Nginx处理HTTP请求的各个阶段
 首先很感谢agentzh的Nginx教程,通过该文章能够基本了解了Nginx的执行过程,本文大部分内容参考自章工的文章,再次向大神致谢。Nginx在处理用户请求的过程中共分为11个阶段phase依次处理的,分别是:post-read、server-rewrite、find-config、rewrite、post-rewrite、preaccess、access、post-access、try-files、content 以及 log,而不是根据配置文件上的顺序。
首先很感谢agentzh的Nginx教程,通过该文章能够基本了解了Nginx的执行过程,本文大部分内容参考自章工的文章,再次向大神致谢。Nginx在处理用户请求的过程中共分为11个阶段phase依次处理的,分别是:post-read、server-rewrite、find-config、rewrite、post-rewrite、preaccess、access、post-access、try-files、content 以及 log,而不是根据配置文件上的顺序。Nginx处理HTTP请求时,可以分为以下几个阶段处理。
| 请求阶段 | 各阶段处理模块(不仅仅只有这些) |
|---|---|
| POST_READ | realip |
| SERVER_REWRITE | rewrite |
| FIND_CONFIG | |
| REWRITE | rewrite |
| POST_REWRITE | |
| PREACCESS | limit_conn,limit_req |
| ACCESS | auth_basic,access,auth_request |
| POST_ACCESS | |
| PRECONTENT | try_files |
| CONTENT | index,autoindex,concat |
| LOG | access_log |
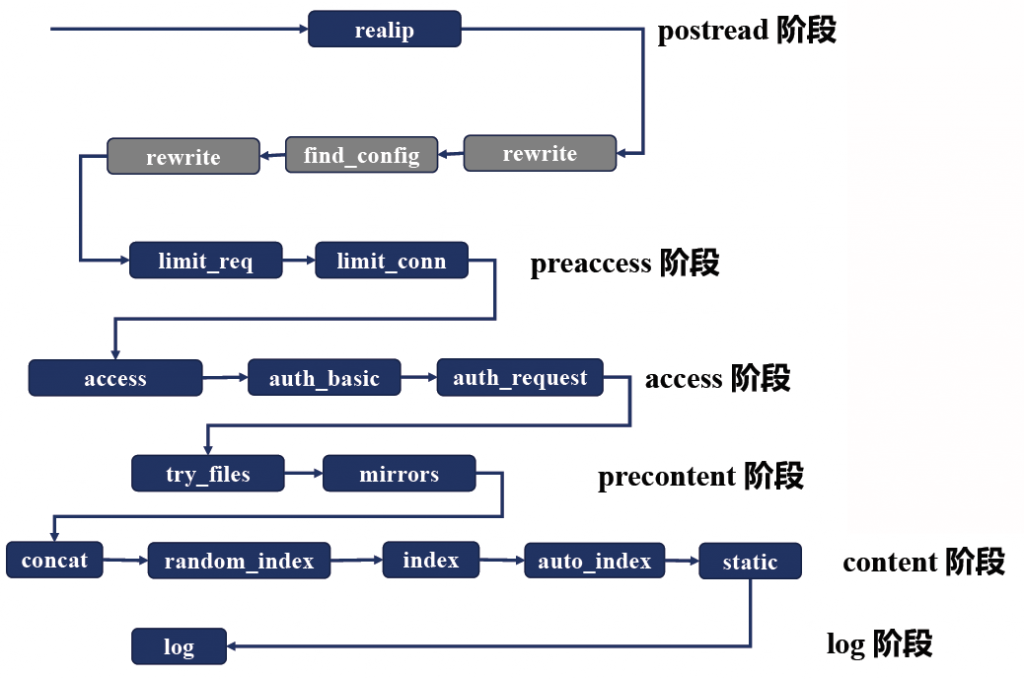
各阶段处理顺序
postread阶段:–>realip–>rewrite–>find_config–>rewrite->
preaccess阶段:–>limit_req–>limit_conn–>
access阶段:–>access–>auth_basic–>auth_request–>
precontent阶段:–>try_files–>mirrors–>
content阶段:–>concat–>random_index–>index–>auto_index–>static–>
log阶段:->log
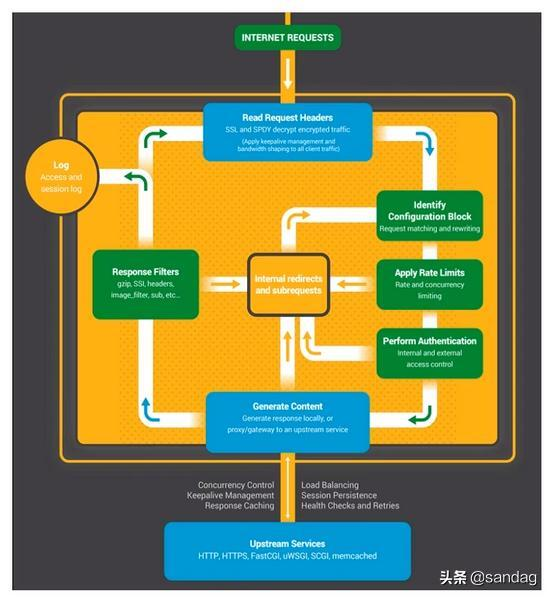
七步骤版的处理流程
1、Read Request Headers:解析请求头。
2、Identify Configuration Block:识别由哪一个 location 进行处理,匹配 URL。
3、Apply Rate Limits:判断是否限速。例如可能这个请求并发的连接数太多超过了限制,或者 QPS 太高。
4、Perform Authentication:连接控制,验证请求。例如可能根据 Referrer 头部做一些防盗链的设置,或者验证用户的权限。
5、Generate Content:生成返回给用户的响应。为了生成这个响应,做反向代理的时候可能会和上游服务Upstream Services进行通信,然后这个过程中还可能会有些子请求或者重定向,那么还会走一下这个过程Internal redirects and subrequests。
6、Response Filters:过滤返回给用户的响应。比如压缩响应,或者对图片进行处理。
7、Log:记录日志。
各(11个)阶段中各个模块处理顺序

POST_READ:在 read 完请求的头部之后,在没有对头部做任何处理之前,想要获取到一些原始的值,就应该在这个阶段进行处理。这里面会涉及到一个 realip 模块。
SERVER_REWRITE:和下面的 REWRITE 阶段一样,都只有一个模块叫 rewrite 模块,一般没有第三方模块会处理这个阶段。
FIND_CONFIG:做 location 的匹配,暂时没有模块会用到。
REWRITE:对 URL 做一些处理。
POST_WRITE:处于 REWRITE 之后,也是暂时没有模块会在这个阶段出现。
接下来是确认用户访问权限的三个模块:
PREACCESS:是在 ACCESS 之前要做一些工作,例如并发连接和 QPS 需要进行限制,涉及到两个模块:limt_conn 和 limit_req
ACCESS:核心要解决的是用户能不能访问的问题,例如 auth_basic 是用户名和密码,access 是用户访问 IP,auth_request根据第三方服务返回是否可以去访问。
POST_ACCESS:是在 ACCESS 之后会做一些事情,同样暂时没有模块会用到。
最后的三个阶段处理响应和日志:
PRECONTENT:在处理 CONTENT 之前会做一些事情,例如会把子请求发送给第三方的服务去处理,try_files 模块也是在这个阶段中。
CONTENT:这个阶段涉及到的模块就非常多了,例如 index, autoindex, concat等都是在这个阶段生效的。
LOG:记录日志 access_log 模块。
以上的这些阶段都是严格按照顺序进行处理的,当然每个阶段中各个 HTTP 模块的处理顺序也很重要,如果某个模块不把请求向下传递,后面的模块是接收不到请求的。而且每个阶段中的模块也不一定所有都要执行一遍,下面就接着讲一下各个阶段模块之间的请求顺序。
安装Nginx时,使用configure命令编译完nginx后,在objs目录中会生成一个ngx_modules.c的文件。使用 --with 引入的模块或者引入的第三方模块都会在该文件中的*ngx_modules[]数组中出现。下列模块顺序和各模块的执行顺序相关。
ngx_module_t *ngx_modules[] = {
&ngx_core_module,
&ngx_errlog_module,
&ngx_conf_module,
&ngx_openssl_module,
&ngx_regex_module,
&ngx_events_module,
&ngx_event_core_module,
&ngx_epoll_module,
&ngx_http_module,
&ngx_http_core_module,
&ngx_http_log_module,
&ngx_http_upstream_module,
&ngx_http_static_module,
&ngx_http_autoindex_module,
&ngx_http_index_module,
&ngx_http_mirror_module,
&ngx_http_try_files_module,
&ngx_http_auth_basic_module,
&ngx_http_access_module,
&ngx_http_limit_conn_module,
&ngx_http_limit_req_module,
&ngx_http_realip_module,
&ngx_http_geo_module,
&ngx_http_map_module,
&ngx_http_split_clients_module,
&ngx_http_referer_module,
&ngx_http_rewrite_module,
&ngx_http_ssl_module,
&ngx_http_proxy_module,
&ngx_http_fastcgi_module,
&ngx_http_uwsgi_module,
&ngx_http_scgi_module,
&ngx_http_memcached_module,
&ngx_http_empty_gif_module,
&ngx_http_browser_module,
&ngx_http_upstream_hash_module,
&ngx_http_upstream_ip_hash_module,
&ngx_http_upstream_least_conn_module,
&ngx_http_upstream_keepalive_module,
&ngx_http_upstream_zone_module,
&ngx_http_write_filter_module,
&ngx_http_header_filter_module,
&ngx_http_chunked_filter_module,
&ngx_http_range_header_filter_module,
&ngx_http_gzip_filter_module,
&ngx_http_postpone_filter_module,
&ngx_http_ssi_filter_module,
&ngx_http_charset_filter_module,
&ngx_http_userid_filter_module,
&ngx_http_headers_filter_module,
&ngx_http_copy_filter_module,
&ngx_http_range_body_filter_module,
&ngx_http_not_modified_filter_module,
NULL
};
在依次向下执行的过程中,也可能不按照这样的顺序。例如,在access 阶段中,有一个指令叫 satisfy,它可以指示当有一个满足的时候就直接跳到下一个阶段进行处理,例如当 access 满足了,就直接跳到 try_files 模块进行处理,而不会再执行 auth_basic、auth_request 模块。
在 content 阶段中,当 index 模块执行了,就不会再执行 auto_index 模块,而是直接跳到 log 模块。
整个 11 个阶段所涉及到的模块和先后顺序如下图所示:
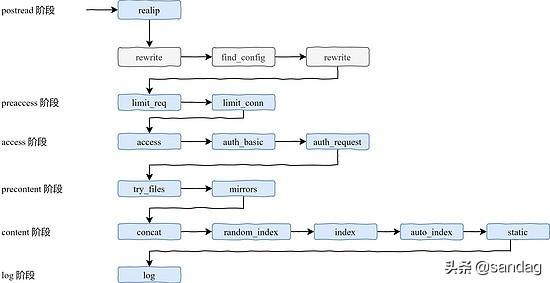
下面开始详细讲解一下各个阶段。先来看下第一个阶段postread 阶段,顾名思义,postread 阶段是在正式处理请求之前起作用的。
--------------------------------------------------------------
post-read 阶段
读取请求内容阶段,读取并解析完请求头之后就立即开始运行。
例如模块 ngx_realip 就在 post-read 阶段注册了处理程序,它的功能是迫使 Nginx 认为当前请求的来源地址是指定的某一个请求头的值。
该阶段是在Nginx读取并解析完请求头request headers之后就立即开始执行的,标准模块的ngx_realip就是在post-read阶段注册了处理程序。它的功能是迫使 Nginx 认为当前请求的来源地址是指定的某一个请求头的值。
server {
listen 8080;
set_real_ip_from 127.0.0.1;
real_ip_header X-My-IP;
location /test {
set $addr $remote_addr;
echo "from: $addr";
}
}
这里的配置是让 Nginx 把那些来自 127.0.0.1 的所有请求的来源地址,都改写为请求头 X-My-IP 所指定的值。同时该例使用了标准内建变量 $remote_addr 来输出当前请求的来源地址,以确认是否被成功改写。
问题:如何拿到用户的真实 IP 地址?
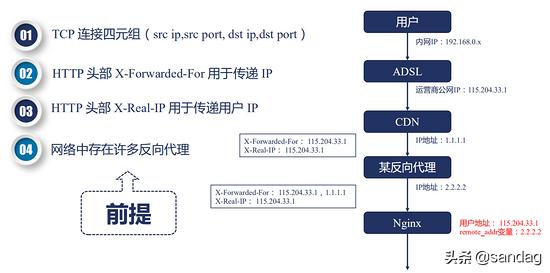
我们知道,TCP 连接是由一个四元组构成的,在四元组中,包含了源 IP 地址。而在真实的互联网中,存在非常多的正向代理和反向代理。例如最终的用户有自己的内网 IP 地址,运营商会分配一个公网 IP,然后访问某个网站的时候,这个网站可能使用了 CDN 加速一些静态文件或图片,如果 CDN 没有命中,那么就会回源,回源的时候可能还要经过一个反向代理,例如云平台的 SLB,然后才会到达 Nginx。
我们要拿到的地址应该是运营商给用户分配的公网 IP 地址 115.204.33.1,对这个 IP 来进行并发连接的控制或者限速,而 Nginx 拿到的却是 2.2.2.2,那么怎么才能拿到真实的用户 IP 呢?
HTTP 协议中,有两个头部可以用来获取用户 IP:
X-Forwardex-For 是用来传递IP 的,这个头部会把经过的节点 IP 都记录下来
X-Real-IP:可以记录用户真实的 IP 地址,只能有一个
拿到真实用户 IP 后如何使用?
针对这个问题,Nginx 是基于变量来使用。例如 binary_remote_addr、remote_addr 这样的变量,其实就是真实的 IP,这样做连接限制也就是 limit_conn 模块才有意义;这也说明了,limit_conn 模块只能在 preaccess 阶段,而不能在 postread 阶段生效。
-------------------------------
realip 模块
默认不会编译进 Nginx需要通过 --with-http_realip_module 启用功能
变量:如果还想要使用原来的 TCP 连接中的地址和端口,需要通过这两个变量保存realip_remote_addr realip_remote_port
功能修改客户端地址
指令set_real_ip_from指定可信的地址,只有从该地址建立的连接,获取的 realip 才是可信的real_ip_header指定从哪个头部取真实的 IP 地址,默认从 X-Real-IP 中取,如果设置从 X-Forwarded-For 中取,会先从最后一个 IP 开始取real_ip_recursive换回地址,默认关闭,打开的时候,如果X-Forwarded-For 最后一个地址与客户端地址相同,会过滤掉该地址
Syntax: set_real_ip_from address | CIDR | unix:;
Default: -
Context: http, server,location
Syntax: real_ip_header field | X-Real-IP | X-Forwarded-For | proxy_protocol;
Default: real_ip_header X-Real-IP;
Context: http, server,location
Syntax: real_ip_recursive on | off;
Default: real_ip_recursive off;
Context: http, server, location
如果使用X-Forwarded-For 获取 realip 的话,需要打开 real_ip_recursive ,并且realip 依赖于 set_real_ip_from 设置的可信地址。那么有人可能就会问了,那直接用 X-Real-IP 来选取真实的 IP 地址不就好了。这是可以的,但是 X-Real-IP 是 Nginx 独有的,不是 RFC 规范,如果客户端与服务器之间还有其他非 Nginx 软件实现的代理,就会造成取不到 X-Real-IP 头部,所以这个要根据实际情况来定。
--------------------------------------------------------------
server-rewrite 阶段
Server请求地址重写阶段,当 ngx_rewrite 模块的set配置指令直接书写在 server 配置块中时,基本上都是运行在 server-rewrite 阶段。
server {
listen 8080;
location /test {
set $b "$a, world";
echo $b;
}
set $a hello;
}
配置语句 set $a hello 直接写在了 server 配置块中,因此它就运行在 server-rewrite 阶段。rewrite 阶段分为两个,一个是 server_rewrite 阶段,一个是 rewrite,这两个阶段都涉及到一个 rewrite 模块,而在 rewrite 模块中,有一个 return 指令,遇到该指令就不会再向下执行,直接返回响应。


-------------------------------
return 指令
return 指令的语法如下:
返回状态码,后面跟上 body
返回状态码,后面跟上 URL
直接返回URL
Syntax: return code [text];
return code URL;
return URL;
Default: -
Context: server, location, if
返回状态码包括以下几种:
Nginx 自定义444:立刻关闭连接,用户收不到响应
HTTP 1.0 标准301:永久重定向302:临时重定向,禁止被缓存
HTTP 1.1 标准303:临时重定向,允许改变方法,禁止被缓存307:临时重定向,不允许改变方法,禁止被缓存308:永久重定向,不允许改变方法
-------------------------------
return 指令与error_page
error_page 的作用大家肯定经常见到。当访问一个网站出现 404 的时候,一般不会直接出现一个 404 NOT FOUND,而是会有一个比较友好的页面,这就是 error_page 的功能。
Syntax: error_page code ... [=[response]] uri;
Default: -
Context: http, server, location, if in location
当 server 下包含 error_page 且 location 下有 return 指令的时候,会执行哪一个呢?
会执行 location 下的 return 指令。
return 指令同时出现在 server 块下和同时出现在 location 块下,它们有合并关系吗?
没有合并关系,先遇到哪个 return 指令就先执行哪一个。
-------------------------------
rewrite 指令
rewrite 指令用于修改用户传入 Nginx 的 URL,来看下rewrite 的指令规则:
Syntax: rewrite regex replacement [flag];
Default: -
Context: server, location, if
它的功能主要有下面几点:
将regex 指定的 URL 替换成 replacement 这个新的 URL可以使用正则表达式及变量提取
当replacement 以 http:// 或者https:// 或者 $schema 开头,则直接返回302 重定向
替换后的URL根据 flag 指定的方式进行处理replacement
rewrite行为记录日志
主要是一个指令 rewrite_log :
Syntax: rewrite_log on | off;
Default: rewrite_log off;
Context: http, server, location, if
这个指令打开之后,会把 rewrite 的日志写入 logs/rewrite_error.log 日志文件中。
-------------------------------
if 指令
if 指令也是在rewrite 阶段生效的,它的语法如下所示:
Syntax: if (condition) { ... }
Default: -
Context: server, location
它的规则是:
条件condition 为真,则执行大括号内的指令;同时还遵循值指令的继承规则。
那么 if 指令的条件表达式包含哪些内容呢?它的规则如下:
检查变量为空或者值是否为 0
将变量与字符串做匹配,使用 = 或 !=
将变量与正则表达式做匹配大小写敏感,~ 或者 !~大小写不敏感,~* 或者 !~*
检查文件是否存在,使用 -f 或者 !-f
检查目录是否存在,使用 -d 或者 !-d
检查文件、目录、软链接是否存在,使用 -e 或者 !-e
检查是否为可执行文件,使用 -x 或者 !-x
下面是一些例子:
if ($http_user_agent ~ MSIE) { #与变量 http_user_agent 匹配
rewrite ^(.*)$ /msie/$1 break;
}
if ($http_cookie ~* "id=([^;]+)(?:;|$)") { #与变量 http_cookie 匹配
set $id $1;
}
if ($request_method = POST) { #与变量 request_method 匹配,获取请求方法
return 405;
}
if ($slow) { # slow 变量在 map 模块中自定义,也可以进行匹配
limit_rate 10k;
}
if ($invalid_referer) {
return 403;
}
--------------------------------------------------------------
find-config 阶段
配置查找阶段,这个阶段并不支持 Nginx 模块注册处理程序,而是由 Nginx 核心来完成当前请求与 location 配置块之间的配对工作。当经过 rewrite 模块,匹配到 URL 之后,就会进入 find_config 阶段,开始寻找 URL 对应的 location 配置。
紧接在 server-rewrite 阶段后边的是 find-config 阶段。这个阶段并不支持 Nginx 模块注册处理程序,而是由 Nginx 核心来完成当前请求与 location 配置块之间的配对工作。换句话说,在此阶段之前,请求并没有与任何 location 配置块相关联。因此,对于运行在 find-config 阶段之前的 post-read 和 server-rewrite 阶段来说,只有 server 配置块以及更外层作用域中的配置指令才会起作用。
location /hello {
echo "hello world";
}
如果启用了 Nginx 的“调试日志”,那么当请求 /hello 接口时,便可以在 error.log 文件中过滤出下面这一行信息:
$ grep 'using config' logs/error.log
[debug] 84579#0: *1 using configuration "/hello"
当经过 rewrite 模块,匹配到 URL 之后,就会进入 find_config 阶段,开始寻找 URL 对应的 location 配置。
-------------------------------
location 指令
指令语法
Syntax: location [ = | ~ | ~* | ^~ ] uri { ... }
location @name { ... }
Default: -
Context: server, location
Syntax: merge_slashes on | off;
Default: merge_slashes on;
Context: http, server
这里面有一个 merge_slashes 指令,这个指令的作用是,加入 URL 中有两个重复的 /,那么会合并为一个,这个指令默认是打开的,只有当对 URL 进行 base64 之类的编码时才需要关闭。
匹配规则
location 的匹配规则是仅匹配 URI,忽略参数,有下面三种大的情况:
前缀字符串常规匹配=:精确匹配^~:匹配上后则不再进行正则表达式匹配
正则表达式~:大小写敏感的正则匹配~*:大小写不敏感
用户内部跳转的命名 location
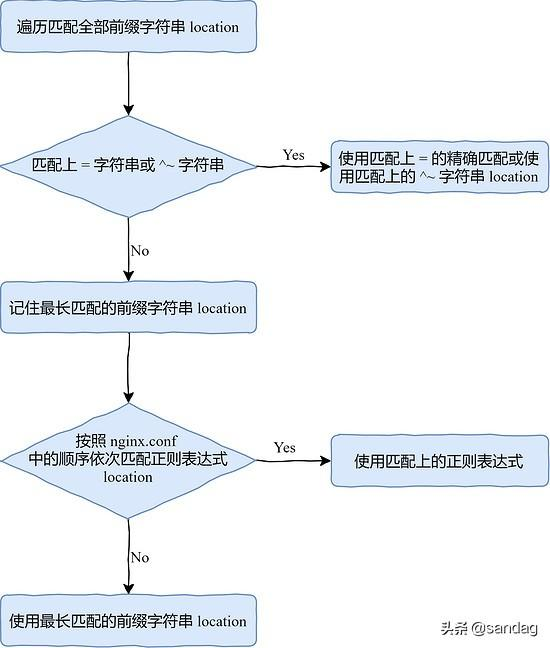
全部的前缀字符串是放置在一棵二叉树中的,Nginx 会分为两部分进行匹配:
先遍历所有的前缀字符串,选取最长的一个前缀字符串,如果这个字符串是 = 的精确匹配或 ^~ 的前缀匹配,会直接使用
如果第一步中没有匹配上 = 或 ^~,那么会先记住最长匹配的前缀字符串 location
按照 nginx.conf 文件中的配置依次匹配正则表达式
如果所有的正则表达式都没有匹配上,那么会使用最长匹配的前缀字符串
--------------------------------------------------------------
rewrite 阶段
Location请求地址重写阶段,当 ngx_rewrite 模块的指令用于 location 块中时,便是运行在这个 rewrite 阶段。另外,ngx_set_misc(设置md5、encode_base64等) 模块的指令,还有 ngx_lua 模块的 set_by_lua 指令和 rewrite_by_lua 指令也在此阶段。
运行在 find-config 阶段之后的便是我们的老朋友 rewrite 阶段。由于 Nginx 已经在 find-config 阶段完成了当前请求与 location 的配对,所以从 rewrite 阶段开始,location 配置块中的指令便可以产生作用。前面介绍过,当 ngx_rewrite 模块的指令用于 location 块中时,便是运行在这个 rewrite 阶段。
--------------------------------------------------------------
post-rewrite 阶段
请求地址重写提交阶段,由 Nginx 核心完成 rewrite 阶段所要求的“内部跳转”操作,如果 rewrite 阶段有此要求的话。
rewrite 阶段再往后便是所谓的 post-rewrite 阶段。这个阶段也像 find-config 阶段那样不接受 Nginx 模块注册处理程序,而是由 Nginx 核心完成 rewrite 阶段所要求的“内部跳转”操作如果 rewrite 阶段有此要求的话。
server {
listen 8080;
location /foo {
set $a hello;
rewrite ^ /bar;
}
location /bar {
echo "a = [$a]";
}
}
这里在 location /foo 中通过 rewrite 指令把当前请求的 URI 无条件地改写为 /bar,同时发起一个“内部跳转”,最终跳进了 location /bar 中。这里比较有趣的地方是内部跳转的工作原理。内部跳转本质上其实就是把当前的请求处理阶段强行倒退到 find-config 阶段,以便重新进行请求 URI 与 location 配置块的配对。比如上例中,运行在 rewrite 阶段的 rewrite 指令就让当前请求的处理阶段倒退回了 find-config 阶段。由于此时当前请求的 URI 已经被 rewrite 指令修改为了 /bar,所以这一次换成了 location /bar 与当前请求相关联,然后再接着从 rewrite 阶段往下执行。
不过这里更有趣的地方是,倒退回 find-config 阶段的动作并不是发生在 rewrite 阶段,而是发生在后面的 post-rewrite 阶段。上例中的 rewrite 指令只是简单地指示 Nginx 有必要在 post-rewrite 阶段发起“内部跳转”。这个设计对于 Nginx 初学者来说,或许显得有些古怪:“为什么不直接在 rewrite 指令执行时立即进行跳转呢?”答案其实很简单,那就是为了在最初匹配的 location 块中支持多次反复地改写 URI,例如:
location /foo {
rewrite ^ /bar;
rewrite ^ /baz;
echo foo;
}
location /bar {
echo bar;
}
location /baz {
echo baz;
}
这里在 location /foo 中连续把当前请求的 URI 改写了两遍:第一遍先无条件地改写为 /bar,第二遍再无条件地改写为 /baz. 而这两条 rewrite 语句只会最终导致 post-rewrite 阶段发生一次“内部跳转”操作,从而不至于在第一次改写 URI 时就直接跳离了当前的 location 而导致后面的 rewrite 语句没有机会执行。请求 /foo 接口的结果证实了这一点:
$ curl localhost:8080/foo
baz
从输出结果可以看到,上例确实成功地从 /foo 一步跳到了 /baz 中。如果启用 Nginx “调试日志”的话,还可以从 find-config 阶段生成的 location 块的匹配信息中进一步证实这一点:
$ grep 'using config' logs/error.log
[debug] 89449#0: *1 using configuration "/foo"
[debug] 89449#0: *1 using configuration "/baz"
可以看到对于该次请求,Nginx 一共只匹配过 /foo 和 /baz 这两个 location,从而只发生过一次“内部跳转”。当然,如果在 server 配置块中直接使用 rewrite 配置指令对请求 URI 进行改写,则不会涉及“内部跳转”,因为此时 URI 改写发生在 server-rewrite 阶段,早于执行 location 配对的 find-config 阶段。比如下面这个例子:
server {
listen 8080;
rewrite ^/foo /bar;
location /foo {
echo foo;
}
location /bar {
echo bar;
}
}
在 server-rewrite 阶段就把那些以 /foo 起始的 URI 改写为 /bar,而此时请求并没有和任何 location 相关联,所以 Nginx 正常往下运行 find-config 阶段,完成最终的 location 匹配。如果请求上例中的 /foo 接口,那么 location /foo 根本就没有机会匹配,因为在第一次也是唯一的一次运行 find-config 阶段时,当前请求的 URI 已经被改写为 /bar,从而只会匹配 location /bar。
--------------------------------------------------------------
preaccess 阶段
访问权限检查准备阶段,标准模块 ngx_limit_req 和 ngx_limit_zone 就运行在此阶段,前者可以控制请求的访问频度,而后者可以限制访问的并发度。限制每个客户端的并发连接数、访问频率?这些就是在 preaccess 阶段处理完成的,顾名思义,preaccess 就是在连接之前。先来看下 limit_conn 模块。
-------------------------------
limit_conn 模块
这里面涉及到的模块是ngx_http_limit_conn_module ,它的基本特性如下:
生效阶段:NGX_HTTP_PREACCESS_PHASE 阶段
模块:http_limit_conn_module
默认编译进Nginx,通过 --without-http_limit_conn_module 禁用
生效范围全部worker 进程基于共享内存进入 preaccess 阶段前不生效限制的有效性取决于 key 的设计:依赖 postread 阶段的 realip 模块取到真实 IP
这里面有一点需要注意,就是 limit_conn key 的设计,所谓的 key 指的就是对哪个变量进行限制,通常我们取的都是用户的真实 IP。
说完了 limit_conn 的模块,再来说一下指令语法。
指令语法
定义共享内存包括大小,以及 key 关键字
Syntax: limit_conn_zone key zone=name:size;
Default: -
Context: http
限制并发连接数
Syntax: limit_conn zone number;
Default: -
Context: http, server, location
限制发生时的日志级别
Syntax: limit_conn_log_level info | notice | warn | error;
Default: limit_conn_log_level error;
Context: http, server, location
限制发生时向客户端返回的错误码
Syntax: limit_conn_status code;
Default: limit_conn_status 503;
Context: http, server, location
-------------------------------
limit_req 模块
关于资源使用最常见的两个问题:
如何限制每个客户端的并发连接数?
如何限制访问频率?
第一个问题限制并发连接数的问题已经解决了,下面来看第二个问题。这里面生效的模块是ngx_http_limit_req_module ,它的基本特性如下:
生效阶段:NGX_HTTP_PREACCESS_PHASE 阶段
模块:http_limit_req_module
默认编译进Nginx,通过 --without-http_limit_req_module 禁用
生效算法:leaky bucket 算法
生效范围全部worker 进程基于共享内存进入 preaccess 阶段前不生效
-------------------------------
leaky bucket 算法
leaky bucket 叫漏桶算法,其他用来限制请求速率的还有令牌环算法等,这里面不展开讲。漏桶算法的原理是,先定义一个桶的大小,所有进入桶内的请求都会以恒定的速率被处理,如果请求太多超出了桶的容量,那么就会立刻返回错误,用一张图解释一下。
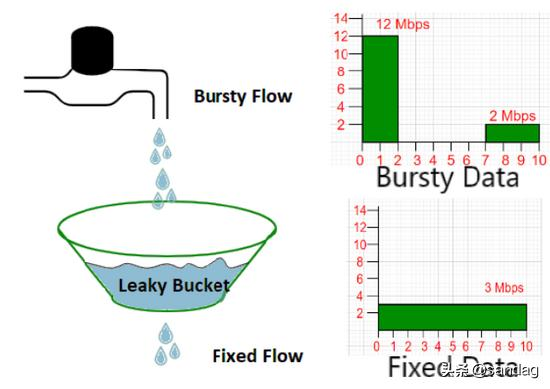
这张图里面,水龙头在不停地滴水,就像用户发来的请求,所有的水滴都会以恒定的速率流出去,也就是被处理。漏洞算法对于突发流量有很好的限制作用,会将所有的请求平滑的处理掉。
指令语法
定义共享内存包括大小,以及 key 关键字和限制速率
Syntax: limit_req_zone key zone=name:size rate=rate ;
Default: -
Context: http
rate 单位为r/s 或者 r/m每分钟或者每秒处理多少个请求
限制并发连接数
Syntax: limit_req zone=name [burst=number] [nodelay];
Default: -
Context: http, server, location
burst 默认为 0
nodelay,如果设置了这个参数,那么对于漏桶中的请求也会立刻返回错误
限制发生时的日志级别
Syntax: limit_req_log_level info | notice | warn | error;
Default: limit_req_log_level error;
Context: http, server, location
限制发生时向客户端返回的错误码
Syntax: limit_req_status code;
Default: limit_req_status 503;
Context: http, server, location
需要注意两个问题:
limit_req 与limit_conn 配置同时生效时,哪个优先级高?
nodelay 添加与否,有什么不同?
在 limit_req zone=one 指令下,超出每分钟处理的请求数后就会立刻返回 503。
改变一下注释的指令:
limit_req zone=one burst=3;
在没有添加 burst 参数时,会立刻返回错误,而加上之后,不会返回错误,而是等待请求限制解除,直到可以处理请求时再返回。
再来看一下 nodelay 参数:
limit_req zone=one burst=3 nodelay;
添加了 nodelay 之后,请求在没有达到 burst 限制之前都可以立刻被处理并返回,超出了 burst 限制之后,才会返回 503。
现在可以回答上面提出的两个问题:
limit_req 与limit_conn 配置同时生效时,哪个优先级高?limit_req 在 limit_conn 处理之前,因此是 limit_req 会生效
nodelay 添加与否,有什么不同?不添加 nodelay,请求会等待,直到能够处理请求;添加 nodelay,在不超出 burst 的限制的情况下会立刻处理并返回,超出限制则会返回 503。
--------------------------------------------------------------
access 阶段
访问权限检查阶段,标准模块 ngx_access、第三方模块 ngx_auth_request 以及第三方模块 ngx_lua 的 access_by_lua 指令就运行在这个阶段。配置指令多是执行访问控制性质的任务,比如检查用户的访问权限,检查用户的来源 IP 地址是否合法。经过 preaccess 阶段对用户的限流之后,就到了 access 阶段。
-------------------------------
access 模块
这里面涉及到的模块是ngx_http_access_module ,它的基本特性如下:
生效阶段:NGX_HTTP_ACCESS_PHASE 阶段
模块:http_access_module
默认编译进Nginx,通过 --without-http_access_module 禁用
生效范围进入access阶段前不生效
指令语法
Syntax: allow address | CIDR | unix: | all;
Default: -
Context: http, server, location, limit_except
Syntax: deny address | CIDR | unix: | all;
Default: -
Context: http, server, location, limit_except
access 模块提供了两条指令 allow 和 deny ,来看几个例子:
location / {
deny 192.168.1.1;
allow 192.168.1.0/24;
allow 10.1.1.0/16;
allow 2001:0db8::/32;
deny all;
}
对于用户访问来说,这些指令是顺序执行的,当满足了一条之后,就不会再向下执行。
-------------------------------
auth_basic 模块
auth_basic 模块是用作用户认证的,当开启了这个模块之后,我们通过浏览器访问网站时,就会返回一个 401 Unauthorized,当然这个 401 用户不会看见,浏览器会弹出一个对话框要求输入用户名和密码。这个模块使用的是 RFC2617 中的定义。
指令语法
基于HTTP Basic Authutication 协议进行用户密码的认证
默认编译进Nginx--without-http_auth_basic_moduledisable ngx_http_auth_basic_module
Syntax: auth_basic string | off;
Default: auth_basic off;
Context: http, server, location, limit_except
Syntax: auth_basic_user_file file;
Default: -
Context: http, server, location, limit_except
这里面我们会用到一个工具叫 htpasswd,这个工具可以用来生成密码文件,而 auth_basic_user_file 就依赖这个密码文件。htpasswd 依赖安装包httpd-tools,为apache httpd web服务器的工具。
生成密码的命令为:
htpasswd –c path_of_pwdfile –b user pass
-------------------------------
auth_request 模块
功能:向上游的服务转发请求,若上游服务返回的响应码是 2xx,则继续执行;若上游服务返回的是 401 或者 403,则将响应返回给客户端
原理:收到请求后,生成子请求,通过反向代理技术把请求传递给上游服务
默认未编译进Nginx,需要通过 --with-http_auth_request_module 编译进去
指令语法
Syntax: auth_request uri | off;
Default: auth_request off;
Context: http, server, location
Syntax: auth_request_set $variable value;
Default: -
Context: http, server, location
实战
在上一个配置文件中添加以下内容
server {
server_name freeoa.net;
listen 80;
error_log logs/error.log debug;
default_type text/plain;
location /auth_basic {
satisfy any;
auth_basic "test auth_basic";
auth_basic_user_file example/auth.pass;
deny all;
}
location / {
auth_request /test_auth;
}
location = /test_auth {
proxy_pass http://127.0.0.1:8090/auth_upstream;
proxy_pass_request_body off;
proxy_set_header Content-Length "";
proxy_set_header X-Original-URI $request_uri;
}
}
这个配置文件中,/ 路径下会将请求转发到另外一个服务中去,可以用 nginx 再搭建一个服务
如果这个服务返回 2xx,那么鉴权成功,如果返回 401 或 403 则鉴权失败
-------------------------------
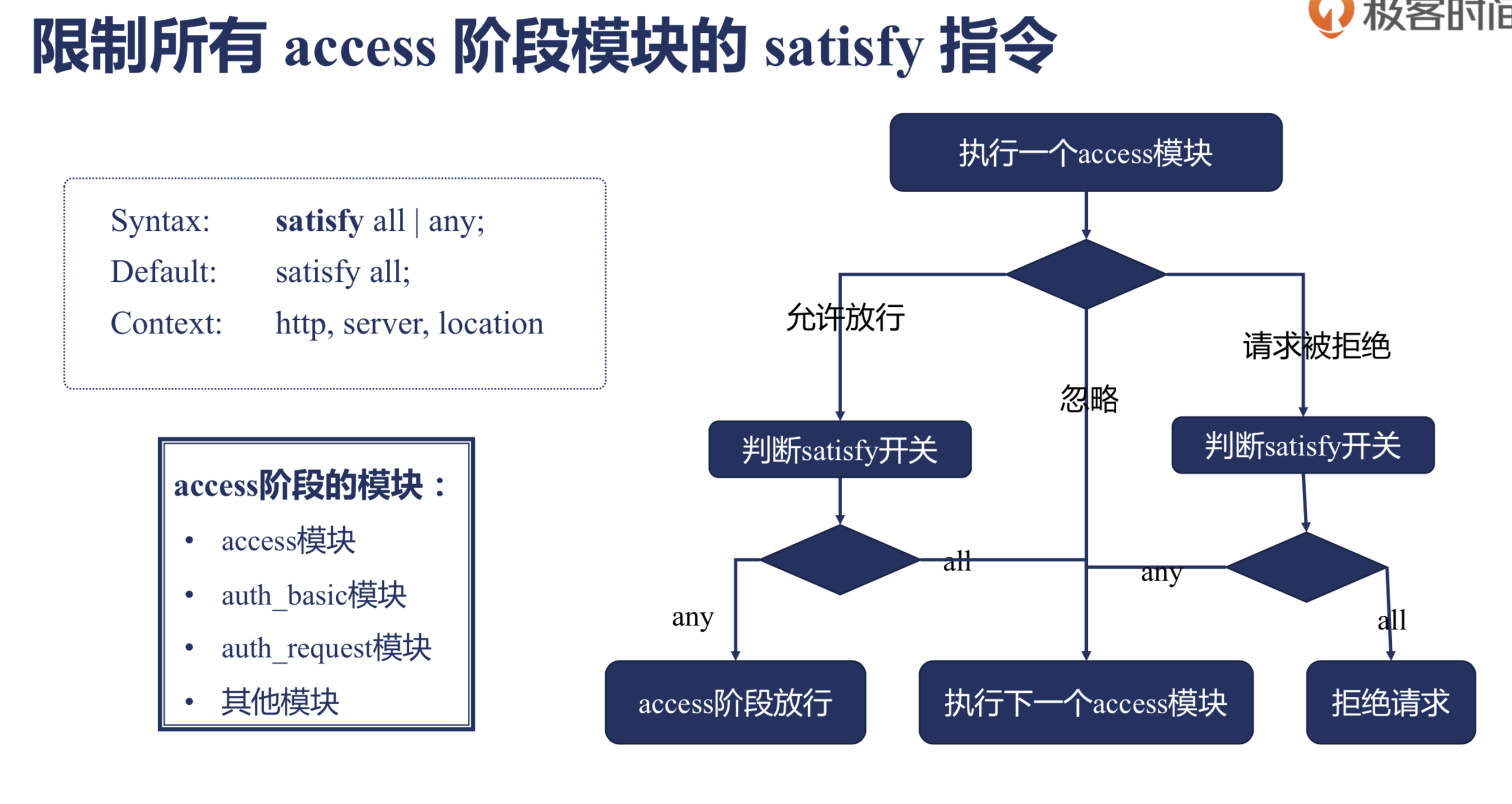
限制所有 access 阶段模块的 satisfy 指令
指令语法
Syntax: satisfy all | any;
Default: satisfy all;
Context: http, server, location
satisfy 指令有两个值一个是 all,一个是 any,这个模块对acces 阶段的三个模块都生效:
access 模块
auth_basic 模块
auth_request 模块
其他模块
如果 satisfy 指令的值是 all 的话,就表示必须所有 access 阶段的模块都要执行,都通过了才会放行;值是 any 的话,表示有任意一个模块得到执行即可。
下面有几个问题可以加深一下理解:
如果有 return 指令,access 阶段会生效吗?return 指令属于 rewrite 阶段,在 access 阶段之前,因此不会生效。
多个 access 模块的顺序有影响吗?ngx_http_auth_request_module, ngx_http_auth_basic_module, ngx_http_access_module,有影响
输对密码,下面可以访问到文件吗?location /{ satisfy any; auth_basic "test auth_basic"; auth_basic_user_file examples/auth.pass; deny all; }可以访问到,因为 satisfy 的值是 any,因此只要有模块满足,即可放行。
如果把 deny all 提到 auth_basic 之前呢?依然可以,因为各个模块执行顺序和指令的顺序无关。
如果改为 allow all,有机会输入密码吗?没有机会,因为 allow all 是 access 模块,先于 auth_basic 模块执行。
--------------------------------------------------------------
post-access 阶段
访问权限检查提交阶段,主要用于配合 access 阶段实现标准 ngx_http_core 模块提供的配置指令 satisfy 的功能。
satisfy all(与关系)
satisfy any(或关系)
对于多个 Nginx 模块注册在 access 阶段的处理程序, satisfy 配置指令可以用于控制它们彼此之间的协作方式。比如模块 A 和 B 都在 access 阶段注册了与访问控制相关的处理程序,那就有两种协作方式,一是模块 A 和模块 B 都得通过验证才算通过,二是模块 A 和模块 B 只要其中任一个通过验证就算通过。第一种协作方式称为 all 方式或者说“与关系”,第二种方式则被称为 any 方式或者说“或关系”。默认情况下,Nginx 使用的是 all 方式。下面是一个例子:
location /test {
satisfy all;
deny all;
access_by_lua 'ngx.exit(ngx.OK)';
echo something important;
}
这里在 /test 接口中同时配置了 ngx_access 模块和 ngx_lua 模块,这样 access 阶段就由这两个模块一起来做检验工作。其中语句 deny all 会让 ngx_access 模块的处理程序总是拒绝当前请求,而语句 access_by_lua 'ngx.exit(ngx.OK)' 则总是允许访问。当通过 satisfy 指令配置了 all 方式时,就需要 access 阶段的所有模块都通过验证,但不幸的是,这里 ngx_access 模块总是会拒绝访问,所以整个请求就会被拒。
-------------------------------
try-files
配置项try_files处理阶段,专门用于实现标准配置指令 try_files 的功能。如果前 N-1 个参数所对应的文件系统对象都不存在,try-files 阶段就会立即发起“内部跳转”到最后一个参数即第 N 个参数所指定的 URI。
这个阶段专门用于实现标准配置指令 try_files 的功能,并不支持 Nginx 模块注册处理程序。try_files 指令接受两个以上任意数量的参数,每个参数都指定了一个 URI. 这里假设配置了 N 个参数,则 Nginx 会在 try-files 阶段,依次把前 N-1 个参数映射为文件系统上的对象文件或者目录,然后检查这些对象是否存在。一旦 Nginx 发现某个文件系统对象存在,就会在 try-files 阶段把当前请求的 URI 改写为该对象所对应的参数 URI但不会包含末尾的斜杠字符,也不会发生 “内部跳转”。如果前 N-1 个参数所对应的文件系统对象都不存在,try-files 阶段就会立即发起“内部跳转”到最后一个参数即第 N 个参数所指定的 URI。
root /var/www/;
location /test {
try_files /foo /bar/ /baz;
echo "uri: $uri";
}
location /foo {
echo foo;
}
location /bar/ {
echo bar;
}
location /baz {
echo baz;
}
这里通过 root 指令把“文档根目录”配置为 /var/www/,如果你系统中的 /var/www/ 路径下存放有重要数据,则可以把它替换为其他任意路径,但此路径对运行 Nginx worker 进程的系统帐号至少有可读权限。我们在 location /test 中使用了 try_files 配置指令,并提供了三个参数,/foo、/bar/ 和 /baz。根据前面对 try_files 指令的介绍,我们可以知道,它会在 try-files 阶段依次检查前两个参数 /foo 和 /bar/ 所对应的文件系统对象是否存在。
不妨先来做一组实验。假设现在 /var/www/ 路径下是空的,则第一个参数 /foo 映射成的文件 /var/www/foo 是不存在的;同样,对于第二个参数 /bar/ 所映射成的目录 /var/www/bar/ 也是不存在的。于是此时 Nginx 会在 try-files 阶段发起到最后一个参数所指定的 URI即 /baz的“内部跳转”。实际的请求结果证实了这一点:
$ curl localhost:8080/test
baz
显然该请求最终和 location /baz 绑定在一起,执行了输出 baz 字符串的工作。上例中定义的 location /foo 和 location /bar/ 完全不会参与这里的运行过程,因为对于 try_files 的前 N-1 个参数,Nginx 只会检查文件系统,而不会去执行 URI 与 location 之间的匹配。
try-files 阶段发生的事情:Nginx 依次检查了文件 /var/www/foo 和目录 /var/www/bar,末了又处理了最后一个参数 /baz。这里最后一条“调试信息”容易产生误解,会让人误以为 Nginx 也把最后一个参数 /baz 给映射成了文件系统对象进行检查,事实并非如此。当 try_files 指令处理到它的最后一个参数时,总是直接执行“内部跳转”,而不论其对应的文件系统对象是否存在。
--------------------------------------------------------------
precontent 阶段
这个阶段只有 try_files 这一个指令(ngx_http_try_files_module),可以替代rewrite来提高解析效率,其作用一般用户url的美化或者是伪静态功能。
格式1:try_files file ... uri;
格式2:try_files file ... =code;
可应用的上下文:server,location段
工作流程大致如下:
1、按指定的file顺序查找存在的文件,并使用第一个找到的文件进行请求处理
2、查找路径是按照给定的root或alias为根路径来查找的
3、如果给出的file都没有匹配到,则重新请求最后一个参数给定的uri,就是新的location匹配
4、如果是格式2,如果最后一个参数是 = 404 ,若给出的file都没有匹配到,则最后返回404的响应码
location / {
try_files $uri $uri/ /index.php?$query_string;
}
location ~ .*\.(php|php5)?$ {
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
}
当用户请求 http://localhost/example 时,这里的 $uri 就是 /example。try_files 会到硬盘里尝试找这个文件。如果存在名为 /root/example其中root是项目代码根目录的文件,就直接把这个文件的内容发送给用户。
显然目录中没有叫 example 的文件。然后就看 uri/,增加了一个 /,也就是看有没有名为 /root/example/ 的目录。又找不到,就会 fall back 到 try_files 的最后一个选项 /index.php,发起一个内部 “子请求”,也就是相当于 nginx 发起一个 HTTP 请求到 http://localhost/index.php
这个请求会被 location ~ .*.(php|php5)?$ { ... } 所匹配,也就是进入 FastCGI 的处理程序。而具体的 URI 及参数是在 REQUEST_URI 中传递给 FastCGI 和 PHP 程序的,因此不受 URI 变化的影响。
location /images/ {
root /opt/html/;
try_files $uri $uri/ /images/default.gif;
}
在请求http://ip/images/test.gif 会依次查找
1.文件/opt/html/images/test.gif
2.文件夹 /opt/html/images/test.gif/下的index文件
3. 请求ip/images/default.gif
4.其他注意事项
1.try-files 如果不写上 $uri/,当直接访问一个目录路径时,并不会去匹配目录下的索引页,即访问ip/images/ 不会去访问 ip/images/index.html。
-------------------------------
try_files 模块
指令语法
Syntax: try_files file ... uri;
try_files file ... =code;
Default: -
Context: server, location
location /first {
try_files /system/maintenance.html $uri $uri/index.html $uri.html
@lasturl;
}
location @lasturl {
return 200 'lasturl!\n';
}
location /second {
try_files $uri $uri/index.html $uri.html = 404;
}
结果如下:
访问/first 实际上到了 lasturl,然后返回 200
访问/second 则返回了 404
这两个结果都与配置文件是一致的。
-------------------------------
mirror 模块
mirror 模块可以实时拷贝流量,这对于需要同时访问多个环境的请求是非常有用的。
指令语法
模块:ngx_http_mirror_module 模块,默认编译进 Nginx通过 --without-http_mirror_module 移除模块
功能:处理请求时,生成子请求访问其他服务,对子请求的返回值不做处理
Syntax: mirror uri | off;
Default: mirror off;
Context: http, server,location
Syntax: mirror_request_body on | off;
Default: mirror_request_body on;
Context: http, server, location
server {
server_name freeoa;
listen 8001;
error_log logs/error_log debug;
location / {
mirror /mirror;
mirror_request_body off;
}
location = /mirror {
internal;
proxy_pass http://127.0.0.1:10020$request_uri;
proxy_pass_request_body off;
proxy_set_header Content-Length "";
proxy_set_header X-Original-URI $request_uri;
}
}
在access.log 文件中可以看到有请求记录日志
--------------------------------------------------------------
content 阶段
内容产生阶段,Nginx 的 content 阶段是所有请求处理阶段中最为重要的一个,因为运行在这个阶段的配置指令一般都肩负着生成“内容”并输出 HTTP 响应的使命。
content阶段主要是处理内容输出的阶段。这里要注意的是绝大多数 Nginx 模块在向 content 阶段注册配置指令时,本质上是在当前的 location 配置块中注册所谓的“内容处理程序”content handler。每一个 location 只能有一个“内容处理程序”,因此,当在 location 中同时使用多个模块的 content 阶段指令时,只有其中一个模块能成功注册“内容处理程序”。例如 echo 和 content_by_lua 如果同时注册,最终只会有一个生效,但具体是哪一个生效是不稳定的。
--------------------------------------------------------------
log 阶段
日志模块处理阶段,用于记录日志。
-------------------------------
单说satisfy指令
在Nginx中的access阶段中有很多限制模块,前面几篇介绍的access、auth_basic、auth_request模块。这些模块的限制顺序规则,在nginx http框架中是怎么规定的呢?下面介绍一下satisfy指令。
satisfy指令说明
语法:satisfy all | any
默认:satisfy all;
上下文:http,server,location
指令说明:例如access阶段按照access模块、auth_basic模块、auth_request模块、其他模块执行顺序。
all:意思是 access阶段的所有模块都是通过,才可以继续往下面执行;只要有任何一个不通过都会返回错误。
any:意思是 所有模块中任何一个验证通过,就放行;无论是前面的还是后面只要有一个验证通过就可以。
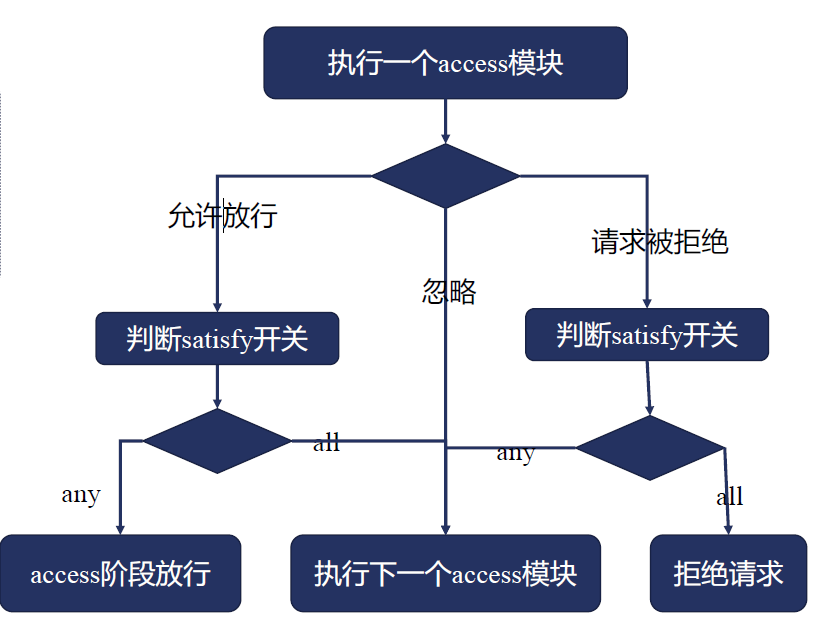
执行流程
1、执行一个access模块,会产生三个结果
1-1、忽略,没有配置任何的指令关于这个模块,继续执行下一个access模块
1-2、放行,验证通过放行
1-2-1、判断satisfy开关,如果为any,access阶段放行通过。
1-2-2、判断satisfy开关,如果为all,继续执行验证下面的一个access模块
1-3、拒绝,验证不通过拒绝
1-3-1、判断satisfy开关,如果为any,继续执行验证下面一个access模块
1-3-2、判断satisfy开关,如果为all,拒绝请求
示例
location / {
satisfy any;
auth_basic "auth_basic";
auth_basic_user_file user.pass;
deny all;
}
注:上面代码执行,让用户名和密码输入正确后,尽管配置了'deny all';仍然会请求通过。