Linux自带的高级流控(Traffic Control)工具快速参考
 1、简介
1、简介1.1、概念
1.2、qdisc队列分类
1.3、分类排队规则和分类处理(Classful qdisc & class 中的 flow)
1.4、qdisc排队规则的层级结构
1.5、过滤器简介
2、tc使用
2.1、tc配置规则案例解析
2.2、tc使用示例
3、tc工具常用命令
4、Red Hat Enterprise LinuxV8 流量控制
5、快速回看
5.1、tc中htb算法下的r2q和quantum
5.2、模拟延迟传输简介
6、小结
6.1 小结1
6.2 小结2
1、简介
Linux操作系统中的流量控制器TC(Traffic Control)用于在输出端口处建立队列以实现流量控制。接收包进入后,通过TC进行流量限制丢弃不符合规定的数据包,然后输入多路分配器判断选择,将包送至目的主机或进行转发。转发过程中,查看路由表决定下一跳,并对包进行排列以便送到输出接口。通常,TC只能限制发送数据包,但通过改变发送次序可以控制传输速率。
TC的流量控制方式包括但不限于QDisc(排队规则)、类(Class)和过滤器(Filter)。QDisc是流量控制的基础,内核根据接口配置将数据包加入队列。类用于分类数据包的离队次序,通过设置优先级为数据流量分配优先级。过滤器则用于数据包分类,决定它们按照何种QDisc进入队列。执行过程分为建立队列、建立分类和建立过滤器。首先针对物理网络设备绑定队列,然后在队列上建立分类,为每个分类建立过滤器,并与过滤器配合建立特定的路由表。
TC命令可以操作QDisc、类和过滤器。应用中,TC主要分为网络物理设备绑定队列、建立分类和过滤器等步骤。例如,对端口、IP进行限速,以及针对特定网络物理设备建立CBQ队列,通过设置包的平均大小、包间隔发送单元大小和可接收冲突的发送最长包数目,控制不同类别的流量。在应用中遇到问题时,可通过在过滤器中加入prio指定规则优先级,以及手动设置网络物理设备带宽来解决。在建立队列、分类和过滤器后,可以通过监视队列、分类、过滤器和路由状况来确保TC配置的正确性。
TC实际上是不断发展的工具链,可以用来配置Linux内核网络子系统堆栈的行为。它可以用来编写网络调度算法,设置控制带宽、延迟、负载均衡等功能。它是一个功能强大的流量控制工具,可以按照您的意愿灵活使用,从而实现自定义Linux网络子系统堆栈的行为。其基于Linux内核中添加的网络子系统堆栈,包括过滤、转发、网络安全等多重功能。其使用非常灵活,可以定义一个范围内的流量控制,允许你限制网络流量的吞吐量,以及可以从多个源并行发送的数据报的数量。TC最为强大的功能是应用程序可以使用它来管理流量,控制网络行为,改变流量路径和优先级,以及最大限度地改善网络性能。
它以qdisc-class-filter的树形结构来实现对流量的分层控制 :
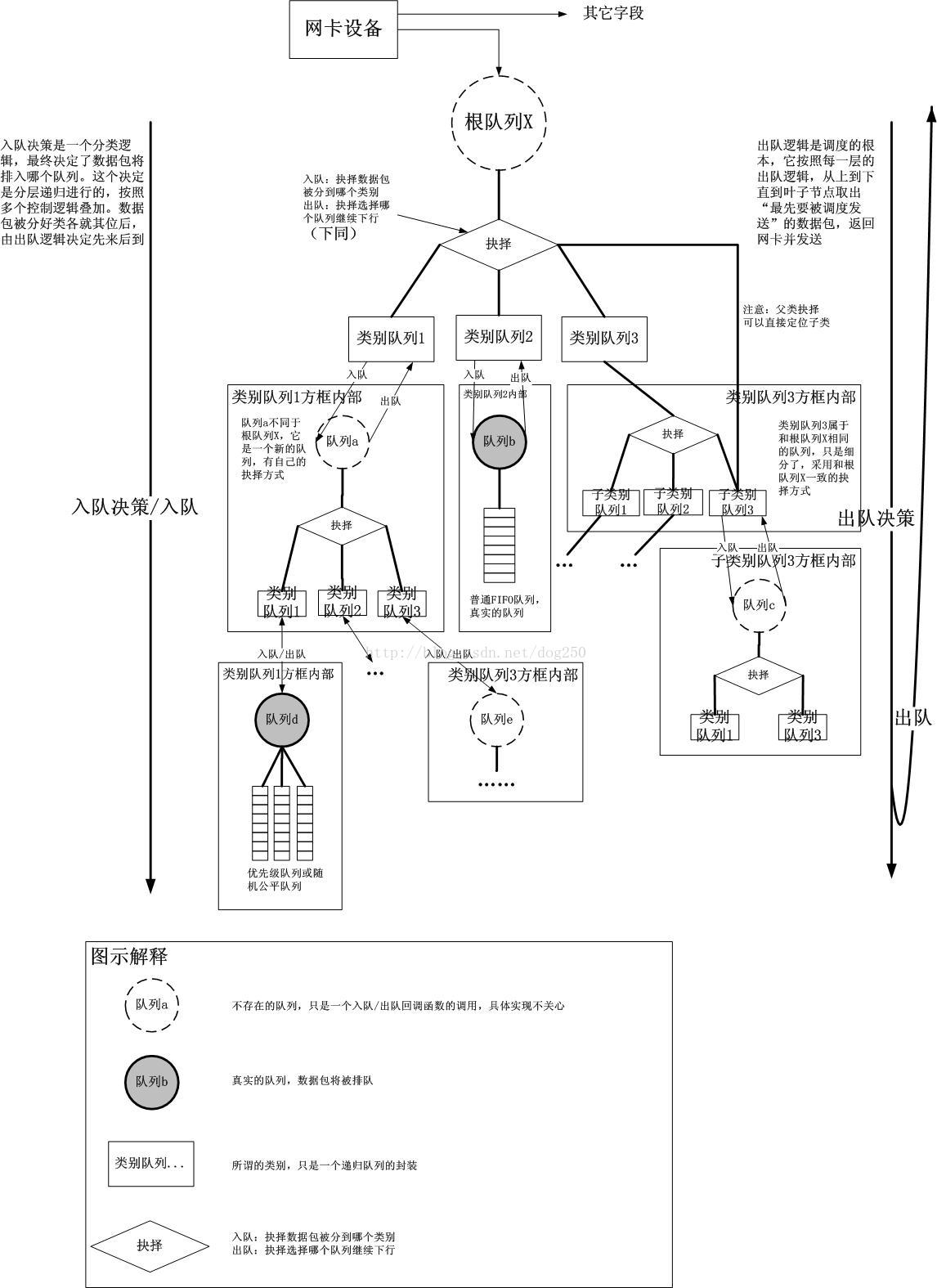
Tc最佳的参考就是Linux Traffic Control HOWTO,其中详细介绍了tc的原理和使用方法。
基本组成
从上图中可以看到,tc由qdisc、fitler和class三部分组成:
1.qdisc通过队列将数据包缓存起来,用来控制网络收发的速度
2.class用来表示控制策略
3.filter用来将数据包划分到具体的控制策略中
qdisc
qdisc通过队列将数据包缓存起来,用来控制网络收发的速度。实际上,每个网卡都有一个关联的qdisc。它包括以下几种:
1.无分类qdisc(只能应用于root队列)
[p|b]fifo:简单先进先出
pfifo_fast:根据数据包的tos将队列划分到3个band,每个band内部先进先出
red:Random Early Detection,带带宽接近限制时随机丢包,适合高带宽应用
sfq:Stochastic Fairness Queueing,按照会话对流量排序并循环发送每个会话的数据包
tbf:Token Bucket Filter,只允许以不超过事先设定的速率到来的数据包通过 , 但可能允许短暂突发流量朝过设定值
2.有分类qdisc(可以包括多个队列)
cbq:Class Based Queueing,借助EWMA(exponential weighted moving average, 指数加权移动均值 ) 算法确认链路的闲置时间足够长 , 以达到降低链路实际带宽的目的。如果发生越限 ,CBQ 就会禁止发包一段时间。
htb:Hierarchy Token Bucket,在tbf的基础上增加了分层。
prio:分类优先算法并不进行整形 , 它仅仅根据你配置的过滤器把流量进一步细分。缺省会自动创建三个FIFO类。
注意,一般说到qdisc都是指egress qdisc。每块网卡实际上还可以添加一个ingress qdisc,不过它有诸多的限制:
1.ingress qdisc不能包含子类,而只能作过滤
2.ingress qdisc只能用于简单的整形
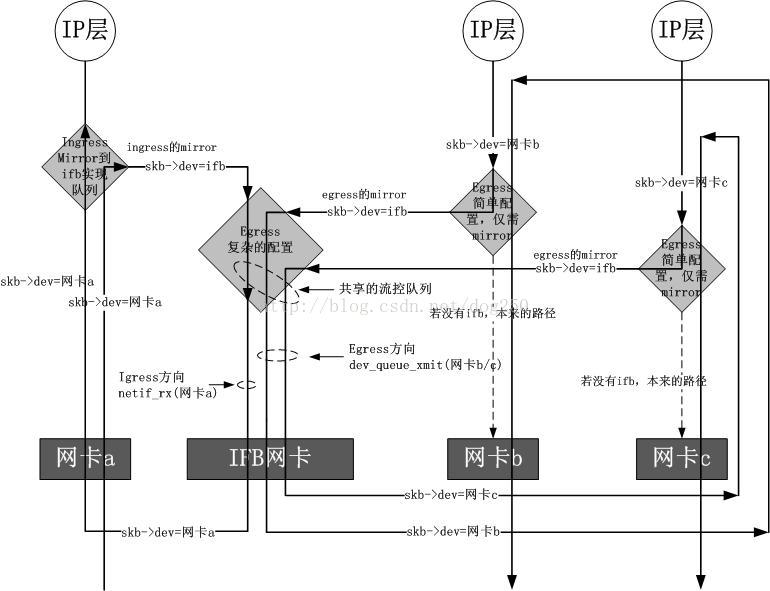
如果相对ingress方向作流量控制的话,可以借助ifb( Intermediate Functional Block)内核模块。因为流入网络接口的流量是无法直接控制的,那么就需要把流入的包导入(通过 tc action)到一个中间的队列,该队列在 ifb 设备上,然后让这些包重走 tc 层,最后流入的包再重新入栈,流出的包重新出栈。
filter
filter用来将数据包划分到具体的控制策略中,包括以下几种:
u32:根据协议、IP、端口等过滤数据包;
fwmark:根据iptables MARK来过滤数据包;
tos:根据tos字段过滤数据包。
class
class用来表示控制策略,只用于有分类的qdisc上。每个class要么包含多个子类,要么只包含一个子qdisc。当然,每个class还包括一些列的filter,控制数据包流向不同的子类,或者是直接丢掉。
TC命令本身由多个子命令组成,其中比较常用的几个包括tc qdisc、filter、class、action、monitor等。
tc qdisc指令是最常用的指令,它可以用来控制Linux网络子系统中报文的速率,延迟,丢弃和传输等行为。举个例子,使用tc qdisc可以限制出站带宽,以免服务器由于带宽不足而发生停顿的情况。
tc filter指令可以用来确保指定网络流量不会受流控影响而发生网络拥塞,以及过滤无用的网络流量,如不必要的Torrents等。
tc class指令可以将网络流量划分为不同的优先级,可以确保低优先级的通信不会影响高优先级的网络通信。
tc action会在指定条件下触发,例如,当TC filter过滤出无效流量时,tc action可以触发一个报文丢弃动作,以及当tc qdisc由于达到带宽限制而进行流控时,可以触发轮询报文发送动作。
最后,tc monitor服务可以用来测试TC命令的结果,如信道带宽、路由负载均衡等,以确保相应的网络子系统在正确运行。
部分术语原义
pfifo_fast: three-layer priority
SFQ: stochastic fair queuing
TBF: token-bucket filter
netem: NETwork EMulator, supports emulation of long delays, specific queue sizes, and random packet drops
RED: Random Early Drop
CoDel (pronounced "coddle"): an easier-to-set-up alternative to RED. Also fq_codel
prio: multi-band priority queuing
HTB: Hierarchical Token Bucket
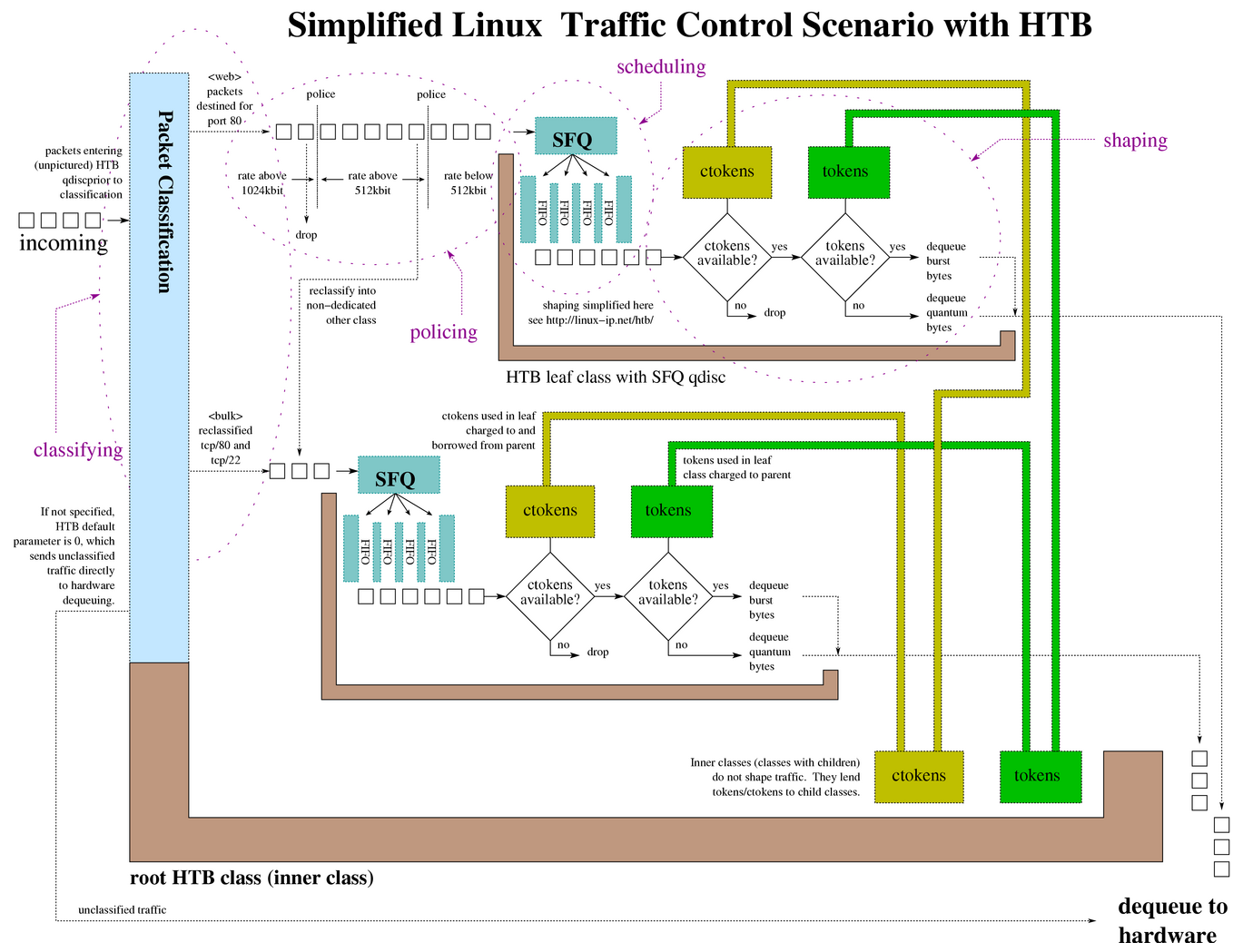
TC是一个功能强大,应用广泛的Linux网络子系统堆栈工具,它可以灵活控制网络流量,优化性能,同时改善网络安全等。这可确保服务总是以最佳的状态运行。它的实用性,使它成为实现网络流量控制、改善性能和提高安全性的首选工具。其诞生是为了实现QoS,它在netdev设备的入方向和出方向增加了挂载点,进而控制网络流量的速度,延时,优先级等。其在整个Linux Kernel Datapath中的位置如下图所示:
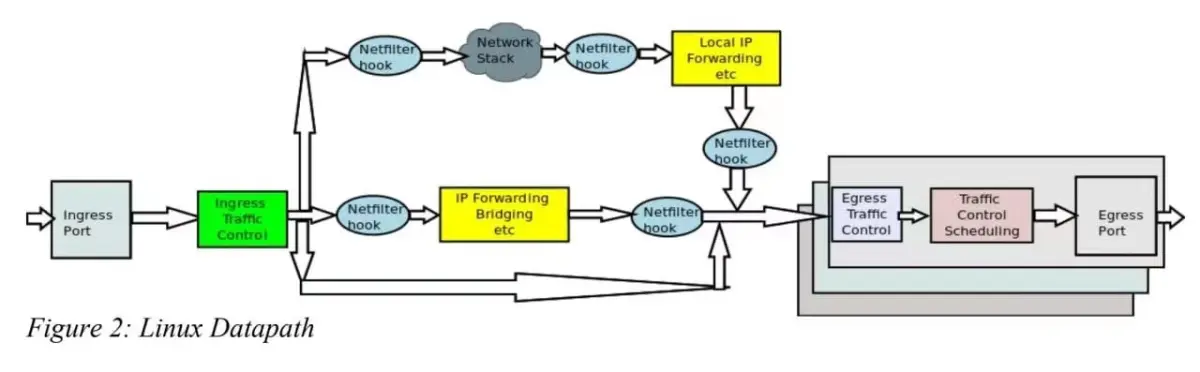
TC用于Linux内核的流量控制,它利用一些队列规则来处理数据包的队列,并定义队列中的数据包被发送的方式,从而实现对流量的控制。TC使用的队列规则分为两类,一类是无类别队列规则,另一类是分类队列规则。无类别队列规则相对简单,而分类队列规则则引出了分类和过滤器等概念,使其流量控制功能增强。
1.1、概念:
报文分组从输入网卡接收进来,经过路由的查找,以确定是发给本机的,还是需要转发的。如果是发给本机的,就直接向上递交给上层的协议,比如TCP,如果是转发的, 则会从输出网卡发出。
网络流量的控制通常发生在输出网卡处,可以通过改变发送次序来控制传输速率。一般说来, 由于无法控制自己网络之外的设备,入口处的流量控制相对较难。
流量控制的一个基本概念是队列,每个网卡都与一个队列相联系,每个队列对应一个QDisc(排队规则),每当内核需要将报文分组从网卡发送出去,都会首先将该报文分组添加到该网卡所配置的QDisc中,由该QDisc决定报文分组的发送顺序,可以说,所有的流量控制都发生在队列中。
为实现复杂QoS,队列需要使用不同的过滤器(Filter)来把报文分组分成不同的类别(Class),因此类别(class)和过滤器(Filter)也是流量控制的另外两个重要的基本概念。
1)、TC相关概念解释:
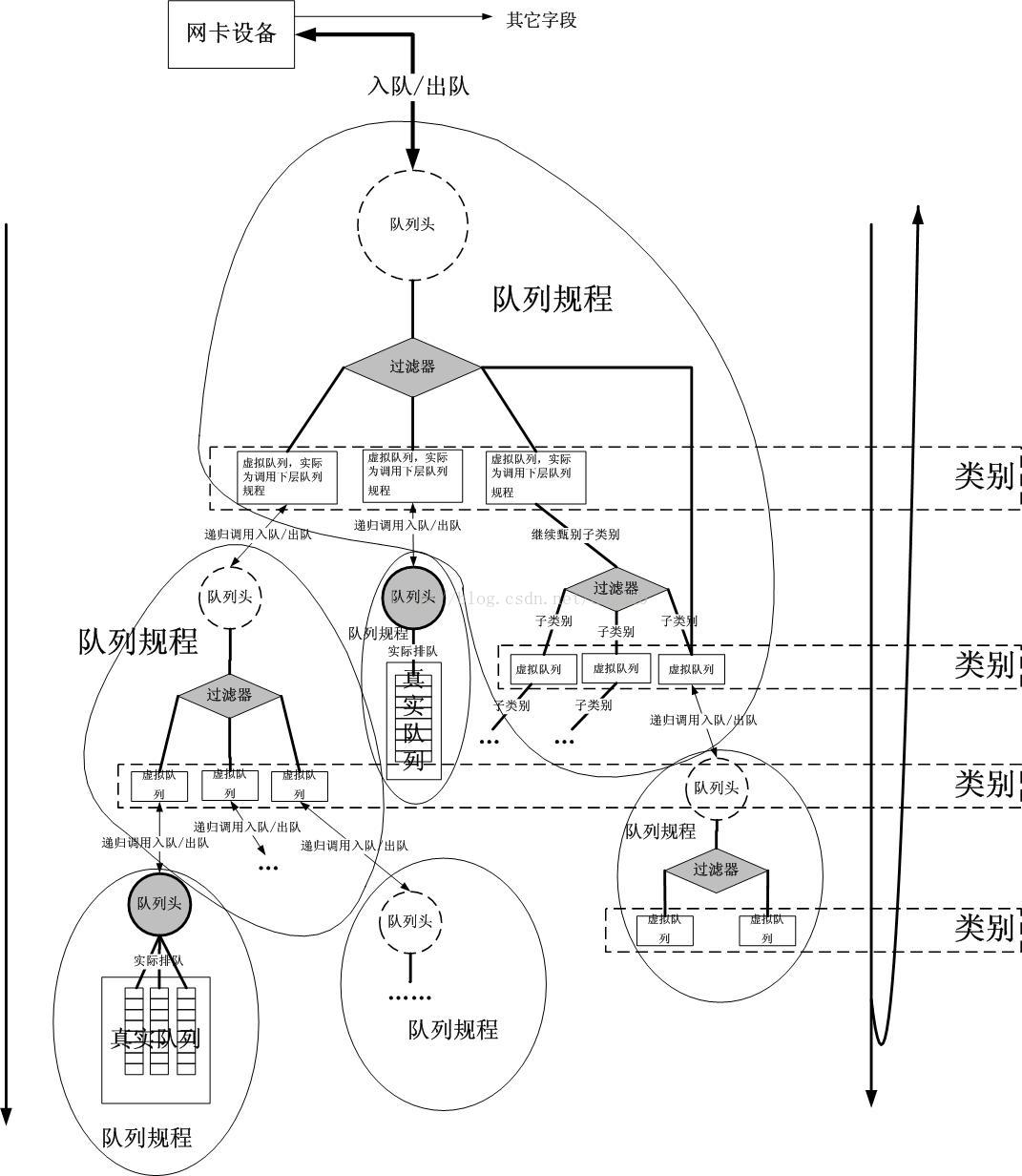
QDisc(排队规则):是queueing discipline的简写,它是理解流量控制(traffic control)的基础。无论何时,内核如果需要通过某个网络接口发送数据包,它都需要按照为这个接口配置的qdisc(排队规则)把数据包加入队列。然后,内核会尽可能多地从qdisc里面取出数据包,把它们交给网络适配器驱动模块。最简单的QDisc规则是pfifo(也是默认规则)它不对进入的数据包做任何的处理,数据包采用先入先出的方式通过队列。不过,它会保存网络接口一时无法处理的数据包;QDisc队列根据规则分为两类,一类是无类别队列规则,另一类是分类队列规则。无类别队列规则相对简单,而分类队列规则则引出了分类和过滤器等概念,使其流量控制功能增强(简单的说即有类别(或称分类别)排队规则是一个排队规则中又包含其他 排队规则)。
Class(类别):每个 classful qdisc 可能会包含几个 class,这些都是 qdisc 内部可见的。对于每 个 class,也是可以再向其添加其他 class 的。因此,一个 class 的 parent 可以 是一个 qdisc,也可以是另一个 class。Leaf class 是没有 child class 的 class。这种 class 中 attach 了一个 qdisc ,负责该 class 的数据发送。创建一个 class 时会自动 attach 一个 fifo qdisc。而当向这个 class 添加 child class 时,这个 fifo qdisc 会被自动删除。对于 leaf class,可以用一个更合适的 qdisc 来替换掉这个fifo qdisc。你甚至能用一个 classful qdisc 来替换这个 fifo qdisc,这样就可以添加其他 class了(简单的说就是QDisc(排队规则)可以包含一些其他类别组成层级的树状结构,不同的类别中可以包含更深入的QDisc(排队规则),通过这些细分的QDisc还可以为进入的队列的数据包排队。通过设置各种类别数据包的离队次序,QDisc可以为设置网络数据流量的优先级)。
filter(过滤器):Filter(过滤器)用于为数据包分类,决定它们按照何种QDisc进入队列。无论何时数据包进入一个划分子类的类别中,都需要进行分类。分类的方法可以有多种,使用fileter(过滤器)就是其中之一。使用filter(过滤器)分类时,内核会调用附属于这个类(class)的所有过滤器,直到返回一个判决。如果没有判决返回,就作进一步的处理,而处理方式和QDISC有关。需要注意的是,filter(过滤器)是在QDisc内部,它们不能作为主体;
2)、流量控制的方式术语:
Scheduling(调度):在分类器的协助下,一个 qdisc 可以判断某些包是不是要先于其他包发送出去,这个过程称为调度,可以通过例如前面提到的 pfifo_fast qdisc 完成。调度也被称为重排序(reordering),但后者容易引起混淆;
Shaping(整形):在包发送出去之前进行延迟处理,以达到预设的最大发送速率的过程。整形是在 egress 做的(前面提到了,ingress 方向的不叫 shaping,叫 policing,译者注)。不严格地说,丢弃包来降低流量的过程有时也称为整形;
Policing(执行策略,决定是否丢弃包):延迟或丢弃(delaying or dropping)包来达到预设带宽的过程。 在 Linux 上, policing 只能对包进行丢弃,不能延迟 —— 没有“入向队列”(”ingress queue”);
DROPPING(丢弃):如果流量超过某个设定的带宽,就丢弃数据包,不管是向内还是向外;
Work-Conserving qdisc(随到随发 qdisc):work-conserving qdisc 只要有包可发送就立即发送。换句话说,只要网卡处于可发送状态(对于 egress qdisc 来说),它永远不会延迟包的发送;
non-Work-Conserving qdisc(非随到随发 qdisc):某些 qdisc,例如 TBF,可能会延迟一段时间再将一个包发送出去,以达到期望的带宽。这意味着它们有时即使有能力发送,也不会发送;
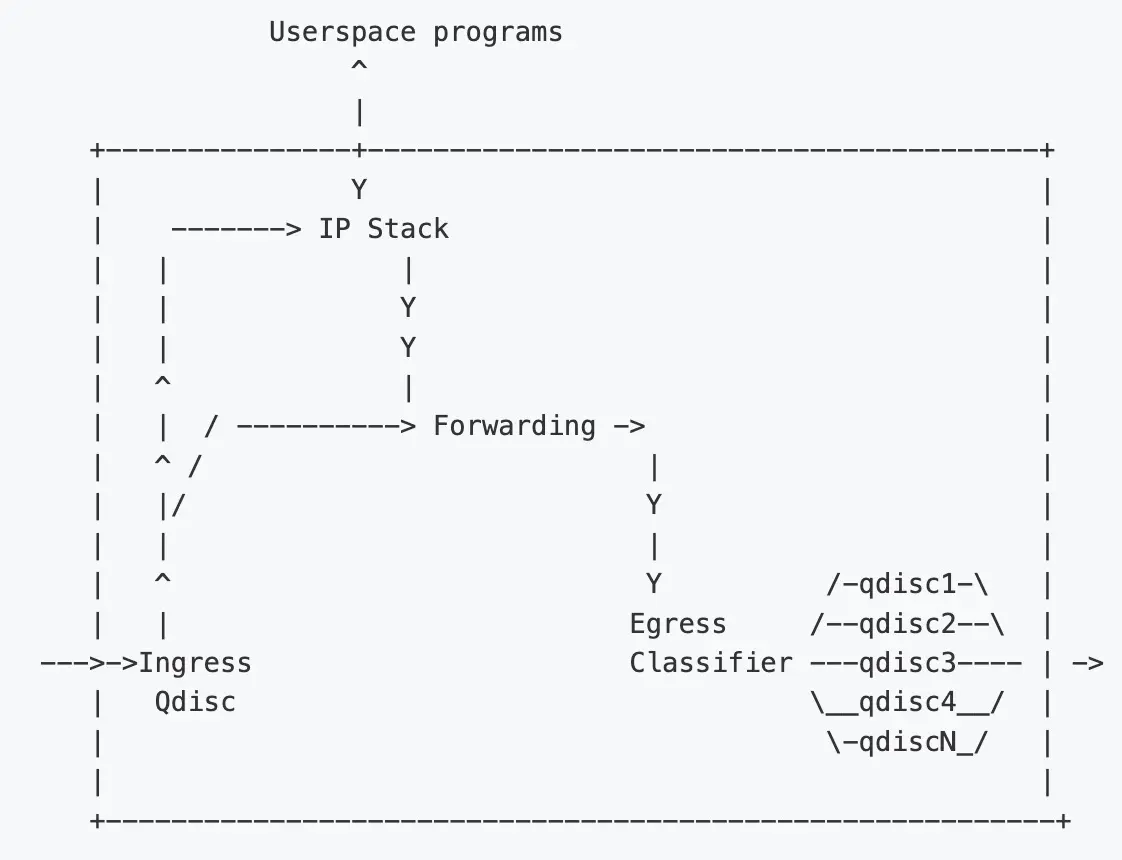
上图中的框代表 Linux 内核。最左侧的箭头表示流量从外部网络进入主机。然后进入 Ingress Qdisc,这里会对包进行过滤(apply Filters),根据结果决定是否要丢弃这个包。这个过程称为“Policing”。这个过程发生在内核处理的很早阶段,在穿过大部分内核基础设施之前。因此在这里丢弃包是很高效的,不会消耗大量 CPU。
如果判断允许这个包通过,那它的目的端可能是本机上的应用(local application),这 种情况下它会进入内核 IP 协议栈进行进一步处理,最后交给相应的用户态程序。另外这个包的目的地也可能是其他主机上的应用,这种情况下就需要通过这台机器 Egress Classifier 再发送出去。主机程序也可能会发送数据,这种情况下也会通过 Egress Classifier 发送。
Egress Classifier 中会用到很多 qdisc。默认情况下只有一个:pfifo_fast qdisc ,它永远会接收包,这称为“入队”(“enqueueing”)。
此时包位于 qdisc 中了,等待内核召唤,然后通过网络接口(network interface)发送出去。 这称为“出队”(“dequeueing”)。
以上画的是单网卡的情况。在多网卡的情况下,每个网卡都有自己的 ingress 和 egress hooks。
1.2、qdisc队列分类:
不可分类规则队列有:
[p|b]fifo:使用最简单的qdisc,纯粹的先进先出。只有一个参数:limit,用来设置队列的长度,pfifo是以数据包的个数为单位;bfifo是以字节数为单位;
pfifo_fast:就是系统的标准QDISC。在编译内核时,如果打开了高级路由器(Advanced Router)编译选项,pfifo_fast就是系统的标准QDISC。它的队列包括三个波段(band)。在每个波段里面,使用先进先出规则。而三个波段(band)的优先级也不相同,band 0的优先级最高,band 2的最低。如果band0里面有数据包,系统就不会处理band 1里面的数据包,band 1和band 2之间也是一样。数据包是按照服务类型(Type of Service,TOS)被分配多三个波段(band)里面的;
red:是Random Early Detection(随机早期探测)的简写。如果使用这种QDISC,当带宽的占用接近于规定的带宽时,系统会随机地丢弃一些数据包。它非常适合高带宽应用;
sfq:是Stochastic Fairness Queueing的简写。它按照会话(session--对应于每个TCP连接或者UDP流)为流量进行排序,然后循环发送每个会话的数据包;
tbf:是Token Bucket Filter的简写,适合于把流速降低到某个值;
可分类队列规则有:
CBQ:是Class Based Queueing(基于类别排队)的缩写。它实现了一个丰富的连接共享类别结构,既有限制(shaping)带宽的能力,也具有带宽优先级管理的能力。带宽限制是通过计算连接的空闲时间完成的。空闲时间的计算标准是数据包离队事件的频率和下层连接(数据链路层)的带宽;
HTB:是Hierarchy Token Bucket的缩写。通过在实践基础上的改进,它实现了一个丰富的连接共享类别体系。使用HTB可以很容易地保证每个类别的带宽,它也允许特定的类可以突破带宽上限,占用别的类的带宽。HTB可以通过TBF(Token Bucket Filter)实现带宽限制,也能够划分类别的优先级;
PRIO:QDisc不能限制带宽,因为属于不同类别的数据包是顺序离队的。使用PRIO QDisc可以很容易对流量进行优先级管理,只有属于高优先级类别的数据包全部发送完毕,才会发送属于低优先级类别的数据包。为了方便管理,需要使用iptables或者ipchains处理数据包的服务类型(Type Of Service,ToS);
1.3、分类排队规则和分类处理(Classful qdisc & class 中的 flow):
当流量进入一个 classful qdisc 时,该 qdisc 需要将其发送到内部的某个 class —— 即需要对这个包进行“分类”。而要这个判断过程,实际上是查询所谓的“过滤器”(‘filters’)。过滤器是在 qdisc 中被调用的,而不是其他地方,理解一点非常重要!
过滤器返回一个判决结果给 qdisc,qdisc 据此将包 enqueue 到合适的 class。每个 subclass 可能会进一步执行其他 filters,以判断是否需要进一步处理。如果没有其他过滤器,这个 class 将把包 enqueue 到它自带的 qdisc。
除了能包含其他 qdisc,大部分 classful qdisc 还会执行流量整形。这对包调度(packet scheduling,例如,基于 SFQ)和速率控制(rate control)都非常有用。当高速设备(例如,以太网)连接到一个低速设备(例如一个调制解调器)时,会用到这个功能。
如果只运行 SFQ,那接下来不会发生什么事情,因为包会无延迟地进入和离开路由器:网卡的发送速度要远大于真实的链路速度。瓶颈不在主机中,就无法用“队列”(queue )来调度这些流量。
1.4、qdisc排队规则的层级结构:
每个接口有一个egress 'root qdisc',默认是pfifo_fast。每个qdisc和class都分配一个句柄handle,句柄用于在后续的配置语句中进行引用。除了egress qdisc,一个接口也可以有一个ingress qdisc,负责管制入站的流量。但是ingress qdisc相比classful qdisc其可能性是非常有限(所以才有所谓的控发不控收,对入站流量进行控制通常需要借助ifb或者imq)。
所有的QDisc、类和过滤器都有ID。ID可手工设置也可以由内核自动分配。ID由一个主序列号和一个从序列号组成,两个数字用一个冒号分开,主序列号在tc中称为handle,用于子类的引用。这些qdisc的ID就是tc中的handles在定义上有两个部分组成,一个major数和一个minor数:<major>:<minor>。习惯上将root qdisc命名为1:,等价于1:0。
子类需要跟它们的parent有相同的major数。major数在一个egress或ingress内必须是唯一的,minor数在一个qdisc和它的class中必须是唯一的。一个典型的层级结构如下:

内核只跟root qdisc进行通信,每当包需要入队或者出队的时候,都需要从root节点开始,最终到达叶子节点,从而决定入队到哪里,或者从哪里出队。比如当一个包入队时,它可能会经过如下路径:
1: -> 1:1 -> 1:12 -> 12: -> 12:2
当然也可能直接走如下路径(这种情况,就是root qdisc上的过滤器决定把包直接送到12:2):
1: -> 12:2
入队时是根据过滤器和包的特征决定走哪条路径,而出队时则取决于qdisc本身的调度算法,比如FIFO、优先级队列、SFQ的顺序调度等。
1.5、过滤器简介:
过滤器类别:
前面已经提到了过滤器用于将包分类到子类,那么具体是如何对包进行分类的呢?
tc支持很多类型的分类器,它们根据数据包相关的不同信息来作出决策。其中最常用的就是u32分类器,它根据数据包中的字段做出决策(例如源IP地址等)。还有比如fw分类器,根据防火墙如何标记数据包来做出决策,你可以使用iptables标记目标数据包,然后通过fw分类器进行过滤。另外还有诸如route分类器、cgroup分类器、bpf分类器等。
分类器一般接收以下几个公共的参数:
protocol:分类器接受的协议,通常你只接受IP流量。必须;
parent:分类器附加到哪个handle上。这个handle必须是一个已经存在的类。必须;
prio|perf:分类器的优先级。数字越小的越先进行匹配尝试;
handle:这个handle对于不同的过滤器表示不同的含义;
flowid:表示将filter匹配的包分类到指定的子类中去;
1)、u32分类器使用:
u32过滤器最简单的格式是设置一组选择器对包进行匹配,匹配的包分到特定的子类中,或者执行一个action。u32分类器提供了多种不同的选择器,可以大致分成特殊选择器和通用选择器两类。
u32特殊选择器:常用的有ip选择器和tcp选择器。特殊选择器简化了一些常用字段的设置,可以匹配包头中的各种字段,比如:
tc filter add dev eth0 protocol ip parent 1:0 prio 10 u32 match ip src 192.168.8.0/24 flowid 1:4
上例匹配ip源地址在192.168.8.0/24子网的包,将匹配的到使用flowid分类到1:4子类中(即qdisc层级树当中的1:4节点中去)。
tc filter add dev eth0 protocol ip parent 1:0 prio 10 u32 \
match ip protocol 0x6 0xff \
match tcp dport 53 0xffff \
flowid 1:2
上例匹配TCP协议(0x6)、且目的端口为53的包。
u32通用选择器:
特殊选择器可以改写成对应的通用选择器,通用选择器可以匹配IP(或上层)头中的几乎任何位(简单的说就是匹配数据包中的原始字段),不过相比特殊选择器较难编写和阅读。其语法如下:
match [ u32 | u16 | u8 ] PATTERN MASK at [OFFSET | nexthdr+OFFSET]
其中u32|u16|u8指定pattern的长度,分别为4个字节、2个字节、1个字节。PATTERN表示匹配的包的pattern,MASK告诉过滤器匹配哪些位,at表示从包的指定偏移处开始匹配。
来看一个例子:
tc filter add dev eth0 protocol ip parent 1:0 pref 10 u32 \
match u32 00100000 00ff0000 at 0 flowid 1:10
选择器会匹配IP头第二个字节为0x10的包,'at 0'表示从头开始匹配,mask为00ff0000所以只匹配第二个字节,pattern为00100000即第二个字节为0x10。
再来看另一个例子:
tc filter add dev eth0 protocol ip parent 1:0 pref 10 u32 \
match u32 00000016 0000ffff at nexthdr+0 flowid 1:10
nexthdr选项表示封装在IP包里的下一个头,即上层协议的头。at nexthdr+0表示从下一个头第一个字节开始匹配。因为mask为0000ffff,所以匹配发生在头的第三和第四个字节。在TCP和UDP协议中这两个字节是包的目的端口。数字是由大段格式给出的,所以pattern 00000016转换成十进制是22。即该选择器会匹配目的端口为22的包。
2、tc使用:
Linux 中的 QoS 分为入口 (Ingress) 部分和出口 (Egress) 部分,入口部分主要用于进行入口流量限速 (Policing),出口部分主要用于队列调度 (Queuing Scheduling)。大多数排队规则 (QDisc) 都是用于输出方向的,输入方向只有一个排队规则,即 Ingress-qdisc。
Ingress-qdisc 本身的功能很有限,输入方向只有一个排队规则,即 IngressqDisc(因为没有缓存只能实现流量的 Drop)但可用于重定向 Incoming-packets;通过 IngressqDisc 把输入方向的数据包重定向到虚拟设备 ifb,而 ifb 的输出方向可以配置多种 QDisc,就可以达到对输入方向的流量做队列调度的目的。
Linux流量控制主要分为建立队列、建立分类和建立过滤器三个方面。基本实现步骤为:
1.针对网络物理设备(如以太网卡eth0)绑定一个队列QDisc;
2.在该队列上建立分类class;
3.为每一分类建立一个基于路由的过滤器filter;
4.最后与过滤器相配合,建立特定的路由表;
2.1、tc配置规则案例解析:
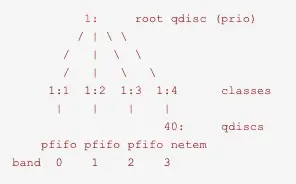
# tc qdisc add dev eth0 root handle 1: prio bands 4
# tc qdisc add dev eth0 parent 1:4 handle 40: netem loss 10% delay 40ms
# tc filter add dev eth0 protocol ip parent 1:0 prio 4 u32 match ip dst 192.168.190.7 match ip dport 36000 0xffff flowid 1:4
解析如下:
一行行来看,第一行在设备eth0上添加了一个root qdisc,句柄为1:,qdisc类型为prio,bands数为4。
prio是一个有类的qdisc。它的作用跟默认的qdisc pfifo_fast类似。pfifo_fast有三个所谓的band,不同band的流量具有不同的优先级。每个band内,则应用FIFO规则。
prio qdisc,默认会创建3个子类,包含纯FIFO qdisc,默认根据ToS位进行分类。可以使用过滤器来对流量进行分类,也可以在子类上附加其他qdisc替换默认的FIFO。
接下来看第二个命令,parent 1:4表示在子类1:4上,"handle 40:"表示句柄为"40:",netem表示添加一个"netem qdisc",loss 10% delay 40ms则是netem的参数,表示丢包10%、延迟40ms。netem是一个用于提供网络仿真功能的无类qdisc,可以模拟延迟、丢包、包重复、包失序等各种情况。
第三个命令则是添加了一个过滤器,parent 1:0表示在根节点上添加该过滤器,prio 4是过滤器的优先级,如果有很多过滤器会根据优先级的值按顺序进行尝试。u32表示使用u32分类器。match ip dst 192.168.190.7表示匹配ip地址为192.168.190.7的包,match ip dport 36000 0xffff表示匹配目的端口为36000的包,多个选择器之间是“与”的关系,flowid 1:4表示将匹配的包分类到1:4子类中。
所以最终的效果是,发往192.168.190.7且目的端口为36000的包,会分类到1:4子类,添加40ms的延迟,且有10%的丢包率。其他包则还是默认的行为,即根据ToS字段分类到1:1、1:2或1:3子类中,然后根据优先级依次发送。画出该例子的分层结构图,大致如下:
2.2、tc使用示例:
tc可以使用以下命令对QDisc、类和过滤器进行操作:
1.add:在一个节点里加入一个QDisc、类或者过滤器。添加时,需要传递一个祖先作为参数,传递参数时既可以使用ID也可以直接传递设备的根。如果要建立一个QDisc或者过滤器,可以使用句柄(handle)来命名;如果要建立一个类,可以使用类识别符(classid)来命名。
2.remove:删除有某个句柄(handle)指定的QDisc,根QDisc(root)也可以删除。被删除QDisc上的所有子类以及附属于各个类的过滤器都会被自动删除。
3.change:以替代的方式修改某些条目。除了句柄(handle)和祖先不能修改以外,change命令的语法和add命令相同。换句话说,change命令不能指定节点的位置。
4.replace对一个现有节点进行近于原子操作的删除/添加。如果节点不存在,这个命令就会建立节点。
5.link:只适用于DQisc,替代一个现有的节点。
2.2.1、tbf流量控制:
测试机器 192.188.88.128 与 192.188.88.129,在192.188.88.128上设置qdisc进行流量控制,控制128节点出去的带宽流量为10m。这里使用不可分类的排队规则qdisc tbf;
由于tbf 属于不可分类qdisc,配置的话只需在对应网卡中配置如下tc规则即可:
tc qdisc add dev enp1s0 handle 1: root tbf rate 10mbit burst 15k limit 20mbit
为enp1s0网卡创建一个qdisc根队列:root表示根队列,handle 表示队列的句柄为"1:"省略则随机给定,tbf表示添加的队列类型为tbf类型;
tbf可以配置的参数如下:
1.limit:队列可以保存的数据包的容量即带宽大小,bytes单位,对没有获取到tokent 排队中包进行限制,达到limit 限定则丢弃。或者可以通过另一个参数latency指定了一个数据包可以在队列中等待令牌可用的最长时间,该参数会影响令牌桶大小、以及令牌生成速率的计算。这两个参数是互斥的,配置时同时指定其中一个;
2.burst:桶的容量,bytes单位。也就是一次可以突发传输的数据量,越大的速率约需要越大的令牌桶,如果大速率配置一个小桶,会导致每次软中断调度只能发送较小的数据量,最终的结果就是速率难以达到实际配置的值;
3.rate:即令牌生成的速率,也就是要限制的数据传输速率;
4.mpu:指定最少需要的令牌数量;
5.peakrate:桶的最大消耗速率,tbf通过添加第二个容量较小的桶来实现;
6.mtu/minburst:第二个桶的容量,指定了小队列的长度,要想实现精准的控制,该值应该是网络设备的MTU;
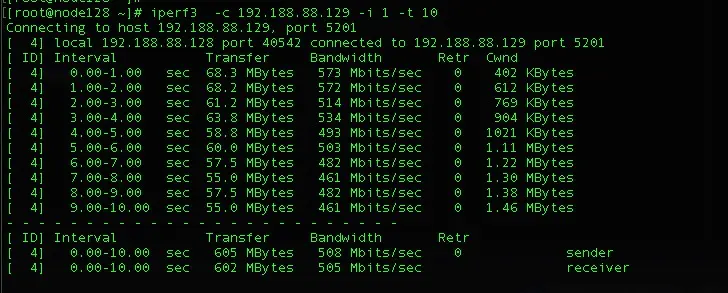
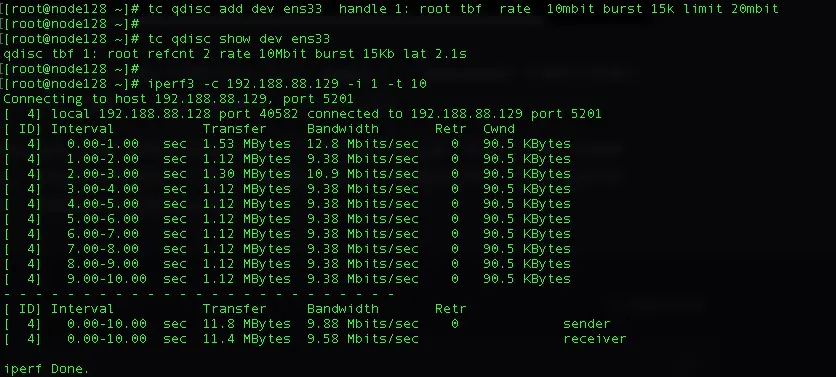
1)、配置tc规则前192.188.88.128机器上的网络流量如下:
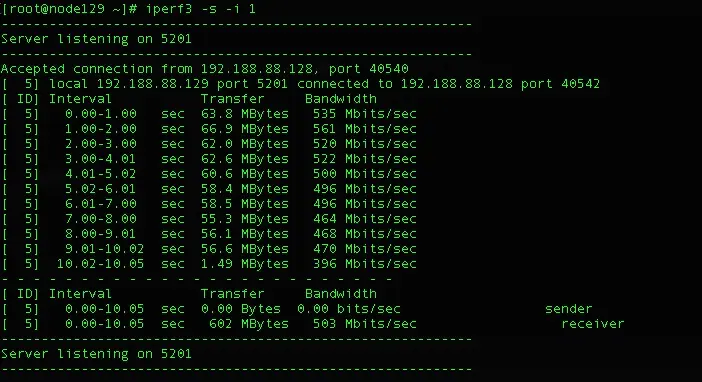
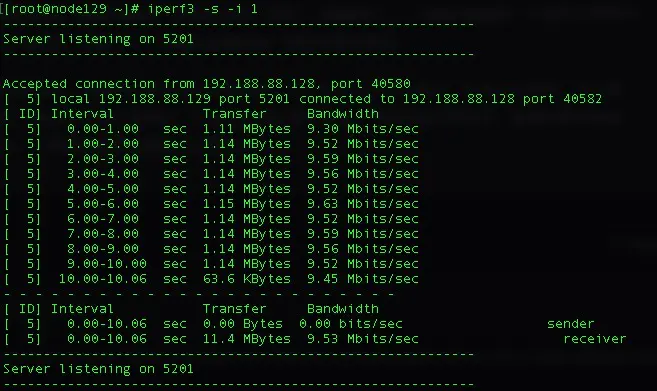
配置tc规则前192.188.88.129机器上的网络流量如下:
2)、配置tc规则后192.188.88.128机器上的网络流量如下:
配置tc规则后192.188.88.129机器上的网络流量如下:
3、tc工具常用命令:
查看所有网卡的qdisc队列规则设置情况
# tc qdisc ls
查看指定网卡的详细队列规则
# tc -s -d qdisc ls dev eth0
查看指定网卡的的分类状况
# tc -s -d class ls dev eth0
查看指定网卡的的过滤器状况
# tc -s -d filter ls dev eth0
清除所有队列规则
# tc qdis del dev eth0 root
修改tc规则
# tc qdisc change dev ens33 root tbf rate 10mbit burst 2k latency 5ms
4、RHELV8 流量控制(网络配置与管理手册第32章)
Linux提供管理和操作数据包传输的工具。Linux内核流量控制(TC)子系统帮助进行策略、分类、控制以及调度网络流量。TC 还可以通过使用过滤器和动作在分类过程中利用数据包内容分栏。TC 子系统使用排队规则(qdisc)来达到此目的,这是其架构的基本元素。
调度机制在进入或退出不同的队列前确定或者重新安排数据包。最常见的调度程序是先入先出(FIFO)调度程序。您可以使用 tc 工具临时执行 qdiscs 操作,也可以使用 NetworkManager 永久执行操作。在 RHEL 中可以使用各种方法配置默认队列规则来管理网络接口上的流量。
32.1. 排队规则概述
排队规则(qdiscs)帮助排队,之后通过网络接口调度流量传输。qdisc 有两个操作:
排队请求,以便在以后传输时对数据包进行排队
出队请求,以便可以选择其中一个排队的数据包进行即时传输。
每个 qdisc 都有一个 16 位十六进制标识数字,称为句柄,带有一个附加的冒号,如 1: 或 abcd:这个数字被称为 qdisc 主号码。如果 qdisc 有类,则标识符是由两个数字组成的对,主号码在次要号码之前,即 <major>:<minor>,例如 abcd:1。次要号码的编号方案取决于 qdisc 类型。有时编号是系统化的,其中第一类的 ID 为 <major>:1,第二类的 ID 为 <major>:2,等等。一些 qdiscs 允许用户在创建类时随机设置类的次要号码。
类 qdiscs
存在不同类型的 qdiscs,帮助向和从网络接口传输数据包。您可以使用根、父或子类配置 qdiscs。子对象可以被附加的位置称为类。qdisc 中的类是灵活的,始终包含多个子类或一个子类 qdisc。不禁止包含类 qdisc 本身的类,这有助于实现复杂的流量控制场景。
类 qdiscs 本身不存储任何数据包。相反,它们根据特定于 qdisc 的标准,将排队和出队请求传到它们其中的一个子类。最后,这个递归数据包传递最终结束保存数据包的位置(在出现排队时从中提取)。
无类别 qdiscs
有些 qdiscs 不包含子类,它们称为无类别 qdiscs。与类 qdiscs 相比,无类别 qdiscs 需要较少的自定义。通常情况下,将它们附加到接口就足够了。
32.2. 使用 tc 工具检查网络接口的 qdiscs
默认情况下,RHEL 系统使用 fq_codel qdisc。可以使用 tc 工具检查 qdisc 计数器。
可选:查看当前的 qdisc :
# tc qdisc show dev enp0s1
检查当前的 qdisc 计数器:
# tc -s qdisc show dev enp0s1
qdisc fq_codel 0: root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5.0ms interval 100.0ms memory_limit 32Mb ecn
Sent 1008193 bytes 5559 pkt (dropped 233, overlimits 55 requeues 77)
backlog 0b 0p requeues 0
不过CentOS 7是这样的:
qdisc pfifo_fast 0: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 213348390640 bytes 2664531755 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
dropped - 由于所有队列已满而丢弃数据包的次数
overlimits - 配置的链路容量已满的次数
sent - 出队的数量
32.3. 更新默认的 qdisc
如果使用当前的 qdisc 观察网络数据包丢失情况,可以根据您的网络要求更改 qdisc。
查看当前的默认的 qdisc:
# sysctl -a | grep qdisc
net.core.default_qdisc = fq_codel
查看当前以太网连接的 qdisc:
# tc -s qdisc show dev enp0s1
qdisc fq_codel 0: root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5.0ms interval 100.0ms memory_limit 32Mb ecn
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
maxpacket 0 drop_overlimit 0 new_flow_count 0 ecn_mark 0
new_flows_len 0 old_flows_len 0
更新现有的 qdisc:
# sysctl -w net.core.default_qdisc=pfifo_fast
要应用更改,请重新加载网络驱动程序:
# modprobe -r NETWORKDRIVERNAME
# modprobe NETWORKDRIVERNAME
启动网络接口:
# ip link set enp0s1 up
验证
查看以太网连接的 qdisc :
# tc -s qdisc show dev enp0s1
qdisc pfifo_fast 0: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 373186 bytes 5333 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
....
32.4. 使用 tc 工具临时设置网络接口的当前 qdisc
可以更新当前的 qdisc 而不更改默认的 qdisc 。
可选:查看当前的 qdisc :
# tc -s qdisc show dev enp0s1
更新当前的 qdisc :
# tc qdisc replace dev enp0s1 root htb
验证
查看更新后的当前 qdisc :
# tc -s qdisc show dev enp0s1
qdisc htb 8001: root refcnt 2 r2q 10 default 0 direct_packets_stat 0 direct_qlen 1000
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
32.5. 使用 NetworkManager 永久设置当前网络接口的 qdisc
可以更新 NetworkManager 连接当前的 qdisc 值。
可选:查看当前的 qdisc :
# tc qdisc show dev enp0s1
qdisc fq_codel 0: root refcnt 2
更新当前的 qdisc :
# nmcli connection modify enp0s1 tc.qdiscs 'root pfifo_fast'
可选:要在现有的 qdisc 上添加另一个 qdisc,请使用 +tc.qdisc 选项:
# nmcli connection modify enp0s1 +tc.qdisc 'ingress handle ffff:'
激活更改:
# nmcli connection up enp0s1
验证
查看网络接口当前的 qdisc:
# tc qdisc show dev enp0s1
qdisc pfifo_fast 8001: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc ingress ffff: parent ffff:fff1 ----------------
其他资源:更多操作可查看系统上的 nm-settings(5) 手册页。
32.6. RHEL 中可用的 qdiscs
每个 qdisc 解决唯一的与网络相关的问题。以下是 RHEL 中可用的 qdiscs 列表,可以使用以下任何一个 qdisc 来根据您的网络要求来塑造网络流量。
表 32.1. RHEL 中的可用调度程序
qdisc 名称 包含在 卸载支持
异步传输模式(ATM) kernel-modules-extra
基于类的队列 kernel-modules-extra
基于信用的塑造程序 kernel-modules-extra 是
CHOose 和 Keep 用于有响应的流量,CHOose 和 Kill 用于没有响应的流量(CHOKE) kernel-modules-extra
受控的延迟(CoDel) kernel-core
轮循(DRR) kernel-modules-extra
Differentiated Services marker (DSMARK) kernel-modules-extra
Enhanced Transmission Selection (ETS) kernel-modules-extra 是
Fair Queue (FQ) kernel-core
Fair Queuing Controlled Delay (FQ_CODel) kernel-core
Generalized Random Early Detection (GRED) kernel-modules-extra
Hierarchical Fair Service Curve (HSFC) kernel-core
Heavy-Hitter Filter (HHF) kernel-core
Hierarchy Token Bucket (HTB) kernel-core
INGRESS kernel-core 是
Multi Queue Priority (MQPRIO) kernel-modules-extra 是
Multiqueue (MULTIQ) kernel-modules-extra 是
Network Emulator (NETEM) kernel-modules-extra
Proportional Integral-controller Enhanced (PIE) kernel-core
PLUG kernel-core
Quick Fair Queueing (QFQ) kernel-modules-extra
Random Early Detection (RED) kernel-modules-extra 是
Stochastic Fair Blue (SFB) kernel-modules-extra
Stochastic Fairness Queueing (SFQ) kernel-core
Token Bucket Filter (TBF) kernel-core 是
Trivial Link Equalizer (TEQL) kernel-modules-extra
重要
qdisc 卸载需要对 NIC 的硬件和驱动程序的支持。
rhelinux-traffic-control_configuring-and-managing-networking
5、快速回看
TC(Traffic Control)是一个用于流量控制和QoS(Quality of Service)管理的Linux命令。它允许用户限制网络流量的带宽、延迟和丢包,并将流量根据特定的规则进行分类和处理。
1. tc命令:tc用于配置Linux内核中的流量控制规则。它可以控制网络流量的传输速度、延迟和丢包率等。
语法:tc [options] command action
示例:tc qdisc show
tc qdisc add dev eth0 root tbf rate 1mbit burst 10kb latency 50ms
解析:上述示例中,第一条命令用于显示当前系统中的队列规则;第二条命令用于添加一个根队列规则,限制eth0接口的传输速度为1mbit,爆发大小为10kb,延迟为50ms。
2. tc qdisc命令:tc qdisc命令用于管理队列规则。
语法:tc qdisc [options] command
示例:tc qdisc add dev eth0 root tbf rate 1mbit burst 10kb latency 50ms
tc qdisc del dev eth0 root
解析:上述示例中,第一条命令用于添加一个根队列规则,限制eth0接口的传输速度为1mbit,爆发大小为10kb,延迟为50ms;第二条命令用于删除eth0接口上的根队列规则。
3. tc class命令:tc class命令用于管理分类规则。
语法:tc class [options] command
示例:tc class add dev eth0 parent 1: classid 1:1 htb rate 1mbit prio 1
tc class del dev eth0 parent 1:
解析:上述示例中,第一条命令用于添加一个分类规则,将来自eth0接口的流量分类到1:1类中,限制传输速度为1mbit,优先级为1;第二条命令用于删除eth0接口上所有的分类规则。
4. tc filter命令:tc filter命令用于管理过滤器规则。
语法:tc filter [options] command
示例:tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip dst 192.168.1.1 flowid 1:1
tc filter del dev eth0 parent 1:
解析:上述示例中,第一条命令用于添加一个过滤器规则,将来自eth0接口的目标IP地址为192.168.1.1的流量匹配到1:1类中;第二条命令用于删除eth0接口上所有的过滤器规则。
TC命令的详细解释:
tc [ OPTIONS ] OBJECT { COMMAND | help }
tc [-force] [-OK] -batch filename
where
OBJECT := { qdisc | class | filter | action | monitor }
OPTIONS := { -s[tatistics] | -d[etails] | -r[aw] | -p[retty] | -b[atch] [filename] | -n[etns] name }
基本语法格式如下:
tc qdisc|class|filter [ OPTIONS ] [ add|replace|change|delete ]
qdisc:队列规则,用于定义输入/输出队列
class:过滤类,用于定义流量分类和优先级
filter:过滤器,用于定义流量过滤条件
在基本语法的基础上,还可以添加一系列的选项(OPTIONS)和操作动作(add、replace、change、delete),来实现具体的操作。
常用选项:
tc 命令支持多种选项来指定具体的配置参数,常用的选项有:
dev:指定网络接口名称
parent:指定父类别
classid:指定类别ID
htb:指定类别类型为 htb
rate:指定速率
protocol:指定协议类型
prio:指定优先级
u32:指定过滤器类型为 u32
match:指定过滤条件
创建队列规则(qdisc)
使用 tc qdisc add 命令创建队列规则,指定具体的 qdisc 类型和配置参数。
tc qdisc add dev eth0 root:创建一个默认的队列规则,默认的队列规则会将所有流量转发到默认的类别中。
tc qdisc add dev eth0 parent 1:1 handle 1: pfifo limit 1000:创建一个 pfifo 类型的队列规则,将父类别为 1:1 的流量的处理句柄设置为 1:1,并限制队列的长度为1000。
创建过滤类别(class)
使用 tc class add 命令创建过滤类别,指定具体的 class 类型和配置参数。
tc class add dev eth0 parent 1: classid 1:11 htb rate 1000kbps:创建一个 htb 类型的过滤类别,将父类别为 1: 的流量的子类别设置为 1:11,并将速率限制为1000kbps。
tc class add dev eth0 parent 1:1 classid 1:11 htb rate 1000kbps:创建一个 htb 类型的过滤类别,将父类别为 1:1 的流量的子类别设置为 1:11,并将速率限制为1000kbps。
创建过滤器(filter)
使用 tc filter add 命令创建过滤器,指定具体的过滤器类型和过滤条件。
tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip src 192.168.1.0/24 flowid 1:11:创建一个IP过滤器,将源IP为 192.168.1.0/24 的流量转发到 1:11 的类别中。
查看和修改队列规则、过滤类别和过滤器
使用 tc qdisc | class | filter show 命令可以分别查看当前系统中的队列规则、过滤类别和过滤器。使用 tc qdisc | class | filter change 命令可以修改已经存在的队列规则、过滤类别和过滤器。
删除队列规则、过滤类别和过滤器
使用 tc qdisc | class | filter delete 命令可以删除已经存在的队列规则、过滤类别和过滤器。
1. tc qdisc:这个命令是Traffic Control的主要命令,用于配置队列调度器。通过设置不同的队列调度算法(如FIFO、SFQ、HTB等),用户可以对网络流量进行管理和控制。
2. tc class:这个命令用于配置分类器,它可以将网络流量分为多个类别,并为每个类别分配带宽。用户可以根据不同的规则和条件(如IP地址、端口号等),将流量分组为不同的类别。
3. tc filter:这个命令用于配置过滤器,它可以根据特定的规则来过滤网络流量。用户可以根据源IP地址、目标IP地址、协议等条件来设置过滤规则,并对匹配的流量进行相应的处理。
4. tc rate:这个命令用于设置带宽限制。用户可以通过指定带宽值和单位(如bps、kbps、mbps),来限制流量的传输速率。
5. tc delay:这个命令用于设置延迟。用户可以通过指定延迟值和单位(如ms、s),来模拟网络延迟,从而对网络流量进行测试和分析。
6. tc loss:这个命令用于设置丢包率。用户可以通过指定丢包率的百分比,来模拟网络丢包情况,从而对网络流量进行测试和分析。
除了以上几个主要命令外,TC还提供了许多其他命令和选项,用于配置和管理网络流量控制。用户可以通过查看man页面或其他文档,了解更多关于TC命令的详细信息和用法。另外,TC命令也可以与其他工具和命令(如iptables、ip、tcpreplay等)结合使用,以实现更复杂的网络流量控制和管理功能。
实例演示
以下是一个使用 tc 命令进行流量控制管理的示例:
1. 查看当前网络接口
假设要对 eth0 接口进行流量控制管理。
2. 创建队列规则
tc qdisc add dev eth0 root
3. 创建过滤类别
tc class add dev eth0 parent 1: classid 1:11 htb rate 1000kbps
4. 创建过滤器
tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip src 192.168.1.0/24 flowid 1:11
5. 查看和修改队列规则、过滤类别和过滤器
tc qdisc | class | filter show
可以使用 tc qdisc | class | filter change 命令修改已经存在的队列规则、过滤类别和过滤器。
6. 删除队列规则、过滤类别和过滤器
tc qdisc delete dev eth0 root
tc class delete dev eth0 parent 1: classid 1:11 htb rate 1000kbps
tc filter delete dev eth0 parent 1: protocol ip prio 1 u32 match ip src 192.168.1.0/24 flowid 1:11
模拟网络延迟、带宽限制、数据包丢失等,以下是一个使用 tc 模拟网络延迟的基本步骤:
1.查看当前的 qdisc(队列规则)和 filter(过滤器)
首先确保要处理网络接口没有设置任何 qdisc。可以使用以下命令查看:
tc qdisc show dev <interface>
其中 <interface> 是网络接口名称,如 eth0。
2. 设置根 qdisc
为了应用 tc 规则,需要在网络接口上设置一个 qdisc。最常用的 qdisc 是 handleroot,但在这里将使用 htb(层次化令牌桶)作为示例,因为它允许设置更复杂的规则(尽管对于简单的延迟模拟,这并不是必需的)。
tc qdisc add dev <interface> root handle 1: htb
3. 添加延迟规则
现在可以添加一个延迟规则。假设想为所有从 <interface> 发送的数据包添加 100ms 的延迟:
tc qdisc add dev <interface> parent 1:1 netem delay 100ms
注意:上面的命令中,1:1 是一个子 qdisc 的句柄。在 htb qdisc 下,通常使用这种子 qdisc 来应用特定的规则。但对于简单的延迟模拟,也可以直接使用 root qdisc,即:
tc qdisc change dev <interface> root netem delay 100ms
4. 验证设置
可以使用 ping 或其他网络工具来验证延迟是否已应用。
5. 删除规则
当完成模拟并希望删除这些规则时,可以使用以下命令:
tc qdisc del dev <interface> root
这将删除网络接口上的所有 qdisc 和相关的规则。
6. 注意
tc 规则在重启或网络接口重新加载后将失效。如果希望这些规则在重启后仍然生效,可能需要考虑将它们添加到启动脚本或 systemd 服务中。但注意,这样设定可能会影响生产环境的网络性能。始终在测试环境中验证更改。
将 eth0 网卡的上传和下载网速限制为 3M/s,在root用户账户下执行
tc qdisc add dev eth0 root handle 1: htb default 12:在 eth0 网卡上添加一个根排队规则,并设置默认的类别为 12。
tc class add dev eth0 parent 1: classid 1:1 htb rate 3mbit burst 15k:在根排队规则下添加一个子类别,并设置上传速率为 3Mbit/s,令牌桶大小为 15KB。
tc class add dev eth0 parent 1:1 classid 1:12 htb rate 3mbit burst 15k:在之前创建的子类别下再添加一个子类别,同样设置上传速率为 3Mbit/s,令牌桶大小为 15KB。
可以使用tc和netem模块来限制流量速率,但这将限制计算机网络接口的速率与性能表现。
tc 使用令牌桶过滤器(TBF)来控制速率。
TBF的一个示例如下(参考此处):
要连接最大持续速率为0.5mbit / s,最大峰值速率为1.0mbit/s,5kb的TBF,并计算出预桶队列大小限制,因此,TBF最多导致70ms的延迟,并具有完美的峰值速率行为, 问题:
# tc qdisc add dev eth0 root tbf rate 0.5mbit burst 5kb latency 70ms peakrate 1mbit minburst 1540
usign tc和netem的另一个示例如下(在此处找到):
netem功能没有内置的速率控制,而是使用其他进行速率控制的功能之一。在此示例中使用令牌桶过滤器(TBF)来限制输出。
添加通过接口eth0进入/进入每个数据包的延迟
# tc qdisc add dev eth0 root handle 1:0 netem delay 100ms
添加以tbf为单位的数据速率,数据包缓冲区大小和最大突发限制
# tc qdisc add dev eth0 parent 1:1 handle 10: tbf rate 256kbit buffer 1600 limit 3000
查看在tc中为接口eth0分配的规则列表
# tc -s qdisc ls dev eth0
上面命令的输出如下
qdisc netem 1: limit 1000 delay 100.0ms
Sent 0 bytes 0 pkts (dropped 0, overlimits 0 )
qdisc tbf 10: rate 256Kbit burst 1599b lat 26.6ms
Sent 0 bytes 0 pkts (dropped 0, overlimits 0 )
检查缓冲区和限制选项,因为您可能会发现需要更大的默认值(以字节为单位)。
5.1、tc中htb算法下的r2q和quantum
tc qdisc add dev eth0 root handle 1: htb r2q 10 default 10
r2q:在规则中的作用是用来分配剩余带宽的全局变量,其默认值为10,此时最实用的规则的速度为15KBps(120kbit)。
quantum与r2q的关系为quantum=rate/r2q,quantum的值必须在1500到60000之间,值越小越好。
每个规则的quantum的值就是从父类借用带宽的因子(也就是每个子类每次可以从父类借用空闲带宽的大小),也可以说是与其他子类同时从父类借带宽的比例。
rate单位为Mbit时,上限临界值为0.7左右,即r2q最小要设为0.7;rate单位为Gbit时,上限临界值为700左右,即r2q最小要设为700。
tc returns: "quantum of class # is small. Consider r2q change."
Bug Description
It is documented in HTB manual. The complaint was not displayed before and sharing was silently wrong. Quantum of leaf should be between 1500 and 60000 and it is computed as rate/r2q (or can be supplied independly). So that if your maximal leaf rate is 1Mbit (120000Bps) then r2q should be 3. If max rate is 10kbit (1200Bps) then r2q should be 1. It is warning only and will not affect functionality, only precision.
Smallest rate: 16kbit = 2 kilobyt / r2q (=10) = 200. And this is < 1500. So you get warnings.
Biggest rate : 100mbit = 12.5 mbyte / r2q = 1.2 Mbyte > 60.000. So you get warnings.
If you do tc qdisc add dev eth0 root handle 1: htb default 10 r2q 1
Smallest rate : 16kbit = 2kilobyte / r2k = 2000. And this is > 1500. So no warnings.
Biggest rate : 100mbit = 12.5 mbyte / r2q = 12.5 Mbyte > 60.000. So you get warnings.
But you can overrule the quantum:
tc class add dev eth0 parent 1:1 classid 1:11 htb rate 128kbit burst 2k quantum 60000
Quantum is used when 2 classes are getting more bandwidth then the rate. So it's only important for sharing the remaining bandwidth. In that case, each class may send quantum bytes.
tc qdisc add dev eth0 root handle 1: htb r2q 10 default 10
r2q:在规则中的作用是用来分配剩余带宽的全局变量,其默认值为10,此时最实用的规则的速度为15KBps(120kbit)。
quantum与r2q的关系为quantum=rate/r2q,quantum的值必须在1500到60000之间,值越小越好。每个规则的quantum的值就是从父类借用带宽的因子(也就是每个子类每次可以从父类借用空闲带宽的大小)也可以说是与其他子类同时从父类借带宽的比例。
TC HTB r2q
HTB:quantum of class 10001 is big. Consider r2q change.
根据HTB的官方文档显示,quantum是在可以“借”的情况下一次可以“借”多少,并且说这个值最好尽量的小,但要大于MTU;而且这个值是不用手动设置,它会根据r2q的值计算出来。
Changing burst will not remove the warning. r2q is "rate to quantum" is used to calculate the quantum for each class : quantum = rate / r2q. Quantum must be 1500 < quantum < 60000. Otherwise you will get warnings from the kernel.
Solution : choose r2q so for each class 1500 < quantum < 60000
Or choose the best r2q you can and specify the quantum manually if you add a class.
> tc qdisc add dev eth0 root handle 1: htb default 10
Default r2q = 10.
> tc class add dev eth0 parent 1: classid 1:1 htb rate 100mbit burst 2k
> tc class add dev eth0 parent 1:1 classid 1:10 htb rate 80mbit ceil 100mbit burst 2k
> tc class add dev eth0 parent 1:1 classid 1:11 htb rate 128kbit burst 2k
> tc class add dev eth0 parent 1:11 classid 1:21 htb rate 16kbit ceil 56kbit burst 2k
> tc class add dev eth0 parent 1:11 classid 1:22 htb rate 16kbit ceil 40kbit burst 2k
> tc class add dev eth0 parent 1:11 classid 1:23 htb rate 16kbit ceil 72kbit burst 2k
> tc class add dev eth0 parent 1:11 classid 1:24 htb rate 16kbit ceil 64kbit burst 2k
> tc class add dev eth0 parent 1:11 classid 1:25 htb rate 16kbit ceil 40kbit burst 2k
> tc class add dev eth0 parent 1:11 classid 1:26 htb rate 16kbit ceil 40kbit burst 2k
> tc class add dev eth0 parent 1:11 classid 1:27 htb rate 16kbit ceil 32kbit burst 2k
> tc class add dev eth0 parent 1:11 classid 1:28 htb rate 16kbit ceil 56kbit burst 2k
Smallest rate : 16kbit = 2 kilobyte / r2q (=10) = 200. And this is < 1500. So you get warnings.
Biggest rate : 100mbit = 12.5 mbyte / r2q = 1.2 Mbyte > 60.000. So you get warnings.
If you do
tc qdisc add dev eth0 root handle 1: htb default 10 r2q 1
Smallest rate: 16kbit = 2kilobyte / r2k = 2000. And this is > 1500. So no warnings.
Biggest rate: 100mbit = 12.5 mbyte / r2q = 12.5 Mbyte > 60.000. So you get warnings. But you can overrule the quantum:
tc class add dev eth0 parent 1:1 classid 1:11 htb rate 128kbit burst 2k quantum 60000
Quantum is used when 2 classes are getting more bandwidth then the rate. So it's only important for sharing the remaining bandwidth. In that case, each class may send quantum bytes.
在centos7偶然看到的内核事件:
[265.642804] HTB: quantum of class 10010 is big. Consider r2q change.
[412.670879] htb: too many events!
HTB示例
# add qdisc
tc qdisc add dev eth0 root handle 1: htb default 2 r2q 100
# add default class
tc class add dev eth0 parent 1:0 classid 1:1 htb rate 1000mbit ceil 1000mbit
tc class add dev eth0 parent 1:1 classid 1:2 htb prio 5 rate 1000mbit ceil 1000mbit
tc qdisc add dev eth0 parent 1:2 handle 2: pfifo limit 500
# add default filter
tc filter add dev eth0 parent 1:0 prio 5 protocol ip u32
tc filter add dev eth0 parent 1:0 prio 5 handle 3: protocol ip u32 divisor 256
tc filter add dev eth0 parent 1:0 prio 5 protocol ip u32 ht 800:: match ip src 192.168.0.0/16 hashkey mask 0x000000ff at 12 link 3:
# add egress rules for 192.168.0.9
tc class add dev eth0 parent 1:1 classid 1:9 htb prio 5 rate 3mbit ceil 3mbit
tc qdisc add dev eth0 parent 1:9 handle 9: pfifo limit 500
tc filter add dev eth0 parent 1: protocol ip prio 5 u32 ht 3:9: match ip src "192.168.0.9" flowid 1:9
5.2、模拟延迟传输简介
netem是Linux-v2.6及以上内核版本提供的一个网络模拟功能模块。该功能模块可以用来在性能良好的局域网中,模拟出复杂的互联网传输性能,诸如低带宽、传输延迟、丢包等等情况。
tc是Linux 系统中的一个工具,全名为 traffic control(流量控制)。它只能控制发包动作,不能控制收包动作,同时它直接对物理接口生效,如果控制了物理的 eth0,那么逻辑网卡(比如 eth0:1)也会受到影响;反之,如果在逻辑网卡上做控制,该控制可能是无效的。
模拟网络抖动
# tc qdisc add dev eth0 root netem delay 100ms
该命令将 eth0 网卡的传输设置为延迟 100 毫秒发送。
更真实的情况下,延迟值不会这么精确,会有一定的波动,可以用下面的情况来模拟出
带有波动性的延迟值:
# tc qdisc add dev eth0 root netem delay 100ms 10ms
该命令将 eth0 网卡的传输设置为延迟 100ms ± 10ms (90 ~ 110 ms 之间的任意值)发送。
还可以更进一步加强这种波动的随机性:
# tc qdisc add dev eth0 root netem delay 100ms 10ms 30%
该命令将 eth0 网卡的传输设置为 100ms,同时大约有 30% 的包会延迟 ± 10ms 发送。在ping该主机时可以看出数据明显的波动性。
# tc qdisc add dev eth0 root netem loss 1%
该命令将 eth0 网卡的传输设置为随机丢掉 1% 的数据包。
# tc qdisc add dev eth0 root netem loss 10%
显示 16 个包只有 13 个收到了。也可以设置丢包的成功率:
# tc qdisc add dev eth0 root netem loss 1% 30%
该命令将 eth0 网卡的传输设置为随机丢掉 1% 的数据包,成功率为 30%。
删除网卡上面的相关配置:将之前命令中的 add 改为 del 即可删除配置:
# tc qdisc del dev eth0 XXX (自己加的配置)该命令将删除 eth0 网卡的相关传输配置。
至此已经可以通过 TC 在测试环境中模拟一定的网络延时和丢包的情况。
模拟包重复:
# tc qdisc add dev eth0 root netem duplicate 1%
该命令将 eth0 网卡的传输设置为随机产生 1% 的重复数据包。
模拟数据包损坏:
# tc qdisc add dev eth0 root netem corrupt 0.2%
该命令将 eth0 网卡的传输设置为随机产生 0.2% 的损坏的数据包(内核版本需在 2.6.16 以上)。
模拟数据包乱序:
# tc qdisc change dev eth0 root netem delay 10ms reorder 25% 50%
该命令将 eth0 网卡的传输设置为:有 25% 的数据包(50%相关)会被立即发送,其他的延迟10秒。
新版本中如下命令也会在一定程度上打乱发包的次序:
# tc qdisc add dev eth0 root netem delay 100ms 10ms
查看已经配置的网络条件:
# tc qdisc show dev eth0
该命令将查看并显示 eth0 网卡的相关传输配置。
6、小结
6.1 小结1
TC 是一个层次式的过滤框架,包括三个基本的构成块:队列规定qdisc(queueing discipline)、类(class)和分类器(Classifiers:Filter)。
在 Linux 中的 tc 有两种控制方法:CBQ 和 HTB,HTB 是设计用来替换 CBQ 的。
TC中的队列(queueing discipline):用来实现控制网络的收发速度。通过队列 linux 可以将网络数据包缓存起来,然后根据用户的设置,在尽量不中断连接(如TCP)的前提下来平滑网络流量。需要注意的是,linux 对接收队列的控制不够好,所以一般只用发送队列,即“控发不控收”。它封装了其他两个主要 TC 组件(类和过滤器)。内核如果需要通过某个网络接口发送数据包,它都需要按照为这个接口配置的qdisc(排队规则)把数据包加入队列。然后,内核会尽可能多地从 qdisc 里面取出数据包,把它们交给网络适配器驱动模块。
最简单的 QDisc 是 pfifo 它不对进入的数据包做任何的处理,数据包采用先入先出的方式通过队列。不过它会保存网络接口一时无法处理的数据包。队列规则包括FIFO(先进先出),RED(随机早期探测),SFQ(随机公平队列)和令牌桶(Token Bucket),类基队列(CBQ),CBQ 是一种超级队列,即它能够包含其它队列(甚至其它 CBQ)。
TC 中的 Class 类
class 用来表示控制策略。很显然,很多时候很可能要对不同的 IP 实行不同的流量控制策略,这时候就得用不同的 class 来表示不同的控制策略了。
TC 中的 Filter 规则
filter 用来将用户划入到具体的控制策略中(即不同的 class 中)。比如现在想对xxa,xxb两个 IP 实行不同的控制策略(A,B),这时可用 filter 将 xxa 划入到控制策略 A,将 xxb 划入到控制策略 B;filter 划分的标志位可用 u32 打标功能或 IPtables 的 set-mark (大多使用iptables 来做标记)功能来实现。
目前tc可以使用的过滤器有:fwmark 分类器,u32 分类器,基于路由的分类器和RSVP分类器(分别用于 IPV6、IPV4)等;其中,fwmark 分类器允许我们使用 Linux netfilter 代码选择流量,而 u32 分类器允许选择基于 ANY 头的流量。需要注意的是,filter (过滤器)是在 QDisc 内部,它们不能作为主体。
TC 的应用流程
数据包->iptables(在通过 iptables 时,iptables 根据不同的 ip 来设置不同的 mark)->TC(class)->TC(queue)
应用举例
假设 eth0 位是服务器的外网网络接口。开始配置之前,先要清除 eth0 所有队列规则
tc qdisc del dev eth0 root
1)定义最顶层(根)队列规则,并指定 default 类别编号
tc qdisc add dev eth0 root handle 1: htb default 2
2)定义第一层的 1:1 类别 (速度)本来是要多定义第二层叶类别,但目前来看,这个应用中就可以了
tc class add dev eth0 parent 1:1 classid 1:2 htb rate 98mbit ceil 100mbit prio 2
tc class add dev eth0 parent 1:1 classid 1:3 htb rate 1mbit ceil 2mbit prio 2
注:以上就是控制输出服务器的速度,一个为 98M,一个为 2M。
rate: 是一个类保证得到的带宽值。如果有不只一个类,请保证所有子类总和是小于或等于父类。
prio:用来指示借用带宽时的竞争力,prio 越小,优先级越高,竞争力越强。
ceil:ceil 是一个类最大能得到的带宽值。
同时为了不使一个会话永占带宽,添加随即公平队列 sfq。
tc qdisc add dev eth0 parent 1:2 handle 2: sfq perturb 10
tc qdisc add dev eth0 parent 1:3 handle 3: sfq perturb 10
也可以合并一处来写:
3)设定过滤器
过滤器可以使用本身的 u32 也可以使用 iptables 来打上标记;指定在 root 类 1:0 中,对 192..168.0.2 的过滤,使用 1:2 的规则,来给他 98M 的速度,写法就如下:
tc filter add dev eth0 protocol ip parent 1:0 u32 match ip src 192.168.0.2 flowid 1:2
tc filter add dev eth0 protocol ip parent 1:0 u32 match ip src 192.168.0.1 flowid 1:3
如果是所有 ip 写法就如下:
tc filter add dev eth0 protocol ip parent 1: prio 50 u32 match ipdst 0.0.0.0/0 flowid 1:10
使用 Iptables 来配合过滤器
还可以使用这个方法,但需要借助下面的 iptables 的命令来做标记了
tc filter add dev eth0 parent 1: protocol ip prio 1 handle 10 fw flowid 1:2
tc filter add dev eth0 parent 1: protocol ip prio 1 handle 20 fw flowid 1:3
iptables 只要打上记号就行了:
iptables -t mangle -A POSTROUTING -d 192.168.0.2 -j MARK --set-mark 10
iptables -t mangle -A POSTROUTING -d 192.168.0.3 -j MARK --set-mark 20
TC 对最对高速度的控制
rate ceiling 速率限度
参数 ceil 指定了一个类可以用的最大带宽,用来限制类可以借用多少带宽;缺省的 ceil 是和速率一样。
这个特性对于 ISP 是很有用的,因为他们一般限制被服务的用户的总量即使其他用户没有请求服务(ISP很想用户付更多的钱得到更好的服务),注意根类是不允许被借用的,所以没有指定 ceil。
注意:ceil 的数值应该至少和它所在的类的速率一样高,也就是说 ceil 应该至少和它的任何一个子类一样高。
Burst 突发
网络硬件只能在一个时间发送一个包这仅仅取决于一个硬件的速率。链路共享软件可以利用这个能力动态产生多个连接运行在不同的速度,所以速率和 ceil 不是一个即时度量只是一个在一个时间里发送包的平均值;实际的情况是怎样使一个流量很小的类在某个时间类以最大的速率提供给其他类,burst 和 cburst 参数控制多少数据可以以硬件最大的速度不费力的发送给需要的其他类。
如果 cburst 小于一个理论上的数据包他形成的突发不会超过 ceil 速率,同样的方法 TBF 的最高速率也是这样。可能会问为什么需要 bursts。因为它可以很容易的提高向应速度在一个很拥挤的链路上。比如 Web 流量是突发的,你访问主页,突发的获得并阅读;在空闲的时间 burst 将再"charge"一次。
注意:burst 和 cburst 至少要和其子类的值一样大。
TC 命令格式:
tc qdisc [ add | change | replace | link ] dev DEV [ parent qdisc-id | root ] [ handle qdisc-id ] qdisc[ qdisc specific parameters ]
tc class [ add | change | replace ] dev DEV parent qdisc-id [ classid class-id ] qdisc [ qdisc specificparameters ]
tc filter [ add | change | replace ] dev DEV [ parent qdisc-id | root ] protocol protocol prio priorityfiltertype [ filtertype specific parameters ] flowid flow-id
查看
tc [-s | -d ] qdisc show [ dev DEV ]
tc [-s | -d ] class show dev DEV
tc filter show dev DEV
查看 TC 的状态
tc -s -d qdisc show dev eth0
tc -s -d class show dev eth0
删除tc规则
tc qdisc del dev eth0 root
实例
使用 TC 下载限制单个 IP 进行速度控制
tc qdisc add dev eth0 root handle 1: htb r2q 1
tc class add dev eth0 parent 1: classid 1:1 htb rate 30mbit ceil 60mbit
tc filter add dev eth0 parent 1: protocol ip prio 16 u32 match ip dst 192.168.1.2 flowid 1:1
就可以限制 192.168.1.2 的下载速度为 30Mbit,最高可以 60Mbit,其中 r2q 是指没有 default 的root,使整个网络的带宽没有限制。
使用 TC 对整段 IP 进行速度控制
tc qdisc add dev eth0 root handle 1: htb r2q 1
tc class add dev eth0 parent 1: classid 1:1 htb rate 50mbit ceil 1000mbit
tc filter add dev eth0 parent 1: protocol ip prio 16 u32 match ip dst 192.168.111.0/24 flowid 1:1
就可以限制 192.168.111.0 到 255 的带宽为 3000k 了,实际下载速度为 200k 左右。这种情况下,这个网段所有机器共享这 200k 的带宽。
还可以加入一个 sfq(随机公平队列)
tc qdisc add dev eth0 root handle 1: htb r2q 1
tc class add dev eth0 parent 1: classid 1:1 htb rate 3000kbit burst 10k
tc qdisc add dev eth0 parent 1:1 handle 10: sfq perturb 10
tc filter add dev eth0 parent 1: protocol ip prio 16 u32 match ip dst 192.168.111.168 flowid 1:1
sfq公平选项可以防止一个段内的一个 ip 占用整个带宽。
6.2 小结2
首先可以先假设把TCP包的架构设成这样,方便后续去了解限速的规则。
[source-ip] | [source-port] | [other-data] | [destination-ip] | [destination-port]
简单概述:
TC 即 Traffic Control,是 Linux 内核提供的一种用于网络流量管理和质量服务(Quality of Service, QoS)的工具。它允许网络管理员对网络接口上的数据包进行精细的控制,包括但不限于:
SHAPING(限制)
当流量被限制时,其传输速率被控制在预设的阈值之下。这种限制可以显著减少突发流量,有助于维持网络的稳定性和预测性。SHAPING 主要应用于向外的流量控制。
SCHEDULING(调度)
调度涉及在可用带宽范围内,按优先级分配带宽资源。这确保了关键应用和服务可以得到优先处理,从而提高了网络的整体效率。SCHEDULING 同样适用于向外的流量。
POLICING(策略)
POLICING 通常用于控制入站流量,当检测到流量超出预设规则时,可以采取行动,如丢弃超额的数据包,以维持网络政策的一致性。
DROPPING(丢弃)
当流量超出设定的带宽限制时,DROPPING 策略将直接丢弃过量的数据包。这一策略适用于入站和出站流量。
tc 命令的基本结构如下:
tc [ OPTIONS ] COMMAND [ @id ] dev DEV [ parent qdisc-id ] [ index INDEX ]
其中 COMMAND 可以是 qdisc, filter, class, action 等不同的子命令,用于执行不同的流量控制任务。
qdisc(排队规则)
qdisc 定义了数据包在接口上排队和调度的策略。它决定了数据包如何被存储和发送,是流量控制的核心机制。qdisc 可分为 CLASSLESS QDISC 和 CLASSFUL QDISC。
CLASSLESS QDISC
包括简单的 FIFO(First-In-First-Out)队列,如 pfifo 和 bfifo,以及更复杂的策略如 pfifo_fast、red、sfq 和 tbf。
[b|p]fifo:简单的 FIFO 队列,前者基于数据包计数,后者基于字节数。
pfifo_fast:在高级路由器配置中作为默认 qdisc,具有三个优先级队列。
red:随机早期检测,用于预防拥塞。
sfq:基于概率的公平队列,适用于多流场景。
tbf:令牌桶过滤器,用于限速和整形。
CLASSFUL QDISC
提供更细粒度的控制,允许创建基于类别的队列,如 HTB 和 CBQ,用于复杂的服务质量策略。
class(类别)
类别用于组织和划分流量,允许为不同类型的流量分配特定的带宽和优先级。
filter(过滤器)
过滤器用于识别和分类数据包,基于 IP 地址、端口、协议等属性,将数据包导向特定的 qdisc 或 class。
qdisc(队列):
带宽分配:限制或保证数据流的带宽。
延迟控制:通过缓存机制控制数据包的发送时间,从而影响网络延迟。
丢包策略:当队列满时决定哪些数据包被丢弃的策略,以防止拥塞。
公平性:确保多个数据流之间的公平带宽分配。
举例:
tc qdisc add dev ens18 handle fff: htb default 22
其中'fff:'就相当于这条队列的特定标识符,也相当于唯一ID。
谈到队列大家可能有些熟悉,是数据结构中的队列吗?先进先出的那个?当然不是,这是由Linux做的一款流量整形队列,你可以把它看作一条支流,对,小溪那种。在正常使用的情况下,其实LInux就已经给网卡分配了一些队列,应该也是用来整形稳定的一种。当对网口设置了一个新的队列后,这个队列就会被我的这个队列给顶替下去。
ethX: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
整形队列算法:
FIFO (First-In-First-Out)
这是最简单的队列纪律类型,没有额外的管理机制。数据包按照它们到达的顺序被发送出去。FIFO不做任何排序或优先级处理,因此所有数据流都被平等对待。这在大多数情况下是默认的行为,但如果网络负载很高,可能会导致一些数据包的延迟或丢失。
PFIFO (Priority FIFO)
PFIFO提供了有限数量的优先级队列,通常为三个:高、中、低。这允许网络管理员根据数据包的类型或来源为其分配不同的优先级,从而确保关键数据包(如语音或视频流)得到优先处理。然而,PFIFO 仍然依赖于简单的先进先出原则,只是在不同的优先级队列中。
SFQ (Stochastic Fair Queuing)
SFQ是一种更复杂的队列管理规则,旨在为每个数据流提供公平的带宽分配,即使在高负载情况下也能保持良好的响应时间。它使用基于概率的算法来分类数据包,然后将它们放入不同的队列中,确保即使小流量的数据流也能获得一定的带宽。
RED (Random Early Detection)
RED是一种主动丢包机制,用于预防网络拥塞。当队列接近其最大容量时,RED开始随机丢弃一些数据包,而不是等到队列完全填满。这种提前丢弃数据包的策略有助于平滑网络流量,减少拥塞的发生,从而改善整体网络性能。
HTB (Hierarchical Token Bucket)
HTB是一种非常灵活的队列规则,支持复杂的带宽分配和优先级管理。它可以创建层次化的令牌桶,允许网络管理员为不同的数据流设定具体的带宽限制和优先级。HTB 特别适用于需要精细控制网络资源分配的场景,如企业网络和数据中心。
TBF (Token Bucket Filter)
TBF是基于令牌桶算法的流量整形工具,主要用于限速和流量整形。它允许指定一个固定的带宽速率,确保数据流不会超过这个速率,这对于避免网络拥塞和保证服务质量非常有用。
NETEM (Network Emulator)
NETEM是一个网络仿真工具,用于模拟各种网络状况,如延迟、丢包和重复。它非常适合在开发和测试环境中模拟真实世界的网络条件,帮助验证应用程序在网络问题下的表现。
CBQ (Class-based Queueing)
CBQ是早期版本中常用的队列规则,类似于HTB,但功能较少且配置更为复杂。它也支持基于类的队列,允许为不同的数据流设置不同的优先级和带宽限制。然而,由于 HTB 的出现,CBQ 在现代系统中的使用已大大减少。
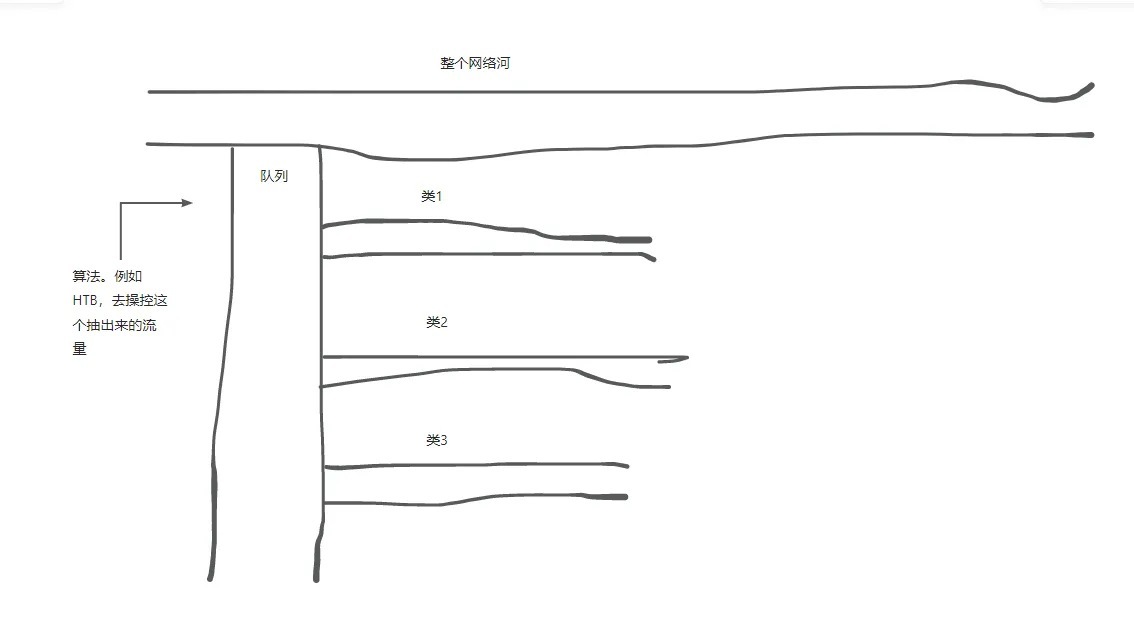
上方这些算法中,如果想进行一些简单的流量控制,那么FIFO和PFIFO即可,如果想要进行真正管理级,逻辑稍微复杂一些的流量整控推荐用HTB,关于HTB它可以进行优先级限制,src和dst IP限制,是一个功能非常强大的算法。SFQ的话是当建立了多条类的话,用于流量平分用。比如从队列里面开出了三条类,也可以理解为引出来了三条小溪流,害怕每条小溪流的水不一样多怎么办?这时候就给每条小溪都配置上一个SFQ。
以wondershaper源码为例:
rate "${RATE}kbit" ceil $((90*${USPEED}/100))kbit prio 3 ${COMMONOPTIONS[@]};
# all get Stochastic Fairness:
tc qdisc add dev "$IFACE" parent 1:10 handle 10: sfq perturb 10 quantum "$QUANTUM";
tc qdisc add dev "$IFACE" parent 1:20 handle 20: sfq perturb 10 quantum "$QUANTUM";
tc qdisc add dev "$IFACE" parent 1:30 handle 30: sfq perturb 10 quantum "$QUANTUM";
这里其他算法就不过多赘述了,专于对HTB算法进行详细讲解。
整形队列流量方向管理:
1.Ingress:表示数据包进入网络设备的方向。当数据包从网络接口接收进来时,这个过程被称为ingress。在这个阶段,设备可以执行诸如数据包过滤、流量整形、优先级标记等操作。
2.Egress:表示数据包离开网络设备的方向。当数据包被发送到另一个网络或设备时,这个过程被称为egress。在egress方向,设备也可能执行类似的操作,如基于策略的路由、QoS 保障、流量限速等。
在 Linux 的 Traffic Control (tc) 工具中,ingress 和 egress 通常用来描述数据包在网卡或网络设备上的流动方向。例如,当使用 tc 进行流量控制时,可以分别对 ingress 和 egress 方向的流量应用不同的队列纪律和过滤规则。这点其实是非常重要的,因为TC实际上是管发不管收的。也就是如果通过tc只能限制别人对我方的下载速度,没办法限制别人对我方的上传速度。
这个在前期确实让人很头痛,那岂不是没有办法在自己的机器上对他人进行上传限速?当然不是,Ingress和Egress就可以解决这个问题。这个在后续应用实例的时候去讲。
Class(类) 和 Filter(过滤器):
class 在 tc 中扮演了组织者和控制器的角色。它允许创建多个类别,每个类别都可以有自己的带宽限制、优先级和调度策略。通过将数据包分配到不同的 class 中,可以实现以下目标:
1.带宽分配:为每个 class 设置不同的带宽上限,确保每个数据流都得到公平或预定的带宽份额。
2.优先级控制:为关键数据流分配更高的优先级,确保它们在拥塞时仍能快速传输。
3.QoS 改善:通过精细调整 class 参数,改善整个网络的服务质量,特别是对于实时应用如 VoIP 和视频会议。
创建 class
class 的创建和配置通常与 qdisc 相结合。首先需要在根 qdisc 下创建一个父 class,然后可以创建子 class 来进一步细分流量。例如使用 htb(Hierarchical Token Bucket)作为 qdisc 时可以这样创建一个 class:
# 创建父 qdisc
tc qdisc add dev <interface> root handle 1: htb default 11
# 创建父 class
tc class add dev <interface> parent 1: classid 1:1 htb rate <rate>
# 创建子 class
tc class add dev <interface> parent 1:1 classid 1:11 htb rate <rate> ceil <max_rate>
在上述命令中,<interface> 是想要控制的网络接口,<rate> 是想要分配给该 class 的带宽速率,<max_rate> 是该 class 可以使用的最大带宽。
使用 class 和 filter
为了将特定的数据包分配到正确的 class 时就需要使用 filter。filter 根据数据包的属性(如源/目的IP、端口号、协议类型等)将它们导向特定的 class。例如:
tc filter add dev <interface> protocol ip parent 1:0 prio 1 u32 match ip dst <destination_ip>/32 flowid 1:11
此命令创建了一个 filter,将目的地为 <destination_ip> 的所有 IP 数据包导向 class 1:11。
问题:此时以文章最开始的包结构为例,这里的destination_ip就是我们包结构里面的[destination-ip]。假如由1.1.1.2给1.1.1.3发消息,那在1.1.1.3中收到的这个包的目标IP就是1.1.1.3,所以此时如果对1.1.1.3进行限速。那直接对这个包里的SRC进行限速呢?这不就完成了对客户端上传速度的限制?但是别忘了,TC是一个管发不管收的工具,既然不管收,那怎么对客户端进行限速呢?
关于速率单位:b或一个无单位数字代表了字节数,bps或一个无单位数字代表了字节数/秒。
问题解决方法:可以去将Ingress的流量进行一个导流,然后把导流的流量重定向到一个网卡上,为了稳定这个采用一个虚拟网卡,然后对虚拟网卡上的流量进行限速,就可以解决对收包进行限速了。
限制IP为1.1.1.3上传速度实例:创建虚拟网卡并启用,暂定虚拟网卡名为ifb0
modprobe ifb numifbs=1
ip link set dev ifb0 up
创建Ingress队列并进行导流
tc qdisc add dev ens18 handle ffff: ingress
tc filter add dev ens18 parent ffff: protocol ip u32 match u32 0 0 action mirred egress redirect dev ifb0
对ifb0进行限速即可
tc qdisc add dev ifb0 root handle 2: htb default 22
tc class add dev ifb0 parent 2: classid 2:22 htb rate 10000mbit ceil 10000mbit burst 10000mbit cburst 10000mbit
tc class add dev ifb0 parent 2: classid 2:1 htb rate 10mbit ceil 10mbit burst 10mbit cburst 10mbit
tc filter add dev ifb0 protocol ip parent 2: prio 1 u32 match ip src 1.1.1.3 flowid 2:1
如果想要限制其他的IP将IP改一下即可。限制IP为1.1.1.3下载速度实例:
正常创建Htb队列,default 22 就是如果没有合适的filter去匹配的话,那就就去找classid为22的类去限速。
tc qdisc add dev ens18 root handle 1:0 htb default 22
# 创建限速类,这里22限制为10GB每秒,相当于未限速,然后对1.1.1.3限速为10mbit每秒。
tc class add dev ens18 parent 1:0 classid 1:1 htb rate 10mbit ceil 10mbit
tc class add dev ens18 parent 1:0 classid 1:22 htb rate 10000mbit ceil 10000mbit
# dst->src
tc filter add dev ens18 parent 1:0 protocol ip prio 1 u32 match ip dst 1.1.1.3 flowid 1:1
再来看一个ifb示例:
# init ifb
modprobe ifb numifbs=1
ip link set ifb0 up
# redirect ingress to ifb0
tc qdisc add dev eth0 ingress handle ffff:
tc filter add dev eth0 parent ffff: protocol ip prio 0 u32 match u32 0 0 flowid ffff: action mirred egress redirect dev ifb0
# add qdisc
tc qdisc add dev ifb0 root handle 1: htb default 2 r2q 100
# add default class
tc class add dev ifb0 parent 1:0 classid 1:1 htb rate 1000mbit ceil 1000mbit
tc class add dev ifb0 parent 1:1 classid 1:2 htb prio 5 rate 1000mbit ceil 1000mbit
tc qdisc add dev ifb0 parent 1:2 handle 2: pfifo limit 500
# add default filter
tc filter add dev ifb0 parent 1:0 prio 5 protocol ip u32
tc filter add dev ifb0 parent 1:0 prio 5 handle 4: protocol ip u32 divisor 256
tc filter add dev ifb0 parent 1:0 prio 5 protocol ip u32 ht 800:: match ip dst 192.168.0.0/16 hashkey mask 0x000000ff at 16 link 4:
# add ingress rules for 192.168.0.9
tc class add dev ifb0 parent 1:1 classid 1:9 htb prio 5 rate 3mbit ceil 3mbit
tc qdisc add dev ifb0 parent 1:9 handle 9: pfifo limit 500
tc filter add dev ifb0 parent 1: protocol ip prio 5 u32 ht 4:9: match ip dst "192.168.0.9" flowid 1:9
u32匹配:在Linux的tc(Traffic Control)工具中,u32是一种匹配器类型,用于基于数据包头部的信息来过滤和分类网络流量。u32匹配器非常灵活,可以依据各种字段(如IP地址、端口号、协议类型等)来创建复杂的匹配规则,是实现高级流量控制策略的关键组件。
u32匹配器的特点
1.灵活性:u32匹配器可以基于多种数据包头部字段进行匹配,包括但不限于IP源地址、目的地址、TCP/UDP源端口、目的端口、协议类型等。
2.复杂规则支持:u32支持逻辑运算,如AND、OR、NOT,允许创建复合的匹配规则,以适应复杂的网络策略需求。
3.性能高效:u32匹配器设计得非常高效,能够快速处理大量的数据包,即使在高负载的网络环境下也能保持良好的性能。
4.基于IP地址匹配
源IP地址匹配:
tc filter add dev [interface] protocol ip parent 1:0 prio 1 u32 match ip src [source_ip] flowid 1:1
目的IP地址匹配:
tc filter add dev [interface] protocol ip parent 1:0 prio 1 u32 match ip dst [destination_ip] flowid 1:1
5.基于端口号匹配
TCP源端口号匹配:
tc filter add dev [interface] protocol tcp parent 1:0 prio 1 u32 match tcp sport [source_port] flowid 1:1
对本机的8084端口服务下载限速(同时控制了整机的对外下载速度为10mbps)
tc qdisc add dev eth0 root handle 1:0 htb default 10
tc class add dev eth0 parent 1:0 classid 1:11 htb rate 2mbit ceil 5mbit
tc class add dev eth0 parent 1:0 classid 1:10 htb rate 10mbit ceil 10mbit
tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip sport 8084 0xffff flowid 1:11
TCP目的端口号匹配:
tc filter add dev [interface] protocol tcp parent 1:0 prio 1 u32 match tcp dport [destination_port] flowid 1:1
UDP源端口号匹配:
tc filter add dev [interface] protocol udp parent 1:0 prio 1 u32 match udp sport [source_port] flowid 1:1
UDP目的端口号匹配:
tc filter add dev [interface] protocol udp parent 1:0 prio 1 u32 match udp dport [destination_port] flowid 1:1
6.基于协议类型匹配
匹配TCP协议:
tc filter add dev [interface] protocol tcp parent 1:0 prio 1 u32 flowid 1:1
匹配UDP协议:
tc filter add dev [interface] protocol udp parent 1:0 prio 1 u32 flowid 1:1
匹配ICMP协议:
tc filter add dev [interface] protocol icmp parent 1:0 prio 1 u32 flowid 1:1
限速总结:对于上传和下载下载的规律是不变的,后续filter跟的一些匹配协议就由大家自由发挥了,例如端口,源端口,协议类型等一些东西都是非常多的,在此就不一一列举了。