内存分配管理-jemalloc
 jemalloc 是一个通用的 malloc(3) 实现,它强调了分段回避和可伸缩并发支持。在 2005 年首次作为 FreeBSD libc 分配器使用,2010年开始其功能延伸到如堆分析和监控/调优等。现代的 jemalloc 版本依然集成在 FreeBSD 中,采用C/C++语言开发并在BSD协议下授权。
jemalloc 是一个通用的 malloc(3) 实现,它强调了分段回避和可伸缩并发支持。在 2005 年首次作为 FreeBSD libc 分配器使用,2010年开始其功能延伸到如堆分析和监控/调优等。现代的 jemalloc 版本依然集成在 FreeBSD 中,采用C/C++语言开发并在BSD协议下授权。jemalloc is a general purpose malloc(3) implementation that emphasizes fragmentation avoidance and scalable concurrency support. jemalloc first came into use as the FreeBSD libc allocator in 2005, and since then it has found its way into numerous applications that rely on its predictable behavior. In 2010 jemalloc development efforts broadened to include developer support features such as heap profiling and extensive monitoring/tuning hooks. Modern jemalloc releases continue to be integrated back into FreeBSD, and therefore versatility remains critical.
jemalloc起源于Jason Evans 2006年在BSDcan conference发表的论文:A Scalable Concurrent malloc Implementation for FreeBSD,jason认为phkmalloc(FreeBSD’s previous malloc implementation by Kamp (1998))没有考虑多处理器的情况,因此在多线程并发下性能低下(事实如此),而jemalloc适合多线程下内存分配管理。开发团队表示,持续集成现在是开发的重点,后续倾向于保持在各个平台(Linux、FreeBSD、macOS 和 Windows)上的稳定性。因此后续发版频率可能会逐渐降低。
Jemalloc的创始人Jason Evans也是在FreeBSD很有名的开发人员,此人就在2006年为提高低性能的malloc而写的jemalloc,Jemalloc是从2007年开始以FreeBSD标准引进来的。最大的优点就是你不需要做任何复杂的工作便可得到这样的效果,不需要代码重编译,只需在执行二进制之前,在命令行窗口中输入:
$ LD_PRELOAD=”tcmalloc_install_path/libtcmalloc.so”
这样在之后执行的应用程序会使用tcmalloc或jemalloc,从而代替glibc标准malloc(ptmalloc),只需简单设置我们便可得到性能20%的提升。目前jemalloc在firefox中也在使用,在firefox2中出现了内存碎片问题之后,便在firefox3中使用了jemalloc,在safari和chrome中使用的是google的tcmalloc。
Jemalloc的技术特性
Jemalloc聚集了malloc的使用过程中所验证的很多技术。忽略细节,从架构着眼,最出色的部分仍是arena和thread cache。
Arena
与其像malloc一样集中管理一整块内存,不如将其分成许多个小块来分而治之。此小块便称为arena。让我们想象一下,给几个小朋友一张大图纸,让他们随意地画点。结果可想而知,他们肯定相互顾忌对方而不敢肆意地画(synchronization),从而影响画图效率。但是如果老师事先在大图纸上划分好每个人的区域,小朋友们就可以又快又准地在各自地领域上画图。这样的概念就是arena。
Thread cache
如果是开辟小块内存,为使不参照arena而直接malloc,给各自的线程thread cache领域。此idea是google的tcmalloc的核心部分,亦在jemalloc中体现。
再拿上面的例子,这次给小朋友们除了一张大图纸外,再各自给A4纸一张。这样,小朋友们在不画大面积的点时,只在自己的A4纸上心情地画即可(no arena seeking)。可以在自己手上的纸上画或涂(using thread cache),完全不用顾忌别人(no synchronization, no locking),迅速有效地画。
下图是jemalloc的核心layout,看着复杂,其实都是上面说明的部分。
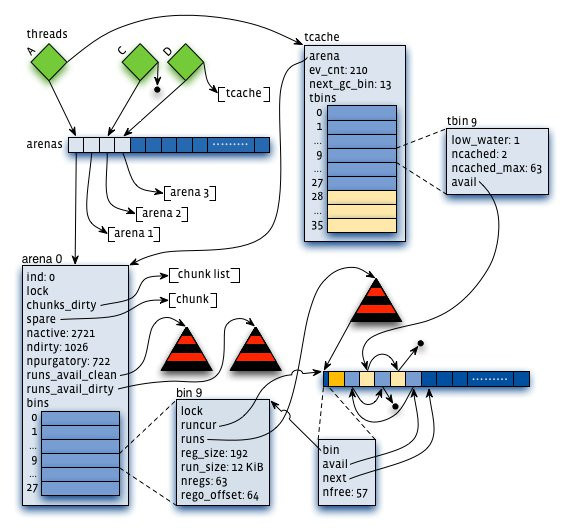
实际jemalloc的性能呢?
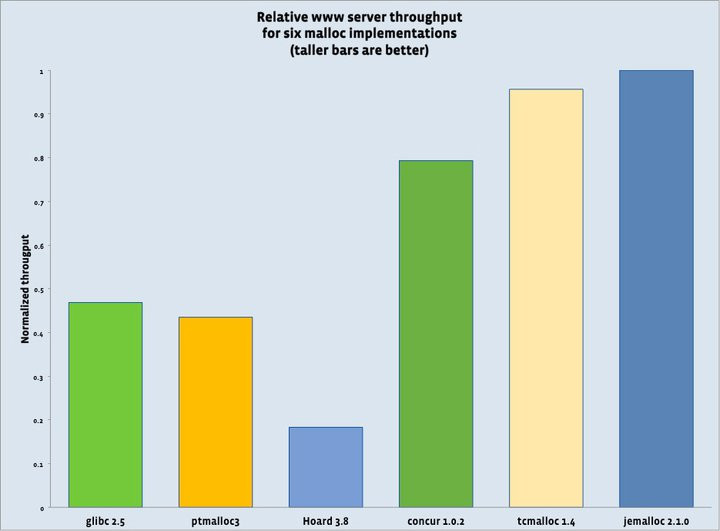
最左边的就是glibc的malloc,最右边的就是jemalloc。从图表上可以看出,jemalloc的性能有glibc的两倍以上。非常压倒性的性能差异。因此,使用了jemalloc的应用程序自然会快很多。Jemalloc旁边的就是tcmalloc。Tcmalloc的性能与其相差甚微,低jemalloc2.1.0慢4.5%。图上和tcmalloc的1.4版本,而如今它已经到了1.6版本,因此实际上这两者应该是不相仲伯的。Jemalloc的创始人jason evans也意识到这一点,说在cpu core 8以上的计算机上jemalloc效率更高。
也有人使用google的tcmalloc。在性能上两者差不多,但google的tcmalloc所提供的程序分析工具非常(heap、cpu profiler)丰富,所以tcmalloc可能更方便一些。
Jemalloc 简介
Jemalloc 是 malloc (3) 的实现,在现代多线程、高并发的互联网应用中,有良好的性能表现,并提供了优秀的内存分析功能。主要有以下几个特点:
1.高效地分配和释放内存,可以有效提升程序的运行速度,并且节省 CPU 资源
2.尽量少的内存碎片,一个长稳运行地程序如果不控制内存碎片的产生,那么可以预见地这个程序会在某一时刻崩溃,限制了程序的运行生命周期
3.支持堆的 profiling,可以有效地用来分析内存问题
4.支持多样化的参数,可以针对自身地程序特点来定制运行时 Jemalloc 各个模块大小,以获得最优的性能和资源占用比
下面主要介绍了 Jemalloc 的内存分配算法、数据结构,以及一些针对具体程序的优化实践和建议。
核心算法与数据结构
Jemalloc 整体的算法和数据结构基于高效和低内存碎片的原则进行设计,主要体现在:
隔离了大 Size 和小 Size 的内存分配 (区分默认阈值为 3.5 个 Pagesize),可以有效地减少内存碎片
在内存重用时默认使用低地址,并将内存控制在尽量少的内存页上
制定 size class 和 slab class,以便减少内存碎片
严格限制 Jemalloc 自身的元数据大小
用一定数量的 arena 来管理内存的单元,每个 arena 管理相当数量的线程,arena 之间独立,尽量减少多线程时锁竞争
来看下 Jemalloc 是如何来实现这些特性的。
Extent
Jemalloc 的内存管理结合了 buddy 算法和 slab 算法,引入 extent 的概念,extent 是 arena 管理的内存对象,在 large size 的 allocation 中充当 buddy 算法中的 chunk,small size allocation 中,充当 slab。每个 extent 的大小是 Pagesize 的整数倍,不同 size 的 extent 会用 buddy 算法来进行拆分和合并,大内存的分配会直接使用一整个的 extent 来存储。小内存的分配使用的是 slab 算法,slab size 的计算规则为 size 和 pagesize 的最小公倍数,因此每个 extent 总是可以存储整数倍个对应 size。
extent 本身设置 bitmap,来记录内存占用情况,以及自身的各种属性,同类型的 extents 用 paring heap 存储,此外 arena 将 extent 分为多种类型,有当前正在使用未被填满的 extent,有一段时间未使用的 dirty extent,还有长时间未使用的 muzzy extent,以及开启 retained 功能后的 retained extent,extent 分类的作用相当于多级缓存,当线程内存分配压力较小时,空余的 extent 会被缓存,以备压力增大时使用,可以避免与操作系统的交互。
Small size align and Slab size
为了减少页内内存碎片,Jemalloc 对 small size 进行了对齐,对于每一个 size,以二进制的视角来看,将其分为两个数:group、mod。group 表示 size 的二进制最高位,如果 size 正好为 2 的幂次,则将其分在上一个 group 中;mod 表示最高位的后两位,有 0、1、2、3 共 4 种可能。这样构成的 align 后的 size 在同一个 group 中步长(即两个相邻 mod 计算得到的 size 之间的差值)相同,group 越大,步长会呈 2 的倍数增长。
如下图,框中的 4 个是同一个 group 中 4 种 mod 在 align 后的 size,其中 160 表示包含了 129B 到 160B 在对齐后的大小:
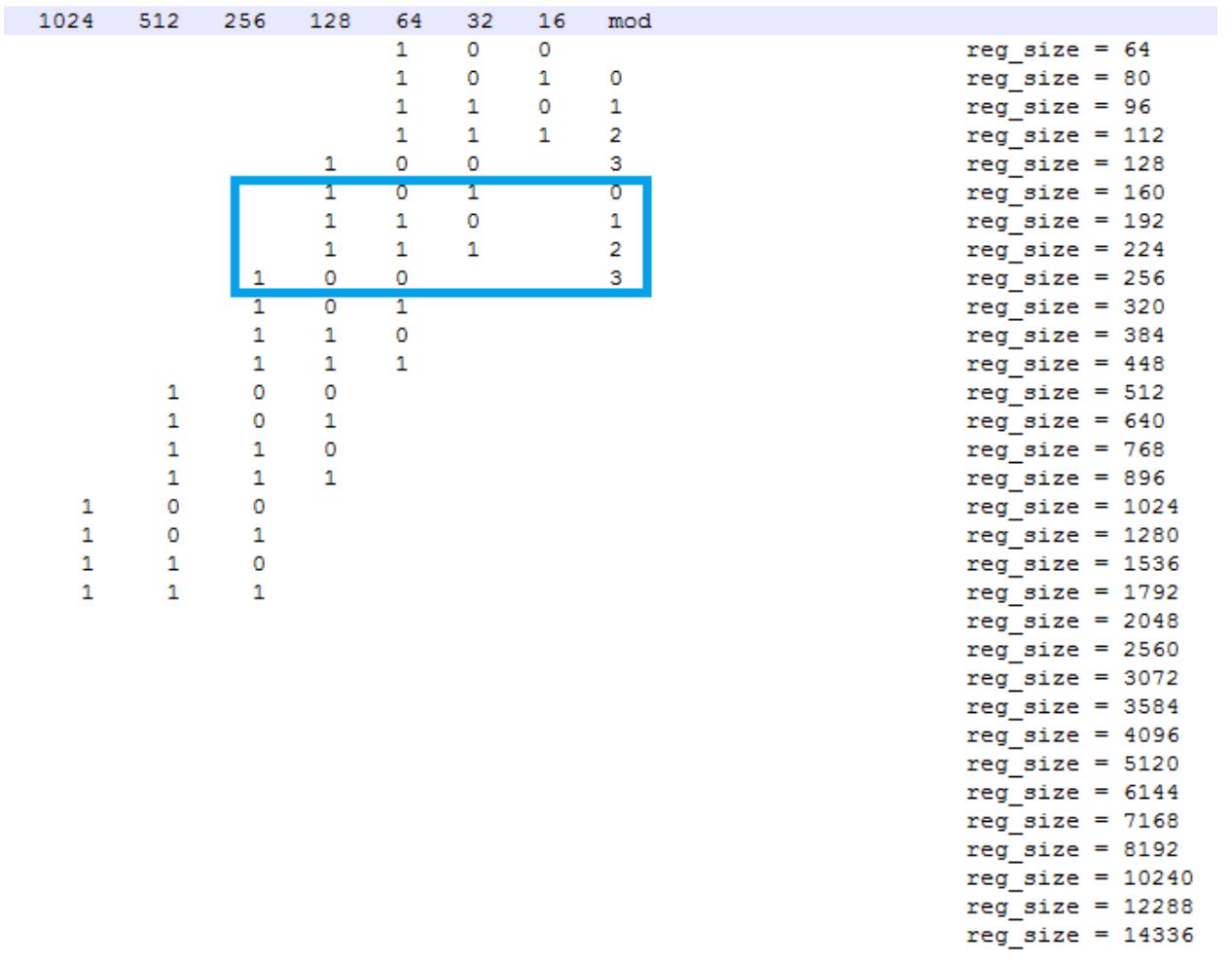
计算出 aligned size 后就需要计算 slab size,每个 slab size 为 pagesize 和 aligned size 的最小公倍数,以防止跨 slab 的 size 或者 slab 无法被填满的情况出现。以 4K page 为例,128B 的 slab size 即 4K,160B 的 slab size 为 20K。
Tcache and arena
为了减少多线程下锁的竞争,Jemalloc 参考 lkmalloc 和 tcmalloc,实现了一套由多个 arena 独立管理内存加 thread cache 的机制,形成 tcache 有空余空间时不需要加锁分配,没有空余空间时将锁控制在线程所属 arena 管理的几个线程之间的模式。
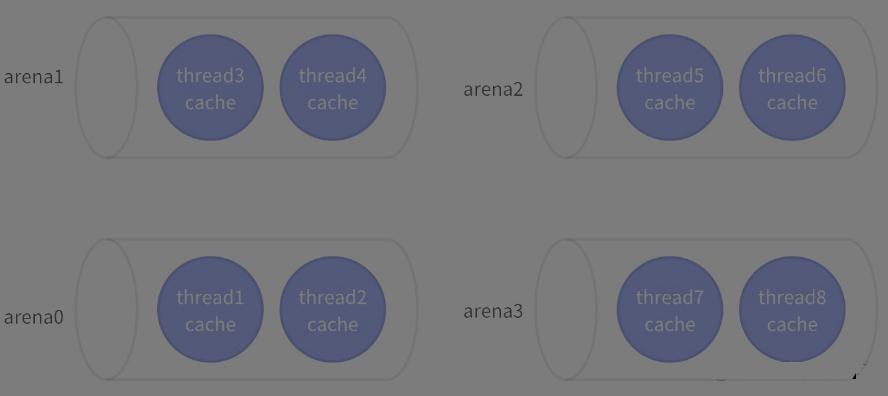
tcache 中每一个 size 对应一个 bin,当 tcache 需要填充时,在 arena 中发生的如下图:
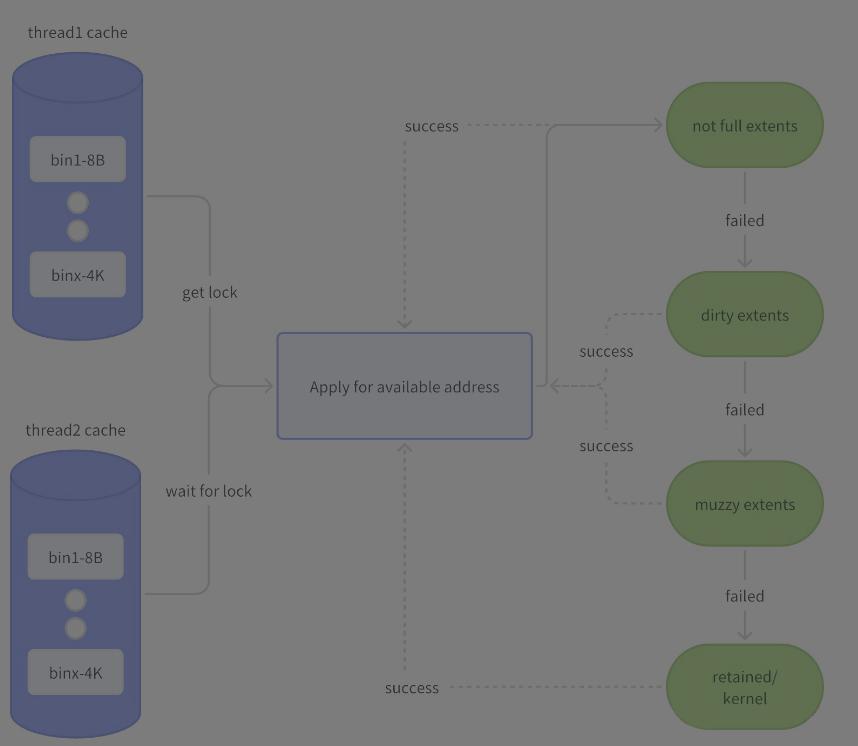
allocation/dallocation in tcache
tcache 以 thread local storage 对象的形式存储,主要服务于 small size 和一小部分 large size。
当 tcache 中有空闲时,一次 malloc 的过程很简单:
1.对 size 做 align 得到 usize
2.查找 usize 对应的 bin,bin 为 tcache 中针对不同 size 设置的 slots
3.bin 有空闲地址则直接返回,没有空闲地址则会向 arena 请求填充
每个 bin 的结构如下图,avail 指向 bin 的起始地址,ncached 初始为 bin 的最大值 ncached_max (与 slab size 相关,最小为 20 最大为 200),每次申请内存会返回 ncached 指向的地址并自减 1,直到小于限制值。
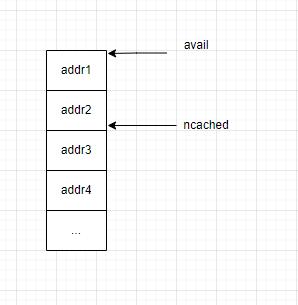
释放的时候相反,当 tcache 不为空,即 ncached 不等于 bin 的 ncached_max 时,ncached 自加 1,并且将 free 的地址填入 bin 中。
Tcache fill
上面的 allocation 过程是 tcache 中有足够的空闲块供分配,当 tcache 中已经没有空闲块时,会向其所属的 arena 申请 fill,此时 arena 中会加锁去分级 extent 取空闲块,并把当前使用的 extent 移入 full extent。
Tcache flush
当 dallocate 触发 tcache 中又没有分配任何内存,即 ncached_max 等于 ncached_max 时,tcache 会触发 flush,flush 会将 tcache 中一半的内存释放回原 extent,即将 tache 的可用空间压缩到原来的一半,这个过程中也会加对应 extent 的锁以保证同步。
优化思路
从上可以看到,jemalloc 对于内存用的是多级缓存的思路,tcache 的代价最小,无须加锁可以直接返回;其次是 arena 的 bin->extent,锁的粒度在对应的 bin 上,会是 bin 对应的 size 在这个 arena 中无法再做 fill 或 flush;然后是 dirty extent、muzzy extent,这部分是 arena 全局加锁,会锁住其他线程的 fill 或者 purge,那么在多线程下,我们可以用几个思路来优化锁的竞争。
arena 优化
从上一章节可知,jemalloc 将锁的范围都控制在 arena 中,每个 arena 会管理一系列线程,线程在 arena 中是平均分配的,arena 默认数量是 CPU 个数 * 4。因此,当我们在一台 8 核的机器上运行 256 个线程时,意味着每个 arena 需要管理 8 个线程,这些线程在内存任务繁重时会产生严重的锁竞争,从而影响性能。此时可选择使用 malloc_conf:narenas:128,增加 arena 数量到 128 个,每个 arena 只需管理 2 个线程,线程之间产生锁竞争的概率就会大大减小。
此外还可以选择用 mallocx 隔离线程,让内存分配任务较重的线程独占 arena。
Slab size 优化
Slab size 的大小如上所述,为 usize 大小和 pagesize 的最小公倍数,这一机制可以保证减少内存碎片,但是 tcache 的 fill 与 flush 都与 slab size 相关,一个和业务内存模型匹配的 slab class 才可以得到最好的性能效果。下面是一张 jemalloc 和 ptmalloc 的对比图,可以看到在 1024 以下的性能 jemalloc 都优于 ptmalloc,但是 jemalloc 自身的性能明显存在波动,几个波动出现在 128B、256B、512B 以及 1024B 周围,因为这些 size 本身就是 pagesize 的因子或者公因子较多,所以 slab size 占用的 page 数也相对较少,fill 和 flush 所需要的 slab 数也越多。
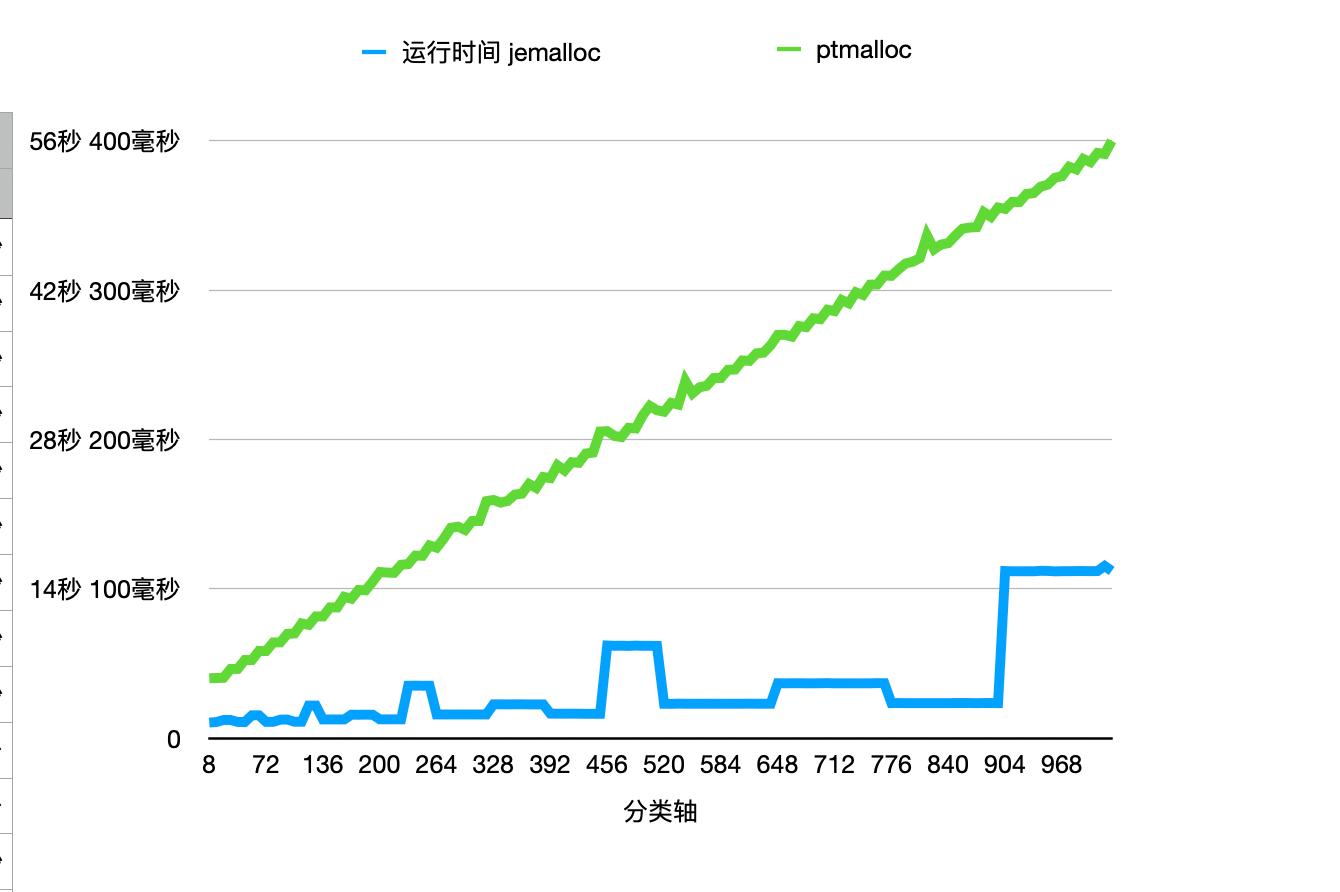
dirty decay & muzzy decay
尽管希望将所有的 malloc、free 内存都可以放在 tcache 中或者 bin 中,这样可以最大化执行效率,但是实际的程序中这很难做到,因为每个线程都需要增加内存,会造成不小的内存压力,而且内存的申请释放往往会有波峰,dirty extents 和 muzzy extents 就可以来应对这些内存申请的波峰,而避免需要转入内核态来重新申请内存页。
dirty_decay_ms 和 muzzy_decay_ms 是 jemalloc 中用来控制长时间空闲内存衰变的时间参数,适当地扩大 dirty decay 的时间可以有效地解决性能劣化的尖刺。
Tcache ncached_max
tcache 中每一个 bin 的 slots 数量由 ncached_max 决定,当 tcache 中 ncached_max 耗尽时会触发 arena 的 fill tcache 而产生锁,而 ncached_max 的大小默认为 2 * slab size,最小为 20,最大为 200,适当地扩大 ncached_max 值可以在一些线程上形成更优的 allocation/deallocation 循环(5.3 版本已支持用 malloc_conf 进行更改)。
优化方法:调优三板斧
结合以上优化思路,通过以下步骤对应用进行调优:
Dump stats
在 long exist 的程序中可调用 jemalloc 的 malloc_stats_print 函数,dump 出应用当前内存分配信息:
// reference: https://jemalloc.net/jemalloc.3.html
void malloc_stats_print(void (*write_cb)(void *, const char *), // 回调函数,可以写入文件
void *cbopaque, // 回调函数参数
const char *opts); // stats的一些选项,如"J"是导出json格式
或通过设置 malloc_conf,在程序运行结束后自动 dump stats:
export MALLOC_CONF=stats_print:true
stats 分析
用 Json 格式 dump stats 后,可以得到如下图所示结构的 json 文件:
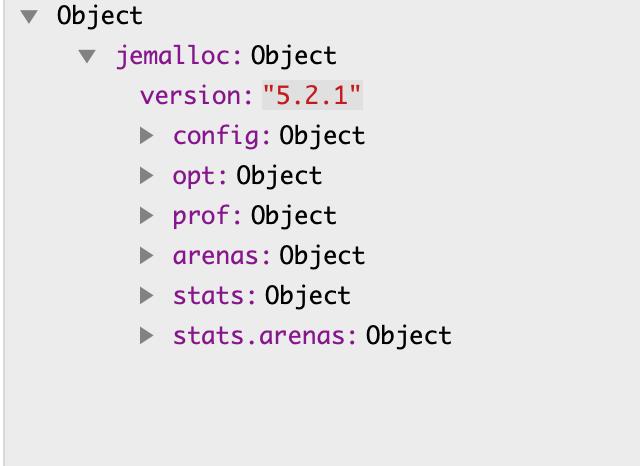
各字段含义可参考此处。
按上一章节思路,可主要关注以下几点:
arena 数量与 threads 数量比例
arena 数:jemalloc->arenas->narenas
threads 数:jemalloc->stats.arenas->merged->nthreads
分析:threads : arenas 比例代表了单个 arena 中管理的 线程数,将 malloc、free 较多,并且有可能产生竞争的线程尽量独占 arena
各个 extent 中 mutex 开销
jemalloc->stats.arenas->merged->mutexes
分析:该节点中的 mutex 操作次数、等锁时间可以反映出该类型 extent 的锁竞争程度,若 extent_retained 锁竞争严重,可适当调大 uzzy_decay_ms;同理,当 extents_muzzy 锁竞争严重,可适当调大 diry_decay_ms;extents_dirty 锁竞争严重,可适当调大 ncached_max,让 malloc 尽量可以在 tcache 中完成。
arena 中各个 bin 的 malloc、free 次数
jemalloc->stats.arenas->merged->bins
分析:bin 中的 nfills 可以反映该 slab 填充的次数,针对 regions 本身较少,nfill 次数又多的 size,如 521B、1024B、2048B、4096B 等,可适当调大 slab size 来减小开销
添加 MALLOC_CONF 参数或修改代码
MALLOC_CONF 是 jemalloc 中用来动态设置参数的途径,无须重新编译二进制,可以通过 MALLOC_CONF 环境变量或者 /etc/malloc_conf 软链接形式设置,参数之间用 ',' 分割。除需要使用线程独占的 arena 外,以上其他优化均可通过 MALLOC_CONF 配置来完成。
arena 优化方法
narenas 设置:
export MALLOC_CONF=narenas:xxx # xxx最大为1024
或
ln -s "narenas:xxx" /etc/malloc_conf
设置线程独占的 arena:
unsigned thread_set_je_exclusive_arena() {
unsigned arena_old, arena_new;
size_t sz = sizeof(unsigned);
/* Bind to a manual arena. */
if (mallctl("arenas.create", &arena_new, &sz, NULL, 0)) {
std::cout << "Jemalloc arena create error\n";
return 0;
}
if (mallctl("thread.arena", &arena_old, &sz, &arena_new, sizeof(arena_new))) {
std::cout << "Thread bind to jemalloc arena error\n";
return 0;
}
return arena_new;
}
各类大小优化方法
dirty extents:
export MALLOC_CONF=dirty_decay_ms:xxx # -1为不释放dirty extents,易发生OOM
muzzy extents:
export MALLOC_CONF=muzzy_decay_ms:xxx # -1为不释放muzzy extents,易发生OOM
tcache ncached_max 调整,ncached_max 与 slab size 相关,计算方式为
(slab_size / region_size) << lg_tcache_nslots_mul (默认值1)
最大限值为 tcache_nslots_small_max (默认 200),最小限值为 tcache_nslots_small_min (默认 20)。
如调整 32B 的 ncached_max,当前系统 page size 为 4K,计算默认的 ncached_max 的方法:
(slab_size / region_size) << lg_tcache_nslots_mul = (4096 / 32) << 1 = 256
超过了 tcache_nslots_small_max,所以 32B 的 ncache_max 默认即为 200。
调整 ncached_max 默认值相关参数:
export MALLOC_CONF=tcache_nslots_small_min:xxx,tcache_nslots_small_max:xxx,lg_tcache_nslots_mul:xxx
Slab size 设置方法:
export MALLOC_CONF="slab_sizes:1-4096:17|100-200:1|128-128:2" # -左右表示size范围,:后设置page数,|分割各个不同的size范围
Jemalloc的20年:从辉煌到停滞的回顾
jemalloc 内存分配器最初构想于 2004 年初,并已公开使用近 20 年。由于开源软件许可证的性质,jemalloc 将无限期地保持公开可用状态,但其上游的活跃开发已经终止。本节简要回顾了 jemalloc 的各个开发阶段,并总结了每个阶段的一些成功和失败,最后附上一些回顾性评论。
阶段 0:Lyken
2004 年,我开始着手开发 Lyken 编程语言,用于科学计算。虽然 Lyken 最终成为一个死胡同,但其手动内存分配器在 2005 年 5 月前就已功能完备(而本应利用其特性的垃圾回收器却从未完成)。2005 年 9 月,我开始将该分配器集成进 FreeBSD,到了 2006 年 3 月,我将其从 Lyken 中移除,改用一些对系统分配器功能的薄封装。
为什么在投入这么多精力后又把分配器从 Lyken 中移除?因为当它被集成进 FreeBSD 后,很快就显现出系统分配器唯一缺失的功能只是一个可以按线程追踪分配量、从而触发垃圾回收的机制。而这个功能完全可以用线程局部存储和 dlsym(3) 来通过薄封装实现。有趣的是,几年后 jemalloc 确实添加了 Lyken 当初所需的统计功能。
阶段 1:FreeBSD
2005 年,当多核处理器逐渐普及时,FreeBSD 使用的是 Poul-Henning Kamp 编写的出色的 phkmalloc 分配器,但它并不支持多线程并行执行。Lyken 的分配器看起来是一个显而易见的扩展方向。在朋友和同事的鼓励下,我将这个分配器整合进了 FreeBSD,它很快就被称作 jemalloc。但问题来了:整合完成后很快发现,jemalloc 在某些负载下会产生严重的内存碎片问题,尤其是在 KDE 应用程序诱发的场景下。正当我以为差不多完成时,这一现实问题严重质疑了 jemalloc 的可行性。
简而言之,碎片问题是因为使用了统一的区段分配策略(即没有按大小分类)。我虽然借鉴了 Doug Lea 的 dlmalloc,但缺乏后者经过多年实战考验的复杂启发式算法。这引发了一系列紧张的研究与实验。到 jemalloc 随 FreeBSD 一起发布时,它的内存布局算法已经完全重写,采用了按大小分区的策略,正如 2006 年 BSDCan 上的 jemalloc 论文中所描述的那样。
阶段 1.5:Firefox
2007 年 11 月,Mozilla Firefox 3 接近发布,但其内存碎片问题仍未解决,尤其是在 Windows 上。因此,我开始与 Mozilla 合作优化内存分配器。将 jemalloc 移植到 Linux 上几乎是轻而易举的事,但 Windows 上却问题重重。
当时 jemalloc 的源代码还在 FreeBSD 的 libc 中,因此我们实际上对 jemalloc 进行了分叉开发,添加可移植性代码,并将与 FreeBSD 相关的改动回馈上游。整个实现仍然只有一个文件,这使得分叉维护尚可接受,但实现复杂度此时早已超出单文件所能承载的合理范围。
多年后,Mozilla 开发者尝试回归上游 jemalloc,并做出了许多贡献。但可惜的是,Mozilla 的基准测试始终显示他们分叉的版本性能优于上游版本。我不清楚这是过度优化导致的局部最优,还是性能真的退化了,但这始终是我对 jemalloc 最大的遗憾之一。
阶段 2:Facebook
2009 年加入 Facebook 后,惊讶地发现:Facebook 基础设施中 jemalloc 推广的最大障碍竟是缺乏调试工具支持;一些关键服务依赖 jemalloc 控制内存碎片,但工程师们却只能用 tcmalloc 和 gperftools 的 pprof 工具排查内存泄露。
于是,在 jemalloc 1.0.0 版本中,我加入了与 pprof 兼容的堆分析功能。接下来的几年里,jemalloc 迁移到 GitHub,继续零散开发,社区贡献逐渐增多:
3.0.0:引入了全面的测试基础设施和 Valgrind 支持
4.x 系列:引入了基于衰减的内存回收机制、JSON 格式遥测数据
5.x 系列:从“chunk”转向“extent”,为支持 2MiB 的大页做准备
争议最大的是我在 5.0.0 版本中移除了 Valgrind 支持,因为它维护起来复杂(有很多微妙依赖),而 Facebook 内部并不使用,主要依赖 pprof 和 MemorySanitizer。我几乎没有收到任何相关反馈,于是误以为没人用它。后来才知道,Rust 编译出来的程序直接集成了 jemalloc,Rust 社区中很多人也用 Valgrind。很多人因此非常愤怒。这也导致 jemalloc 早早被移出 Rust 二进制中。
Facebook 的内部遥测系统极其强大,让我们能在千变万化的服务中观察性能趋势,尤其对内存分配器的开发极为有利。比如:
1.快路径优化在拥有 perf 汇总数据的情况下更容易调优
2.避免碎片仍然是难题,但若几千种工作负载表现都良好,那说明更改是安全的
此外,jemalloc 本身的统计系统正是受 Facebook 监控文化的启发而添加的,后来也帮助了无数其他应用调优和调试。
我在 Facebook 最后一年的时候,还被鼓励组建了一个小型 jemalloc 团队,解决一些原本不可能单人完成的难题,推进了性能改进、持续集成测试和遥测系统。在我 2017 年离职后,jemalloc 团队继续在我几乎不参与的情况下,由优秀的同事 Qi Wang 领导,完成了数年高质量的开发与维护。
阶段 3:Meta
Facebook 更名为 Meta 后,jemalloc 的开发方向开始发生变化。基础架构团队减少了对底层技术的投入,更加关注投资回报。从 commit 记录上就能看出变化。例如,“大页分配”(HPA)早在 2016 年就种下了种子,但开发进度时快时慢,后来补丁叠加太多,缺乏重构,代码健康状况持续恶化。最终该功能发展停滞。这让我很遗憾,但我已经多年没有深度参与。如今,Meta 内部已经没人关注 jemalloc 的长期通用性发展。
我不想渲染戏剧冲突,但可以说,即便大多数人都在尽力而为,jemalloc 最终在 Meta 手中走向终结也是令人唏嘘的。公司文化会随着外部与内部压力而演化。个人往往被逼到三种选择:1)在巨大压力下做出不当决策;2)在压力下妥协;3)被绕过。我们偶尔能延缓这种系统性崩溃,甚至激发一时的复兴,但无法阻止整体趋势。
我仍然对以前所有在 jemalloc 上共事的同仁,以及 Facebook/Meta 长期以来对该项目的支持表示深深的感激。
阶段 4:停滞
那么现在呢?对我来说,jemalloc 的“上游”开发已经结束。Meta 的需求早已与外部用户需求脱节,他们也应该走自己的路了。
如果我要重启开发,第一步就需要几百小时的重构来偿还技术债。而我对后续工作的兴趣不足以支撑这样的前期投入。也许未来有人会基于 dev 分支或已经三年未更新的 5.3.0 版本创建新的分支项目。
上文提到了一些阶段性失败,但也有一些更普遍、让我这个做开源多年的人都感到意外的失败。
1.移除 Valgrind 支持带来负面反馈的根本原因是:对外部用户需求缺乏了解。如果我早知道 Valgrind 很重要,我肯定会和其他人一起保留它。
2.例如,我曾完全不知道 Android 用了 jemalloc 做默认分配器长达两年,也是在它被替换后才得知此事。
尽管 jemalloc 一直是公开开发的(没有被 Facebook 完全封闭),但它从未形成跨组织的主要贡献者团队:
1.Mozilla 开发者 Mike Hommey 推动 Firefox 回归上游几乎成功,却最终未能达成
2.CMake 构建系统的迁移尝试反复失败,从未完成
我曾在 Darwin 平台的惨痛经历中学到,封闭式的开源项目无法茁壮成长(HHVM 项目再次印证了这一点)。jemalloc 即便是开放开发,也仍然缺乏独立成长所需的外部结构和资源。对我而言,jemalloc 算是个奇怪的转折,因为我本人25 年来一直主张垃圾回收优于手动内存管理。如今我回归了垃圾回收系统,感到非常开心。但 jemalloc 是个极其充实且有意义的项目。感谢所有让这个项目变得有价值的人:合作者、支持者,以及使用者。
jemalloc-5.0不能取得其版本号
我系统中明明是jemalloc-5.0.1的库。执行# /usr/bin/jemalloc-config --version
0.0.0-0-g0000000000000000000000000000000000000000
发现输出居然是这样。发现只有在5.0以上这会这样,4.5版是正常的,能正常显示:
$ /usr/local/jemalloc/bin/jemalloc-config --version
4.5.0-0-g04380e79f1e2428bd0ad000bbc6e3d2dfc6b66a5
可以正常输出版本号。都是采用源码编译,但源码包中没提供'make uninstall'方法,先查看一下有哪些相关目录:
$ /usr/bin/jemalloc-config --config
--prefix=/usr
$ /usr/bin/jemalloc-config --bindir
/usr/bin
$ /usr/bin/jemalloc-config --datadir
/usr/share
$ /usr/bin/jemalloc-config --includedir
/usr/include
$ /usr/bin/jemalloc-config --libdir
/usr/lib
$ /usr/bin/jemalloc-config --mandir
/usr/share/man
手动删除:
rm -rfv /usr/bin/jemalloc* /usr/bin/jeprof /usr/include/jemalloc /usr/lib/libjemalloc* /usr/lib64/libjemalloc* /usr/lib/pkgconfig/jemalloc.pc /usr/share/doc/jemalloc /usr/share/man/man3/jemalloc.3
removed '/usr/bin/jemalloc-config'
removed '/usr/bin/jemalloc.sh'
removed '/usr/bin/jeprof'
removed '/usr/include/jemalloc/jemalloc.h'
removed directory '/usr/include/jemalloc'
removed '/usr/lib/libjemalloc.a'
removed '/usr/lib/libjemalloc_pic.a'
removed '/usr/lib/libjemalloc.so'
removed '/usr/lib/libjemalloc.so.2'
removed '/usr/lib/pkgconfig/jemalloc.pc'
removed directory '/usr/share/doc/jemalloc'
安装jemalloc-4.5版(/usr而非/usr/local)
jemalloc-4.5.0# make install
/usr/bin/install -c -d /usr/bin
/usr/bin/install -c -m 755 bin/jemalloc-config /usr/bin
/usr/bin/install -c -m 755 bin/jemalloc.sh /usr/bin
/usr/bin/install -c -m 755 bin/jeprof /usr/bin
/usr/bin/install -c -d /usr/include/jemalloc
/usr/bin/install -c -m 644 include/jemalloc/jemalloc.h /usr/include/jemalloc
/usr/bin/install -c -d /usr/lib
/usr/bin/install -c -m 755 lib/libjemalloc.so.2 /usr/lib
ln -sf libjemalloc.so.2 /usr/lib/libjemalloc.so
/usr/bin/install -c -d /usr/lib
/usr/bin/install -c -m 755 lib/libjemalloc.a /usr/lib
/usr/bin/install -c -m 755 lib/libjemalloc_pic.a /usr/lib
/usr/bin/install -c -d /usr/lib/pkgconfig
/usr/bin/install -c -m 644 jemalloc.pc /usr/lib/pkgconfig
/usr/bin/install -c -d /usr/share/doc/jemalloc
/usr/bin/install -c -m 644 doc/jemalloc.html /usr/share/doc/jemalloc
/usr/bin/install -c -d /usr/share/man/man3
/usr/bin/install -c -m 644 doc/jemalloc.3 /usr/share/man/man3
如果程序在安装好后还是不能正常识别jemalloc,可能是其运行的终端环境中没有设定预加载的变量。
在终端中强制设定预加载库:
LD_PRELOAD="/usr/local/jemalloc/lib/libjemalloc.so.2"
export LD_PRELOAD
可在终端中查询一下:
printenv "LD_PRELOAD"
可在程序开启前执行'jemalloc.sh'脚本,由它来初始一些预加载库,该脚本由jemalloc程序自带,安装好它之后就有的。
jemalloc.sh your-program arguments &
执行jemalloc-config --help可查看该库自身一些环境信息。或在系统profile文件中加载(source /usr/bin/jemalloc.sh)。
LD_PRELOAD
A whitespace-separated list of additional, user-specified, ELF shared libraries to be loaded before all others. This can be used to selectively override functions in other shared libraries. For setuid/setgid ELF binaries, only libraries in the standard search directories that are also setgid will be loaded.
You could use LD_PRELOAD enviroment variable to preload the jemalloc.so before you run your application, if it runs in a single terminal. Like this:
export LD_PRELOAD=$LD_PRELOAD:/path_of_jemalloc/lib/jemalloc.so.2
最新版本:5.0
jemalloc 发布了全新的 5.0.0 版本,与以前所有的版本不同,新版本不使用自然对齐的“chunks”进行虚拟内存管理,而是使用页面对齐的“extents”。部分更新内容:
新增 C ++ 新建/删除 operator bindings。
将衰减时间分辨率从秒增加到毫秒。
将 MALLCTL_ARENAS_ALL 添加为固定索引,用于通过 mallctl 访问合并/销毁的 arena 统计信息。
新增互斥量分析,用于收集各种有助于诊断开销/争用问题的统计信息。
在初始化期间检测到无效的配置选项时,可以选择中止 opt.abort_conf。
新增 --with-version = VERSION,以将 jemalloc 嵌入到另一个项目的 git 仓库中使用。
新增 --disable-thp 来支持交叉编译。
新增 --with-lg-hugepage 以支持交叉编译。
新增 mallctl 接口:
该版本有非常多的更新,详情请查阅发行主页。
官方主页:http://jemalloc.net/