服务发现之Zookeeper vs Consul vs Etcd
 本文并不打算在此介绍服务发现的基本原理,除了一致性算法之外,并没有太多高深的算法,网上的资料很容易让大家明白上面是服务发现。
本文并不打算在此介绍服务发现的基本原理,除了一致性算法之外,并没有太多高深的算法,网上的资料很容易让大家明白上面是服务发现。市面上有非常多的服务发现工具,下面列举了常用的开源的服务发现工具。分布式服务架构中,一个应用可能由一组职责单一化的服务组成。此时就需要一个注册服务的机制,注册某个服务或者某个节点是可用的,还需要一个发现服务的机制来找到哪些服务或者哪些节点还在提供服务。在实际应用中,通常还都需要一个配置文件告诉我们一些配置信息,比如数据连接的地址等。但很多时候,想要动态地在不修改代码的情况下得到这些信息,并且能很好地管理它们。
| Name | Type | AP or CP | Language | Dependencies | Integration |
|---|---|---|---|---|---|
| Zookeeper | General | CP | Java | JVM | Client Binding |
| Doozer | General | CP | Go | Client Binding | |
| Etcd | General | Mixed | Go | Client Binding/HTTP |
有了这些需求,于是发展出了一系列的开源框架,比如 ZooKeeper, Etcd, Consul 等等。这些框架一般会提供这样的服务:
服务注册
主机名,端口号,版本号,或者一些环境信息。
服务发现
可以让客户端拿到服务端地址。
一个分布式的通用 k/v 存储系统
基于 Paxos 算法或者 Raft 算法
领导者选举 (Leader Election)
其它一些例子:
分布式锁 (Distributed locking)
原子广播 (Atomic broadcast)
序列号 (Sequence numbers)
…
我们都知道 CAP 是 Eric Brewer 提出的分布式系统三要素:
强一致性 (Consistency)
可用性 (Availability)
分区容忍性 (Partition Tolerance)
几乎所有的服务发现和注册方案都是 CP 系统,也就是说满足了在同一个数据有多个副本的情况下,对于数据的更新操作达到最终的效果和操作一份数据是一样的,但是在出现网络分区(分区间的节点无法进行网络通信)这样的故障的时候,在节点之间恢复通信并且同步数据之前,一些节点将会无法提供服务(一些系统在节点丢失的情况下支持 stale reads )。
ZooKeeper 作为这类框架中历史最悠久的之一,是由 Java 编写开发的。
| Feature | Consul | zookeeper | etcd |
|---|---|---|---|
| 服务健康检查 | 服务状态,内存,硬盘等 | (弱)长连接,keepalive | 连接心跳 |
| 多数据中心 | 支持 | — | — |
| kv存储服务 | 支持 | 支持 | 支持 |
| 一致性 | raft | paxos | raft |
| cap | ca | cp | cp |
| 使用接口(多语言能力) | 支持http和dns | 客户端 | http/grpc |
| watch支持 | 全量/支持long polling | 支持 | 支持 long polling |
| 自身监控 | metrics | — | metrics |
| 安全 | acl /https | acl | https支持(弱) |
| spring cloud集成 | 已支持 | 已支持 | 已支持 |
Zookeeper
zookeeper的功能有:
作为配置信息的存储的中心服务器
命名服务
分布式同步
分组服务
能看出,zookeeper并不只是作为服务发现框架使用的,它非常庞大。如果只是打算将zookeeper作为服务发现工具,就需要用到其配置存储和分布式同步的功能。前者可以理解成具有一致性的kv存储,后者提供了zookeeper特有的watcher注册于异步通知机制,zookeeper能将节点的状态实时异步通知给zookeeper客户端。
zookeeper使用
zookeeper的使用流程如下:
确保有所选语言的sdk,理论上github上第三方的库有一些,仔细筛选一下应该可以用。
调用zookeeper接口连接zookeeper服务器。
注册自身服务
通过watcher获取监听服务的状态
服务提供者需自行保持与zookeeper服务器的心跳。
总得来说,zookeeper需要胖客户端,每个客户端都需要通过其sdk与zookeeper服务保活,增加了编写程序的复杂性。此外,还提供api实现服务注册与发现逻辑,需要服务的消费者实现服务提供者存活的检测。
Etcd
etcd是一个采用http协议的分布式键值对存储系统,因其易用,简单。很多系统都采用或支持etcd作为服务发现的一部分,比如kubernetes。但正事因为其只是一个存储系统,如果想要提供完整的服务发现功能,必须搭配一些第三方的工具。
比如配合etcd、Registrator、confd组合,就能搭建一个非常简单而强大的服务发现框架。但这种搭建操作就稍微麻烦了点,尤其是相对consul来说。所以etcd大部分场景都是被用来做kv存储,比如kubernetes。
Consul
相较于etcd、zookeeper,consul最大的特点就是:它整合了用户服务发现普遍的需求,开箱即用,降低了使用的门槛,并不需要任何第三方的工具。代码实现上也足够简单。consul的功能有:
通过DNS或HTTP,应用能轻易地找到它们依赖的系统
提供了多种健康检查方式:http返回码200,内存是否超限,tcp连接是否成功
kv存储,并提供http api
多数据中心,这点是zookeeper所不具备的。
consul使用
相比于zookeeper的服务发现使用,consul并不需要专门的sdk集成到服务中,因此它不限制任何语言的使用。我们看看consul一般是怎么使用的:
每台服务器上都要安装一个consul agent。
consul agent支持通过配置文件注册服务,或者在服务中通过http接口来注册服务。
注册服务后,consul agent通过指定的健康检查方式,定期检查服务是否存活。
如果服务想查询其他服务的存活状态,只需要与本机的consul agent发起一次http请求或者dns请求即可。
简单点说,consul的使用不依赖任何sdk,依靠简单的http请求就能满足服务发现的所有逻辑。不过,服务每次都从consul agent获取其他服务的存活状态,相比于zookeeper的watcher机制,实时性稍差一点,需考虑如何尽可能提高实时性,问题不会很大。
服务的健康检查
Euraka 使用时需要显式配置健康检查支持;Zookeeper,Etcd 则在失去了和服务进程的连接情况下任务不健康,而 Consul 相对更为详细点,比如内存是否已使用了90%,文件系统的空间是不是快不足了。
多数据中心支持
Consul 通过 WAN 的 Gossip 协议,完成跨数据中心的同步;而且其他的产品则需要额外的开发工作来实现;
KV 存储服务
除了 Eureka ,其他几款都能够对外支持 k-v 的存储服务,所以后面会讲到这几款产品追求高一致性的重要原因。而提供存储服务,也能够较好的转化为动态配置服务;
产品设计中 CAP 理论的取舍
Eureka 典型的 AP,作为分布式场景下的服务发现的产品较为合适,服务发现场景的可用性优先级较高,一致性并不是特别致命。其次 CA 类型的场景 Consul,也能提供较高的可用性,并能 k-v store 服务保证一致性。 而Zookeeper,Etcd则是CP类型 牺牲可用性,在服务发现场景并没太大优势;
多语言能力与对外提供服务的接入协议
Zookeeper的跨语言支持较弱,其他几款支持 http11 提供接入的可能。Euraka 一般通过 sidecar的方式提供多语言客户端的接入支持。Etcd 还提供了Grpc的支持。 Consul除了标准的Rest服务api,还提供了DNS的支持;
Watch的支持(客户端观察到服务提供者变化)
Zookeeper 支持服务器端推送变化,Eureka 2.0(正在开发中)也计划支持。 Eureka 1,Consul,Etcd则都通过长轮询的方式来实现变化的感知;
自身集群的监控
除了 Zookeeper ,其他几款都默认支持 metrics,运维者可以搜集并报警这些度量信息达到监控目的;
安全
Consul、Zookeeper 支持ACL,另外 Consul,Etcd 支持安全通道https。
小结
| 名称 | 优点 | 缺点 | 接口 | 一致性算法 |
|---|---|---|---|---|
| zookeeper | 1.功能强大,不仅仅只是服务发现 2.提供watcher机制能实时获取服务提供者的状态 3.dubbo等框架支持 | 1.没有健康检查 2.需在服务中集成sdk,复杂度高 3.不支持多数据中心 | sdk | Paxos |
| consul | 1.简单易用,不需要集成sdk 2.自带健康检查 3.支持多数据中心 4.提供web管理界面 | 1.不能实时获取服务信息的变化通知 | http/dns | Raft |
| etcd | 1.简单易用,不需要集成sdk 2.可配置性强 | 1.没有健康检查 2.需配合第三方工具一起完成服务发现 3.不支持多数据中心 | http | Raft |
Zookeeper、Etcd和Consul性能对比
一致性键值存储的用处
许多现代分布式应用程序都建立在分布式一致键值存储之上。Hadoop生态系统中的应用程序和“Netflix栈”的许多部分都使用Zookeeper。Consul公开了服务发现和运行状况检查API,并支持Nomad等集群工具。Kubernetes容器编排系统,MySQL的Vitess水平扩展,Google Key Transparency项目以及许多其他系统都是基于etcd构建的。有了这么多关键任务集群,服务发现和基于这些一致键值存储的数据库应用程序,测量可靠性和性能是至关重要的。
满足写性能需要的条件
理想的键值存储每秒摄取许多键,快速持久并确认每次写入,并保存大量数据。如果存储无法跟上写入,那么请求将超时,可能会触发故障转移和停机。如果写入速度很慢,那么应用程序看起来很慢。如果数据过多,存储系统可能会爬行甚至无法运行。使用dbtester来模拟写入,并发现etcd在这些基准测试中优于类似的一致分布式键值存储软件。在较低的层面上,背后的架构决策可以更加统一和有效地利用资源,这些决策转化为在合理的工作负载和规模下可靠的良好吞吐量、延迟和总容量。这反过来又有助于使用etd的应用程序,如Kubernetes,可靠、易于监控和高效。
性能有很多方面,本文将深入介绍键的创建,键值的填充和存储,来说明底层的机制。
资源利用
在跳到高级性能之前,首先通过资源利用率和并发性突出键值存储行为的差异是有帮助的,写操作为验证这个问题提供了一个很好的例子。写操作必须和磁盘关联起来,因为写操作会持久键值到媒体。然后,这些数据必须跨服务器进行复制(replicate across machines),从而导致集群间大量网络流量。这些流量构成了处理写的全部开销的一部分,这会消耗CPU。最后,将键放入存储区直接利用内存获取键用户数据,并间接用于簿记(book-keeping)。
根据最近的一项用户调查,大多数etcd部署都使用虚拟机。为了遵守最常见的平台配置,所有的测试都在谷歌云平台计算引擎虚拟机(Google Cloud Platform Compute Engine virtual machines)上运行,并且使用Linux OS(所有虚拟机都有Ubuntu 16.10, Linux内核4.8.0-37-generic和ext4文件系统。我们选择Ubuntu作为一个中立的Linux操作系统,而不是像Container Linux那样的CoreOS项目,以说明这些结果应该适用于任何类型的Linux发行版。但是,在容器Linux上收集这些基准测试将得到非常相似的结果)。每个集群使用三个VM,足以容忍单个节点故障。每个VM都有16个专用的vcpu、30GB内存和300GB SSD,可以达到150 MB/s的持续写操作。这个配置足够强大,可以模拟来自1000个客户机的流量,这对于etcd的用例和以下资源度量所选择的目标来说是最小的。所有的测试都进行了多次试验,在运行之间的偏差相对较小,不影响任何一般结论。etcd的使用如下图所示:
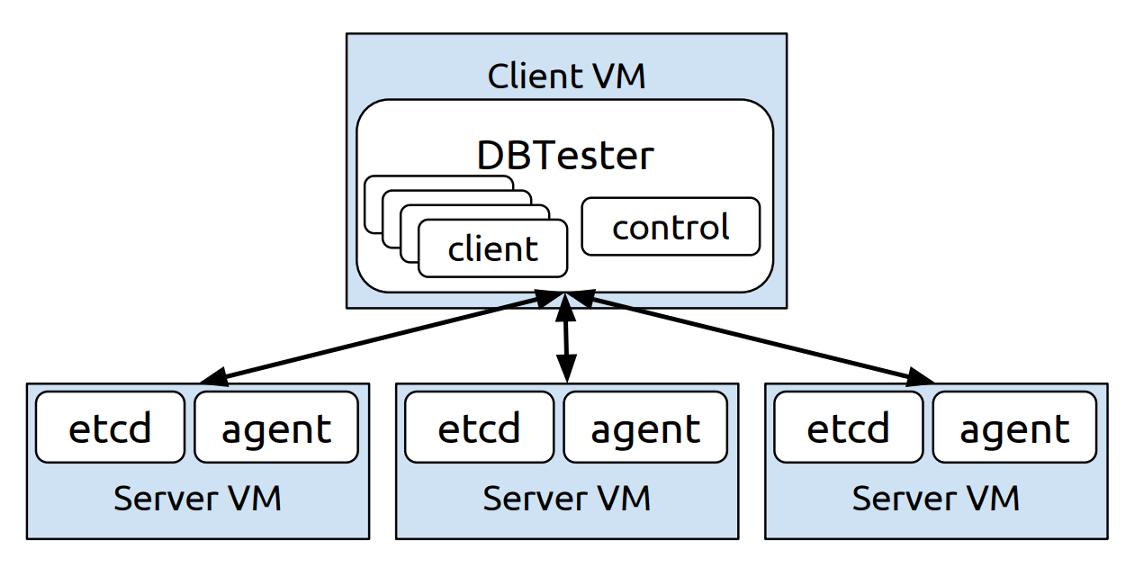
键值存储基准测试设置
所有基准测试都使用以下软件配置:
软件名称 | 版本 | 编译语言版本 |
|---|---|---|
etcd | v3.1.0 | Go 1.7.5 |
Zookeeper | r3.4.9 | Java 8 (JRE build 1.8.0_121-b13) |
Consul | v0.7.4 | Go 1.7.5 |
每个资源利用率测试都会创建一百万个具有1024字节值的唯一256字节键(one million unique 256-byte keys with 1024-byte values)。选择键长度以使用共同的最大路径长度对存储软件施加压力,选择值长度是因为它是protobuf编码的Kubernetes值的预期平均大小。虽然精确的平均键长度和值长度是与工作负载相关的,但长度代表极端之间的权衡。更精确的敏感性研究将为每个存储软件提供更多关于最佳案例表现特征的见解,但风险更大。
磁盘带宽
写操作必须持久化到磁盘,他们记录共识提案(consensus proposals),压缩旧数据,并保存存储快照。在大多数情况下,写入应该以记录共识提案为主。etcd的日志(log)将protobuf编码的提议流转换为一系列预分配文件,在页面边界处同步,每个条目都有滚动的CRC32校验和。 Zookeeper的事务日志(transaction log)类似,但是使用Adler32进行jute编码和校验和。Consul采用不同的方法,而是记录到boltdb/bolt后端,raft-boltdb。
下图显示了扩展客户端并发性如何影响磁盘写入。正如预期的那样,当并发性增加时,ext4文件系统上/proc/diskstats上的磁盘带宽会增加,以应对请求压力的增加。etcd的磁盘带宽稳定增长,它写的数据比Zookeeper还多,因为除了日志外,它还必须写boltDB。另一方面,Zookeeper会因为写入完整的状态快照而丢失数据速率,这些完整的快照与etcd的增量和并发提交相反,后者只写入更新,而不会停止所有正在进行的操作(stopping the world)。Consul的数据率最初大于etcd,这可能是由于在B+树中删除了提交的raft协议(raft proposals)而导致的写放大,然后由于花了几秒钟写快照而出现波动。
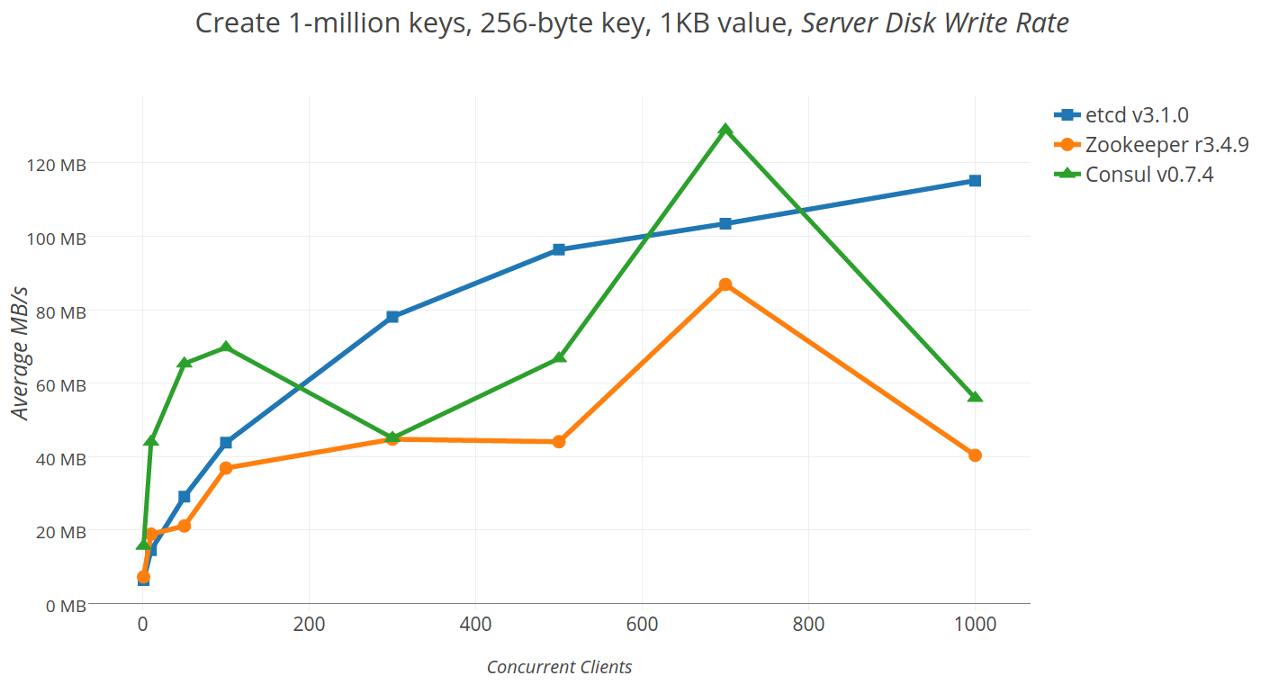
创建一百万个键时的平均服务器磁盘写入吞吐量
网络
网络是分布式键值存储的中心。客户端与键值存储集群的服务器进行通信,集群中的服务器相互通信。每个键值存储都有自己的客户端协议,etcd客户端使用建立在HTTP/2之上的Protocol Buffer v3 gRPC协议,Zookeeper客户端使用自定义的流式TCP协议Jute,Consul使用JSON。同样,每个协议都有自己的TCP服务器协议。etcd peer stream protobuf编码的raft RPC提议,Zookeeper将TCP流用于有序的双向jute编码ZAB通道,Consul发布用MsgPack编码的raft RPC。
下表显示了所有服务器和客户端的总网络利用率。在大多数情况下,etcd具有最低的网络使用率,除了Consul客户端接收的数据略少。这可以通过etcd的Put响应来解释,其中包含带有修订数据的标题,而Consul只是以明文true响应。Zookeeper和Consul的服务器间流量可能是由于传输大型快照和节省空间的协议编码较少。
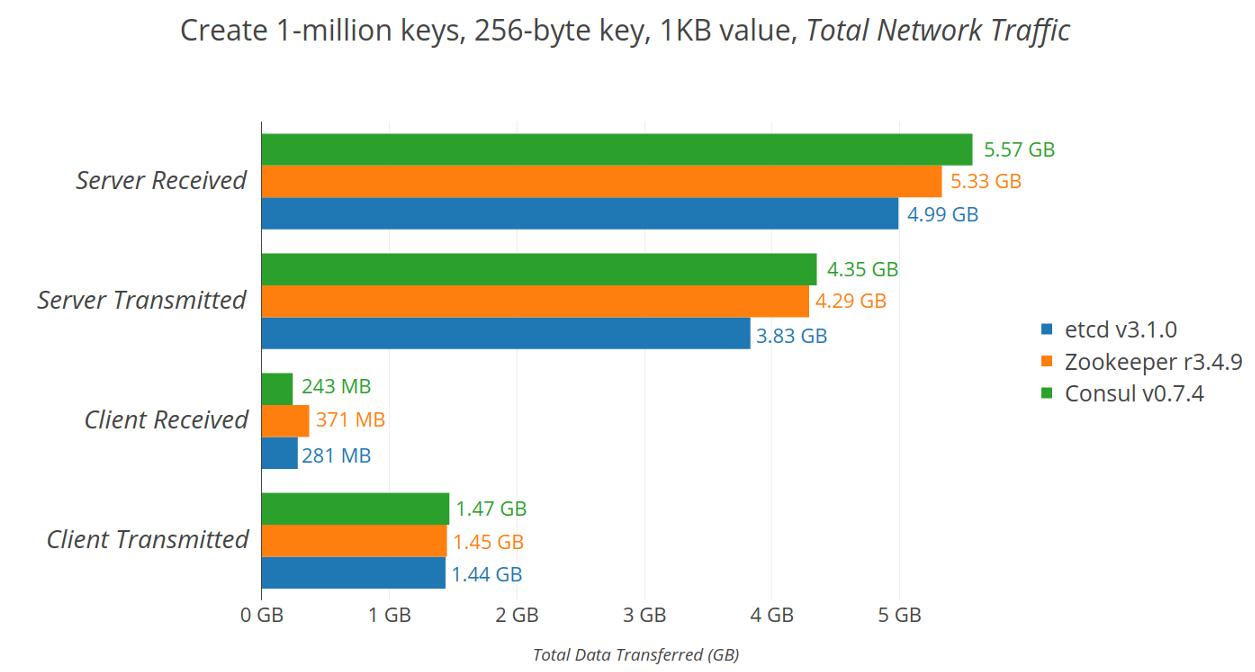
使用1,000个客户端创建一百万个键时传输的总数据量
CPU
即使存储和网络速度很快,集群也必须小心处理开销。浪费CPU的机会比比皆是:许多消息必须被编码和解码,糟糕的并发控制可以对抗锁定,系统调用可以以惊人的频率进行,并且内存堆可以捶打。 由于etcd、Zookeeper和Consul都希望leader服务器节点处理写入,因此较差的CPU利用率可以轻松降低性能。
下图显示了在扩展客户端时使用top -b -d 1测量的服务器CPU利用率。etcd CPU利用率按预期平均和最大负载进行扩展,随着更多连接的增加,CPU负载依次增加。最引人注目的是Zookeeper的平均跌幅为700,但客户端数量增加了1000,日志报告太忙以捕捉,跳过其SyncRequestProcessor,然后创建新的日志文件,从1,073%利用率到230%。 这种下降也发生在1,000个客户端,但从平均值来看不太明显,利用率从894%上升到321%。同样,处理快照时Consul CPU利用率下降10秒,从389% CPU降至16%。
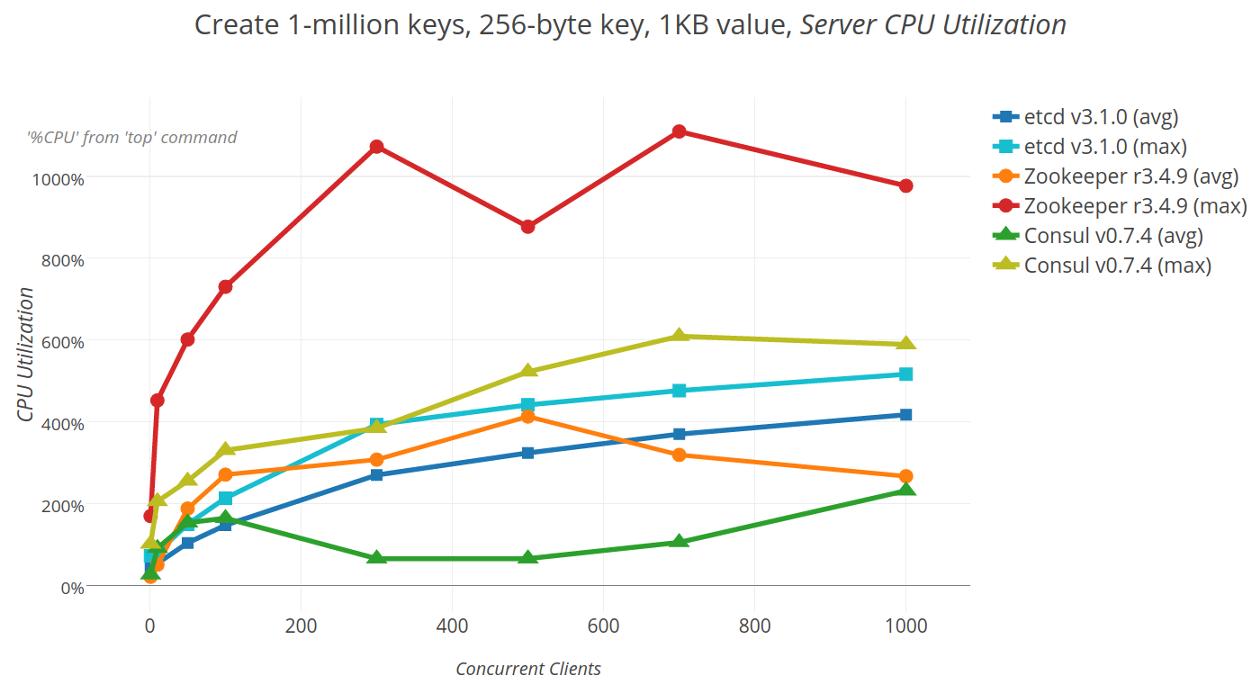
用于在客户端扩展时创建一百万个键的服务器CPU使用
内存
当键值存储设计为仅管理元数据大小的数据时,大多数数据可以缓存在内存中。维护内存数据库可以提高速度,但代价是过多的内存占用可能会导致频繁的垃圾回收和磁盘交换,从而降低整体性能。当Zookeeper和Consul在内存中加载所有键值数据时,etcd只保留一个小的驻留内存索引,直接通过boltdb中的内存映射文件支持其大部分数据,仅将数据保存在boltDB中会因请求分页而导致磁盘访问,但总体而言,etcd更好地考虑操作系统设施。
下图显示了在集群总内存占用量中向集群添加更多键的效果。最值得注意的是,一旦存储系统中有大量的键,etcd使用的内存量不到Zookeeper或Consul的一半。Zookeeper位居第二,占据了四倍的内存,这符合仔细调整JVM堆设置的建议(recommendation)。最后,尽管Consul使用了etcd所用的boltDB,但它的内存存储(in-memory store)否定了etcd中的占用空间优势,消耗了三者中最大的内存。
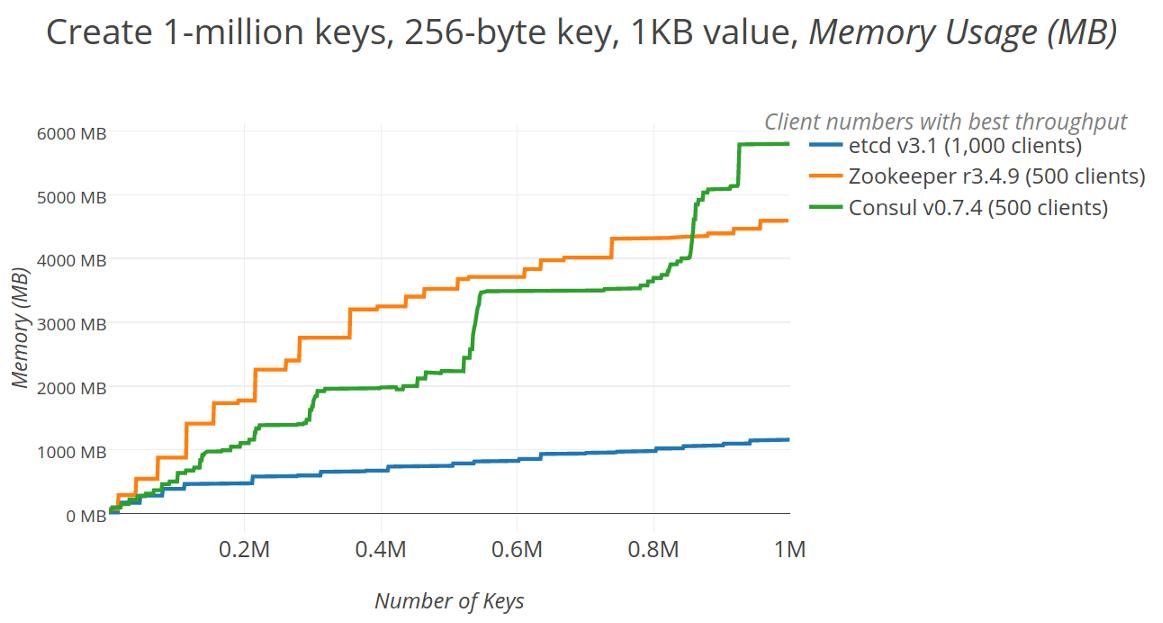
创建一百万个键时的服务器内存占用
存储爆炸
随着物理资源的确定,重点可以回归到聚合基准测试。首先,为了找到最大键提取率,系统并发性可扩展到一千个客户端。这些最佳摄取率为测量负载下的延迟提供了基础,从而衡量总的等待时间。同样,每个系统客户端以最佳摄取速率计数,当密钥从一百万个键扩展到三百万个键时,可以通过测量吞吐量的下降来强调总容量。
吞吐量变化
随着越来越多的客户端同时写入集群,理想情况下,在提升之前,提取率应该稳定上升。但是,下图显示在写出一百万个键时缩放客户端数量时不是这种情况。 相反,Zookeeper(最大速率为43,458 req/sec)波动很大,这并不奇怪,因为它必须明确配置为允许大量连接。Consul的吞吐量(最大速率16,486 req/sec)可以很好地扩展,但在并发压力下会降低到低速率。etcd的吞吐量(最大速率34,747 req/sec)总体稳定,随着并发性而缓慢上升。最后,尽管Consul和Zookeeper使用了更多的CPU,但最大吞吐量仍然落后于etcd。
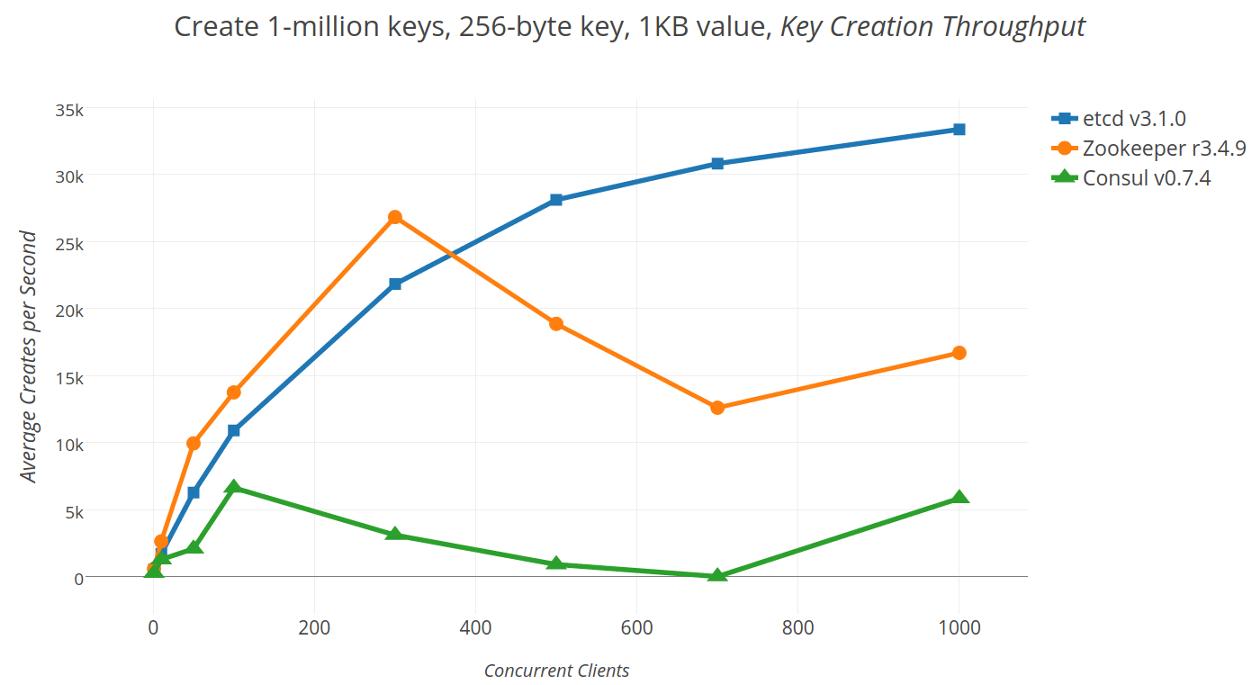
随客户端规模创建一百万个键的平均吞吐量
延迟分布
鉴于存储系统的最佳吞吐量,延迟应该是局部最小且稳定,排队效应将延迟其他并发操作。同样,理想情况下,随着键总数的增加,延迟会保持低且稳定,如果请求变得不可预测,则可能存在级联超时,抖动监视警报或故障。然而,通过下面显示的延迟测量来判断,只有etcd具有最低的平均等待时间和规模上的紧密、稳定的界限。
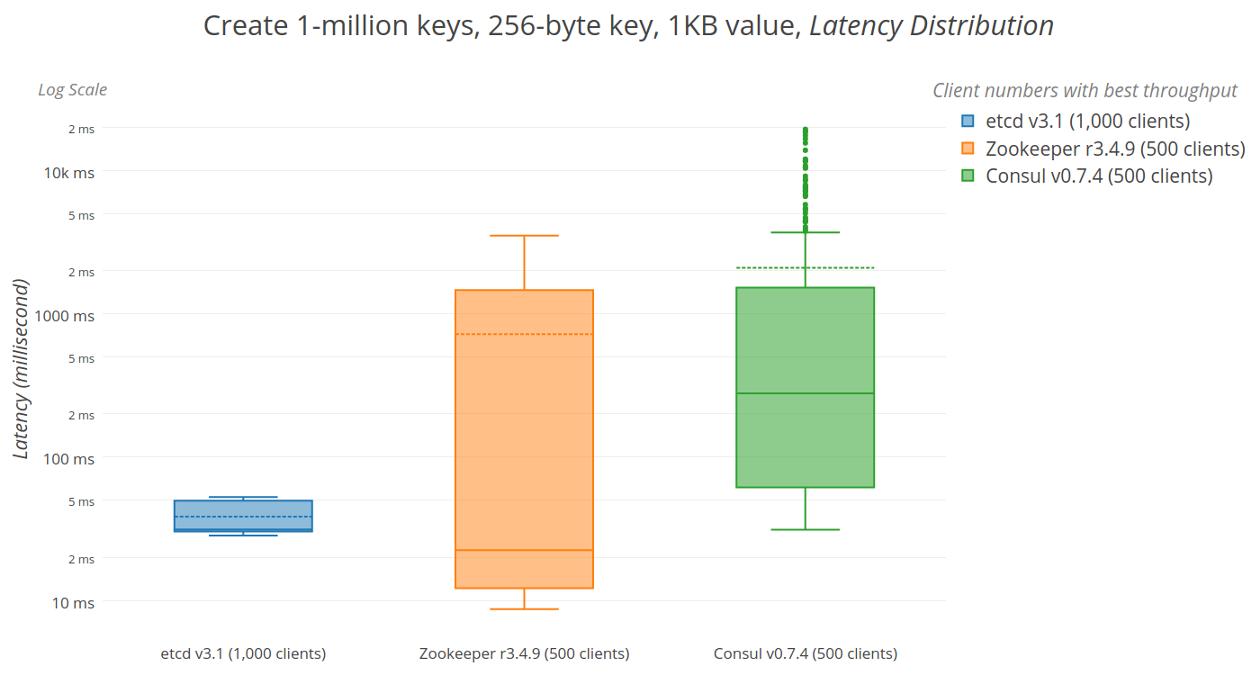
etcd,Zookeeper和Consul键创建延迟位数和范围
Zookeeper努力为并发客户提供最佳吞吐量,一旦它触发快照,客户端请求就会开始失败。服务器记录列表错误,例如Too busy to snap, skipping, fsync-ing the write ahead log和fsync-ing the write ahead log in SyncThread: 1 took 1,038 ms which will adversely effect operation latency,最终导致leader节点丢失,Exception when following the leader。客户端请求偶尔会失败,包括zk等错误,例如zk: could not connect to a server和zk: connection closed错误。Consul报告没有错误,尽管可能应该,它经历了广泛的差异降级性能,可能是由于其大量写入放大。
键总数
凭借最佳平均吞吐量达到100万个键的最大并发性,可以在容量扩展时测试吞吐量。下图显示了时间序列延迟,以及延迟峰值的对数标度,因为键被添加到存储中,最多可达300万个键。在大约50万个键之后,Zookeeper和Consul延迟峰值都会增长。由于高效的并发快照,etcd没有出现尖峰,但是在一百万个键之前略有延迟。
特别值得注意的是,就在两百万个键之前,Zookeeper完全失败了。其追随者落后,未能及时收到快照,这表明领导者选举需要长达20秒才能锁定集群。
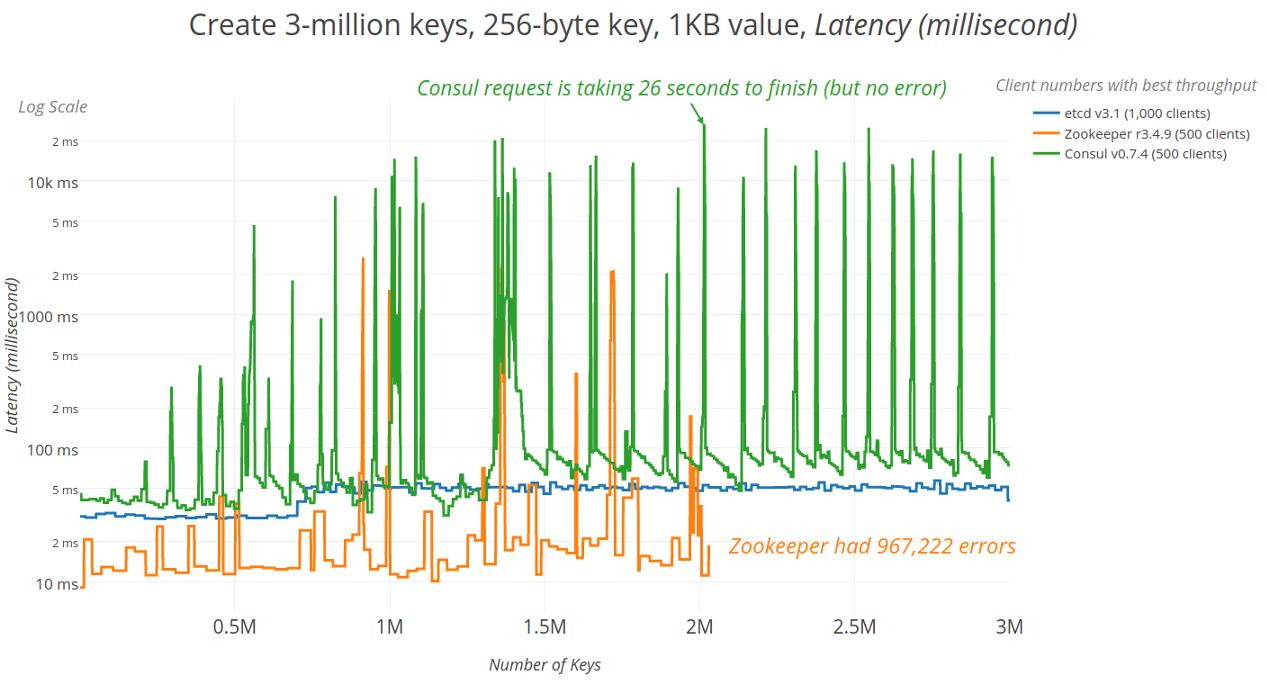
创建300万个键时的延迟
下一步是什么
在创建一百万个或更多键时,etcd可以比Zookeeper或Consul稳定地提供更好的吞吐量和延迟。此外,它实现了这一目标,只有一半的内存,显示出更高的效率。但是,还有一些改进的余地,Zookeeper设法通过etcd提供更好的最小延迟,代价是不可预测的平均延迟。
所有基准测试都是使用etcd的开源dbtester生成的。任何希望重现结果的人都可以获得上述测试的测试用例参数。对于更简单,仅限etcd的基准测试,请尝试使用etcd3基准测试工具。