 众所周知,文件系统是操作系统最为重要的一部分,每种操作系统都有自己的文件系统,文件系统直接影响着操作系统的稳定性和可靠性。Linux下的文件系统通常有两种,即日志文件系统和非日志文件系统,以下简单介绍两类文件系统。
众所周知,文件系统是操作系统最为重要的一部分,每种操作系统都有自己的文件系统,文件系统直接影响着操作系统的稳定性和可靠性。Linux下的文件系统通常有两种,即日志文件系统和非日志文件系统,以下简单介绍两类文件系统。一、非日志文件系统
非日志文件系统在工作时,不对文件系统的更改进行日志记录。文件系统通过为文件分配文件块的方式把数据存储在磁盘上。每个文件在磁盘上都会占用一个以上的磁盘扇区,文件系统的工作就是维护文件在磁盘上的存放,记录文件占用了哪几个扇区。另外扇区的使用情况也要记录在磁盘上。文件系统在读写文件时,首先找到文件使用的扇区号,然后从中读出文件内容。如果要写文件,文件系统首先找到可用扇区,进行数据追加。同时更新文件扇区使用信息。不同的文件系统用不同的方法分配和读取文件块。例如,dos/windows 就使用fat文件系统,而windows Nt则采用NTFS文件系统。
非日志文件系统能够工作得很稳定,但是,它存在不少问题。各位请看,对于一个普通的日志文件系统,如Ext2文件系统,如果系统刚将文件的磁盘分区占用信息(meta-data)写入到磁盘分区中,还没有来得及将文件内容写入磁盘,这时意外发生了:系统断电了,结果会造成:文件的内容仍然是老内容,而meta-data信息是新内容,二者不一致了。
让我们再看一下Linux系统中fsck是如何工作的:通常情况下,当 Linux 系统启动时,首先运行fsck,由它扫描/etc/fstab 文件中列出的所有本地文件系统。fsck 的工作就是确保要装载的文件系统的元数据是处于可使用的状态。当系统关闭时,fsck又把所有的缓冲区数据转送到磁盘,并确保文件系统被彻底卸载,以保证系统下次启动时能够正常使用。
然而意想不到掉电或者其它故障会导致系统死机、重启。出现这种情况时,操作系统来不及卸载文件系统。重启后,fsck对磁盘进行彻底扫描,全面地检查元数据,竭尽全能修正检查过程中能找到的所有错误。对所有的元数据做彻底的一致性检查极其耗时。文件系统越大,完成彻底的扫描时间就越长。Fsck也会碰到它无法修复的磁盘错误。碰到这种情况,就是简单地将文件删除或另存为一个文件。在高密度访问的数据中心,fsck可能会造成极大的数据文件破坏。只有当fsck 完成扫描、检查与修复工作后,Linux系统才能开始使用。当然,如果有严重的文件或数据丢失的话,系统很可能无法重新启动了!
非日志文件系统的种类:Linux可以支持种类繁多的文件系统,几乎所有的Linux发行版都用ext2作为默认的文件系统,Ext2文件系统就是一个非日志文件系统。此外,Linux支持的其它非日志文件系统还有:FAT、VFAT、HPFS(OS/2)、NTFS(Windows NT)、Sun的UFS等。
二、日志式文件系统
日志文件系统则是在非日志文件系统的基础上,加入了文件系统更改的日志记录。日志文件的设计思想是:跟踪记录文件系统的变化,并将变化内容记录入日志。日志式文件系统的思想来自于大型数据库系统。数据库操作由多个相关的、相互依赖的子操作组成,任何一个子操作的失败都意味着整个操作的无效性,所以对数据的任何修改都要求回复到操作以前的状态。日志式文件系统采用了类似的技术。
日志文件系统在磁盘分区中保存有日志记录,写操作首先是对记录文件进行操作,若整个写操作由于某种原因(如系统掉电)而中断,系统重启时,会根据日志记录来恢复中断前的写操作。这个过程只需要几秒钟到几分钟。
A journaling file system is more reliable when it comes to data storage. Journaling file systems do not necessarily prevent corruption, but they do prevent inconsistency and are much faster at file system checks than non-journaled file systems. If a power failure happens while you are saving a file, the save will not complete and you end up with corrupted data and an inconsistent file system. Instead of actually writing directly to the part of the disk where the file is stored, it first writes it to another part of the hard drive and notes the necessary changes to a log, then in the background it goes through each entry to the journal and begins to complete the task, and when the task is complete, it checks it off on the list. Thus the file system is always in a consistent state (the file got saved, the journal reports it as not completely saved, or the journal is inconsistent (but can be rebuilt from the file system)). Some journaling file systems can prevent corruption as well by writing data twice.
Now below is a very brief comparison of the most common file systems in use with the Linux world.
FileSystem | MaxFile Size | MaxPartition Size | Journaling | Notes |
Fat16 | 2GB | 2GB | No | Legacy |
Fat32 | 4GB | 8TB | No | Legacy |
NTFS | 2TB | 256TB | Yes | (ForWindows Compatibility) NTFS-3g is installed by default in Ubuntu,allowing Read/Write support |
ext2 | 2TB | 32TB | No | Legacy |
ext3 | 2TB | 32TB | Yes | Standardlinux filesystem for many years. Best choice for super-standardinstallation. |
ext4 | 16TB | 1EiB | Yes | Moderniteration of ext3. Best choice for new installations wheresuper-standard isn't necessary. |
reiserFS | 8TB | 16TB | Yes | Nolonger well-maintained. |
JFS | 4PB | 32PB | Yes(metadata) | Createdby IBM - Not well maintained. |
XFS | 8EB | 8EB | Yes(metadata) | Createdby SGI. Best choice for a mix of stability and advancedjournaling. |
GB= Gigabyte (1024 MB) :: TB = Terabyte (1024 GB) :: PB = Petabyte(1024 TB) :: EB = Exabyte (1024 PB) | ||||
Above you'll see a brief comparison of two main attributes of different filesystems, the max file size and the largest a partition of that data can be. Of the above file systems the only one you cannot install Linux on is the NTFS. It is not recommended to install Linux on any type of FAT file system, because FAT does not have any of the permissions of a true Unix FS.
日志文件系统是如何工作的:在日志文件系统中,所有的文件系统的变化、添加和改变都被记录到“日志”(即记录文件metadata信息的数据)中。每隔一定时间,文件系统会将更新后的文件metadata及文件内容写入磁盘,之后删除这部分日志。重新开始新日志记录。
在对元数据做任何改变以前,文件系统驱动程序会向日志中写入一个条目,这个条目描述了它将要做些什么。然后,它继续并修改元数据。通过这种方法,日志文件系统就拥有了近期元数据被修改的历史记录,当检查到没有彻底卸载的文件系统的一致性问题时,只要根据数据的修改历史进行相应的检查即可了。也即日志文件系统除了存储数据和元数据(metadata)以外,它们还保存有一个日志,我们可以称之为元元数据(关于元数据的元数据)。日志文件系统使得数据、文件变安全了,但是系统开销加大了。每一次更新和大多数的日志操作都需要写同步,这需要更多的磁盘I/O操作。从日志文件的原理出发,将那些需要经常写操作的分区上使用日志文件系统是一个好的主意。
Linux系统中可以混合使用日志文件系统或非日志文件系统。日志增加了文件操作的时间,但从文件安全性角度出发,磁盘文件的安全性得到了重大的提高。笔者对日志文件系统进行了测试,日志文件系统的性能并不比ext2文件系统有太大的性能损失,有的日志文件系统由于采用B+树算法,在操作一些大尺寸的文件时,性能反面比非日志文件系统的性能还要好。
使用日志文件系统有什么好处:文件的安全提高了,文件被破坏的机率降低了,对磁盘的扫描时间缩短了,扫描次数减少了。当系统意外宕机后,不会再有文件内容的丢失,至少文件应该保持上一个版本的内容;采用日志文件系统,通常系统每重新启动20-30次后,才会对磁盘进行一次整体扫描,扫描次数减少了。
Linux操作系统下的日志文件系统:
XFS文件系统:SGI的xfs
JFS文件系统:IBM的jfs
Reiserfs文件系统:http://www.namesys.com
EXT3文件系统:http://www.zip.com.au/~akpm/linux/ext3/
GFS文件系统:http://linux4u.jinr.ru/LinuxArchive/Ftp/kernel/gfs/4.2/
Vertas文件系统:http://www.veritas.com/products/
Linux日志文件系统面面观
文件系统是用来管理和组织保存在磁盘驱动器上的数据的系统软件,其实现了数据完整性的保证,也就是保证写入磁盘的数据和随后读出的内容的一致性。除了保存以文件方式存储的数据以外,一个文件系统同样存储和管理关于文件和文件系统自身的一些重要信息(例如:日期时间、属主、访问权限、文件大小和存储位置等等)。这些信息通常被称为元数据(metadata)。
由于为了避免磁盘访问瓶颈效应,一般文件系统大都以异步方式工作,因此如果磁盘操作被突然中断可能导致数据被丢失。例如如果出现这种情况:如果当你处理一个在linux的ext2文件系统上的文档,突然机器崩溃会出现什么情况?有这几种可能:
1)当你保存文件以后,系统崩溃。这是最好的情况,你不会丢失任何信息。只需要重新启动计算机然后继续工作。
2)在你保存文件之前系统崩溃。你会丢失你所有的工作内容,但是老版本的文档还会存在。
3)当正在将保存的文档写入磁盘时系统崩溃。这是最糟的情况:新版文件覆盖了旧版本的文件。这样磁盘上只剩下一个部分新部分旧的文件。如果文件是二进制文件那么就会出现不能打开文件的情况,因为其文件格式和应用所期待的不同。
在最后这种情况下,如果系统崩溃是发生在驱动器正在写入元数据时,那么情况可能更糟。这时候就是文件系统发生了损坏,你可能会丢失整个目录或者整个磁盘分区的数据。
Linux标准文件系统(ext2fs)在重新启动时会通过调用文件扫描工具fsck试图恢复损坏的元数据信息。由于ext2文件系统保存有冗余的关键元数据信息的备份,因此一般来说不大可能出现数据完全丢失。系统会计算出被损坏的数据的位置,然后或者是通过恢复冗余的元数据信息,或者是直接删除被损坏或是元数据信息损毁的文件。
很明显,要检测的文件系统越大,检测过程费时就越长。对于有几十个G大小的分区,可能会花费很长时间来进行检测。由于Linux开始用于大型服务器中越来越重要的应用,因此就越来越不能容忍长时间的当机时间。这就需要更复杂和精巧的文件系统来替代ext2。因此就出现了日志式文件系统(journalling filesystems)来满足这样的需求。
大多数现代文件系统都使用了来自于数据库系统中为了提高崩溃恢复能力而开发的日志技术。磁盘事务在被真正写入到磁盘的最终位置以前首先按照顺序方式写入磁盘中日志区(或是log区)的特定位置。根据日志文件系统实现技术的不同,写入日志区的信息是不完全一样的。某些实现技术仅仅写文件系统元数据,而其他则会记录所有的写操作到日志中。现在如果崩溃发生在日志内容被写入之前发生,那么原始数据仍然在磁盘上,丢失的仅仅是最新的更新内容。如果当崩溃发生在真正的写操作时(也就是日志内容已经更新),日志文件系统的日志内容则会显示进行了哪些操作。因此当系统重启时,它能轻易根据日志内容,很快地恢复被破坏的更新。
在任何一种情况下,都会得到完整的数据,不会出现损坏的分区的情况。由于恢复过程根据日志进行,因此整个过程会非常快只需要几秒钟时间。应该注意的是使用日志文件系统并不意味着完全不需要使用文件扫描工具fsck了。随机发生的文件系统的硬件和软件错误是根据日志是无法恢复的,必须借助于fsck工具。
目前Linux环境下的日志文件系统:在下面的内容里将讨论三种日志文件系统:第一种是ext3,由Linux内核Stephen Tweedie开发。ext3是通过向ext2文件系统上添加日志功能来实现的,是自redhat7.2的默认文件系统;Namesys开发的 ReiserFs日志式文件系统,可以从这里下载,目前Mandrake8.1采用该日志式文件系统。SGI在2001年三月发布了XFS日志式文件系统。文章最后面将对这三种日志文件系统采用不同的工具进行检测和性能测试。
三、硬链接与软链接
Linux链接分两种,一种被称为硬链接(Hard Link),另一种被称为软链接,即符号链接(Symbolic Link)。
在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,这个编号被称之为索引节点号(Inode Index),也就是常说的inode号。Inode号上与文件名关联,下与用户数据库(data block)关联。
硬链接指文件名与索引节点号(即inode号)的链接(所以创建一个新的文件,该文件使用stat命令查看时,links显示的是1),索引节点号(inode号)可以对应一个或多个文件名,并且这些文件名可以在同一或不同目录。
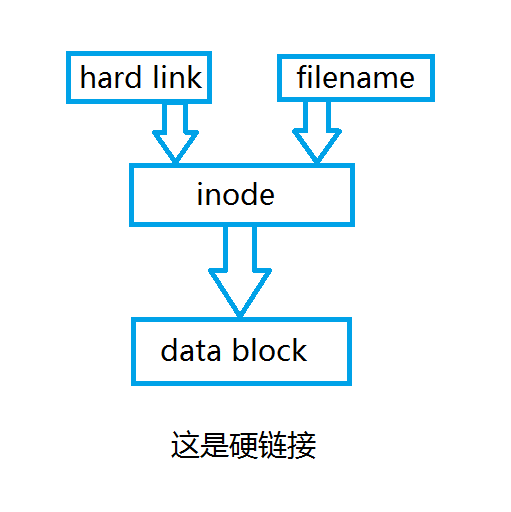
由于硬链接是直接将文件名与索引节点号(即inode号)链接,因此硬链接存在以下几个特点:
1、文件有相同的inode号及data block,这使得修改其中一个硬链接文件属性或文件数据时,其他硬链接文件都会发生相应修改;
2、只能对已存在的文件进行创建;
3、不能跨文件系统(即分区)进行创建;
4、不能对目录文件进行创建;
5、删除其中一个硬链接文件时,不会对其他硬链接文件产生影响。
软链接类似于Windows的快捷方式。它实际上是一个特殊的文件,有着自己的索引节点号(即inode号)以及用户数据块(data block),但用户数据块(data block)中包含的是另一个文件的位置信息。
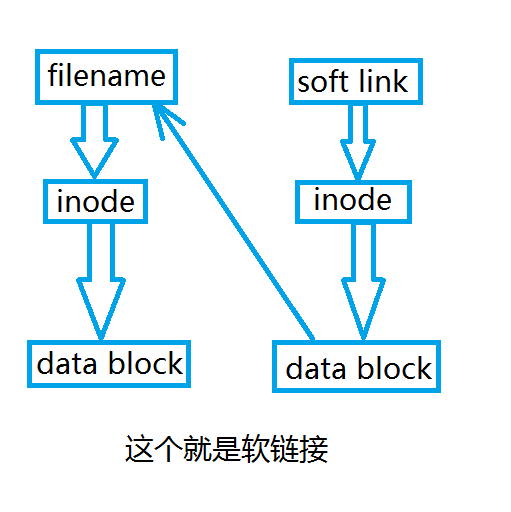
由于软链接有着自己的索引节点号(即inode号)以及用户数据块(data block),因此没有硬链接的诸多限制,它的特性如下:
1、软链接有自己的文件属性、inode号和data block,但是编辑文件其实就是编辑源文件;
2、可以对不存在的文件或目录进行创建;
3、可以跨文件系统(即分区)进行创建,使用ln命令跨文件系统创建时,源文件必须是绝对路径,否则为死链接;
4、可以对文件或目录文件进行创建;
5、删除软链接并不影响源文件,但源文件被删除,则相关软链接文件变为死链接(dangling link),若源文件(原地址原文件名)重新被创建,则死链接恢复为正常软链接。
实例:如果源文件没有给others读写权限,软链接显示的是有权限,但实际不能读写。
软、硬链接特性比较
1、硬链接与源文件具有相同inode号和data block,修改文件属性或文件数据会应影响所有硬链接(包括源文件);软链接虽然有自己的inode号和data block,但修改的其实还是源文件。
# stat File |grep Inode //也可使用ls -i File查看
2、硬链接不能对不存在的文件进行创建,但软链接可以(包括目录文件)
3、硬链接不可以跨文件系统(即分区)创建,软链接可以,但源文件必须是绝对路径,否则为死链接
4、硬链接不能对目录创建链接,但软链接可以
5、删除源文件,硬链接没有影响;软链接变成死链接,但在相同位置重新创建同名文件,软链接变成指向新文件的链接
注意:虽然目录无法创建硬链接,但是目录的链接数却是2。其实这是由于目录文件本身以及其下的'.'文件。
文件系统 I/O 设置与优化
Linux系统中文件系统的缺省配置一般来说都比较中庸,强调普遍适用性。然而在特定应用下,这种配置往往在I/O性能方面不能达到最优。如果应用对I/O性能要求较高,除了采用性能更高的硬件(如SSD)外还可以通过对文件系统进行性能调优,来获得更高的I/O性能提升。总的来说,主要可以从三个方面来做工作:
1、Disk相关参数调优
2、文件系统本身参数调优
3、文件系统挂载(mount)参数调优
当然,负载情况不同,需要结合理论分析与充分的测试和实验来得到合理的参数。下面以SAS(Serial attached SCSI)磁盘上的EXT3文件系统为例,给出Linux文件系统性能优化的一般方法。
1、Disk相关参数
1.1 Cache mode:启用WCE=1(Write Cache Enable), RCD=0(Read Cache Disable)模式
sdparm -s WCE=1, RCD=0 -S /dev/sdb
1.2 Linux I/O scheduler算法
经过实验,在重负载情形下,deadline调度方式对数据库I/O负载具有更好的性能表现。其他三种为noop(fifo)、as、cfq,noop多用于SAN/RAID存储系统,as多用于大文件顺序读写,cfq适于桌面应用。
echo deadline > /sys/block/sdb/queue/scheduler
1.3 deadline调度参数
对于redhat linux建议 read_expire = 1/2 write_expire,对于大量频繁的小文件I/O负载,应当这两者取较小值。更合适的值,需要通过实验测试得到:
echo 500 > /sys/block/sdb/queue/iosched/read_expire
echo 1000 > /sys/block/sdb/queue/iosched/write_expire
1.4 readahead 预读扇区数
预读是提高磁盘性能的有效手段,目前对顺序读比较有效,主要利用数据的局部性特点。比如在我的系统上,通过实验设置通读256块扇区性能较优:
blockdev --setra 256 /dev/sdb
2、EXT文件系统参数
2.1 block size = 4096 (4KB)
mkfs.ext3 -b指定,大的数据块会浪费一定空间,但会提升I/O性能。EXT3文件系统块大小可以为1KB、2KB、4KB。
2.2 inode size
这是一个逻辑概念,即一个inode所对应的文件相应占用多大物理空间。mkfs.ext3 -i指定,可用文件系统文件大小平均值来设定,可减少磁盘寻址和元数据操作时间。
2.3 reserved block
该值由'mkfs.ext3|4 -m'指定,缺省为5%,可调小该值以增大部分可用存储空间。可用以下方法释放ext3|4的保留空间,在较大的分区或是不重要的分区上这种设置会占据过多不必要的空间,利用mke2fs的-m reserved-percentage选项可以调整这个设置来获得更多的磁盘空间且不影响性能。而在创建了文件系统之后,用户可以用tune2fs来修改这个设置。
使用tune2fs来取得对应的分区设备的保留块的情况
tune2fs -l /dev/mapper/vg_data-lv_data | grep -i Reserved
2.3.1)、使用比例方法来调整
tune2fs -m 2 /dev/partition
tune2fs 1.39 (29-May-2006)
Setting reserved blocks percentage to 2% (NNN blocks)
'-m 2'就是保留2%的空间。不推荐0,因为如果是root盘还是有点保留一点好,一般留100~300M就可以了。
-m reserved-blocks-percentage
2.3.2)、直接设定保留块的大小
tune2fs -r NN /dev/partition
tune2fs 1.39 (29-May-2006)
Setting reserved blocks percentage to 2% (NN blocks)
保留100MB:
tune2fs -r 25600 /dev/sdx
100M=(25600*4Kb)/1024
保留256MB:
tune2fs -r 65536 /dev/sdx
命令执行完毕立即生效,无需重启。如果是数据盘默认的5%肯定是浪费了,2TB的硬盘格式化之后5%的保留空间是93.3G,不过数据盘不推荐使用EXT系列的格式。
2.4 disable journal
对数据安全要求不高的应用(如web cache),可以关闭日志功能,以提高I/O性能。
tune2fs -O^has_journal /dev/sdb
3、mount参数
3.1 noatime, nodirtime
访问文件目录,不修改访问文件元信息,对于频繁的小文件负载,可以有效提高性能。
3.2 async
异步I/O方式,提高写性能。
3.3 data=writeback (if journal)
日志模式下,启用写回机制,可提高写性能。数据写入顺序不再保护,可能会造成文件系统数据不一致性,重要数据应用慎用。
3.4 barrier=0 (if journal)
barrier=1,可以保证文件系统在日志数据写入磁盘之后才写commit记录,但影响性能。重要数据应用慎用,有可能造成数据损坏。这是在生产环境上的hdfs的独立硬盘的挂载参数:
defaults,inode64,nobarrier,nolargeio,noatime,nodiratime
4、小结
以/dev/sdb为例,优化操作方法如下:
sdparm -s WCE=1, RCD=0 -S /dev/sdb
echo deadline > /sys/block/sdb/queue/scheduler
echo 500 > /sys/block/sdb/queue/iosched/read_expire
echo 1000 > /sys/block/sdb/queue/iosched/write_expire
blockdev --setra 256 /dev/sdb
mkfs.ext3 -b 4096 -i 16384 -m 2 /dev/sdb1
tune2fs -O^has_journal /dev/sdb1
mount /dev/sdb1/cache1 -o defaults,noatime,nodirtime,async,data=writeback,barrier=0 (with journal)
mount /dev/sdb /cache1 -o defaults,noatime,nodirtime,async (without journal)
Ext4文件系统的一些特性
大文件顺序访问,衡量指标是IO吞吐量,文件系统性能瓶颈在 于数据块布局(layout)、数据寻址。Ext4对ext3主要作了两方面的优化:
1)、是inode预分配。这使得inode具有很好的局部性特征,同一目录文件inode尽量放在一起,加速了目录寻址与操作性能。因此在小文件应用方面也具有很好的性能表现。
2)、是extent/delay/multi的数据块分配策 略。这些策略使得大文件的数据块保持连续存储在磁盘上,数据寻址次数大大减少,显著提高I/O吞吐量。
因此对于顺序大I/O读写,EXT4是很好的选择,XFS性能在大文件方面也相当不错。
用到的命令:
检测硬盘的读效率:hdparm -tT /dev/hda
检测硬盘的写效率:time dd if=/dev/zero of=/media/freeoa-file bs=4k count=65536
写入字符到/media/freeoa-file文件,bs为块大小,count为快数。
系统IO情况:vmstat,如果wa大说明瓶颈在io上。iostat用于监视io情况。
I/O性能调优工具:
edquota
quoton
sysctl
system boot loader line:
elevator=xxx
磁盘IO优化
修改fstab,在加载参数上加入noatime,禁止加入访问文件时间
控制swappness 参数,尽量减少应用的内存被交换到交换分区中,默认是60
块大小的优化 ,节点块的优化(默认block size = 4096(4K),大的数据块会浪费一定的空间,比如此设置会使一个空的文件夹占用4K的空间,不过会提高I/O性能)
inode size:这是一个逻辑概念,即一个inode所对应的文件相应占用多大物理空间,mkfs.ext3 -i指定,可用文件系统文件大小平均值来设定,可减少磁盘寻址和元数据操作时间
linux I/O调度方式启用异步方式,提高读写性能
有关IO的几个内核参数:
/proc/sys/vm/dirty_ratio
这个参数控制文件系统的文件系统写缓冲区的大小,单位是百分比,表示系统内存的百分比,表示当写缓冲使用到系统内存多少的时候,开始向磁盘写出数据。增大之会使用更多系统内存用于磁盘写缓冲,也可以极大提高系统的写性能。但是,当你需要持续、恒定的写入场合时,应该降低其数值,一般启动上缺省是 10。
/proc/sys/vm/dirty_expire_centisecs
这个参数声明Linux内核写缓冲区里面的数据多“旧”了之后,pdflush进程就开始考虑写到磁盘中去。单位是 1/100秒。缺省是 30000,也就是 30 秒的数据就算旧了,将会刷新磁盘。对于特别重载的写操作来说,这个值适当缩小也是好的,但也不能缩小太多,因为缩小太多也会导致IO提高太快。建议设置为 1500,也就是15秒算旧。
/proc/sys/vm/dirty_background_ratio
这个参数控制文件系统的pdflush进程,在何时刷新磁盘。单位是百分比,表示系统内存的百分比,意思是当写缓冲使用到系统内存多少的时候, pdflush开始向磁盘写出数据。增大之会使用更多系统内存用于磁盘写缓冲,也可以极大提高系统的写性能。但是,当你需要持续、恒定的写入场合时,应该 降低其数值,一般启动上缺省是 5。
/proc/sys/vm/dirty_writeback_centisecs
这个参数控制内核的脏数据刷新进程pdflush的运行间隔。单位是 1/100 秒。缺省数值是500,也就是 5 秒。如果你的系统是持续地写入动作,那么实际上还是降低这个数值比较好,这样可以把尖峰的写操作削平成多次写操作。当然最主要的还是升级硬件或通过做RAID实现。
I/O性能调整
系统出现以下情况时,我们认为该系统存在I/O性能问题:
系统等待I/O的时间超过50%;
一个设备的平均队列长度大于5。
我们可以通过诸如vmstat等命令,查看CPU的wa等待时间,以得到系统是否存在I/O性能问题的准确信息。
I/O性能调整方法:
1、修改I/O调度算法。
Linux已知的I/O调试算法有4种:
deadline - Deadline I/O scheduler
as - Anticipatory I/O scheduler
cfq - Complete Fair Queuing scheduler
noop - Noop I/O scheduler
# more /boot/grub/grub.cfg
linux /vmlinuz-3.2.0-4-amd64 root=UUID=nnn ro ipv6.disable=1 elevator=deadline quiet nmi_watchdog=0
# vim /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="elevator=deadline quiet"
编辑/etc/default/grub文件,加入
elevator=ios
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash" 改为
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash elevator=deadline ipv6.disable=1"
执行update-grub重写系统的引导加载程序,重启后生效。
文件系统调整公认的准则
将I/O负载相对平均的分配到所有可用的磁盘上;
选择合适的文件系统,Linux内核支持reiserfs、ext2、ext3、jfs、xfs等文件系统,优先选用xfs;
文件系统即使在建立后,本身也可以通过命令调优:
tune2fs (extn)
reiserfstune
jfs_tune
xfs_admin
文件系统Mount时可加入选项noatime、nodiratime来减少被动的I/O。
# vi /etc/fstab
…
/dev/sdb1 /backup reiserfs acl, user_xattr, noatime, nodiratime 1 1
调整块设备的READAHEAD,调大RA值,先查看一下:
# blockdev --report
RO RA SSZ BSZ StartSec Size Device
…
rw 256 512 4096 0 71096640 /dev/sdb
rw 256 512 4096 32 71094240 /dev/sdb1
重新设置:
# blockdev --setra 2048 /dev/sdb1
# blockdev --report
RO RA SSZ BSZ StartSec Size Device
…
rw 2048 512 4096 0 71096640 /dev/sdb
rw 2048 512 4096 32 71094240 /dev/sdb1
Ext文件系统运行时状态参数
tune2fs命令是针对ext2+的文件系统非常有用的工具。
1、使用'-l'选项查看文件系统参数,它将以key=>value的形式返回。
2、改变最大挂载量及被挂载次数
默认地,最大挂载数(maximum mount count)被设置为'-1',这意味着该文件系统不会被e2fsck所处理,下面将设定其值为20,即每被挂载过20次就将会被e2fsck工具检查一次。
tune2fs -l /dev/sda1| grep -i mount
tune2fs -c 20 /dev/sda1
当前的被挂载数也可以被设定,下面将该值设定为5次。
tune2fs -C 5 /dev/sda1
3、使用'-j'选项转换文件系统类型,仅用于将ext2转为ext3。
tune2fs -j /dev/sdb1
'-j'仅是一个测试而已,但可能会损坏文件系统,在操作前请确认。想改变默认的日志参数,就需要使用'-J'参数了,它有若干子命令:size=journal-size, device=external-journal,location=journal-location。具体还要参考其手册。
注意只有一个值能被一次设定到该文件系统
tune2fs -J size=4MB /dev/sda10
为分区设置标签
tune2fs -L "ROOT" /dev/sda10
4、设置文件系统的属性
使用'-O'参数来设置来将ext3转为ext4。
tune2fs -O extents,uninit_bg,dir_index /dev/sda2
注意:该操作同样具有测试性质,可能会导致文件系统损坏。下面的可以使用的选项参数:
debug
bsdgroups
user_xattr
acl
uid16
journal_data
journal_data_ordered
journal_data_writeback
nobarrier
block_validity
discard
nodelalloc
查看与设置卷的标签
查看/dev/sda1的标签名称
# tune2fs -l /dev/sda1 | grep -i name
Filesystem volume name:
为其设定一个友好的标签名
# tune2fs -L /home /dev/sda2
列出被挂载目录与最后检查时间
使用'-M'来设定文件系统设置最后安装的目录。还可以使用'-T'选项指定上次执行文件系统检查的时间。在正常情况下不需要设置此项。但是当使用LVM时就可能需要这样做来获取一致性快照。
The following indicates when the filesystem was checked last.
# tune2fs -l /dev/sda1 | grep -i check
Last checked:Mon Jul 15 20:46:13 2019
Check interval:0 (<none>)
下面将最后一次检查设置为当前时间戳,只有当知道文件系统是干净的时才这样做。
# tune2fs -T now /dev/sda1
日期时间格式:YYYYMMDD [HH[MM[SS]]]
在特定的时间执行相关检查
就像挂载时依赖检查一样。在挂载了N数次之后对文件系统进行检查,还可以进行特定的时间进行检查,在x天、月或周之后检查文件系统。下面的示例指示将在10天后执行文件系统检查。
# tune2fs -i 10d /dev/sda1
Setting interval between checks to 864000 seconds
可以查看当前的时间相关检查,如下所示。
# tune2fs -l /dev/sda1 | grep -i check
Last checked:Tue Jan 8 20:33:05 2019
Check interval:864000 (1 week, 3 days)
Next check after:Fri Jan 18 20:33:05 2019
可选的时间间隔
10d – Indicates 10 days (same as 10)
10w – Indicates 10 weeks
10m – Indicates 10 months
dumpe2fs也一个专门针对ext1+的文件系统工具,它会展示超级块与块组的信息
dumpe2fs /dev/sda1
使用'-b'可显示文件系统中保留为坏块(没有输出意味着无坏块)
检查文件系统中的错误
e2fsck就是为ext[2-4]的检查修复工具,可通过调用fsck.ext[n]来实现。
e2fack/fsck 工具是否对文件系统检查依赖于 /etc/fstab 中所定义的批示参数,在文件系统未被正常卸载时会被调用。
注意:该工具不能对已经挂载了的文件系统运行,可能会导致文件系统损坏。
使用'-V'参数来开启详细输出,'-t'可用于指定文件系统类型
$ fsck -Vt ext4 /dev/sda1
EXT文件系统调试
debugfs是一个简单的交互式的ext[2-4]文件系统调试工具,它的子命令可能通过'?'来提示。
debugfs /dev/sda1
默认情况下,文件系统应该以读写模式打开,使用'-w'选项可以开启读写模式。要在紧急模式下打开它,请使用'-c'选项。
显示可用空间碎片,请使用freefag指令
debugfs: freefrag
使用'q'选项来退出该工具。
Linux tune2fs Command
硬盘管理技巧速看
在Linux系统运维中,硬盘管理是每位工程师必须掌握的核心技能。无论是服务器磁盘空间告急,还是业务扩容需要在线扩展存储,高效的存储管理能力直接关系到系统稳定性和数据安全。据调查显示,超过40%的服务器故障由磁盘问题引发。在此将解析20个关键磁盘管理技巧,涵盖从基础查看命令到高级LVM操作的相关知识,助力构建完整的磁盘管理知识体系。
1、基础查看与信息获取
1. 块设备拓扑查看(lsblk)
lsblk -o NAME,SIZE,FSTYPE,MOUNTPOINT
此命令以树状结构清晰展示磁盘、分区及挂载点的关系,是快速定位存储架构的首选工具。
2. 设备标识解析(blkid)
blkid /dev/sda1
输出设备的UUID和文件系统类型,避免设备名变更导致的挂载错误,是配置/etc/fstab的最佳实践。
3. 磁盘健康监测(smartctl)
smartctl -a /dev/sda
通过SMART协议获取硬盘健康状态,可提前预判磁盘故障,包含温度、坏道计数等关键指标。
4. 空间概览分析(df)
df -hT --total
-h 以人性化单位显示,-T 包含文件系统类型,--total 生成汇总统计,快速定位空间紧张的分区。
2、分区与格式化
5. 分区表操作选择
• fdisk:适用于传统MBR分区(≤2TB)
• parted:支持GPT分区(>2TB磁盘必备)
parted /dev/sdb mklabel gpt mkpart primary xfs 0% 100%
parted支持百分比分配,避免柱面计算错误。
6. 分区无损调整策略
使用gparted LiveCD调整已分区磁盘:
1).下载ISO制作启动盘
2).BIOS设置USB/CD启动
3).图形化调整分区边界
4).数据备份是必要前提
7. 文件系统创建优化
mkfs.xfs -f /dev/sdb1 # 强制创建
mkfs.ext4 -i 8192 /dev/sdb2 # 调整inode密度
根据文件数量规模合理配置inode,避免小文件场景下inode耗尽。
3、挂载与自动挂载
8. UUID挂载实践
# 获取UUID
blkid /dev/sdb1
# /etc/fstab配置
UUID=1234-5678 /data xfs defaults 0 0
设备名(/dev/sdX)可能变动,UUID是唯一持久标识。
9. 临时挂载组合技
mount -o noatime,nodev /dev/sdc1 /mnt/tmp
noatime 禁用访问时间写入,降低磁盘I/O压力,适合日志缓存等场景。
10. 自动挂载增强
/etc/fstab高级参数:
# 网络存储场景
nas:/share /mnt/nfs nfs rw,hard,intr 0 0
# 磁盘错误防护
/dev/sdb1 /data ext4 defaults,nofail 0 2
nofail 选项允许磁盘不存在时系统继续启动。
4、空间分析与清理
11. 目录深度扫描(du)
du -h --max-depth=1 /var | sort -hr
--max-depth 控制扫描层级,搭配 sort -hr 实现降序排序,快速定位大目录。
12. 日志文件精准清理
journalctl --vacuum-size=200M # 限制日志大小
logrotate -f /etc/logrotate.conf # 强制轮转
避免直接rm删除,使用工具确保日志服务连续性。
13. 大文件狩猎技巧
find / -type f -size +1G -exec ls -lh {} \;
扫描1GiB以上文件并列出。
5、LVM常见管理
14. LVM三件套创建
pvcreate /dev/sdb # 物理卷
vgcreate data_vg /dev/sdb # 卷组
lvcreate -L 10T -n data_lv data_vg # 逻辑卷
物理卷→卷组→逻辑卷的层级管理,实现存储池化。
15. 在线扩容四步法
lvextend -L +5G /dev/data_vg/data_lv # 扩展逻辑卷
resize2fs /dev/data_vg/data_lv # EXT4调整
xfs_growfs /data # XFS调整
vgextend data_vg /dev/sdc # 扩展卷组
业务零停机扩容的关键步骤,注意文件系统类型匹配命令。
16. LVM快照备份
lvcreate -L 1G -s -n db_snap /dev/data_vg/db_lv
创建一致性时间点快照,适用于数据库备份。
6、文件系统深度技巧
17. Inode与Block解析
• inode:存储文件元信息(权限、时间戳、block指针)
• block:实际数据存储块
小文件场景需关注inode使用率(df -i)。
18. 文件系统修复流程
umount /dev/sdb1 # 必须先卸载
fsck -y /dev/sdb1
禁止对已挂载文件系统执行fsck,否则导致元数据损坏。
7、RAID配置
19. 软RAID创建
mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sdd /dev/sde
常用RAID级别:
• RAID 0:条带化(性能翻倍,无冗余)
• RAID 1:镜像(冗余性强,容量减半)
• RAID 5:分布式校验(性能与冗余平衡)
8、性能监控与优化
20. 磁盘I/O性能分析
iostat -dx 1 # 设备级I/O统计
iotop # 进程级I/O排序
定位高IO进程,%util超过80%表示磁盘饱和。
小结
1. 分区策略:/home单独分区,系统与数据隔离
2. 文件系统选型:XFS适合大文件,EXT4通用性强
3. LVM强制使用:生产环境必选,避免分区大小固化
4. 空间预警机制:df + du + find组合监控
5. 备份为先:任何磁盘操作前验证备份可用性
文件系统参数调优之tune2fs、xfs_admin、btrfs指令
1、文件系统调优核心思路与注意事项
调优原则:
先基准测试(fio / iozone),再调优加验证;
备份优先(LVM 快照或 rsync);
线上操作需谨慎,多数参数支持在线修改,少数需 remount 或 fsck;
结合硬件:SSD 必加 discard、NVMe 优化队列深度;
监控跟进:iostat、iotop、Prometheus 观察调优前后变化。
202x年主流硬件适配:NVMe 4.0+、企业级SSD、ARM64 服务器。
2、ext4 调优神器:tune2fs 全面指南
tune2fs 是 ext4 最强大、最常用的调优工具,可修改超级块参数。
常用查看命令:
tune2fs -l /dev/datavg/data_lv | less # 查看所有参数
dumpe2fs -h /dev/sda1 # 更详细超级块信息
生产推荐调优命令(一次性执行):
# 基础安全与性能调优
tune2fs -m 1 /dev/sda1 # 预留块降至 1%(让出空间)
tune2fs -O extents,uninit_bg,dir_index,has_journal,sparse_super,large_file /dev/sda1
tune2fs -E lazy_itable_init=1 /dev/sda1 # 延迟 inode 初始化(快速格式化)
# 性能关键参数
tune2fs -o journal_data_ordered /dev/sda1 # 日志模式(平衡性能与安全)
tune2fs -c 30 -i 30d /dev/sda1 # 强制 fsck 间隔(更宽松)
tune2fs -r 0 /dev/sda1 # 关闭保留块(生产数据盘)
# SSD 专用
tune2fs -o discard /dev/sda1 # 启用在线 TRIM
在线修改挂载选项(无需 remount):
mount -o remount,noatime,nodiratime,discard,barrier=0 /data
ext4 推荐生产挂载选项(/etc/fstab):
UUID=xxxx /data ext4 defaults,noatime,nodiratime,discard,commit=60,data=ordered 0 2
3、XFS 调优工具:xfs_admin 与 xfs_info
XFS 调优相对简单,但效果显著。
查看信息:
xfs_info /data
xfs_admin -u /dev/datavg/data_lv # 查看 UUID
关键调优命令:
# 格式化时推荐参数(最重要!)
mkfs.xfs -f -i size=512 -m crc=1,reflink=1,rmapbt=1, -b size=4k /dev/nvme1n1p1
# 在线调整
xfs_admin -L newlabel /dev/xxx # 修改标签
xfs_growfs /data # 在线扩容(LVM 配合)
# 碎片整理
xfs_fsr -v /data # 在线碎片整理
推荐挂载选项:
defaults,noatime,nodiratime,discard,allocsize=4m,swalloc
XFS 大文件/数据库场景优化:
增大 log size(格式化时 -l size=128m)
启用 reflink(节省空间,类似 cp --reflink)
4、Btrfs 调优工具全家桶
Btrfs 特性丰富,调优命令比较多。
核心命令:
btrfs filesystem df /data # 详细空间使用
btrfs filesystem usage /data
btrfs filesystem show
# 平衡数据块(解决碎片化)
btrfs balance start -dusage=80 -musage=80 /data
btrfs balance start -v /data # 全平衡(小心,耗时长)
# 压缩与 autodefrag
btrfs property set /data compression zstd:3
mount -o compress=zstd:3,autodefrag /data
# 清理与维护
btrfs scrub start -Bd /data # 数据校验 + 修复
btrfs quota enable /data
btrfs filesystem defragment -r -v -cless /data
推荐挂载选项:
compress=zstd:3,noatime,space_cache=v2,autodefrag,commit=60,discard=async
子卷优化:
btrfs subvolume create /data/@app
btrfs subvolume set-default /data/@app
5、三大文件系统参数对比与性能调优建议
| 参数维度 | ext4 (tune2fs) | XFS | Btrfs | 推荐场景 |
| 预留块 | tune2fs -m 1 | 无需 | 无需 | 数据盘 |
| TRIM/discard | 支持 | 支持 | 支持 async | 所有 SSD |
| 压缩 | 无原生 | 无 | zstd:3(最佳) | Btrfs |
| 碎片整理 | e4defrag | xfs_fsr | balance + defragment | 长期运行系统 |
| 日志模式 | journal_data_ordered | 内置 | CoW | 数据库慎用 barrier=0 |
| 在线扩容 | resize2fs | xfs_growfs | btrfs filesystem resize | LVM 配合 |
| 快照 | 靠 LVM | 靠 LVM | 原生子卷 | Btrfs |
数据库场景推荐:
MySQL/PostgreSQL → XFS + large allocsize
高并发小文件 → ext4 + dir_index
需要快照/回滚 → Btrfs + zstd
6、生产调优完整流程
基准测试:fio --name=test --size=10G --rw=randrw --bs=4k
备份/快照
应用推荐参数(格式化或 tune)
remount 测试
负载测试验证
监测一周来观察 await、%util、碎片率
7、生产事故复盘
事故1:ext4 未启用 discard,SSD 使用 18 个月后写入速度下降 70%,切换 discard 后恢复。
事故2:Btrfs 未定期 balance,碎片化导致 ls 命令耗时从 0.1s 升到 8s。
事故3:XFS 格式化时未加 reflink,大文件复制占用双倍空间。
事故4:tune2fs 修改后未更新 fstab,重启后参数丢失。
事故5:数据库分区 barrier=1 未关闭,TPS 比优化后低 35%。
谈谈Linux文件IO路径
这里以穿越各层看写文件工作方式,程序的最终目的是要把数据写到磁盘上,但是系统从通用性和性能角度,尽量提供一个折中的方案来保证这些,先来看一个最常用的写文件典型示例,也是路径最长的IO。
{
char *buf = malloc(MAX_BUF_SIZE);
strncpy(buf, src, , MAX_BUF_SIZE);
fwrite(buf, MAX_BUF_SIZE, 1, fp);
fclose(fp);
}
这里malloc的buf对于图层中的application buffer,即应用程序的buffer;调用fwrite后,把数据从application buffer 拷贝到了CLib buffer,即C库标准IObuffer。fwrite返回后,数据还在CLib buffer,如果这时候进程core掉,这些数据会丢失,不会写到磁盘介质上。当调用fclose的时候,fclose调用会把这些数据刷新到磁盘介质上。除了fclose方法外,还有一个主动刷新操作fflush函数,不过fflush函数只是把数据从CLib buffer拷贝到page cache中,并没有刷新到磁盘上,从page cache刷新到磁盘上可以通过调用fsync函数完成。
从上面类子看到,一个常用的fwrite函数过程,基本上历经千辛万苦,数据经过多次复制转发才到达目的地。有人会有疑问,这样会提高性能吗,反而会降低性能吧。这个问题先放一放。
也有人说我不想通过fwrite+fflush这样组合,我想直接写到page cache,这就是我们常见的文件IO调read/write函数。这些函数基本上是一个函数对应着一个系统调用,如sys_read/sys_write.调用write函数,是直接通过系统调用把数据从应用层拷贝到内核层,从application buffer 拷贝到 page cache 中。
系统调用,write会触发用户态/内核态切换?是的,那有没有办法避免这些消耗?有,此时该mmap出场了,mmap把page cache 地址空间映射到用户空间,应用程序像操作应用层内存一样,写文件省去了系统调用开销。那如果继续刨根问底,如果想绕过page cache,直接把数据送到磁盘设备上怎么办。通过open文件带上O_DIRECT参数,这是write该文件。就是直接写到设备上。如果继续较劲,直接写扇区有没有办法。这就是所谓的RAW设备写,绕开了文件系统,直接写扇区,像fdsik、dd、cpio之类的工具就是这一类操作。
IO调用链
列举了上述各种穿透各种cache 层写操作,可以看到系统提供的接口相当丰富,满足你各种写要求。下面通过讲解了解一下文件IO的调用链。
fwrite是系统提供的最上层接口,也是最常用的接口。它在用户进程空间开辟一个buffer,将多次小数据量相邻写操作先缓存起来、合并、最终调用write函数一次性写入(或者将大块数据分解多次write调用)。
Write函数通过调用系统调用接口,将数据从应用层copy到内核层,所以write会触发内核态/用户态切换。当数据到达page cache后,内核并不会立即把数据往下传递。而是返回用户空间。数据什么时候写入硬盘,有内核IO调度决定,所以write是一个异步调用。这一点和read不同,read调用是先检查page cache里面是否有数据,如果有,就取出来返回用户,如果没有,就同步传递下去并等待有数据,再返回用户,所以read是一个同步过程。当然你也可以把write的异步过程改成同步过程,就是在open文件的时候带上O_SYNC标记。
数据到了page cache后,内核有pdflush线程在不停的检测脏页,判断是否要写回到磁盘中。把需要写回的页提交到IO队列--即IO调度队列,又通过IO调度队列调度策略调度何时写回。提到IO调度队列,不得不提一下磁盘结构。这里要讲一下,磁头和电梯一样,尽量走到头再回来,避免来回抢占是跑,磁盘也是单向旋转,不会反复逆时针顺时针转的。
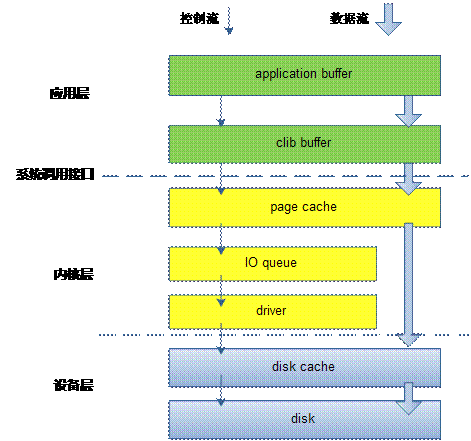
IO队列有2个主要任务:一是合并相邻扇区的,二是排序。合并相信很容易理解,排序就是尽量按照磁盘选择方向和磁头前进方向排序,因为磁头寻道时间是和昂贵的。
这里IO队列和我们常用的分析工具IOStat关系密切。IOStat中rrqm/s wrqm/s表示读写合并个数。avgqu-sz表示平均队列长度。
内核中有多种IO调度算法。当硬盘是SSD时候,没有什么磁道磁头,是随机读写的,加上这些调度算法反而画蛇添足。刚好有个调度算法叫noop调度算法,就是什么都不错(合并是做了),刚好可以用来配置SSD硬盘的系统。
从IO队列出来后,就到了驱动层(当然内核中有更多的细分层,这里忽略掉),驱动层通过DMA,将数据写入磁盘cache。至于磁盘cache时候写入磁盘介质,那是磁盘控制器自己的事情;如果想要睡个安慰觉,确认要写到磁盘介质上。就调用fsync函数吧,它可以确定写到磁盘上了。
一致性和安全性
谈完调用细节,再将一下一致性问题和安全问题。既然数据没有到到磁盘介质前,可能处在不同的物理内存cache中,那么如果出现进程死机、内核死机、掉电这样事件发生,数据会丢失吗?
当进程死机后:只有数据还处在application cache或CLib cache时候,数据会丢失。数据到了page cache。进程core掉,即使数据还没有到硬盘,数据也不会丢失。
当内核core掉后:只要数据没有到达disk cache,数据都会丢失。
掉电情况呢:这时候谁也救不了你,结果不用多说。
那么一致性呢,如果两个进程或线程同时写,会写乱吗?或A进程写,B进程读,会写脏吗?
在这里讲一下大概判断原则吧。fwrite操作的buffer是在进程私有空间,两个线程读写,肯定需要锁保护的;如果进程,各有各的地址空间,是否要加锁,看具体的应用场景。
write操作如果写大小小于PIPE_BUF(一般是4096),是原子操作,能保证两个进程“AAA”,“BBB”写操作,不会出现“ABAABB”这样的数据交错。O_APPEND标志能保证每次重新计算pos,写到文件尾的原子性。
数据到了内核层后,内核会加锁,会保证一致性的。
性能问题
性能从系统层面和设备层面去分析,磁盘的物理特性从根本上决定了性能。相关使用的IO调度策略,系统调用也是致命杀手。
磁盘的寻道时间是相当的慢,平均寻道时间大概是在10ms,也就是是每秒只能100-200次寻道。磁盘转速也是影响性能的关键,目前最快15000rpm,大概就每秒500转,满打满算,就让磁头不寻道,设想所有的数据连续存放在一个柱面上。大家可以算一下每秒最多可以读多少数据,当然这个是理论值。一般情况下,盘片转太快导致磁头感应跟不上,所以需要转几圈才能完全读出磁道内容。另外设备接口总线传输率是实际速率的上限。有些等密度磁盘,磁盘外围磁道扇区多,线速度快,如果频繁操作的数据放在外围扇区,也能提高性能。利用多磁盘并发操作,也不失为提高性能的手段。
这里给个业界经验值:机械硬盘顺序写~30MB,顺序读取速率一般~50MB好的可以达到100多M,SSD读达到~400MB,SSD写性能和机械硬盘差不多。
O_DIRECT 和 RAW设备最根本的区别是O_DIRECT是基于文件系统的,也就是在应用层来看,其操作对象是文件句柄,内核和文件层来看,其操作是基于inode和数据块,这些概念都是和ext2/3的文件系统相关,写到磁盘上最终是ext3文件。
而RAW设备写是没有文件系统概念,操作的是扇区号,操作对象是扇区,写出来的东西不一定是ext3文件(如果按照ext3规则写就是ext3文件)。
一般基于O_DIRECT来设计优化自己的文件模块,是不满系统的cache和调度策略,自己在应用层实现这些,来制定自己特有的业务特色文件读写。但是写出来的东西是ext3文件,该磁盘卸下来,mount到其他任何linux系统上,都可以查看。而基于RAW设备的设计系统,一般是不满现有ext3的诸多缺陷,设计自己的文件系统,来自行设计文件布局和索引方式。举个极端例子:把整个磁盘做一个文件来写,不要索引。这样没有inode限制,没有文件大小限制,磁盘有多大,文件就能多大。这样的磁盘卸下来,mount到其他linux系统上,是无法识别其数据的。
两者都要通过驱动层读写,在系统引导启动,还处于实模式的时候,可以通过bios接口读写raw设备。
Linux各种文件系统(ext3,reiserfs,jfs,xfs)的性能
现在还可以得到的许多Linux filesystems 比较,但是他们中大多数是古老的,基于为人任务的或者在更老的情况下完成。 这篇基准测试文基于与老一代的适合一台文件服务器的11项硬件(奔腾II/III,EIDE硬盘)。
从最初编制到出版,文章已经产生许多变化,意见和建议改进,目前正努力进行一些新的试验(回答在原文范围的问题)。
为什么要做基准测试?
我发现quantitative and reproductible benchmark基准使用2.6.x kernel。Benoit在2003年在有512 MB RAM 的PIII 500服务器上使用大文件(1 + GB)实现12次试验。 这次试验信息十分丰富,但是结果对2.6.x kernel开始,主要适用于底座, 专门操作大的锉(例如,多媒体、科学、数据库)。Piszcz 在2006年实现21项任务(有768 MB RAM 和一个400GBEIDE-133硬盘在PIII-500 模拟多种文件操作)。到目前为止,这测试看起来是在2.6.x kernel上的最全面的工作。 但很多任务是人造的(例如,复制和删除10,000个空目录,新建10,000个文件,递归分割文件),把这些结论应用到现实世界可能是无意义的。因此测试的基准的目标是验证一些Piszcz(2006)的结论, 通过专门应用于现实世界在小型企业文件服务器(看见任务描述)里找到。
测试基础
* Hardware Processor : Intel Celeron 533
* RAM : 512MB RAM PC100
* Motherboard : ASUS P2B
* Hard drive : WD Caviar SE 160GB (EIDE 100, 7200 RPM, 8MB Cache)
* Controller : ATA/133 PCI (Silicon Image)
* OS Debian Etch (kernel 2.6.15), distribution upgraded on April 18, 2006
* All optional daemons killed (cron,ssh,saMBa,etc.)
* Filesystems Ext3 (e2fsprogs 1.38)
* ReiserFS (reiserfsprogs 1.3.6.19)
* JFS (jfsutils 1.1.8)
* XFS (xfsprogs 2.7.14)
选择的测试任务描述
*在一个大文件(ISO 镜像文件,700 MB)的从第2个磁盘复制到这个试验磁盘
*再从在另一个位置再复制这个 ISO 一次
*删除这个ISO 的两个副本
*操作一文件树(有7500 文件,900 目录,1.9GB),从第2 磁盘复制到这个试验磁盘
*再从在另一个位置再复制这个文件树一次
*删除这个文件树的两个副本
*用递归的方法遍历文件树目录和文件树的全部内容,复制到这个试验磁盘
*匹配通配符,在文件树查找具体的文件
*用(mkfs) 建立filesystem(全部FS都使用默认值)
*mount filesystem
*Umount filesystem
上述11项任务(从建立filesystem到umounting filesystem)的顺序,编写为Bash script运行完成3 次(报告平均成绩)。 每个顺序花费大约7分种,完成任务的时间用秒计算, GNU time utility (version 1.7) 记录任务时的CPU 的利用百分比。
结果
分区能力
(在filesystem 创造之后)初始化分区并重新划分block的过程里,Ext3有最差的初始利用率(92.77%), 其它的filesystem 几乎可是使用全部的容量(ReiserFS = 99.83%,JFS = 99.82%,XFS = 99.95%)。
结论:为了使用你的分区的的最大容量,选择ReiserFS,JFS或者XFS。
建立文件系统,mount和unmounting
在20GB的分区创造filesystem测试,划分为Ext3带14.7秒, 与为相比其他filesystem多2秒或更少。(ReiserFS = 2.2,JFS = 1.3,XFS = 0.7)。
不过,挂载ReiserFS 要比其他的FS多花费5-15倍时间(2.3秒)(Ext3 = 0.2, JFS = 0.2, XFS = 0.5),umount以及要比其他的FS多花费2 倍时间(0.4秒)。
所有的FS都花费差不多CPU占用来创建FS(59%(ReiserFS) -74%(JFS)),挂载FS(在6和9%之间)。 不过,Ext3 和XFS多用2倍的CPU占用 给umount(37% 和45%), ReiserFS和JFS(14% 和27%)。
结论:对创建FS性能和mounting/unmounting来说,选择JFS或者XFS。
大文件操作性能(ISO image,700 MB)
把大文件复制到Ext3(38.2秒)和ReiserFS(41.8),要比JFS和XFS(35.1和34.8)需要更多时间。使用XFS有助于提高在相同的磁盘上复制相同的文件(XFS=33.1,Ext3 = 37.3,JFS = 39.4,ReiserFS = 43.9)相比。 在JFS和XFS上删除那些ISO 大约要快100 倍(0.02秒),(ReiserFS1.5秒,Ext3 2.5秒)!所有FS复制时的CPU利用(在46和51%之间),再复制时(在38%到50%之间)。当其他FS使用大约10%时,ReiserFS使用49%的CPU。 比他FS大约少5到10%),JFS使用较少的CPU。
结论:对大文件操作性能来说,最好选择JFS或者XFS。 如果你需要使CPU利用减到最小,更推荐JFS。
目录树(7500个文件,900份目录,1.9GB)的操作
最初复制目录树时,Ext3(158.3秒)和XFS(166.1秒)更迅速,ReiserFS和JFS(172.1和180.1)。在第二次复制的时候有相似的结果。(Ext3=120秒,XFS = 135.2,ReiserFS = 136.9 和JFS = 151)。但是, 移动目录树时Ext3(22秒)相比ReiserFS(8.2秒, XFS(10.5秒)和JFS(12.5秒))大约多2倍时间!所有FS在复制和再复制目录树时都使用较多的CPU (复制在27和36%之间),(再复制在29%-JFS和45%-ReiserFS之间)。
令人吃惊,ReiserFS 和XFS使用更多的CPU 删除目录树(86% 和65%),而其他FS只使用大约15%的(Ext3和JFS)。再次,与任何其他FS相比较,JFS的明显使用较少CPU。当有较多的数量较小页面时适合ReiserFS。这个差别在目录树的再复制和移动里的ReiserFS将有更高的速度。
结论:对在大容量的目录树操作来说,选择Ext3或者XFS。来自其他作者的基准测试已经证明如果使用ReiserFS,对大量的小文件更为合适。但是,目前包括各种各样尺寸(10KB在5 MB)数千文件的目录树操作上,建议使用Ext3或者XFS可能获得更好的性能。如果JFS的CPU占用减到最小,这种FS带着相当高的性能。
目录列表和文件查找
递归显示目录的目录列表,ReiserFS(1.4秒)和XFS更迅速的1.8), Ext3和JFS(2.5和3.1)。文件查找有着相同的结果。在文件查找项目, ReiserFS(0.8秒)相比XFS(2.8)和Ext3(4.6秒)和JFS(5秒)更迅速。 Ext3和JFS有更好CPU占用:目录列表(35%),文件查找(6%)。 XFS目录列表(70%)使用更多的CPU,文件查找(10%)。 ReiserFS 看起来是占用CPU最多的FS,目录列表71%,文件查找36% 。
结论:结果表明那, 对于这些CPU占用任务来说,(ext3和JFS)filesystems 能更少的使用CPU的。 XFS作为好备选,带有相对适中的性能和CPU的占用。
小结
这些结果从Piszcz(2006)关于分解的Ext3,ReiserFS的磁盘能力报告一样,这两篇文章两篇已经显示JFS是最低的CPU利用的FS。最后这份报告看起来没有显示出ReiserFS的high page faults activity.
由于一个分区只能有一个filesystem,认识每种filesystem的优缺点很重要。如果以这篇文章的全部测试为基准,XFS看起来是家庭或者小型企业最适合的应用于文件服务器的filesystem:
*它使用你的服务器硬盘(s)的拥有最大的容量
*创建FS,mount和unmount很迅速
*操作大文件最迅速的FS(>500 MB)
*这FS得第二名地方给经营关于许多在适度尺寸文件和目录小
*在CPU占用和目录列表或者文件搜寻性能之间比较平衡
*没有最小CPU要求,老一代硬件也可十分接受
Piszcz(2006)当时没有明确推荐XFS,他只是说:"就个人来说,我仍然愿意选择同时具备性能和可伸缩性的XFS",现在我只能支持这个结论。
参考
贝努瓦,M.(2003)。 Linux 文件系统基准。
Piszcz,J.(2006)。 基准问题测试Filesystems第二部分,Linux Gazette, 122 (January 2006)。