem.limit_in_bytes # 设置/读取 内核内存限制的hard limit
memory.kmem.usage_in_bytes # 读取当前内核内存的分配
memory.kmem.failcnt # 读取当前内核内存分配受限的次数
memory.kmem.max_usage_in_bytes # 读取最大内核内存使用量
memory.kmem.tcp.limit_in_bytes # 设置tcp 缓存内存的hard limit
memory.kmem.tcp.usage_in_bytes # 读取tcp 缓存内存的使用量
memory.kmem.tcp.failcnt # tcp 缓存内存分配的受限次数
memory.kmem.tcp.max_usage_in_bytes # tcp 缓存内存的最大使用量
network 子系统
多用于限制速率上,这个的实现原理比较复杂,建议阅读 cgroup 子系统之 net_cls 和 net_prio
---------------------------------------------------------------
九、cgroup文件的写与资源控制流程小结
cgroup作为linux的文件系统之一,可以说是如今云计算的基石。其主要有如下两个问题:
1.cgroup文件是如何读写的,即操作cgroup文件的工作机制;
2.cgroup文件是如何对进程起到限制作用的,这是了解进程运转机制的其中一环。
一般通过修改proc文件进而改变linux内核变量,然后这些变量在整个操作系统环境中起到作用;进一步的讲,在linux操作系统中,虽然文件系统很多,但是大致可以分为两类:
1.一类是仅存在于内存中的文件系统;
2.一种是主要为了便于读写块设备的文件系统。
存在于内存中的文件系统,其目的各种各样,但是都是通过文件的方式去访问、去操作。
/proc/filesystems
nodev sysfs
nodev rootfs
nodev ramfs
nodev bdev
nodev proc
nodev cgroup
nodev cpuset
nodev tmpfs
nodev devtmpfs
nodev debugfs
nodev securityfs
nodev sockfs
nodev pipefs
nodev anon_inodefs
nodev devpts
ext3
ext2
ext4
nodev hugetlbfs
vfat
nodev ecryptfs
fuseblk
nodev fuse
nodev fusectl
nodev pstore
nodev mqueue
nodev binfmt_misc
nodev vboxsf
cgroup文件的写机制
判断本机是Cgroup V1还是V2
通过下面这条命令来查看当前系统使用的 Cgroups V1 还是 V2
stat -fc %T /sys/fs/cgroup/
tmpfs # V1
stat -fc %T /sys/fs/cgroup/
cgroup2fs # V2
以cgroupV1为基本的研究环境
启用cgroup相关子系统:
cpu,主要限制进程的 cpu 使用率。
cpuacct,可以统计 cgroups 中的进程的 cpu 使用报告。
cpuset,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
memory,可以限制进程的 memory 使用量。
blkio,可以限制进程的块设备 io。
devices,可以控制进程能够访问某些设备。
net_cls,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
freezer,可以挂起或者恢复 cgroups 中的进程。
ns,可以使不同 cgroups 下面的进程使用不同的 namespace。
在此处也说明一下,cgroupV2和V1的不同,其实就是文件目录的组织形式不同。
发现cpu memory并没有被挂载
mount | grep cgroup
none on /sys/fs/cgroup type tmpfs (rw)
systemd on /sys/fs/cgroup/systemd type cgroup (rw,noexec,nosuid,nodev,none,name=systemd)
在/sys/fs/cgroup下创建一个cpu目录然后直接挂载。
# 创建cpu目录
mkdir -p /sys/fs/cgroup/cpu
# 挂载 cpu
mount -t cgroup -o cpu none /sys/fs/cgroup/cpu
# 查看挂载情况
mount | grep cgroup
none on /sys/fs/cgroup type tmpfs (rw)
systemd on /sys/fs/cgroup/systemd type cgroup (rw,noexec,nosuid,nodev,none,name=systemd)
none on /sys/fs/cgroup/cpu type cgroup (rw,cpu)
# 查看cpu目录下的文件树结构
.
├── cgroup.clone_children
├── cgroup.event_control
├── cgroup.procs
├── cgroup.sane_behavior
├── cpu.cfs_period_us
├── cpu.cfs_quota_us
├── cpu.shares
├── cpu.stat
├── notify_on_release
├── release_agent
├── tasks
└── test
├── cgroup.clone_children
├── cgroup.event_control
├── cgroup.procs
├── cpu.cfs_period_us
├── cpu.cfs_quota_us
├── cpu.shares
├── cpu.stat
├── notify_on_release
└── tasks
写cgroup文件
现在尝试往cgroup文件中写入内容
echo 100000 > /sys/fs/cgroup/cpu/test/cpu.cfs_period_us
通过debug可以发现写入逻辑如下
SyS_write()
...
vfs_write()
cgroup_file_write()
cpu_cfs_period_write_u64()
tg_set_cfs_bandwidth()
...
而cpu_cfs_period_write_u64的定义如下:
//file:kernel/sched/core.c
static struct cftype cpu_legacy_files[] = {
...
{
.name = "cfs_quota_us",
.read_s64 = cpu_cfs_quota_read_s64,
.write_s64 = cpu_cfs_quota_write_s64,
},
{
.name = "cfs_period_us",
.read_u64 = cpu_cfs_period_read_u64,
.write_u64 = cpu_cfs_period_write_u64,
},
...
}
也就是说在创建cfs_period_us文件的时候,该文件的inode和该方法都已经关联上了。
cgroup文件是如何对进程起到限制作用
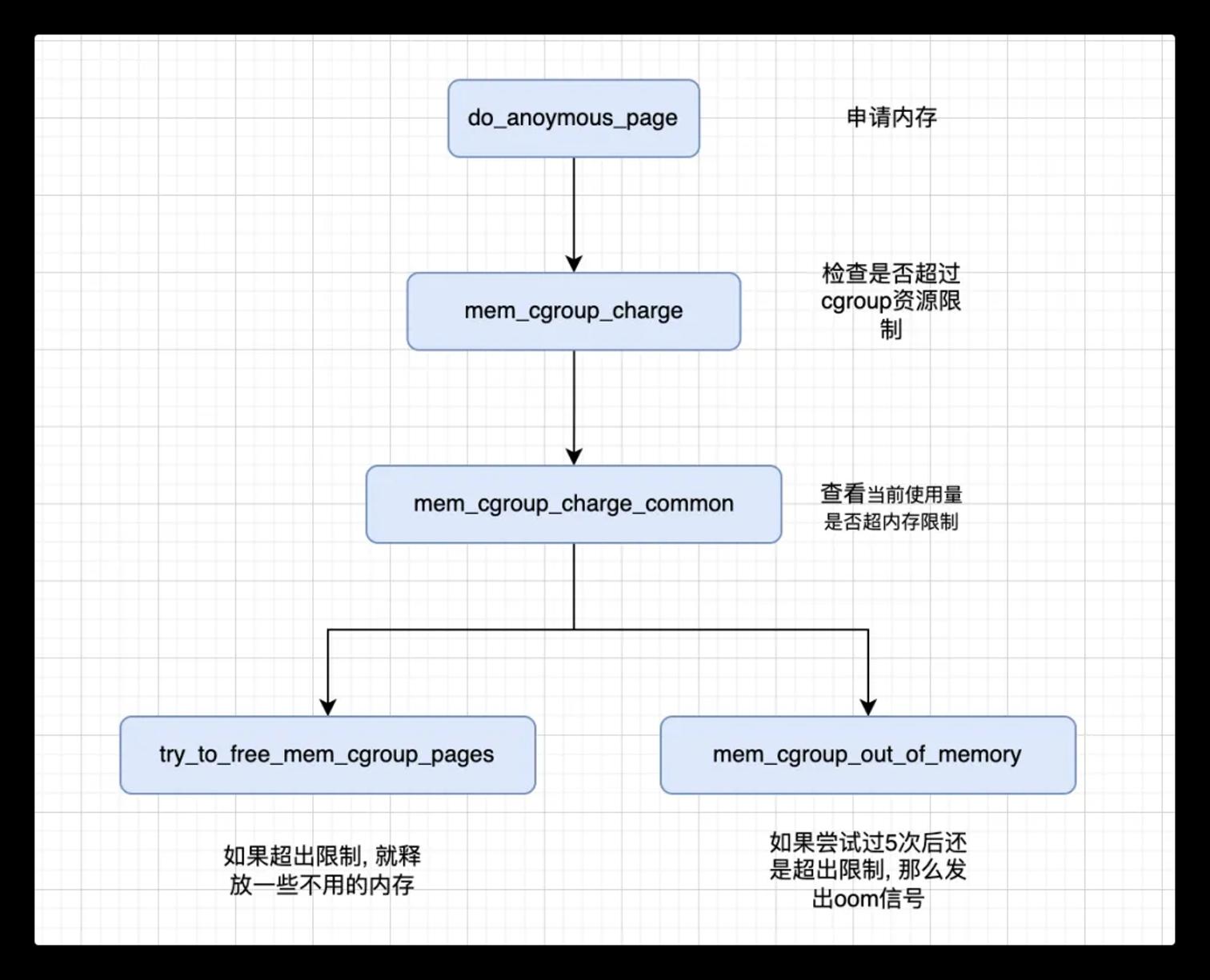
cgroup文件系统确实复杂了,这个跟其他文件系统完全不同。复杂的原因有二:
首先是cgroup文件本身的组织形式比较复杂,一个cgroup里边有很多个子系统,不同cgroup之间又有父子关系、兄弟关系,然后这些cgroup又需要跟进程关联到一起。
其次是这些cgroup管理的都是cpu、mem这些计算机的核心资源,在使用cgroup文件的流程上具有复杂性,因为不同的资源,不同的限制项,在linux内核中所处的位置不同,所使用的方式不同。
即这两种原因导致了cgroup文件系统整体来说要比其他的文件系统要复杂的多,只想了解这块工作机制的话只需要了解cgroup文件读写和使用的基本流程即可。
---------------------------------------------------------------
十、参考链接
cgroup-v1
cgroup-v2
Using cgroups to limit I/O
Linux Control Group 简介
Using cgroups to limit Hadoop
cgroup 分析之CPU和内存部分