Linux下主要内存管理库简单比较
 Linux 内存分配与分配器
Linux 内存分配与分配器当代 Linux 系统中可以同时运行多种多样的进程,并且进程之间可以做到内存互相隔离,这得益于 Linux 的进程地址空间管理。一个进程的地址空间中,包含了静态内存、以及动态内存 (常说的堆栈),栈的动态分配和释放由编译器完成,对于堆上内存,Linux 提供了 brk、sbrk、mmap、munmap 等系统调用来进行内存分配和释放,但是这些函数的直接使用会带来不小的理解门槛和使用复杂性,如 brk 需要指定堆的上界地址,容易出现内存错误;mmap 直接申请 pagesize 为单位的内存,对于小于此内存的分配会造成极大的内存浪费。因此需要有内存分配器来辅助管理堆的动态申请和释放。
通常内存分配器如 ptmalloc 提供了 malloc 等函数来进行内存的分配,free 进行内存释放,这些函数在底层调用了 brk、mmap 等函数申请内存,并以地址的形式返回给用户,用户在 malloc、free 匹配的情况下不必担心在分配和释放时出现内存错误或者内存浪费。
内存碎片
虽然内存分配器在一定程度上保证了内存的利用率,但是不可避免地会出现内存碎片,包括了内存页内碎片和内存页间碎片,碎片的产生会导致部分内存不可用,内存碎片的大小也是评估一个内存分配器好坏的重要指标。
常见的内存分配管理算法
堆上内存以链式形式存在,最简单的动态内存分配算法有:
First fit:寻找找第一个满足请求 size 的内存块做分配
Next fit:从当前分配的地址开始,寻找下一个满足请求 size 的空闲块
best fist:对空闲块进行排序,然后找第一个满足要求的空闲块
另外还有 Buddy 算法和 Slab 算法,也是 jemalloc 中用到的两大核心算法:
Buddy allocation

Buddy 算法简单来说如上图,一般 2 的 n 次幂大小来管理内存,当申请的内存 size 较小,且当前空闲内存块均大于 size 的两倍,那么会将较大的块分裂,直到分裂出大于 size,并小于 size * 2 的块为止;当内存 size 较大时则相反,会将空闲块不断合并。该算法没有块间内存碎片,但是块内内存碎片较大,可以看到当申请 2KB+1B 的 size 时,需要用 4KB 的内存块,内存碎片最坏情况可达 50%。
Slab allocation
调用 Linux 系统调用进行内存的分配和释放会让程序陷入内核态,带来不小的性能开销,slab 算法应运而生。每个 slab 都是一块连续内存,并将其划分成大小相同的 slots,用 bitmap 来记录这些 slots 的空闲情况,内存分配时,返回一个 bitmap 中记录的空闲块,释放时,将其记录忙碌即可,而 slab size 和 slot size 是内存碎片大小的关键。
ptmalloc是glibc的内存分配管理
tcmalloc是google的内存分配管理模块
jemalloc是BSD的提供的内存分配管理
Jemalloc
Jemalloc的创始人Jason Evans也是在FreeBSD很有名的开发人员,他在2006年为提高低性能的malloc而写的jemalloc,从2007年开始以FreeBSD标准引进来的。软件技术革新很多是FreeBSD发起的,在FreeBSD应用广泛的技术会慢慢导入到Linux。
目前jemalloc在firefox中也在使用。在firefox2中出现了内存碎片问题之后,便在firefox3中引入了它。在safari和chrome中使用的是google的tcmalloc。后来facebook也在其自己的应用上使用了jemalloc,在tengine的版本中之所以加了对jemalloc的支持,应该很大程序上是受了facebook的影响。
Jemalloc的技术特性
Jemalloc聚集了malloc的使用过程中所验证的很多技术。如果忽略细节,从架构着眼,最出色的部分仍是arena和thread cache(事实上这两个与tcmalloc的架构几乎相同。)
Arena
与其像malloc一样集中管理一整块内存,不如将其分成许多个小块来分而治之,此小块便称为arena。让我们想象一下,给几个小朋友一张大图纸,让他们随意地画点。结果可想而知,他们肯定相互顾忌对方而不敢肆意地画(synchronization),从而影响画图效率。但是如果老师事先在大图纸上划分好每个人的区域,小朋友们就可以又快又准地在各自地领域上画图。这样的概念就是arena。
Thread cache
如果是开辟小块内存,为使不参照arena而直接malloc,给各自的线程thread cache领域。此idea是google的tcmalloc的核心部分,亦在jemalloc中体现。
再拿上面的例子,这次给小朋友们除了一张大图纸外,再各自给A4纸一张。这样,小朋友们在不画大面积的点时,只在自己的A4纸上心情地画即可(no arena seeking)。可以在自己手上的纸上画或涂(using thread cache),完全不用顾忌别人(no synchronization, no locking),迅速有效地画。
下图是jemalloc的核心layout。
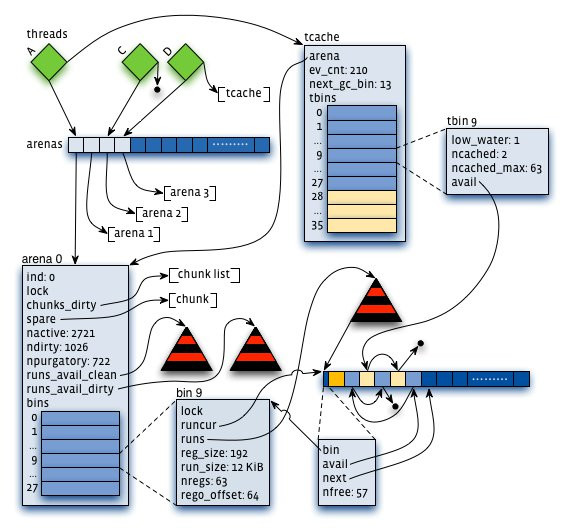
Redis 2.4版本之后,默认使用jemalloc来做内存管理;tengine也整合jemalloc。jemalloc从各方评测的结果可见与google tcmalloc都不相伯仲,皆为内存管理器领域最高水平。如下图:
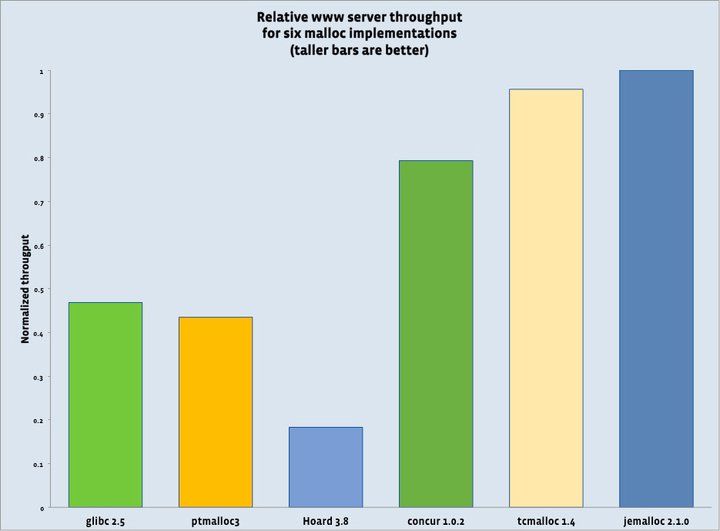
最左边的就是glibc的malloc,最右边的就是jemalloc。从图表上可以看出,jemalloc的性能有glibc的两倍以上。非常压倒性的性能差异。因此,使用了jemalloc的应用程序自然会快很多。Jemalloc旁边的就是tcmalloc。Tcmalloc的性能与其相差甚微,低jemalloc2.1.0慢4.5%。图上和tcmalloc的1.4版本,而现在已经到2.1版本,因此实际上这两者应该是不相仲伯的。Jemalloc的创始人jason evans也意识到这一点,说在cpu core 8以上的计算机上jemalloc效率更高。
tcmalloc vs. jemalloc
Both libraries try to de-contention memory acquire by having threads pick the memory from different caches, but they have different strategies:
jemalloc (used by Facebook) maintains a cache per thread
tcmalloc (from Google) maintains a pool of caches, and threads develop a "natural" affinity for a cache, but may change
This led, once again if I remember correctly, to an important difference in term of thread management.
jemalloc is faster if threads are static, for example using pools
tcmalloc is faster when threads are created/destructed
There is also the problem that since jemalloc spin new caches to accommodate new thread ids, having a sudden spike of threads will leave you with (mostly) empty caches in the subsequent calm phase.
As a result, I would recommend tcmalloc in the general case, and reserve jemalloc for very specific usages (low variation on the number of threads during the lifetime of the application).
TCMalloc
优点:很多系统都可以用源来安装 TCMalloc ,而且支持的 gcc 编译库比较新。
缺点:软件是在 Google Perftools 下的,安装的时候如果不编译好可能会安装到我们不需要的其他软件,而且 Google Perftools 安装过程比较复杂还需要安装相应的库。
Jemalloc
优点:目前是 Maridab 、Tengine、Redis 中默认推荐的内存优化工具,所以使用 Jemalloc 对这些程序的兼容度还是比较高的。而且经过测试高负载情况下 Jemalloc 更加优秀。安装过程方便,不用安装额外的库。
缺点:对使用最新的gcc编译不友好。