Linux流量控制指南(Traffic control HOWTO)
 导读
导读Linux流量控制是一种网络管理技术,用于管理网络接口上等待发送或接收的数据包。它涉及到数据包的入队、监管、分类、调度、整流和丢弃等操作。本指南旨在介绍Linux下的流量控制机制和操作方法。
本文转自charlieroro的个人空间,网上有多个Traffic-Control-HOWTO的翻译版本,官方英文版本还是停留在2006年10月的v1.0.2。感谢众多网友的支持。
流量控制的概念包括:
1. 流量控制的定义:一种管理网络数据流的技术,旨在通过控制网络传输速度,确保网络资源的合理分配和高效使用。
2. 流量控制应用原因:主要目的是避免网络拥塞,提高网络传输质量,平衡网络负载,确保关键服务的网络带宽得到满足。
3. 流量控制的优点:可以减少数据传输延迟,提升网络性能,保障不同服务的带宽需求得到满足。
4. 流量控制的缺点:配置不当可能会导致网络性能降低,甚至产生新的瓶颈。
5. 流量控制中的队列:数据包在等待传输时所处的缓冲区,通常涉及到不同排队策略。
6. 流量控制中的数据流:指网络上的数据传输活动,流量控制主要作用于这些数据流。
7. 流量控制中的令牌桶:一种用于控制数据传输速率和突发流量的数据结构,用于限制和调节数据流。
8. 流量控制中的包和帧:网络传输的基本单位,包是IP层的传输单位,帧是链路层的数据封装单位。
流量控制中几个必备元素包括:
1. 整流:调整数据流使之适应网络的传输能力。
2. 调度:决定数据包如何被发送的策略。
3. 分类:将不同类型的网络数据流进行区分。
4. 监管:对数据流进行速率限制和监管。
5. 丢弃:在网络过载时选择性地放弃某些数据包。
6. 标记:对数据包进行标记以供后续处理。
流量控制组件包括:1. 排队规则(qdisc):定义了数据包排队和调度的规则。
2. 分类(class):将不同的数据流分配到不同的队列中。
3. 过滤器(filter):用于根据特定规则对数据包进行分类。
4. 分类器(classifier):确定数据包属于哪个分类的工具。
5. 监管器(policer):用来执行监管操作的工具。
6. 丢包(drop):在需要的时候负责丢弃数据包。
7. 句柄(handle):用于唯一标识一个qdisc或class。
Linux下流量控制的软件包和工具集包括:
1. 内核版本要求:确保所使用的内核支持流量控制功能。
2. iproute2工具(tc):Linux下的主要流量控制命令行工具。
3. tcng:下一代流量控制工具,提供更高级的流量控制脚本。
4. IMQ:中间队列设备,允许在内核空间和用户空间处理数据包。
无分类排队规则(qdiscs)包括:
1. FIFO(先进先出):最基本的排队规则,按照数据包到达的顺序进行处理。
2. pfifo_fast:Linux系统的默认排队规则,使用三个队列来区分数据包优先级。
3. SFQ(随机公平队列):按流分配数据包到多个队列,实现各流之间的公平传输。
4. ESFQ(扩展的随机公平队列):SFQ的改进版本,提供了更多的参数用于调整性能。
5. GRED(通用早期随机丢包):基于平均队列长度的随机丢包策略。
6. TBF(令牌桶过滤器):控制数据包发送速率,避免突发流量导致的网络拥塞。
常用的流量控制规则和方法包括:
1. Linux流量控制的一般规则:提供了基础的流量控制指导原则。
2. 在已知带宽的线路上实施流量控制:根据线路的带宽限制数据流的传输速率。
3. 基于流来分享、划分带宽:根据连接中的数据流特性来分配带宽。
4. 基于IP来分享、划分带宽:根据IP地址来划分网络带宽资源。
此外文中还提到了用于Qos和流量控制的脚本,包括:
1. wondershaper:一个用于Linux的简单流量控制器。
2. myshaper:用于ADSL宽带的流量控制脚本。
3. htb.init, tcng.init, cbq.init:基于相应流量控制技术的初始化脚本。
文档还提供了图表来直观展示流量控制的架构,以及相关资源链接来辅助读者深入了解流量控制技术。另外也提供了修订记录和版权声明,说明了文档的版本更新、修订者信息以及使用和分发文档的权限许可。本指南由Martin A. Brown撰写,并由ziven进行了中文翻译。正文由此开始。
1. Linux流量控制介绍
Linux提供了丰富的工具来管理和控制报文的发送。社区对于在Linux下对报文进行修改、应用防火墙策略(Netfilter,以及之前的Ipchains)以及大量的可以运行在操作系统上的网络服务工具非常熟悉。但只有小部分Linux社区内和更少的社区外人员了解Linux流量控制子系统的强大功能,并且该子系统已经在v2.2和v2.4内核中变得更为成熟。
本指南试图介绍流量控制的思想,传统的流量控制要素,Linux流量控制组件,同时提供了一些参考。这份指南是通过对LARTC指南上的文档以及重要的LARTC邮件列表学习、整理出来的。对于没有耐心阅读本指南,想要立即体验流量控制的用户,推荐阅读Traffic Control using tcng and HTB HOWTO和LARTC HOWTO,这两份文档会很有用。
1.1. 目标及假定读者
本指南的目标读者是想对流量控制及对Linux下的流量控制工具有所了解的网络管理人员或者有一定基础的家庭用户,读者应该熟悉UNIX操作环境及命令行且具备一定的IP网络知识。如果想要对流量控制进行应用,还需具有对linux内核或软件进行打补丁,编译及安装的能力。对于拥有较新内核版本(2.4.20及以上,参见5.1节)的用户,只需要会安装和使用软件就够了。
一般来说,本指南应该适合各类用户。虽然有些读者可能已经有在Linux下进行流量控制的经验,但我仍假设所有读者都没有相关经验
1.2. 排版约定
本文档是在DocBook中通过vim来编写的。所有格式由基于DocBook XSL和LDP XSL表格样式的xsltproc来控制。字体格式和显示样式和大多数印刷及电子技术文档相似。
1.3. 推荐学习方法
强烈建议读者先通过tc和tcng来突击学习下流量控制的规则,在集中学习tcng之前,只需对tc命令行工具有一个大致的了解。tcng软件包定义了一个完整的语言来描述流量控制结构。第一眼看上去,这门语言会让人生畏,但当你掌握之后,它会使你能很容易使用流量控制,而这是直接使用tc工具不能办到的。
如果可能的话,我将以一种抽象的方式来描述Linux下流量控制系统的行为,但有些时候我也会借用其他类似的系统来描述这些结构。同一个例子,我不会既用tcng语言又用tc命令行来实现,聪名的读者会将两者融会贯通。
1.4. 待补充内容,错误指正及读者反馈
本指南仍然缺少些内容。下面的内容会在未来某个时间点添加进本文档。
有关GRED, WRR, PRIO 和CBQ的描述及图表。
使用示例。
对分类器(classifier)进行详细介绍的小节。
对流量测量技术进行讨论的小节。
对标记有覆盖的小节。
更多关于tcng的细节。
欢迎将建议、错误指正及反馈发送至<martin@linux-ip.net>。理论上来说,所有的错误和疏忽都是我的错,虽然我已经尽力确保了当前文档的正确性,但我不能承担读者根据此文档进行操作后的任何后果。
2. 概览(Overview of Concepts)
本章将介绍流量控制,研究出现流量控制的原因及其优缺点,并介绍流量控制的关键概念。了解Linux的流量控制的目的:一是为了更好地理解底层对报文的处理逻辑,二是在流量控制中使用了很多很好的流量处理方法,可以学习一下这些方法和思想。
目录
2.1. 什么是流量控制
2.2. 为什么使用流量控制
2.3 优点
2.4 缺点
2.5 队列
2.6 流
2.7 令牌和桶
2.8 报文和帧
2.9 NIC,网络接口控制器
2.9.1 网络栈的巨包
2.10 饥饿和延迟
2.11 吞吐量和延迟之间的关系
2.1. 什么是流量控制
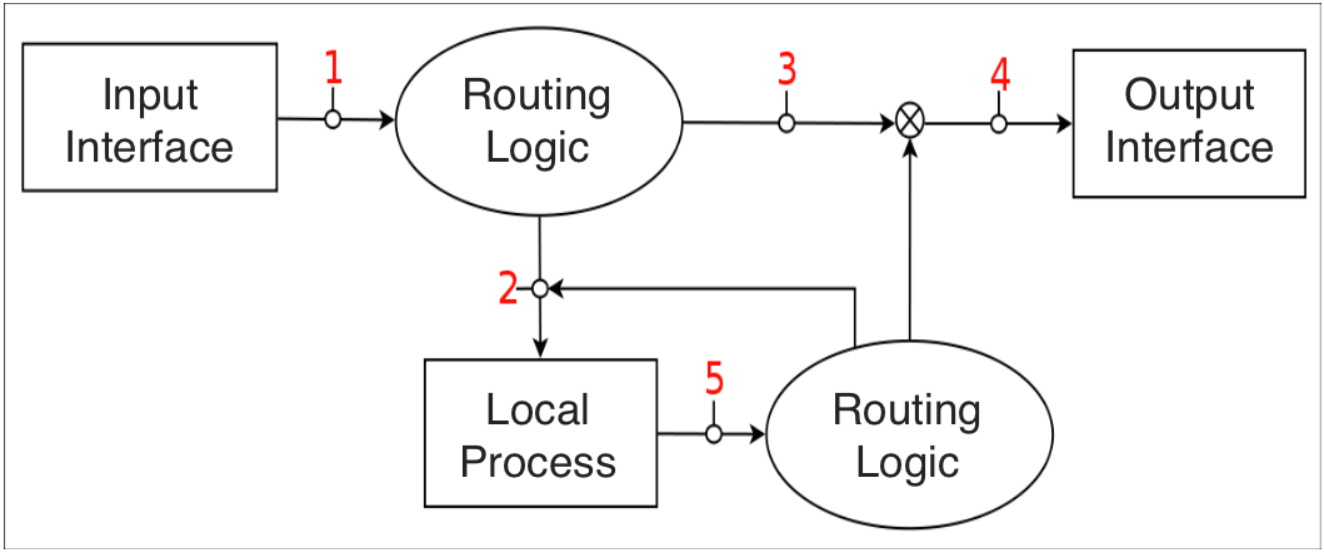
流量控制是指在路由器上接收和传输数据包的队列系统和机制的统称。包括决定(如果和)输入接口上以哪种速率接收哪个包,以及决定在输出接口上以哪种顺序传输那些包。
在最简单的模型中,流量控制包含简单的队列,该队列收集了所有的报文,并在硬件(或底层设备)可以接收报文时尽快让这些报文出队列。这种队列即FIFO。它就像一个进入高速公路的收费站,每辆车必须停下并缴纳过路费,而此时其他汽车也必须等待。
注:Linux下默认的qdisc为pfifo_fast,它比FIFO更加复杂。
在各种软件中都有队列的影子。队列是一种组织挂起的任务或数据(参见Section 2.5, “Queues”)的方式。由于网络链接通常会以序列化的方式携带数据,因此需要一个队列来管理出站的数据包。
在台式机和一台高效的网络服务器共享(到因特网的)同一上行链路的情况下,可能会对带宽资源产生竞争。例如,服务器填充路由器上的输出队列的速度可能比通过链路传输数据的速度还要快,此时路由器开始丢包(缓冲已经满了),这样台式机(可能是交互应用的用户)可能会面临丢包和高延迟。通过划分内部队列来服务这两种不同的应用,就可以在两个应用间更好地共享网络。
流量控制是一组允许管理员对这些队列进行精细控制的工具和网络设备的排队机制的统称。虽然这些工具重新分配流量和包的能力是强大的,同时也可能会很复杂,但最好留有足够的带宽。
术语Quality of Service (QoS)通常作为ip层的流量控制的代名词。
2.2. 为什么使用流量控制
流量控制工具允许实现者对传输到网络中的数据包或网络流应用首选项、组织或业务策略,进而管理网络资源,如吞吐量或延迟。
从根本上说,由于网络中的分组交换,流量控制变得非常必要。
为了简要说明数据包交换的新颖性和巧妙性,考虑一下在整个20世纪构建起来的电路交换电话网络。为了发起一个呼叫,网络设备需要了解建立呼叫的规则。当一个呼叫者尝试发起连接时,网络会使用这些规则来为整个呼叫或连接期间保留一个电路。当有一个使用该资源的通话占线时,其他呼叫或呼叫者都不能使用该资源,意味着由于资源不可用,许多设备可能会因为单个部件而阻塞通话的建立。
回到分组交换网络,这是20世纪中期的一项发明,后来被广泛使用,并且在21世纪几乎无处不在。分组交换网络与基于电路的网络有一个非常重要的区别,即网络设备处理的数据单位不再是电路,而是一小块的数据,称为数据包。分组交换网络只需要处理一小部分的工作:读取目的地标识,并传输该数据包。
分组交换网络有时会被认为为无状态的,这是因为它不需要跟踪网络上所有的活动的流。因此,缺乏对特定数据包或网络流重要性的区分是这种分组交换网络的一个弱点。网络可能会因数据包的相互竞争而超载。
简单来说,流量控制工具允许根据数据包的属性,通过不同的方式将数据包放入网络。不同的工具用于解决不同的问题,可以组合多个工具来实现复杂的规则,满足偏好或业务目标。
下面是一些常见问题的例子,可以用于解决或改善这些工具。
下面并没有给出流量控制的所有解决方案,仅给出了可以使用流量控制工具解决的常见问题,用于最大化利用网络。
常用的流量控制方案
1.将总带宽限制为某个值:TBF,和带子类的HTB。
2.限制特定用户、服务或客户的带宽:HTB 类和带filter的分类。
3.最大化非对称链路上的TCP吞吐量;提升传输的ACK包的优先级:wondershaper。
4.为特定应用或用户预留带宽:带子类的HTB和分类。
5.偏好延迟敏感的流量:HTB类中的PRIO。
6.管理超额的带宽:HTB租借。
7.允许公平分配未预留的带宽:HTB租借。
8.确保丢弃特定类型的流量:给filter添加policer,使用drop动作。
需要注意的是,有时候最好订购更多的带宽,流量控制并不能解决所有的问题。
2.3 优点
正确引入流量控制可以更加可靠地对网络资源地利用进行预测,并可以减少对这些资源的不稳定竞争,这样就可以实现流量控制配置的目标。即使在为更高优先级的交互式流量提供服务同时,也可以为批量下载分配合理的带宽;即使低优先级的数据传输(如邮件),也可以分配到一定的带宽,而不会对其他类型的流量造成巨大的影响。
如果流量控制中的配置代表了用户的策略,那么该用户(或应用)就应该知道后续会网络的影响。
2.4 缺点
使用流量控制的最大缺点之一是其复杂性。实践中,有一些方法可以用来熟悉流量控制工具,简化关于流量控制及其机制的学习曲线,但如何确定一个流量控制的错误配置仍然是一个相当大的挑战。
当正确配置流量控制时,可以公平地分配网络资源。但不合理的使用可能导致对资源的分裂性争夺。
路由器上支持流量控制方案所需的计算资源必须能够处理维护流量控制结构的成本的增加。幸运的是,它的成本增量很小,但随着配置和复杂度的增加,其成本可能显著增加。
对于个人来说,不需要考虑引入量流量控制带来的培训成本,但对于一个公司来说,相比引入流量控制,采购更多的带宽可能是一个更简单的解决方案(员工的培训成本可能要远高于采购带宽的成本)。
2.5 队列
所有的流量控制都会用到队列,它是调度算法不可或缺的一部分。一个队列是一个位置(或缓冲),包含有限数目的元素,等待相应的动作或服务。在网络中,一个队列是报文(单位)等待被硬件(服务)传输的地方。在最简单的模型中,报文根据先进先出的方式进行传输。在计算机网络(和更普遍的计算机科学)的学科中,这种队列被称为FIFO。
如果没有其他机制,队列是不会为流量控制提供任何优化。此时一个队列只有两个需要关注的动作:任何到达队列的报文(或单位)都会在队列中排队;为了从队列中移除一个元素,则需要对其执行出队列操作。
当结合其他机制时,队列可以提供更加丰富的功能,如延迟包容,重新排列,丢弃,以及优先处理多个队列中的数据包。一个队列可能会使用子队列,用来处理更加复杂的调度行为。
从上层的软件的角度来看,当一个报文入队列后,该队列对待传输报文的处理行为和处理顺序对上层软件来说是无关紧要的。因此,对上层来说,整个流量控制队列系统可能只是一个单一的队列,只有对使用了流量控制的那一层来说,流量控制结构才是可见的。
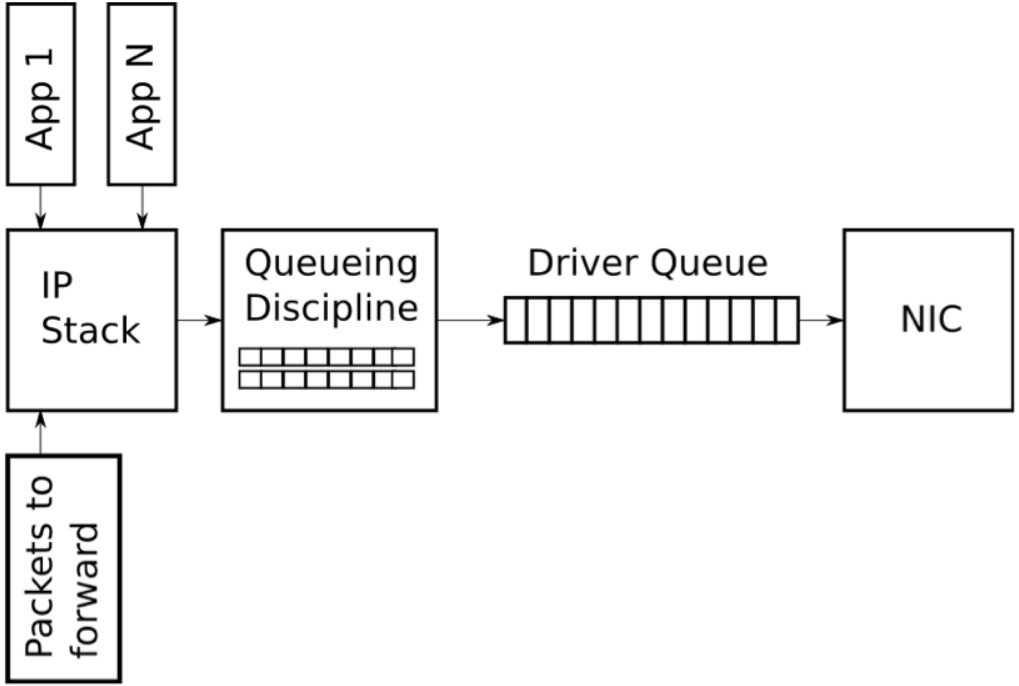
下图展示了一个高度简化的Linux网络栈的传输路径上的队列图:
2.6 流
一条流指两个主机之间的特定连接或会话。两个主机之间的任何(唯一的)报文集都可以看作是一条流。TCP使用源IP和端口,目的IP和端口来表示一条流,UDP流也是类似的。
流量控制机制经常会将流量划分为不同的类,并以聚合流的方式(如DiffServ)对这些流进行聚合和传输。类似的,可能会基于单个流来平均分配带宽。
当尝试在一组竞争流中平均分配带宽时,对流的处理就变得很重要,尤其是在某些应用故意构建大量流时。
2.7 令牌和桶
整流机制的两个关键概念是令牌和桶。
为了控制出队列的速率,实现中可以在每个元素出队列时计算出列的报文数或字节数(虽然这样会使用复杂的定时器和工具进行精确限制)。除了计算当前使用量和时间,还有一种方法广泛用到流量控制中,即以一定速率生成令牌,只有存在可用的令牌是才允许报文或字节出队列。
考虑一个游乐园游乐设施,人们排队等候体验游乐设施。让我们将该设施想象成一个轨道,在这个轨道上,推车会通过一个固定的轨道。这些推车以固定的速率排在队伍的前头。为了享受乘坐的乐趣,每个人必须等待一辆可用的推车,每个推车类似于一个令牌,人类似于一个报文。这种机制就是限流或整流机制。 在特定时期内,只有一定数量的人可以体验骑行。
为了扩展这个类比,想象游乐园里有一条空的线路,而轨道上有大量的推车准备载客,如果大量的人一起进入队列,很多(也许全部)人可以体验乘坐,因为此时有一定数量的可用的推车。推车的数量是一个类似于桶的概念。一个桶包含很多令牌,可以使用桶中现有的令牌,而无需等待。
为了完成这个类比,游乐园里的推车(我们的令牌)的到达的速率是固定的,且可用的推车不超过桶大小。因此,令牌会以固定速率填充到桶,如果没有使用令牌,则桶可以被填满。如果使用了令牌,则桶不会被填满。桶是支持突发流量(如HTTP)的一个关键概念。
TBF qdisc是一个典型的整流器(关于TBF包括一个图表,它可以帮助以可视化的方式展示令牌和桶的概念)。TBF会生成速率令牌,只有当令牌可用时才能传输报文。令牌是一个通用的整流概念。
当队列不需要令牌时,这些令牌会被收集起来,并在后续需要时使用。无限制地收集令牌会抵消整流带来的好处,因此需要限制收集的令牌的数量。队列中的令牌可用于需要出队列的报文或字节。 这些无形的令牌存储在无形的桶中,可以存储的令牌数量取决于桶的大小。
这也意味着,在任意时刻都可能存在一个满token的桶,可预测的流量可以使用小的桶,突发流量可以使用大的桶(除非目标是为了降低流的突发)。
总之,令牌使用一定速率来生成,最大可用的令牌数由桶的大小来决定。通过这种方式可以处理突发流量,使得传输的流量变得平滑。
令牌和桶是息息相关的,用于 TBF (classless qdiscs的一种) 和 HTB (classful qdiscs的一种)。在tcng语言中,二色和三色标识法就是令牌桶的应用。
2.8 报文和帧
网络上传输的数据的术语取决于其所在的网络层。尽管在此处给出了报文和帧的技术上的区别,但本文并不作区分。
帧通常用于描述二层网络上转发的数据单位。以太接口,PPP接口和T1接口都将二层数据单位称为帧。帧是流量控制的实际单位。
从另一方面将,报文时上层协议的概念,表示三层数据单位。本文档的使用了报文。
2.9 NIC,网络接口控制器
一个网络接口控制器是一个计算机硬件组件,与前面的软件组件不同,它将一个计算机连接到一个计算机网络。网络控制器使用特定的数据链路层和物理层标准实现了通信所需的电子电路,如 Ethernet, Fibre Channel, Wi-Fi or Token Ring。流量控制必须处理NIC接口的物理限制和特征。
2.9.1 网络栈的巨包
大多数NICs都有一个固定的传输单位(MTU),即物理媒介可以传输的最大帧。对于以太网来说,默认为1500字节,但对于支持巨型帧的以太网来说,其MTU可以达到9000字节。在IP网络栈中,MTU作为发送或传输报文时的大小限制。例如,如果一个应用向TCP socket写入了2000字节的数据,那么IP栈需要创建两个IP报文来保证报文小于或等于1500字节的MTU。当需要传输大于MTU的数据时,会导致创建大量的小报文,并传输到 驱动队列。
为了避免在传输路径上对大报文处理产生的开销,Linux内核实现了几类优化:TCP分段卸载(TSO),UDP分片卸载(USO)以及通用的分段卸载 (GSO)。所有这些优化都允许IP栈创建的报文大于传出的NIC上的MTU。对于IPv4,创建并放到驱动队列中的报文可以达到65536字节。在TSO和UFO场景下,NIC硬件负责将单个大报文切分为可以在物理接口上传输的小报文。对于没有硬件支持的NIC,GSO会在报文进入驱动队列之前对其进行相同的操作。
回顾一下,驱动队列包含一个固定数目的描述符,每个描述符指向大小不同的报文,由于TSO, UFO 和GSO 允许更大长度的报文,因此这些优化会大大增加驱动队列中保存的字节数(即驱动中的描述符可能指向一个大于MTU的报文,后续会在NIC中进行报文切割)。
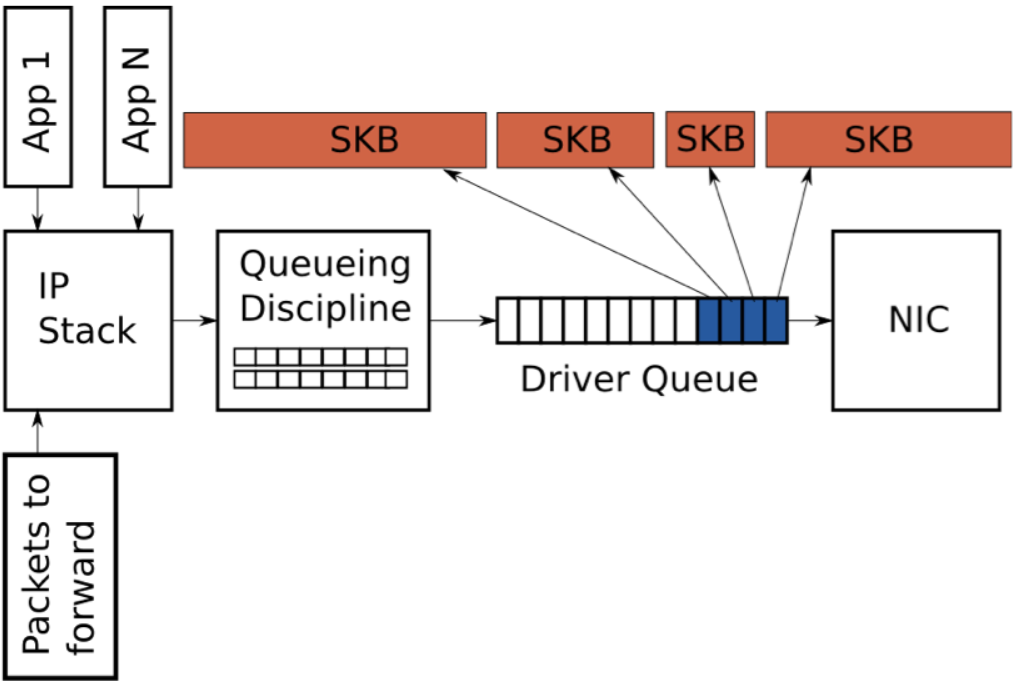
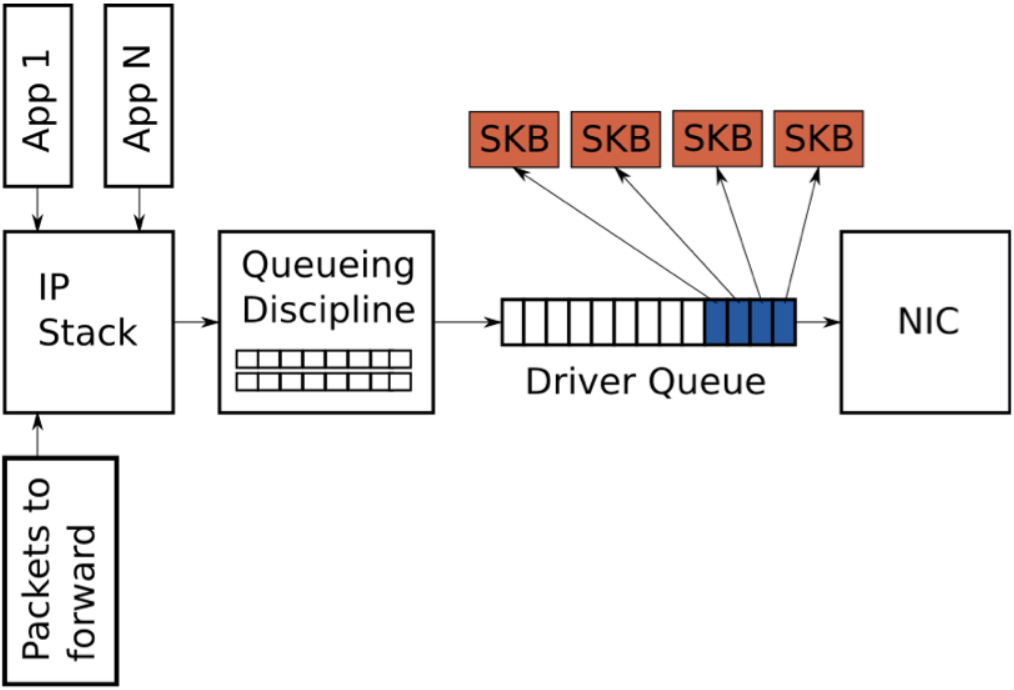
2.10 饥饿和延迟
IP栈和硬件(参见4.2章节的驱动队列,和5.5章节对启动队列的管理)之间的队列引入了两个问题:饥饿和延迟。
NIC驱动程序从队列中取出数据包进行传输,但队列是空的,此时硬件会错失一次传输的机会,进而导致系统吞吐量下降,这种情况称为饥饿。注意,当系统不需要传输任何数据时,队列也是空的,这是正常情况,并不归类为饥饿。与避免饥饿相关的复杂情况是,正在填充队列的IP栈和消耗队列的硬件驱动程序是异步运行的,更糟糕的是,填充和获取事件的间隔会随着系统的负载和外部状况(如网口的物理媒介)而变化。例如,在一个繁忙的系统上,IP栈向缓冲区添加报文的机会将变少,这会导致硬件在更多数据包入队列之前耗尽缓冲区。基于这种原因,使用比较大的缓冲可以降低饥饿的概率,并保证高吞吐量。
当使用一个大的队列来为一个繁忙的系统保持高吞吐量时,同时也会引入大量延迟。
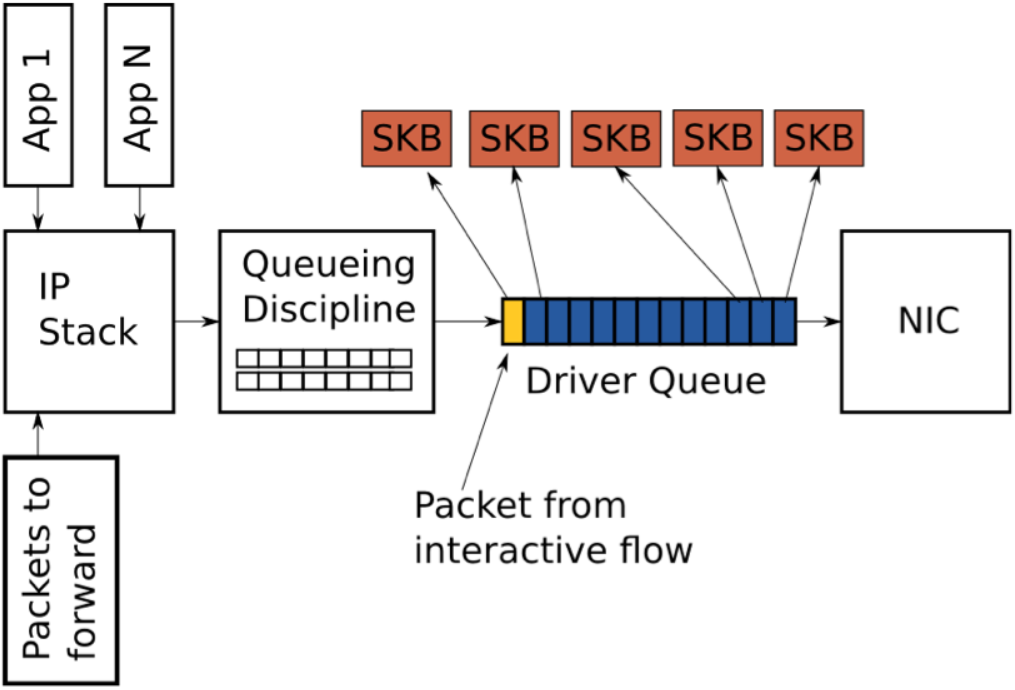
上图展示了一个驱动队列,其中几乎填满了高带宽,大流量(蓝色)下的TCP段。队列的最后一个报文来自一个VoIP或游戏流(黄色)。像VoIP或游戏这样的交互式应用通常会以固定间隔的时间发送小的报文,它们是延迟敏感型的。而高带宽数据传输会产生更高的报文速率和更大的报文,更高的报文速率会填满交互式报文之间的缓冲,导致交互式报文的传输被推迟。为了描述这种行为,考虑下面这种场景:
1.网口上允许传输的速率为5 Mbit/sec 或 5,000,000 bits/sec。
2.大流量上的每个报文是 1,500 bytes 或12,000 bits。
3.交互式流量上的每个报文是500 bytes。
4.队列的深度为128个描述符。
5.此时队列中有127个大流量报文和1个交互式报文。
鉴于上述假设,耗尽127个大流量报文并给交互式报文创造传输机会的时间为(127 * 12,000) / 5,000,000 = 0.304 seconds (对于根据ping来衡量的延迟结果为304毫秒),这样的延迟对交互式应用来说是不可接受的,且不代表完整的往返时间(仅仅是交互式报文在队列中等待传输前的时间)。如前面所述,当启用TSO, UFO 或 GSO时,驱动队列中的报文大小可以大于1500字节,这将导致延迟更加严重。
为驱动队列选择一个合适的大小可以看作是一个Goldilocks 问题,为了保证吞吐量而不能大小,为了保证延迟而不能太大。
2.11 吞吐量和延迟之间的关系
在所有流量控制系统中,吞吐量和延迟都存在一定的关系。网络链路上传输的的最大信息速率称为带宽,但是对于网络上用户来说,实际获得的带宽还有一个专用术语,吞吐量。
延迟
1.发送者传输和接收者解码或接收数据之间的延迟,总是非负或非0的值。
2.原则上,延迟是单向的,但几乎整个Internet网络社区都在谈论双向延迟--发送方发送数据和通过某种方式确认收到数据之间的时间延迟,如ping
3.以毫秒计算延迟;在以太网上,延迟通常是0.3到1ms之间,在广域网上,延迟为5到300ms之间。
吞吐量
1.衡量发送者和接收者之间成功传输的数据总量;
2.以bit/sec为单位进行衡量;
注:延迟和吞吐量是常用的计算术语。例如,应用程序开发人员在尝试构建响应工具时会提到了用户感知的延迟。数据库和文件系统人员会提到磁盘吞吐量。在网络层上,在DNS中查询网站名称的延迟是感知一个网站性能的重要指标。
为了最大化下载吞吐量,设备供应商和供应商通常会调整他们的设备来容纳大量数据包。当网络准备接收另外一个报文时,网络设备的队列中如果有一个报文,则简单地发送该报文即可。通过这种方式可以保证用户的下载吞吐量。
该技术以延迟的代价来最大化吞吐量。想象一下,当高优先级的报文位于大队列的末尾时,该报文在这个网络上的理论上的延迟可能是100ms,但必须在队列中等待传输。
虽然最大化吞吐量的决定非常成功,但对延迟的影响也是显著的。
斯图尔特·柴郡(Stuart Cheshire)在1990年代中期发出了一个名为愚蠢的延迟的警告,它采用了术语bufferbloat,大约15年后由吉姆·盖蒂(Jim Getty)在他的博客的ACM队列文章bufferbloat:互联网中的黑暗缓冲 和 Bufferbloat FAQ 中重点介绍了最大化吞吐量的选择。
在学术、网络和Linux开发社区中,分组交换网络存在的延迟和吞吐量之间的关系是众所周知的。Linux流量控制核心数据结构可以追溯到1990年代,并且一直在不断开发和扩展,并增加了新的调度器和功能。
3. 传统的流量控制元素
目录
3.1 整流
3.2 调度
3.3 分类
3.4 策略
3.5 丢弃
3.6 标记
3.1 整流
整流器通过延迟报文来满足所需的传输速率。整流是一种通过延迟传输到输出队列的报文来满足期望的输出速率的机制。这是寻求带宽控制解决方案的用户面临的最常见的需求之一。延迟报文作为流量控制解决方案的一部分,使得每种整流机制都变成了一种不会节省工作量的机制,即"为了延迟报文需要作额外的工作"。
反过来看,这种不会节省工作量的机制提供了整流功能,而节省工作量的机制(如 PRIO)则不能够延迟报文。
整流器会尝试限制或分配流量,使其满足但不会超过配置的速率(通常为每秒报文数或每秒的比特/字节数)。也正是因为其运作机制,整流器可以使突发流量变得平滑。对带宽进行整流的好处是可以控制报文的延迟。整流的底层通常会使用令牌和桶机制。
3.2 调度
调度器会协调或重新协调出去的报文。
调度是一种在特定队列的输入和输出之间协调(或重新协调)报文的机制。最常见的调度器是FIFO(先进先出)调度器。从更高层面上看,任何在输出队列上设置的流量控制机制都可以看作是一个调度器(因为这些机制也会协调出去的报文)。
其他通用的调度机制可以用于补偿各种网络条件。如公平队列算法(SFQ)可以用于防止单个客户端或流占用全部网络资源;轮询算法(WRR)以轮询的方式给每个流或客户端的报文提供出队列的机会。其他复杂的调度算法可以用于防止骨干过载(参见GRED)或改进其他调度机制(参见ESFQ)。
3.3 分类
分类器用于对进入队列的流量进行分类或分割。
分类是一种以不同的方式处理报文的机制,通常对应不同的输出队列。在处理过程中,当路由和传输一个报文时,网络设备可以使用多种方式对报文进行分类。分类可以包含对报文的标记,通常发生在单个管理控制下的网络边界,或者单独的每一跳上。
Linux模型(参见Section 4.3, “filter”)允许报文在流量控制结构中级联多个分类器,并与策略器一起进行分类(另请参见Section 4.5, “policer”)。
3.4 策略
策略器用于衡量或限制特定队列的流量。
策略是流量控制的一个元素,是一种限制流量的简单机制。策略广泛运用到网络边界,用于保证对端占用的带宽不会超配额。一个策略器会以一定的速率接收流量,当超过该速率之后会执行某些动作。一个比较严格的方案是直接丢弃流量(虽然流量可以通过重新分类进行处理,而不用简单地丢弃)。
策略是关于进入队列的流量速率的是和否的问题,如果进入队列的报文低于给定的速率,则允许该报文入队列;如果进入队列的报文超过给定的速率,则执行其他动作。虽然策略器内部使用了令牌桶机制,但它无法像整流机制一样延迟报文。
3.5 丢弃
丢弃整个报文,流或分类。
丢弃一个报文意味着废弃一个报文。
3.6 标记
标记是一种更改报文的机制。
注:不同于fwmark。iptables 目标的MARK和ipchains的--mark用于修改报文的元数据,而不是报文本身。
流量控制的标记机制会在报文上安装一个DSCP,然后由管理域内的其他路由器使用并遵守(通常用于DiffServ)。
4. Linux流量控制的组件
流量控制元素与Linux组件之间的相关性:
| traditional element | Linux component |
|---|---|
| 入队列 | 修订:从用户或网络接收报文 |
| 整流 | class提供了整流的能力 |
| 调度 | 一个qdisc就是一个调度器。调度器可以是一个简单的FIFO,也可以变得很复杂,包括classes和其他qdiscs,如HTB。 |
| 分类 | filter对象通过一个classifier对象执行分类。严格上讲,除filter之外的组件不会用到分类器。 |
| 策略 | policer仅作为filter的一部分而存在。 |
| 丢弃 | drop流量要求使用一个带policer的filter,动作为"drop" |
| 标记 | dsmark qdisc用于标记报文。 |
| 入队列 | 驱动队列位于qdisc和网络接口控制器(NIC)之间。驱动队列给上层(IP栈和流量控制子系统)提供了数据异步入队列的位置(后续由硬件对数据进行操作)。队列的大小由Byte Queue Limits (BQL)动态设置。 |
4.1 qdisc
简单讲,一个qidsc就是一个调度器。每个出接口都需要某种类型的调度器,默认的调度器为FIFO。Linux下的其他qdisc会根据调度器的规则来重新安排进入调度器队列的报文。
qdisc是构建所有Linux流量控制的主要部件,也被称为排队规则。
classful qdiscs 可以包含类,并提供了可以附加到过滤器的句柄。一个classful qidsc可以不使用子类,但这样通常会消耗CPU周期和其他系统资源,且毫无意义。
classless qdiscs 不包含类,也不会附加过滤器。由于一个classless qdisc不包含任何类的子类,因此不能使用分类,意味着不能附加任何过滤器。
在使用中可能会对术语root qdisc 和ingress qdisc产生混淆。实际中并不存在真正的排队规则,而是连接流量控制结构的出站(出流量)和入口(入流量)的位置。
每个接口都会包含root qdisc 和ingress qdisc。最主要和最常用的是egress qdisc,即root qdisc,它可以包含任何排队规则(qdiscs)以及潜在的类和类结构。大部分文档适用于root qdisc及其子qdisc。一个接口传输的流量会经过egress或root qdisc。
一个接口上接收到的流量会经过ingress qdisc。由于其功能的限制,不允许创建子类,且仅允许存在一个被过滤器 附加的对象。事实上,ingress qdisc仅仅是一个对象,可以在其上附加策略器来限制网络接口上接收的流量。
总之,由于egress qdisc包含一个真正的qdisc,且具有流量控制系统的全部功能,因此可以使用egress qdisc做很多事情。而一个ingress qdisc仅支持一个策略器。除非另有说明,本文后续将主要关注附加到root qdisc的流量控制结构。
4.2 类
类仅会存在于classful qdisc (如 HTB 和 CBQ)。类非常灵活,可以包含多个子类或单个子qdisc。一个子类本身也可以包含一个classful qdisc,通过这种方式可以实现复杂的流量控制场景。
任何类都可以附加任意多的过滤器,从而允许选择一个子类或使用过滤器来重新分类或直接丢弃进入特定类的流量。叶子类是qdisc中的终止类,它包含一个qdisc(默认是FIFO),且不会包含子类。任何包含子类的类都属于内部类(或root类),而非叶子类。
4.3 过滤器
过滤器是Linux流量控制系统中最复杂的组件,提供了将流量控制的主要元素粘合到一起的机制。过滤器最简单和最明显的角色就是对报文进行分类(Section 3.3, “Classifying”)。Linux过滤器允许用户使用多个或单个过滤器来将报文分类到一个输出队列。
1.一个过滤器必须包含一个分类器
2.一个过滤器可能包含一个策略器
过滤器可能附加到classful qdiscs或类,但入队列的报文总是首先进入root qdisc。在报文经过的root qdisc上附加的过滤器后,报文可能被重定向到任何子类(子类可以包含自己的过滤器),后续可能对报文进一步分类。
4.4 分类器
过滤器的对象,可以使用tc进行操作,且可以使用不同的分类机制,其中最常用的是u32分类器。u32分类器允许用户根据报文的属性选择报文。
分类器可以作为过滤器的一部分来标识报文的特征或元数据。Linux分类器对象可以看作是流量控制分类的基本操作和基本机制。
4.5 策略器
该机制仅作为Linux流量控制中的过滤器的一部分。一个策略器可以在速率超过指定速率时执行一个动作,在速率低于指定速率时执行另一个动作,善用策略可以模拟出一个三色表。参见 Section 10, “Diagram”。
虽然策略 和整流 都是流量控制中用来限制带宽的基本元素,但使用策略器并不会导致流量延迟。它只会根据特定的准则来执行某个动作。参见Example 5, “tc filter”。
4.6 丢弃
该流量控制机制仅作为策略器的一部分。任何附加到过滤器的策略器都包含一个drop动作。
注:策略器是流量控制系统中唯一可以显式地丢弃报文的地方。策略器可以限制入队列的报文的速率,或丢弃匹配特定模式的所有流量。
流量控制系统中,报文的丢失可能是由某个动作引起的副作用。例如,如果使用的调度器使用和GRED一样的方法控制流时,报文将被丢弃。
或者,当出现突发或超负荷时,如果整流器或调度器的缓冲用尽,也可能会丢弃报文。
4.7 句柄
每个类和classful qdisc(Section 7, “Classful Queuing Disciplines (qdiscs)”)都要求在流量控制结构中存在一个唯一的标识符,该唯一标识符被称为句柄,每个句柄包含两个组成成员,一个主号和一个次号。用户可以根据以下规则随意分配这些号。
类和qdiscs的句柄号:
1.主号:该参数对内核完全没有意义。用户可能会任意使用一个编号方案,但流量控制结构中具有相同父qdisc的所有对象必须共享一个次句柄号。对于直接附加到root qdisc的对象,传统的编号方案会从1开始。
2.次号:如果次号为0,则表明该对象为qdisc,否则表明该对象为一个类。所有共享同一个qdisc的类必须包含一个唯一的次号。
特殊的句柄 ffff:0 保留给ingress qdisc使用。
句柄作为tc过滤器的classid和flowid的目标参数,同时也是用户侧应用使用的标识对象的外部标识符。内核为每个对象维护内部标识符。
4.8 txqueuelen
可以使用ip或ifconfig目录获取当前传输队列的长度。令人困惑的是,这些命令对传输队列长度的命名各部不同:
$ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:19:F3:51:44:19
inet addr:192.168.1.58 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::218:f3ff:fe51:4410/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:435033 errors:0 dropped:0 overruns:0 frame:0
TX packets:429919 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:65651219 (62.6 MiB) TX bytes:132143593 (126.0 MiB)
Interrupt:23
$ip link
1: lo: mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:19:F3:51:44:19 brd ff:ff:ff:ff:ff:ff
Linux默认的传输队列的长度为1000个报文,这是一个相当大的缓冲(特别是当带宽比较低时)。(为了理解其原因,请参见针对延迟和吞吐量的讨论,特别是缓冲膨胀。)
更有趣的是,txqueuelen仅用作这些排队规则的默认队列长度。
1.pfifo_fast (Linux的默认队列规则)
2.sch_fifo
3.sch_gred
4.sch_htb (仅用于默认队列)
5.sch_plug
6.sch_sfb
7.sch_teql
txqueuelen参数控制上述QDiscs的队列大小。对于大多数的队列规则,tc命令行中的limit参数会覆盖默认的txqueuelen 值。总之,如果没有使用上述的任意一种队列规则或覆盖了默认的队列长度,那么txqueuelen 就没有任何意义。
可以使用ip或ifconfig命令来配置接口的传输队列长度。
ip link set txqueuelen 500 dev eth0
注意:ip命令使用qlen来表示txqueuelen。
4.9 驱动队列(即ring buffer)
在IP栈和网络接口控制器之间存在驱动队列。该队列通常使用先进先出的ring buffer来实现(可以认为是一个固定长度的缓冲)。驱动队列不包含任何报文数据,仅包含指向其他数据结构(socket kernel buffers,简称SKBs)的描述符,SKB包含报文数据,并在整个内核中使用。
驱动队列的输入源为保存了完整IP报文的IP栈,这些报文可能是本地的,或当设备作为路由器时接收到的需要从一个NIC路由到另一个NIC的报文。IP栈会将报文添加到驱动队列,并由硬件驱动出队列,在传输时会通过数据总线发送到NIC硬件。
驱动队列存在的原因是为了保证在任何时候,当系统需要传输数据时,NIC会立即传输该数据。即,驱动队列为IP栈和硬件操作提供了一个异步处理数据的位置。一个备选方案是,一旦物理媒介就绪时就向IP栈查询可用的报文。但由于对这类请求的响应不可能是即时的,因此这种设计浪费了宝贵的传输机会,导致吞吐量降低。相反的方案是,IP栈在创建一个报文后会等待硬件就绪,这种方案同样不理想,因为IP栈将无法继续其他工作。
更多关于驱动队列的细节参见5.5章节。
4.10 Byte Queue Limits(BQL)
Byte Queue Limits (BQL) 是Linux内核(> 3.3.0)引入的一个新特性,用于尝试自动解决驱动程序队列大小的问题。该特性添加了一层处理,它会根据当前系统的情况计算出避免出现饥饿的最小缓冲大小,以此作为报文进入驱动队列的依据。回顾一下,队列中的数据总量越少,队列中的报文的最大延迟越小。
需要注意的是,BQL不会修改驱动队列的实际长度,相反,它会计算当前时间可以入队列的数据的(字节数)上限。当队列中的数据超过该限制之后,驱动队列的上层需要决定是否保留会丢弃这部分数据。
当发生两种情况时会触发BQL机制:当报文进入驱动队列,或当线路上的传输已经结束。下面给出了一个简单的BQL算法。LIMIT指BQL计算出的值。
****
** After adding packets to the queue
****
if the number of queued bytes is over the current LIMIT value then
disable the queueing of more data to the driver queue
BQL基于测试设备是否发生了饥饿现象,如果是,则增加LIMIT来允许更多的报文入队列,以此降低饥饿的概率。如果设备繁忙,且后续还有报文持续传输到队列中,当队列中的报文大于当前系统所需要的数量时,会降低LIMIT来限制饥饿。
下面给出一个真实的例子,可以帮助了解BQL能够在多大程度上影响排队的数据量。在一台服务器上,驱动队列的大小默认为256个描述符。由于以太网的MTU为1500字节,意味着驱动队列中的报文最大为256 * 1,500 = 384,000字节(禁用TSO,GSO等)。但此时BQL计算出的限制值为3012字节。如你所见,BQL大大限制了进入队列的数据量。
从名称的第一个单词可以推断出BQL的一个有趣的特点--字节。与驱动队列和其他大多数报文队列不同,BQL操作的是字节。这是因为相比报文数或描述符,字节数与物理媒介的传输时间有着更为直接的关系。
BQL将进入队列的数据量限制到避免饿死所需的最小数量,从而减少了网络延迟。它还有一个非常重要的副作用,那就是将大多数报文排队的点从驱动队列(一个简单的FIFO)移动到排队规则(QDisc)层,从而实现更复杂的排队策略。下一节将介绍Linux的QDisc层。
4.10.1 设置BQL
BQL算法是自适应的,并不需要过多的人为接入。但如果需要关注低比特率下的最佳延迟,则有可能需要覆盖计算出的LIMIT值。可以在/sys目录根据NIC的名称和位置下找到BQL的状态和配置。例如我的一台服务器上的eth0的目录为:
可以使用ethtool -i <接口名称>来查看设备的PCI号。
/sys/devices/pci0000:00/0000:00:14.0/net/eth0/queues/tx-0/byte_queue_limits
该目录中的文件为:
1.hold_time: 修改LIMIT的间隔时间,单位毫秒
2.inflight: 队列中还没有传输的字节数
3.limit: BQL计算出的LIMIT值。如果NIC驱动不支持BQL,则为0
4.limit_max: 可配置的LIMIT的最大值,减小该值可以优化延迟
5.limit_min: 可配置的LIMIT的最小值,增大该值可以优化吞吐量
要对可排队的字节数设置上限,请将新值写入limit_max文件:
echo "3000" > limit_max
5. 软件和工具
5.1 内核要求
许多发行版都为内核提供了模块化或整体式的流量控制(QOS)。自定义的内核可能不会支持这些特性。
对内核编译不了解或经验不多的用户建议阅读Kernel-HOWTO。对于熟练的内核编译者在了解流量控制之后就可以确定需要开启如下哪些选项。
例1.内核的编译选项
# QoS and/or fair queueing
#
CONFIG_NET_SCHED=y
CONFIG_NET_SCH_CBQ=m
CONFIG_NET_SCH_HTB=m
CONFIG_NET_SCH_CSZ=m
CONFIG_NET_SCH_PRIO=m
CONFIG_NET_SCH_RED=m
CONFIG_NET_SCH_SFQ=m
CONFIG_NET_SCH_TEQL=m
CONFIG_NET_SCH_TBF=m
CONFIG_NET_SCH_GRED=m
CONFIG_NET_SCH_DSMARK=m
CONFIG_NET_SCH_INGRESS=m
CONFIG_NET_QOS=y
CONFIG_NET_ESTIMATOR=y
CONFIG_NET_CLS=y
CONFIG_NET_CLS_TCINDEX=m
CONFIG_NET_CLS_ROUTE4=m
CONFIG_NET_CLS_ROUTE=y
CONFIG_NET_CLS_FW=m
CONFIG_NET_CLS_U32=m
CONFIG_NET_CLS_RSVP=m
CONFIG_NET_CLS_RSVP6=m
CONFIG_NET_CLS_POLICE=y
使用如上选项编译的内核可以为本文讨论的所有场景提供模块化支持。用户在使用一个给定的特性前可能需要执行modprobe *module*。
5.2 iproute2工具(tc)
iproute2是一个命令行套件,可以用于管理一台机器上与IP网络配置有关的内核结构。如果要查看这些工具技术文档,可以参阅iproute2文档,如果要了解更具探讨性的内容,请参阅linux-ip.net上的文档。在iproute2工具包中,二进制的tc是唯一用于流量控制的工具。本文档将忽略其他工具。
由于tc需要与内核交互来创建,删除和修改流量控制结构,因此在编译tc时需要支持所有期望的qdisc。实际上,在iproute2上游包中还不支持HTB qdisc。更多信息参见Section 7.1, “HTB, Hierarchical Token Bucket”。
tc工具会执行支持流量控制所需要的所有内核结构配置。由于它的用法多种多样,其命令语法也是晦涩难懂的。该工具将三个Linux流量控制组件(qdisc、class或filter)中的一个作为其第一个必选参数。
例2.tc命令的用法
# tc
Usage: tc [ OPTIONS ] OBJECT { COMMAND | help }
where OBJECT := { qdisc | class | filter }
OPTIONS := { -s[tatistics] | -d[etails] | -r[aw] }
每个对象都可以接收其他不同的选项,本文后续将会进行完整的描述。下例展示了tc命令行语法的多种用法。更多用法可以参见 LARTC HOWTO。如果要更好地了解tc,可以参阅内核和iproute2源码。
例3.tc qdisc
# tc qdisc add \ <1>
> dev eth0 \ <2>
> root \ <3>
> handle 1:0 \ <4>
> htb <5>
1.添加一个队列规则,动作也可以为del
2.指定附加新队列规则的设备
3.表示"ergess",此处必须使用root。另外一个qdisc的功能是受限的,ingress qdisc可以附加到相同的设备上
4.handle是一个使用major:minor格式指定的用户自定义号。当使用队列规则句柄时,次号必须为0。qdisc句柄可以简写为"1:"(等同于"1:0"),如果没有指定,则次号默认为0
5.附加的队列规则,上例为HTB。队列规则指定的参数将会跟在后面。上例中没有指定任何参数
上述展示了使用tc工具将一个队列规则添加到一个设备的用法。下面是使用tc给现有的父类添加类的用法:
例4.tc 类
# tc class add \ <1>
> dev eth0 \ <2>
> parent 1:1 \ <3>
> classid 1:6 \ <4>
> htb \ <5>
> rate 256kbit \ <6>
> ceil 512kbit <7>
1.添加一个类,动作也可以为del
2.指定附加的新类的设备
3.指定附加的新类的父句柄
4.表示类的唯一句柄(主:次)。次号必须为非0值
5.这两个classful qdiscs都要求任何子类使用与父类相同类型的类。此时一个HTB qdisc将包含一个HTB类
6.这是一个类指定的参数,更多参见Section 7.1, “HTB, Hierarchical Token Bucket”
例5. tc过滤器
# tc filter add \ <1>
> dev eth0 \ <2>
> parent 1:0 \ <3>
> protocol ip \ <4>
> prio 5 \ <5>
> u32 \ <6>
> match ip port 22 0xffff \ <7>
> match ip tos 0x10 0xff \ <8>
> flowid 1:6 \ <9>
> police \ <10>
> rate 32000bps \ <11>
> burst 10240 \ <12>
> mpu 0 \ <13>
> action drop/continue <14>
1.添加一个过滤器,动作也可以为del
2.指定附加的新过滤器的设备
3.指定附加的新过滤器的父句柄
4.该参数是必须的
5.prio 参数允许给定的过滤器优先于另一个过滤器
6.这是一个分类器,是每个tc过滤器命令中必需的部分
7-8.这些是分类器的参数。这种情况将选择具有tos类型(用于交互使用)和匹配端口22的数据包
9.flowid 指定了目标类(或qdisc)的句柄,匹配的过滤器应该将选定的数据包发送到该类
10.这是一个策略器,这是每个tc过滤器命令可选的部分
11.策略器会在速率达到某一个值后执行一个动作,并在速率低于某一值时执行另一个动作
12.突发与HTB中的突发类似(突发是桶的概念)
13.最小的策略单元,为了计算所有的流量,使用的mpu为0
14.action表示当rate与策略器的属性匹配时将会执行那些操作。第一个字段指定了当超过策略器后的动作,第二个字段指定了其他情况下的动作。
如上所示,即使对于上述简单的例子来说,tc命令行工具的语法也是晦涩难懂的,如果说存在一种更简单的方法来配置Linux流量控制,对于读者来说,应该不会感到惊讶。参见下一节Section 5.3, “tcng, Traffic Control Next Generation”。
5.3 tcng下一代流量控制
参见 Traffic Control using tcng and HTB HOWTO 以及 tcng 文档。
下一代流量控制(tcng)为Linux提供了所有流量控制的能力。
5.4 Netfilter
Netfilter是Linux内核提供的一个框架,允许使用自定义的格式来实现各种与网络有关的操作。它为报文过滤、网络地址转换、端口转换等提供了多种功能和操作,这些功能包括在网络中重定向报文所需的功能,以及提供禁止报文到达计算机网络中的敏感位置的功能。
Netfilter为一组Linux内核钩子,允许特定的内核模块将回调函数注册到内核的网络栈上。这些函数通常会用于流量的过滤和规则的修改,当报文经过网络栈的各个钩子时都会调用这些函数。
5.4.1 iptables
iptables是一个用户空间的应用程序,允许系统管理员配置由Linux内核防火墙(由不同的Netfilter实现)提供的表以及其保存的链和规则。不同的内核模块和程序目前用于不同的协议,iptables用于IPv4,ip6tables用于IPv6,arptables用于ARP,ebtables用于以太帧。
iptables需要提升到特权才能运行,并且必须由root用户执行,否则无法运行。在大多数Linux系统上,iptables安装在/usr/sbin/iptables 下,且有对应的man文档。此外iptables安装还可能安装在/sbin/iptables下,但相比于一个基本的二进制可执行文件,iptables更像一个服务,因此最好将其保留在/usr/sbin下面。
术语iptables也通常用于指内核级的组件。x_tables是内核模块的名称,其中包含四个模块所使用的共享代码部分,这些模块还提供了用于扩展的API。后来,Xtables或多或少被用来指整个防火墙(v4、v6、arp和eb)体系结构。
Xtables允许系统管理员定义包含处理报文的规则的表。每个表都与一个不同类型的报文处理相关联。报文会按照顺序通过链中的规则来处理。链中的一个规则可能会跳转到另外一个链,通过这种方式可以做到任意级别的嵌套。每个到达或离开计算机的报文都会经过至少一个链。
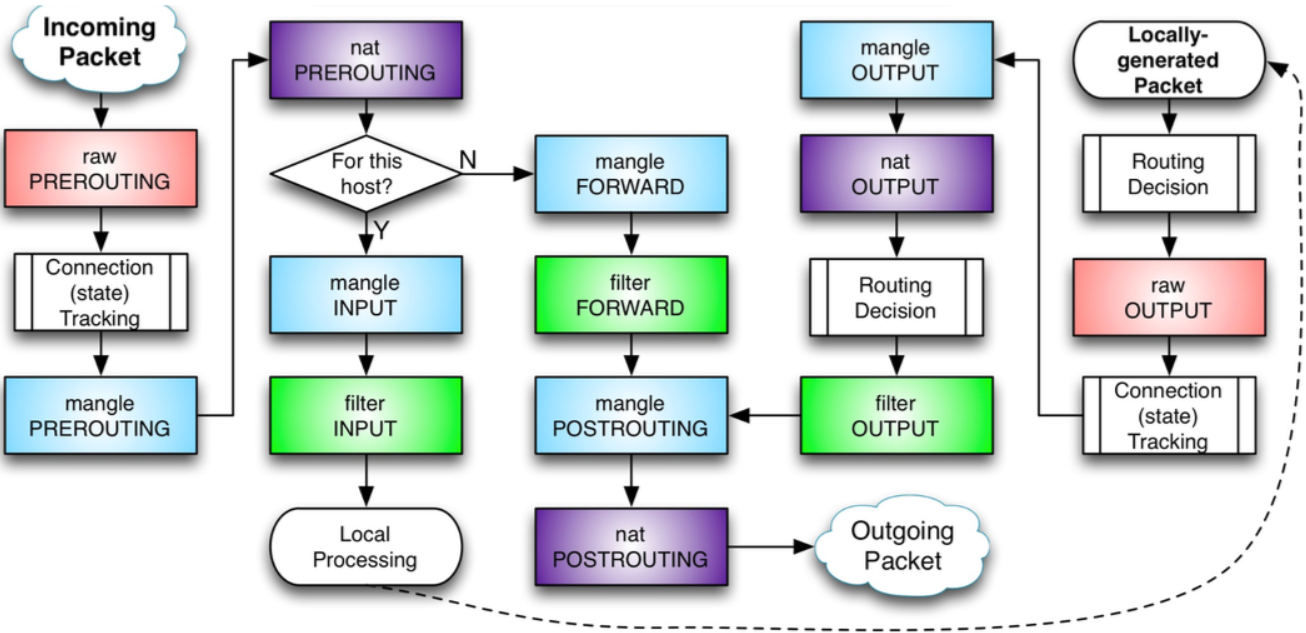
报文的源可以决定该报文首先进入哪个链。iptables中预定义了五个链(对应五个Netfilter钩子),但不是每个表都包含所有的链。
预定义的链都有一个策略,如DROP,即当报文到达链尾时会执行丢弃动作。系统管理员可以按照需要创建任意多的链,新创建的链并没有任何策略,当报文到达链尾时,会返回到调用该链的位置。一个链也可能是空的。
1.PREROUTING: 报文在进行路由处理前会进入该链。
2.INPUT: 报文会上送到本地,它与本地打开的socket没有任何关系。本地上送的逻辑由"本地上送"路由表控制。可以使用ip route show table local命令查看
3.FORWARD: 所有已经路由到非本地的报文将会经过该链
4.OUTPUT: 本机发送的报文会经过该链
5.POSTROUTING: 在完成路由决策后,报文传递给硬件之前进入这个链
链中的每个规则都包含报文匹配的规范,还有可能包含目标(target,用于扩展)或判定(verdict,内置决策之一)。当一个报文进入一条链后,会按照顺序逐一检查链中的每条规则,如果这条规则不匹配,则检查下一条规则。如果一个规则匹配报文,那么就会按照规则中的目标/判定指定的动作来处理该报文,执行的结果可能会允许或拒绝继续在链中处理报文。由于匹配包含了报文检测的条件,因此其占了规则集的绝大部分。这些匹配场景可能发生在OSI模型的任何层,例如——mac-source和-p tcp——dport参数,此外也可以包含独立于协议的匹配规则,如-m时间。
报文会继续在链中处理,直到发生下面任意一种情况:
1.匹配到一条规则(且该规则决定了报文的最终命运,如调用了ACCEPT或DROP),或使用了一个决定报文最终命运的模块。
2.规则调用了RETURN,导致处理返回到调用链。
3.到达链尾,后续会在父链中继续处理(如果使用了RETURN),或基于链策略处理。
目标也会返回类似ACCEPT(NAT模块会这么做)或DROP(如REJECT模块)的判定,但也可能会暗示CONTINUE(如LOG模块;CONTINUE是一个内部名称)来继续处理下一个规则(如果没有指定任何目标/判定)。
5.5 IMQ,中间队列设备
中间队列设备并不是qdisc,但它的用法与qdiscs紧密相关。在Linux中,qdisc会附加到网络设备上,任何要进入设备的报文,首先会进入qdisc,然后才会进入驱动队列。从这个观点看,会有两个限制:
1.只能做egress整流(虽然存在ingress qdisc,但相对于classful qdisc来说,其功能非常有限)
2.一个qdisc只能看到一个接口的流量,无法做全局限制
IMQ用于解决这两大限制。简单地说,可以将任意选定的内容放到一个qdisc中。特殊标记的报文会在netfilter NF_IP_PRE_ROUTING 和NF_IP_POST_ROUTING钩子中被拦截,并通过附加的qdisc传递给imq设备。iptables目标可以用于标记报文。
这种方式允许对ingress流量进行整流,只要标记来自某处的报文,并/或将接口当作类来设置全局的限制。此外做很多其他的事情,比如把http流量放到qdisc中,把新的连接请求放到qdisc中等。
5.5.1 配置示例
下面使用ingress整流来授权一个高带宽。对其他接口的配置类似:
tc qdisc add dev imq0 root handle 1: htb default 20
tc class add dev imq0 parent 1: classid 1:1 htb rate 2mbit burst 15k
tc class add dev imq0 parent 1:1 classid 1:10 htb rate 1mbit
tc class add dev imq0 parent 1:1 classid 1:20 htb rate 1mbit
tc qdisc add dev imq0 parent 1:10 handle 10: pfifo
tc qdisc add dev imq0 parent 1:20 handle 20: sfq
tc filter add dev imq0 parent 10:0 protocol ip prio 1 u32 match \ ip dst 10.0.0.230/32 flowid 1:10
本例使用u32来分类。此外还可以使用其他分类器,后续的流量将会被选择并打上标记,最后入队列到imq0。
iptables -t mangle -A PREROUTING -i eth0 -j IMQ --todev 0
ip link set imq0 up
在iptables的mangle表的PREROUTING 和POSTROUTING 链中可以配置IMQ目标。语法为:
IMQ [ --todev n ] n : number of imq device
也支持ip6tables目标。
注意,流量不是在目标被匹配时进入队列,而是在匹配之后。当流量进入imq设备之后的具体位置取决于流量的方向(进/出)。这些位置由iptables预定义的netfilter 钩子决定。
enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN,
NF_IP_PRI_CONNTRACK = -200,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_NAT_SRC = 100,
NF_IP_PRI_LAST = INT_MAX,
};
对于ingress流量,imq会使用NF_IP_PRI_MANGLE + 1 的优先级,意味着在处理完PREROUTING 链之后,报文会直接进入imq设备。
对于使用NF_IP_PRI_LAST 的egress流量,意味着,被过滤表丢弃的报文将不会占用带宽。
5.6 ethtool,驱动队列
ethtool 命令用于控制以太接口的驱动队列大小。ethtool 也提供了底层接口的信息以及启用/禁用IP栈和驱动特性的能力。
ethtool 的-g标志可以展示驱动队列(ring)的参数:
$ ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 16384
RX Mini: 0
RX Jumbo: 0
TX: 16384
Current hardware settings:
RX: 512
RX Mini: 0
RX Jumbo: 0
TX: 256
可以看到该NIC的驱动的输出队列为256个描述符。为了减少延迟,通常建议降低驱动队列的大小。在引入BQL(假设NIC驱动支持)之后,就不需要修改驱动队列了。
ethtool还可以管理如 TSO, UFO 和GSO这样的优化特性。-k表示展示了当前设置的卸载,可以使用-K进行修改。
$ ethtool -k eth0
Offload parameters for eth0:
rx-checksumming: off
tx-checksumming: off
scatter-gather: off
tcp-segmentation-offload: off
udp-fragmentation-offload: off
generic-segmentation-offload: off
generic-receive-offload: on
large-receive-offload: off
rx-vlan-offload: off
tx-vlan-offload: off
ntuple-filters: off
receive-hashing: off
由于TSO, GSO, UFO和GRO通常会增加驱动队列中的报文字节数,如果需要优化延迟(而非吞吐量),建议关闭这些特性。除非系统正在处理非常高速率的数据,否则禁用这些特性时,可能不会注意到任何CPU影响或吞吐量下降。
6. Classless Queuing Disciplines (qdiscs)
本文涉及的队列规则(Qdisc)都可以作为接口上的主qdisc,或作为一个classful qdiscs的叶子类。这些是Linux下使用的基本调度器。默认的调度器为pfifo_fast。
6.1 FIFO,先进先出(pfifo和bfifo)
注:虽然FIFO是队列系统中最简单的元素之一,但pfifo和bfifo都不是Linux接口上的默认qdisc。参见 Section 6.2, “pfifo_fast, the default Linux qdisc”了解更多关于默认qdisc(pfifo_fast)的信息。
6.1.1 pfifo, bfifo算法
FIFO算法是所有Linux网络接口的默认qdisc(pfifo_fast)。它不会对报文进行整流和重排,仅在接收到报文并在报文入队列后尽快将其发送出去。这也是新创建的类使用的qdisc(除非使用其他的qdisc或类替换FIFO)。
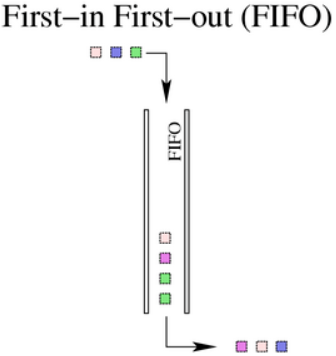
FIFO算法维护了一个报文列表,当一个报文入队列后,会将其插入队列末尾。当需要将一个报文发送到网络上时,会将列表首部的报文进行发送。
6.1.2 limit参数
真实的FIFO qdisc必须限制列表的大小(缓冲大小)来防止溢出,这种情况下无法将接收到的报文入队列。Linux实现了两个基本的FIFO qdisc,一个基于字节数,另一个基于报文。如果不考虑使用的FIFO类型,队列的大小由参数limit决定。对于pfifo(Packet limited First In, First Out queue),其单位为报文,对于bfifo(Byte limited First In, First Out queue) ,其单位为字节。
对于pfifo,大小默认等于接口的txqueuelen,可以使用ifconfig或ip查看。该参数的范围为[0, UINT32_MAX]。
对于bfifo,大小默认等于txqueuelen乘以接口MTU。该参数的范围为[0, UINT32_MAX]字节。在计算报文长度时会考虑链路层首部。
例6. 为一个报文FIFO或字节FIFO指定一个limit
# cat bfifo.tcc
/*
* make a FIFO on eth0 with 10kbyte queue size
*/
dev eth0 {
egress {
fifo (limit 10kB );
}
}
# tcc < bfifo.tcc
# ================================ Device eth0 ================================
tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0
tc qdisc add dev eth0 handle 2:0 parent 1:0 bfifo limit 10240
# cat pfifo.tcc
/*
* make a FIFO on eth0 with 30 packet queue size
*/
dev eth0 {
egress {
fifo (limit 30p );
}
}
# tcc < pfifo.tcc
# ================================ Device eth0 ================================
tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0
tc qdisc add dev eth0 handle 2:0 parent 1:0 pfifo limit 30
6.1.3. tc –s qdisc ls
tc -s qdisc ls的输出包含limit(报文数或字节数),以及实际发送的字节数和报文数。未发送和丢弃的报文使用括号括起来,并不计算在Sent之内。
本例中,队列长度为1000个报文,发送的681个报文的大小为45894 字节。没有丢包,由于pfifo不会降低报文的速率,因此没有overlimits:
$ tc -s qdisc ls dev eth0
qdisc pfifo 8001: dev eth0 limit 100p
Sent 45894 bytes 681 pkts (dropped 0, overlimits 0)
如果出现积压(overlimits),也会显示出来。
与所有非默认的qdisc一样,pfifo和bfifo会维护统计数据。
6.2. pfifo_fast, 默认的Linux qdisc
pfifo_fast (three-band first in, first out queue) qdisc是Linux上所有接口使用的默认qdisc。当创建一个接口后,会自动使用pfifo_fast qdisc队列。如果附加了其他qdisc,这些qdisc则会抢占默认的pfifo_fast,当移除现有的qdisc时,pfifo_fast会自动恢复运行。
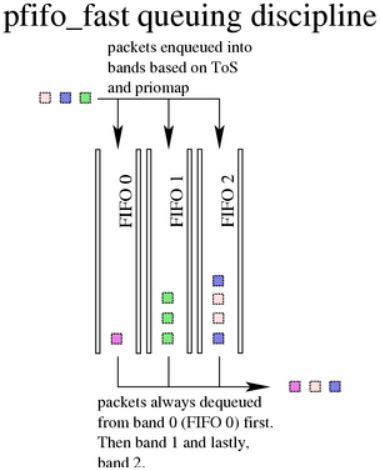
6.2.1. pfifo_fast算法
该算法基于传统的FIFO qdisc,但同时也提供了一些基于优先级的处理。它使用三个不同的band(独立的FIFO)来分割流量。具有最高优先级的流量(交互式流量)会进入band 0,总是会被优先处理。类似地,在band 2出队列之前,band 1中不会存在未处理的报文。
该算法与classful prio qdisc非常类似。pfifo_fast qdisc就像三个并排的pfifo队列,一个报文可以根据其服务类型(ToS)位进入其中某一个FIFO。三个band并不能同时入队列(当具有最小值,即优先级高的band包含流量时,具有高数值的,即优先级低的band就不能出队列)。这样可以优先处理交互流量,或者对“最低成本”的流量进行惩罚。每个band最多可以容纳txqueuelen 大小的报文,可以使用ifconfig或ip配置。当接收到额外的报文时,如果特定的band满了,则会丢弃该报文。
参见下面的6.2.3章节来了解ToS为如何转换为band。
6.2.2. txqueuelen 参数
三个band的长度取决于接口的txqueuelen。
6.2.3. Bugs
终端用户无需对pfifo_fast qdisc进行配置。下面是默认配置。
priomap决定了报文的优先级,由内核分配并映射到bands。内核会根据报文的八个比特位的ToS进行映射,ToS如下:

四个ToS位的定义如下:

可以使用 tcpdump -v -v 显示整个报文的ToS字段(不仅仅是四个比特位的内容)。
上面展示了很多数值,第二列包含于ToS比特位相关的数值,后面是其对应的意义。例如15表示期望最小货币开销,最大可靠性,最大吞吐量以及最小延迟。
上述四列的内容给出了Linux是如何解析ToS 比特位的,以及它们被映射到的优先级,如优先级4映射到的band 号为1。允许映射到更高的优先级(>7),但这类优先级与ToS映射无关,表示其他意义。
最后一列给出了默认的优先级映射的结果。在命令行中,默认的优先级映射为:
1, 2, 2, 2, 1, 2, 0, 0 , 1, 1, 1, 1, 1, 1, 1, 1
与其他非标准的qdisc不同,pfifo_fast不会维护信息,且不会展示在tc qdisc ls命令中。这是因为它是默认的qdisc。
6.3. SFQ, 随机公平队列
随机公平队列是tc命令使用的用于流量控制的classless qdisc。SFQ不会整流,仅负责根据流来调度传输的报文,目的是保证公平,这样每个流都能够依次发送数据,防止因为单条流影响了其他流的传输速率。SFQ使用一个哈希函数将流分到不同的FIFO中,使用轮询的方式出队列。因为在哈希函数的选择上存在不公平的可能性,该函数会周期性地改变,通过扰动(参数perturb)来设置此周变动期性(参见6.3.3参数)。
因此,SFQ qdisc会在任意多的流中,尝试给每条流分配相同的机会来发送数据。
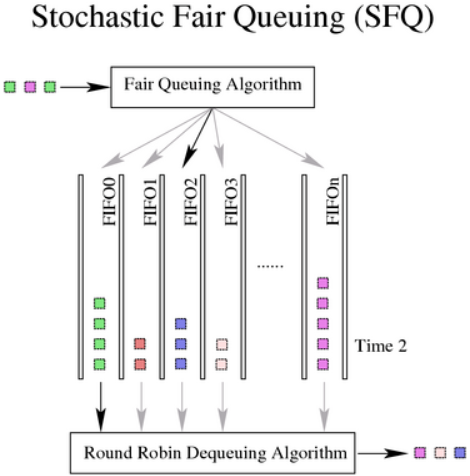
6.3.1. SFQ 算法
在进入队列之后,会基于报文的哈希值给每个报文分配一个哈希桶。该哈希值可能是从外部的流分类器获取到的,如果没有配置外部分类器,则使用默认的内部分类器。当使用内部分类器时,sfq会使用:
1.源地址
2.目的地址
3.源和目的端口
SFQ能够区分ipv4,ipv6,以及UDP,TCP和ESP等。其他协议的报文会基于32位的目的和源进行哈希。一条流大多数对应一个TCP/IP连接。
每个桶都应该表示唯一的一条流。由于多条流可能哈希到同一个桶,sdq的内部哈希算法可能会在可配置的时间间隔内受到干扰,但不公平仅会持续很短的一段时间。然而,扰动可能会在无意中导致发送报文的重排。在Linux 3-3之后,就不会存在报文重排的问题,但可能在重哈希达到上限(流的数目或每条流的报文数)后丢弃报文。
当出队列时,会以轮询的方式请求每个哈希桶的数据。
在Linux3-3之前,SFQ 的最大长度为128个报文,即最多可以分布在128个桶(1024个可用桶)上。当发生溢出时,满的桶会发生尾部丢弃,从而保持公平性。
在Linux3-3之后,SFQ 的最大长度为65535 个报文,除数的极限是65536。当发生溢出时,除非明确要求头部丢弃,否则满的桶会发生尾部丢弃,
6.3.2. 命令行使用
tc qdisc ... [divisor hashtablesize] [limit packets] [perturb seconds] [quantum bytes] [flows number] [depth number] [head drop] [redflowlimit bytes] [min bytes] [max bytes] [avpkt bytes] [burst packets] [probability P] [ecn] [harddrop]
6.3.3. 参数
divisor: 可以用于设置不同的哈希表大小,从2.6.39内核开始可用。指定的除数必须是2的幂,并且不能大于65536。默认为1024。
limit: SFQ limit的上限。可以用于减少默认的127个报文长度。在linux-3.3之后,可以增加该值。
depth: 每条流的报文限制(linux-3.3之后)。默认为127,可以降低。
perturb: 队列算法干扰的时间间隔(秒)。默认为 0,意味着不会发生干扰。不要设置过低的值,因为每个干扰都可能导致报文的重排或丢失。建议值为60。当使用外部流分类时,该值将不起作用。为了降低哈希冲突,可以增加该建议值。
quantum: 在轮询处理期间允许出队列的字节数。默认为接口的MTU,这也是建议的最小值。
flows: 在linux-3.3之后,可以修改默认的流的限制,默认为127。
headdrop: 默认的SFQ行为是尾部丢弃一条流的报文。也可以使用首部丢弃,可以给TCP流提供更好的反馈。
redflowlimit: 在每个SFQ流上配置可选的RED模块(用于防止产生bufferbloat问题)。RED(Random Early Detection)的原理是以概率的方式标记或丢弃报文。redflowlimit对每条SFQ流队列的大小作了硬性限制,单位为字节。(以下参数为RED的参数)
min: 可以进行标记的平均队列大小,默认为max的三分之一。
max: 在此平均队列大小下,标记的概率最大。默认为 redflowlimit的四分之一。
probability: 可以用于标记的最大概率,为一个0.0到1.0的浮点数,默认为0.02。
avpkt: 以字节为单位。与burst一起用于确定平均队列大小计算的时间常数,默认为1000。
burst: 用于确定真实队列大小对平均队列大小的影响速度,默认为: (2 * min + max) / (3 * avpkt)。
ecn: RED可以执行"标记"或"丢弃 "。显式的拥塞通知(Explicit Congestion Notification)允许RED通知远程主机它们的速率超过了可用带宽。没有启用ECN的主机可能会接收到报文丢弃的通知。如果指定了该参数,那么支持ECN的主机的报文将会被标记,而不会被丢弃(除非队列满)。
harddrop: 如果平均流队列长度大于max字节数,该参数会强制丢弃报文,而不会执行ecn标记。
SFQ中比较容易混淆的是参数:limit,depth,flows这三个参数。limit用于限制SFQ的队列数目,depth用于限制每条流的数目,flows用于限制流的数目。SFQ会对报文进行哈希,将哈希结果相同的报文作为同一条流上的报文,然后将这条流单独放到一个队列中(受限于哈希算法,有可能存在实际上多个不同的流被哈希成了SFQ中的同一条流,因此引入了perturb)。
6.3.4 例子和用法
附加到ppp0口。
$ tc qdisc add dev ppp0 root sfq
请注意SFQ和其他非整流的qdisc一样,仅对其拥有的队列有效。链路速度等于实际可用的带宽时就是这种情况。适用于常规电话调制解调器,ISDN连接和直接非交换式以太网链接。
大多数情况下,有线调制解调器和DSL设备不属于这一类。当连接到交换机并尝试将数据发送到同样连接到该交换机的拥塞段时,情况也是如此。在这种情况下,有效队列并不在Linux内,因此不能用于调度。在classful qdisc中嵌入SFQ可以确保它拥有该队列。
可以在sfq中使用外部分类器,例如基于源/目的IP地址对流量进行哈希:
$ tc filter add ... flow hash keys src,dst perturb 30 divisor 1024
注意给定的divisor应该匹配sfq使用的一个哈希表。如果修改了sfq的divisor的默认值1024,则流哈希过滤器也会使用相同的值。
例7. 带可选RED模块的SFQ
# tc qdisc add dev eth0 parent 1:1 handle 10: sfq limit 3000 flows 512 divisor 16384 redflowlimit 100000 min 8000 max 60000 probability 0.20 ecn headdrop
例8. 创建一个SFQ
# cat sfq.tcc
/*
* make an SFQ on eth0 with a 10 second perturbation
*/
dev eth0 {
egress {
sfq( perturb 10s );
}
}
# tcc < sfq.tcc
# ================================ Device eth0 ================================
tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0
tc qdisc add dev eth0 handle 2:0 parent 1:0 sfq perturb 10
不幸的是,一些聪明的软件(如Kazaa和eMule等)会通过打开尽可能多的TCP会话(流)来消除公平排队带来的好处。在很多网络中,对于行为良好的用户,SFQ可以充分地将网络资源分配给竞争的流,但当遭受恶意软件入侵网络时,可能需要采取其他措施。
可以参见说明文档:man tc-sfq。
SFQ是多队列算法,RED是单队列算法,可以通过结合两个算法来达到更好的流量控制的目的。
6.4. ESFQ, 扩展随机公平队列
从概念上而言,虽然这类qdisc相比SFQ给用户提供了更多的参数,但它与SFQ并没有什么不同。该qdisc旨在解决上述SFQ的缺点。通过允许用户控制用于分配网络带宽的哈希算法(hash参数),有可能实现更加公平的带宽分配。
例9. ESFQ用法
Usage: ... esfq [ perturb SECS ] [ quantum BYTES ] [ depth FLOWS ]
[ divisor HASHBITS ] [ limit PKTS ] [ hash HASHTYPE]
Where:
HASHTYPE := { classic | src | dst }
6.5. RED,Random Early Drop
随机早期探测(Random Early Detection)是一种灵活的用于管理队列大小的classless qdisc。一般的队列在满后会从尾部丢弃报文,这种行为有可能不是最优的。RED也会执行尾部丢弃,但是以一种更平缓的方式。
一旦队列达到特定的平均长度,入队列的报文会有一定的(可配置)概率会被标记(有可能意味着丢弃该报文),这个概率会线性地增加到某一点,称为最大平均队列长度(队列也可能会变更大)。
相比简单的尾部丢弃,这样做有很多好处,且不会占用大量处理器。这种方式可以避免在流量突增之后导致的同步重传(这些重传会导致更多的重传)。这样做的目的是使用一个比较小的队列长度,在信息的交互的同时不会因为在流量突增之后导致的丢包而干扰TCP/IP流量。
取决于配置的ECN,标记有可能意味着丢弃或仅仅表示该报文是超限的报文。
6.5.2. Algorithm
平均队列大小用于确定标记的概率,该概率是使用指数加权平均算法计算出来的,通过该值可以调节对流量突发的敏感度。当平均队列大小低于最小字节时,此时不会标记任何报文;当超过最小字节时,概率会直线上升到probability(参数指定),直到平均队列大小达到最大字节数。因为通常不会将概率设置为100%,而队列大小也可能会超过最大字节,因此,limit参数用于硬性设置队列大小的最大值。
大致工作方式为:
1.低于min:此时不做任何处理,队列压力较小,可以直接正常处理。
2.在min和max之间:此时界定为队列感受到阻塞压力,开始按照某一几率P从队列中丢包,几率计算公式为:P = probability * (平均队列长度 - min)/(max - min)。
3.高于max:此时新入队的请求也将丢弃。
6.5.3. 用法
$ tc qdisc ... red limit bytes [min bytes] [max bytes] avpkt bytes [burst packets] [ecn] [harddrop] [bandwidth rate] [probability chance] [adaptive]
6.5.4. 参数
min: 可能进行标记的平均队列大小。默认为 max/3.
max: 当平均队列大小达到该值后,标记的概率值是最大的。为了避免同步重传,应该至少是min的两倍,且大于最小的min值,默认为limit/4。
probability: 标记的概率的最大值,为0.0到1.0之间的浮点数,建议值为0.01或0.02(分别表示1%或2%),默认为0.02。
limit: 真实(非平均)队列的硬性限制,单位为字节。应该大于max+burst的值。建议将这个值设置为最大值的几倍。
burst: 用于决定平均队列大小受真实队列大小影响的速度。更大的值会延缓计算的速度,从而允许在标记开始之前出现更长的流量突发。实际经验遵循如下准则: (min+min+max)/(3*avpkt)。
avpkt: 单位是字节,与burst一起确定平均队列长度的时间常数。建议值1000。
bandwidth: 该速率用于在一段空闲时间之后计算平均队列的大小,设置为接口的带宽。并不意味着RED会进行整流。可选,默认值为10Mbit。
ecn: 如上所述,RED可以执行"标记"或"丢弃",显式拥塞通知允许RED通知远程主机它们的速率超过了可用带宽。不支持ECN的主机仅会通知报文丢弃。如果指定了该参数,支持ECN的主机上的报文只会被标记而不会被丢弃(除非队列达到limit的字节数),推荐使用。
harddrop: 如果平均流大小大于max字节数,该参数会强制丢弃报文,而不是进行ECN标记。
adaptive: (linux-3.3新加的功能 ) 在自适应模式中设置RED,参见 http://icir.org/floyd/papers/adaptiveRed.pdf,自适应的RED的目的是在1%和50%之间动态设置probability,以达到目标平均队列:(max-min)/2。
6.5.5. 例子
# tc qdisc add dev eth0 parent 1:1 handle 10: red limit 400000 min 30000 max 90000 avpkt 1000 burst 55 ecn adaptive bandwidth 10Mbit
6.6. GRED, Generic Random Early Drop
GRED用在DiffServ 实现中,且在物理队列中包含虚拟队列(VQ)。当前,虚拟队列的数值限制为16。
GRED分两步配置:首先是通用的参数,用于选择虚拟队列DPs的数目,以及是否打开类RIO的缓冲区共享方案。此时会选择一个默认的虚拟队列。
其次为单独的虚拟队列设置参数。
6.6.1. 用法
... gred DP drop-probability limit BYTES min BYTES max BYTES avpkt BYTES burst PACKETS probability PROBABILITY bandwidth KBPS [prio value]
OR
... gred setup DPs "num of DPs" default "default DP" [grio]
6.6.2. 参数
setup: 表示这是一个GRED的通用设置
DPs: 虚拟队列的数目
default: 指定默认的虚拟队列
grio: 启用类RIO的缓冲方案
limit: 定义虚拟队列的"物理"限制,单位字节
min: 定义最小的阈值,单位字节
max: 定义最大的阈值,单位字节
avpkt: 平均报文大小,单位字节
bandwidth: 接口的线路速度
burst: 允许突发的平均大小的报文数目
probability: 定义丢弃的概率范围 (0…)
DP: 标识分配给这些参数的虚拟队列
prio: 如果在通用参数中设置了grio,则表示虚拟队列的优先级
6.7. TBF,令牌桶过滤器
该qdisc构建在令牌和桶上。它会对接口上传输的流量进行整形(支持整流)。为了限制特定接口上出队列的报文的速度,TBF qdisc是个不错的选择。它仅会将传输的流量下降到特定的速率。
只有在包含足够的令牌时才能传输报文。否则,会推迟报文的发送。以这种方式延迟的报文将报文的往返时间中引入人为的延迟。
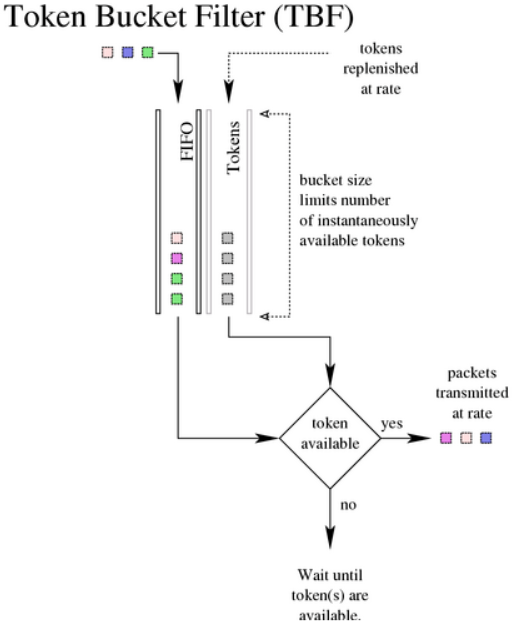
6.7.1. 算法
如其名称所示,对流量的过滤会基于消耗的令牌。令牌会大致对应到字节数,每个报文会消耗一个令牌,无论该报文有多小。这样会导致零字节的报文占用一定的链路时间。在创建时,TBF会保存一定的令牌,以应对一次性流量突发的量。令牌会以稳定的速率放到桶中,直到桶满为止。如果没有可用的令牌,则报文会保留在队列中(队列中的报文不能超过配置的上限)。TBF会计算令牌的亏空,并进行节流,直到可以发送队列中的第一个报文。如果不能接收最大速度的报文突发,可以配置峰值速率来限制桶清空的速度。峰值速率使用第二个TBF来实现,其桶相对较小,因此不会发生突发。
6.7.2. 参数
1.limit or latency:limit表示可以在队列中等待令牌的字节数。还可以通过设置延迟参数的方式变相地设置此值,延迟参数指定了报文可以在TBF中停留的最大时间。后者的计算会使用到桶的大小,速率和峰值速率(如果设置) 。这两个参数是互斥的。
2.Burst:即突发或最大突发。等于桶的大小,单位是字节。这是令牌在一瞬间可用的最大字节数。通常大的整流速率需要大的缓冲。如对于Intel上的10mbit/s,则至少需要10kbyte的缓冲才能跟上配置的速率。如果缓存过小,可能导致报文丢失,此时每个时间点到达的报文要大于桶的可用容量。最小的缓冲大小可以用频率除以HZ计算出来。
对令牌使用的计算是通过一个表来计算的,该表默认情况下有8个报文的分辨率。可以通过指定突发的单元大小来更改此分辨率。例如,为了指定一个6000字节的缓冲,其单元大小为16字节,需要将突发设置为6000/16。单元大小必须是2的整数次幂。
3.Mpu:零大小的报文不会使用零带宽。对于以太网来说,报文的大小不能小于64字节。最小的报文单元(MTU)决定了一个报文使用的最小令牌(单位字节),默认是0。
4.Rate:速度旋钮。此外,如果需要峰值速率,可以使用以下参数:
5.peakrate:桶的最大消耗速率。只有在需要毫秒级别的整流时才会用到峰值速率。
6.mtu/minburst:指定了峰值速率的桶大小。为了精确计算,应该将其设置为MTU的大小。如果用了峰值速率,但有些突发又是可以接受的,则可以增加该值的大小。一个3000字节的minburst可以允许3mbit/s的峰值速率,支持1000字节的报文。与常规的突发大小一样,也可以指定单元大小。
6.7.3. 例子
例10. 创建一个 256kbit/s 的TBF
# cat tbf.tcc
/*
* make a 256kbit/s TBF on eth0
*/
dev eth0 {
egress {
tbf( rate 256 kbps, burst 20 kB, limit 20 kB, mtu 1514 B );
}
}
# tcc < tbf.tcc
# ================================ Device eth0 ================================
tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0
tc qdisc add dev eth0 handle 2:0 parent 1:0 tbf burst 20480 limit 20480 mtu 1514 rate 32000bps
7. Classful Queuing Disciplines
可以使用classful qdisc的代理来解锁Linux流量控制的灵活性和控制力。classful qdisc可以附加过滤器,允许将报文重定向到特定的类和子队列。
有几个常见的术语用来描述直接附加到root qdisc和终止类的类。附加到root qdisc的类称为根类,一般为内部类。任何特定qdisc中的终止类称为叶类,类似于树形结构的类。除了把结构比喻成一棵树外,通常也会使用家庭关系进行比喻。
7.1. HTB, 层级令牌桶
HTB是Linux中CBQ(参阅第7.4章)qdisc的一种更易理解和直观的替换品。CBQ和HTB可以控制给定链路上的出站带宽。这两种方式都可以使用一个物理链路来模拟多个较慢的链接,并将不同的链路发送到不同的模拟链路上。在这两种情况下,必须指定如何将物理链路划分为模拟链路,以及确定要发送的报文使用哪个模拟链路。
HTB使用了令牌和桶的概念,并使用了基于类的系统和过滤器对流量进行复杂和细粒度的控制。通过一个复杂的借用模型,HTB可以实现各种复杂的流量控制技术。另一种最简单的方式是在整流时使用HTB。
通过理解令牌和桶或掌握HTB的功能可以了解到,HTB仅仅是一个逻辑上的步骤。该qdisc允许用户定义令牌和桶的特性,并允许用户任意嵌套这些桶。当与分类方案结合使用时,可以以非常细粒度的方式控制流量。
例11. HTB的tc用法:
Usage: ... qdisc add ... htb [default N] [r2q N]
default minor id of class to which unclassified packets are sent {0}
r2q DRR quantums are computed as rate in Bps/r2q {10}
debug string of 16 numbers each 0-3 {0}
... class add ... htb rate R1 burst B1 [prio P] [slot S] [pslot PS]
[ceil R2] [cburst B2] [mtu MTU] [quantum Q]
rate rate allocated to this class (class can still borrow)
burst max bytes burst which can be accumulated during idle period {computed}
ceil definite upper class rate (no borrows) {rate}
cburst burst but for ceil {computed}
mtu max packet size we create rate map for {1600}
prio priority of leaf; lower are served first {0}
quantum how much bytes to serve from leaf at once {use r2q}
TC HTB version 3.3
7.1.1. 软件要求
不同于前面讨论的几乎所有软件,HTB是一个新的qdisc,现有的发行版可能缺少使用HTB所需要的所有软件和能力。内核版本2.4.20及其以后的版本会支持HTB,早期的内核版本需要打补丁。为了在用户空间支持HTB,参见HTB。
7.1.2. 整流
HTB的最常见应用之一是将传输的流量调整到特定速率。
所有的整流都发生在叶类上。内部或根类上不会发送整流,这些类仅会在借用模型中给出如何分配可用的令牌。
7.1.3. 借用
HTB的一个基本功能是借用机制。当子类超速率之后会借用父类的令牌。在达到ceil(此时子类会有数据包排队,等待传输,直到有更多可用的令牌为止。)之前,子类会持续尝试借用父类的令牌。由于使用HTB仅可以创建两种主要的类(叶子类和内部类),因此下面的表和图区分了借用机制的各种可能的状态和行为。
表2.HTB类型状态和和潜在的action令牌
| type of class | class state | HTB internal state | action taken |
|---|---|---|---|
| leaf | < rate | HTB_CAN_SEND | 叶子类会出站队列中的数据,不能大于突发的报文。 |
| leaf | > rate, < ceil | HTB_MAY_BORROW | 叶子类会尝试从父类借用令牌(tokens/ctokens)。如果有可用的令牌,则以quantum增量的方式借出,且叶子类的出站速率不能大于cburst字节。 |
| leaf | > ceil | HTB_CANT_SEND | 没有出队列的报文。会导致报文延迟,并增加延迟以满足所需的速率。 |
| inner, root | < rate | HTB_CAN_SEND | 内部类会给子类借用令牌 |
| inner, root | > rate, < ceil | HTB_MAY_BORROW | 叶子类会尝试从父类借用令牌(tokens/ctokens),父类会以quantum递增的方式将令牌借给竞争的子类。 |
| inner, root | > ceil | HTB_CANT_SEND | 内部类不会尝试从父类借用令牌,且父类不会将令牌借给子类。 |
下图展示了借用令牌的流程,被借用的令牌会计入父类。为了借用模型能够正常工作,每个类都必须精确计算自身和子类使用的令牌。基于这种原则,子类或叶子类使用的令牌会计入父类中,直到到达root类。
任何想要借用令牌的子类会从其父类中请求一个令牌,如果父类也达到了rate的限制,它将会向自己的父类借用令牌,以此类推,直到找到一个可用的令牌或达到root类为止。因此借用的令牌会流向叶子类,而对令牌的统计则会流向root类。
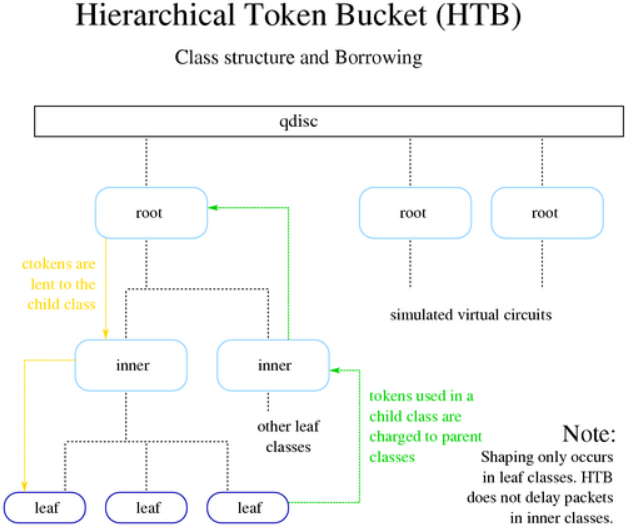
注意:上图中有好几个HTB root类,每个root类都可以模拟一个虚拟回路。
7.1.4. HTB 类参数
default
每个HTB qdisc对象可选的参数,默认的default为0,这样未分类的流量会使用硬件速度出队列,不会经过附加到root qdisc的所有类。
rate
用于设置限制传输流量的最小速度。可以认为其相当于信息的提交速率,或为一个给定的叶子类保证的带宽。
ceil
用于设置限制传输流量的最大速度。借用模型应该说明如何使用该参数。可以认为其等同于"突发的带宽"。
burst
rate的桶大小。HTB在等待更多令牌前可以入队列burst字节的数据。
cburst
ceil 的桶大小。HTB在等待更多ctokens前可以入队列cburst 字节的数据。
quantum
这是HTB用于控制借用的关键参数。通常HTB会计算一个正确的quantum,用户无需指定。修改该值会对竞争下的借用和整流造成巨大的影响(因为它会在流量超过rate(且低于ceil)的子类间对流量进行分割,并传输这些子类的报文)。
r2q
提供给用户使用,用于帮助优化特定类的quantum。
mtu
prio
在轮询处理中,可以优先处理具有最低优先级字段数值的类对应的报文。强制字段。
prio
类在层次结构中的位置。如果一个类直连到一个qdisc而不是另一个类,则可以省略minor(见下)。强制性字段。
prio
与qdisc类型,也可以命名类。major号必须等于其附加到的qdisc的major号。该字段是可选的,但在类包含子类时需要配置该字段。
7.1.5. HTB root 参数
一个HTB qdisc类树的root包含三个字段:
parent major:minor | root
该强制参数确定了HTB实例的位置:接口的root位置还是位于一个已存在的类中。
handle major:
与其他的qdisc类似,可以给HTB分配一个句柄,该句柄应该包含一个major号,后跟一个冒号。可选字段,但如果类将在这个qdisc中生成,则非常有用。
default minor-id
未分类的流量会使用该minor-id发送到类。
7.1.6. 规则
以下是从https://www.docum.org/和(new) LARTC mailing list (也可以参见 (old) LARTC mailing list archive)中挑选的使用HTB的一般准则。这些准则可以方便初学者在最大程度上了解HTB。
1.HTB的整流仅发生在叶子类上。
2.由于HTB不会在除叶子类的类上进行整流,因此叶子类的rates之和不能大于父类的ceil。理想情况下子类的rates之和应该与父类的ceil相匹配,允许父类将剩余的带宽(ceil - rate)分配给子类。
3.在使用HTB时,会多次重复这个关键概念。只有叶子类才会真正进行整流;报文只会在这些叶子类上延迟。内部类(到root类路径上的类)定义了如何进行借入/借出(参见Section 7.1.3, “Borrowing”)。
4.只有在一个类大于rate但低于ceil时才会用到quantum。
5.quantum应该设置为等于或大于MTU的值。即使在quantum很小的情况下,HTB也会至少给每个服务一次报文入队列的机会。这种情况下,HTB将无法精确计算真实使用的带宽。
6.父类以增量为quantum的方式将令牌提供给子类,以便获得最大的粒度和最均匀的瞬时带宽分布,quantum应该尽量小,但不能小于MTU。
7.tokens和ctokens的不同点仅对叶子类有意义,因为非叶子的类仅会借给子类令牌。
8.对HTB借用的更精确的描述应该是"使用"(并不会归还)。
7.1.7. 分类
如前面所述,一个HTB实例可能会包含很多类,每个类都包含一个qdisc,默认为tc-pfifo。当入队列一个报文时,HTB会从root类开始,使用多种方式来决定哪个类去接收该数据。在没有特殊配置选项的情况下,处理会相当简单。在树的每个节点上查找一条指令,然后转到指令指向的类。如果找到的类是一个叶子类,则将报文入队列到此处,如果不是一个叶子节点,则从该节点开始重复上述工作。
在访问的每个节点上会执行以下操作,直到发送到另一个节点(子节点)或终止该过程为止:
1.查询附加到类的过滤器。如果发送到一个叶节点,则工作完成。否则,重新启动。
2.如果上述操作没有返回指令,则在该节点上将报文入队列。
这种算法会确保报文总是在某个地方结束。
7.2. HFSC, 分层公平服务曲线(Hierarchical Fair Service Curve)
HFSC classful qdisc会对延迟敏感的流量和吞吐量敏感的流量进行平衡。当处于拥塞或挤压状态下时,HFSC排队规则会在需要时根据服务曲线定义穿插处理对延迟敏感的流量。
7.3. PRIO, 优先级调度器
PRIO classful qdisc的工作原理非常简单。当它需要入队列一个报文时,会检查第一个类,如果该类包含报文,则将该报文入队列,否则检查下一个类,直到最后一个类。PRIO是一个不会延迟报文的调度器,它是一个连续工作的qdisc(尽管包含在类中的qdisc可能不是连续工作的)。
7.3.1. 算法
当使用tc qdisc add命令创建PRIO时,会创建固定数目的bands(与pfifo类似)。每个band就是一个类(虽然不能使用tc class add添加类)。创建qdisc的时候创建的band的数目是固定的。
当入队列报文时,总会优先检查band 0。如果band 0中没有报文,则PRIO会检查band 1,以此类推。具有最大可靠性的报文会进入band 0,最小延迟的报文会进入band 1,其余进入band 2。
由于PRIO本地包含minor号0,band 0实际上就是major:1,band 1为major:2,等等。对于major,可以用handle参数替换'tc qdisc add'上分配给qdisc的major号。
7.3.2. 用法
$ tc qdisc ... dev dev ( parent classid | root) [ handle major: ] prio [bands bands ] [ priomap band band band... ] [ estimator interval time‐constant ]
7.3.3. 分类
有三种方式决定一个报文入队列时的band:
1.在用户空间中,具有足够特权的进程可以直接使用SO_PRIORITY对目标类进行编码。
2.通过编程,附加到root qdisc的tc过滤器可以将任何流量直接指向一个类。
3.通常,参考priomap,报文的优先级是从分配给报文的服务类型(ToS)派生出来的。
只有此qdisc指定了priomap。
7.3.4. 可配置的参数
1.bands:不同band的数目,如果该值不是默认值3,则需要更新priomap。
2.priomap:附加到root qdisc的tc过滤器,可以将流量直接指向一个类。
一个priomap 指定了该qdisc如何将一个报文映射到一个特定的band。对报文的映射基于其TOS的值。
0 1 2 3 4 5 6 7
+-----+-----+-----+-----+-----+-----+-----+-----+
| PRECEDENCE | ToS | MBZ | RFC 791
+-----+-----+-----+-----+-----+-----+-----+-----+
0 1 2 3 4 5 6 7
+-----+-----+-----+-----+-----+-----+-----+-----+
| DiffServ Code Point (DSCP) | (unused) | RFC 2474
+-----+-----+-----+-----+-----+-----+-----+-----+
RFC 791 和RFC 2474对(4个比特位的)TOS的定义稍微有所不同,后者取代了前者在格式上的定义,但不是所有的软件,系统和术语都能及时跟上这种变化。因此,报文分析程序通常会使用Type of Service (ToS)而不是DiffServ Code Point (DSCP)。
RFC 791 对IP的TOS首部的解析如下:
| Binary | Decimal | Meaning |
|---|---|---|
| 1000 | 8 | Minimize delay (md) |
| 0100 | 4 | Maximize throughput (mt) |
| 0010 | 2 | Maximize reliability (mr) |
| 0001 | 1 | Minimize monetary cost (mmc) |
| 0000 | 0 | Normal Service |
由于这4个比特位的右边还有一个比特位,因此TOS字段的实际值为TOS比特值的两倍。运行 tcpdump -v -v可以显示整个TOS字段的值,而不仅仅4个比特位的值。
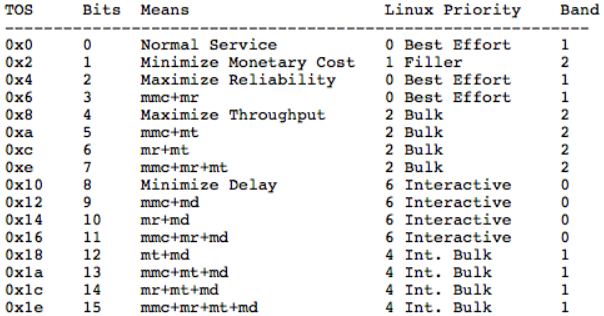
下表展示了如何将TOS值映射到priomap band:
| ToS Field | ToS Bits | Meaning | Linux Priority | Band |
|---|---|---|---|---|
| 0x0 | 0 | Normal Service | 0 Best Effort | 1 |
| 0x2 | 1 | Minimize Monetary Cost (mmc) | 1 Filler | 2 |
| 0x4 | 2 | Maximize Reliability (mr) | 0 Best Effort | 1 |
| 0x6 | 3 | mmc+mr | 0 Best Effort | 1 |
| 0x8 | 4 | Maximize Throughput (mt) | 2 Bulk | 2 |
| 0xa | 5 | mmc+mt | 2 Bulk | 2 |
| 0xc | 6 | mr+mt | 2 Bulk | 2 |
| 0xe | 7 | mmc+mr+mt | 2 Bulk | 2 |
| 0x10 | 8 | Minimize Delay (md) | 6 Interactive | 0 |
| 0x12 | 9 | mmc+md | 6 Interactive | 0 |
| 0x14 | 10 | mr+md | 6 Interactive | 0 |
| 0x16 | 11 | mmc+mr+md | 6 Interactive | 0 |
| 0x18 | 12 | mt+md | 4 Int. Bulk | 1 |
| 0x1a | 13 | mmc+mt+md | 4 Int. Bulk | 1 |
| 0x1c | 14 | mr+mt+md | 4 Int. Bulk | 1 |
| 0x1e | 15 | mmc+mr+mt+md | 4 Int. Bulk | 1 |
第二列包含相关的四个ToS位的值,以及它们的含义。例如,15表示想要最小成本,最大可靠性,最大吞吐量以及最小延迟。
第四列列出了Linux内核解析TOS比特位的方式,展示了TOS映射到的优先级。
最后一列展示了默认的priomap值。在命令行中,默认的priomap为:1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1,其对应的优先级为4,对应的band为1。priormap允许更高的优先级(>7),这类优先级并不对应TOS的映射,表示其他的含义。
7.3.5. 类
无法对PRIO类进行进一步的配置——它们在附加PRIO qdisc时自动创建。但每个类可以包含更多的qdisc。
7.3.6. Bugs
当低band中包含了大量流时,可能会导致高band饥饿。可以给这些band附加一个整流器,以确保这些band不会占用大部分链路。
7.4. CBQ, 基于类的队列 (CBQ)
CBQ是一个流量控制系统的类实现。CBQ是一个classful qdisc,它可以在类层次结构中共享链路。它包含整流元素以及优先级功能。通过对入队列事件的链路空闲时间和对底层链路带宽的了解来实现整流。
7.4.1. 整流算法
通过计算链路空闲时间以及设置当结果偏离了设定的限定值时所采取的动作来实现整流。
当一个10mbit/s连接到1mbit/s时,该链路上90%的时间都是空闲的。如果不是,则需要对其进行限流,使其90%的时间处于空闲状态。
从内核的角度很难对流量进行衡量,因此,CBQ会根据设备驱动程序请求数据之间的毫秒数计算空闲时间。结合报文的大小,可以近似知道链路满或空的程度。
应当谨慎应对这种结果,因为并不是每次都能计算出合适的结果。在不太真实的网络设备(例如以太网上的PPP或TCP/IP上的PPTP)的情况下,对物理链路带宽的定义可能不正确。
在操作时,有效空闲时间是用指数加权移动平均(EWMA)来进行测量的。这种针对空闲状态计算出的最近的报文数是以前的报文数的指数倍。EWMA是一种有效的计算方法,可以解决系统处于活动状态或非活动状态的问题。例如,UNIX系统的平均负载就采用了这种计算方式。
从EWMA测得的值中减去计算出的空闲时间,结果称为avgidle(平均空闲时间)。一个完美加载的链路的avgidle应该为0:接收的报文间隔等于计算的结果。
一个过载的链路的avgidle为负值,如果负值过大,则CBQ会限流。相反,如果一个空闲的链路的avgidle过大,则在一段时间的静默后,可能会允许无限的带宽。为了防止发生这种情况,将avgidle的上限是maxidle。
从理论上讲,如果超出限制,CBQ会严格限制计算出的用于放通报文的时间,然后放通一个报文,然后再进行限流。由于定时器精度的限制,这种方式可能不可行,参见下图的minburst参数。
7.4.2. 分类
在CBQ qdisc下可能存在很多类。每个类会包含其他qdisc,默认为tc-pfifo。
当入队列一个报文时,CBQ会从root开始,使用多种方法来确定使用哪个类来接收该数据。如果做出判定,则对接收的类重复此过程,该类可能有进一步的方法来将流量分类到子类(如果有的话)。CBQ可以使用如下方法将一个报文分类给任何子类:
1.skb->priority类编码。可以由设置了SO_PRIORITY setsockopt的用户空间的应用进行设置。skb->priority类编码只适用于当skb->priority持有此qdisc中现有类的major:minor句柄的情况。
2.附加到该类的tc过滤器。
3.一个类的defmap,由split和defmap参数设置。defmap 可能包含针对每个可能的Linux报文优先级的指令。
每个类也有一个级别。连接到类层次结构底部的叶节点的级别为0。
7.4.3. 分类算法
分类是一个循环,当达到叶子类时终止。循环中的任一点都可能跳到一个回退算法中。循环包含如下步骤:
1.如果报文是本地生成的,且在skb->priority中编码了一个有效的classid,则选择该类,并终止循环。
2.查询附加到该子类的tc过滤器(如果存在)。如果返回的类不是叶子类,则从返回的类上重新执行循环。如果返回的类是叶子类,则选择该类并终止循环。
3.如果tc过滤器没有返回类,也没有返回类的有效引用,则将引用的minor号作为优先级,然后从该类的defmap中检索一个此优先级的类。如果没有此优先级的类,则查询该类的defmap,检视一个BEST_EFFORT类。如果这是一个向上引用,或者没有定义BEST_EFFORT类,则进入回退算法。如果发现一个有效的类,且非叶节点,则从该类重启循环;如果是一个叶节点,则选择该类并终止循环。如果根据classid提取的优先级或BEST_EFFORT优先级均未发现相关的类,则进入回退算法。
回退算法位于循环之外,遵循如下规则:
1.查询要回退的跳转发生在哪个类的defmap,如果该defmap包含一个与该类的优先级(与TOS字段相关)相同的类,则选择该类并终止循环。
2.查询BEST_EFFORT 优先级的类,如果找到,则选择该类并终止循环。
3.选择发生回退算法的类。 终止循环。
当任意一种算法终止时,报文被加入到所选择的类中。因此,报文可以不在叶节点入队列,而在层次结构的中间入队列。
7.4.4. 链路共享算法
当入队列发送到网络驱动的报文时,CBQ决定哪个类可以发送报文。CBQ使用一个基于权重的轮询处理,每个类中的报文都有机会按照顺序发送出去。WRR会从具有最高优先级的类中处理报文,直到这些类中没有任何数据,然后处理低优先级的类。
由于每个类都不允许以长度发送数据,因此只能在每轮中取出可配置数量的数据。
如果一个类即将超出限制,且不受限制,它将尝试从没有隔离的兄弟节点中借用avgidle,从下向上重复这个过程。如果一个类无法借用到足够的avgidle来发送报文,则这个类会限流,并且不要求报文等待足够的时间来使avgidle增加到零以上。
7.4.5. root 参数
CBQ的root qdisc有如下参数:
parent root | major:minor:
强制参数,确定CBQ实例的位置,即接口的root类还是一个现有的类中。
handle major:
与其他类的qdisc类似,CBQ可以分配一个句柄。应该包含一个使用冒号分割的主号。可选参数。
avpkt bytes
为了计算,平均报文大小必须事先可知。默认至少为MTU的2/3。强制参数。
bandwidth rate
底层可用的带宽,用于确定空闲时间,CBQ必须知道带宽:A)目标带宽;B)底层物理接口或C)父qdisc。这是一个至关重要的参数,后面会详细介绍。强制参数。
cell size
cell大小确定了报文传输时间计算的粒度,必须是2的整数次幂,默认为8。
mpu bytes
0大小的报文可能也会占用传输的时间。这个值是报文传输时间计算的下限,小于该值的报文仍然被认为是这个大小。默认值为0。
ewma log
CBQ使用指数加权移动平均值(EWMA)来计算空闲状态,该方法可以以平滑测量的方式轻松应对短时间的突发。log值决定了平滑发送的数量。更低的值意味着更高的灵敏度。必须为0~31之间的数值,默认为5。
一个CBQ qdisc不会自行整流。它需要知道有关底层链路的某些参数。实际的整流是在类中完成的。
7.4.6. 类参数
类有很多参数类配置其操作:
parent major:minor
层级结构中类的位置。如果直接附加到一个qdisc,而不是一个类,则可以忽略minor。强制参数。
classid major:minor
与qdisc类似,class是可命名的。majob号必须等于其属于的qdisc的major号。可选参数,但如果一个类包含子类时必选。
weight weightvalue
当入队列到底层时,将以循环方式使用类处理流量。通常具有更高权重的qdisc的类在一轮循环中可以发送更多的流量,因此该类也可以入队列更多的流量。由于一个类下的所有权重都被归一化了,因此只有比率才是重要的。默认使用配置的速率,除非该类的优先级是最大的,在这种情况下,它的优先级设置为1。
allot bytes
allot 指定了在每个轮询中一个qdisc可以入队列的字节数据。可以使用上面描述的权重对该参数进行加权。
priority priovalue
在轮询处理中,具有最低优先级字段值的类会优先处理报文。强制字段。
rate bitrate
这个类(包括子类)能够传输的最大聚合速率。bitrate 使用tc的方式指定速率(如1544kbit)。强制字段。
bandwidth bitrate
该参数与创建CBQ qdisc时指定的带宽不同。CBQ类的bandwidth参数仅用于确定maxidle和offtime,而该参数仅在指定maxburst或minburst时才计算。因此,该参数仅在指定maxburst或minburst时使用。
maxburst packetcount
该报文数用于计算maxidle,这样在avgidle达到maxidle时,且在avgidle将到0前,允许平均报文的突发。增加该值可以允许更大的突发。用户无法直接设置maxilde,只能通过该参数设置。
minburst packetcount
如前面所述,CBQ需要设置限制来防止发生超额。理想的解决方案是精确计算出空闲时间,然后传递1个报文。然而,Unix内核通常很难调度小于10ms的事件,因此最好能在一段比较长的时间内限流,然后一次性传递minburst的报文,然后使minburst时间更长。等待的时间称为offtime。从长远角度看,更大的minburst 值会获得更精确的整流效果,但在毫秒时间尺度上会产生更大的突发。
minidle microseconds
minidle:如果avgidle小于0,则说明此时已经超额,需要等到avgidle能够发送一个报文为止。为了防止底层链路长时间中断导致的突发,如果avgidle值过低,则会重置为minidle。minidle使用负值表示,因此10表示avgidle的上限为-10us。
bounded | borrow
指定了一个借用策略。即要么类会从兄弟节点借用带宽,要么将自己视为受限的。 二者是互斥的。
isolated | sharing
指一个共享策略。这个类要么对它的兄弟类使用共享策略,要么认为自己是孤立的。二者是互斥的。
split major:minor and defmap bitmap[/bitmap]:如果查询附加到类的过滤器之后没有给出结论,CBQ可以根据报文的优先级进行分类。有16个优先级,从0到15。defmap指定了类期望接收的优先级,优先级使用位图进行表示。最低有效位对应的优先级为零。split参数告诉CBQ必须在哪个类上做出决定,这个类应该是要添加的类的(祖)父类。
如,'tc class add ... classid 10:1 cbq .. split 10:0 defmap c0' 配置类10:0发送优先级为6和7到10:1的报文。
可替代的写法为:'tc class add ... classid 10:2 cbq ... split 10:0 defmap 3f',将发送所有的优先级为0, 1, 2, 3, 4 和5 的报文到10:1。
estimator interval timeconstant:CBQ可以测量每个类使用的带宽,以及哪些tc过滤器可以用来对报文进行分类。为了确定带宽,它使用了一个非常简单的评估器,每隔一微秒测量通过了多少流量。这也是一个EWMA,它的时间常数可以指定,同样是以微秒为单位。时间常数对应于测量的迟缓性,或者相反,对应平均值对短脉冲的灵敏度。更高的值表示更低的灵敏度。
7.5. WRR, 基于权重的轮询
该qdisc不包含在标志的内核中。
WRR qdisc使用加权轮询方案在其类之间分配带宽。它与CBQ qdisc类似,包含可以插入任意qdisc的类。具有足够需求的所有类都将获得与类相关的权重成比例的带宽。可以通过tc程序手动设置权重。但是对于传输大量数据的类,也可以使它们自动减少。
该qdisc有一个内置的分类器,可以将来自或发送到不同机器的数据包分配给不同的类(使用MAC或IP以及源或目的地址)。当Linux作为桥时会使用MAC地址。这些类会根据所看到的报文自动分配给机器。
该qdisc在许多无关的人共享Internet连接的站点上时非常有用。WRR发行版的关键部分是一组为此类站点设置相关行为的脚本。
8. 流量控制的规则、准则和方法
8.1. Linux流量控制的通用规则
可以使用如下通用规则来学习Linux流量控制。可以使用tcng或tc进行初始化配置Linux下的流量控制结构。
1.任何执行整流功能的路由器都应该成为链路的瓶颈,并且应该调整为略低于最大可用的链路带宽。通过整流可以防止在其他路由器中形成队列,从而最大程度地控制到整流设备的报文的延迟/延期。
2.一个设备可以对其传输的流量进行调整。由于已经在输入接口上接收到流量,因此无法调整这类流量。 解决此问题的传统方法是使用ingress策略。
3.每个接口必须包含一个qdisc。当没有明确附加其他qdisc时会使用默认的qdisc( pfifo_fast qdisc)。
4.如果一个接口附加了classful qdiscs ,但没有任何子类,这种情况会无意义地消耗CPU。
5.任何新创建的类都包含一个 FIFO。可以使用任何qdisc来替换这个qdisc。当一个子类附加到该类时,会隐式地删除FIFO qdisc。
6.直接附加到root qdisc的类可以模拟虚拟电路。
7.可以在类或任意一种classful qdiscs上附加过滤器。
8.2. 处理已知带宽的链路
当一个链路已知带宽时,HTB是一个理想的qdisc,因为可以给最内层的(最根)类设置给定链接上的最大可用带宽。流量后续会被分割到子类中,用于保证特定类型的流量的带宽或允许优先选择特定类型的流量。
8.3. 处理已知可变带宽的链路
理论上,PRIO是一个理想的用于处理可变带宽的调度器,因为它是一个连续工作的qdisc(这意味着它不提供整流)。在带宽未知或波动的链路中,PRIO 调度器更喜欢优先将具有最高优先级的band中的所有报文出队列,然后再处理较低优先级的队列中。
8.4. 基于流的带宽共享和分割
在多种类型的网络带宽竞争中,这通常是比较容易处理的竞争类型之一。通过使用SFQ,特定队列中的流量可以分为多条流,然后公平地处理该队列中的每条流。表现良好的应用程序(和用户)会发现,使用SFQ和ESFQ足以满足大多数共享需求。
这些公平排队算法的致命弱点是无法抵御行为不端的用户或应用程序同时打开很多连接(例如,eMule, eDonkey, Kazaa)。通过创建大量独立的流,应用程序可以控制公平排队算法中的时间间隙。重申一下,公平排队算法不知道单个应用程序会生成大多数流,并且不会惩罚用户。 需要依赖其他方法。
8.5. 基于IP的带宽共享和分割
对于许多管理员来说,这是在用户之间划分带宽的理想方法。不幸的是,没有简单的解决方案,而且随着共享网络连接的机器数量的增加,它变得越来越复杂。
为了在N个IP地址之间公平地分配带宽,必须有N个类。
9. 使用QoS/流量控制的脚本
9.1. wondershaper
更多参见 wondershaper.
9.2. ADSL Bandwidth HOWTO script (myshaper)
更多参见 myshaper.
9.3. htb.init
更多参见 htb.init.
9.4. tcng.init
更多参见 tcng.init.
9.5. cbq.init
更多参见 cbq.init.
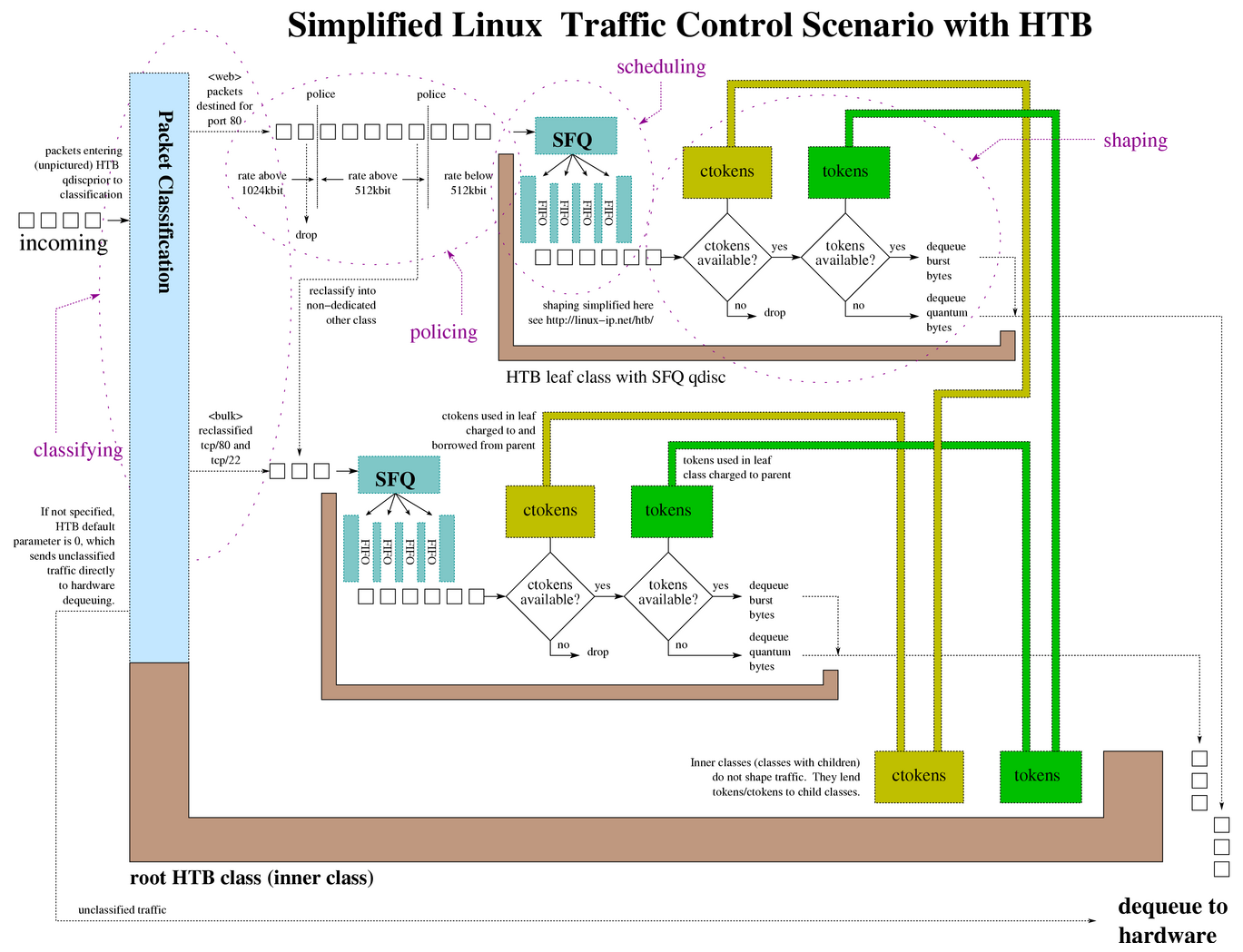
10. 图表
10.1. 总图
下图是分类排队规则各组件之间的关系总图(图中是HTB排队规则),点这里可以查看大图。
11. 有关流量控制的资源链接
本部分列出了一些有关流量控制和流量控制软件的文档链接。每个链接下面都有一个该链接内容的简单描述。
· HTB site, HTBuser guide and HTBtheory (Martin "devik" Devera)
分层令牌桶, 也就是HTB,是一个分类排队规则。它被广泛的使用和支持,其拥有完善的用户使用手册和网站 Stef Coene's site。
· General Quality of Service docs(Leonardo Balliache)
在这个网站上有许多易懂的介绍性文档,特别是有很多优秀的概述文章。
· tcng (Traffic Control NextGeneration) and tcngmanual (WernerAlmesberger)
tcng软件包包含了一个语言,以及一组用来创建和测试流量控制结构的工具。除了能以tc命令的方式输出外,它还能够为非Linux应用提供输出。在本文档中被忽视掉的关键部分是tscim流量控制模拟器
tcng软件包提供的帮助手册已经通过latex2html工具转换成了HTML格式,该版本将通过TeX文档来发布。
· iproute2 and iproute2 manual (Alexey Kuznetsov)
这里是iproute2套件的源代码,包含了必不可少的tc二进制可执行命令。注意,iproute2-2.4.7-now-ss020116-try.tar.gz并不支持HTB,需要从HTB上获取一个支持HTB的补丁。
这里有该工具套件中所有工具的帮助文档,尽管有关tc的文档可能不完整。当对帮助文档中的内容有疑惑时,最好去LARTC HOWTO寻找相关答案。
· Documentation, graphs, scripts and guidelines to traffic controlunder Linux (StefCoene)
Stef Coene已经收集了在Linux下使用QoS的一些脚本、建议、统计数据和测试结构。 在Stef的站点上还有一些非常实用的图表和指南。
· LARTC HOWTO (bert hubert, et. al.)
Linux高级路由和流量控制指南(Linux Advanced Routing and Traffic Control HOWTO)是讲解Linux下复杂流量控制技术的有用文档。流量控制入门指南(Traffic ControlIntroduction HOWTO)应该向读者提供足够的应用背景及流量控制思想,LARTC HOWTO是读者查找流量控制信息的好地方。
· Guide to IP Networking with Linux (Martin A. Brown)
虽然和流量控制没有直接联系,但这个站点上有一些和Linux IP层有关的文章和常见资源。
· WernerAlmesberger's Papers
Werner Almesberger是Linux流量控制的主要开发者和拥护者之一(他也是tcng的作者)。他的文章《Linux流量控制-应用概述》,是描述Linux内核中流量控制架构的一份重要文档,你可以获取该文档的PDF 或 PS版。
· Linux DiffServ project
下面这段内容是从DiffServ网站主页上毫不犹豫的剪切过来的...
差分服务(简称: Diffserv)为网络流量提供不同类或不同等级的服务。差分服务的一个关键特征是:流可以在网络中聚合在一起形成一条聚合流,因此核心路由器只需要识别少量的聚合流就行了,即使一条聚合流中可能包含成千上万条独立的流。