Linux高并发环境下调优Nginx
 本文是参考了诸多的文章后总结而来的,主要用于在Linux环境下,遇到高并发时对Nginx的相关的调优,在对Nginx调优前是很有必要对Linux操作系统进行一次调优;任何一项目调优都不是独立的,当深入了解后会对此有更深刻的理解,这更源于对整体知识的全面了解。
本文是参考了诸多的文章后总结而来的,主要用于在Linux环境下,遇到高并发时对Nginx的相关的调优,在对Nginx调优前是很有必要对Linux操作系统进行一次调优;任何一项目调优都不是独立的,当深入了解后会对此有更深刻的理解,这更源于对整体知识的全面了解。Nginx层面的参数优化:
这里重点列出了对 Nginx 影响比较大的参数
1、nginx 进程数,建议按照cpu 数目来指定,一般为它的倍数 (如两个四核的cpu可设为8)。
worker_processes 8;
也可以直接写 auto;
worker_processes auto;
2、增加worker_connections数量
events {
worker_connections 20000; #经测试太大和太小最不好, 这个4096的值是比较适合的
multi_accept off; #建议为默认值 off, 除非测试时确认为 on 时有性能提升
accept_mutex off; #当使用 epoll 或 listen reuseport 时要关掉这个,当然默认情况下也是关闭的(注意, nginx 1.11.3之前默认是开启)
}
3、nginx有一个worker_rlimit_nofile directive,可以用来设置系统可用的文件描述符,这与ulimit设置可用文件描述符的作用是一样的。如果它们都设置了可用文件描述符,那么worker_rlimit_nofile会覆盖ulimit的设置。
worker_rlimit_nofile = 30000;
4、worker_cpu_affinity
为每个进程分配cpu,上例中将8个进程分配到8个cpu,当然可以写多个,或者将一个进程分配到多个cpu:
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000 00100000 01000000 10000000;
或者直接适用auto选项,让nginx自动绑定可用的cpu核:
worker_cpu_affinity auto;
5、worker_rlimit_nofile
这个指令是指当一个nginx进程打开的最多文件描述符数目,理论值应该是最多打开文件数(ulimit -n)与nginx进程数相除,但是nginx分配请求并不是那么均匀,所以最好与ulimit -n的值保持一致:
worker_rlimit_nofile 102400;
6、sendfile
当应用程序传输文件时,内核首先缓冲数据,然后将数据发送到应用程序缓冲区。应用程序最后将数据发送到目的地。sendfile方法则是对输出传输方法进行改进,其中数据在操作系统内核空间内的文件描述符之间复制,而不将数据传输到应用程序缓冲区,这样极大提高了系统资源的利用率。
http {
sendfile on;
}
7、epoll
使用epoll的I/O模型
use epoll;
8、worker_connections
每个进程允许的最大连接数,理论上每台nginx服务器的最大连接数为worker_process*worker_connections:
worker_connections 102400;
9、keepalive_timeout
keepalive超时时间:
keepalive_timeout 60;
10、client_header_buffer_size
客户端请求头部的缓冲区大小,这个可以根据你的系统分页大小来设置,一般一个请求的头部大小不会超过1k,不过由于一般系统分页都要大于1k,所以这里设置为分页大小。分页大小可以用命令getconf PAGESIZE取得:
client_header_buffer_size 4k;
11、open_file_cache_valid
这个将为打开文件指定缓存,默认是没有启用的,max指定缓存数量,建议和打开文件数一致,inactive是指经过多长时间文件没被请求后删除缓存:
open_file_cache_valid 30s;
12、open_file_cache_min_uses
这个是指多长时间检查一次缓存的有效信息:
open_file_cache_min_uses 1;
Nginx连接性能优化
1、nginx长连接之keepalive
1)、从client到nginx的连接是长连接从nginx到server的连接是长连接
保持和client的长连接:默认情况下,nginx已经自动开启了对client连接的keep alive支持(同时client发送的HTTP请求要求keep alive)。一般场景可以直接使用,但是对于一些比较特殊的场景,还是有必要调整它的派生参数(keepalive_timeout和keepalive_requests)。
http {
keepalive_timeout 120s 120s;
keepalive_requests 10000;
}
解释:
keepalive_timeout
第一个参数:设置keep-alive客户端连接在服务器端保持开启的超时值(默认75s);值为0会禁用keep-alive客户端连接;
第二个参数:可选、在响应的header域中设置一个值“Keep-Alive: timeout=time”;通常可以不用设置;
注:keepalive_timeout默认75s,一般情况下也够用,对于一些请求比较大的内部服务器通讯的场景,适当加大为120s或者300s;
keepalive_requests
keepalive_requests指令用于设置一个keep-alive连接上可以服务的请求的最大数量,当最大请求数量达到时,连接被关闭。默认是100。这个参数的真实含义,是指一个keep alive建立之后,nginx就会为这个连接设置一个计数器,记录这个keep alive的长连接上已经接收并处理的客户端请求的数量。
如果达到这个参数设置的最大值时,则nginx会强行关闭这个长连接,逼迫客户端不得不重新建立新的长连接。大多数情况下当QPS(每秒请求数)不是很高时,默认值100够用。但对于一些QPS比较高(比如超过10000QPS,甚至达到30000,50000甚至更高) 的场景,默认的100就显得太低。
简单计算一下,QPS=10000时,客户端每秒发送10000个请求(通常建立有多个长连接),每个连接只能最多跑100次请求,意味着平均每秒钟就会有100个长连接因此被nginx关闭。同样意味着为了保持QPS,客户端不得不每秒中重新新建100个连接。因此,就会发现有大量的TIME_WAIT的socket连接(即使此时keep alive已经在client和nginx之间生效)。因此对于QPS较高的场景,非常有必要加大这个参数,以避免出现大量连接被生成再抛弃的情况,减少TIME_WAIT。
2)、保持和后端server的长连接:
为了让nginx和后端server(nginx称为upstream)之间保持长连接,典型设置如下:(默认nginx访问后端都是用的短连接(HTTP1.0),一个请求来了,Nginx 新开一个端口和后端建立连接,后端执行完毕后主动关闭该链接)。
http {
upstream FREEOA {
server 129.9.10.104:8080 weight=1 max_fails=2 fail_timeout=30s;
server 129.9.10.105:8080 weight=1 max_fails=2 fail_timeout=30s;
keepalive 300; #根据后端服务连接数大小和nginx的情况来决定
}
server {
listen 8080 default_server;
server_name "";
#不返回 server 的 version 标识,以减少响应数据
server_tokens off;
#下面将完全禁止返回 Server. 上面的只是不显示版本
more_clear_headers Server;
#禁止返回 Date
more_clear_headers Date;
keepalive_requests 9000; #表示每个 keepalive tcp 连接,最大可处理多少个请求,这个在高 QPS 下还要调高它
keepalive_timeout 30;
location /X1 {
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_pass http://FREEOA;
proxy_set_header Host $Host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header x-forwarded-for $remote_addr;
add_header Cache-Control no-store;
add_header Pragma no-cache;
}
location /X2 {
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_pass http://freeoaserv;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
client_max_body_size 16m;
client_body_buffer_size 512k;
proxy_buffers 4 256k;
proxy_buffer_size 256k;
proxy_busy_buffers_size 512k;
proxy_temp_file_write_size 512k;
}
}
}
(1)、location中有两个参数需要设置:
http {
server {
location / {
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
}
HTTP协议中对长连接的支持是从1.1版本之后才有的,因此最好通过proxy_http_version指令设置为"1.1";而"Connection" header应该被清理。清理的意思,应该是清理从client过来的http header,因为即使是client和nginx之间是短连接,nginx和upstream之间也是可以开启长连接的。这种情况下就要必须清理来自client请求中的"Connection" header。
(2)、upstream中的keepalive设置:
此处keepalive的含义不是开启、关闭长连接的开关,也不是用来设置超时的timeout,更不是设置长连接池最大连接数。官方解释:The connections parameter sets the maximum number of idle keepalive connections to upstream servers connections(设置到upstream服务器的空闲keepalive连接的最大数量).When this number is exceeded, the least recently used connections are closed. (当这个数量被突破时,最近使用最少的连接将被关闭)It should be particularly noted that the keepalive directive does not limit the total number of connections to upstream servers that an nginx worker process can open.(特别提醒:keepalive指令不会限制一个nginx worker进程到upstream服务器连接的总数量)
我们先假设一个场景: 有一个HTTP服务,作为upstream服务器接收请求,响应时间为100毫秒。如果要达到10000 QPS的性能,就需要在nginx和upstream服务器之间建立大约1000条HTTP连接。nginx为此建立连接池,然后请求过来时为每个请求分配一个连接,请求结束时回收连接放入连接池中,连接的状态也就更改为idle。再假设这个upstream服务器的keepalive参数设置比较小,比如常见的10。
A、假设请求和响应是均匀而平稳的,那么这1000条连接应该都是一放回连接池就立即被后续请求申请使用,线程池中的idle线程会非常的少,趋进于零,不会造成连接数量反复震荡。
B、显示中请求和响应不可能平稳,我们以10毫秒为一个单位,来看连接的情况(注意场景是1000个线程+100毫秒响应时间,每秒有10000个请求完成),我们假设应答始终都是平稳的,只是请求不平稳,第一个10毫秒只有50,第二个10毫秒有150:
下一个10毫秒,有100个连接结束请求回收连接到连接池,但是假设此时请求不均匀10毫秒内没有预计的100个请求进来,而是只有50个请求。注意此时连接池回收了100个连接又分配出去50个连接,因此连接池内有50个空闲连接。
然后注意看keepalive=10的设置,这意味着连接池中最多容许保留有10个空闲连接。因此nginx不得不将这50个空闲连接中的40个关闭,只留下10个。再下一个10个毫秒,有150个请求进来,有100个请求结束任务释放连接。150 - 100 = 50,空缺了50个连接,减掉前面连接池保留的10个空闲连接,nginx不得不新建40个新连接来满足要求。
C、同样,如果假设相应不均衡也会出现上面的连接数波动情况。
造成连接数量反波动的一个推手,就是这个keepalive 这个最大空闲连接数。毕竟连接池中的1000个连接在频繁利用时,出现短时间内多余10个空闲连接的概率实在太高。因此为了避免出现上面的连接波动,必须考虑加大这个参数,比如上面的场景如果将keepalive设置为100或者200,就可以非常有效的缓冲请求和应答不均匀。
(3)、upstream中的keepalive设置的作用:
HTTP协议中对长连接的支持是从1.1版本之后才有的,因此最好通过proxy_http_version指令设置为'1.1';而'Connection' header应该被清理。是清理从client过来的http header,因为即使是client和nginx之间是短连接,nginx和upstream之间也是可以开启长连接的。这种情况下还必须清理来自client请求中的'Connection' header。
小结:
nginx出现大量TIME_WAIT的情况
(1)、导致nginx端出现大量TIME_WAIT的情况有两种:
keepalive_requests设置比较小,高并发下超过此值后nginx会强制关闭和客户端保持的keepalive长连接;(主动关闭连接后导致nginx出现TIME_WAIT)
keepalive设置的比较小(空闲数太小),导致高并发下nginx会频繁出现连接数震荡(超过该值会关闭连接),不停的关闭、开启和后端server保持的keepalive长连接;
(2)、导致后端server端出现大量TIME_WAIT的情况:
nginx没有打开和后端的长连接,即:没有设置
proxy_http_version 1.1;
proxy_set_header Connection "";
从而导致后端server每次关闭连接,高并发下就会出现server端出现大量TIME_WAIT。两类'_WAIT'高的可能原因有:
TIME_WAIT : (主动关闭)无法真正释放句柄资源,可通过 sysctl -w net.ipv4.tcp_fin_timeout=15 来减小超时时间,默认是 60 (单位是秒)。
CLOSE_WAIT : (被动关闭)过多的话,很可能是程序自身的问题,比如程序自己忘记关闭连接。
Nginx反向代理应用服务器,导致后端应用服务器TIME_WAIT过多问题分析:
案例一:nginx端出现大量TIME_WAIT
将nginx作为反向代理时,后连tomcat等服务器。测试中不同并发压力下多次、反复出现nginx服务器端口资源耗尽的问题。表现为nginx服务器出现大量time_wait状态连接,端口资源耗尽(nginx报错:cannot assign requested address )。首先检查nginx开启了长连接keepalive,但是系统仍然出现了大量的TIME_WAIT,这就和之前提到的当系统产生TIME_WAIT的速度大于其消耗速度时,就会累计TIME_WAIT。原因是:keepalive取配置太小,将其增大后问题得以解决(nginx总的keepalive连接池大小 = keepalive取值 * nginx worker数)。
注:从nginx 1.1.4 开始有了原生的ngx_http_upstream_keepalive 模块。
案例二:tomcat端出现大量TIME_WAIT
Nginx作为反向代理,长连接配置主要有三项,upstream中的keepalive设置单个worker最大请求数,参数proxy_http_version 1.1强制转换为http1.1协议(默认支持长连接),proxy_set_header Connection将请求头部connection为空(因为http1.0请求默认connection头部为close)。如下:
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
#tcp_nopush on;
#gzip on;
keepalive_timeout 65;#默认0,长连接的持续时间
include conf.d/*.conf;
}
upstream http_backend {
server 127.0.0.1:8080;
keepalive 16;#连接池大小
}
server {
...
location /http/ {
proxy_pass http://http_backend;
proxy_http_version 1.1;
proxy_set_header Connection "";
...
}
}
但是会有疑问:TIME_WAIT为何出现在Tomcat而不是在Nginx上?从抓包可以看出Nginx发送给Tomcat包头部Connection为close,所以Tomcat在处理完head请求后就主动关闭,所以TIME_WAIT出现在Tomcat侧的服务器上。
2、upstream 的 keepalive 问题
因为默认情况下,Nginx -> 后端的 upstream 服务器是使用 http 1.0 的,这个可以从官方文档中查证到的。所以为了开启 keepalive可以修改该参数:
proxy_http_version 1.0 -> proxy_http_version 1.1
注意, 还要同时设置 proxy_set_header Connection "";
注意, upstream 指令下的 keepalive N; 中的 N表示的是每个 Nginx Worker 最大空闲的 keepalive 数量。
通过 tcpdump 可以看到. 如果不设置的话, 默认 nginx 与 upstream 后端的HTTP 通信的请求为:
HTTP/1.0
Connection: close
upstream 中的 keepalive 以及设置建议:
proxy_http_version 1.1;
proxy_set_header Connection "";
3、upstream prematurely closed connection while reading response header from upstream
在分析ngnix的错误日志时会发现偶发的502错误:"upstream prematurely closed connection while reading response header from upstream",这么一条错误日志的大意,即在请求时后端服务过早的关闭了连接,或认为通过之前建立好的连接发起查询时却发现此连接已经不复存在了。
可能的两种原因:
1、Nginx中的keepalive_timeout配置为65秒,即是说长连接保持的时间,如果没有任何数据传输的话,超过这个时间,服务端会关闭这个连接。说明在这65秒没有任何数据传输,也正好在此时Clien向Server发送了数据,而Server关闭了这个连接,于是就出现了上面的现象。可以暂时调大keepalive_timeout的值来缓解这一情况,这是在有多个nginx传输链路的情况下。
如果系统并发量不大,没有必要开启长连接。可从试一下这种调整方式:
1)、第一台nginx可以去除这两个配置
proxy_http_version 1.1; proxy_set_header Connection "0";
2)、第二台nginx的keepalive_timeout可以配置为0(默认是75),值为0时会禁用keep-alive客户端连接。
2、从报错直接定位到应用后端的问题(为什么在读取的时候发生了这个问题,且前端的请求并不高的情况下),这里只有一层的nginx的代理,直接在后端应用上去找问题看看,在后端java应用的日志中发现了类似的oom的报错提示且有比较快的刷屏,对新建的连接请求接收后直接进行了丢弃,这与nginx上的表现相符合,与开发合计后,滚动重启了后端的应用,问题解决。
如果访问非常频繁很容易引起'no live upstreams while connecting to upstream'问题,前端页面容易报出错误;网上找答案,有说是ngxin缓存目录权限问题,也有说是 keepalive_timeout 时间设置太短,试了以后,发现均不能解决问题。在upstream中取消keepalive设定后,不再出现此问题。
4、应用程序在系统层上的调优
最好设置 CPU 亲和性
taskset -cp CPUID(从0开始) PID
查看亲和性
taskset -cp PID
减少带宽
减少返回的 body 字节数
压缩
JSON 的 null 字段去掉
不必要的字节
使用不同的算法来压缩值. 比如 long -> 36 进制
减少 nignx 不必要的 Header
204 可以只返回 HTTP/1.1 204 No Content\r\n
Date 去掉
Server 去掉
Connection 去掉(http1.1),这个操作可能要修改源码重新编译。
配置参考
user nginx;
worker_processes 4;
error_log logs/error.log;
worker_rlimit_nofile 65535;
events {
worker_connections 10240;
}
http {
include mime.types;
default_type application/octet-stream;
log_format main '$remote_addr:$remote_port - $http_x_forwarded_for - $request_time - $upstream_cache_status - $remote_user - [$time_iso8601] - "$request" - $status - $body_bytes_sent - "$http_user_agent" - $http_referer - $upstream_addr - $upstream_response_time - $upstream_status';
add_header Cache-Control no-cache;
#access_log logs/access.log main;
access_log off;
client_max_body_size 1000m;
sendfile on;
keepalive_timeout 120;
map $http_upgrade $connection_upgrade{
default upgrade;
'' close;
}
map $http_browser_type $browser_type {
default 0;
cef 1;
}
include someother.conf;
server {
listen 80;
server_name localhost;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_set_header Host $host:$server_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
include someother.conf;
location /ngx_status {
stub_status on;
access_log off;
allow 127.0.0.1;
deny all;
}
}
}
events {
use epoll;
worker_connections 409600;
multi_accept on;
accept_mutex off;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main ...
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 300;
keepalive_requests 20000000;
open_file_cache max=10240 inactive=20s;
open_file_cache_valid 30s;
open_file_cache_min_uses 1;
gzip on;
gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_http_version 1.0;
gzip_comp_level 2;
gzip_types text/plain application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png;
gzip_vary on;
include /etc/nginx/conf.d/*.conf;
}
events表示启用epoll模型来处理高并发的请求,epoll模型是linux底层的高性能、高并发处理模型,nginx也是基于此实现的。
在http的主配置中,开启sendfile、tcp_nopush和tcp_nodelay;
同时keepalive一定要配置上,timeout表示超时时间;requests表示同一个连接接收多少请求后断开;
剩下的就是一些常用的配置,记得在最后如果有其他额外的配置,要放到conf.d目录下。
负载节点信息
upstream freeoa {
server foapp:5001 max_fails=0;
server foapp:5002 max_fails=0;
server foapp:5003 max_fails=0;
server foapp:5004 max_fails=0;
keepalive 300;
}
这里相当于我们申请了一个叫做freeoa的负载结构,里面把请求均匀地分配到4个节点上,同时一定要加上keepalive,否则这个节点的负载就是短链接,而不是长连接。注意max_fails=0表示忽略当前负载节点的报错,如果不配置,默认值为1,即当负载节点报错1次后,即暂停向当前节点分发请求。
注:对于可靠性较高的负载节点,可以忽略掉报错,因为极端情况下,如果所有节点均出错,则当前服务即不可用,下文还有述。
server {
listen 443 ssl http2 backlog=65535;
listen [::]:443 ssl http2 backlog=65535;
server_name localhost.com;
access_log off;
ssl_certificate your-cert-file-path;
ssl_certificate_key your-cert-key-file-path;
ssl_session_timeout 1d;
ssl_session_cache shared:SSL:50m;
ssl_session_tickets off;
# modern configuration
ssl_protocols TLSv1.2;
ssl_ciphers 'ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256';
ssl_prefer_server_ciphers on;
# HSTS (ngx_http_headers_module is required) (15768000 seconds = 6 months)
add_header Strict-Transport-Security max-age=15768000;
location /freeoa {
proxy_pass http://freeoa;
proxy_set_header Host $host:$server_port;
proxy_set_header X-Forwarded-Host $server_name;
proxy_set_header proxy_x_forward_ip $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Port $server_port;
proxy_http_version 1.1;
proxy_set_header Connect "";
}
}
后面会时不时出现这个报错:no live upstreams while connecting to upstreams
从字面上看,就是没有可用的负载节点。没有负载节点? 其实无非就是下面两个原因:
负载节点down掉了
nginx任务负载节点不可用
负载节点有没有down掉可以很容易验证,而且我们的负载节点已经验证过是完全可靠的,只不过业务峰值的请求量超过了单线程处理时的最大能力,所以才在前面搭建了nginx作为负载均衡节点。那就剩下为什么nginx会认为负载节点不可用。期间有人提到,会不会是tcp连接队列太小了,导致nginx任务负载节点连接出了问题,会间歇性地出现502错误。
默认情况下,当一个节点出错时,nginx会将当前节点自动设置成down状态,及新的请求不会下发到当前节点,在一段时间后,重新上线该节点。当某个请求导致了nginx的所有负载节点均返回了失败的结果,nginx将所有节点下线,所以新的请求到来时就会没有负载可用,便返回错误;而过段时间后,节点尝试上线,业务恢复。可设置忽略负载节点错误max_fail=0,让业务运行正常,不再出现上述的无可用节点的错误。
连接建立
网上有非常多的tcp连接队列的讲解和配置。不过中文的blog其实都是大家相互转载和借鉴,真正付诸实践的文章就那么几篇。但是每个人遇到的情况肯定是不同的,所以也不能单纯按照网上的文章去碰运气,还是要彻底搞清楚底层的原理,才能对自己的问题有所帮助。
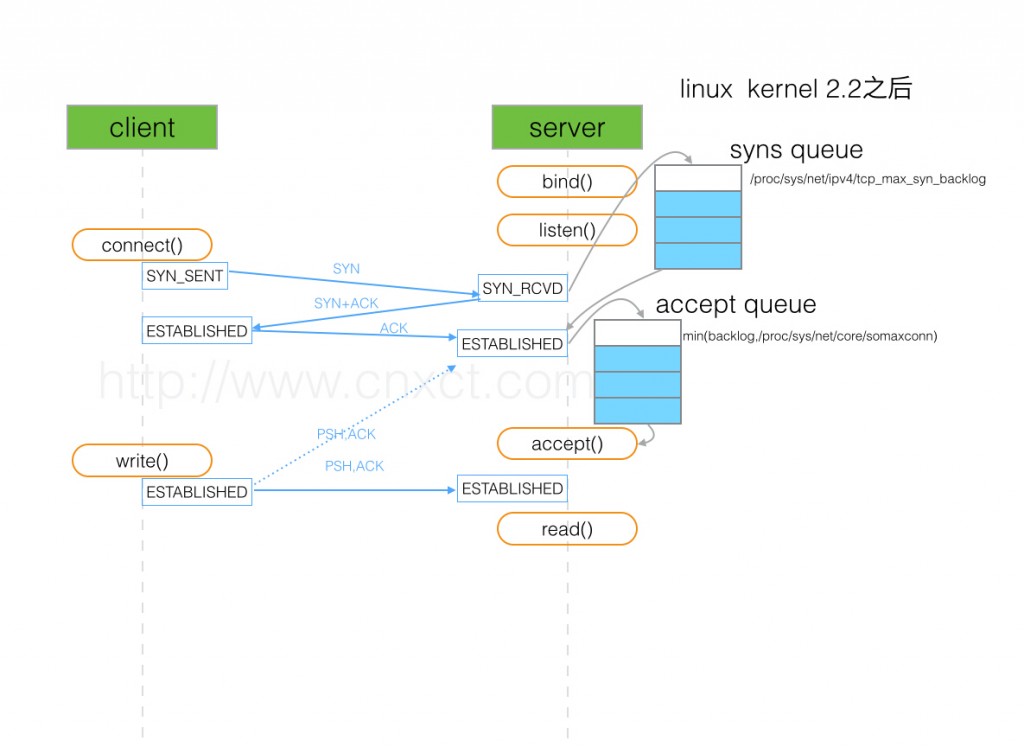
当server收到syn后,在系统底层,就把一个tcp连接,放到了半连接队列(syns queue)中,等到收到client回复的ack后,将其从半连接队列移入全连接队列(accept queue)。所以就有了针对半连接队列的攻击,即如果server收不到client回复的ack,那么半连接队列就有被占满的可能,也就是syn flood攻击。
当TCP连接被放入到accept queue中后,要等待上层的应用把这个连接取走(accpet),上层应用取走一个连接后,全连接队列就空出来一个位置。所以全连接队列数*不等于*established数
连接关闭
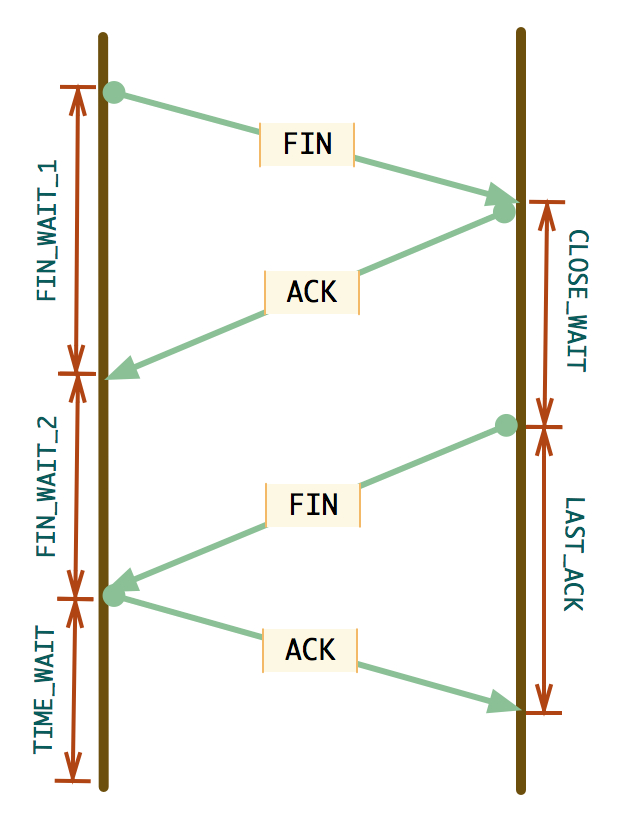
这里介绍了在一个连接关闭时的全过程,图中已经画的非常详细了。
TCP队列溢出及丢弃
回到我们分析问题的路上,既然TCP有两个队列,就存在溢出的可能,我们怎么确定是否队列有溢出呢?
执行下面的两个命令都可以查看TCP的连接队列是否有异常:
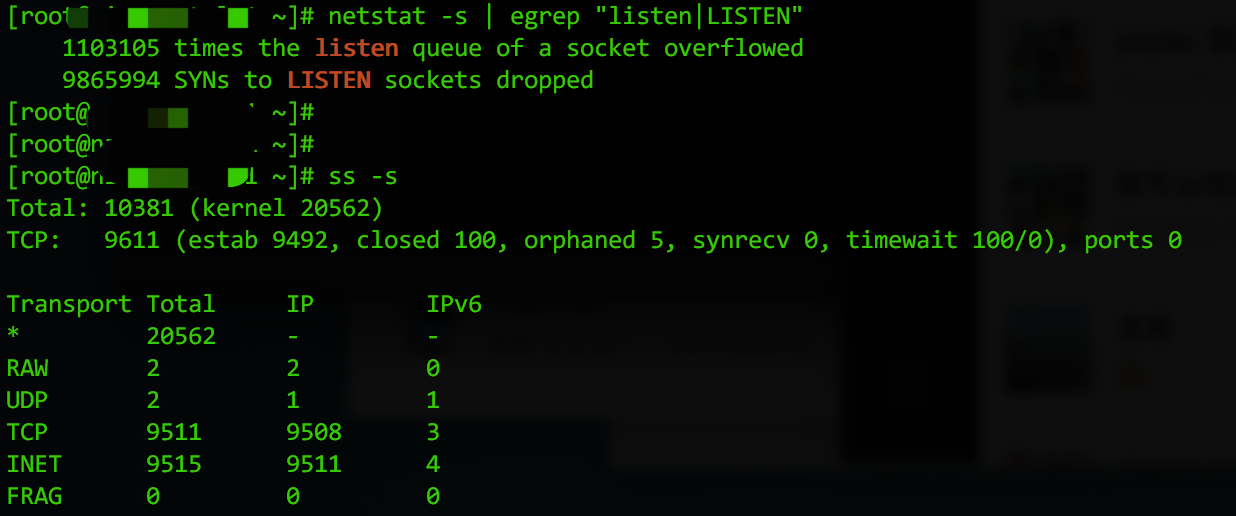
# netstat -s | egrep "listen|LISTEN"
或者
# ss -s
理论上,ss命令和netstat都可以显示tcp连接的分析统计,但是笔者猜测,netstat看到的应该是从服务器启动到现在的所有记录,即其结果是不清零的,而ss -s命令则是有一个时间统计区间的,所以上图中,只有netstat命令显示了很多半连接队列溢出或全连接队列丢弃的统计,而ss -s命令则只显示了当前的socket队列连接情况,因为上次调优后,没有出现tcp队列溢出的情况了,所以ss就显示正常的结果。
$ netstat -n | awk '/^tcp/ {++state[$NF]} END {for(key in state) print key,"\t",state[key]}'
既然TCP连接队列长度不够,我们就需要调整其长度。
半连接队列的最大值取决于:max(/proc/sys/net/ipv4/tcp_max_syn_backlog),默认为512;当启用syncookies时,没有逻辑最大长度,忽略tcp_max_syn_backlog设置,syncookies的设置可以防范SYN flood攻击。所以只要我们启用了syncookies,则队列长度即可忽略,而且现在基本上可以通过防火墙来防范syn flood攻击。
全连接队列的最大值取决于:min(backlog, /proc/sys/net/core/somaxconn),在linux内核2.2版本以后,backlog参数控制的accept queue的大小,backlog是在socket创建的时候传入的,属于listen函数里的参数;somaxconn是内核的参数,默认是128
所以,我们的重点就在于调整全连接队列长度,backlog是由应用程序在创建监听时传入的,nginx这个值默认是511,至于java和C程序都可以通过相关函数来设置backlog值;而somaxconn是通过net.core.somaxconn参数来设置的,默认是128。
来看一下经过系统调优和nginx参数优化(调优过程参见此链接)后的全连接队列数:
执行下列语句(ss 参数说明: -l 显示监听 -n忽略主机名 -t仅显示tcp -4 ipv4协议)
# ss -lnt -4
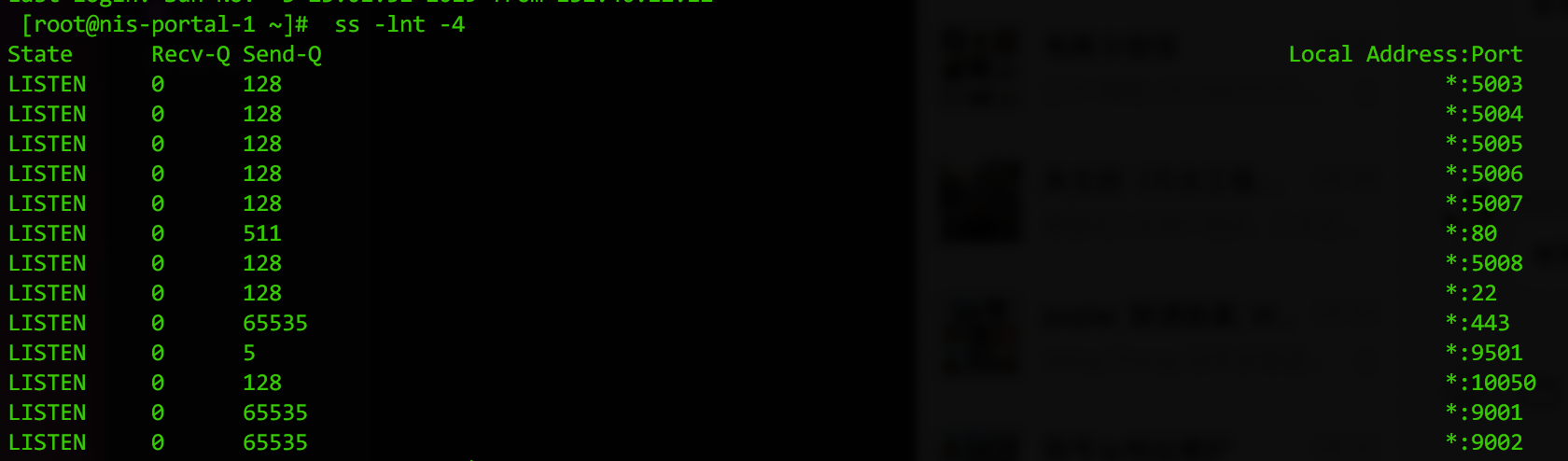
如上图显示,Recv-Q就是当前TCP队列中的数量,当上层应用取TCP连接取的足够快时,队列都是空的;Send-Q是队列总长度。可以看到nginx监听的443端口上已经调优到了65535。
之前一直纠结为何ss统计后的ESTABLISHED连接数量要远远大于监听时设置的128默认全连接队列长度,后来终于在这个StackOverFlow的回答中找到了答案。
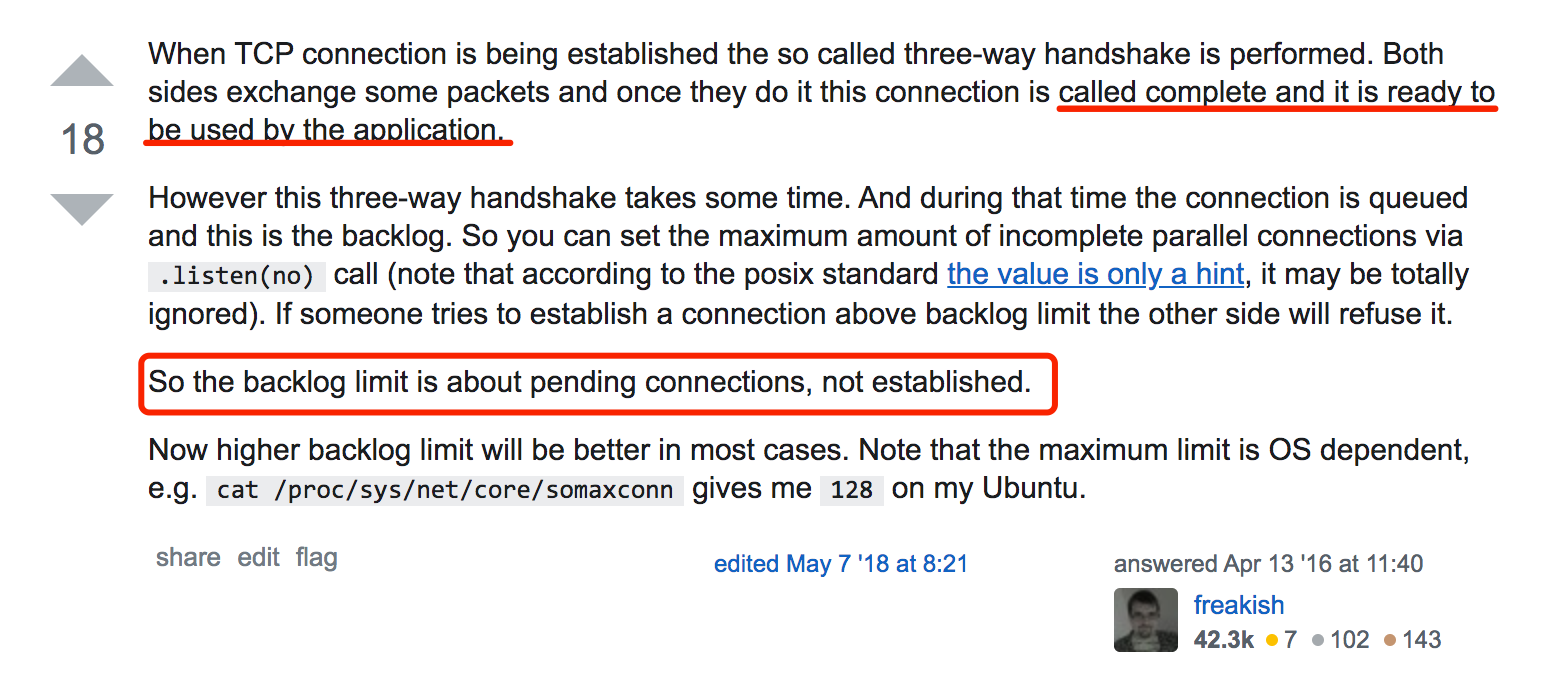
在解决这个问题的过程中,也顺带了解了一些其他有用的知识,比如ESTABLISHED连接的时间状态,tcp keepalive的开启机制等等。
我们执行下面的命令:
# netstat -apno | grep ESTAB | head
在最后一列,因为加入了-o命令,所以会显示ESTABLISHED连接的检测时间。
keepalive - when the keepalive timer is ON for the socket
on - when the retransmission timer is ON for the socket
off - none of the above is ON
我们可以通过这个值,看到每个连接检测的时间,如果想要使用keepalive,必须在客户端发起socket连接时,显示地声明keepalive才行。笔者的服务端看到的ESTABLISHED连接,基本都是off状态,即没有任何时间检测,一旦因为网络问题,比如防火墙直接掐掉了这些连接,这些连接就会变成不可用的假连接。
可以参见这个问题的讨论:Too many established connections left open
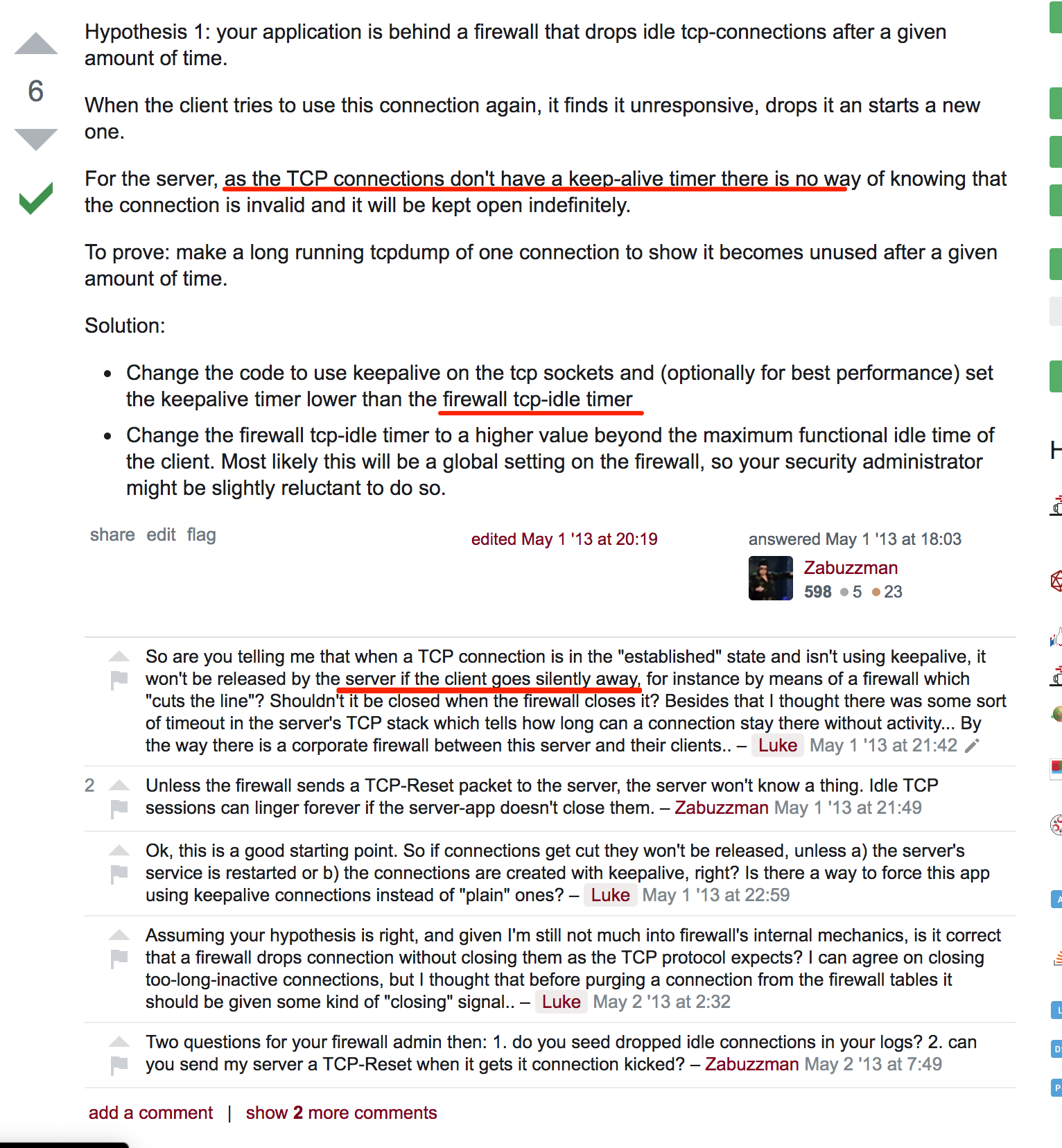
写在最后,这次Trouble Shooting过程中,发现了很多内容都是许多年前的了,比如tcp_tw_recycle这个参数,还有不少文章推荐打开,其实对现代服务器,节省的那点资源,基本上可以忽略不计,所以解决问题还要靠自己对很多基础知识的深入了解。解决这个问题,前后研究TCP状态,研究Nginx配置,研究backlog参数等等,其实花费了很长的时间。只有如此,才能真正做到触类旁通,而不是停留在病急乱投医地状态。
最后跟作者一样,附上所参考的相关文章链接,感谢原作者。
参考链接
TCP connection status
TIME_WAIT状态实验分析
TCP的半连接队列与全连接队列
关于TCP半连接队列和全连接队列
调整Linux内核参数进行TCP性能调优
What is "backlog" in TCP connections?