ZFS文件系统简介及特性
 ZFS简介
ZFS简介1.1 ZFS发展史
ZFS是由SUN公司的Jeff Bonwick和Matthew Ahrens大神于2001年领导设计开发,并在2004年2月14日发布的集合了文件系统处理逻辑和卷管理器功能的文件系统。ZFS的全拼是Zettabyte File System,Zetta是一个数量单位,1ZB=270字节,而1ZB=1024EB=1048576 PB,而facebook目前最大的单个HDFS集群中存储了100PB的log数据。当然单台服务器不可能也不会存储这么多数据,这从一个侧面说明了zfs的存储容量从实际使用中来说是没有上限的。zfs不是类似于hdfs的分布式文件系统或者lustre之类的集群文件系统,通常可以用来作HDFS和lustre的后端存储文件系统使用。
SUN公司从2008年开始组织并支持开源open solaris项目,ZFS是其中一个重要的组成部分,随着oracle公司收购了sun,并于2010年停止了open solaris的开发工作,原先的ZFS核心开发者们也逐步的离开了oracle,他们中的一部份人继续着ZFS的开发,参与或者组成了Joyent、Nexenta、Delphix等以opensolaris或ZFS为蓝本的公司,他们的oracle个人blog也随着离开oracle停止更新或者无法访问,而open solaris的社区也将在2013年3月24日关闭,届时我们将失去学习一个学习目前最为先进的商业操作系统的途径,这也是促使我完成《zfs源代码剖析》系列的原因,作为软件设计中的一项杰作,ZFS值得我们深入的学习,包括它斟酌权衡的设计,令人赞叹的细节实现和追求完美的态度,在接下来的文章中将为各位读者一一说明和展现。
1.2 ZFS特性
ZFS作为一个划时代的文件系统,被移植到了多个OS平台上,它具有的特性主要如下:
1.接近于无限的存储空间 ZFS针对若干磁盘组成的集合抽象出了zpool的概念,而文件系统则是活动的,每个文件系统实例可以从zpool中分配空间,zpool的大小可以动态变化,在空间不足的时候可以动态添加磁盘,在空间充足的时候也可以通过移动数据的办法抽调出磁盘。ZFS的一些理论极限如下:对于任意ZFS文件系统实例,支持248个快照,支持248个文件,单个文件系统实例最大16EB,单个文件最大16EB,单个zpool最大128ZB,每个zpool最多支持264个设备等等。
2.COW事务模型 COW是Copy On Write的缩写,是指在对数据进行修改时并不是直接原地修改,而是拷贝一份新的与修改的内容合并。使用COW的一个例子就是Unix的fork函数实现,通常fork的过程中子进程需要拷贝父进程的页表等虚拟内存信息,而如果子进程对拷贝的页表修改较少这样的拷贝工作就会带来额外的负担,因此fork的时候子进程不拷贝父进程的页表等信息,而是与其父进程共享,在修改的时候拷贝出一份新的进行修改,在此处COW的主要功能是减少额外的copy带来的负担。对于文件系统而言,COW是实现快照等功能的基础,通过保留每个快照的时刻的数据而重定向新修改的数据,可以保证快照时刻的完整数据。对于通常的文件系统,例如ext3/4,xfs等,写入是modify in place的,这样的好处是可以保证在顺序写入后修改时磁盘上的数据的连续性,而劣势在于修改的时候面对宕机断电等意外情况,必须保证任意时刻的数据是合法的,因此ext3/4和xfs均引入了日志机制(ext3使用到了JBD),在写入数据的时候记入额外的信息来保障数据可以恢复,随之带来的则是一次数据的写入可能会引发若干次的日志写入操作,而日志的存储区通常与数据存储区是分开的,这就带来了磁盘额外的seek操作,影响性能。ZFS和Btrfs等文件系统采取了另外一种处理办法,即对所有的数据修改均采用COW的办法,这样可以保证磁盘上的数据时刻均是完整的,不必记录额外的日志,这里有一个关于各种使用COW文件系统的性能对比,采用COW的劣势在于处理随机写后顺序读取的情况,对于modify in place的文件系统,数据在磁盘上仍是连续存储的,而ZFS则由于COW机制,随机更新的数据已经散落在磁盘上的各处,后续的顺序读取则不必要的引入了多余的seek操作。
事务模型(Transactional Model)是从关系型数据库中借鉴而来的概念,对文件系统而言指的是保证一组操作的原子性,即要么成功,要么失败,不存在中间状态,并且各个transaction之间是隔离的,互不影响。ext3/4,xfs的日志实现和ZFS/BTRFS的实现均采用了事务的模型,关于ZFS的实现将在后文中说明,此处需要注意的是,即便使用了事务模型,也不一定能保证用户数据逻辑上的完整性,因为只有用户接触到的最上层应用才能确保数据逻辑上的完成性。对于数据库而言是用户接触的最上层应用,而文件系统通常是作为其他应用软件存储数据的仓库,事务模型只能保证文件系统在异常情况下其内部逻辑的正确性,而用户数据逻辑上的正确性仍需要自己保证。
3.端到端的数据安全性 ZFS的主要设计者之一Jeff Bonwick写过一篇博文《ZFS End-to-End Data Integrity》,概要性的说明了ZFS如何保证其数据的安全性。关于“端到端的数据安全性”笔者曾与一位网友进行过讨论,在这里而言这个概念是指从ZFS接收到数据开始到调用内核中各个不同硬件设备注册的驱动写入数据之间的过程,对于之前或者之后的过程,由于软件分层次的限制,ZFS无法得知上层应用传输的数据的正确性和硬件设备驱动、firmware没有bug,故无法保证数据的安全性。
ZFS的数据安全性主要通过RAID,checksum校验,多副本(ditto blocks)数据冗余的方法保证,分别介绍如下:
1>RAID:ZFS的卷管理器功能实现了RAID 0/1/10,RAID Z(RAID 5)/Z2(RAID 6)/Z3多个级别的RAID功能 ,其中RAID1/10,RAID Z/Z2/Z3有对数据的保护功能,RAID 1/10比较常见,RAIDZ/Z2/Z3则是ZFS引入的raid级别,RAIDZ相当于RAID 5实现,但没有RAID 5存在的write hole ,RAID Z类似与RAID 5,支持一块盘损坏情况下数据的恢复,RAID Z2存储了两套校验码,允许两块盘损坏情况下数据的恢复,同理,RAID Z3支持三块盘损坏情况下数据的恢复。
2>checksum校验: 通常的ext3/4,xfs默认数据写入磁盘之后,读出的数据和写入的数据是相同的,而在大规模的集群中,silent corruption是极其常见的情况,而此类文件系统无法判断出此类错误,当用户发现数据损坏时为时已晚。为了解决这个问题,ZFS为所有写入磁盘的数据都生成了checksum,checksum算法基于Fletcher或者SHA256,每块数据生成的校验值存储不是存在数据块内部(这是一个先有鸡还是先有蛋的问题),而是在指向该块数据的指针中,接下来ZFS也对此指针生成checksum,记录在指向此指针的指针中,依次类推,ZFS的checksum向上递归至文件系统的根节点,根节点也生成了checksum并存储了多份,形成了一颗hash tree。在读取数据的过程中,zfs会对读取到的数据重新生成校验值,和存储在父节点中的校验值进行对比,如果相同,则证明数据正确,否则出现了silent corruption的情况,此时如果使用了RAID或者是数据存储了多份,ZFS会使用别的正确的数据修复错误的这个版本,如果没有RAID或者所有版本均存在错误,ZFS会报告错误。
3>多副本数据冗余 用户可以设置ZFS中每份数据存储的份数,最多为3份,而ZFS默认会为文件系统的元数据在zpool的多块磁盘上存储多份,避免这些关键数据的损坏带来的更为严重的后果。
4.online fsck 常见的各种Unix文件系统都提供了fsck工具,用以检测文件系统内部可能存在的数据错误情况,而这种操作需要文件系统处于offline的状态,而zfs的scrub(擦洗)功能允许文件系统在online的情况下进行fsck工作。并且通常的fsck工具只检查元数据而非数据,而ZFS的scrub功能检查包括数据、元数据在内的所有数据。ZFS Best Practices Guide建议对于使用企业级硬盘的服务器,每月进行一次scrub操作,而对于桌面级磁盘,建议每周执行一次scrub操作。
5.高效的快照功能 由于ZFS采用的COW机制,每次的写入或者是更新均不会影响到磁盘上已有的数据,也就是说,如果必要的话,ZFS可以记录下每次写入/更新的操作内容,这是实现快照功能的基础,实际的快照功能实现只是在其中选择一个从ZFS文件系统角度而言完整的事务作为快照点。笔者曾经使用过linux下的LVM卷管理器,LVM卷管理器支持快照功能,在同样的硬件环境和用例情况下对二者的快照功能进行对比测试,lvm打开快照功能之后,数据更新写入性能下降到原来的1/6,对比zfs创建快照之后的更新写性能,下降约15%,发现有少量读取io,相比lvm中kernel的kcopyd线程有大量的读取io,由于ZFS延迟合并了写入,并且判断出是对于旧有整个block的更新,所以就不需要读取旧有的数据,更新旧有元数据就可以了,但是由于LVM工作在IO栈的device mapper层,也没有对fs加hook区分,无法从细粒度层面上对block写入进行感知和优化,这里有对于lvm使用中需要注意问题的详尽描述。lvm的snapshot功能直到最近才加入了对于递归快照的支持,而对于ZFS来说,实现递归快照并不会带来更多的复杂度。
基于高效的快照实现,ZFS实现了快照数据的发送(send)和接收(receive)功能,通过此功能,ZFS可以高效的实现离线异地数据同步的功能,得益于COW机制,ZFS可以快速的计算出来自于同一个ZFS文件系统实例的两个快照之间修改的数据,dump出文件发送到远端进行合并,而不必使用rsync来计算所有文件的数据块的校验值进而同步数据的办法。
6.自适应字节序功能 从5中的描述也可以看出,ZFS的数据可以在不同的平台(主要是由CPU的大小端决定)导入和导出。
7.高效的缓存管理功能 对于文件系统而言,除非是sync写入的或者OS内存紧张的状态(在linux下由dirty_ratio参数控制),否则数据是首先写入文件系统缓存,之后由文件系统或者操作系统的刷新线程(对于linux 2.6.32以上内核为backing device的flush线程,低于此版本为pdflush线程)异步写入的,由此可见缓存的实现是文件系统写性能的决定性因素之一。ZFS作为一个革新的文件系统,实现了自己的一些缓存替换算法,但为了保持与原有OS组件的兼容性,而又不损失性能,ZFS实现了自己的page cache功能,其他文件系统,例如UFS则继续使用旧版本的page cache,ZFS采用了Adaptive Replacement Cache缓存替换算法,取得了较好的性能。ARC相当于CPU的L1 Cache,使用内存实现,因此存储的数据有限,ZFS类似CPU的L2 Cache,包括两个部分:L2ARC和ZIL(ZFS Intent Log).L2ARC是读缓存,存储在L2ARC的数据是可以随时丢弃掉,从磁盘获取到的干净数据,而ZIL中存储的则是缓存的脏数据,需要写入到磁盘,通常ZIL中缓存的都是需要同步写入的数据,ZIL将需要同步写入的数据缓存起来,并在合适的时机按照一个事务组批量异步写入。为了保证数据的安全性,写入ZIL的数据都会记录日志,此日志只有在恢复的过程中才会读取,使用ZIL可以显著提高NFS和数据库应用的性能。类似与CPU的Cache分层中容量递增,读写速度递减的规则,ZFS通常使用SSD作为L2ARC和ZIL。
8.可变的block size 由于早期的磁盘物理参数限制,在各类*nix系统中,磁盘sector的大小通常定义为512字节,文件系统分配空间的最小block size也定义为了512字节。随着Advanced Format的出现,磁盘的sector可以做到4KB甚至更大,更大的sector在存储大文件时带来更好的性能,而在许多*nix系统中,这个常量是hard coded的,修改起来并不容易,ZFS支持从512字节到128KB大小的block size,针对各种不同的应用环境调优选择,以达到更高的性能。
9.数据去重功能 数据去重功能是现在各种中高端存储设备的必备功能之一,甚至有不少备份软件也内置了数据去重的功能,通过使用SHA256等特征较好的hash算法计算数据的指纹,在写入的过程中比对指纹,相同的数据只存储一份进而提高了存储利用率。ZFS的数据去重功能相当消耗内存,因此通常使用7中描述的L2ARC来存储数据指纹。笔者曾从事了两年多的数据消冗去重文件系统的研发和设计工作,从个人的角度来看ZFS的数据去重功能实现还有很多提高的余地,这点将在后文代码分析的过程中详细说明。
10.其他的功能特点 ZFS支持对数据的压缩,目前支持LZJB和ZIP两种压缩算法。支持deadline模式下的IO优先级调度,这点对于一些延时敏感的应用来说相当重要。支持读取时的数据预读功能,支持高效的IO请求排序和汇聚,支持按照用户和文件系统实例的磁盘限额功能等,最新版本的ZFS支持了透明的数据压缩功能,并且使用了非对称的加密算法提高安全级别。
ZFS 特性简介
将 ZFS 称为文件系统有点名不副实,因为它在传统意义上不仅仅是个文件系统。ZFS 将逻辑卷管理器的概念与功能丰富的和可大规模扩展的文件系统结合起来。让我们开始先探索一些 ZFS 所基于的原则。首先,ZFS 使用池存储模型,而不是传统的基于卷的模型。这意味着 ZFS 视存储为可根据需要动态分配(和缩减)的共享池。这优于传统模型,在传统模型中,文件系统位于卷上,使用独立卷管理器来管理这些资产。ZFS 内嵌入的是重要功能集(如快照、即写即拷克隆、连续完整性检查和通过 RAID-Z 的数据保护)的实现。更进一步,可以在 ZFS 卷的顶端使用您自己最喜爱的文件系统(如 ext4)。这意味着您可以获得那些 ZFS 的功能,如独立文件系统中的快照(该文件系统可能并不直接支持它们)。
但是 ZFS 不只是组成有用文件系统的功能集合。相反,它是构建出色文件系统的集成和补充功能的集合。让我们来看看其中的一些功能,然后再看看它们的一些实际应用。
存储池
正如前面所讨论的,ZFS 合并了卷管理功能来提取底层物理存储设备到文件系统。ZFS 对存储池(称为 zpools)进行操作,而不是直接查看物理块设备,存储池构建自虚拟驱动器,可由驱动器或驱动器的一部分物理地进行表示。此外,可以动态构造这些池,甚至这些池正在活跃地使用时也可以。
即写即拷
ZFS 使用即写即拷模型来管理存储中的数据。虽然这意味着数据永远不会写入到位(从来没有被覆盖),而是写入新块并更新元数据来引用数据。即写即拷有利的原因有多个(不仅仅是因为它可以启用的快照和克隆等一些功能)。由于从来不覆盖数据,这可以更简单地确保存储永远不会处于不一致的状态(因为在新的写入操作完成以后较早的数据仍保留)。这允许 ZFS 基于事务,且更容易实现类似原子操作等的功能。
即写即拷设计的一个有趣的副作用是文件系统的所有写入都成为顺序写入(因为始终进行重新映射)。此行为避免存储中的热点并利用顺序写入的性能(比随机写入更快)。
数据保护
可以使用 ZFS 的众多保护方案之一来保护由虚拟设备组成的存储池。您不但可以跨两个或多个设备(RAID 1)来对池进行镜像,通过奇偶校验来保护该池(类似于 RAID 5),而且还可以跨动态带区宽度(后面详细介绍)来镜像池。基于池中设备数量,ZFS 支持各种不同的的奇偶校验方案。例如,您可以通过 RAID-Z (RAID-Z 1) 来保护三个设备;对于四个设备,您可以使用 RAID-Z 2(双重奇偶校验,类似于 RAID6)。对于更大的保护来说,您可以将 RAID-Z 3 用于更大数量的磁盘进行三重奇偶校验。
为提高速度(不存在错误检测以外的数据保护),您可以跨设备进行条带化(RAID 0)。您还可以创建条带化镜像(来镜像条带化设备),类似于 RAID 10。
ZFS 的一个有趣属性随 RAID-Z、即写即拷事务和动态条带宽度的组合而来。在传统的 RAID 5 体系结构中,所有磁盘都必须在条带内具有其自己的数据,或者条带不一致。因为没有方法自动更新所有磁盘,所以这可能产生众所周知的 RAID 5 写入漏洞问题(其中在 RAID 集的驱动器中条带是不一致的)。假设 ZFS 处理事务且从不需要写入到位,则写入漏洞问题就消除了。此方法的另外一个便捷性体现在磁盘出现故障且需要重建时。传统的 RAID 5 系统使用来自该集中其他磁盘的数据来重建新驱动器的数据。RAID-Z 遍历可用的元数据以便只读取有关几何学的数据并避免读取磁盘上未使用的空间。随着磁盘变得更大以及重建次数的增加,此行为变得更加重要。
校验和
虽然数据保护提供了在故障时重新生成数据的能力,但是这并不涉及处于第一位的数据的有效性。ZFS 通过为写入的每个块的元数据生成 32 位校验和(或 256 位散列)解决了此问题。在读取块时,将验证此校验和以避免静默数据损坏问题。在有数据保护(镜像或 AID-Z)的卷中,可自动读取或重新生成备用数据。在 ZFS 上校验和与元数据存储在一起,所以可以检测并更正错位写入 — 如果提供数据保护(RAID-Z)—。
快照和克隆
由于 ZFS 的即写即拷性质,类似快照和克隆的功能变得易于提供。因为 ZFS 从不覆盖数据而是写入到新的位置,所以可以保护较早的数据(但是在不重要的情况下被标记为删除以逆转磁盘空间)。快照 就是旧块的保存以便及时维护给定实例中的文件系统状态。这种方法也是空间有效的,因为无需复制(除非重新写入文件系统中的所有数据)。克隆是一种快照形式,在其中获取可写入的快照。在这种情况下,由每一个克隆共享初始的未写入块,且被写入的块仅可用于特定文件系统克隆。
可变块大小
传统的文件系统由匹配后端存储(512 字节)的静态大小的块组成。ZFS 为各种不同的使用实现了可变块大小(通常大小达到 128KB,但是您可以变更此值)。可变块大小的一个重要使用是压缩(因为压缩时的结果块大小理想情况下将小于初始大小)。除了提供更好的存储网络利用外,此功能也使存储系统中的浪费最小化(因为传输更好的数据到存储需要更少的时间)。在压缩以外,支持可变块大小还意味着您可以针对所期望的特定工作量优化块大小,以便改进性能。
其他功能
ZFS 并入了许多其他功能,如重复数据删除(最小化数据重复)、可配置的复制、加密、缓存管理的自适应更换缓存以及在线磁盘清理(标识并修复在不使用保护时可以修复的潜在错误)。它通过巨大的可扩展性来实现该功能,支持 16 千兆兆个字节的可寻址存储(264 字节)。
ZFS 的前生今世
ZFS 的开发并非是一帆风顺的。
诞生
ZFS 与 Solaris 是密不可分的。让我们回到 20 年前。当时,Sun 公司如日中天,1992 年发布的 Solaris、1995 年发布 Java 都是其辉煌的证明。1993 年,Sun 进入了财富 500 强。在公司业绩蒸蒸日上的环境下,ZFS 诞生了。2001 年,Solaris 已诞生了整整 10 年,Sun 希望改进 Unix 文件系统(Unix File System)以解决一些问题。Sun 内部的 Jeff Bonwick 就是在此时有了对 ZFS 架构的基本构思。他说服了 Sun 高管,组建了 ZFS 的开发团队。2004 年 9 月 14 日,Sun 正式 宣布了 ZFS 文件系统 。2005 年 6 月 14 日,Sun 公司将正在开发中的 Solaris 11 的源代码以 CDDL 许可开放,这一开放版本就是 OpenSolaris。2005 年 10 月 31 日,ZFS 并入了 Solaris 开发的主干源代码,并在 2005 年 11 月 16 日作为 OpenSolaris build 27 的一部分发布。
波折
好景不长,2009 年 4 月 20 日,甲骨文公司宣布以 74 亿美金收购 Sun 公司。此时的 Sun 已如夕阳。由于甲骨文公司对 OpenSolaris 计划没有积极支援的意图。OpenSolaris 委员会于 2010 年 7 月 12 日对甲骨文给出“最后通牒”,要求在 8 月 16 日派出一位代理人商讨计划的走向,否则将在 8 月 23 日的委员会会议中做出回应。由于甲骨文未加回应,委员会于该日达成共识,解散 OpenSolaris 委员会,社区将不再提供新的源码,计划的控制权由开发员社区交还给甲骨文。至此,Sun 的 ZFS 已成为 Oracle 的专有软件,ZFS 成为 Oracle 的注册商标,而 OpenSolaris,包括其中的 ZFS,由 illumos 项目继续着开发。
壮大
但 ZFS 并没有至此没落。社区在 2013 年成立了 OpenZFS 以配合 ZFS 在 illumos 中的开源发展,由 Jeff Bonwick 当年组建的 ZFS 开发团队中的 Matt Ahrens 作为 OpenZFS 项目的负责人。在开源社区的努力下,ZFS 不断增加新特性、提升稳定性。时间来到 2007 年,苹果将 ZFS 移植到了 Mac OS X 上,但该项目在 2009 年被关闭,之后 MacZFS 项目继续维护着代码;2008 年,ZFS 随 FreeBSD 7.0 正式进入了 FreeBSD;同年,ZFS 开始被原生移植至 Linux,后来成为了 OpenZFS 下属的 ZFS on Linux 项目。如今几乎所有主流操作系统都支持了 ZFS,甚至有OpenZFS on Windows 项目 为 Windows 提供 ZFS 移植!我们今天所说的 ZFS 在绝大多数情况下指的都是 OpenZFS。
什么是 ZFS
ZFS 这个名字本身没有含义,只是 "Zettabyte File System" 的首字母缩写。但 ZFS 本身并不具备任何的缩写意涵,只是想阐述做为一个具备高扩展容量文件系统且还有支持许多延伸功能的一个产品。它是一个 128 位的文件系统,也就是说它能存储 1800 亿亿(18.4×10^18)倍于当前 64 位文件系统的数据。ZFS 的设计如此超前以至于这个极限就当前现实可能永远无法遇到。
Jeff Bonwick 曾说过:要填满一个 128 位的文件系统,将耗尽地球上所有存储设备。除非你拥有煮沸整个海洋的能量,不然你不可能将其填满。并解释填满 ZFS 与煮沸海洋的关系:尽管我们都希望摩尔定律永远延续,但是量子力学给定了任何物理设备上计算速率与信息量的理论极限。举例而言,一个质量为 1 公斤,体积为 1 升的物体,每秒至多在 10^31 位信息 上进行 10^51 次运算。一个完全的 128 位存储池将包含 2^128 个块 =2^137 字节 =2^140 位;因此,保存这些数据位至少需要 (2^140 位) / (10^31 位 / 公斤) = 1360 亿公斤的物质。
但单纯的“大”并不能成为 ZFS 的代替其它文件系统的原因,因为如今有很多文件系统(如 XFS)也可做到这点,虽然不及 ZFS,但数据存储量也暂时不会成为其瓶颈。ZFS 的优点远不止“大”,下面来介绍 ZFS 的众多优秀特性。
特性
虚拟设备(VDEV)、存储池(zpool)、数据集(dataset)、虚拟卷(zvol)
这些是 ZFS 的实现核心,是 ZFS 易用性的基础,ZFS 的绝大多数优点是在其上实现的。
我们在使用传统文件系统时,“分区”与“分区表”是相互独立的,基于不同的技术实现。ZFS 则不同,可以认为它同时承担了分区与分区表的角色。
虚拟设备(VDEV)
VDEV 类似于 Linux 中的 Device Mapper 层,可以认为是 ZFS 架构中的最底层,它用来定义使用设备的类型。为何叫做虚拟设备?因为一个 VDEV 并不需要是一个特定的独立设备(例如一块硬盘),它可以是一块硬盘、一个 RAID 阵列、RAID-Z(ZFS 实现的 RAID 方式,下文会详细介绍)、甚至是一个文件。
ZFS 支持以下 VDEV 类型:
文件(File)
一块磁盘或一个 RAID0 阵列(Stripe)
标准 RAID1 阵列(Mirror)
RAID-Z(包括 RAID-Z1、RAID-Z2、RAID-Z3)
热备盘(Spare)
L2ARC(Cache,用 ARC 算法实现的二级缓存,保存于高速存储设备上,通常使用 SSD)
ZIL(Log,记录两次 transaction group 之间发生的 fsync,保证突发断电时的一致性)
存储池(zpool)
存储池建立于 VDEV 之上,可以认为与传统文件系统中的“分区表”对应。它拥有类似于 LVM 的功能,能管理一个或多个 VDEV。类似于内存,存储池大小会是所有设备的大小总和。这意味着在一个存储池中,可以同时包含一块硬盘、一个 RAID1 阵列和 RAID0 阵列等不同部分!
LVM 不能作为最终文件系统,建立的 LV 需要格式化为最终文件系统(如 ext4、fat32、NTFS、F2FS 等)后才能使用。不同于 LVM,建立好的 ZFS 存储池不需要任何操作即可直接使用。
数据集(dataset)、虚拟块(zvol)
将数据集与虚拟块放在一起介绍是因为它们是“平级”的,都建立于存储池之上,可以认为与传统文件系统中的“分区”对应。虽然存储池可以直接使用,但是有时我们需要实现一些特殊的需求,例如:你将 ZFS 作为根系统挂载,在快照系统时不想将 /tmp 下的文件和目录加入快照,怎么办?这时你可以定义一个“tmp”数据集,并设置其属性为com.sun:auto-snapshot=false
细心的朋友可能会发现,即使在没有创建“tmp”数据集时,/tmp 仍然是存在的,因为在 ZFS 中,可以认为数据集是为设置权限,限额,快照,挂载点等高级特性才存在的。在没有定义数据集大小的情况下,ZFS 会自动为其分配存储池中的空间。ZFS 也允许子数据集的存在,在没有特别设定的情况下子数据集将继承父数据集的属性。
虚拟块是 ZFS 提供的块设备方式,类似于数据集,虚拟块为 block 设备,可以被格式化,可以被 iSCSI 分享。举个例子,你想在一块被分入存储池的空间上划分出一个 F2FS 文件系统格式的“分区”,你需要使用的就是虚拟块。由此可见,在 ZFS 下,操作一个“分区”就像是操作一个目录一样简单,并且“分区”是动态大小的!
写时复制(copy-on-write,CoW)
在绝大多数文件系统下,当我们覆写一个文件时,已覆写的部分会完全丢失,在覆写的中途想要取消是不可能的。ZFS 不同,当你执行覆盖文件操作时,新数据会先存储在不同的区域,在写入完成后再将文件系统元数据信息指向新写入的区域。这能极大地提升系统的稳定性与安全性。突然断电时,正在操作的文件也不会损坏。所以如果使用了 ZFS,就可以完全抛弃 fsck 了。
当然,这么做有一个显著的缺点:文件会散落在磁盘的各个区域,也就是我们常说的“磁盘碎片”。但是,随着 SSD 的普及,磁盘碎片已经变得无伤大雅,而传统的机械硬盘也更多地成为了“长期存储设备”,例如用于 NAS,其上数据不会非常频繁地进行覆写操作。
数据完整性验证、自动修复
写入的数据时,ZFS 会创建数据的校验和,校验和是数据的 256 位散列,校验和功能的范围可以从简单快速的 fletcher4(默认)到强加密散列(如 SHA256)。读取数据时,ZFS 会检查读到数据的校验和,如果与写入时的检验和不符,那么就说明遇到了错误,ZFS 会尝试自动修正错误。这能在很大程度上保证资料完整性。
RAID-Z
上文在介绍 VDEV 时提到了 RAID-Z,这是 ZFS 实现的 RAID 方式,不需要任何其它硬件或软件。现时 RAID- Z 有 3 种类型:RAID-Z1、RAID-Z2、RAID-Z3。
RAID-Z1,类似于 RAID5,一重奇偶校验,至少需要三块硬盘;
RAID-Z2,类似于 RAID6,双重奇偶校验,至少需要四块硬盘;
RAID-Z3,三重奇偶校验,ZFS 独有,至少需要五块硬盘。
快照(Snapshot)
这时 ZFS 在文件系统层级实现的备份功能。当 ZFS写入新数据时,可以保留包含旧数据的块,因而能够维护文件系统的快照版本。而因为组合快照的所有数据都会被储存,且整个存储池通常每小时会进行几次快照,所以快照的创建速度非常快。任何未变动的数据会在文件系统及其快照之间进行共享,因此也具备空间高效性。快照本质上是只读的,确保在创建后快照不会被修改。快照可以被整个恢复,也可以恢复快照中的某些文件或目录。ZFS 也可以创建可写快照:“克隆(Clone)”。“克隆”让两个独立的文件系统共享一组块。对克隆文件系统的修改都会创建新的数据块以反映这些更改。但是无论存在多少个克隆,未变动的块仍然会被共享。这是写入时复制原则的实施方式。
去重(Deduplication)
ZFS 提供文件级别(file-level)、块级别(block-level)、字节级别(byte-level)的去重。
文件级别去重通过比对校验和来发现重复,是一般使用的级别,对性能影响最小。
其它两个级别的去重可以用于某些特殊场合,能节省更多的存储空间。
后文会为该功能进行详述。
透明压缩(Compression)
ZFS 原生提供透明压缩功能,也就是在读写文件时实时进行压缩与解压缩。ZFS 会尝试压缩文件的头部,如果压缩率不佳,会自动放弃压缩将原数据写入。压缩可以在一定程度上“提高 IO”,但代价是占用 CPU 性能,要在考虑 IO 性能与 CPU 性能后再选择是否开启。ZFS 支持以下压缩算法:
lz4,默认且推荐的压缩算法,对系统性能影响小,存取数据的速度几乎与不采用压缩时一样;
gzip,这个不用解释,ZFS 默认的 gzip 级别是 6。对性能有一定的要求,但如果存储的数据是存档,可以考虑使用 gzip;
lzjb,与 lz4 类似,但更推荐 lz4;
zle,简单来说就是“去 0”。
一般来说,不推荐同时开启 ZFS 的压缩与块级别以上的去重。
透明加密(ZFS Native Encryption)
这是 ZFS 支持的最新特性,能够加密存储池或数据集。默认下,ZFS 使用 aes-128-ccm 作为加密算法,目前为止是绝对安全的,如果不放心,还可以选择更高级别的加密。传统的 LUKS 需要为每一个加密分区提供密钥,而 ZFS 可以对存储池加密。当然,开启加密必定会影响性能,要在考虑性能后再选择是否开启。
综上,不难发现 ZFS 不只是一个单纯的文件系统,它还提供了一系列工具来提高使用体验。但是拥有如此多的优点,为什么 ZFS 没有在更大程度上流行?
回到 2005 年,最初的 ZFS 随着 OpenSolaris 的开源而进入了开源世界,但同时也因许可证问题与 Linux“天生不合”。OpenSolaris 开源时采用通用开发与散布许可证(CDDL),从而 ZFS 也成为了 CDDL 协议下的开源软件。Oracle 收购 Sun后终止了 OpenSolaris 开发,让我们口中的 ZFS 变成了 OpenZFS,OpenZFS 项目因无法联系到所有 ZFS 的初期开发者而无法变更许可证。CDDL 协议与 GPL 协议不兼容,所以很多 Linuxer 无法接触到 ZFS,从而导致了 ZFS 无法在更大程度上流行。
但最近 ZFS 也在慢慢融入 Linux 家庭中,上文中提到的 ZFS on Linux 项目 对此作出了巨大的贡献。2019 年,Canonical 在 Ubuntu19.10 中默认加入了 ZFS 的支持。这是 ZFS 融入 Linux 的历史性的一步!虽然有着许可证问题,但是更多人能逐渐理解并包容这一历史遗留问题。Canonical 目前为止还没有因 ZFS 的引入而被缠入法律纠纷。有了第一个“吃西红柿的人”,相信之后会有更多的发行版拥抱 ZFS。
如今,ext 在某些方面的缺点已经成为瓶颈,BtrFS 因开发缓慢且不够稳定而暂时无法成为生产环境下的文件系统,ZFS 应是最佳文件系统的候选之一。多年以后,当 BtrFS 成为主流时,也请不要忘记 ZFS,不要忘记这个优秀的开源社区,不要忘记这个伟大的文件系统探路者。
-------------------------------
ZFS与数据去重
什么是Deduplication?
Deduplication是消除重复数据的过程。去重过程可以基于file-level文件级,block-level块级或者byte-level字节级。使用非常高可能性的hash算法来唯一标识数据块(文件,块,字节)。当使用安全hash,例如SHA256时,hash碰撞的可能性为2的256次方。
选择哪个等级的去重,files,blocks,bytes?
数据可以在文件级,块级,字节级被去重。
文件级的去重对文件作为整体来计算hash签名,如果处理的是自然的文件,则此方法需要的消耗最小,但是缺点是对文件的任何修改都需要重新计算文件的hash签名,即对文件的任何修改,将使得此文件之前节约的空间消失,因为两个文件将不再相同。此中方法比较适合类似于文件JPEG,MPEG,但是对于像虚拟机镜像(大文件)文件将无效,因为即使他们只是很小的一部分不同,但是文件级别他们将是不同的文件。
块级别的去重(相同大小的块),相比文件级的去重,需要更多的计算消耗,但是他能够很好地对像虚拟机镜像类似的大文件去重。大部分的虚拟机镜像文件是重复数据,例如镜像文件中的操作系统部分。使用块级的去重将使得只有镜像特别的数据才占用额外的空间,相同的数据将共享。
字节级别的去重,将需要更多的计算消耗来决定重复数据的开始和结束区域,不管怎么说,此方法对mail服务器来说是理想的选择,例如一个邮件的附件可能出现很多次,但是使用块级别去重时他们并不能被优化。此类型的去重一般用来一些应用程序的去重中,例如exchangeserver,因为应用程序知道他管理的数据,可以在内部容易地去重。
ZFS提供了块级别的去重技术,此种技术更适合通用的情况。且ZFS使用SHA256来计算hash签名。
什么时候去重,现在还是将来?
除了以上描述的文件级,块级,字节级的区别外,去重还可以分为同步(实时或内置)和异步(批处理或离线处理)。在同步去重中,重复文件在出现的时候即被去除,在异步去重中,文件已经存储在磁盘上,然后通过后续的处理来去重(例如在夜间来处理)。异步去重典型地被用在拥有有限的cpu和多线程的存储系统,最小化对日常工作的影响。但是如果cpu的性能足够,同步去重是推荐的方法,因为避免了无用的磁盘的写操作。ZFS去重是同步的去重,ZFS需要高性能的cpu和高度多线程支持的操作系统(例如solaris)。
如何使用ZFS的去重
使用非常的简单,如果你有存储池tank,你需要对tank使用zfs,则设置为:
zfs set dedup=on tank
是否需要ZFS的去重的权衡
主要还是取决于你的数据。如果你的数据确实不包含重复,则开启去重功能则会带来额外的开销且没有任何的好处。但是如果你的数据包含重复,则使用zfs的去重可以节约空间而且提高性能。节约空间是显而易见的,性能的提高是因为减少了重复数据的写磁盘消耗和内存页的置换。
大部分的存储环境都是多种数据的混合,zfs支持对有重复的部分开启去重操作,例如你的存储池包含了home目录,虚拟机镜像目录,源代码目录。此时你可以设置如下:
zfs set dedup=off tank/home
zfs set dedup=on tank/vm
zfs set dedup=on tank/src
信任或验证
如果两个数据的hash相同,我们则认为两个数据是同一个数据,hash例如SHA256,两个不同数据hash相同的可能性为1/2^256,是个很小的概率。当然zfs也提供了验证的选项,此选项对两个数据进行全比较来确定他们是否相同,如果不相同则处理,指定verify的语法如下:
zfs set dedup=verify tank
hash的选择
因为不同种类的hash所需要的运算也不相同,一种推荐的方法是使用较弱的hash(需要的运算较少)加verify来提供快速的去重,zfs对应的选项为:
zfs set dedup=fletcher4,verify tank
不像SHA256,fletcher4不能被信任为无碰撞,只适合与verify一起使用,verify来确保碰撞的处理。总的来说性能相对要好些。通常如果不确定哪种的hash的效率跟高的话,即使用默认的设置dedup=on
扩展性和效率
大部分的去重方案都只能针对有限的数据,一般在TB等级,因为他们需要去重数据表常驻在内存。ZFS对数据大大小没有限制,可以处理PB级的数据。但是如果去重数据表常驻内存的话,性能比较好。
ZFS 引入 RAID-Z Expansion 功能
2022年2月消息,FreeBSD 基金会宣布了 ZFS 的一项新特性:RAID-Z Expansion。
根据介绍,此功能可以对现有的数据进行重新排列 (reflow) —— 本质上是将数据重写到一个新的磁盘阵列上,即在原来的组加上一个新增加的磁盘。此操作会在逻辑 RAID-Z 组的末尾创建一个新的相邻空闲空间块,从而在每个物理磁盘的末尾也进行同样的操作。
重新排列的数据会保留原始的逻辑 stripe width,这意味着数据与奇偶校验位的比率将保持不变。新写入的数据会使用新的逻辑 stripe width,并优化数据与奇偶校验位的比率。和其他 zfs 和 zpool 操作一样,重新排列操作会在线进行。
Expansion 可以多次进行,不过前提是存储池处于健康状态,如果磁盘挂掉,此过程会被暂停,以允许被重新构建,目前适用于 RAIDZ-1/2/3。下面的两张图说明了 RAID 4/5/6 的传统扩展方式(图 1)与新 RAID-Z Expansion 工作方式(图 2)之间的差异。
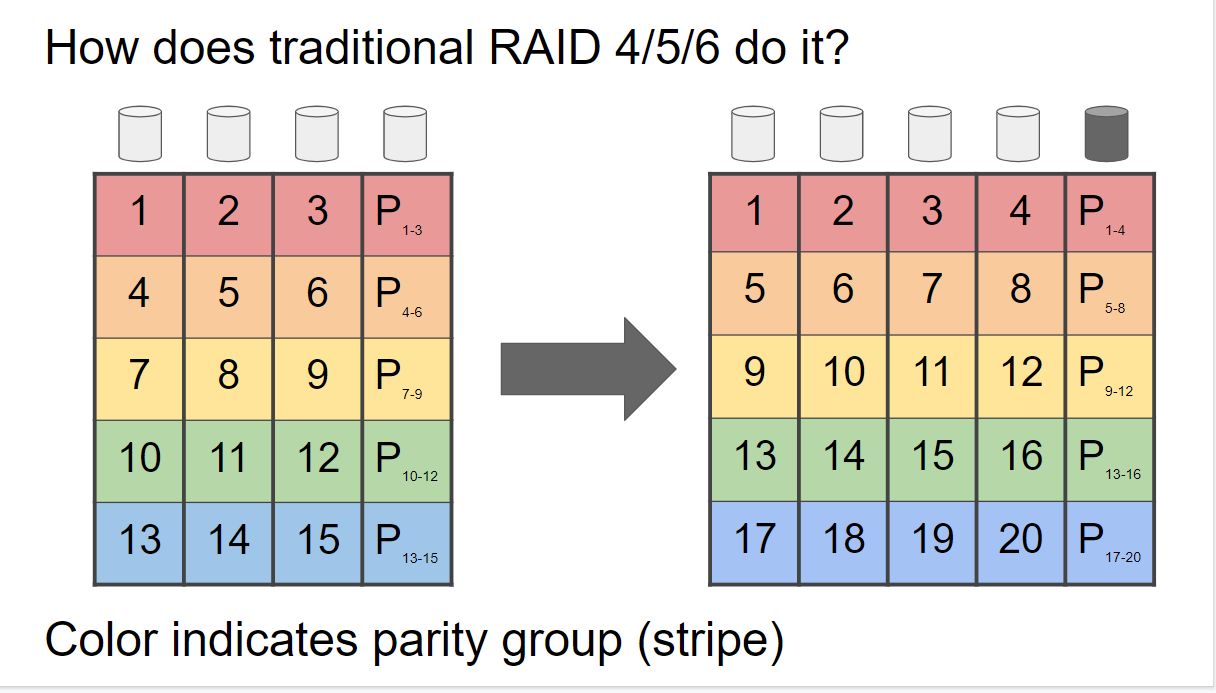
图1
重新排列的数据不会改变或读取块指针。读取和写入是按顺序进行的。空间图显示了哪些数据需要被复制。此外,每个 logical stripe 都是独立的,无需知道奇偶校验的位置。分段则仍然存储在不同的磁盘上,这保证了数据的冗余。
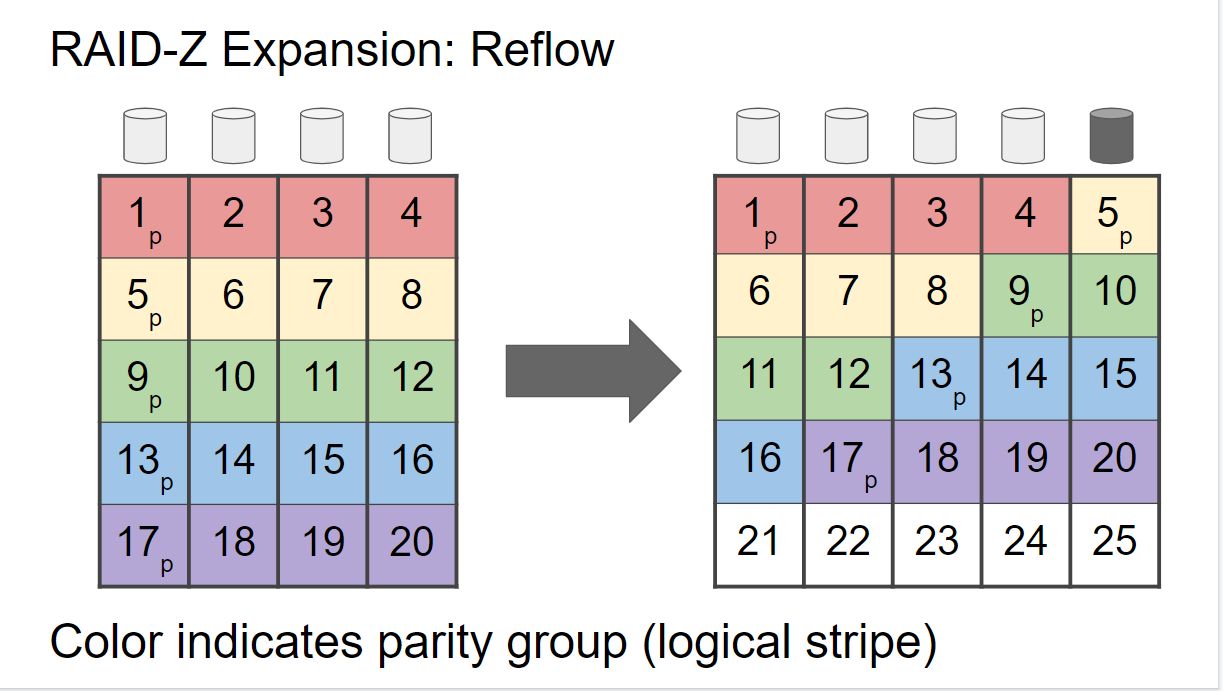
图2
使用方法
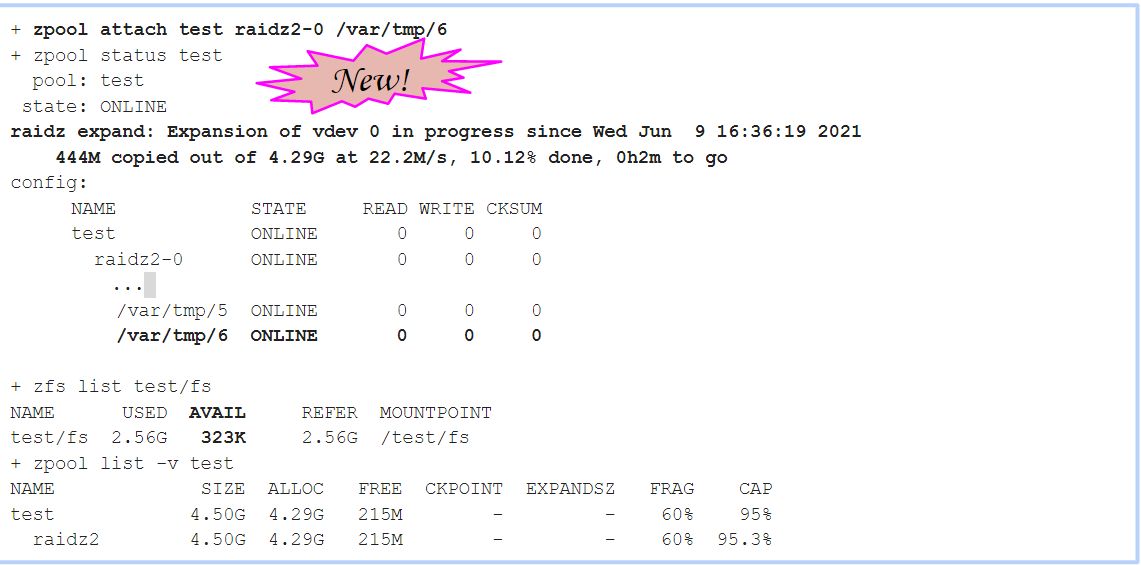
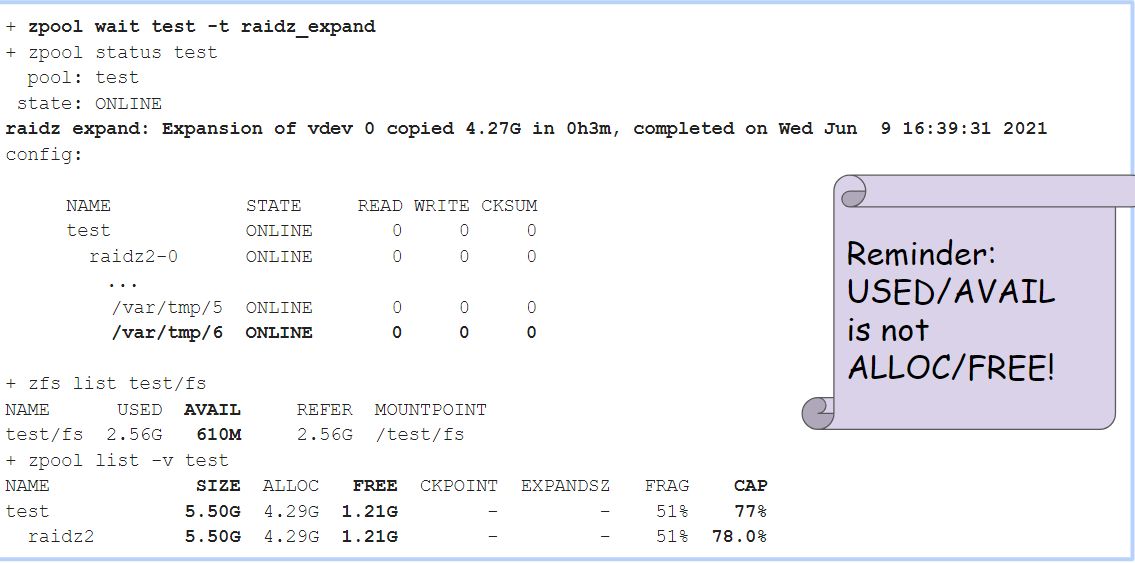
从命令行开始:
+ zpool attach test raidz2-0 /var/tmp/6
虽然 RAID-Z Expansion 的所有功能都已实现,而且到目前为止所有的测试都已通过,但仍有一些未尽事宜需要解决。具体来说,还需要清理代码、删除冗长的日志,编写代码文档,以及其他类似的相对较小的任务。官方称目标是在2022年第三季度前完成这些工作。不过最需要额外帮助的是进一步测试该功能,并在集成此功能前进行代码审查。