PostgreSQL源码安装及配置
 PostgreSQL 的通用安装部署
PostgreSQL 的通用安装部署建立postgres用户
PostgreSQL的数据库主进程postmaster是一个特别的进程,它负责处理所有的用户对所有数据库的访问,它必须允许用户访问自己的数据但在没授权的情况下不允许访问其他用户的数据。为了实现这个功能,它需要能够控制所有的数据文件,因而普通用户不允许直接访问这些文件,postmaster进程将通过检查访问数据的用户的赋权情况控制对数据文件的访问。
PostgreSQL需要用一个非管理员用户运行,也就是说可以是任何普通用户,通常这是一个叫做postgres的用户被建立用来管理这些数据文件,它不需要其他的访问权限。另外postgres虚拟用户可以提供一些其他的安全措施,例如这个用户无法登录,所以别人无法非法访问这些数据。postmaster程序代表其他用户用这个用户去访问数据库文件。因此需要建立一个可运行的PostgreSQL系统的第一步就是建立postgres用户。Linux可以通过root用户使用useradd命令添加:
# useradd -m -r -s /bin/bash -u 5432 postgres
其他的UNIX系统中可能需要建立home目录,修改配置文件或者运行相关的工具,请参考所使用系统的文档来获得相关管理工具的细节。
建立数据库目录
下一步,你必须通过root用户建立一个目录给PostgreSQL用来存放数据库,并将目录的所有者设置为postgres:
# mkdir /usr/local/pgsql/data
# chown postgres /usr/local/pgsql/data
在这里我们使用默认的位置给数据库,可以选择在其他地方存储数据。
需要安装的软件gcc,make,perl,python
configure && make
./configure --prefix=/opt/pgsql --with-segsize=8 --with-wal-segsize=64 --with-wal-blocksize=16 --with-blocksize=16 --with-libedit-preferred --with-perl --with-python --with-openssl --with-libxml --with-libxslt --enable-profiling --enable-thread-safety --enable-nls=zh_CN
make && make install
或
make world && make install -world
当然这样也行:
gmake world(make world安装包含了文档,所有的contrib)
接着安装(带world参数可以安装Pg的附属信息,如文档,帮助等):
gmake install-world
如果有对xml支持需要的话,还要安装相关的开发依赖:libxml2-dev libxslt1-dev,这个在下面会详述。
数据库服务的初始及启动
$ /opt/pgsql12/bin/initdb --pgdata=/home/postgres/pgdata12 --encoding=utf8 --wal-segsize=64
属于此数据库系统的文件宿主为用户 "postgres".
此用户也必须为服务器进程的宿主.
数据库簇将使用本地化语言 "zh_CN.UTF-8"进行初始化.
initdb: could not find suitable text search configuration for locale "zh_CN.UTF-8"
缺省的文本搜索配置将会被设置到"simple"
禁止为数据页生成校验和.
修复已存在目录 /home/postgres/pgdata12 的权限 ... 成功
正在创建子目录 ... 成功
选择动态共享内存实现 ......posix
选择默认最大联接数 (max_connections) ... 100
选择默认共享缓冲区大小 (shared_buffers) ... 128MB
selecting default time zone ... PRC
创建配置文件 ... 成功
正在运行自举脚本 ...成功
正在执行自举后初始化 ...成功
同步数据到磁盘...成功
initdb: 警告: 为本地连接启用"trust"身份验证
你可以通过编辑 pg_hba.conf 更改或你下次
执行 initdb 时使用 -A或者--auth-local和--auth-host选项.
成功。您现在可以用下面的命令开启数据库服务器:
/opt/pgsql12/bin/pg_ctl -D /home/postgres/pgdata12 -l 日志文件 start
该初始语句带上'--show'参数后可打印出初始过程中的相关初始设定,不会进行真正初始化操作。用上述语句启动数据库服务,最简单的启动:
/opt/pgsql12/bin/pg_ctl -D /home/postgres/pgdata12 -l logfile start
等待服务器进程启动 ....2021-08-07 20:21:21.613 CST [13054] 日志: 正在启动 PostgreSQL 12.7 on x86_64-pc-linux-gnu, compiled by gcc (CRUX-x86_64-multilib) 5.2.0, 64-bit
2021-08-07 20:21:21.613 CST [13054] 日志: 正在监听IPv4地址"0.0.0.0",端口 5438
2021-08-07 20:21:21.613 CST [13054] 日志: 正在监听IPv6地址"::",端口 5438
2021-08-07 20:21:21.614 CST [13054] 日志: 在Unix套接字 "/tmp/.s.PGSQL.5438"上侦听
2021-08-07 20:21:21.622 CST [13055] 日志: 数据库上次关闭时间为 2021-08-07 20:02:56 CST
2021-08-07 20:21:21.624 CST [13054] 日志: 数据库系统准备接受连接
完成
服务器进程已经启动
PostgreSQL 11.2 版本对with-wal-segsize已经不支持了,改为wal-segsize:
configure: WARNING: unrecognized options: --with-wal-segsize
选用这个进行编译:
./configure --prefix=/opt/pgsql --with-segsize=8 --with-blocksize=16 --with-libedit-preferred --with-perl --with-python --with-openssl --with-libxml --with-libxslt --enable-thread-safety --enable-nls=zh_CN
configure都和什么内容有关
configure和configure.in文件是GNU autoconf包的一部分。configure允许我们来检测操作系统对不同方面的兼容性,以及接下来可以被C程序和Makefile检测到变量,autoconf也安装在PostgreSQL的主服务器上。如果希望给configure文件添加选项,可以编辑configure.in,之后运行autoconf以产生configure文件。
当用户运行configure,其就开始检测操作系统的各项兼容性,将这些结果保存在config.status和config.cache,并且修改*.in文件。例如,如果存在一个Makefile.in,configure将生成一个Makefile,其已经替换掉了configure所找到的@var@参数。
当你需要编辑文件时,请确认你没将时间浪费在修改由configure产生的文件。你可以编辑*.in文件,之后重新运行configure以重现创建需要的文件。如果你在源代码目录的顶层目录下运行了make distclean,所有由configure产生的文件将会被移除,此时你将只会看到源代码分发版中的文件。
--with-segsize=SEGSIZE
设置段尺寸,以 G 字节计。大型的表会被分解成多个操作系统文件,每一个的尺寸等于段尺寸。这避免了与操作系统对文件大小限制相关的问题。默认的段尺寸(1G字节)在所有支持的平台上都是安全的。如果你的操作系统有"largefile"支持(如今大部分都支持),你可以使用一个更大的段尺寸,这可以有助于在使用非常大的表时消耗的文件描述符数目,但是要当心不能选择一个超过你将使用的平台和文件系统所支持尺寸的值。你可能希望使用的其他工具(如tar)也可以对可用文件尺寸设限。如非绝对必要,我们推荐这个值应为2的幂。注意改变这个值需要一次 initdb。
--with-blocksize=BLOCKSIZE
设置块尺寸,以 K 字节计。这是表内存储和I/O的单位。默认值(8K字节)适合于大多数情况,但是在特殊情况下可能其他值更有用。这个值必须是2的幂并且在 1 和 32 (K字节)之间。注意修改这个值需要一次 initdb。
--with-wal-segsize=SEGSIZE
设置WAL 段尺寸,以 M 字节计。这是 WAL 日志中每一个独立文件的尺寸。调整这个值来控制传送 WAL 日志的粒度非常有用。默认尺寸为 16 M字节。这个值必须是2的幂并且在 1 到 64 (M字节)之间。注意修改这个值需要一次 initdb。
--with-wal-blocksize=BLOCKSIZE
设置WAL 块尺寸,以 K 字节计。这是 WAL 日志存储和I/O的单位。默认值(8K 字节)适合于大多数情况,但是在特殊情况下其他值更好有用。这个值必须是2的幂并且在 1 到 64(K字节)之间。注意修改这个值需要一次 initdb。
源码安装常见依赖包问题
PostgreSQL源码安装时如果相关依赖包缺失会导致编译失败,以下是常见的编译选项碰到的依赖包缺失问题和解决办法。
操作系统环境:
Centos 6、Debian 7
1、checking for flags to link embedded Perl... Can't locate ExtUtils/Embed.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .).
BEGIN failed--compilation aborted.
no configure: error: could not determine flags for linking embedded Perl.
This probably means that ExtUtils::Embed or ExtUtils::MakeMaker is not
installed.
解决方法:
yum install perl-ExtUtils-Embed
2、configure: error: readline library not found
If you have readline already installed, see config.log for details on the
failure. It is possible the compiler isn't looking in the proper directory.
Use --without-readline to disable readline support.
解决方法:
yum install readline readline-devel
3、checking for inflate in -lz... no
configure: error: zlib library not found
If you have zlib already installed, see config.log for details on the
failure. It is possible the compiler isn't looking in the proper directory.
Use --without-zlib to disable zlib support.
解决方法:
yum install zlib zlib-devel
4、checking for CRYPTO_new_ex_data in -lcrypto... no
configure: error: library 'crypto' is required for OpenSSL
crypto是什么呢?是OpenSSL 加密库(lib),这个库需要openssl-devel包,在debian中就是 libssl-dev。
解决方法:
yum install openssl openssl-devel
5、checking for pam_start in -lpam... no
configure: error: library 'pam' is required for PAM
解决方法:
yum install pam pam-devel
6、checking for xmlSaveToBuffer in -lxml2... no
configure: error: library 'xml2' (version >= 2.6.23) is required for XML support
解决方法:
yum install libxml2 libxml2-devel
7、checking for xsltCleanupGlobals in -lxslt... no
configure: error: library 'xslt' is required for XSLT supportconfigure: error: library 'xslt' is required for XSLT support
解决方法:
libxslt libxslt-devel
8、checking for ldap.h... no
configure: error: header file is required for LDAP
解决方法:
yum install openldap openldap-devel
9、checking for Python.h... no
checking Python.h usability... no
checking Python.h presence... no
checking for Python.h... no
configure: error: header file <Python.h> is required for Python
解决方法是安装python-dev,这是Python的头文件和静态库包。
解决方法:
yum install python-devel
10、Error when bootstrapping CMake:
Cannot find appropriate C++ compiler on this system.
Please specify one using environment variable CXX.
See cmake_bootstrap.log for compilers attempted.
解决方法:
yum install gcc-c++
11、checking for dtrace... no
configure: error: dtrace not found
解决方法:
yum install systemtap-sdt-devel
12、configure: error: Tcl shell not found
解决方法:
yum install tcl tcl-devel
13、checking for msgfmt... no
configure: error: msgfmt is required for NLS
需要安装gettext组件
yum install gettext gettext-devel
14、bison flex
如果系统上已经有安装的话:
checking for bison... /usr/bin/bison
configure: using bison (GNU Bison) 3.0.4
checking for flex... /usr/bin/flex
configure: using flex 2.5.37
没有会在configure的过程中报出:
***
WARNING: `bison' is missing on your system. You should only need it
if you changed the file `gram.y'; these changes will not take effect.
You can get bison from a GNU mirror site.
***
***
WARNING: `flex' is missing on your system. You should only need it
if you changed the file `specscanner.l'; these changes will not take effect.
You can get flex from a GNU mirror site.
***
安装它们的开发包不能解决这个问题
yum install bison-devel flex-devel
而要安装这两个开发功能包本身
yum install bison flex
CentOS下一次装好:
yum install openssl openssl-devel pam pam-devel libxml2 libxml2-devel libxslt libxslt-devel perl perl-devel python-devel perl-ExtUtils-Embed readline readline-devel zlib zlib-devel gettext gettext-devel bison flex
可选软件包
可选软件包(详细见文档):
(1)为了编译PL/Perl服务器端编程语言,需要完整Perl的安装,包括libperl库和头文件。
(2)为了编译PL/Python服务器端语言,需要一个包含头文件和distuils模块的python安装。
(3)为了编译PL/Tcl服务器端语言,需要Tcl的安装。
(4)为了使用NSL,即具有使用不同于英语的一种语言显示消息的能力,需要一种Gettext API的实现。
(5)需要Kerberos, OpenSSL, OpenLDAP, and/or PAM,如果你想要使用这些服务支持认证或加密。
(6)为了编译PostgreSQL的文档,有一组独立的要求。
源码目录结构简介
进入解压目录:cd postgresql-9.3.2,查看其结构:
(1)configure:源码安装的配置脚本
查看配置脚本支持的参数:./configure --help
(2)configure.in:configure文件的雏形
(3)COPYRIGHT:版权信息
(4)Makefile:Makefile模版
(5)GUNMakefile.in:Makefile的雏形
(6)HISTORY:版本变更的历史记录
(7)INSTALL:安装简要说明
(8)README:简单说明
(9)aclocal.m4:config用的文件的一部分
(10)config/:config用的文件的目录,存放了一些系统的配置文件,如c-compiler.m4文件中提供了检测C编译器的宏
(11)contrib/:已打包到PG源码中的第三方贡献的插件源码
第三方插件简介
adminpack:一些管理函数
auth_delay:认证失败后延迟报异常,可以防止暴力破解
auto_explain:将超过指定执行时间的SQL的执行计划输出到日志中
btree_gin:gin索引方法的btree操作符扩展(在某些情况下“多列gin组合索引”比“多个btree单列索引”的bitmap anding更高效)
btree_gist:gist索引方法的btree操作符扩展(在组合索引中的某些列类型仅支持gist索引访问方法,而另一些列的类型支持btree以及gist时btree_gist更为有效,同时btree_gist还新增了<>用于排他约束,<->用于近邻算法)
chkpass:自动加密的字段类型(使用UNIX标准函数crypt()进行封装,所以仅支持前8位安全)'abcdefghijkl'::chkpass--'abcdefgh'
citext:不区分大小写的数据类型
cube:多维立方体类型,支持多维立方体对象的相同,相交,包含等运算
dblink:PostgreSQL跨库操作插件
dict_int:全文检索的一个字典模版,用于控制数字被拆分的最大长度,以控制数字在全文检索中的分词个数(maxlen=6:12345678 --> 123456截断成6个,rejectlong=true则忽略这个分词)
dict_xsyn:全文检索的一个字典模块,设置分词的同义词,支持同义词匹配
dummy_seclabel:用于安全标签SQL的测试
earthdistance:可以使用cube或point类型计算地球表面两点之间的距离
file_fdw:文件外部表模块
fuzzystrmatch:单字节字符串之间的相似性判断
hstore:用于存储K-V数据类型,同时这个插件还提供了比较V类型相关的函数和操作符。例如提供数组,json,hstore之间的转换,K-V的存在判断,删除K-V值
intagg:int类型的数组聚合函数(内建的array_agg函数已包含这个功能)
intarray:int类型的数组功能扩展库,提供了一些常用的函数和操作符(数组元素个数,元素排序,元素下标,取元素子集,相交,包含,增加元素,删除元素,合并等)
isn:提供国际通用的产品标识码数据类型,例如ISBN,ISMN...
lo:大对象的一个可选模块,lo类型以及自动unlink大对象的触发器,方便大对象在消亡后的自动unlink,防止大对象存储泄漏(类似内存泄漏)
ltree:异构数据类型以及操作函数和操作符。例如China.Zhejiang.Hang<@'China'
oid2name:id转换成name的命令行工具,不属于extension。或通过系统表查询得到.
pageinspect:用于读取数据库PAGE裸信息的插件,可以读main,fsm,vm FORK的页数据,一般用于debug(使用时请参照对应数据库版本的头文件解读信息)
passwordcheck:创建用户或者修改用户密码时,检查密码的安全性,如果太弱的话,将返回错误。
pg_archivecleanup:清除归档文件的命令,不属于extension
pgbench:数据库性能测试的命令,不属于extension
pg_buffercache:输出当前的shared buffer的状态数据(细化到page number)
pgcrypto:PostgreSQL的服务端数据加密的扩展库
pg_freespacemap:输出对象指定page或所有page的free space map信息
pgrowlocks:(从行头信息中的informask获取行锁信息),注意输出的不是snapshot
pg_standby:8.4以及以前的版本方便于创建warm standby的命令行
pg_stat_statements:跟踪数据库的SQL,收集SQL的统计信息
pgstattuple:行级统计信息(dead tuples,live tuples,table_len,free_space,free_percent),索引的统计信息
pg_test_fsync:测试磁盘的fsync速率。适用于选择最快的wal_sync_method
pg_test_timing:测试系统定时器的开销,开销越大,explain analyze时间结果越不准,需要调整系统时钟源
pg_trgm:将字符串拆分成3个一组的多个单元,用于测试两个字符串之间的近似度,比分词更加暴力。
pg_upgrade:跨大版本的升级工具(例如9.0-->9.1)
pg_upgrade_support:pg_upgrade用到的服务端函数集
pg_xlogdump:从xlog中dump出一些易读的底层信息
postgres_fdw:postgresq跨库的外部表插件
seg:线段类型和浮点数的区间类型,以及相关的操作符,索引访问方法等
sepgsql:基于SELinux安全策略的访问控制模块
spi:一些服务端的触发器函数(例如跟踪记录的存活时间,被哪个用户修改了,记录的修改时间等)
sslinfo:输出ssl认证的客户端的一些认证信息
start-scripts:数据库启动脚本模版
tablefunc:一般可用于行列变换,异构数据处理等
tcn:提供异步消息输出的触发器
test_parser:全文检索中的一个自定义parser的测试插件
tsearch2:全文检索相关的插件,在全文检索未引入PG内核前的PG版本可以使用这个插件来实现全文检索功能,大于8.3以后就不需要这个了
unaccept:全文检索相关的插件
uuid-ossp:生成UUID的插件
vacuumlo:大对象垃圾回收的命令
worker_spi:9.3新增的服务端worker编程范例
xml2:xml相关插件
(12)doc/:文档目录
(13)src/:源代码目录,存放了PG的核心代码
src目录简介:
DEVELOPERS:面向开发人员的注视
Makefile:Makefile
Makefile.global.in:make的设定值(从configure生成的)
Makefile.shlib:共享库用的Makefile
nls-global.mk:信息目录用的Makefile文件的规则
backend/:数据库引擎代码,数据库各个功能进程代码,系统存储部分代码,事务处理代码,查询优化部分代码等。PG最重要的代码都位于此目录
bin/:数据库外围工具代码,如initdb,psql,pg_dump等的代码
include/:系统依赖的头文件统一按照c文件的目录结构组织在include目录下
interfaces/:数据库系统提供的对外接口,如libpq。但是如ODBC、JDBC等不在这个目录,它们作为独立的项目存在
makefiles/:存放了针对不同操作系统编译所使用的makefile文件
pl/:pg提供的存储过程,包括tcl、perl、python三种脚本语言支持的存储过程和PL/pgSQL支持的存储过程
port/:平台移植相关的代码,对src\bin下的工具提供的基本函数的支持,编译后的样式是一个lib库
template/:针对不同操作系统提供的一些脚本样例
test/:各种测试脚本,PG提供的回归测试用例和自动化测试框架
timezone/:时区相关代码(从http://www.iana.org/time-zones同步的时区库)
tools/:辅助开发工具
tutorial/:PG提供的部分示例,如如何写PG认识的SQL,如何写PG风格一致的C代码等
backend目录结构简介:
access/:数据访问层(很重要的目录),存放了和索引相关以及事务处理相关的代码:各种存储访问方法(在各个子目录下) common(共同函数)、gin (Generalized Inverted Index通用逆向索引)、gist (Generalized Search Tree通用索引)、 hash (哈希索引)、heap (heap的访问方法)、index (通用索引函数)、 nbtree (Btree函数)、transam (事务处理)。本层之下,是数据缓冲区,再下层,是真正的数据存储层。
bootstrap/:初始化数据库时要使用的代码,和src\bin\initdb下的initdb工具紧密相关。
catalog/:PG提供的针对系统表的操作代码,包含用于操作系统表的专用函数。
parser/:编译器,对SQL语句进行解析的代码(注意gram.y文件)。即将SQL查询转化为内部查询树。
optimizer/:查询优化器,根据查询树创建最优的查询路径和查询计划。
executor/ 执行器(访问的执行),执行来自Optimizer的查询计划。与commands目录中的代码联合完成查询处理功能。
commands/:执行非计划查询的SQL目录,如create table命令等。SQL命令被解析后执行具体命令时对应的操作代码(SELECT/INSERT/UPDATE/DELETE以外的SQL文的处理)
tcop/:postgres服务进程(数据库引擎的进程)的主要部分,它调用Parser、Optimizer、Executor和Commands中的函数来执行客户端提交的查询。
foreign/:FDW(Foreign Data Wrapper)处理
lib/:共同函数,字符串处理和链表处理辅助函数。
libpq/:处理与客户端间的通信,几乎所有的模块都依赖它。如:同身份认证或口令识别相关代码,以进行安全的网络通讯。如ssl,md5等等。
main/:主程序模块,它负责将控制权转到Postmaster进程或Postgres进程。PG的main函数所在。PG启动入口。
nodes/:定义系统内部所用到的节点、链表等结构,以及处理这些结构的函数。
po/:实现国际化(i18n)功能的一部分。把一些数据库的提示信息国际化。
port/:平台兼容性处理相关函数。屏蔽一些不同操作系统在一些实现上的差别。如windows上的socket、darwin系统上对system函数的支持、sunos4系统对于float类型的支持等。
postmaster/:监听用户请求的守护进程,并控制Postgres进程的启动和终止。PG的主要进程。如主服务进程postmaster,归档进程pgarch等。
regex/:正则表达式库及相关函数,用于支持正则表达式处理。
replication/:streaming replication
rewrite/:查询重写,根据规则系统对查询进行重写。
snowball/:支持全文检索的代码
storage/:很重要的一个目录,有关物理存储系统相关代码。管理各种类型的存储系统(如磁盘、闪存等),即共享内存、磁盘上的存储、缓存等全部一次/二次记录管理:buffer/(缓存管理)、 file/(文件)、freespace/(Fee Space Map管理) ipc/(进程间通信)、large_object /(大对象的访问函数)、 lmgr/(锁管理)、page/(页面访问相关函数)、 smgr/(存储管理器)。
tsearch/:全文检索相关代码
utils/:各种支持函数,如错误报告、各种初始化操作等等。各种模块(目录):adt/(嵌入的数据类型)、cache/(缓存管理)、 error/(错误处理)、fmgr/(函数管理)、hash/(hash函数)、init/(数据库初始化、postgres的初期处理)、 mb/(多字节文字处理)、misc/(其他)、mmgr/(内存的管理函数)、 resowner/(查询处理中的数据(buffer pin及表锁)的管理)、sort/(排序处理)、time/(事务的 MVCC 管理)
backend等的代码的头文件包含在include里面。其组织虽然与backend的目录结构类似,但是并非完全相同,基本上来说下一级的子目录不再设下一级目录。例如backend的目录下面有utils这个目录,而util下面还有adt这个子目录,但是include里面省略了这个目录,变成了扁平的结构。
配置选项说明:
--prefix=/opt/pgsql9x:安装所有文件在/opt/pgsql9x中(取代默认时的/usr/local/pgsql)。
--with-pgport=5432:为服务器和客户端设置默认端口号。默认是5432。
--with-perl:编译PL/Perl服务端语言。
--with-python:编译PL/Python服务端语言。
--with-tcl:编译PL/Tcl服务端语言。
--with-openssl:编译支持SLL(加密)连接。这需要安装OpenSSL包。
--with-pam:编译支持PAM(Pluggable Authentication Modules,可插拔认证模块)
--without-ldap:编译支持认证和连接参数检查
--with-libxml:编译libxml(支持SQL/XML),支持这个选项需要Libxml 2.6.23及最新版
--with-libxslt:编译xml2模块,使用libxslt
--enable-thread-safety:让客户端库是线程安全的
--with-wal-blocksize=16:WAL:预写式日志(Write-Ahead Logging)
设置WAL的block size,以MB为单位。这是在WAL日志中的每个独立文件的大小。为了控制WAL日志传送的粒度去调整其大小,这可能是非常有用的。默认为16MB。这个值必须是2的1到64次方(MB)。注意,改变这个值需要一个initdb。
--with-blocksize=16:设置block size,以KB为单位。这是表的存储和IO单元。默认为8K,适用于大多数情况;但是在特殊场合中,其他的值可能是非常有用的。这个值必须是2的1到32次方(KB)。注意,改变这个值需要一个initdb。
--enable-dtrace:编译PostgreSQL支持动态跟踪工具DTrace
--enable-debug:把所有程序和库以带有调试符号的方式编译
--enable-nls[=LANGUAGES]:打开本地语言支持(NLS),即以非英文显示程序的信息的能力。LANGUAGES是一个空格分隔的语言代码列表,标识你想支持的语言。比如--enable-nls='zh_cn de fr'(你提供的列表和实际支持的列表之间的交集将会自动计算出来)。如果你没有声明一个列表,那么就安装所有可用的翻译。(还可以在--enable-debug前,添加两个选项:--enable-depend --enable-cassert)
配置过程可能会遇到依赖的动态库缺失, 安装这些缺失的库即可。记录下我这里的缺失lib的安装。
dtrace工具的安装:
PostgreSQL支持动态跟踪, 可以通过dtrace或者systemtap工具统计相关探针的信息。
在CentOS中安装systemtap:
在安装systemtap前,要保证kernel对应的kernel-devel包的版本保持一致:
检查:
[root@localhost ~]# rpm -qa|grep kernel
[root@localhost ~]# uname -a
不一致的话,则安装对应的kernel-devel版本或者升级kernel:
[root@localhost ~]# yum install kernel-devel
或:yum update kernel
重启服务器。
安装systemtap
[root@localhost ~]# yum install systemtap systemtap-sdt-devel
其中:安装systemtap时,安装了systemtap-devel、systemtap-client和systemtap-runtime这3个包。systemtap-sdt-devel是编译PostgreSQL时,选项--enable-dtrace需要的包。
使用命令:
[root@localhost ~]# rpm -qf /usr/bin/stap
systemtap-devel-2.3-4.el6_5.x86_64
systemtap-client-2.3-4.el6_5.x86_64
rpm -qf:查询文件隶属的软件包
来检查stap是否正常。
当PostgreSQL数据库安装成功后, 会在该目录下创建一系列与PostgreSQL相关的目录以及文件,分别是:bin、include、lib和share 这四个目录。其中bin目录下存放的是PostgreSQL数据库相关的所有命令列表,包括初始化、创建、删除、启动、停止、备份、连接数据库等等命令。lib目录下存储的与PostgreSQL数据库相关的编译动态库文件,include下存储的是相关头文件,share目录下存储的是命令列表中用到的一些共享的公共配置文件和数据,比如initdb初始化时候需要读取share目录下的postgresql.conf.sample文件。
使用libpg库来开发PostgreSQL的客户端交互代码时候,就需要连接libpg.so库文件,因此可以直接来lib目录下获取。当然libpg.so文件并不仅仅存储于该目录下,在PostgreSQL源码包的"src/interfaces/libpq"目录下也同样有对应的动态库和静态库。
设定用户shell环境
# su - postgres
$ vim .bash_profile
# postgres
#PostgreSQL端口
PGPORT=5432
#PostgreSQL数据目录
PGDATA=/data/pgdata
export PGPORT PGDATA
#所使用的语言
export LANG=zh_CN.utf8
#PostgreSQL 安装目录
export PGHOME=/data/pg
#PostgreSQL 连接库文件
export LD_LIBRARY_PATH=$PGHOME/lib:/lib64:/usr/lib64:/usr/local/lib64:/lib:/usr/lib:/usr/local/lib:$LD_LIBRARY_PATH
export DATE=`date +"%Y%m%d%H%M"`
#将PostgreSQL的命令行添加到 PATH 环境变量
export PATH=$PGHOME/bin:$PATH
#PostgreSQL的 man 手册
export MANPATH=$PGHOME/share/man:$MANPATH
#PostgreSQL的默认用户
export PGUSER=postgres
#PostgreSQL默认主机地址
export PGHOST=127.0.0.1
#默认的数据库名
export PGDATABASE=postgres
#定义日志存放目录
PGLOG="$PGDATA/serverlog"
初始化数据库
#执行数据库初始化脚本
$/data/pg/bin/initdb --encoding=utf8 -D /data/pg/data
警告:为本地连接启动了 "trust" 认证.
你可以通过编辑 pg_hba.conf 更改或你下次
行 initdb 时使用 -A或者--auth-local和--auth-host选项.
成功。您现在可以用下面的命令开启数据库服务器:
bin/pg_ctl -D data -l logfile start
通过initdb工具初始化PostgreSQL数据库,初始化时需要制定你文件系统中想要存储数据库的位置。这将做很多事,包括建立PostgreSQL需要运行的数据结构以及初始化一个可工作的数据库:template1。
你需要使用postgres用户来运行initdb工具。为了做到这点,最可靠的方法是完成两步,第一步是通过su命令切换到root用户,然后切换成postgres用户,就像以下所示(作为一个普通用户,你可能无法用其他用户身份运行程序,所以你必须先变成超级用户):
su - postgres
现在你运行的程序是以postgres用户运行的,并且你可以访问PostgreSQL的数据文件了。很明显,我们现实了postgres用户的shell的命令提示符$。
警告:不要为了图方便直接用root而不是postgres用户完成以上过程。由于安全原因,用root身份运行服务进程可能非常危险。如果这个进程有问题,可能导致外部通过网络非法访问你的系统。由于这个原因,postmaster将拒绝通过root运行。
通过initdb命令初始化数据库:
/usr/local/pgsql/bin/initdb -D /usr/local/pgsql/data
The files belonging to this database system will be owned by user “postgres”.
This user must also own the server process.
The database cluster will be initialized with locale en_US.UTF-8.
The default database encoding has accordingly been set to UTF8.
The default text search configuration will be set to “english”.
…
WARNING: enabling “trust” authentication for local connections
You can change this by editing pg_hba.conf or using the -A option the
next time you run initdb.
Success. You can now start the database server using:
/usr/local/pgsql/bin/postgres -D pgdata
or
/usr/local/pgsql/bin/pg_ctl -D pgdata -l logfile start
如果一切正常,你将在initdb命令的-D参数指向的位置拥有一个全新的空白数据库。这里使用了en_US的locale,这是当前的默认的shell环境变量决定的,也可以指定相应的locale来进行初始化,前提是本地系统的locales中有。
将编译过的数据库(非标准安装路径如:/opt/pgsql)的开发及库文件链接到系统标准目录下
# ln -s /opt/pgsql/lib /usr/lib64/postgresql
# ln -s /opt/pgsql/include /usr/include/postgresql
需要注意环境变量
#postgresql env
export PGPORT=5432
export PGUSER=postgres
export PGHOME=/home/postgres
export PGDATA=/apps/pgdata
export PGDATABASE=postgres
export PGLOCALEDIR=/opt/pgsql/share/locale
export MANPATH=$MANPATH:/opt/postgres/share/man
一些地方还有与开发头和开发库相关的变量,但在手册中页中没有看到
POSTGRES_INCLUDE: /install_path/include
POSTGRES_LIB: /install_path/lib
参考来源
libpq-envarsv12-cn
libpq-envarsv12-en
配置连接权限
默认情况下,PostgreSQL不允许全面的远程访问。为了赋权给远程连接,你必须编辑配置文件pg_hba.conf。这个文件存在于数据库文件的区域(在本例中,位于/usr/local/pgsql/),它包含允许或者拒绝特定用户连接到数据库的权限的配置记录。默认情况下,本地用户可以连接但远程用户不允许。文件格式非常简单,PostgreSQL自带的默认文件包含大量的有用的注释用于协助添加记录。你可以根据需要给单个的用户、主机、计算机组或者单独的数据库赋权。
例如,希望允许用户neil通过IP地址为192.168.0.3的主机连接到bpsimple数据库,添加以下行到pg_hba.conf文件:
host freeoa neil 192.168.0.3/32 md5
注意,在早于8.0版本的PostgreSQL中,pg_hba.conf通过IP地址和子网掩码说明一个主机地址,所以之前的例子应该写成这样:
host freeoa neil 192.168.0.3 255.255.255.255 md5
本例中将添加一条记录来运行局域网中(本例中,子网为192.168.x.x)的任何计算机通过密码认证访问数据库(如果你需要不同的访问策略,参考配置文件里头的注释)。添加一行到pg_hba.conf的末尾,就像这样:
host all all 192.168.0.0/16 md5
这意味着IP地址由192.168开头的计算机可以访问所有的数据库。此外加入信任网络中的所有用户,可以通过指定使用trust标记不受限的访问方法作为访问策略,就像这样:
host all all 192.168.0.0/16 trust
PostgreSQL的postmaster服务进程读取配置文件postgresql.conf(也存在于数据目录中)来设置一系列的运行选项,包括(如果没有另外指定-D选项或者配置PGDATA环境变量)数据库数据文件的位置。这个配置文件被很好的注释了,如果想修改任何设置,它都提供了向导。PostgreSQL的文档有一章讲述了运行配置。
例如,可以设置postgresql.conf文件中的listen_addresses参数允许服务器监听网络连接,而不是通过-i选项:
listen_addresses=’*’
实际上推荐通过postgresql.conf设置配置参数来控制postmaster进程的行为。
启动postmaster进程
现在可以启动服务进程了。再次提醒,可以使用-D选项告诉postmaster数据库文件所在位置。如果你想允许网络上的用户访问你的数据,可以使用-i选项启用远程访问(如果没在postgresql.conf文件中启用listen_addresses选项,就像前面所说的):
/usr/local/pgsql/bin/postmaster -i -D /usr/local/pgsql/data >logfile 2>&1 &
这条命令启动postmaster,重定向进程输出到一个文件(名叫logfile,存放在postgres用户的home目录中),并且通过shell的2>&1合并标准输出和标准错误输出。可以通过重定向输出到其他文件来选择不同的日志位置。
PostgreSQL提供的pg_ctl工具提供了一种简单的方法启动、停止和重启(就是停止和启动)postmaster进程。如果PostgreSQL就像之前所属的那样完全由postgresql.conf文件配置,可以简单的使用以下命令启动、停止和重启:
pg_ctl start
pg_ctl stop
pg_ctl restart
连接到数据库
现在你可以通过尝试连接到数据库测试它是否正常工作了。psql工具是用来与数据库进行交互和进行简单的管理工作例如建立用户,建立数据库以及建表。在本章后面我们将用它来建立和填充数据库,在第5章将详细讲解它的功能。现在,你可以简单地尝试连接到一个数据库。以下的反馈显示你已经运行了postmaster:
/usr/local/pgsql/bin/psql
psql: FATAL 1: Database “postgres” does not exist in the system catalog.
不要被上面显示的致命错误吓着。默认情况下,psql连接到本机的数据库并尝试用启动这个程序的用户的名称打开数据库。因为在这里没有建立叫postgres的数据库,所以连接失败。这意味着,postmaster进程运行了并且能够正常响应失败的细节。
为了指定连接的数据库,可以传递-d参数给psql。全新的PostgreSQL系统包含一些系统使用的数据库作为你需要新建的数据库的模板。其中有一个叫做template1。如果需要,可以连接到数据库这个数据库用来完成管理功能。为了检查网络连接,可以使用网络上其他机器安装的psql作为客户端,或者其他的PostgreSQL兼容的程序。在psql中,可以使用-h选项指定主机(无论是名称还是IP地址),并指定一个系统数据库(如果你还没建立一个真正的数据库)。
PostgreSQL好在哪里
用一句话其实难以尽述。如果非要总结,可以认为有以下几点:
稳定
PostgreSQL的代码质量是被很多人认可的,经常会有人笑称PG的开发者都是处女座。基本上,PG的一个大版本发布,经过三两个小版本就可以上生产,这是值得为人称道的一个地方。从PostgreSQL漂亮的commit log就可见一斑,PostgreSQL的COMMIT LOG而得益于PostgreSQL的多进程架构,一个连接的异常并不影响主进程和其他连接,从而带来不错的稳定性。
性能
我们内部有些性能上的数据,TPCC的性能测试显示PostgreSQL的性能与商业数据库基本在同一个层面上。
丰富
PostgreSQL的丰富性是最值得诉说的地方。因为太丰富了,以至于不知道该如何突出重点。最全面的例子,这里只列举几个我认为比较有意思的几点(查询、类型、功能):
查询的丰富
且不说HASH\Merge\NestLoop JOIN,还有递归、树形(connect by)、窗口、rollup、cube、grouping sets、物化视图、SQL标准等,还有各种全文检索、规则表达式、模糊查询、相似度等。在这些之外,最重要的是PostgreSQL强大的基于成本的优化器,结合并行执行(并行扫瞄、并行JOIN等)和多种成本因子,带来各种各样丰富灵活高效的查询支持。
类型的丰富
如高精度numeric, 浮点, 自增序列,货币,字节流,时间,日期,时间戳,布尔, 枚举,平面几何,立体几何,多维几何,地球,PostGIS,网络,比特流,全文检索,UUID,XML,JSON,数组,复合类型,域类型,范围,树类型,化 学类型,基因序列,FDW, 大对象, 图像等。
[注意: 这里的数组,可以让用户像操作JAVA中的数组一样操作数据库中的数据,如 item[0][1]即表示二维数组中的一个元素,而item可以作为表的一个字段。]
或者,如果以上不够满足,可以自定义自己的类型(create type),并且可以针对这些类型进行**运算符重载**,比如实现IP类型的加减乘除(其操作定义依赖于具体实现,意思是:想让IP的加法是什么样子就是什么样子)。
另外还有各种索引的类型,如btree, hash, gist, sp-gist, gin, brin , bloom , rum 索引等,甚至可以为自己定义的类型定制特定的索引和索引扫瞄。
功能的丰富
PostgreSQL有一个无与伦比的特性——插件。其利用内核代码中的Hook,可以让你在不修改数据库内核代码的情况下,自主添加任意功能,如PostGIS、JSON、基因等,都是在插件中做了很多的自定义而又不影响任何内核代码从而满足丰富多样的需求。而PostgreSQL的插件,不计其数。FDW机制更让你可以在同一个PostgreSQL中像操作本地表一样访问其他数据源,如Hadoop、MySQL、Oracle、Mongo等,且不会占用PG的过多资源。
至于其他的,举个简单的例子,PostgreSQL的DDL(如加减字段)是可以在事务中完成的 [PS: PostgreSQL是Catalog-Driven的,DDL的修改基本可以理解为一条记录的修改]。这一点,相信做业务的同学会有体会。
PostgreSQL支持大部分SQL标准并且提供了许多其它现代特性:
复杂查询
外键
触发器
可更新的视图
事务完整性
多版本并发控制
另外,PostgreSQL可以用许多方法进行扩展,比如通过增加新的:
数据类型
函数
操作符
聚合函数
索引方法
过程语言
经过二十几年的发展,PostgreSQL 是目前世界上最先进的开源数据库系统。
体系基本概念
PostgreSQL使用常见的客户端/服务器的模式,一次PostgreSQL会话由下列相关的进程(程序)组成:
服务器进程
它管理数据库文件,接受来自客户端应用与数据库的连接,并且代表客户端在数据库上执行操作。数据库服务器程序叫postgres。
客户端应用
客户端应用可能本身就是多种多样的:它们可以是一个字符界面的工具,也可以是一个图形界面的应用,或者是一个通过访问数据库来显示网页的 web 服务器,或者是一个特殊的数据库管理工具。一些客户端应用是和PostgreSQL发布一起提供的,但绝大部分是用户开发的。
PostgreSQL服务器可以处理来自客户端的多个并发连接。它为每个连接启动(“forks”)一个新的进程。从这个时候开始,客户端和新服务器进程就不再经过最初的postgres进程进行通讯。主服务器总是在运行,等待客户端连接,而客户端及其相关联的服务器进程则是起起停停。
更改字段属性,含空格
如果把字段colname把属性Text转化为int,原来text里面存在空的,可以:
ALTER TABLE tablename ALTER COLUMN colname TYPE int USING (trim(keyword)::integer);
向表中插入数据
如果表中字段有大写的字段,则需要对应的加上双引号。例:insert into test (no, "Name") values ('123', 'freeoa');
值用单引号引起来(''),不能用双引号("")
两个查询结果做差 except
(select node_id from node where node_id=1 or node_id=2) except (select node_id from node where node_id=1);
登录后,psql常用的元命令:
\?, 查看psql所有可以使用的元命令和说明信息;
\c demodb, 连接到demodb数据库;
\c[onnect] [数据库名称|- 用户名称|- 主机|- 端口|-], 连接到新的数据库;
\d, 列出表,视图和序列;
\d 名称, 描述表,视图,序列,或索引;
\db [模式], 列出表空间
\di [模式], 列出所有索引;
\dt [模式], 列出所有表;
\dT [模式], 列出数据类型
\h, 列出所有的SQL命令;
\h select, 列出select语句的语法;
\i file, 执行来自file的命令;
\q, 退出psql;
select * from pg_stat_activity; 显示当前活动任务列表.
查询结果存储到输出文件
格式:
\o file_path
这样就会把查询结果存储到输出文件中。
\l 列出所有数据库 或者: SELECT datname FROM pg_database;
\du 列出所有角色/用户 或者: SELECT rolname FROM pg_roles;
\dx 显示安装的插件
\x 切换横向竖向显示
show <参数名> 查看该参数的值
创建用户及权限
PostgreSQL使用角色的概念管理数据库访问权限。根据角色自身的设置不同,一个角色可以看做是一个数据库用户,或者一组数据库用户。角色可以拥有数据库对象(比如表)以及可以把这些对象上的权限赋予其它角色,以控制谁拥有访问哪些对象的权限。另外,我们也可以把一个角色的成员权限赋予其它角色,这样就允许成员角色使用分配给另一个角色的权限。角色的概念替换了”用户”和”组”。在PostgreSQL 版本 8.1 之前,用户和组是独立类型的记录,但现在它们只是角色。任何角色都可以是一个用户、一个组、或者两者。
数据库角色从概念上与操作系统用户是完全无关的。在实际使用中把它们对应起来可能比较方便,但这不是必须的。数据库角色在整个数据库集群中是全局的(而不是每个库不同)。要创建一个角色,使用 SQL 命令CREATE ROLE执行:
CREATE ROLE name;
name遵循 SQL 标识的规则:要么完全没有特殊字符,要么用双引号包围(实际上你通常会给命令增加额外的选项,比如LOGIN)。要删除一个现有角色,使用类似的DROP ROLE命令:
DROP ROLE name;
为了方便,程序createuser和dropuser 提供了对了这些 SQL 命令的封装。
要检查现有角色的集合,可以检查pg_roles系统表,比如:
SELECT rolname FROM pg_roles;
psql的元命令\du
也可以用于列出现有角色。
插件(扩展)
PostgreSQL的contrib目录和extension目录附带包含若干插件的源代码,在附录 F中被描述。其它插件是独立开发的比如PostGIS,甚至PostgreSQL的复制方案也是在外部开发的。 比如 Slony-I 是一个流行的主/从复制方案,它就是独立在核心项目之外开发的。
PostgreSQL的插件主要用来提供新的用户自定义函数,操作符,或类型。若要使用插件,需要在数据库系统中注册新的SQL对象。(如果该插件没有在contrib或extension目录下,需要先自己安装,或者在编译源码的时候指定。) 在PostgreSQL 9.1和以后版本,这是通过执行 CREATE EXTENSION命令来实现:
CREATE EXTENSION module_name;
此命令必须由数据库管理员运行。如想在某个数据库中使用该插件,则必须在该数据库中运行如上命令。另外在数据库template1中运行它,这样在随后创建的数据库中也可使用该插件。
配置Postgresql中的日志
PostgreSQL: Important Parameters to enable Log for all Queries
A database log is necessary for finding different statuses, errors, bad queries and any changes on the Database Server.A Database Administrator can also log different executed queries and analyze it for performance tuning.Following are few relevant parameters to enable PostgreSQL log for all queries.
Please open your postgresql.conf file and make sure about all logs related parameter’s value which is mentioned here.
log_directory = ‘pg_log’ (default directory name)
log_filename = ‘postgresql-%Y-%m-%d_%H%M%S.log’ (default file name structure)
log_statement = ‘all’ (value ‘all’ is recommended {none, ddl, mod, all})
logging_collector = ON
log_line_prefix = ‘%t %c %u ‘ (time, sessionid, user)
log_destination = ON (stderr,syslog,csvlog,eventlog)
log_rotation_size = 15MB
log_rotation_age = 1d (create new log file every day)
In postgresql.conf file, change the log_statement setting to 'all'.
SELECT set_config('log_statement', 'all', true);
With a corresponding user right may use the query above after connect. This will affect logging until session ends.
PostgreSQL: Difference between pg_log, pg_clog and pg_xlog log directories
If you look into your PostgreSQL data directory, you can find a different type of log folders.
pg_log:
This is a default database logs like: error messages, executed query log, dead lock information, Postgers start/stop messages.
First, you should look into this folder for any investigation. Most of the time we are getting an error because of bad queries or wrong configuration so in these cases we can find the important log messages from this folder.
You can also delete unwanted or old log files because It stores only database action related messages which are not critical for PostgreSQL Server.
There are a few parameters in Postgres.conf file related to pg_log folder, you access below article for this.
pg_clog:
We cannot read log files of this folder because it is for PostgreSQL internals. It contains logs for transaction metadata. PostgreSQL server access this folder to take the decision like which transaction completed or which did not.
This is critical log folder, you should never forget this folder during your pg_data directory backup.
pg_xlog:
At all the times, PostgreSQL maintains a write-ahead log (WAL) in the pg_xlog/ subdirectory of the cluster’s data directory. The log records for every change made to the database’s data files. These log messages exists primarily for crash-safety purposes.
It contains the main binary transaction log data or binary log files. If you are planning for replication or Point in time Recovery, we can use this transaction log files.
We cannot delete this file. Otherwise, it causes a database corruption. The size of this folder would be greater than actual data so If you are dealing with massive database, 99% chance to face disk space related issues especially for the pg_xlog folder.
But don’t worry, There are multiple ways to optimize pg_xlog folder by removing old WAL files.
Postgresql的日志(pg_log,类似oracle的alter文件,非pg_xlog)确实是很灵活,功能也很丰富的,下面是借用postgres的日志来实现一些管理功能,所涉及的参数都在文件$PGDATA/postgresql.conf里面:
logging_collector --是否开启日志收集开关,默认off,开启要重启DB
log_destination --日志记录类型,默认是stderr,只记录错误输出
log_directory --日志路径,默认是$PGDATA/pg_log
log_filename --日志名称,默认是postgresql-%Y-%m-%d_%H%M%S.log
log_connections --用户session登陆时是否写入日志,默认off
log_disconnections --用户session退出时是否写入日志,默认off
log_rotation_age --保留单个文件的最大时长,默认是1d,也有1h,1min,1s,个人觉得不实用
log_rotation_size --保留单个文件的最大尺寸,默认是10MB
配置值:
logging_collector = on
log_destination = 'csvlog'
log_directory = '/home/postgres/pg_log'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_connections = on
log_disconnections = on
log_rotation_age = 1d
log_rotation_size = 20MB
配置完重启DB,检查日志情况(pg_log目录下),记录用户登陆数据库后的各种操作,postgres日志里分成了3类,通过参数pg_statement来控制,默认的pg_statement参数值是none,即不记录,可以设置ddl(记录create,drop和alter)、mod(记录ddl+insert,delete,update和truncate)和all(mod+select)。
示例:
[postgres@localhost ~]$ vi $PGDATA/postgresql.conf
log_statement = ddl
postgres=# show log_statement;
log_statement
---------------
ddl
--修改为mod级别,并reload
postgres=# show log_statement;
log_statement
---------------
mod
--修改为all级别,并reload
postgres=# show log_statement;
log_statement
---------------
all
一般的OLTP系统审计级别设置为ddl就够了,因为记录输出各种SQL对性能的影响还是蛮大的,安全级别高一点的也可以设置mod模式,有条件也可以不在数据库层面做,而是购买设备放在网络层监控解析。
定位慢查询SQL
可以设置一定时长的参数(log_min_duration_statement),来记录超过该时长的所有SQL,对找出当前数据库的慢查询很有效。比如log_min_duration_statement = 2s,记录超过2秒的SQL,改完需要重载一下。
示例:
postgres=# show log_min_duration_statement ;
log_min_duration_statement
----------------------------
2s
监控数据库的锁
数据库的锁通常可以在pg_locks这个系统表里找,但这只是当前的锁表/行信息,如果你想看一天内有多少个超过死锁时间的锁发生,可以在日志里设置并查看,log_lock_waits 默认是off,可以设置开启。这个可以区分SQL慢是资源紧张还是锁等待的问题,示例:
postgres=# show log_lock_waits ;
log_lock_waits
----------------
on
(1 row)
postgres=# show deadlock_timeout ;
deadlock_timeout
------------------
1s
监控数据库的checkpoint
当数据库进行一项大更新操作时,如果参数设置不当,会在日志里留下大量的告警信息,频繁的做checkpoint会导致系统变慢。但是不会记录系统正常的checkpoint,如果你想看系统一天之类发生了多少次checkpoint,以及每次checkpoint的一些详细信息,比如buffer,sync等,就可以通过设置log_checkpoints,该参数默认值是off,修改log_checkpoints = on 示例:
postgres=# show log_checkpoints ;
log_checkpoints
-----------------
on
配置文件主要选项,详细的配置文件请点这里。
1. 连接相关
listen_addresses = '*' 数据库用来监听客户端连接的IP地址,*表示监听所有IP。
port = 5432 数据库监听户端连接的TCP端口。默认值是5432。
max_connections = 100 允许客户端的最大连接数,默认是100,足够了。
superuser_reserved_connections = 3 为超级用户保留的连接数,默认为3。
2. 资源使用
shared_buffers = 128MB 可以被PostgreSQL用于缓存数据的内存大小。大的shared_buffers需要大的checkpoint_segments,同时需要申请更多的System V共享内存资源。这个值不需要设的太大,因为PostgreSQL还依赖操作系统的cache来提高读性能。另外写操作频繁的数据库这个设太大反而会增加checkpoint压力(除非你使用了SSD或者IOPS能力很好的存储)。
work_mem = 4MB 内部排序和哈希操作可使用的工作内存大小。
maintenance_work_mem = 64MB 这里定义的内存只是在CREATE INDEX, VACUUM等时用到。这个值越大,VACUUM, CREATE INDEX的操作越快,当然大到一定程度瓶颈就不在内存了,可能是CPU例如创建索引。这个值是一个操作的内存使用上限,而不是一次性分配出去的。并且需要注意如果开启了autovacuum,最大可能有autovacuum_max_workers*maintenance_work_mem的内存被系统消耗掉。
3. WAL
wal_level = hot_standby 如果需要做数据库WAL日志备份的话至少需要设置成archive级别,如果需要做hot_standby那么需要设置成hot_standby。hot_standby意味着WAL记录得更详细,如果没有打算做hot_standby设置得越低性能越好。
fsync = on 强制把数据同步更新到磁盘
wal_buffers = -1 默认是-1 根据shared_buffers的设置自动调整shared_buffers*3%,最大限制是XLOG的segment_size。
checkpoint_segments = 3 多少个xlog file产生后开始checkpoint操作。建议设置为shared_buffers除以单个XLOG文件的大小。
checkpoint_timeout = 5min 这个和checkpoint_segments的效果是一样的,只是触发的条件是时间条件。
archive_mode = on 允许归档。
archive_command = 'cp %p /opt/pgsql/pg_archive/%f' 归档调用的命令。
4. 主从复制
## postgresql.conf
max_wal_senders = 32 最大的wal sender进程数。
hot_standby = on 在从服务器上设置为 on ,则该服务器也可用作查询。
max_standby_streaming_delay = 30s 数据流备份的最大延迟时间。
wal_receiver_status_interval = 10s 多久向主报告一次从的状态,当然从每次数据复制都会向主报告状态,这里只是设置最长的间隔时间。
hot_standby_feedback = on 如果有错误的数据复制,是否向主进行反馈。
## recovery.conf(只有从服务器需要配置)
standby_mode = on 说明该节点是从服务器
primary_conninfo = 'host=192.168.0.93 port=5432 user=replica password=replica' 主服务器的信息以及连接的用户
recovery_target_timeline = 'latest'
5. 内核资源
max_files_per_process = 1000 设定每个数据库进程能够打开的文件的数目。默认值是1000。
shared_preload_libraries = '' 设置数据库在启动时要加载的操作系统共享库文件。如果有多个库文件,名字用逗号分开。如果数据库在启动时未找到shared_preload_libraries指定的某个库文件,数据库将无法启动。默认值为空串。
6. AUTOVACUUM参数
autovacuum = on 是否打开数据库的自动垃圾收集功能。默认值是on。如果autovacuum被设为on,参数track_counts也要被设为on,自动垃圾收集才能正常工作。注意,即使这个参数被设为off,如果事务ID回绕即将发生,数据库会自动启动一个垃圾收集操作。这个参数只能在文件postgresql.conf中被设置。
log_autovacuum_min_duration = -1 单位是毫秒。如果它的值为0,所有的垃圾搜集操作都会被记录在数据库运行日志中,如果它的值是-1,所有的垃圾收集操作都不会被记录在数据库运行日志中。如果把它的值设为250毫秒,只要自动垃圾搜集发出的VACUUM和ANALYZE命令的执行时间超过250毫秒,VACUUM和ANALYZE命令的相关信息就会被记录在数据库运行日志中。默认值是-1。
autovacuum_max_workers = 3 设置能同时运行的最大的自动垃圾收集工作进程的数目。默认值是3。
autovacuum_naptime = 1min 设置自动垃圾收集控制进程的睡眠时间。
autovacuum_vacuum_threshold = 50 设置触发垃圾收集操作的阈值。默认值是50。只有一个表上被删除或更新的记录的数目超过了autovacuum_vacuum_threshold的值,才会对这个表执行垃圾收集操作。
7. 文件位置
data_directory = '/opt/pgsql/data' 数据存放位置,初始化时可以指定,也可以在这里修改。
hba_file = '/opt/pgsql/data/pg_hba.conf' 主从复制配置文件pg_hba.conf的路径
ident_file = /opt/pgsql/data/pg_ident.conf' 配置文件pg_ident.conf的路径
8. 编码
lc_messages = 'zh_CN.UTF-8' 系统错误信息的语言环境
lc_monetary = 'zh_CN.UTF-8' 货币格式的语言环境
lc_numeric = 'zh_CN.UTF-8' 数字的语言环境
lc_time = 'zh_CN.UTF-8' 时间的语言环境
9.一些不常见的配置文件项
log_min_duration_statement = 2000ms #跟踪哪些SQL执行时间长
log_statement = 'ddl' #记录DDL语句, 一般用于跟踪数据库中的危险操作
log_checkpoints = on #记录每一次checkpoint到日志中.
log_lock_waits = on #记录锁等待超过1秒的操作, 一般用于排查业务逻辑上的问题
deadlock_timeout = 1s
track_activity_query_size = 2048 #显示更长的SQL
autovacuum = on #log_autovacuum_min_duration = 0记录所有的autovacuum操作
默认的template0、template1和postgres系统数据库(该部分转自君子黎的微信空间)
当使用initdb命令初始化数据库集簇并且pg_ctl启动服务之后,该PostgreSQL中默认就会存在3个数据库,它们分别是:template1、template0 和 postgres,这三个数据库在PostgreSQL中也被称为“系统数据库”。这三个数据库之间有一定区别,也有一定联系。为了更加直观、形象地说明3个默认数据库之间的异同,先从一个数据库本身具有哪些属性字段、以及各自代表意义说起。PostgreSQL提供了一个名为pg_database的表,它可在所有数据库之间共享。通过查询该表,可以得到一个数据库的完整属性信息。
该表中各字段所代表的含义参考下图:
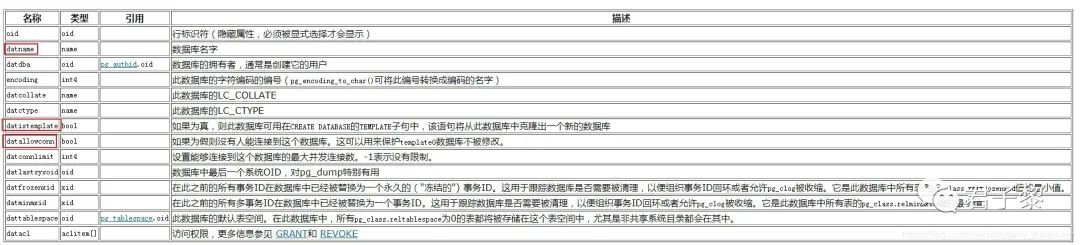
该表结构是在schemapg.h文件中进行声明的,它由genbki.pl文件相关函数API生成,并最终由relcache.c文件使用。
#define Schema_pg_database \
{ 1262, {"oid"}, 26, -1, 4, 1, 0, -1, -1, true, 'p', 'i', true, false, false, '\0', '\0', false, true, 0, 0 }, \
{ 1262, {"datname"}, 19, -1, NAMEDATALEN, 2, 0, -1, -1, false, 'p', 'c', true, false, false, '\0', '\0', false, true, 0, 950 }, \
{ 1262, {"datdba"}, 26, -1, 4, 3, 0, -1, -1, true, 'p', 'i', true, false, false, '\0', '\0', false, true, 0, 0 }, \
{ 1262, {"encoding"}, 23, -1, 4, 4, 0, -1, -1, true, 'p', 'i', true, false, false, '\0', '\0', false, true, 0, 0 }, \
{ 1262, {"datcollate"}, 19, -1, NAMEDATALEN, 5, 0, -1, -1, false, 'p', 'c', true, false, false, '\0', '\0', false, true, 0, 950 }, \
{ 1262, {"datctype"}, 19, -1, NAMEDATALEN, 6, 0, -1, -1, false, 'p', 'c', true, false, false, '\0', '\0', false, true, 0, 950 }, \
{ 1262, {"datistemplate"}, 16, -1, 1, 7, 0, -1, -1, true, 'p', 'c', true, false, false, '\0', '\0', false, true, 0, 0 }, \
{ 1262, {"datallowconn"}, 16, -1, 1, 8, 0, -1, -1, true, 'p', 'c', true, false, false, '\0', '\0', false, true, 0, 0 }, \
{ 1262, {"datconnlimit"}, 23, -1, 4, 9, 0, -1, -1, true, 'p', 'i', true, false, false, '\0', '\0', false, true, 0, 0 }, \
{ 1262, {"datlastsysoid"}, 26, -1, 4, 10, 0, -1, -1, true, 'p', 'i', true, false, false, '\0', '\0', false, true, 0, 0 }, \
{ 1262, {"datfrozenxid"}, 28, -1, 4, 11, 0, -1, -1, true, 'p', 'i', true, false, false, '\0', '\0', false, true, 0, 0 }, \
{ 1262, {"datminmxid"}, 28, -1, 4, 12, 0, -1, -1, true, 'p', 'i', true, false, false, '\0', '\0', false, true, 0, 0 }, \
{ 1262, {"dattablespace"}, 26, -1, 4, 13, 0, -1, -1, true, 'p', 'i', true, false, false, '\0', '\0', false, true, 0, 0 }, \
{ 1262, {"datacl"}, 1034, -1, -1, 14, 1, -1, -1, false, 'x', 'i', false, false, false, '\0', '\0', false, true, 0, 0 }
三个文件之间的调用示意图如下:

在这里,我们重点关注pg_database中的三个字段:datname、datistemplate 和 datallowconn。其中datname指定数据库名,datistemplate指明当前数据库是否为模板数据库t-是,f-否;datallowconn表示当前数据库是否允许用户连接登录。
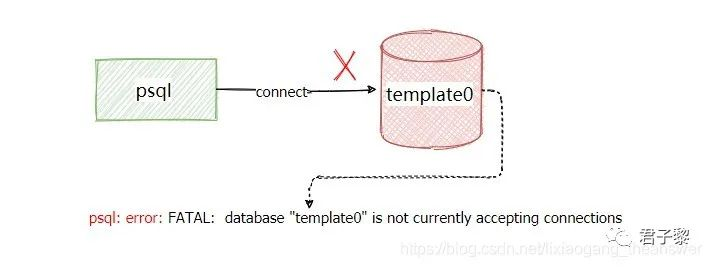
对于template0、template1和postgres三个系统数据库,它们具有以下几个特点:template0和template1数据库的datistemplate字段值是t,而postgres数据库的datistemplate字段值是f。表明template[0,1]这两个数据库是模板数据库,而postgres非模板数据库。postgres 和 template1数据库的datallowconn字段为t,而template0数据库f,表明数据库postgres和template1是允许用户包括psql连接,而template0不允许连接。
比如尝试连接template0数据库时候会报错:
# psql -p 9998 -U postgres -d template0;
psql: error: FATAL: database "template0" is not currently accepting connections
连接示意图如下:
postgres数据库是应用程序连接的默认数据库。它只是模板数据库template1的一个副本,如有必要,可以将其删除并重新创建。CREATE DATABASE语句创建数据库时,实际上是通过复制template1模板数据库得到。
使template0可连接
默认情况下,template0模板数据库不接受用户连接。但可以通过修改UPDATE其字段datallowconn值为t,使其接收用户连接。如下:
template1=# select * from pg_database;
oid | datname | datdba | encoding | datcollate | datctype | datistemplate | datallowconn | datconnlimit | datlastsysoid | datfrozenxid | datminmxid | dattablespace | datacl
-------+-----------+--------+----------+-------------+-------------+---------------+--------------+--------------+---------------+--------------+------------+---------------+-------------------------------
------
13580 | postgres | 10 | 6 | en_US.UTF-8 | en_US.UTF-8 | f | t | -1 | 13579 | 478 | 1 | 1663 |
1 | template1 | 10 | 6 | en_US.UTF-8 | en_US.UTF-8 | t | t | -1 | 13579 | 478 | 1 | 1663 | {=c/postgres,postgres=CTc/post
gres}
13579 | template0 | 10 | 6 | en_US.UTF-8 | en_US.UTF-8 | t | f | -1 | 13579 | 478 | 1 | 1663 | {=c/postgres,postgres=CTc/post
gres}
template1=# update pg_database set datallowconn = 't' where oid = 13579;
UPDATE 1
[root@freeoa postgresql-13.2]# psql -p 9998 -U postgres -d template0;
psql (13.2)
Type "help" for help.
当修改了datallowconn字段为t之后,现在psql命令用户可以登录template0数据库。但是不建议这么做,因为你不能保证永不会对该模板数据库中的数据信息作出修改。
注意:不能删除用户当前连接到的数据库。
系统表的定义
除了上面用于查看数据库的pg_database表之外,还有pg_class查看表结构体、pg_type查看数据基本类型、pg_proc存储关于函数信息、pg_attribute存储关于表字段信息等等。这些系统表的生成过程大致是:所有系统表定义通过Catalog.pm来转为perl中的数据结构,最后通过genbki.pl脚本转换为postgres.bki文件;而bki文件则是用于初始化PostgreSQL目标数据库。转换示意图如下:
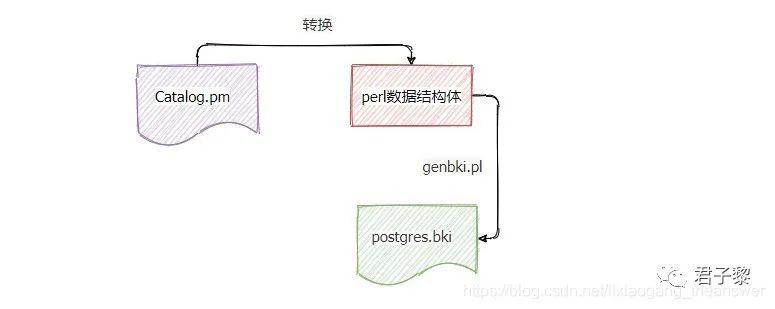
其中postgres.bki文件位于源码安装时所指定--prefix参数目录路径的share目录执行。
对于postgres.bki中的文件,其内容格式如下:
# PostgreSQL 13
create pg_proc 1255 bootstrap rowtype_oid 81
(
oid = oid ,
proname = name ,
. . . //省略若干
proacl = _aclitem
)
. . . //省略若干
insert ( 33 charout 11 10 12 1 0 0 0 f f f t f i s 1 0 2275 18 _null_ _null_ _null_ _null_ _null_ charout _null_ _null_ _null_ )
当使用initdb来初始化数据库集簇时候,有相应函数API来读取该文件并进行执行创建template1模板数据库,其整个创建流程图大致如下:
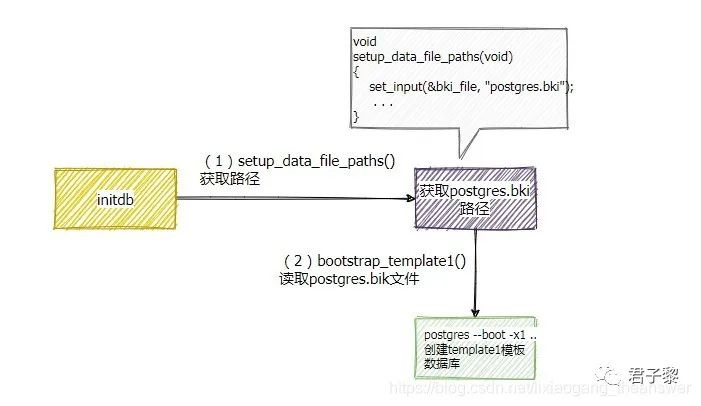
对于模板数据库tempate1创建过程的更多细节,阅读initdb.c文件,主要由函数bootstrap_template1()完成。
template1作为默认模板
当用户创建数据库时,在不特意指定createdb -T 模板数据库名、CREATE DATABASE WITH 模板数据库名模板数据库源的情况下,默认是从template1模板数据库中进行拷贝。因此template1模板数据库中的原有的所有数据表、表、索引和函数等等都会被新创建的数据库给继承。
1、将当前数据库切换到template1中
postgres=# \c template1;
You are now connected to database "template1" as user "postgres".
2、在template1中创建名为TEST的数据表
template1=# CREATE TABLE TEST(id SERIAL PRIMARY KEY, name VARCHAR(20));
CREATE TABLE
template1=# \d+
List of relations
Schema | Name | Type | Owner | Persistence | Size | Description
--------+-------------+----------+----------+-------------+------------+-------------
public | test | table | postgres | permanent | 0 bytes |
public | test_id_seq | sequence | postgres | permanent | 8192 bytes |
(2 rows)
3、向表中插入5条记录
template1=# INSERT INTO TEST(name) VALUES ('1');
INSERT 0 1
template1=# INSERT INTO TEST(name) VALUES ('2');
INSERT 0 1
template1=# INSERT INTO TEST(name) VALUES ('3');
INSERT 0 1
template1=# INSERT INTO TEST(name) VALUES ('4');
INSERT 0 1
template1=# INSERT INTO TEST(name) VALUES ('5');
INSERT 0 1
4、查看TEST表信息
template1=# SELECT *FROM TEST;
id | name
----+------
1 | 1
2 | 2
3 | 3
4 | 4
5 | 5
5、现在重新创建一个名为db_test的数据库,然后切换到db_test数据库中,实用\d+命令查看当前数据库下的表信息时,可看到有一个名为test的数据表。该表是从template1目模板数据库中继承过来,包括里面的数据。正如前面所言,CREATE DATABASEcreatedb原理都一样创建数据库时候,默认情况下会继承template1中的所有数据信息。
template1=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
template1=# CREATE DATABASE db_test;
CREATE DATABASE
template1=# \c db_test;
You are now connected to database "db_test" as user "postgres".
db_test=# \d+
List of relations
Schema | Name | Type | Owner | Persistence | Size | Description
--------+-------------+----------+----------+-------------+------------+-------------
public | test | table | postgres | permanent | 8192 bytes |
public | test_id_seq | sequence | postgres | permanent | 8192 bytes |
(2 rows)
db_test=# SELECT *FROM test;
id | name
----+------
1 | 1
2 | 2
3 | 3
4 | 4
5 | 5
模板数据库template0除了不是创建数据库默认的源数据库模板之外,tempate1和template0没有任何其他的特殊状态。比如我们可以删除template1并从template0中重新创建它,而不会产生任何其他不良的影响。会不会有人会疑惑template0是不是显得有些多余?其实不然,因为template1默认支持用户连接,那么就有可能会面临着其数据信息被不小心篡改的风险。因此PostgreSQL为了满足能够给用户一个干净也就是最原始的数据库需求,当需要时候可用指定从template0模板数据库中去继承。
删除模板
PostgreSQL中这三个系统数据库都是可删除的,但是若该数据库为模板数据库,则不支持删除除非手动修改字段datistemplate的值为f。在datistemplate字段为t时,若尝试删除该模板数据库,则会报错。
template1=# select datistemplate from pg_database where datname = 'template1';
datistemplate
---------------
t
template1=# DROP DATABASE template1;
ERROR: cannot drop a template database
删除示意图如下图:
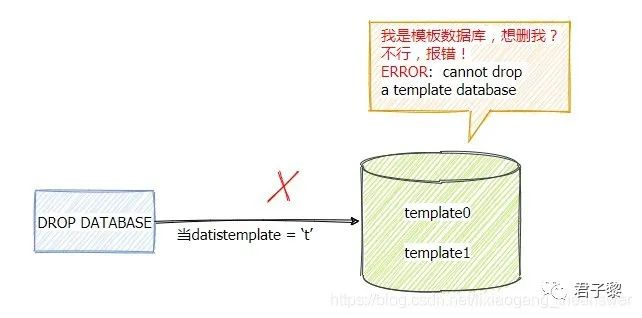
若将字段datistemplate修改为f,则可以进行删除。
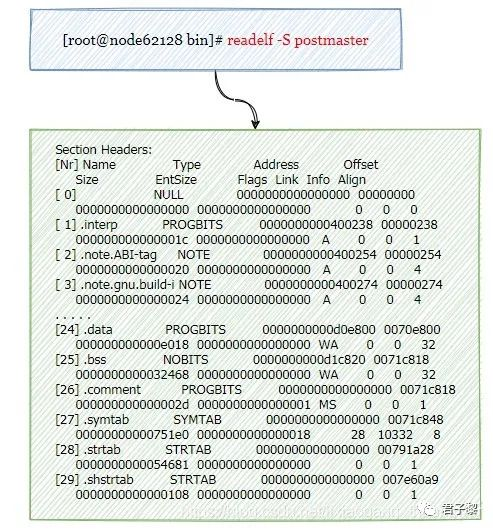
关于对PosgrgreSQL调试
在执行configure可执行程序时候,可附加上与调试信息相关的系列参数。可执行文件postmaster中当前共有30个段表,但是该段表中不存在与调试信息(与调试信息相关的段均以.debug_开头)相关的符号表。因此在postmaster服务出现某些底层内核问题(比如访问非法内存,发送SIGSEGV信号)的时候,是无法进一步地进行定位和分析的。所以这里主要目的就是讲解如何编译带调试符号信息的postmaster,以及如何通过gdb结合源码来定位问题。
在执行configure可执行程序时候,附加上与调试信息相关的系列参数。通过执行./configure --help可得知当前该configure可执行程序所能支持的完整选项参数列表。在这里选择 --enable-debug(-g)、-- enable-depend 和 --enable-cassert即可,它们各项所代表的的意义将在下面分别一一介绍。
1)允许断言
--enable-cassert参数表示将允许在postmaster服务器中打开断言检查。它将会检查许多不可能的条件和选项。
2)允许调试符号
--enable_debug参数选项表示编译带调试信息的postmaster可执行程序。用调试信息去编译所有的程序和库,从而使得可用GDB(程序调试工具)来跟踪postmaster服务中行为异常的逻辑代码和业务。
3)自动依赖性跟踪
--enable_depend选项参数表示将打开自动依赖性检测和跟踪,这个参数使用场景较少,所以这里不会太多篇幅来讲解,仅做了解即可。
完整的执行命令
在对这三个可选参数有了一定了解后,我们来看下完整的configure程序执行的命令方式,如下:
(1)[postgresql-13.2] # ./configure --enable-debug --enable-depend --enable-cassert --prefix=/opt/pg132
(2)make -j & make install //当然,你也可以选择其拆开为两个步骤执行,即: (2.1) make -j; (2.2) make install
在使用GDB调试工具来跟踪postmaster运行情况或是分析源码时候,我们可以有两种方式来获取postmaster进程的PID。
1)、pg_backend_pid()获取PID
psql程序命令登录postmaster服务,然后使用pg_backend_pid()函数来获取当前会话的服务器进程的PID。如下所示:
postgres=# select pg_backend_pid();
pg_backend_pid
----------------
9527
2)、ps -eLf|grep postgres获取PID
通过ps命令来获取postmaster服务的进程PID。在得知了postmaster服务的进程PID之后,便可使用GDB来跟踪进程服务状态信息了。通过 gdb -p PID的方式,来调试postmaster服务。如下所示,在gdb跟踪到该进程之后,使用list命令列出当前位置的postmaster服务源代码,当然也可以根据自己需要开始对源码进行断点等操作。
# gdb -p 9527
Loaded symbols for /lib64/libnss_files.so.2
0x00007fb6ff1a9a13 in __select_nocancel () from /lib64/libc.so.6
Missing separate debuginfos, use: debuginfo-install glibc-2.17-323.el7_9.x86_64
(gdb) list //列出当前位置的源码,
52 static void help(const char *progname);
53 static void check_root(const char *progname);
54
55
56 /*
57 * Any Postgres server process begins execution here.
58 */
59 int
60 main(int argc, char *argv[])
61 {
(gdb)
附:建议在使用gdb来调试postmaster服务的时候,结合该postmaster服务所对应的源码版本进行分析,效果更佳。
除了使用 gdb -p PID的方式外还可以使用以下步骤来进行调试:
# gdb //开启gdb调试
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-120.el7
(gdb) attach 9527 //使gdb与当前指定PID相关联
如果觉得源码安装过于繁琐,可以在各个操作系统发行版本中使用其提供的官方软件源进行安装或《使用非官方源安装最新的Postgresql》。