调整Linux内核参数进行TCP性能调优
 TCP/IP协议对网络编程的重要性,进行过网络开发的人员都知道,我们所编写的网络程序除了硬件,结构等限制,通过修改tcp/ip内核参数也能得到很大的性能提升。下面就列举一些tcp/ip内核参数,解释它们的含义并通过修改来它们来优化我们的网络程序,主要是针对高并发情况。这里网络程序主要指的是服务器端。
TCP/IP协议对网络编程的重要性,进行过网络开发的人员都知道,我们所编写的网络程序除了硬件,结构等限制,通过修改tcp/ip内核参数也能得到很大的性能提升。下面就列举一些tcp/ip内核参数,解释它们的含义并通过修改来它们来优化我们的网络程序,主要是针对高并发情况。这里网络程序主要指的是服务器端。1. fs.file-max
最大可以打开的文件描述符数量,注意是整个系统。
在服务器中,我们知道每创建一个连接,系统就会打开一个文件描述符,所以文件描述符打开的最大数量也决定了我们的最大连接数select在高并发情况下被取代的原因也是文件描述符打开的最大值,虽然它可以修改但一般不建议这么做。这个参数虽然是系统级别的,却与网络处理能力非常相关。
可使用ulimit命令查看系统允许当前用户进程打开的文件数限制:
# ulimit -n
1024
这表示当前用户的每个进程最多允许同时打开1024个文件,这1024个文件中还得除去每个进程必然打开的标准输入,标准输出,标准错误,服务器监听 socket,进程间通讯的unix域socket等文件,那么剩下的可用于客户端socket连接的文件数就只有大概1024-10=1014个左右。也就是说缺省情况下,基于Linux的通讯程序最多允许同时1014个TCP并发连接。
对于想支持更高数量的TCP并发连接的通讯处理程序,就必须修改Linux对当前用户的进程同时打开的文件数量的软限制(soft limit)和硬限制(hardlimit)。其中软限制是指Linux在当前系统能够承受的范围内进一步限制用户同时打开的文件数;硬限制则是根据系统硬件资源状况(主要是系统内存)计算出来的系统最多可同时打开的文件数量,通常软限制小于或等于硬限制。修改上述限制的最简单的办法就是使用ulimit命令:
# ulimit -n
上述命令中,在中指定要设置的单一进程允许打开的最大文件数。如果系统回显类似于"Operation notpermitted"之类的话,说明上述限制修改失败,实际上是因为在中指定的数值超过了Linux系统对该用户打开文件数的软限制或硬限制。因此就需要修改Linux系统对用户的关于打开文件数的软限制和硬限制。
第一步,修改/etc/security/limits.conf文件,在文件中添加如下行:
freeoa soft nofile 10240
freeoa hard nofile 10240
其中freeoa指定了要修改哪个用户的打开文件数限制,可用'*'号表示修改所有用户的限制;soft或hard指定要修改软限制还是硬限制;10240则指定了想要修改的新的限制值,即最大打开文件数(请注意软限制值要小于或等于硬限制),修改完后保存文件。
第二步,修改/etc/pam.d/login文件,在文件中添加如下行:
session required /lib/security/pam_limits.so
这是告诉Linux在用户完成系统登录后,应该调用pam_limits.so模块来设置系统对该用户可使用的各种资源数量的最大限制(包括用户可打开的最大文件数限制),而pam_limits.so模块就会从/etc/security/limits.conf文件中读取配置来设置这些限制值。修改完后保存此文件。
第三步,查看Linux系统级的最大打开文件数限制,使用如下命令:
# cat /proc/sys/fs/file-max
1628899
这表明这台Linux系统最多允许同时打开(即包含所有用户打开文件数总和)1628899个文件,是Linux系统级硬限制,所有用户级的打开文件数限制都不应超过这个数值。通常这个系统级硬限制是Linux系统在启动时根据系统硬件资源状况计算出来的最佳的最大同时打开文件数限制,如果没有特殊需要,不应该修改此限制,除非想为用户级打开文件数限制设置超过此限制的值。修改此硬限制的方法是修改/etc/rc.local脚本,在脚本中添加如下行:
# echo 1628900 > /proc/sys/fs/file-max
这是让Linux在启动完成后强行将系统级打开文件数硬限制设置为1628900,修改完后保存此文件。完成上述步骤后重启系统,一般情况下就可以将Linux系统对指定用户的单一进程允许同时打开的最大文件数限制设为指定的数值。如果重启后用 ulimit-n命令查看用户可打开文件数限制仍然低于上述步骤中设置的最大值,这可能是因为在用户登录脚本/etc/profile中使用ulimit -n命令已经将用户可同时打开的文件数做了限制。由于通过ulimit-n修改系统对用户可同时打开文件的最大数限制时,新修改的值只能小于或等于上次 ulimit-n设置的值,因此想用此命令增大这个限制值是不可能的。如果有上述问题存在,就只能去打开/etc/profile脚本文件,在文件中查找是否使用了ulimit-n限制了用户可同时打开的最大文件数量,如果找到,则删除这行命令,或者将其设置的值改为合适的值,然后保存文件,用户退出并重新登录系统即可。
通过上述步骤,就为支持高并发TCP连接处理的通讯处理程序解除关于打开文件数量方面的系统限制。
2.net.ipv4.tcp_max_syn_backlog
Tcp syn队列的最大长度,在进行系统调用connect时会发生Tcp的三次握手,server内核会为Tcp维护两个队列,Syn队列和Accept队列,Syn队列是指存放完成第一次握手的连接,Accept队列是存放完成整个Tcp三次握手的连接,修改net.ipv4.tcp_max_syn_backlog使之增大可以接受更多的网络连接。
注意:此参数过大可能遭遇到Syn flood攻击,即对方发送多个Syn报文端填充满Syn队列,使server无法继续接受其他连接。
我们看下 man 手册上是如何说的:
The behavior of the backlog argument on TCP sockets changed with Linux 2.2. Now it specifies the queue length for completely established sockets waiting to be accepted, instead of the number of incomplete connection requests. The maximum length of the queue for incomplete sockets can be set using /proc/sys/net/ipv4/tcp_max_syn_backlog. When syncookies are enabled there is no logical maximum length and this setting is ignored. See tcp(7) for more information.
If the backlog argument is greater than the value in /proc/sys/net/core/somaxconn, then it is silently truncated to that value; the default value in this file is 128. In kernels before 2.4.25, this limit was a hard coded value, SOMAXCONN, with the value 128.
自 Linux 内核 2.2 版本以后,backlog 为已完成连接队列的最大值,未完成连接队列大小以 /proc/sys/net/ipv4/tcp_max_syn_backlog 确定,但是已连接队列大小受 SOMAXCONN 限制,为 min(backlog, SOMAXCONN)
3.net.ipv4.tcp_syncookies
修改此参数可以有效的防范上面所说的syn flood攻击。
原理:在Tcp服务器收到Tcp Syn包并返回Tcp Syn+ack包时,不专门分配一个数据区,而是根据这个Syn包计算出一个cookie值。在收到Tcp ack包时,Tcp服务器在根据那个cookie值检查这个Tcp ack包的合法性。如果合法,再分配专门的数据区进行处理未来的TCP连接。
默认为0,1表示开启。
4.net.ipv4.tcp_keepalive_time
Tcp keepalive心跳包机制,用于检测连接是否已断开,可以修改默认时间来间断心跳包发送的频率。
keepalive一般是服务器对客户端进行发送查看客户端是否在线,因为服务器为客户端分配一定的资源,但是Tcp 的keepalive机制很有争议,因为它们可耗费一定的带宽。
Tcp keepalive详情见Tcp/Ip详解卷1-第23章
5.net.ipv4.tcp_tw_reuse
针对time_wait状态,大量处于time_wait状态是很浪费资源的,它们占用server的描述符等。
修改此参数,允许重用处于time_wait的socket。
默认为0,1表示开启。
6.net.ipv4.tcp_tw_recycle
也是针对time_wait状态的,该参数表示快速回收处于time_wait的socket。
默认为0,1表示开启。
7.net.ipv4.tcp_fin_timeout
修改time_wait状的存在时间,默认的2MSL。
注意:time_wait存在且生存时间为2MSL是有原因的,所以修改它有一定的风险,还是根据具体的情况来分析。
8.net.ipv4.tcp_max_tw_buckets
所允许存在time_wait状态的最大数值,超过则立刻被清楚并且警告。
9.net.ipv4.ip_local_port_range
表示对外连接的端口范围。
10.net.core.somaxconn
前面说了Syn队列的最大长度限制,somaxconn参数决定Accept队列长度,在listen函数调用时backlog参数即决定Accept队列的长度,该参数太小也会限制最大并发连接数,因为同一时间完成3次握手的连接数量太小,server处理连接速度也就越慢。服务器端调用accept函数实际上就是从已连接Accept队列中取走完成三次握手的连接。Accept队列和Syn队列是listen函数完成创建维护的。可修改/proc/sys/net/core/somaxconn的值来完成。
对于一个TCP连接,Server与Client需要通过三次握手来建立网络连接,当三次握手成功后我们可以看到端口的状态由LISTEN转变为ESTABLISHED,接着这条链路上就可以开始传送数据了。每一个处于监听(Listen)状态的端口,都有自己的监听队列,监听队列的长度,与如下两方面有关:
- somaxconn参数.
- 使用该端口的程序中listen()函数.
关于somaxconn参数:它定义了系统中每一个端口最大的监听队列的长度,这是个全局的参数,默认值为128,这限制了每个端口接收新tcp连接侦听队列的大小。对于一个经常处理新连接的高负载 web服务环境来说,默认的 128 太小了,大多数环境这个值建议增加到 1024 或者更多。服务进程会自己限制侦听队列的大小(例如 sendmail(8) 或者 Apache),常常在它们的配置文件中有设置队列大小的选项。较大的侦听队列对防止拒绝服务 DoS 攻击也会有所帮助。
上面每一个参数其实都够写一篇文章来分析了,这里只是概述下部分参数,注意在修改Tcp参数时我们一定要根据自己的实际需求以及测试结果来决定,文章后面还会对这些参数进行解析,因为它们太重要了。
修改网络内核对TCP连接的有关限制
在Linux上编写支持高并发TCP连接的客户端通讯处理程序时,有时会发现尽管已经解除了系统对用户同时打开文件数的限制,但仍会出现并发TCP连接数增加到一定数量时,再也无法成功建立新的TCP连接的现象。出现这种现在的原因有多种。
第一种原因可能是因为Linux网络内核对本地端口号范围有限制。此时,进一步分析为什么无法建立TCP连接,会发现问题出在connect()调用返回失败,查看系统错误提示消息是"Can't assign requestedaddress"。同时,如果在此时用tcpdump工具监视网络,会发现根本没有TCP连接时客户端发SYN包的网络流量,这些情况说明问题在于本地Linux系统内核中有限制。其实,问题的根本原因在于Linux内核的TCP/IP协议实现模块对系统中所有的客户端TCP连接对应的本地端口号的范围进行了限制(例如,内核限制本地端口号的范围为1024~32768之间)。
当系统中某一时刻同时存在太多的TCP客户端连接时,由于每个TCP客户端连接都要占用一个唯一的本地端口号(此端口号在系统的本地端口号范围限制中),如果现有的TCP客户端连接已将所有的本地端口号占满,则此时就无法为新的TCP客户端连接分配一个本地端口号了,因此系统会在这种情况下在connect()调用中返回失败,并将错误提示消息设为"Can't assign requestedaddress"。有关这些控制逻辑可以查看Linux内核源代码,以linux2.6内核为例,可以查看tcp_ipv4.c文件中如下函数:
static int tcp_v4_hash_connect(struct sock *sk)
请注意上述函数中对变量sysctl_local_port_range的访问控制,变量sysctl_local_port_range的初始化则是在tcp.c文件中的如下函数中设置:
void __init tcp_init(void)
内核编译时默认设置的本地端口号范围可能太小,因此需要修改此本地端口范围限制。
修改/etc/sysctl.conf文件,在文件中添加如下行:
net.ipv4.ip_local_port_range = 1024 65000
这表明将系统对本地端口范围限制设置为1024~65000之间。请注意,本地端口范围的最小值必须大于或等于1024;而端口范围的最大值则应小于或等于65535,修改完后保存此文件。
执行sysctl命令让其立即生效:# sysctl -p
如果系统没有错误提示,就表明新的本地端口范围设置成功。如果按上述端口范围进行设置,则理论上单独一个进程最多可以同时建立60000多个TCP客户端连接。
第二种无法建立TCP连接的原因可能是因为Linux网络内核的IP_TABLE防火墙对最大跟踪的TCP连接数有限制。此时程序会表现为在 connect()调用中阻塞,如同死机,如果用tcpdump工具监视网络,也会发现根本没有TCP连接时客户端发SYN包的网络流量。由于 IP_TABLE防火墙在内核中会对每个TCP连接的状态进行跟踪,跟踪信息将会放在位于内核内存中的conntrackdatabase中,这个数据库的大小有限,当系统中存在过多的TCP连接时,数据库容量不足,IP_TABLE无法为新的TCP连接建立跟踪信息,于是表现为在connect()调用中阻塞。此时就必须修改内核对最大跟踪的TCP连接数的限制,方法同修改内核对本地端口号范围的限制是类似的:
修改/etc/sysctl.conf文件,在文件中添加如下行:
net.ipv4.ip_conntrack_max = 10240
这表明将系统对最大跟踪的TCP连接数限制设置为10240。请注意,此限制值要尽量小,以节省对内核内存的占用。
执行sysctl命令让其立即生效:# sysctl -p
如果系统没有错误提示,就表明系统对新的最大跟踪的TCP连接数限制修改成功。如果按上述参数进行设置,则理论上单独一个进程最多可以同时建立10000多个TCP客户端连接。
使用支持高并发网络I/O的编程技术
在Linux上编写高并发TCP连接应用程序时,必须使用合适的网络I/O技术和I/O事件分发机制。
可用的I/O技术有同步I/O,非阻塞式同步I/O(也称反应式I/O),以及异步I/O。在高TCP并发的情形下,如果使用同步I/O,这会严重阻塞程序的运转,除非为每个TCP连接的I/O创建一个线程。但是,过多的线程又会因系统对线程的调度造成巨大开销。因此,在高TCP并发的情形下使用同步 I/O是不可取的,这时可以考虑使用非阻塞式同步I/O或异步I/O。非阻塞式同步I/O的技术包括使用select(),poll(),epoll等机制。异步I/O的技术就是使用AIO。
从I/O事件分发机制来看,使用select()是不合适的,因为它所支持的并发连接数有限(通常在1024个以内)。如果考虑性能,poll()也是不合适的,尽管它可以支持的较高的TCP并发数,但是由于其采用“轮询”机制,当并发数较高时,其运行效率相当低,并可能存在I/O事件分发不均,导致部分TCP连接上的I/O出现“饥饿”现象。而如果使用epoll或AIO,则没有上述问题(早期Linux内核的AIO技术实现是通过在内核中为每个 I/O请求创建一个线程来实现的,这种实现机制在高并发TCP连接的情形下使用其实也有严重的性能问题。但在最新的Linux内核中,AIO的实现已经得到改进)。
综上所述,在开发支持高并发TCP连接的Linux应用程序时,应尽量使用epoll或AIO技术来实现并发的TCP连接上的I/O控制,这将为提升程序对高并发TCP连接的支持提供有效的I/O保证。当然系统在各个方面都需要配合调整才能发挥出整体优化,因此对系统及内核的参数调整也是必要的,故这些参数都是需要注意的:
1.vm.swappiness:该参数控制系统在内存不足时,内核将页面交换到磁盘的程度。默认值为60,建议值为10-30。
2.vm.overcommit_memory:该参数控制系统是否允许超额分配内存。默认值为0,建议值为1。
3.vm.dirty_ratio:该参数控制系统脏页占内存的比例。默认值为20,建议值为5-10。
4.vm.dirty_background_ratio:该参数控制系统后台写入脏页的比例。默认值为10,建议值为1-5。
5.vm.dirty_expire_centisecs:该参数控制系统脏页过期时间。默认值为3000,建议值为1000-2000。
6.vm.dirty_writeback_centisecs:该参数控制系统写回脏页的时间间隔。默认值为500,建议值为100-200。
7.vm.vfs_cache_pressure:该参数控制系统内核缓存的大小和清理频率。默认值为100,建议值为50-100。
8.vm.min_free_kbytes:该参数控制系统保留的最小空闲内存。默认值为4096,建议值为65536。
9.vm.max_map_count:该参数控制系统允许的最大内存映射数量。默认值为65530,建议值为262144。
10.net.core.somaxconn:该参数控制系统TCP连接的最大排队数量。默认值为128,建议值为1024。
11.net.core.netdev_max_backlog:该参数控制系统网络设备接收数据包的队列大小。默认值为1000,建议值为5000。
12.net.core.rmem_max:该参数控制系统TCP接收缓冲区的最大大小。默认值为212992,建议值为524288。
13.net.core.wmem_max:该参数控制系统TCP发送缓冲区的最大大小。默认值为212992,建议值为524288。
14.net.ipv4.tcp_fin_timeout:该参数控制系统TCP连关闭的超时时间。默认值为60,建议值为10-20。
15.net.ipv4.tcp_tw_reuse:该参数控制系统是否允许重用TIME_WAIT状态的TCP连接。默认值为O,建议值为1。
16.net.ipv4.tcp_tw_recycle:该参数控制系统是否启用TCP连接回收机制。默认值为0,建议值为1。
17.net.ipv4.tcp_max_syn_backlog:该参数控制系统TCP连接请求队列的大小。默认值为128,建议值为1024。
18.net.ipv4.tcp_keepalive_time:该参数控制系统TCP连接的保持时间。默认值为7200秒,建议值为600-1200。
19.net.ipv4.tcp_max_tw_buckets:该参数控制系统可以处理的TIME_WAIT状态的TCP连接的最大数量。默认值为180000,建议值为262144。
20.net.ipv4.ip_local_port_range:该参数控制系统可以使用的本地端口范围。默认值为32768-61000,建议值为1024-65535。
21.net.ipv4.tcp_slow_start_after_idle:该参数控制系统TCP连接空闲一段时间后是否重新进入慢启动状态。默认值为1,建议值为0。
22.net.ipv4.tcp_no_metrics_save:该参数控制系统是否保存TCP连接的性能指标。默认值为0,建议值为1。
23.net.ipv4.tcp_mtu_probing:该参数控制系统是否启用TCPMTU探测。默认值为0,建议值为1。
24.net.ipv4.tcp_congestion_control:该参数控制系统TCP拥塞控制算法。默认值为cubic,建议值为bbr。
25.fs.file-max:该参数控制系统可以打开的文件句柄数量。默认值为65536,建议值为1048576。
26.fs.nr_open:该参数控制系统可以打开的文件句柄数量。默认值为1048576,建议值为1048576。
27.fs.inotify.max_user_watches:该参数控制系统可以监视的文件数量。默认值为8192,建议值为524288。
28.kernel.sem:该参数控制系统信号量的数量。默认值为250,建议值为512-1024。
29.kernel.shmmax:该参数控制系统的共享内存大小。默认值为4294967295,建议值为536870912。
30.kernel.shmall:该参数控制系统的共享内存大小。默认值为2097152,建议值为134217728。
31.kernel.pid_max:该参数控制系统可以创建的最大进程数。默认值为32768,建议值为524288。
32.kernel.core_pattern:该参数控制系统在出现核心转储文件时的文件名格式。默认值为core,建议值为/corefiles/core-%e-%s-%u-%g-%p-%t。
33.kernel.msgmnb:该参数控制系统消息队列的最大大小。默认值为16384,建议值为65536。
34.kernel.msgmax:该参数控制系统消息队列的最大大小。默认值为8192,建议值为65536。
35.kernel.sysrq:该参数控制系统是否允许使用SysRq键。
接下来就较为详细地介绍这些配置及参数
用户级进程的打开文件数限制(ulimit -a)
vim /etc/security/limits.conf
* hard nproc 65535
* soft nproc 65535
* hard nofile 65535
* soft nofile 65535
要修改的就是nofile这两个配置,hard表示当前可以设置的最大值,soft表示当前的值,可把这两个值改成比如500000,单机50万的并发连接基本也到nginx的极限了。
注:nofile的最大值不能超过/proc/sys/fs/nr_open这个值,默认是(1048576)
完成后再次执行ulimit -a查看是否生效了。
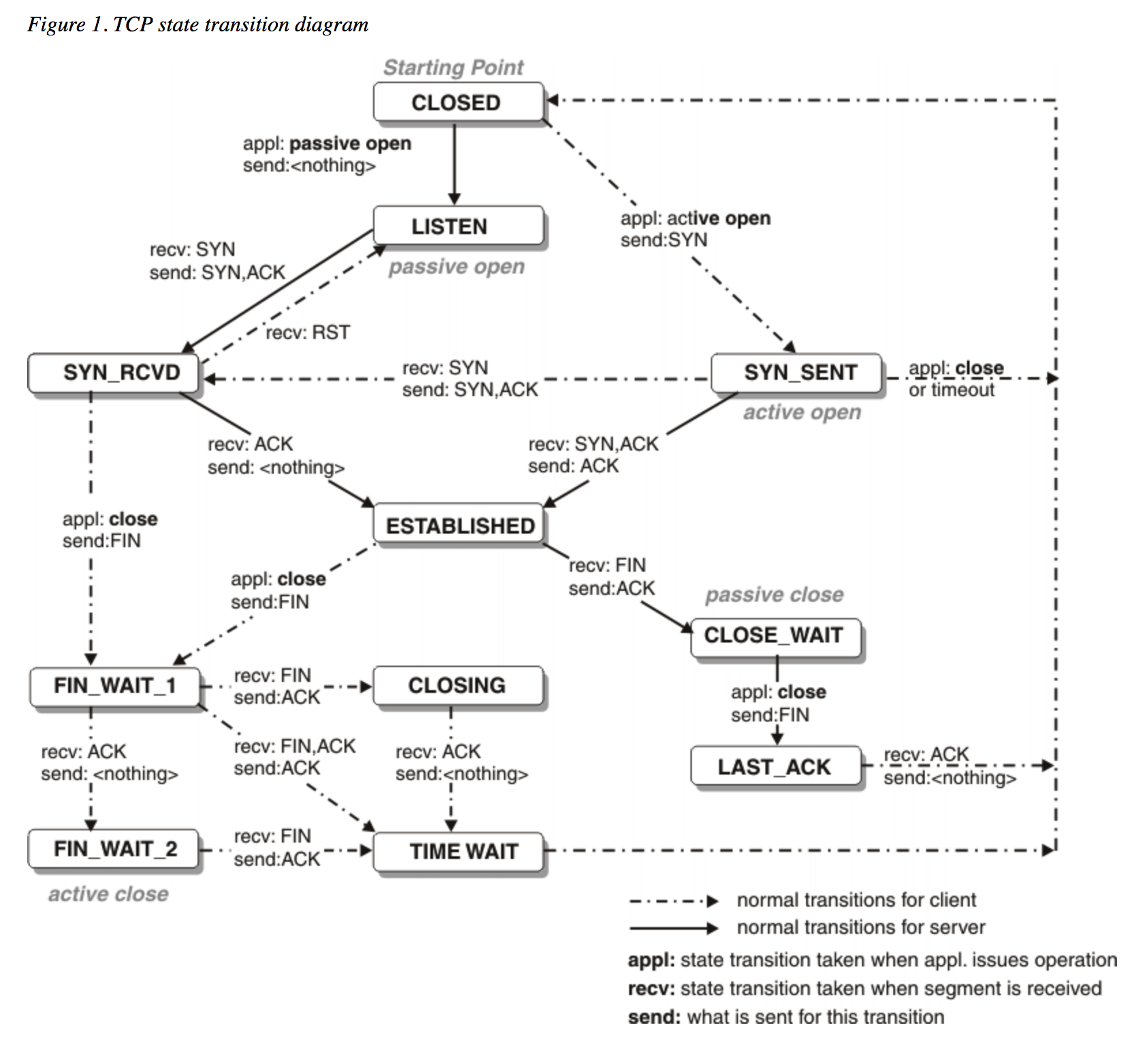
注:有些服务器因为系统配置原因,可能通过ssh登录时无法看到生效信息,可以通过配置/etc/ssh/sshd_config中的UsePAM 和 UseLogin参数来实现。在其配置文件中修改或添加UsePAM yes和UseLogin yes,然后重新登录ssh即可。在正式开始介绍前,我们先来看一下那幅经典的状态转换图:
查看一下服务器上的TCP连接的总情况:
# netstat -n | awk '/^tcp/ {++state[$NF]} END {for(key in state) print key,"\t",state[key]}'
查看tcp网络相关的系统参数
# sysctl -a|grep net.ipv4.tcp
由于默认的linux内核参数考虑的是最通用场景,这明显不符合用于支持高并发访问的Web服务器的定义,所以需要修改Linux内核参数,是的Nginx可以拥有更高的性能;在优化内核时,可以做的事情很多,不过我们通常会根据业务特点来进行调整;当Nginx作为静态web内容服务器、反向代理或者提供压缩服务器的服务器时,内核参数的调整都是不同的,这里针对最通用的、使Nginx支持更多并发请求的TCP网络参数做简单的配置。
首先需要修改 /etc/sysctl.conf 来更改内核参数。
Linux内核参数默认考虑的是最通用的场景,但是在高并发的web服务器上,这个不太适用。所以需要根据实际的业务特点来进行调整,提高Nginx的并发性能。如下是几个比较关键的参数。我们可以通过修改/etc/sysctl.conf来修改内核参数。
增大套接字读写缓存
读缓冲区,缓存了远端发送过来的数据。如果读缓冲区已满,就不能再接收新的数据
写缓冲区,缓存了要发出去的数据。如果缓冲区已满,应用程序的写操作就会阻塞
所以为了提高网络的吞吐量,通常要调整这些缓冲区大小。
套接字内核选项列表
套接字优化方法 内核选项 参考设置
增大每个套接字的缓冲区大小 net.core.optmem_max 81920
增大套接字接收缓冲区大小 net.core.rmem_max 513920
增大套接字发送缓冲区大小 net.core.wmem_max 513920
增大TCP接收缓冲区范围 net.ipv4.tcp_rmem 4096 87380 16777216
增大TCP发送缓冲区范围 net.ipv4.tcp_wmem 4096 65536 16777216
增大UDP缓冲区范围 net.ipv4.udp_mem 188562 251418 377124
一些重要的参数简介,上文有过一些介绍,它们太常见和重要了。
fs.file-max = 999999
表示单个进程最大可以打开的句柄数。
net.ipv4.tcp_tw_reuse = 1
参数设置为 1 表示开启重用。表示允许将TIME_WAIT状态的socket重新用于新的TCP链接,这对于服务器来说意义重大,因为总有大量TIME_WAIT状态的链接存在;默认为0,表示关闭。开启重用功能,允许将TIME-WAIT状态的sockets重新用于新的TCP链接。设置为1,表示允许将TIME-WAIT状态的socket重新用于新的TCP连接,这意味着服务器总会有大量的TIME_WAIT状态的连接存在。
net.ipv4.tcp_keepalive_time = 600
当keepalive启动时,TCP发送keepalive消息的频度;默认是2小时,将其设置为10分钟,可以更快的清理无效链接。
net.ipv4.tcp_fin_timeout = 30
当服务器主动关闭链接时,socket保持在FIN_WAIT_2状态的最大时间。即如果套接字由本端要求关闭,它将决定保持在FIN-WAIT-2状态的时间。
net.ipv4.tcp_max_tw_buckets = 9999
这个参数表示操作系统允许TIME_WAIT套接字数量的最大值,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。该参数默认为180000,过多的TIME_WAIT套接字会使Web服务器变慢。对于Apache、Nginx等服务器,上几行的参数可以很好地减少TIME_WAIT套接字数量,但是对于Squid,效果却不大。此项参数可以控制TIME_WAIT套接字的最大数量,避免Squid服务器被大量的TIME_WAIT套接字拖累。
net.ipv4.ip_local_port_range = 4096 65000
定义UDP和TCP链接的本地端口的取值范围。缺省情况下很小:32768到61000。
net.ipv4.tcp_rmem = 10240 87380 12582912
定义了TCP接受缓存的最小值、默认值、最大值。
net.ipv4.tcp_wmem = 10240 87380 12582912
定义TCP发送缓存的最小值、默认值、最大值。
net.core.netdev_max_backlog = 8196
当网卡接收数据包的速度大于内核处理速度时,会有一个列队保存这些数据包。这个参数表示该列队的最大值。
net.core.rmem_default = 6291456
表示内核套接字接受缓存区默认大小。
net.core.wmem_default = 6291456
表示内核套接字发送缓存区默认大小。
net.core.rmem_max = 12582912
表示内核套接字接受缓存区最大大小。
net.core.wmem_max = 12582912
表示内核套接字发送缓存区最大大小。
注意:以上的几个参数,需要根据业务逻辑和实际的硬件成本来综合考虑。
net.ipv4.tcp_syncookies = 1
与性能无关,用于解决TCP的SYN攻击。表示开启SYN Cookies,当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭。
net.ipv4.tcp_max_syn_backlog = 8192
这个参数表示TCP三次握手建立阶段接受SYN请求列队的最大长度,默认1024,加大队列长度为8192;将其设置的大一些可以使出现Nginx繁忙来不及accept新连接的情况时,Linux不至于丢失客户端发起的链接请求,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_tw_recycle = 1
表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。开启即启用timewait快速回收。
net.core.somaxconn=262114
选项默认值是128,这个参数用于调节系统同时发起的TCP连接数,在高并发的请求中,默认的值可能会导致链接超时或者重传,因此需要结合高并发请求数来调节此值。
net.ipv4.tcp_max_orphans=262114
选项用于设定系统中最多有多少个TCP套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤立链接将立即被复位并输出警告信息。这个限制指示为了防止简单的DOS攻击,不用过分依靠这个限制甚至认为的减小这个值,更多的情况是增加这个值。
Time Wait 控制的相关参数
net.ipv4.tcp_tw_recycle
recycle可以加快tcp连接的回收速度,但是recycle这个值的使用很容易出现问题,尤其在NAT的环境下,很多正常的连接会被丢弃。原理是当连接被很快复用后,从不同的服务器发来的请求,会被认为是从通一个remote过来的连接,但是这些服务器的时间戳是不一样的,就很容易被server认为tcp包序乱而丢弃掉。从client看来就是很多连接超时了没有响应。所以这个值保险起见,都设置成0,即不启用。之前的内容也提到了,作为server,只要它和后端的负载节点之间是长连接,就不会出现很多time_wait的连接。而作为server,被动连接进来的time_wait的tcp连接并不会占用server本身的资源。
net.ipv4.tcp_tw_reuse
recycle不安全,但是reuse就要安全地多,所以这个值可以打开,reuse可以安全地回收利用tcp连接。
net.ipv4.tcp_fin_timeout
对于本端断开的socket连接,TCP保持在FIN-WAIT-2状态的时间,对方可能会断开连接或一直不结束连接或不可预料的进程死亡。默认值为 60 秒。降低这个值可以一定程度上防范DDOS攻击。
net.ipv4.tcp_keepalive_intvl
两次检测tcp连接活动状态的间隔时间,默认75秒。
net.ipv4.tcp_keepalive_probes
最大多少次连接检测tcp非活动状态后断开连接,默认9次。
net.ipv4.tcp_keepalive_time
长连接超时时间,默认7200秒。
为了方便使用,下方不带注释的可以直接复制,这是我服务器常用的内核参数调优:
net.ipv4.ip_forward = 0
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 0
net.ipv4.tcp_syncookies = 0
net.ipv4.tcp_timestamps = 0 # recycle 等同无效
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_time = 600
net.ipv4.conf.all.accept_redirects = 0
net.ipv4.tcp_max_tw_buckets = 15000
net.ipv4.ip_local_port_range = 10240 65000
net.core.somaxconn = 65535
net.core.rmem_default = 262144
net.core.wmem_default = 262144
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.netdev_max_backlog = 262144
net.ipv4.tcp_rmem = 4096 4096 16777216
net.ipv4.tcp_wmem = 4096 4096 16777216
net.ipv4.tcp_mem = 786432 3145728 4194304
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.default.accept_source_route = 0
fs.file-max = 999999
kernel.sysrq = 0
vm.swappiness = 9
vm.vfs_cache_pressure = 50
vm.max_map_count = 262144
kernel.core_uses_pid = 1
kernel.msgmnb = 65536
kernel.msgmax = 65536
kernel.shmmax = 68719476736
kernel.shmall = 4294967296
net.ipv4.tcp_sack = 1
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_orphan_retries = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_max_orphans = 3276800
net.ipv4.tcp_max_syn_backlog = 16384
# modprobe ip_conntrack
# 遇到 kernel nf_conntrack: table full, dropping packet 加入
net.ipv4.netfilter.ip_conntrack_max = 655350
net.ipv4.netfilter.ip_conntrack_tcp_timeout_established = 1200
# sysctl -p # 重新加载设置(sysctl.conf)
修改好配置文件,执行 sysctl -p 命令,使配置立即生效。
TCP三次握手和Time Wait的来历
第一次握手:建立连接时,客户端发送syn包和一个随机序列号seq=x到服务器,并进入SYN_SEND状态,等待服务器进行确认(syn,同 步序列编号)。第二次握手,服务器收到syn包,必须确认客户的SYN,然后服务器发送一个 ACK=1,SYN=1,Seq=y 的随机数和Ack=x+1的确认数的包发送回去。第三次握手是客户端收到服务器端的SYN+ACK包,然后向服务器端发送确认包 Ack=y+1, Seq=x+1, ACK=1, 客户端和服务器端进入ESTABLISHED状态,完成三次握手。具体图示如下:
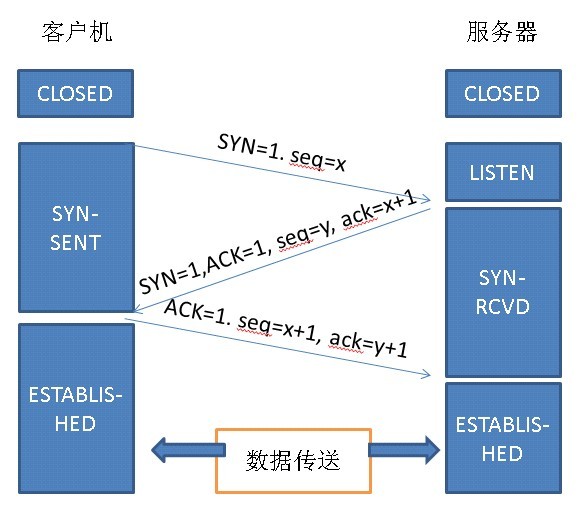
这里多说一点,既然提到了连接时的三次握手,就顺便把断开连接时的四次挥手也复习一下。首先客户端主动发送Fin=1,seq=u,它等于前面已传送过去的最后一个字节的序号加1,这是A进入FIN-WAIT-1状态,等待B的确认。B收到连接后立即发出确认,确认号是ack=u+1,而这个报文段自己的序号是v,等于B前面已传送过的数据的最后一个字节的序号加1,然后B即进入CLOSE-WAIT状态。因而A到B的这个链接现在已经断开了,这时的TCP连接处于半关闭状态,即A已经没有数据需要发送了。但B若发送数据,A还是要接受的。A收到来自B的确认之后就进入了FIN-WAIT-2状态等待B发出连接释放报文段。若B已经没有要向A发送数据,其应用进程就通知TCP释放连接。这时B发出的连接释放报文段必须使用FIN=1,现在假定B的序号为w,B还必须重复上次已发送过的确认号ack=u+1,这时B就进入了LAST-ACK状态,等待A确认。A在收到B的连接释放之后必须对此发出确认,在确认号中把ACK置1,确认号ack=w+1,而自己的序号是seq=u+1,接着A进入TIME-WAIT状态。为了保证B可以收到确认释放报文 段。如下图:
是不是所有执行主动关闭的socket都会进入TIME_WAIT状态呢?有没有什么情况使主动关闭的socket直接进入CLOSED状态呢?
主动关闭的一方在发送最后一个 ack 后就会进入 TIME_WAIT 状态 停留2MSL(max segment lifetime)时间,这个是TCP/IP必不可少的,也就是“解决”不了的。是TCP/IP设计者本来是这么设计的,主要有两个原因:
• 防止上一次连接中的包,迷路后重新出现,影响新连接(经过2MSL,上一次连接中所有的重复包都会消失)
• 可靠的关闭TCP连接,在主动关闭方发送的最后一个 ack(fin) ,有可能丢失,这时被动方会重新发fin, 如果这时主动方处于 CLOSED 状态 ,就会响应 rst 而不是 ack。所以主动方要处于 TIME_WAIT 状态,而不能是 CLOSED 。
小结:
-因为TCP连接是双向的,所以在关闭连接的时候,两个方向各自都需要关闭。先发FIN包的一方执行的是主动关闭;后发FIN包的一方执行的是被动关闭。主动关闭的一方会进入TIME_WAIT状态,并且在此状态停留两倍的MSL时长(指的是报文段的最大生存时间)。
-TIME_WAIT产生原因:为什么主动关闭的一端不直接进入closed状态,而是要先进入time_wait并且停留两倍的MSL时长呢?这是因为TCP是建立在不可靠网络上的可靠协议。如果主动关闭的一端收到被动关闭一端的发出的FIN包后,返回ACK包,同时进入TIME_WAIT,但是由于网络的原因,主动关闭一端发送的ACK包可能会延迟,从而触发被动关闭一方重传FIN包,这样一来一回极端情况正好是2MSL。如果主动关闭的一端直接close或者不到两倍MSL时间就关闭,那么被动关闭发出重传FIN包到达,可能出现的问题是:旧的连接不存在,系统只能返回RST包;新的TCP连接已经建立,延迟包可能会干扰新连接。这都可能导致TCP不可靠。
-在生产过程中,如果服务器使用短连接,那么完成一次请求后会主动断开连接,就会造成大量time_wait状态。因此我们常常在系统中会采用长连接,减少建立连接的消耗,同时也减少TIME_WAIT的产生,但实际上即使使用长连接配置不当时,当TIME_WAIT的生产速度远大于其消耗速度时,系统仍然会累计大量的TIME_WAIT状态的连接。TIME_WAIT状态连接过多就会造成一些问题。如果客户端的TIME_WAIT连接过多,同时它还在不断产生,将会导致客户端端口耗尽,新的端口分配不出来,出现错误。如果服务器端的TIME_WAIT连接过多,可能会导致客户端的请求连接失败。
开启 TCP Fast Open
Tcp fast open 可以让我们的传输更快,也就是上网速度更快,修改相关配置文件来完成,打开/etc/sysctl.conf文件,在文件末尾添加如下内容:
net.ipv4.tcp_fastopen = 3
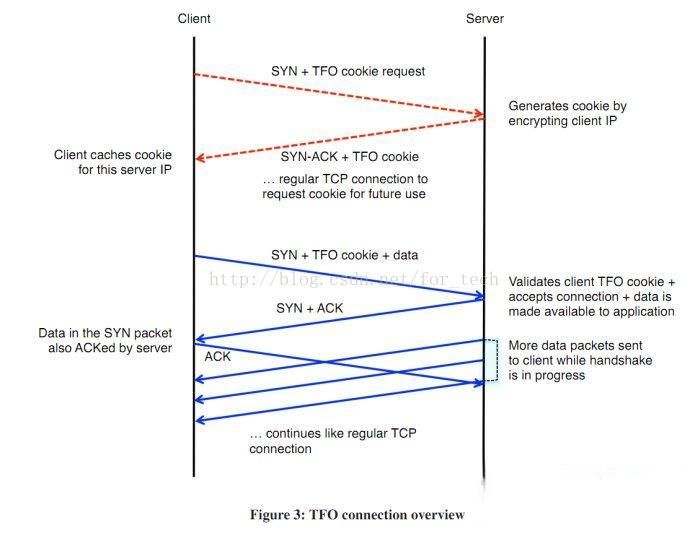
TCP快速打开(TCP Fast Open,TFO)是对TCP的一种简化握手手续的拓展,用于提高两端点间连接的打开速度。简而言之,就是在TCP的三次握手过程中传输实际有用的数据。这个扩展最初在Linux系统上实现。
它通过握手开始时的SYN包中的TFO cookie来验证一个之前连接过的客户端。如果验证成功,它可以在三次握手最终的ACK包收到之前就开始发送数据,这样便跳过了一个绕路的行为,更在传输开始时就降低了延迟。这个加密的Cookie被存储在客户端,在一开始的连接时被设定好。然后每当客户端连接时,这个Cookie被重复返回。
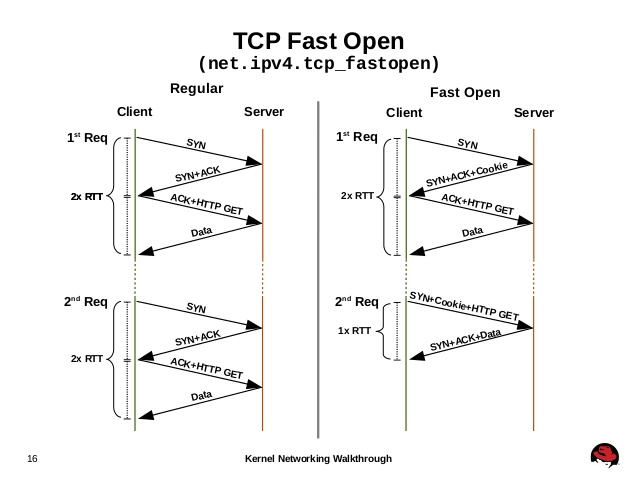
三次握手的过程中,当用户首次访问server时,发送syn包,server根据用户IP生成cookie,并与syn+ack一同发回client;client再次访问server时,在syn包携带TCP cookie;如果server校验合法,则在用户回复ack前就可以直接发送数据;否则按照正常三次握手进行。
TFO提高性能的关键是省去了热请求的三次握手,这在充斥着小对象的移动应用场景中能够极大提升性能。
Google研究发现TCP 二次握手是页面延迟时间的重要部分,所以提出TFO
TFO的fast open标志体现在TCP报文的头部的OPTION字段
TCP Fast Open的标准文档是rfc7413
TFO与2.6.34内核合并到主线,lwn通告地址
TFO的使用目前还是有些复杂的,从linux的network文档来看:
TFO的配置说明:
tcp_fastopen - INTEGER
Enable TCP Fast Open feature (draft-ietf-tcpm-fastopen) to send data in the opening SYN packet. To use this feature, the client application must use sendmsg() or sendto() with MSG_FASTOPEN flag rather than connect() to perform a TCP handshake automatically.
The values (bitmap) are
1: Enables sending data in the opening SYN on the client w/ MSG_FASTOPEN.
2: Enables TCP Fast Open on the server side, i.e., allowing data in a SYN packet to be accepted and passed to the application before 3-way hand shake finishes.
4: Send data in the opening SYN regardless of cookie availability and without a cookie option.
0x100: Accept SYN data w/o validating the cookie.
0x200: Accept data-in-SYN w/o any cookie option present.
0x400/0x800: Enable Fast Open on all listeners regardless of the TCP_FASTOPEN socket option. The two different flags designate two different ways of setting max_qlen without the TCP_FASTOPEN socket option.
Default: 1
Note that the client & server side Fast Open flags (1 and 2 respectively) must be also enabled before the rest of flags can take effect.See include/net/tcp.h and the code for more details.
为了启用 tcp fast open 功能
- client需要使用sendmsg或者sento系统调用,加上MSG_FASTOPEN flag,来连接server端,代替connect系统调用。
- 对server端不做要求。
linux系统(高版本内核)默认tcp_fastopen为1:
$ sysctl -a | grep fastopen
net.ipv4.tcp_fastopen = 1
关于如何使能TFO,在前文中的TFO的配置说明中,我们可以看到:
The values (bitmap) are 1: Enables sending data in the opening SYN on the client w/ MSG_FASTOPEN.
使能client端的TFO特性
2: Enables TCP Fast Open on the server side, i.e., allowing data in a SYN packet to be accepted and passed to the application before 3-way hand shake finishes.
使能server端的TFO特性
4: Send data in the opening SYN regardless of cookie availability and without a cookie option.
并且这个标志是位操作,将本机作为sever端和client端的话,需要两个位都使能,所以应该将该值设置为3。同时可以看到,tcp fast open是非常向后兼容的,升级成本不高,需要高于3.7+版本内核,但总体来说值得采用。
nginx从1.5.18开始支持tcp fast open,在nginx中配置开启:
server {
listen 192.168.25.23 fastopen=50;
server_name www.freeoa.net;
}
前提是服务器本身也启用了TCP Fast Open。在服务器上使用以下grep来查明是否使用了TCP Fast Open:
grep '^TcpExt:' /proc/net/netstat | cut -d ' ' -f 87-92 | column -t
大致原理
1.客户端发送一个SYN包到服务器,这个包中携带了Fast Open Cookie Request;
2.服务器生成一个cookie,这个cookie是加密客户端的IP地址生成的。服务器给客户端发送SYN+ACK响应,在响应包的选项中包含了这个cookie;
3.客户端存储这个cookie以便将来再次与这个服务器的IP建立TFO连接时使用;
也就是说,第一次TCP连接只是交换cookie信息,无法在SYN包中携带数据,在第一次交换之后,接下来的TCP连接就可以在SYN中携带数据了。流程如下:
1.客户端发送一个SYN包,这个包比较特殊,因为它携带应用数据和cookie;
2.服务器验证这个cookie,如果合法,服务器发送一个SYN+ACK,这个ACK同时确认SYN和数据。然后数据被传递到应用进程;如果不合法,服务器丢弃数据,发送一个SYN+ACK,这个ACK只确认SYN,接下来走三次握手的普通流程;
3.如果验证合法(接收了SYN包中的数据),服务器在接收到客户端的第一个ACK前可以发送其它响应数据;
4.如果验证不合法(客户端在SYN中带的数据没被确认),客户端发送ACK确认服务器的SYN;并且,数据会在ACK包中重传;
5.从上图的流程看与普通的TCP交互流程无异
下面记录了一些内核参数设置时所碰到的一些问题集:
1、TCP最大连接数(somaxconn)
该值当不设置时默认为128,但是这样系统重启后会失效,所以需要在/etc/sysctl.conf中添加:
net.core.somaxconn = 20480
TCP连接立即回收、复用(recycle、reuse),recycle这个参数有一定的争议,可视情况修改:
echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse
echo 1 > /proc/sys/net/ipv4/tcp_tw_recycle
不做TCP洪水抵御
echo 0 > /proc/sys/net/ipv4/tcp_syncookies
之后执行:sysctl -p 来使生效设置。
2、sysctl: setting key "net.core.somaxconn": 无效的参数
net.core.somaxconn是Linux中的一个kernel参数,表示socket监听(listen)的backlog上限。什么是backlog呢?backlog就是socket的监听队列,当一个请求(request)尚未被处理或建立时,他会进入backlog。而socket server可以一次性处理backlog中的所有请求,处理后的请求不再位于监听队列中。当server处理请求较慢,以至于监听队列被填满后,新来的请求会被拒绝。
在Hadoop 1.0中,参数ipc.server.listen.queue.size控制了服务端socket的监听队列长度,即backlog长度,默认值是128。而Linux的参数net.core.somaxconn默认值同样为128。当服务端繁忙时,如NameNode或JobTracker,128是远远不够的。这样就需要增大backlog,为了使得整个参数达到预期效果,同样需要将kernel参数net.core.somaxconn设成一个大于等于32768的值。
Nginx Connection 不够用时的参数调整
机器的负载很低,但是连接总是会出现找不到数据,重新再试一次的消息,如下述:
HTTP request sent, awaiting response... No data received.Retrying.
直觉猜测就是 Connection、文件数、TCP... 等满了的问题,于是作些调整。
注:netstat -ant | grep TIME_WAIT | wc -l # TIME_WAIT 数值应该很高
Nginx worker_connections 不够用的系统参数调整
直接把调整的参数写到配置文件中(/etc/sysctl.conf ),需要系统这些设置,否则 Nginx worker_connections 无法调整到 1024 以上。
在编辑/etc/sysctl.conf并执行sysctl-p之后,尝试设置Linux内核。它显示错误:Invalid argument "setting key "net.core.somaxconn"
当尝试微调引擎时也遇到了同样的问题,这是Ubuntu内核补丁的问题。这个sock结构的sk_max_ack_backlog字段定义为无符号短。因此,inet_listen()不应超过USHRT_MAX。listen()syscall中的backlog参数被截断为somaxconn值。因此,somaxconn值不应超过65535(ushrt_max)。简而言之,要使net.core.somaxconn工作,不应给出大于65535的值。
目前没有很好的方法解决这个问题,直到你可以重新编译你的内核,参考链接。
3、TCP: time wait bucket table overflow解决方法
收到一台web服务器告警消息,查看/var/log/message日志信息如下所示:
kernel: TCP: time wait bucket table overflow
该台服务器每日有kw的pv,压力有些大,服务器的TCP连接数,超出了内核定义最大数。可修改内核参数:在 TIME_WAIT 数量等于 tcp_max_tw_buckets 时,不会有新的 TIME_WAIT 产生。具体的参数:/proc/sys/net/ipv4/tcp_max_tw_buckets
# echo 20000 > /proc/sys/net/ipv4/tcp_max_tw_buckets
写入/etc/sysctl.conf使之永久生效
net.ipv4.tcp_max_tw_buckets = 20000
tcp_max_tw_buckets 应该如何配置
如果不是类似 Nginx 之类的中间代理(即不担心端口耗尽),通常不用关心这个值,使用官方默认的就好,甚至官方建议在内存大的情况下可以增加这个值。类似 Nginx 之类的中间代理一定要关注这个值,因为它对你的系统起到一个保护的作用,一旦端口全部被占用,服务就异常了。 tcp_max_tw_buckets 能帮你降低这种情况的发生概率,争取补救时间。这个值可能会有不好的影响。
在完全下面 2 条完全满足的情况下
当前服务器主动关闭连接
当前服务器 TIME_WAIT 数等于或大于 tcp_max_tw_buckets
可能会出现两种异常情况:
1)、对端服务器发完最后一个 Fin 包,没有收到当前服务器返回最后一个 Ack,又重发了 Fin 包,因为新的 TimeWait 没有办法创建,这个连接在当前服务器上就消失了,对端服务器将会收到一个 Reset 包。因为这个连接是明确要关闭的,所以收到一个 Reset 也不会有什么大问题(但是违反了 TCP/IP 协议)。
2)、因为这个连接在当前服务器上消失,那么刚刚释放的端口可能被立刻使用,如果这时对端服务器没有释放连接,当前服务器就会收到对端服务器发来的 Reset 包。如果当前服务器是代理服务器,就可能会给用户返回 502 错误(这种异常对服务或者用户是有影响的)。
建议在只有 60000 多个端口可用的情况下,配置为:net.ipv4.tcp_max_tw_buckets = 55000
(在尽可能不违反 TCP/IP 协议的情况下保证系统的可用性)
官方文档参考
官方手册中有一段警告:
This limit exists only to prevent simple DoS attacks, you _must_ not lower the limit artificially,
but rather increase it (probably, after increasing installed memory),
if network conditions require more than default value.
基本意思是这个用于防止Dos攻击,我们不应该人工减少,如果网络条件需要的话,反而应该增加。
Linux TIME_WAIT 相关参数:
net.ipv4.tcp_tw_reuse = 0 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭
net.ipv4.tcp_tw_recycle = 0 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭
net.ipv4.tcp_fin_timeout = 60 表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间,可认为是系統默认的TIMEOUT时间
net.ipv4.tcp_syncookies = 1 表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭
注意:
- 不像Windows 可以修改注册表修改2MSL 的值,linux 需要修改内核宏定义重新编译,tcp_fin_timeout 不是2MSL 而是Fin-WAIT-2状态超时时间。
- tcp_tw_reuse 和 SO_REUSEADDR 是两个完全不同的概念。
SO_REUSEADDR 允许同时绑定 127.0.0.1 和 0.0.0.0 同一个端口;SO_RESUSEPORT linux 3.7才支持,用于绑定相同ip:port,像nginx 那样 fork方式也能实现。
1. tw_reuse,tw_recycle 必须在客户端和服务端 timestamps 开启时才管用(默认打开)
2. tw_reuse 只对客户端起作用,开启后客户端在1s内回收
3. tw_recycle 对客户端和服务器同时起作用,开启后在 3.5*RTO 内回收,RTO 200ms~ 120s 具体时间视网络状况
内网状况比 tw_reuse 稍快,公网尤其移动网络大多要比 tw_reuse 慢,优点就是能够回收服务端的TIME_WAIT数量。
对于客户端
1. 作为客户端因为有端口65535问题,TIME_OUT过多直接影响处理能力,打开tw_reuse 即可解决,不建议同时打开tw_recycle,帮助不大;
2. tw_reuse 帮助客户端1s完成连接回收,基本可实现单机6w/s短连接请求,需要再高就增加IP数量;
3. 如果内网压测场景,且客户端不需要接收连接,同时 tw_recycle 会有一点点好处;
4. 业务上也可以设计由服务端主动关闭连接。
对于服务端
1. 打开tw_reuse无效
2. 线上环境 tw_recycle 不建议打开
服务器处于NAT负载后,或者客户端处于NAT后(基本公司家庭网络基本都走NAT);公网服务打开就可能造成部分连接失败,内网的话到时可以视情况打开;公司对外服务都放在负载后面,网关会把 timestamp 都给清空,就算你打开也不起作用。
3. 服务器TIME_WAIT 高怎么办
不像客户端有端口限制,处理大量TIME_WAIT Linux已经优化很好了,每个处于TIME_WAIT 状态下连接内存消耗很少,而且也能通过 tcp_max_tw_buckets = 262144 配置最大上限,如果机器不缺内存的话。
下面一台每秒峰值1w请求的 http 短连接服务,长期处于tw_buckets 溢出状态,tw_socket_TCP 占用70M,因为业务简单服务占用CPU 200% 运行很稳定。系统日志中overflow 错误一直在报,也许该将 buckets 调大一下了
TCP: time wait bucket table overflow
TCP: time wait bucket table overflow
...
TCP: time wait bucket table overflow
4. 业务上也可以设计由客户端主动关闭连接
close_wait是server主动关闭连接是产生的关闭状态,time_wait无法真正释放句柄资源。如果没有做好相关配置时,可能服务器这个值会很高的。如果nginx连接到负载均衡节点时是短链接,那么nginx这台服务器的本地端口就会被耗尽,client就会得到nginx502的错误响应,错误原因大致是Cannot assign requested address for upstream。
一起因应用被人利用攻击他网站导致本地连接资源耗尽的问题(Cannot assign requested address)
由于一应用频繁的连服务器且每次连接都在很短的时间内结束,导致很多的连接状态为TIME_WAIT,以至于用光了可用的端口号,新的连接没办法绑定端口,即"Cannot assign requested address"问题,可以明确是是客户端的问题。通过netstat,的确看到很多TIME_WAIT状态的连接。这是可分配的客户端连接端口用尽,无法建立socket连接所致,虽然socket正常关闭,但是端口不是立即释放,而是处于TIME_WAIT状态,默认情况下等待60s后才释放。
可行解决方法1:调低time_wait状态端口等待时间:
1).调低端口释放后的等待时间,从默认为60s改为15~30s
# sysctl -w net.ipv4.tcp_fin_timeout=30
2).修改tcp/ip协议配置,通过配置/proc/sys/net/ipv4/tcp_tw_resue,从默认为0修改为1,即释放TIME_WAIT端口给新连接使用(开启对于TCP时间戳的支持,若该项设置为0,则下面一项设置(tcp_tw_recycle)不起作用)
# sysctl -w net.ipv4.tcp_timestamps=1
3).修改tcp/ip协议配置,快速回收socket资源,从默认为0修改为1(表示开启TCP连接中TIME-WAIT Sockets的快速回收[重用,循环使用])
# sysctl -w net.ipv4.tcp_tw_recycle=1
可行解决办法2:增加可用端口:
# sysctl -a |grep port_range
net.ipv4.ip_local_port_range = 50000 65000 --即50000~65000端口可用
修改参数:
# sysctl -w net.ipv4.ip_local_port_range="10000 65000"
或添加到配置文件(/etc/sysctl.conf)中,下次重启后依然有效
net.ipv4.ip_local_port_range = 10000 65000 --即10000~65000端口可用
改完还不能很好解决问题的话,就需要修改tcp_max_tw_buckets
echo '5000' > /proc/sys/net/ipv4/tcp_max_tw_buckets
原理分析
1. MSL 由来
发起连接关闭方回复最后一个fin的ack,为避免对方ack收不到、重发的或还在中间路由上的fin把新连接给丢掉了,等个2MSL(linux 默认2min)。也就是连接有谁关闭的那一方有time_wait问题,被关那方无此问题。
2. reuse、recycle
通过timestamp的递增性来区分是否新连接,新连接的timestamp更大,那么保证小的timestamp的 fin 不会fin掉新连接,不用等2MSL。
3. reuse
通过timestamp 递增性,客户端、服务器能够处理outofbind fin包。
4. recycle
对于服务端,同一个src ip,可能会是NAT后很多机器,这些机器timestamp递增性无可保证,服务器会拒绝非递增请求连接。